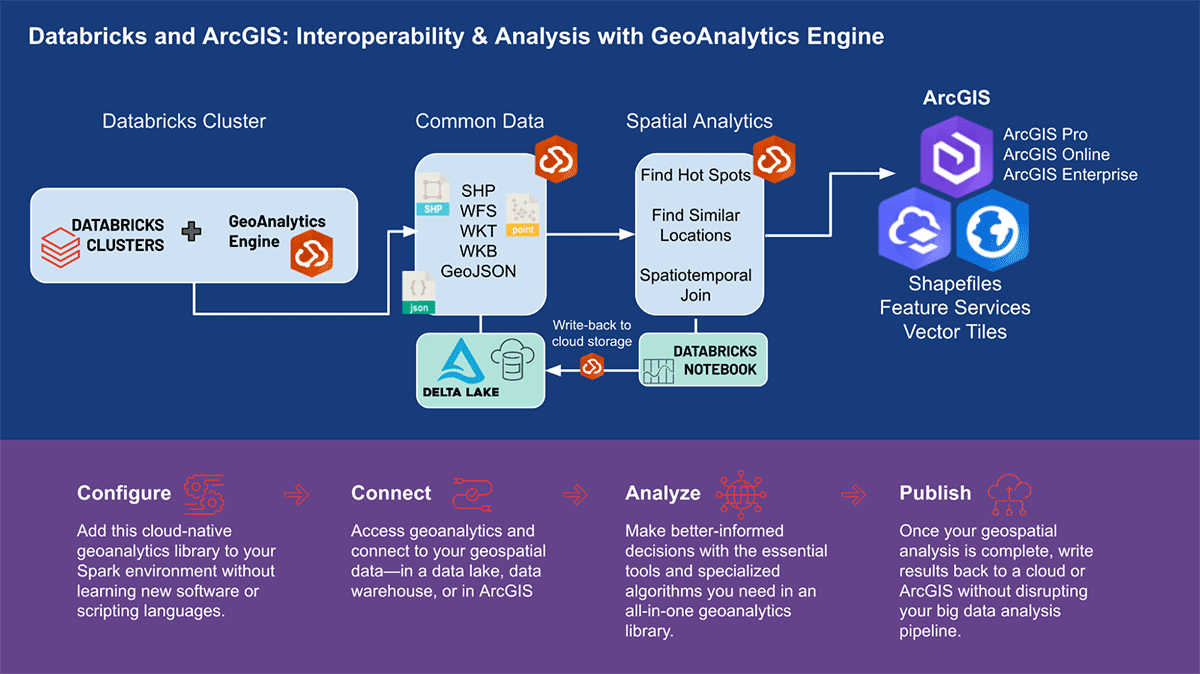
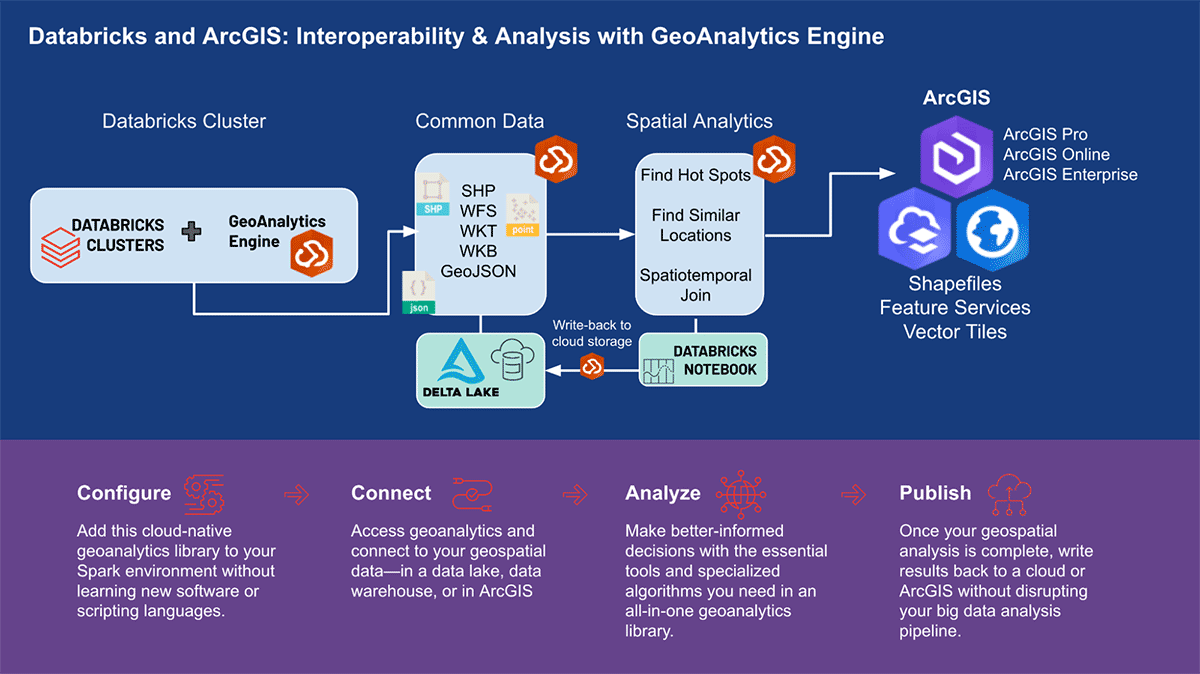
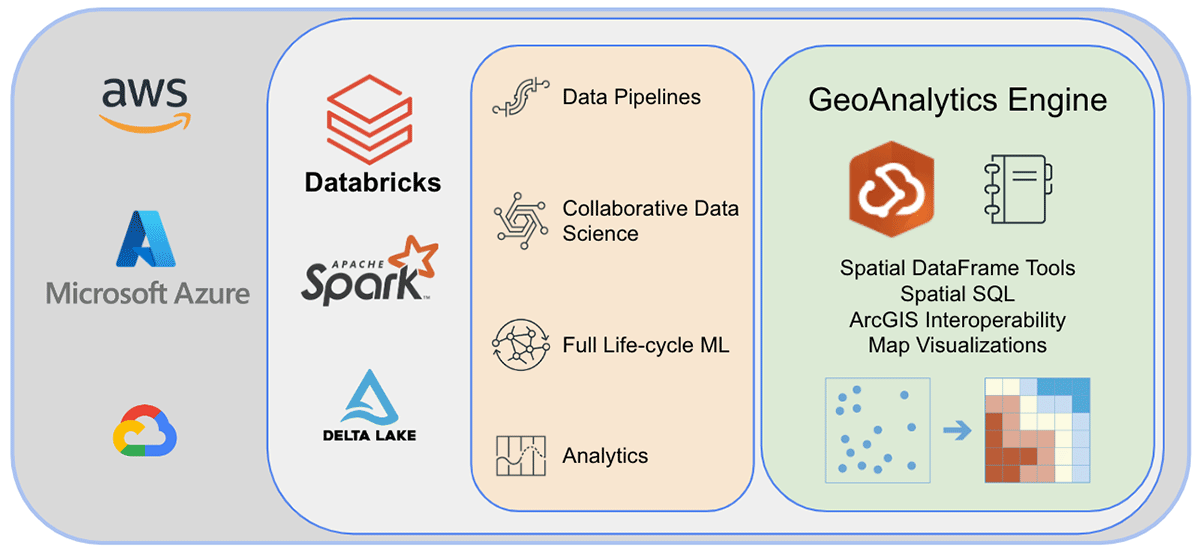
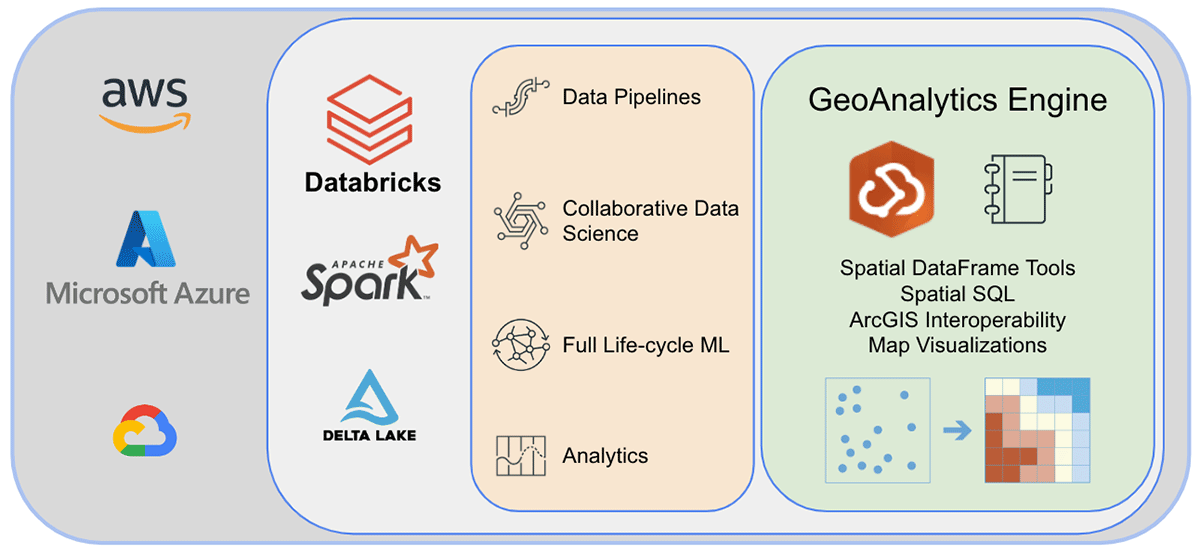
DatabricksにおけるArcGIS GeoAnalytics Engine
データサイエンスワークフローにおけるスケーラブルな地理空間分析
によって Kent Marten 、 Arif Masrur による投稿
これはEsriとDatabricksによる共同投稿です。EsriのシニアソリューションエンジニアであるArif Masrur博士のご貢献に感謝いたします。
ビッグデータの進歩により、あらゆる業界の組織が重要な科学的、社会的、ビジネス上の問題に対処できるようになりました。ビッグデータインフラストラクチャの開発は、データアナリスト、エンジニア、科学者が、ビッグデータの扱う上での核となる課題である、ボリューム、ベロシティ、ベラシティ、バリュー、バラエティに対処するのに役立ちます。しかし、膨大な地理空間データの処理と分析には、それ独自の課題があります。毎日、数百エクサバイトもの位置情報データが生成されています。これらのデータセットには、現実世界のエンティティ間の広範なつながりや複雑な関係が含まれており、空間結合や時空間結合などの最適化された操作を通じて、これらの多面的な関係を効果的に結合できる高度なツールが必要とされます。効率的な大規模分析のために取り込み、検証、標準化する必要がある多数の地理空間フォーマットも、複雑さを増しています。
地理データを取り扱う上でのいくつかの困難は、最近発表されたDatabricksにおける組み込みH3式のサポートによって対処されています。しかし、より複雑なものや、グリッドインデックスよりもジオメトリに焦点を当てたものなど、多くの地理空間ユースケースが存在します。ユーザーは、Databricksプラットフォーム上でさまざまなツールやライブラリを操作しながら、多数のLakehouse機能を活用できます。
世界をリードするGISソフトウェアベンダーであるEsriは、前述の地理分析の課題を解決するために、ArcGIS Enterprise、ArcGIS Pro、ArcGIS Onlineを含む包括的なツールセットを提供しています。Databricksを使用する組織やデータ実務者は、ArcGIS環境外で日常業務を行うためのツールへのアクセスを必要としています。