Unity Catalogによる分散型データガバナンスと孤立した環境の実現
Original : Distributed Data Governance and Isolated Environments with Unity Catalog
翻訳: junichi.maruyama
データ、アナリティクス、AIに業務を依存する組織では、効果的なデータガバナンスが不可欠です。多くの組織で、集中型データガバナンスの価値提案に対する認識が高まってきています。しかし、最高の意図を持っていても、適切な組織プロセスとリソースがなければ、集中型ガバナンスの導入は困難な場合があります。多くの組織では、最高データ責任者(CDO)の役割がまだ確立されておらず、誰が組織全体のデータガバナンス方針を定義し、実行するのかについて疑問が残ります。
その結果、組織全体のデータガバナンスポリシーを定義し実行する責任が一元化されていないことが多く、組織内のビジネスライン、サブユニット、その他の部門間でポリシーが異なったり、管理団体が異なったりすることになります。簡単のため、このパターンを分散型ガバナンスと呼ぶことにします。このようなガバナンスユニット間の区別に関する一般的な合意はありますが、必ずしも中央データガバナンス機能があるわけではありません。
このブログでは、レイクハウスのデータ、アナリティクス、AIの統合ガバナンスソリューションを提供するDatabricks Unity Catalogを使用して、分散型ガバナンスモデルの実装を検討します。
Databricksにおけるデータガバナンスの進化形
Unity Catalogの導入以前は、ワークスペースの概念は一枚岩で、各ワークスペースは独自のメタストア、ユーザー管理、テーブルACLストアを有していました。そのため、ワークスペース間のデータおよびガバナンスの分離境界が内在し、ワークスペース間の一貫性に対処するための労力が重複していました。
この問題を解決するために、メタストアとACLを同期させるパイプラインやコードを実行したり、ワークスペース間で使用する自己管理型メタストアを設定したりするお客様もいらっしゃいました。しかし、これらのソリューションでは、オーバーヘッドとメンテナンスコストが増加し、組織全体でデータをどのように分割するかというアーキテクチャを前もって決定しなければならず、データサイロが発生してしまいます。
Unity Catalogによるデータガバナンス
