Databricks Workspace 管理 – アカウント、ワークスペース、メタストア管理者のためのベストプラクティス
3人の管理者の物語
によって アニンディタ・マハパトラ, Mohan Mathews 、 Greg Wood による投稿
このブログは、Databricks管理者を対象としたトピックについて説明する、管理者の基本事項シリーズの一部です。他のブログには、ワークスペース管理のベストプラクティス、Terraform を使用した DR 戦略などがあります。今後もコンテンツにご期待ください。過去の管理者向けブログでは、DR、CI/CD、システムヘルスチェックなどの側面を自動化し、事前の設計を通じて強力なワークスペース組織を確立および維持する方法について説明しました。管理の同様に重要な側面は、ワークスペース内の整理方法です。特に、Lakehouse 内に存在する可能性のあるさまざまな種類の管理者ペルソナを考慮すると重要です。このブログでは、次のようなワークスペース管理の管理上の考慮事項について説明します。
- 新しいユーザーとユースケースのオンボーディングを将来にわたって保護するためのポリシーとガードレールの設定
- リソースの使用状況の管理
- 許可されたデータアクセスを保証
- 投資を最大限に活用するためのコンピューティング使用量の最適化
ロールの区別を理解するために、まずアカウント管理者とワークスペース管理者の違い、および各ロールが管理する特定のコンポーネントを理解する必要があります。
アカウント管理者 vs ワークスペース管理者 vs メタストア管理者
管理上の懸念事項は、アカウント(組織と 1:1 でマッピングされることが多い高レベルの構造)とワークスペース(LOB ごとにマッピングす��るなど、さまざまな方法でマッピングできる、より詳細な分離レベル)の両方にまたがって分割されます。これらの 3 つのロール間の職務分掌を見てみましょう。
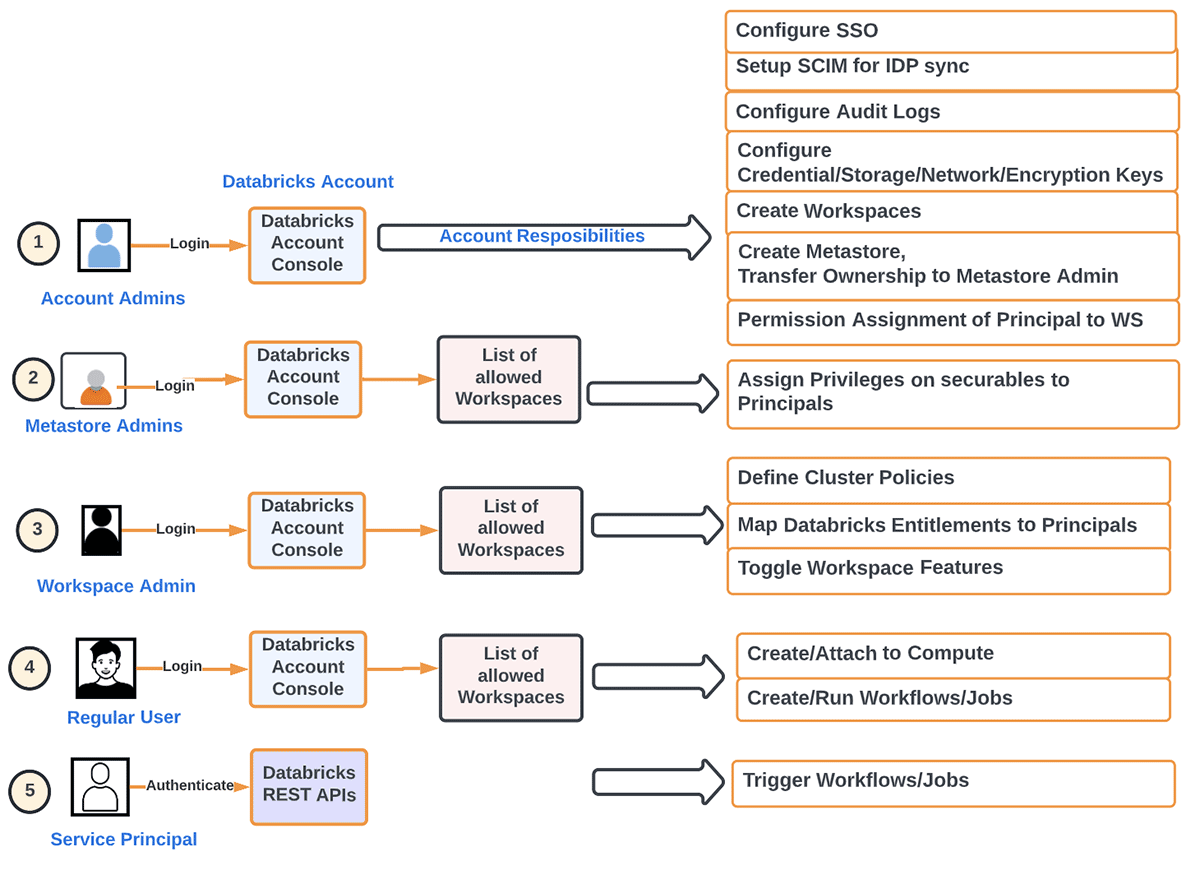
これを別の方法で表現すると、アカウント管理者の主な責任を次のように分解できます。
- アカウントレベルでのプリンシパル(グループ/ユーザー/サービス)と SSO のプロビジョニング。ID フェデレーションとは、アカウントレベルの ID にアカウントから直接ワークスペースへのアクセスを割り当てることを指します。
- メタストアの構成
- 監査ログの設定
- アカウントレベルでの使用状況の監視(DBU、請求)
- 希望する組織方法に従ったワークスペースの作成
- 他のワークスペースレベルのオブジェクト(ストレージ、資格情報、ネットワークなど)の管理
- 人間的要素を排除するために IaC を使用した開発ワークロードの自動化
- サーバーレスワークロード、Delta sharing などの機能をアカウントレベルでオン/オフにする