そのため、データサイエンティスト、エンジニア、アナリストが既存のビッグデータ分析環境内で地理空間データを分析できるArcGIS GeoAnalytics Engine(以下、GA Engine)の最初のリリースを発表できること�を大変嬉しく思います。具体的には、このエンジンはApache Sparkのプラグインであり、非常に高速な空間処理と分析でデータフレームを拡張し、Databricksで実行する準備ができています。
ArcGIS GeoAnalytics Engineの利点
EsriのGA Engineにより、データサイエンティストはDatabricks環境内で地理分析機能とツールにアクセスできます。GA Engineの主な機能は以下の通りです。
- 120以上の空間SQL関数—PythonまたはSQL構文を使用して、ジオメトリの作成、空間関係のテストなどを行います
- 強力な分析ツール—わずか数行のコードで一般的な時空間および統計分析ワークフローを実行します
- 自動空間インデックス作成—最適化された空間結合やその他の操作を即座に実行します
- 一般的なGISデータソースとの相互運用性—シェープファイル、フィーチャサービス、ベクタータイルからデータをロードおよび保存します
- クラウドネイティブおよびSparkネイティブ—Databricksでのインストールがテスト済みで準備ができています
- 使いやすさ—PySparkを拡張する直感的なPython APIを使用して、空間対応のビッグデータパイプラインを構築し��ます
SQL関数と分析ツール
現在、GA Engineは、高度な空間および時空間分析をサポートする120以上のSQL関数と15以上の空間分析ツールを提供しています。本質的に、GA Engine関数は、DataFrame列での空間クエリを可能にすることで、Spark SQL APIを拡張します。これらの関数は、Python関数またはPySpark SQLクエリステートメントで呼び出すことができ、ジオメトリの作成、ジオメトリの操作、空間関係の評価、ジオメトリの要約などを可能にします。1つまたは2つの列を使用して行ごとに操作するSQL関数とは対照的に、GA EngineツールはDataFrame内のすべての列を認識し、必要に応じてすべての行を使用して結果を計算します。これらの幅広い分析ツールにより、データセット全体を管理、強化、要約、または分析できます。
|
|
GA Engineは強力な分析ツールです。しかし、GA Engineが一般的なGISフォーマットでの作業をいかに容易にするかという点も見過ごせません。GA Engineのドキュメントには、シェープファイルやフィーチャサービスとの間でデータを読み書きするための複数のチュートリアルが含まれています。GISフォーマットを使用して地理空間データを処理する機能は、DatabricksとEsri製品間の優れた相互運用性を提供します。