これらの制約を克服するために、Databricksは、データガバナンスを簡単に実装しながら、データのコラボレーションと共有の能力を最大化することを目的とした「Unity Catalog」を開発しました。これを実現するための最初のステップは、組織内のあらゆるデータへのアクセスを許可する共通ネームスペースの実装でした。
このアプローチは、前述の分散ガバナンスパターンに対する挑戦のように見えるかもしれませんが、Unity Catalogは、組織が従来複数のHiveメタストアを使用して対処してきたネームスペース内の新しい分離メカニズムを提供します。これらの分離メカニズムにより、グループは最小限の相互作用で独立して動作することができ、また、本番環境と開発環境など、他のシナリオでも分離を実現することができるようになります。
DatabricksにおけるHive MetastoreとUnity Catalogの比較
Hiveでは、メタストアはサービスの境界であり、異なるメタストアを持つことは、異なるホストされたHiveの基礎サービスや異なる基礎データベースを意味しました。Unity CatalogはDatabricks Lakehouse Platform内のプラットフォームサービスであるため、考慮すべきサービス境界は存在しません。
Unity Catalogは共通の名前空間を提供し、データを1か所で管理・監査できるようにします。
Hiveを使用する場合、開発環境と本番環境の分離を実現したり、運用単位でデータの分離を可能にするために、それぞれ独自の名前空間を持つ複数のメタストアを使用することが一般的でした。
Unity Catalogでは、これらの要件は、データの共有や共同作業の能力を損なわず、一方通行で難しい先行アーキテクチャの決定を必要としない、ネームスペース上の動的な分離メカニズムによって解決されます。
異なるチームや環境での作業
データプラットフォームを利用する場合、開発/生産などの環境間や、組織のビジネスグループ、チーム、事業部間の隔離境界が強く求められることがあります。
まず、Databricksのようなデータプラットフォームにおける隔離境界の定義から始めましょう:
- ユーザーは、合意されたアクセスルールに基づいてのみデータにアクセスできるようにする。
- データは指定された人またはチームによって管理することができる
- データはストレージ内で物理的に分離する
- データは指定された環境でのみアクセスできるようにする
ユーザーは、合意されたアクセスルールに基づき、データへのアクセスのみを行うべきである