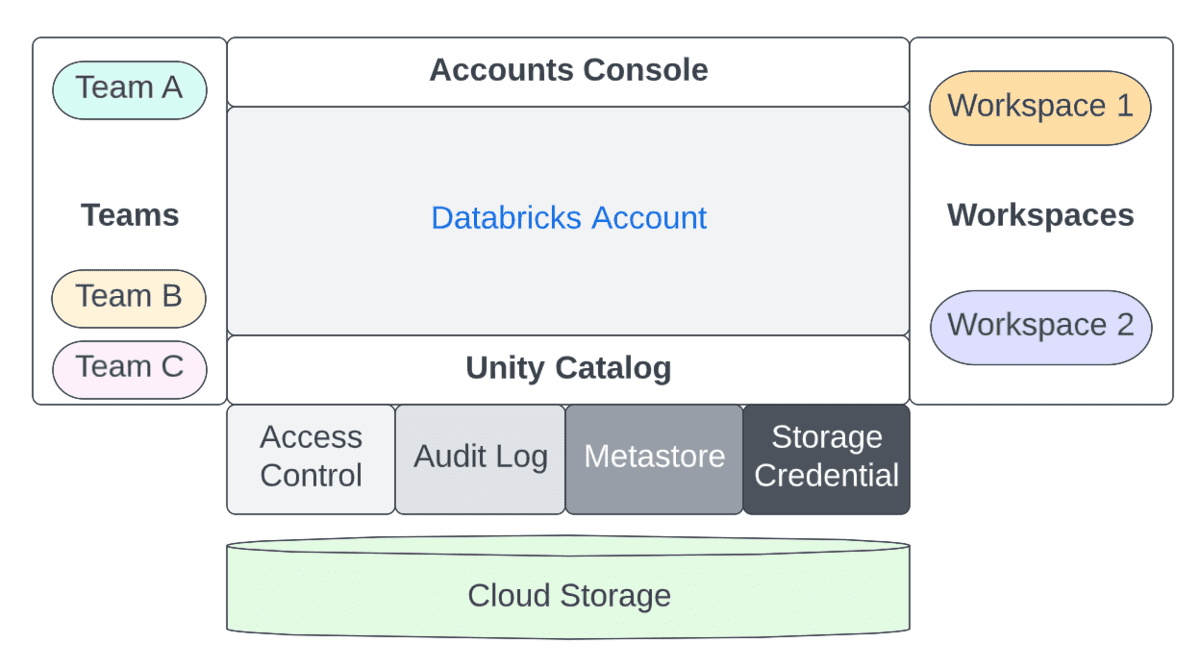
一方、ワークスペース管理者の主な関心事は次のとおりです。
- プリンシパルへのワークスペースレベルでの適切なロール(ユーザー/管理者)の割り当て
- プリンシパルへのワークスペースレベルでの適切な権限(ACL)の割り当て
- ワークスペースレベルでの SSO のオプション設定
- プリンシパルに権限を付与するためのクラスターポリシーの定義。これにより、プリンシパルは次のことが可能になります。
- コンピューティングリソース(クラスター/ウェアハウス/プール)の定義
- オーケストレーション(ジョブ/パイプライン/ワークフロー)の定義
- ワークスペースレベルでの機能のオン/オフ
- プリンシパルへの権限の割り当て
- データアクセス(内部/外部 Hive メタストアを使用する場合)
- コンピューティングリソースへのプリンシパルのアクセスの管理
- Repos などの機能の外部 URL の管理(許可リストを含む)
- セキュリティとデータ保護の制御
- チーム間での意図しないデータ漏洩を防ぐために DBFS をオフ/制限する
- データ漏洩を防ぐために、結果データのダウンロード(ノートブック/DBSQL から)を防止する
- アクセ�ス制御(ワークスペースオブジェクト、クラスター、プール、ジョブ、テーブルなど)を有効にする
- クラスターレベルでのログ配信の定義(つまり、クラスターログ用のストレージの設定。理想的にはクラスターポリシーを介して)
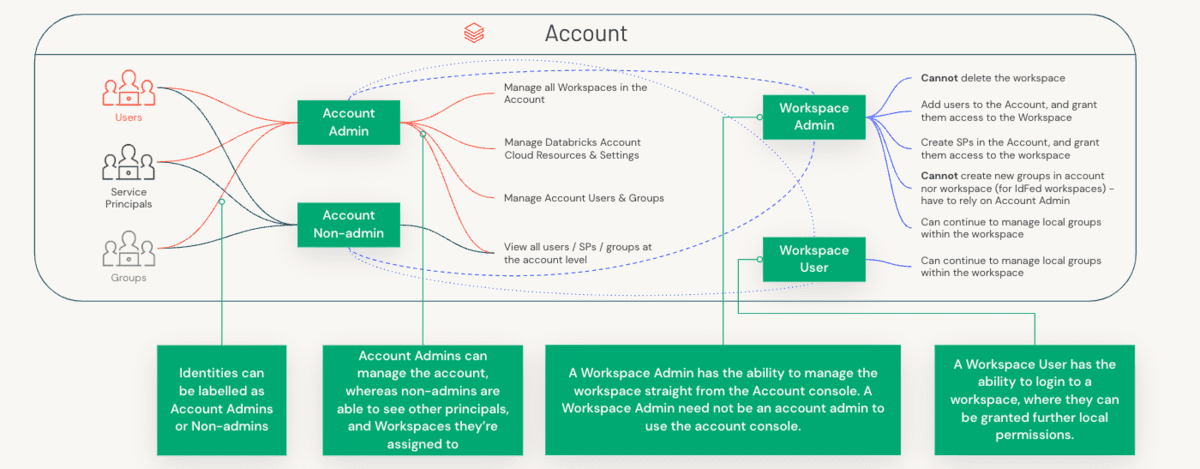
アカウント管理者とワークスペース管理者の違いを要約すると、次の表は、いくつかの主要な次元におけるこれらの 2 つのペルソナ間の分離を示しています。
| アカウント管理者 | メタストア管理者 | ワークスペース管理者 | |
|---|---|---|---|
| ワークスペース管理 | - ワークスペースの作成、更新、削除 - 他の管理者の追加が可能 |
適用外 | - ワークスペース内のアセットのみを管理 |
| ユーザー管理 | - ユーザー、�グループ、サービスプリンシパルを作成するか、SCIM を使用して IDP からデータを同期する。 - アクセス許可割り当て API を使用してプリンシパルにワークスペースへの権限を付与する |
適用外 | - すべてのデータアセット(セキュラブル)の集中管理には UC の使用を推奨します。ID フェデレーションは、Unity Catalog(UC)メタストアにリンクされたすべてのワークスペースで有効になります。 - ID フェデレーションで有効化されたワークスペースの場合、すべてのプリンシパルについてアカウントレベルで SCIM を設定し、ワークスペースレベルでの SCIM は停止します。 - UC 以外のワークスペースの場合、ワークスペースレベルで SCIM を使用できます(ただし、これらのユーザーはアカウントレベルの ID にも昇格されます)。 - ワークスペースレベルで作成されたグループは、「ローカル」ワークスペースレベルのグループと見なされ、Unity Catalog へのアクセス権は持ちません |