{kind=link}
さまざまなユースケースに対応するGA Engine
ESRIのGA Engineが大量の空間データをどのように処理するかを示すために、さまざまな業界のいくつかのユースケースシナリオを見ていきましょう。スケーラブルな空間および時空間分析のサポートは、あらゆる企業が重要な意思決定を行うのに役立つことを意図しています。モビリティ、消費者取引、公共サービスの3つの多様なデータ分析ドメインにおいて、地理的洞察の解明に焦点を当てます。
モビリティデータ分析
モビリティデータは常に増加しており、人間の移動と車両の移動の2つのカテゴリに分けられます。携帯電話サービスエリアのスマートフォンユーザーから収集された人間のモビリティデータは、人間の活動パターンをより深く掘り下げて示します。数百万台のコネクテッドカーの移動データは、方向別交通量、交通流、平均速度、渋滞などに関する豊富なリアルタイム情報を提供します。これらのデータセットは通常、大規模(数十億レコード)で複雑(数百の属性)です。これらのデータには、基本的な空間分析を超えた空間および時空間分析が必要であり、高度な統計ツールと専門的な地理分析機能への即時アクセスが求められます。
EsriのパートナーであるOoklaのCell Analyticsデータに基づいた人間の移動分析の例から始めましょう。Ooklaは、Speedtestアプリケーションに基づいて、グローバルなワイヤレスサービスパフォーマンス、カバレッジ、および信号測定に関�するビッグデータを収集しています。このデータには、ソースデバイス、モバイルネットワーク接続、位置、タイムスタンプに関する情報が含まれています。このケースでは、約160億レコードを含むデータサブセットを扱いました。Apache Sparkでの並列操作に最適化されていないツールでは、この大量のデータを読み込み、時空間操作を可能にするのに数時間の処理時間がかかる可能性があります。GeoAnalytics Engineを使用すると、1行のコードで、このデータをParquetファイルから数秒で取り込むことができます。
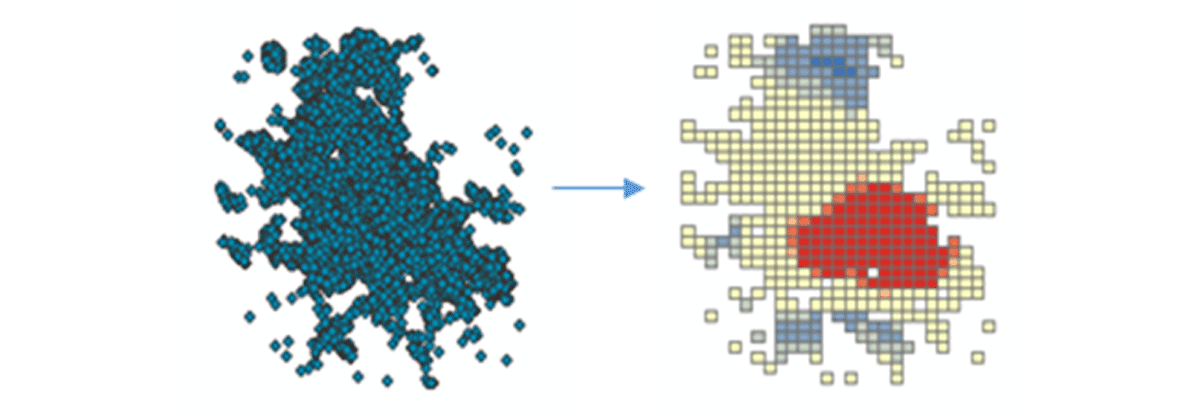
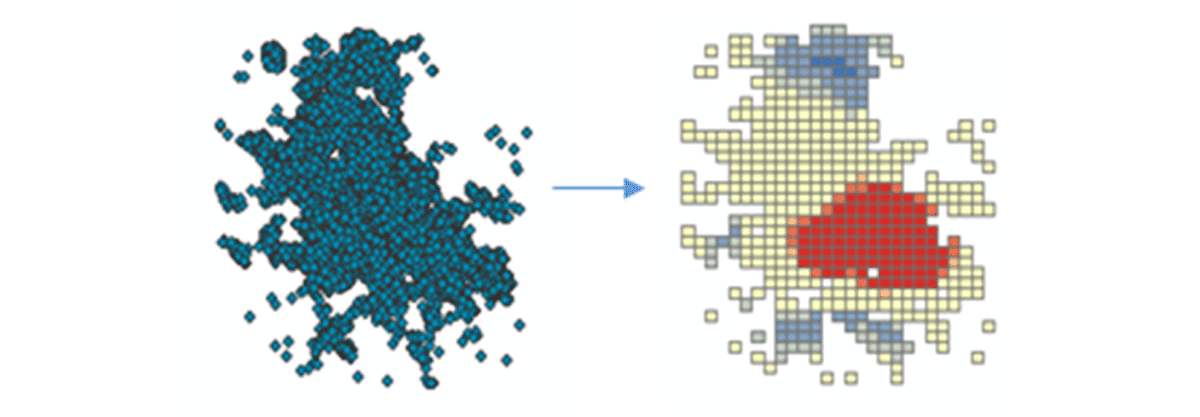