組織は通常、データの安全性を保つために、組織や規制の要件に基づいてデータアクセスに関する厳格な要件を定めています。典型的な例としては、従業員の給与情報やクレジットカードの支払い情報などが挙げられます。
このような情報へのアクセスは、通常、厳しく管理され、定期的に監査されます。Unity Catalogは、これらの業界標準を満たすために、カタログ内のデータ資産に対するきめ細かい制御を組織に提供します。コントロールにより、Unity Catalogは、ユーザーが閲覧およびクエリする権利があるデータのみを閲覧およびクエリすることができます。
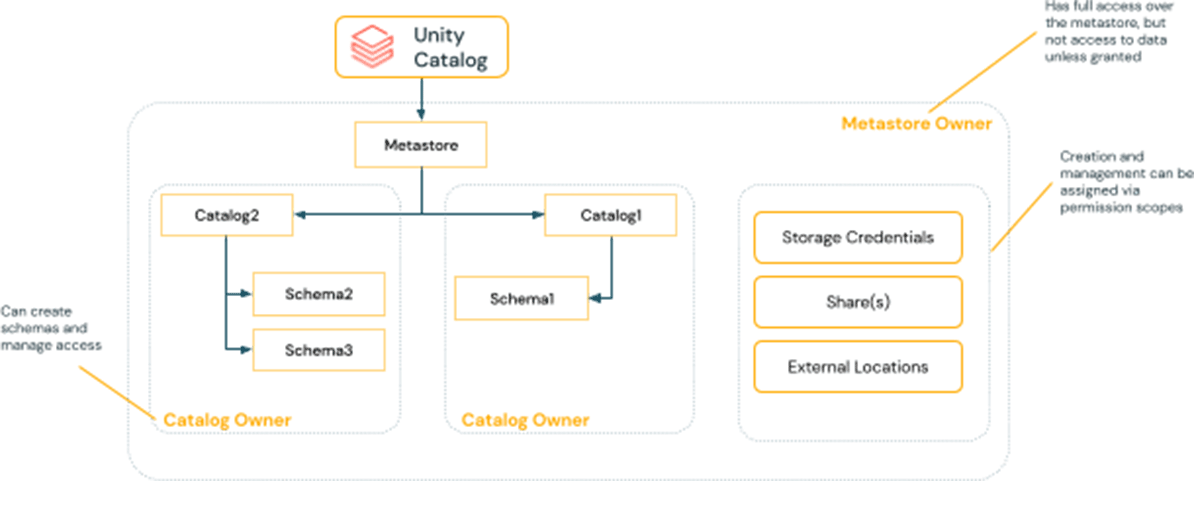
データを指定された人またはチームで管理することができる
Unity Catalogでは、集中型ガバナンスモデルと分散型ガバナンスモデルから選択することができます。
集中型ガバナンスモデルでは、ガバナンス管理者がメタストアのオーナーとなり、任意のオブジェクトの所有権を取得し、ACLやポリシーを設定することができます。
分散ガバナンスモデルでは、カタログまたはカタログのセットをデータドメインと見なすことになります。そのカタログの所有者は、すべてのアセットを作成し所有し、そのドメイン内のガバナンスを管理することができます。したがって、ドメインの所有者は、他のドメインの他の所有者から独立して操作することができます。
管理がツールで行われる場合は、これらのオプションの両方で、グループをオーナーまたはサービスプリ��ンシパルに設定することを強くお勧めします。
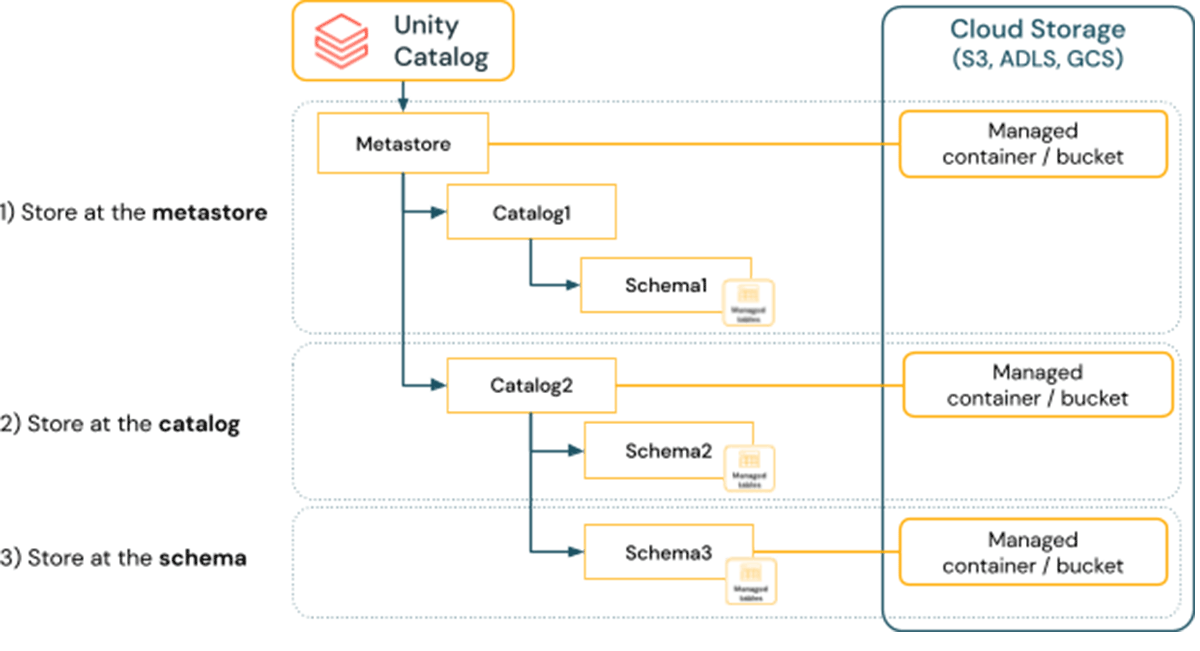
データは物理的に分離して保管する必要がある
デフォルトでは、UC メタストアの作成時に、Databricks アカウント管理者は、管理対象テーブルのデフォルトの場所として、単一のクラウドストレージ場所とクレデンシャルを提供します。
規制上の理由から、あるいはSDLCスコープ間、事業部間、あるいはコスト配分を目的としたデータの物理的な分離を必要とする組織は、カタログおよびスキーマレベルでの管理対象データソース機能を検討する必要があります。
Unity Catalogでは、データがストレージ内でどのように分離されるかのデフォルトを選択することができます。デフォルトでは、すべてのデータはメタストアに保存されます。カタログとスキーマでのマネージドデータソースの機能サポートにより、データの保存とアクセスを物理的に分離することができ、組織のガバナンスとデータ管理要件の達成を支援します。