| データアクセスと管理 | - メタストアの作成 - メタストアへのワークスペースのリンク - メタストアの所有権をメタストア管理者/グループに移管 |
Unity Catalog を使用する場合: - メタストアのすべてのセキュラブル(カタログ、スキーマ、テーブル、ビュー)に対する権限の管理 - データスチュワード/オーナーへのカタログ、スキーマ(データベース)、テーブル、ビュー、外部ロケーション、ストレージ資格情報へのアクセスを付与(委任) |
- 現在の Hive メタストアでは、顧客はインスタンス��プロファイル(AWS)、サービスプリンシパル(Azure)、テーブル ACL、資格情報パススルーなど、さまざまな構造を使用してデータアクセスを保護しています。 - Unity Catalog では、これはアカウントレベルで定義され、ANSI GRANTS を使用してすべてのセキュラブルを ACL 化します |
| クラスター管理 | 適用外 | 適用外 | - DE/ML/SQL ペルソナ向けのさまざまなペルソナ/サイズのクラスターの作成(S/M/L ワークロード向け) - デフォルトのユーザーグループからallow-cluster-create権限を削除する。 - クラスターポリシーを作成し、適切なグループにポリシーへのアクセスを付与する - SQLウェアハウスに対するグループへの Can_Use 権限を付与する |
| ワークフロー管理 | 適用外 | 適用外 | - ジョブ/DLT/オールパーパスクラスターポリシーが存在し、グループがそれらにアクセスできることを確認する - ユーザーが再起動できるアプリケーション専用クラスターを事前作成する |
| 予算管理 | - ワークスペース/SKU/クラスタータグごとの予算の設定 - アカウントコンソールでのタグによる使用状況の監視(ロードマップ) - DBSQL を介してクエリ可能な請求対象使用量システムテーブル(ロードマップ) |
適用外 | 適用外 |
| 最適化 / チューニング | 該当な�し | 該当なし | - コンピューティングの最大化; 最新のDBRを使用; Photonを使用 - ベストプラクティスと最適化に従い、インフラストラクチャ投資を最大限に活用するために、事業部門/センターオブエクセレンスチームと連携する |
ワークスペースをピーク時のコンピューティングニーズに合わせてサイジングする