実用的な洞察を導き出すために、簡単な質問からデータに深く入り込みましょう。米国本土におけるモバイルデバイスの空間パターンはどのようなものか? これにより、人間の存在と活動を特徴付け始めることができます。FindHotSpotsツールは、統計的に有意な高値の空間クラスター(ホットスポット)と低値の空間クラスター(コールドスポット)を特定するために使用できます。
{kind=link}
ホットスポットのDataFrameは、Matplotlibを使用して視覚化され、スタイルが設定されました(図2)。これは、米国本土における接続デバイスの低密度な場所(青)と比較して、デバイス接続の多くの記録(赤)を示しました。驚くことではありませんが、主要な都市部では接続デバイスの密度が高いことが示されました。
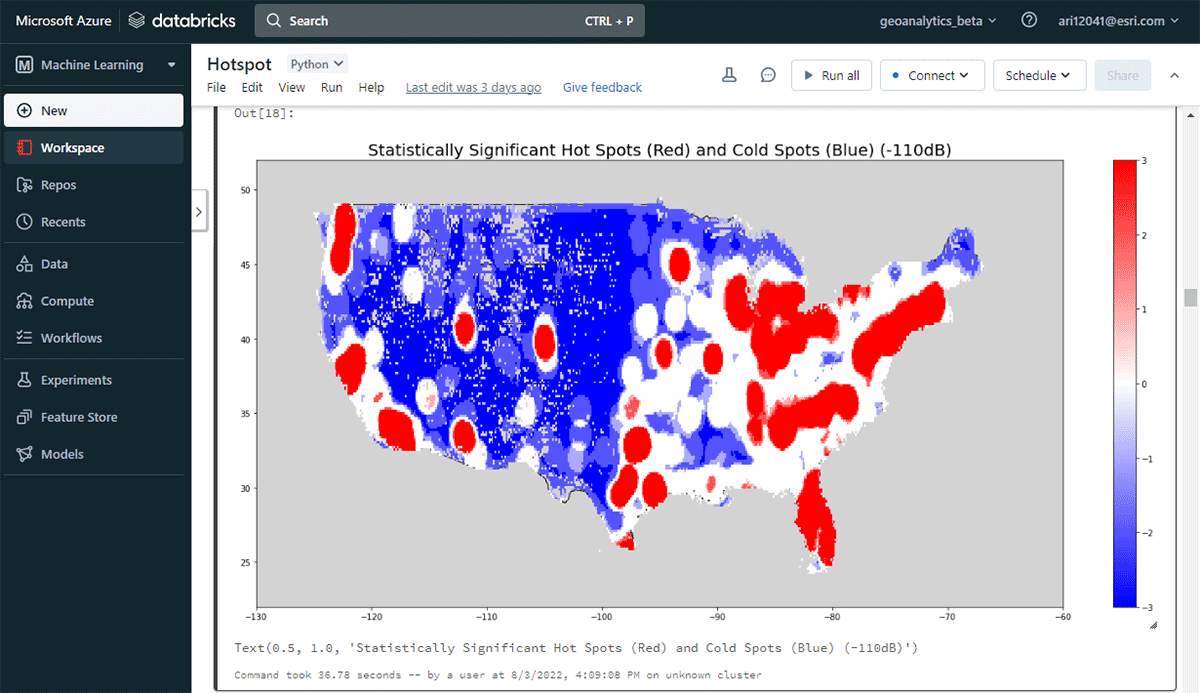
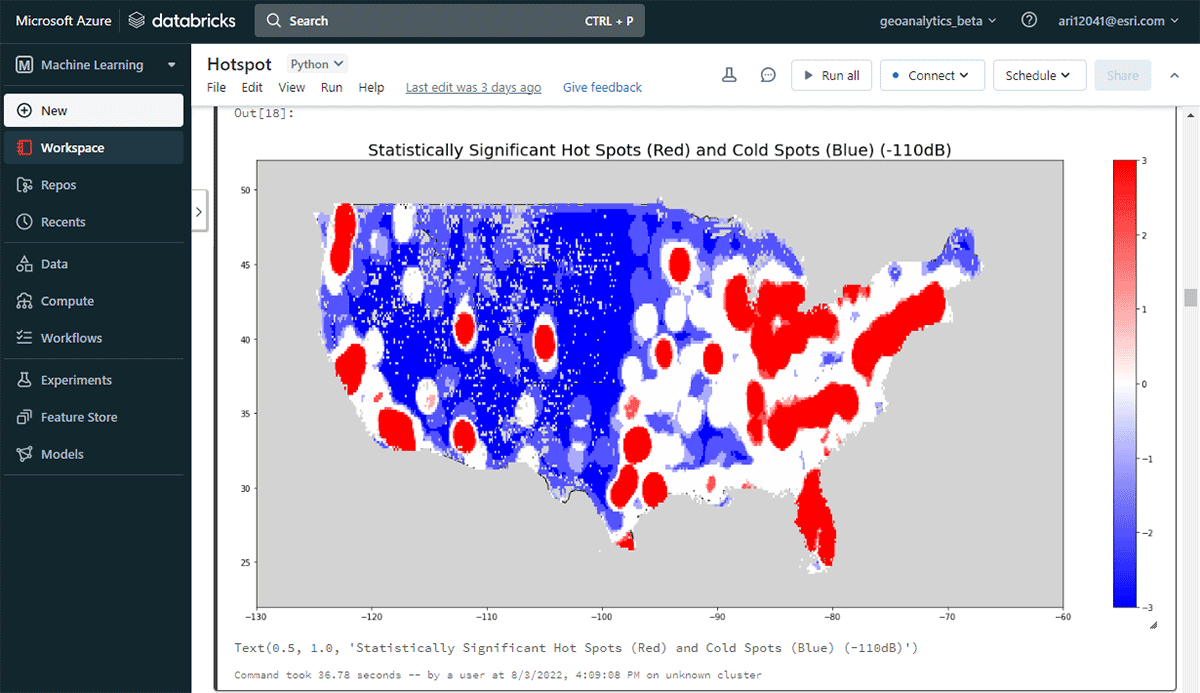{kind=link}
次に、モバイルネットワークの信号強度は米国全体で均一なパターンに従っているのか、という疑問を抱きました。 その問いに答えるため、AggregatePointsツールを使用して、デバイスの観測結果を六角形のビンに集約し、特に強いセルラーサービスと特に弱いセルラーサービスのエリアを特定しました(図3)。モバイルネットワークの信号強度を測定するために使用される値であるrsrp(参照信号受信電力)を使用して、15kmビンごとの平均統計量を計算しました。この分析により、セルラーサービスの信号強度は一貫しておらず、主要な道路網や都市部でより強い傾向があることが明らかになりました。
st_plottingを使用して結果をプロットするだけでなく、arcgisモジュールを使用し、結果のDataFrameをArcGIS Onlineのフィーチャレイヤーとして公開し、マップベースのインタラクティブな視覚化を作成しました。
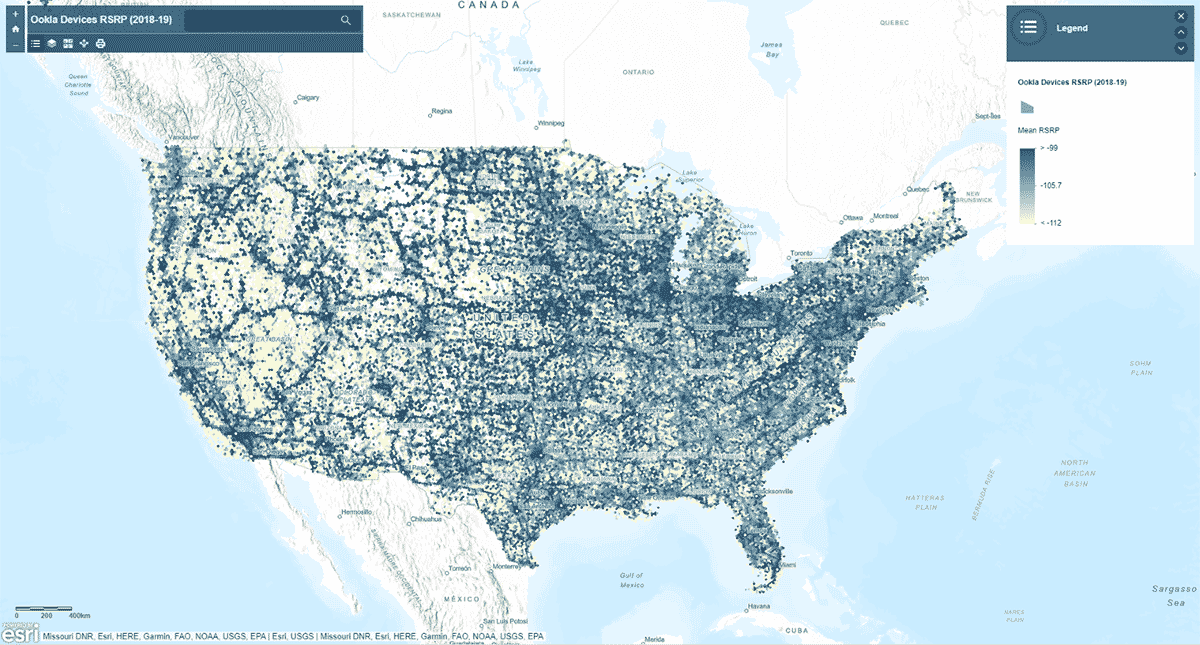
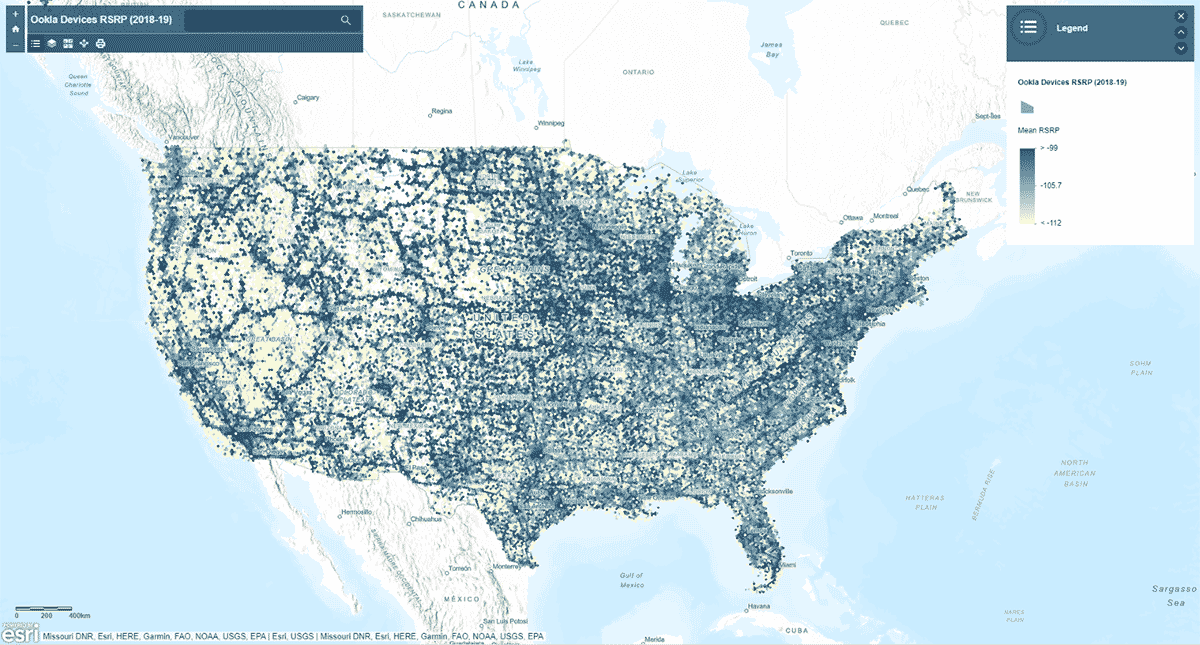{kind=link}
モバイルデバイスの広範な空間パターンを理解したところで、人間の活動パターンについてより深い洞察を得るにはどうすればよいでしょうか?人々はどこで時間を過ごしているのでしょうか? その問いに答えるため、FindDwellLocationsを使用して、2019年5月31日(金曜日)にコロラド州デンバーで同じ一般的な場所に少なくとも5分間滞在したデバイスを探しました。この分析は、より長時間の活動が行われる場所、つまり消費者の目的地を理解し、これらを一般的な移動活動から区別するのに役立ちます。