マネージドテーブルを作成する場合、データはスキーマの場所(ある場合)、カタログの場所(ある場合)の順に使用され、前の2つの場所が設定されていない場合はメタストアの場��所のみが使用されます。
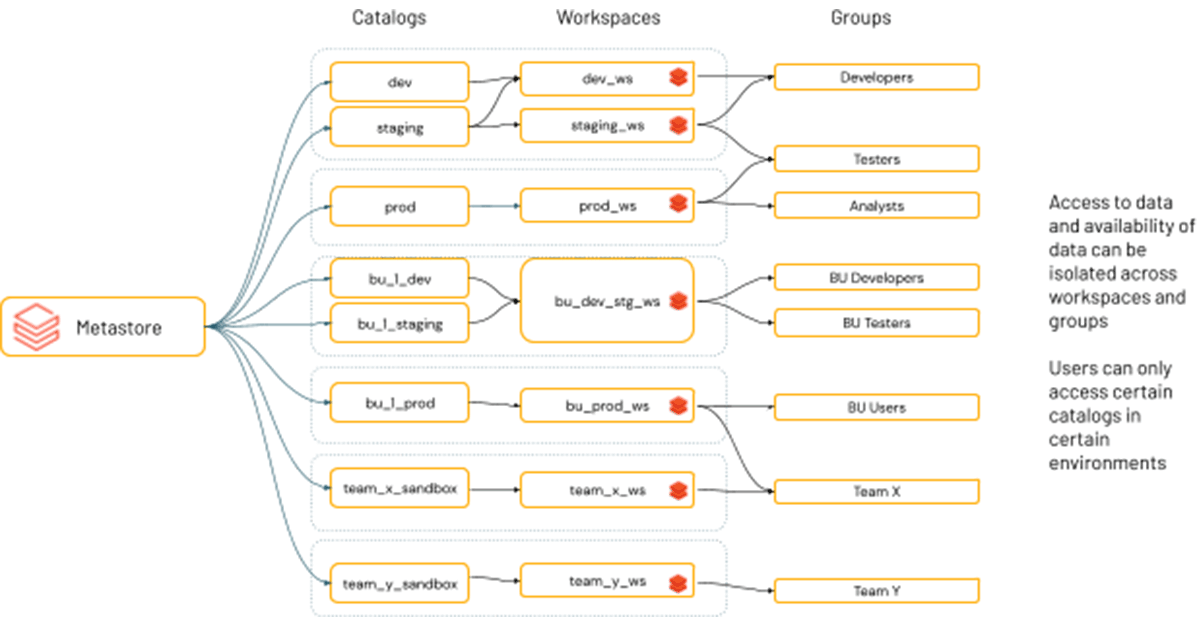
データは、そのデータの目的に基づき、指定された環境でのみアクセスされるべきです。
多くの場合、組織やコンプライアンス要件により、特定のデータに特定の環境でのみアクセスできるようにする必要があることがあります。例えば、開発環境と本番環境、HIPAAやPII環境では、分析用のPIIデータを含むため、データにアクセスできる人やそのデータへのアクセスを許可する環境に関する特別なアクセスルールがあります。また、特定のデータセットやドメインが混在したり結合したりできないような要件が定められていることもあります。
Databricksでは、ワークスペースを環境の1つとみなしています。Unity Catalogには、カタログをワークスペースに「バインド」できる機能があります。この環境を意識したACLにより、ユーザーの個々のACLに関係なく、ワークスペース内で特定のカタログのみを利用できるようにすることができます。つまり、メタストア管理者、またはカタログ所有者は、データカタログがアクセスできるワークスペースを定義することができます。これは、UIやAPI/terraformを使用して簡単に統合することができます。また、最近terraform経由でUnityカタログを制御する方法についてのブログを公開しましたので、特定のガバナンスモデルに適合させるのに役立ち��ます。
まとめ
Unity Catalogをレイクハウスアーキテクチャの中心に据えることで、データを効率的に管理・共有する能力を犠牲にすることなく、柔軟で拡張性のあるガバナンスの実装を実現できます。Unity Catalogを使用すると、既存のHiveメタストアの制限や制約を克服し、特定のビジネスニーズに応じて、より簡単にデータを分離してコラボレーションできるようになります。Unity Catalogのガイド(AWS, Azure)に従って、まずはお試しください。データレイクハウスの効果的なガバナンス戦略を構築するためのベストプラクティスについては、データ、アナリティクス、AIガバナンスに関するこの無料eブックをダウンロードしてください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。