クラスターノードの最大数(間接的には最大のジョブまたは同時実行ジョブの最大数)は、VPCで利用可能なIPの最大数によって決まります。したがって、VPCを正しくサイジングすることは重要な設計上の考慮事項です。各ノードは2つのIPを消費します(Azure、AWSの場合)。お使いのクラウドに関する関連詳細は次のとおりです: AWS、Azure、GCP。これを説明するために、Databricks on AWSの例を使用します。CIDRをIPにマッピングするにはこちらを使用してください。E2ワークスペースで許可されるVPC CIDR範囲は /25 から /16 です。少なくとも2つの異なるアベイラビリティゾーンに2つのプライベートサブネットを設定する必要があります。サブネットマスクは /16 から /17 の間である必要があります。VPCは論理的な分離単位であり、2つのVPCが通信する必要がない限り(つまり、ピアリングする必要がない限り)、同じ範囲を持つことができます。ただし、通信する必要がある場合は、IPの重複を避けるために注意が必要です。CIDR範囲 /16 のVPCの例を取り上げましょう:
| VPC CIDR /16 | このVPCの最大IP数: 65,536 | シングル/マルチノードクラスターはサブネット内で起動されます |
| 2 AZ | 各AZが /17 の場合: => 32,768 * 2 = 65,536 IP 他のサブネットは使用できません | 32,768 IP => 各サブネットで最大16,384ノード |
| 各AZが /23 の場合: => 512 * 2 = 1,024 IP 65,536 - 1,024 = 64, 512 IPが残ります | 512 IP => 各サブネットで最大256ノード | |
| 4 AZ | 各AZが /18 の場合: 16,384 * 4 = 65,536 IP 他のサブネットは使用できません | 16,384 IP => 各サブネットで最大8192ノード |
管理者にとってのコントロールとアジリティのバランス
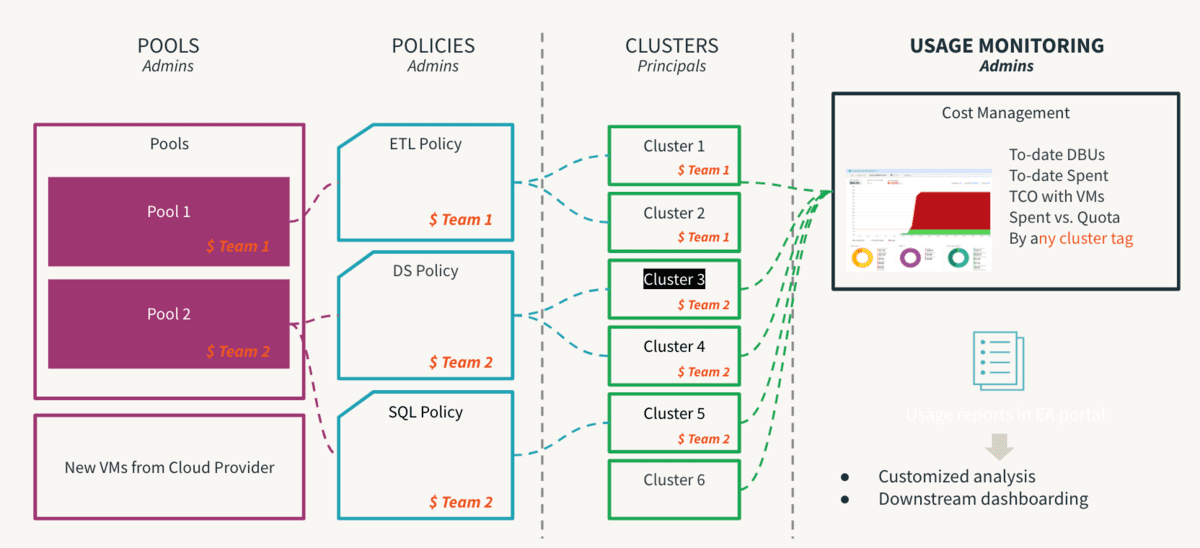
コンピューティングは、あらゆるクラウドインフラストラクチャ投資の中で最も高価なコンポーネントです。データの民主化はイノベーションにつながり、セルフサービスを促進することは、データ主導の文化を可能にするための最初のステップです。しかし、マルチテナント環境では、経験の浅いユーザーや意図しないヒューマンエラーが、コストの暴走や意図しない情報漏洩につながる可能性があります。コントロールが厳しすぎると、アクセスがボトルネックとなり、イノベーションが阻害されます。そのため、管理者は、固有のリスクなしにセルフサービスを許可するためのガードレールを設定する必要があります。さらに、これらのコントロールの遵守状況を監視できる必要があります。そこで役立つのがクラスターポリシーです。