result_dwellデータフレームは、異なる場所に滞在したデバイスまたは個人に関する情報を提供します。図4の滞在時間ヒートマップは、デンバー周辺で人々がどこで時間を過ごしているかについての概要を示しています。
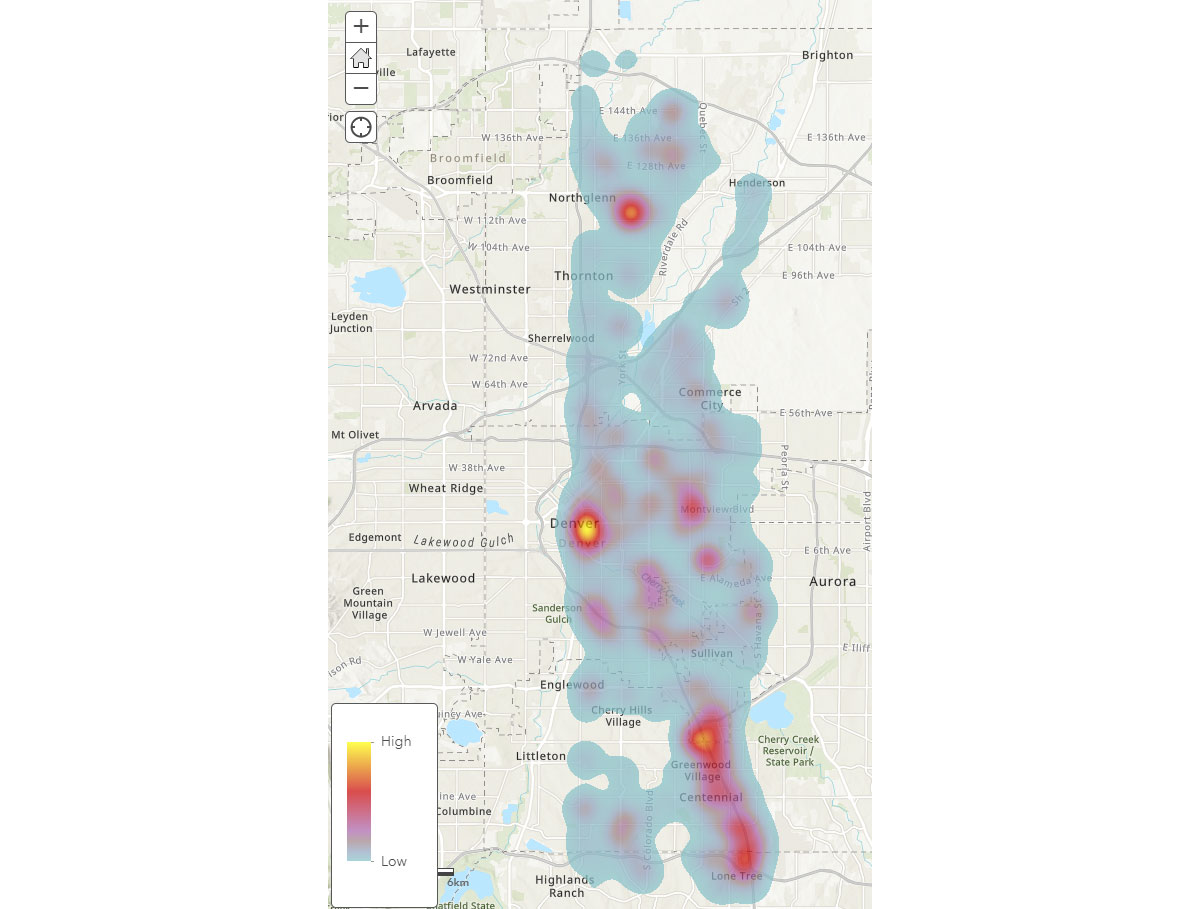
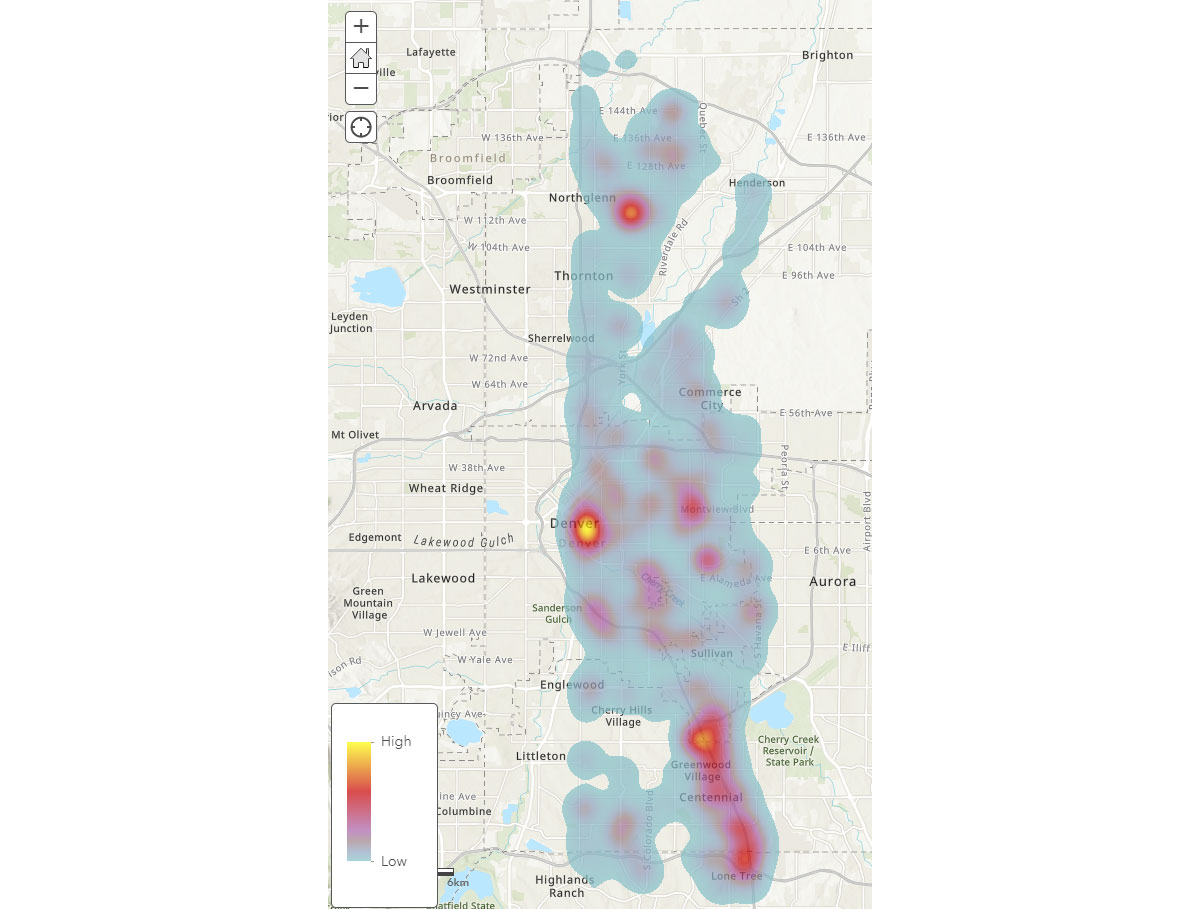{kind=link}
また、人々がより長く滞在する場所を調査したいと考えました。そのため、Overlayを使用して、2019年5月31日にSafeGraph Geometryデータからの関心地点(POI)フットプリントが滞在場所(result_dwell DataFrameから)と交差する場所を特定しました。groupBy関数を使用して、上位のPOIカテゴリごとに接続デバイスの滞在時間を集計しました。図5は、デンバーのいくつかの都市POIが、事務用品店、文房具・ギフト店、および専門工事業者のオフィ��スなど、より長い滞在時間と一致していることを示しています。
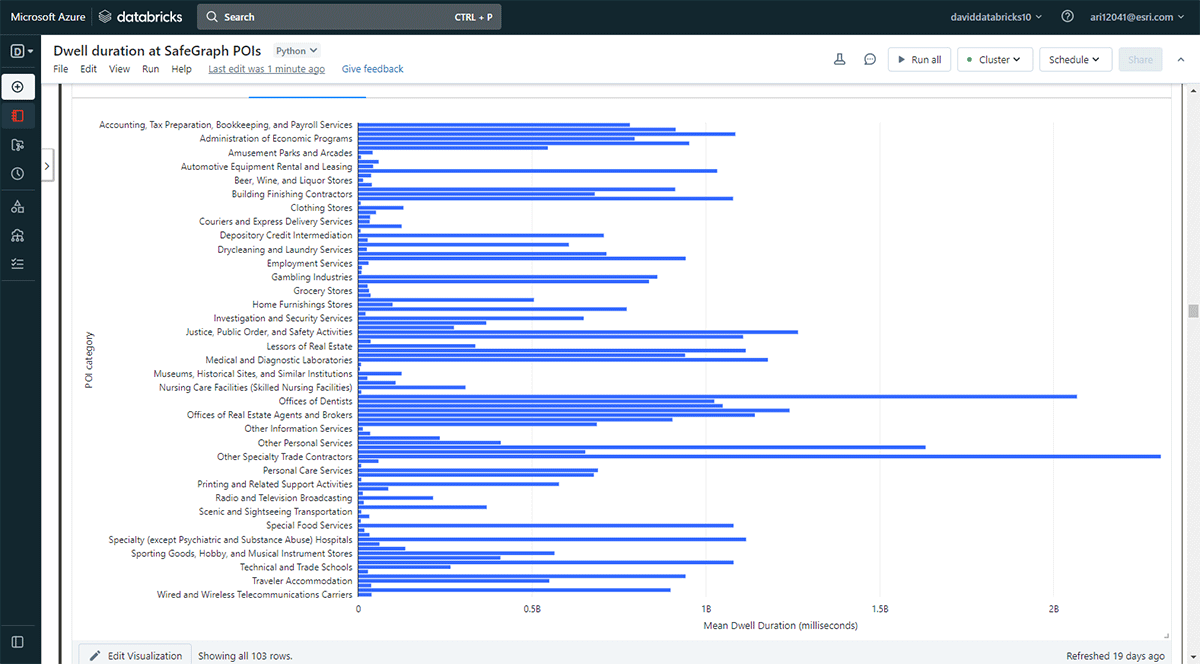
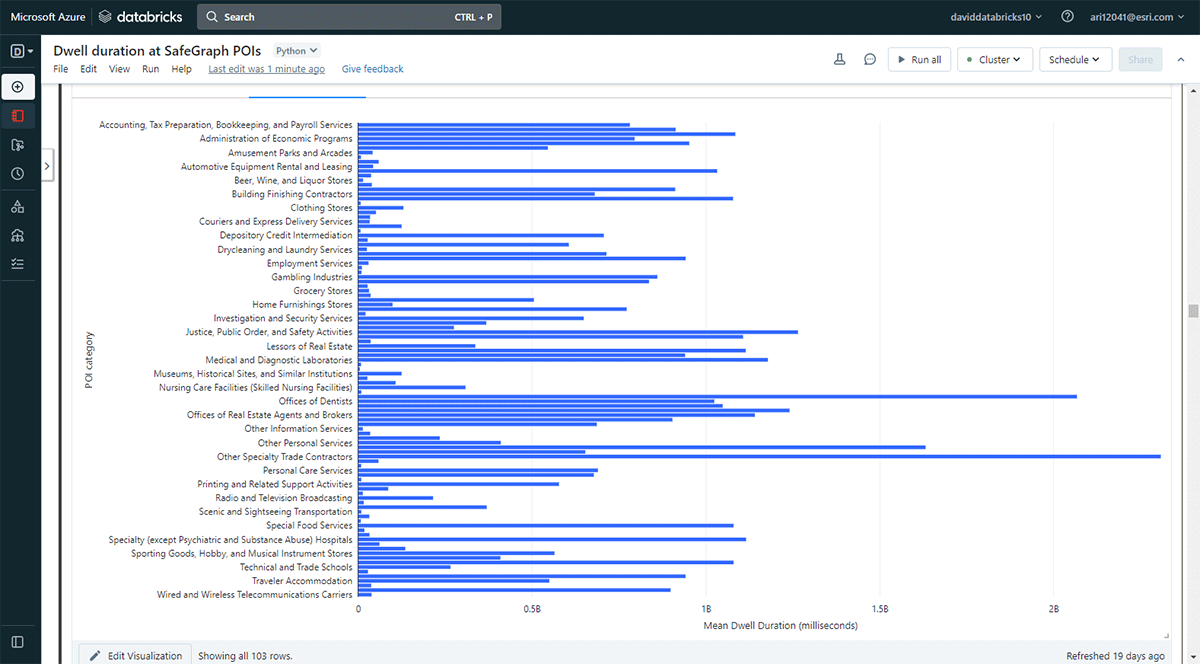{kind=link}
Cell AnalyticsTMデータを用いたこの分析ワークフローのサンプルは、人々の活動をより具体的に特徴づけるために適用または再利用することができます。例えば、小売店の周辺における消費者の行動に関する洞察を得るためにデータを利用できます。これらのデバイスや個人は、WalmartやCostcoで買い物をした後、どのレストランやコーヒーショップを訪れたのでしょうか?さらに、これらのデータセットはパンデミックや自然災害の管理にも役立ちます。例えば、パンデミック中に人々は公衆衛生上の緊急事態ガイドラインに従っているでしょうか?どの都市部が次のCOVID-19または山火事による大気汚染のホットスポットになる可能性があるでしょうか?より広範な地理的規模で、所得格差による人々の移動性や活動の格差は見られるでしょうか?
トランザクションデータ分析
関心地点ごとの集約されたトランザクションデータには、人々が特定の場所でいつ、どのように支出しているかに関する豊富な情報が含まれ��ています。これらのデータの膨大な量と速度は、消費者の支出行動を明確に理解するために高度な空間分析ツールを必要とします。消費者の行動は地理的にどのように異なりますか?どのようなビジネスが収益性を高めるために共存する傾向がありますか?消費者は実店舗(例:Walmart)でどのような商品を買い、オンラインで購入する商品と比較してどうですか?COVID-19のような極端なイベント中に消費者の行動は変化しますか?