ここではルールが定義され、権限がマッピングされるため、ユーザーは許容される範囲内で操作でき、意思決定プロセスが大幅に簡素化されます。ポリシーは、プロセスによって裏付けられて初めて真に効果的になることに注意してください。これにより、例外的なケースをプロセスで管理して、不必要な混乱を避けることができます。このプロセスの重要なステップの1つは、ワークスペースのデフォルトのusersグループからallow-cluster-create権限を削除することです。これにより、ユーザーはクラスターポリシーで管理されたコンピューティングのみを利用できるようになります。�以下は、クラスターポリシーのベストプラクティスのトップ推奨事項であり、以下のように要約できます:
- Tシャツサイズを使用して標準的なクラスターテンプレートを提供する
- ワークロードサイズ別(小、中、大)
- ペルソナ別(DE/ ML/ BI)
- 習熟度別(市民/上級)
- 以下の使用を強制することでガバナンスを管理する
- タグ: チーム、ユーザー、ユースケースによる属性付け
- 命名規則は標準化する
- 一部の属性を必須にすると、一貫したレポート作成に役立ちます
- タグ: チーム、ユーザー、ユースケースによる属性付け
- 以下の制限により消費を制御する
- DBUバーンレートとポリシーの目的
- 自動終了タイムアウト、最小/最大スケールサイズ
コンピューティングに関する考慮事項
固定のオンプレミスコンピューティングインフラストラクチャとは異なり、クラウドは、対象となるワークロードとSLAに適切なコンピューティングを一致させるための弾力性と柔軟性を提供します。下の図は、さまざまなオプションを示しています。入力は、ワークロードの種類や環境などのパラメータであり、出力は最適なコンピューティングの種類とサイズです。
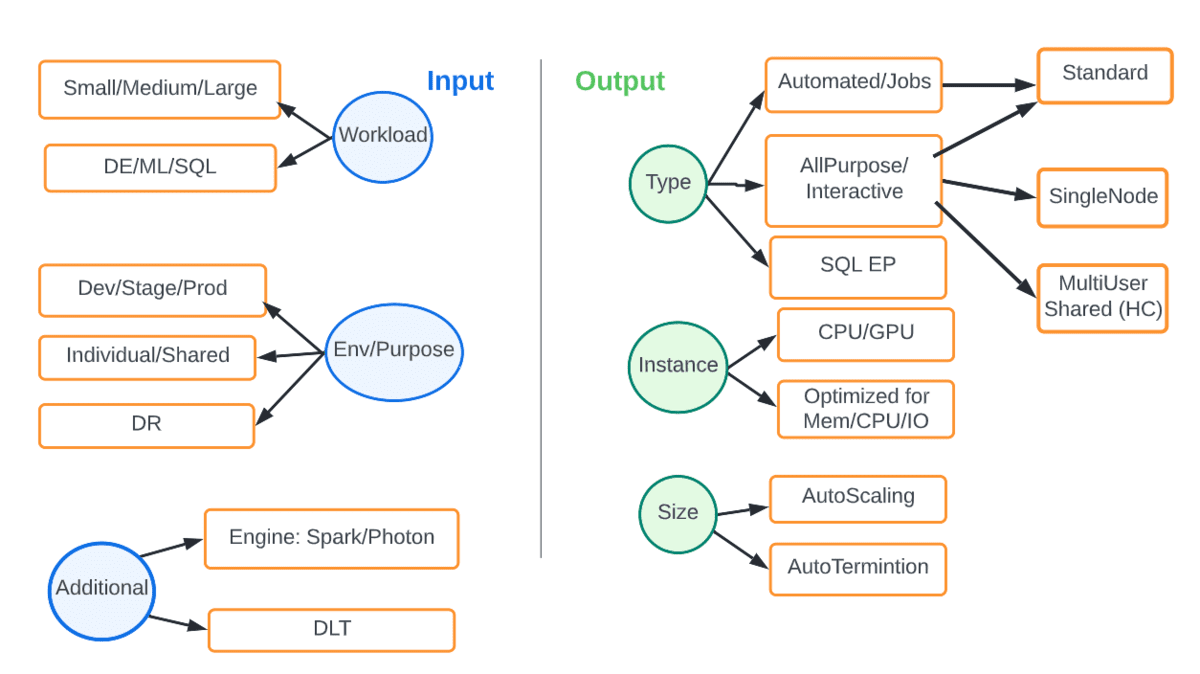
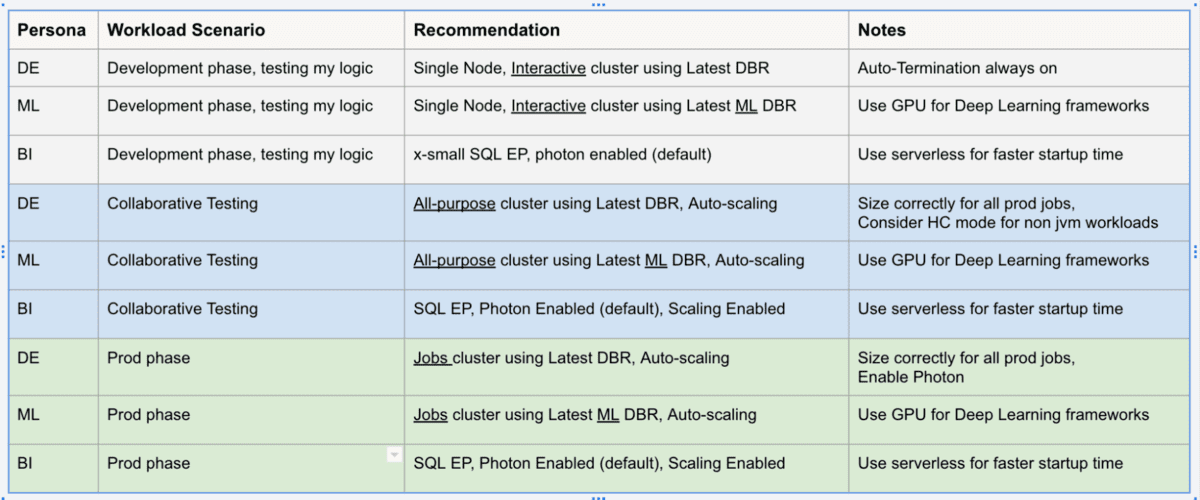
たとえば、本番環境のDEワークロードは、常に自動ジョブクラスターで実行されるべきであり、最新のDBRを使用し、オートスケーリングを有効にし、Photonエンジンを使用することが推奨されます。下の表は、一般的なシナリオをまとめたものです。
ワークフローに関する考慮事項
コンピューティング要件が正式化されたので、次に考慮すべきは次の点です:
- ワークフローの定義とトリガー方法
- タスクが互いにコンピューティングを再利用する方法
- タスクの依存関係の管理方法
- 失敗したタスクの再試行方法
- バージョンアップグレード(Spark、ライブラリ)とパッチの適用方法
これらは、ユースケースを中心に据えたデータエンジニアリングおよびDevOpsの考慮事項であり、通常は管理者の直接的な関心事です。監視できる衛生上のタスクがいくつかあります:
- ワークスペースには、設定されたジョブの総数に最大制限があります。しかし、これらのジョブの多くは呼び出されず、正規のジョブのためにスペースを確保するためにクリーンアップする必要があります。管理者は、無効なジョブの追放リストを決定するためのチェックを実行できます。
- すべての本番ジョブはサービスプリンシパルとして実行されるべきであり、本番環境へのユーザーアクセスは厳しく制限されるべきです。ジョブの権限を確認してください。
- ジョブは失敗する可能性があるため、すべてのジョブで失敗アラートを設定し、オプションで再試行を設定する必要があります。ここで、email_notifications、max_retries、その他のプロパティを確認してください。
- すべてのジョブはクラスターポリシーに関連付けられ、属性付けのために適切にタグ付けされるべきです。
DLT: 大規模な信頼性の高いパイプラインのための理想的なフレームワークの例
大小さまざまな数千ものクライアントとさまざまな業界の垂直分野で作業する中で、開発と運用における一般的なデータ課題が明らかになったため、DatabricksはDelta Live Tables (DLT) を作成しました。これは、ETLワークロードの開発とメンテナンスを簡素化するマネージドプラットフォームであり、「どのように」ではなく「何を」指定することで宣言型のパイプラインを作成できます。これにより、データエンジニアのタスクが簡素化され、管理者のサポートシナリオが減少します。
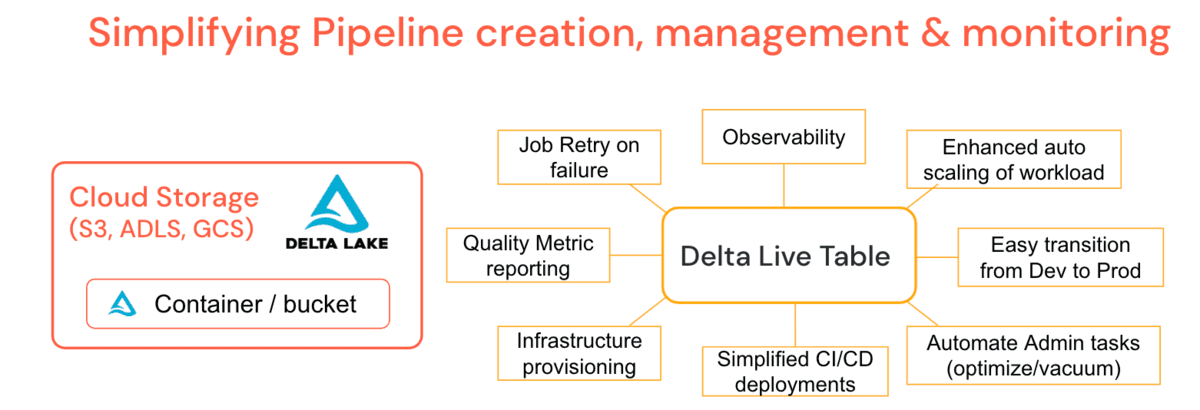
DLTは、定期的なoptimize & vacuumジョブなどの一般的な管理機能をパイプライン定義に組み込んでおり、追加の監視なしで実行できるメンテナンスジョブを提供します。DLTは、リネージ、監視、データ品質チェックなどの運用を簡素化するためのパイプラインの深いオブザーバビリティを提供します。たとえば、クラスターが終了した場合、プラットフォームはデータエンジニアが明示的にプロビジョニングしたことに依存するのではなく、(本番モードで)自動再試行します。強化された自動スケーリングは、クラスターのサイズ変更を必要とする突然のデータバーストを処理し、スムーズにスケールダウンできます。つまり、自動化されたクラスターのスケーリングとパイプラインの耐障害性はプラットフォームの機能です。ターンテーブルレイテンシにより、バッチまたはストリーミングでパイプラインを実行でき、コードではなく構成を管理することで、開発パイプラインを比較的簡単に本番環境に移行できます。パイプラインのコストは、DLT固有のクラスターポリシーを利用することで制御できます。DLTはランタイムエンジンも自動アップグレードす��るため、管理者やデータエンジニアの責任が軽減され、ビジネス価値の創出に集中できます。