これらの質問は、SafeGraph SpendデータとGeoAnalytics Engineを使用して回答できます。例えば、米国におけるCOVID-19期間中に人々の移動パターンがどのように影響を受けたかを特定したいと考えました。そのため、2020年と2021年の全国的なSafeGraph Spendデータを分析しました。以下に、米国郡別に集計された、エンタープライズレンタカーに対する消費者の年間支出(USD)を示します。DataFrameをArcGIS Onlineに公開した後、ArcGIS Web AppBuilderのSwipeウィジェットを使用してインタラクティブなマップを作成し、どの郡が時間の経過とともに変化を示したかを迅速に探索しました(図6)。
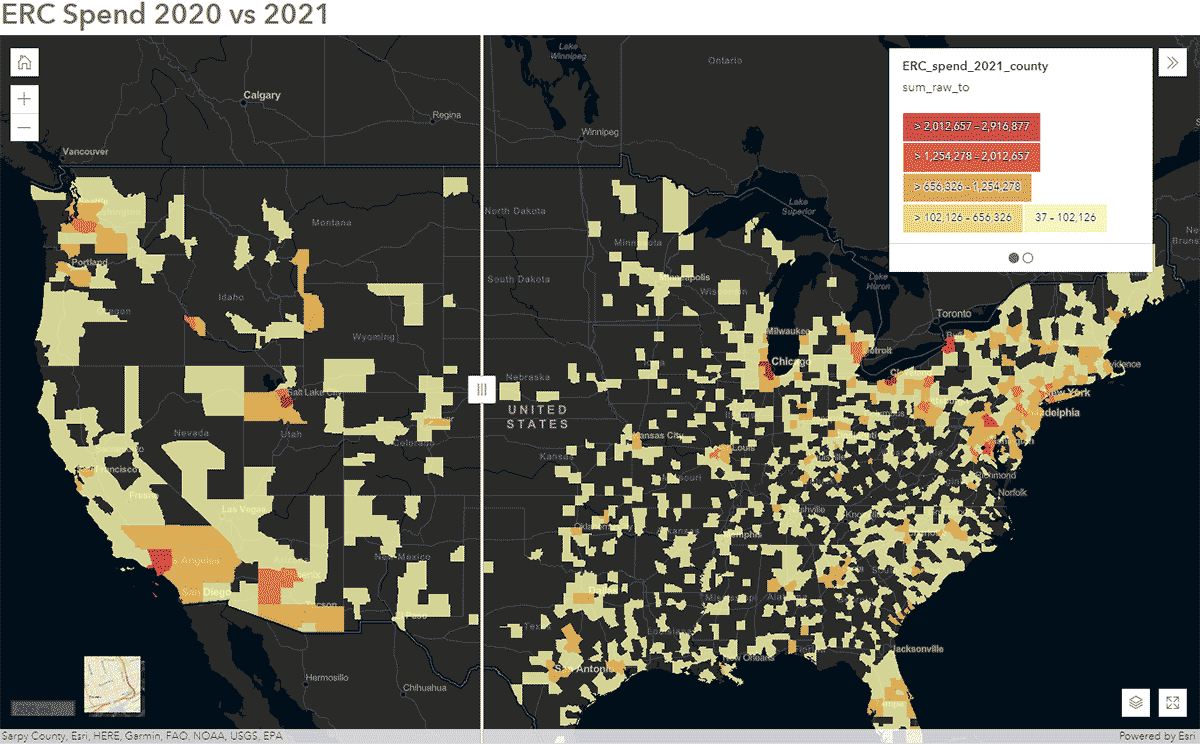
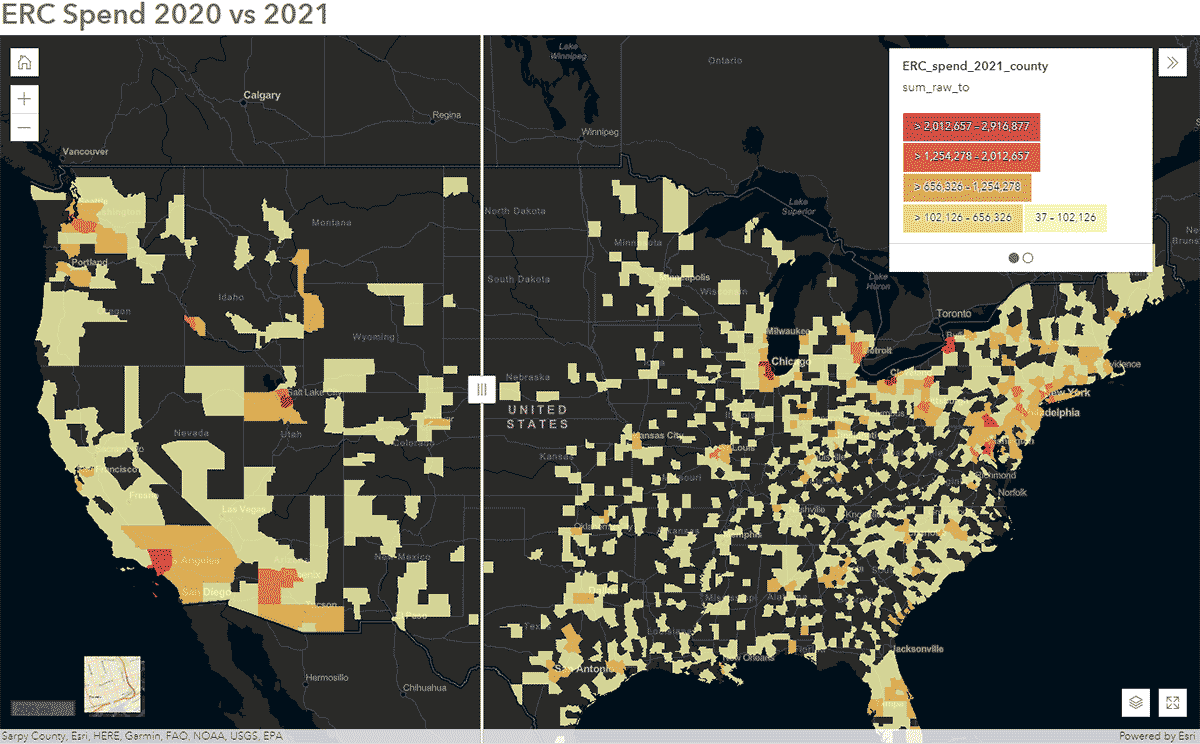{kind=link}
次に、年間で最もオンライン支出が多かった米国の郡と、人口および農産物販売パターンの類似性を考慮した上で、同様のオンラインショッピング支出パターンを持つ他の郡を調査しました。支出DataFrameの属性フィルタリングに基づき、2020年のオンラインショッピング支出でサクラメントがトップであったことを特定しました。類似する地域を調べるために、FindSimilarLocationsツールを使用して、オンラインショッピングと支出の点でサクラメントに最も類似または非類似の郡を特定しました。ただし、これは人口と農業(耕作地の総面積と農産物の平均販売額)の類似性に関連しています(図7)。
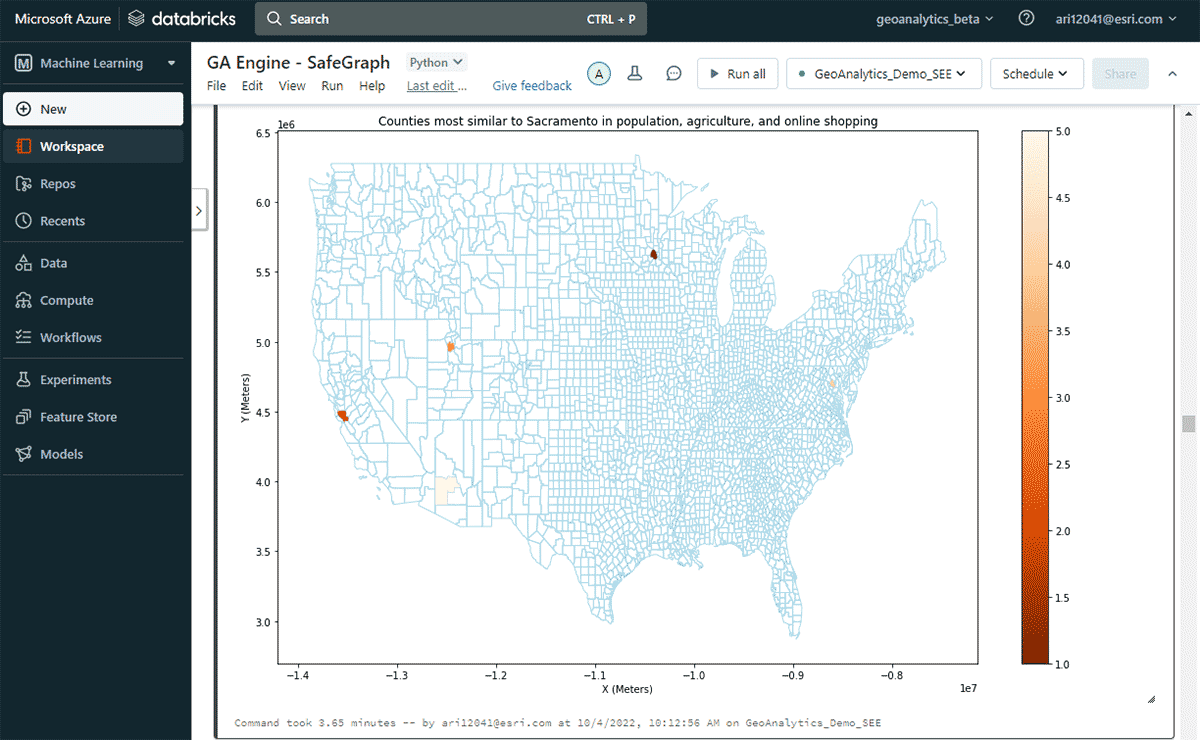
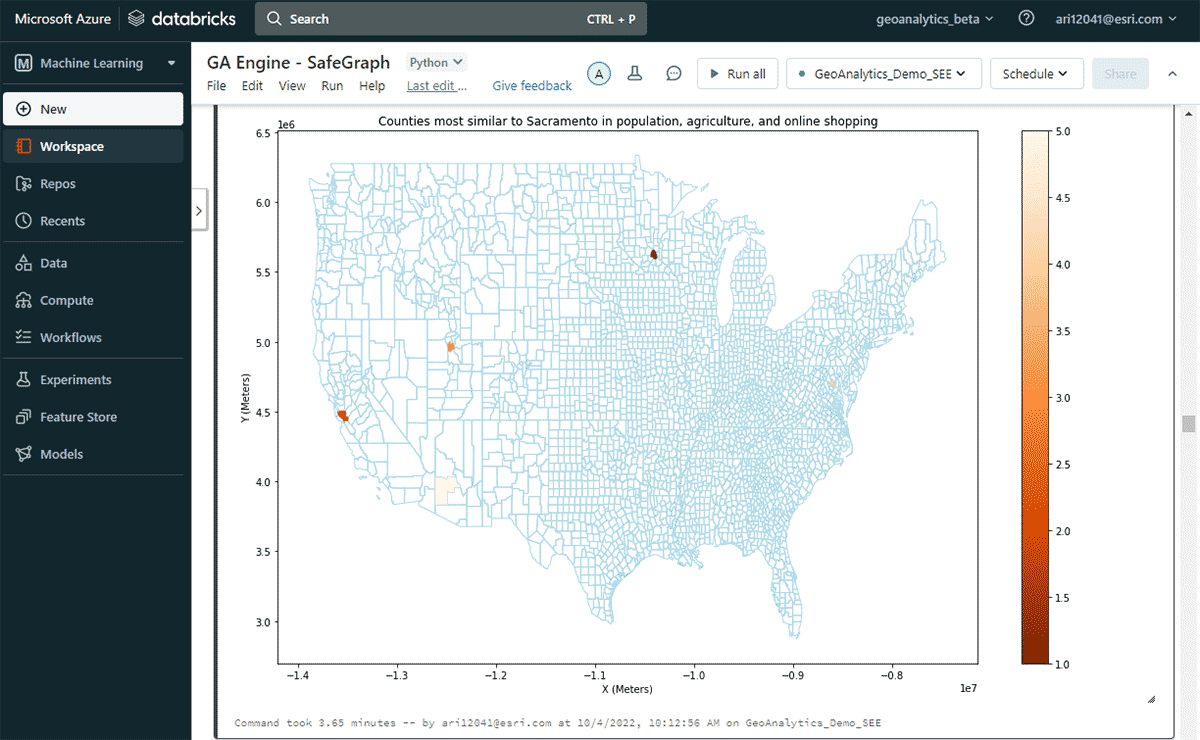{kind=link}
公共サービスデータ分析
311通報記録のような公共サービスデータセットには、住民に提供される緊急性のないサービスに関する貴重な情報が含まれています。このデータにおける時空間パターンのタイムリーな監視と特定は、地方自治体が効率的な311通報解決のためにリソースを計画し、割り当てるのに役立ちます。
この例では、2010年から2022年2月までのニューヨークの311サービスリクエスト約2,700万件のレコードを迅速に読み込み、処理/クリーンアップし、フィルタリングした後、ニューヨーク市エリアに関する以下の質問に答えることを目標としました。
- 311応答時間の平均が最も長い地域はどこですか?
- 平均応答時間が長い苦情の種類にパターンはありますか?
最初の質問に答えるために、応答時間が最も長い通話が特定されました。次に、データは平均期間に3つの標準偏差を加えたものよりも長いレコードを含むようにフィルタリングされました。