UC: 理想的なデータガバナンスフレームワークの例
Unity Catalog(UC)により、組織は単一のアカウント下のすべてのワークスペースに対してテーブルとファイルの共通セキュリティモデルを採用できます。これは、単純なGRANTステートメントでは以前は不可能でした。DE/DSクラスターまたはSQL Warehouseからのデータ、テーブル、またはファイルへのすべてのアクセスを付与および監査することにより、組織はクラウドごとのプリミティブに依存することなく、監査および監視戦略を簡素化できます。UCが提供する主な機能は次のとおりです。
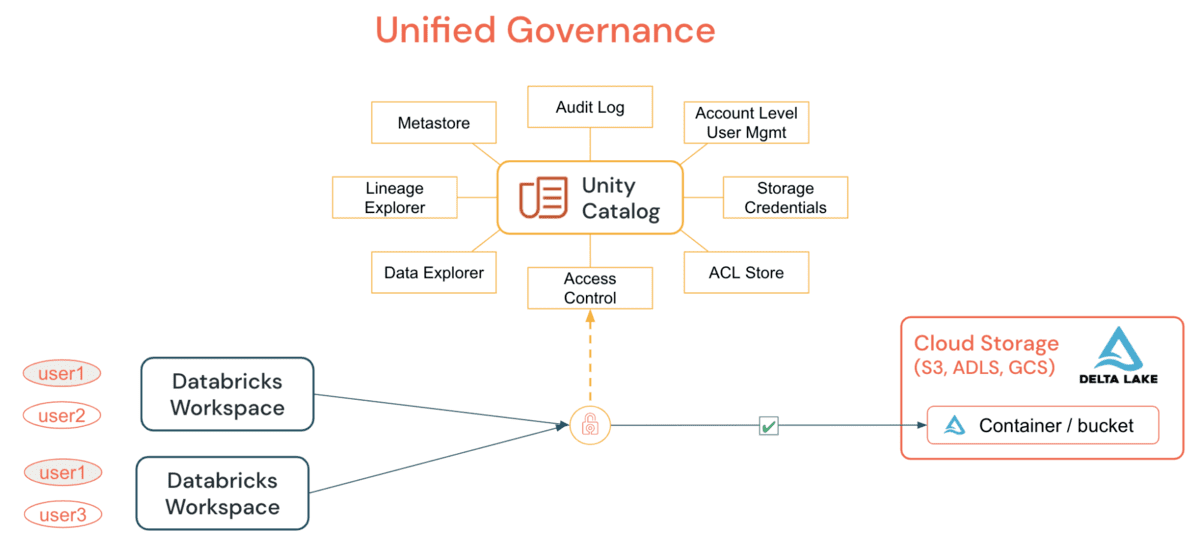
UCは、メタストア全体でのデータの定義、監視、検出可能性を一元化し、ワークスペースの数に関係なく安全にデータを共有しやすくすることで、管理者(アカウントレベルとワークスペースレベルの両方)のジョブを簡素化します。これは、一度定義すればどこでも安全というモデルを利用することで、ユーザーの権限が誤っ�て表現された場合に、意図しないデータへのアクセスを許可してしまうというシナリオでの偶発的なデータ漏洩を防ぐという利点があります。これらはすべて、アカウントレベルのIDとデータ権限を利用することで簡単に実現できます。UC監査ログにより、すべてのレベルのすべてのユーザーによるすべてのオブジェクトに対するすべての操作を完全に可視化できます。また、詳細な監査ログを構成すると、ノートブックまたはDatabricks SQLから実行された各コマンドがキャプチャされます。セキュラブルへのアクセスは、メタストア管理者、オブジェクトの所有者、またはオブジェクトを含むカタログまたはスキーマの所有者によって付与できます。アカウントレベル管理者は、メタストア管理者の役割を委任し、適切なアクセス権限を付与することのみを目的としたグループを指定することが推奨されます。
推奨事項とベストプラクティス
- アカウント管理者、メタストア管理者、ワークスペース管理者の役割と責任は明確に定義されており、相互に補完的です。自動化、変更要求、エスカレーションなどのワークフローは、ワークスペースがLOBによって設定されているか、中央のCenter of Excellenceによって管理されているかに関わらず、適切な所有者に流れるべきです。
- アカウントレベルのIDを有効にしてください。これにより、すべてのワークスペースで集中管理されたプリンシパル管理が可能になり、管理が簡素化されます。アカウントレベルでのSSO、SCIM、監査ログなどの機能の設定をお勧めします。SSOフェデレーション機能が利用可能になるまで、ワークスペースレベルのSSOは引き続き必要です。