重要な苦情グループを見つけるという2番目の質問に答えるために、GroupByProximityツールを活用し、互いに500フィート以内、かつ5日以内に発生した同じ種類の苦情を探しました。その後、10件以上のレコードを持つグループをフィルタリングし、各苦情グループの凸包を作成しました。これは、それらの空間パターンを視覚化するのに役立ちます(図8)。ArcGIS GeoAnalytics Engineに含まれる軽量なプロットメソッドであるst.plot()を使用すると、DataFrameに保存されたジオメトリを即座に表示できます。
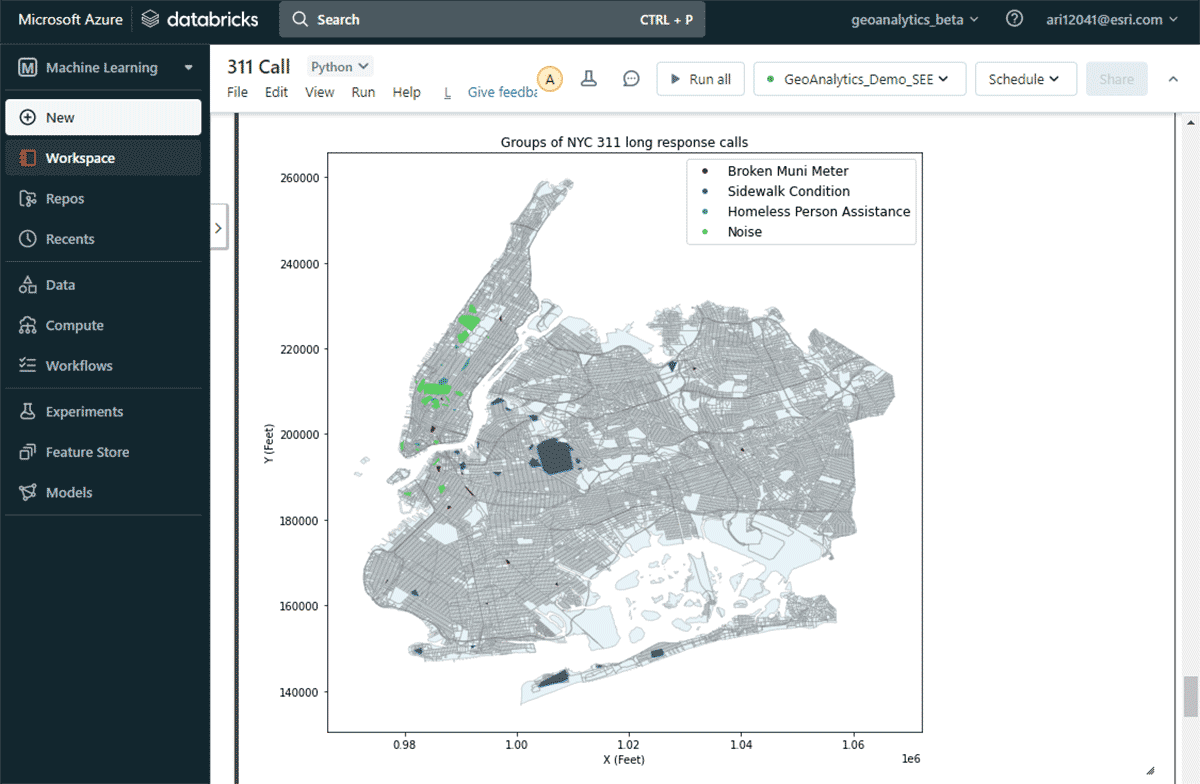
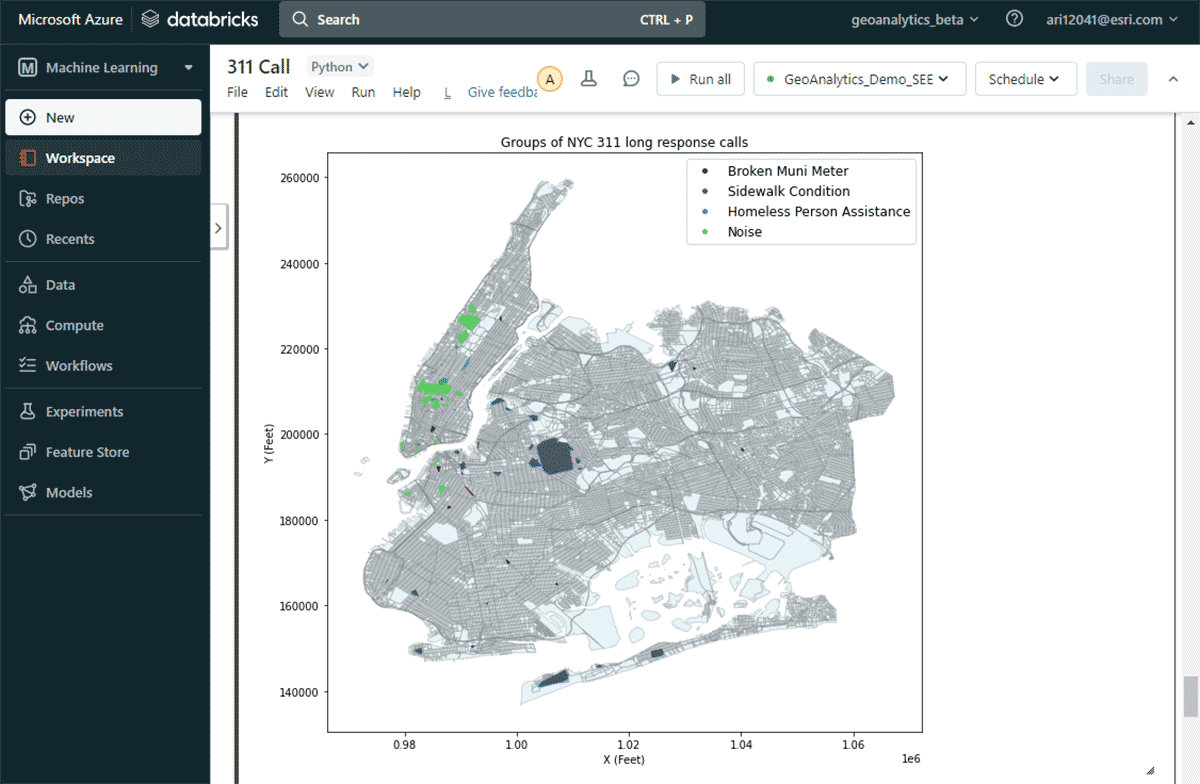{kind=link}
このマップを使うと、ニューヨーク市におけるさまざまな苦情タイプの空間分布を簡単に特定できました。例えば、マンハッタンの中部から下部にかけては騒音に関する苦情がかなり多く、ブルックリンとクイーンズ周辺では歩道の状態が大きな懸念事項となっていました。これらの迅速なデータに基づいた洞察は、意思決定者が具体的な対策を講じるのに役立ちます。
ベンチマーク
多くの顧客にとって、分析ソリューションを選択する際の決定要因はパフォーマンスです。Esriのベンチマークテストでは、GA Engineがオープンソースパッケージと比較して、ビッグデータ空間分析を実行する際により優れたパフォーマンスを提供することが示されています。データサイズが大きくなるにつれてパフォーマンスの向上も大きくなるため、より大規模なデータセットではさらに優れたパフォーマンスが期待できます。例えば、以下の表は、数百万レコードに及ぶさまざまなサイズの2つの入力データセット(点とポリゴン)��を結合する空間交差タスクの計算時間を示しています。各結合シナリオは、単一マシンおよび複数マシンのDatabricksクラスターでテストされました。
| 空間交差入力 | 計算時間(秒) | ||
|---|---|---|---|
| 左データセット | 右データセット | シングルマシン | マルチマシン |
| 50 ポリゴン | 6K ポイント | 6 | 5 |
| 3K ポリゴン | 6K ポイント | 10 | 5 |
| 3K ポリゴン | 2M ポイント | 19 | 9 |
| 3K ポリゴン | 17M ポイント | 46 | 16 |
| 220K ポリゴン | 17M ��ポイント | 80 | 29 |
| 11M ポリゴン | 17M ポイント | 515 (8.6分) | 129 (2.1分) |
| 11M ポリゴン | 19M ポイント | 1,373 (22分) | 310 (5分) |