- クラスターポリシーは、効果的なセルフサービスのためのガードレールを提供する強力な手段であり、ワークスペース管理者の役割を大幅に簡素化します。サンプルポリシーはこちらで提供しています。アカウント管理者は、主にペルソナ/Tシャツサイズに基づいたシンプルなデフォルトポリシーを、理想的にはTerraformなどの自動化を通じて提供する必要があります。ワークスペース管理者は、より詳細な制御のためにそのリストに追加できます。適切なプロセスと組み合わせることで、すべての例外的なシナリオに柔軟に対応できます。
- すべてのワークスペースにわたるすべてのワークロードタイプの継続的な消費の追跡は、アカウントコンソールを通じてアカウント管理者が確認できます。請求可能な使用状況ログの配信を設定し、すべて中央のクラウドストレージに送信して、チャージバックと分析を行うことをお勧めします。予算API(プレビュー版)はアカウントレベルで構成する必要�があり、これによりアカウント管理者はワークスペース、SKU、クラスタータグレベルでしきい値を作成し、消費に関するアラートを受け取ることができるため、割り当てられた予算内に収まるようにタイムリーなアクションを実行できます。計算リソースの利用率に関して改善の余地がある領域を特定するのに役立つ、Overwatchのようなツールを使用して、さらに詳細なレベルで使用状況を追跡します。
- Databricksプラットフォームは、一般的な管理機能をプラットフォームに抽象化することで、さまざまなデータペルソナのジョブを革新し、簡素化し続けています。新しいパイプラインにはDelta Live Tablesを、すべてのユーザー管理とデータアクセス制御にはUnity Catalogを使用することをお勧めします。
最後に、これらのベストプラクティスのほとんど、そして実際、このブログで言及していることのほとんどにおいて、連携とチームワークが成功の鍵であることを覚えておくことが重要です。アカウント管理者とワークスペース管理者がサイロ化して存在する可能性は理論的にはありますが、これは一般的なLakehouseの原則に反するだけでなく、関係者全員の生活を困難にします。おそらくこの記事から持ち帰るべき最も重要な提案は、組織内のアカウント/ワークスペース管理者とプロジェクト/データリード、およびユーザーを連携させることです。Teams/Slackチャンネル、�メールエイリアス、および/または週次のミーティングなどのメカニズムが成功したことが証明されています。Databricksで私たちが目にする最も効果的な組織は、テクノロジーだけでなく、運用においてもオープンさを受け入れている組織です。ログ記録と流出防止の推奨事項から、管理に焦点を当てたプラットフォーム機能のエキサイティングなまとめまで、管理者に焦点を当てたブログがまもなく登場しますので、ご期待ください。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。