アーキテクチャとインストール
最後に、GeoAnalytics Engineのアーキテクチャの内部を覗き、その仕組みを探ってみましょう。クラウドネイティブかつSparkネイティブであるため、GeoAnalyticsライブラリをクラウドベースのSpark環境で簡単に使用できます。Databricks環境にGeoAnalytics Engineをデプロイするには、最小限の設定で済みます。モジュールはJARファイルを介してロードされ、クラスターによって提供されるリソースを使用して実行されます。
インストールには、AWS、Azure、GCP全体に適用される2つの基本的なステップがあります。
- ワークスペースの準備
- Databricksワークスペースを作成または起動する
- GeoAnalytics JARファイルをDBFSにアップロードする
- 初期化スクリプトを追加して有効にする
- クラスターを作成��する
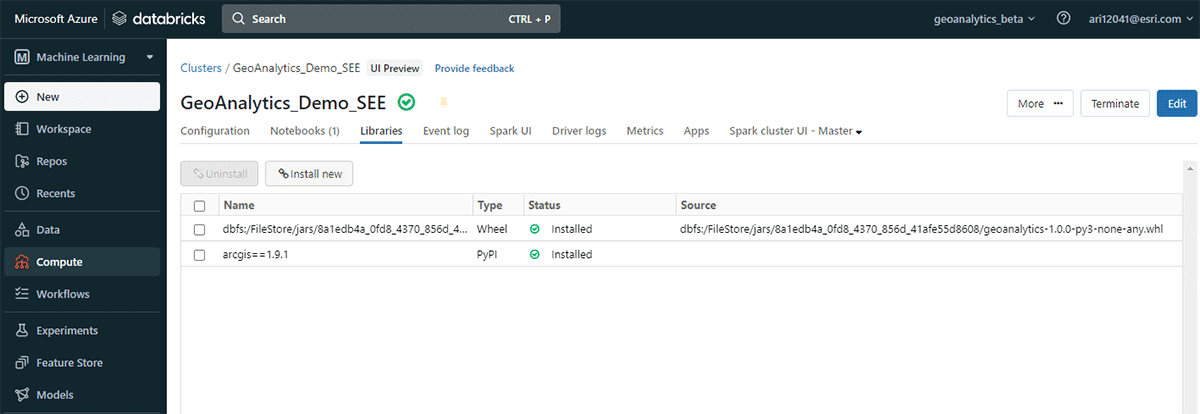
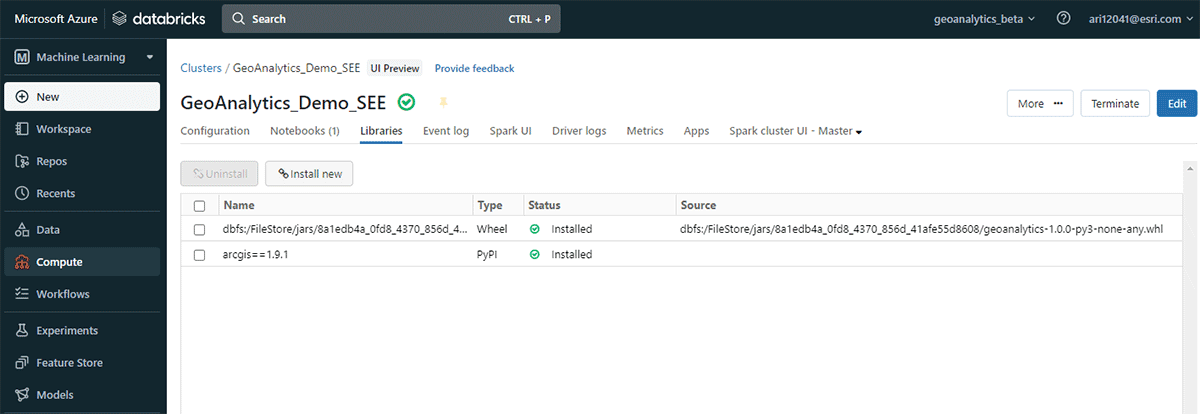{kind=link}
インストール後、ユーザーはSpark環境にアタッチされたPythonノートブックを使用して分析を行います。Databricks Lakehouse Platformのデータに即座にアクセスし、分析を実行できます。分析後、結果をデータレイク、SQL Warehouse、BI(ビジネスインテリジェンス)サービス、またはArcGISに書き戻すことで永続化できます。
{kind=link}
今後の展望
このブログでは、Databricks上のArcGIS GeoAnalytics Engineの強力な機能を紹介し、最も困難な地理空間ユースケースにどのように一緒に取り組めるかを示しました。上記の例の詳細については、このDatabricks ノートブックを参照してください。今後、GeoAnalytics Engineは、GeoJSONエクスポート、H3ビニングサポート、K近傍法などのクラスタリングアルゴリズムを含む追加機能で強化される予定です。
GeoAnalytics Engineは、Azure、AWS、GCP上のDatabricksで動作します。ご希望のDatabricks環境でGeoAnalyticsライブラリをデプロイする方法の詳細については、DatabricksおよびEsriのアカウントチームにお問い合わせください。GeoAnalytics Engineの詳細と、この強力な製品へのアクセス方法については、Esriのウェブサイトをご覧ください。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。