Predictive I/O for Updatesのパブリックプレビューのお知らせ
Up to 10x Performance Gains for MERGE, UPDATE, and DELETE
によって Piyush Revuri, バート・サンウェル, アラ・ルシュチャク, ラース・クロール, ポロ=フランソワ・ポリ, フランク・ムンツ 、 Himanshu Raja による投稿
Original Blog : Announcing the Public Preview of Predictive I/O for Updates
翻訳: junichi.maruyama
前回、Predictive I/Oと呼ばれる新技術により、CDWのお客様がノブなしで選択的読み取りを最大35倍まで改善できることをご紹介しました。本日は、もう一つの革新的な飛躍であるPredictive I/O for Updatesのパブリックプレビューを発表し、MERGE、UPDATE、DELETEのクエリパフォーマンスを最大10倍高速化することができるようになりました。
Databricksのお客様は、毎日1エクサバイト以上のデータを処理しており、50%以上のテーブルでMERGE、UPDATE、DELETEなどのデータ操作言語(DML)オペレーションを利用しています。このブログでは、Predictive I/Oが機械学習を使用してこの大規模なパフォーマンス向上を達成した方法を説明します。しかし、良い部分にスキップして、テーブルをPredictive I/O for Updatesにオプトインしたい場合は、当社のドキュメントを参照してください。
データレイクを更新する際の課題
今日、ユーザーがレイクハウスでMERGE、UPDATE、DELETE操作を実行すると、クエリエンジンによって以下のように処理されます:
- 修正が必要な行を含むファイルを検索する。
- 削除された行をフィルタリングし、更新された行を追加しながら、変更されていないすべての行を新しいファイルにコピーして書き換えます。
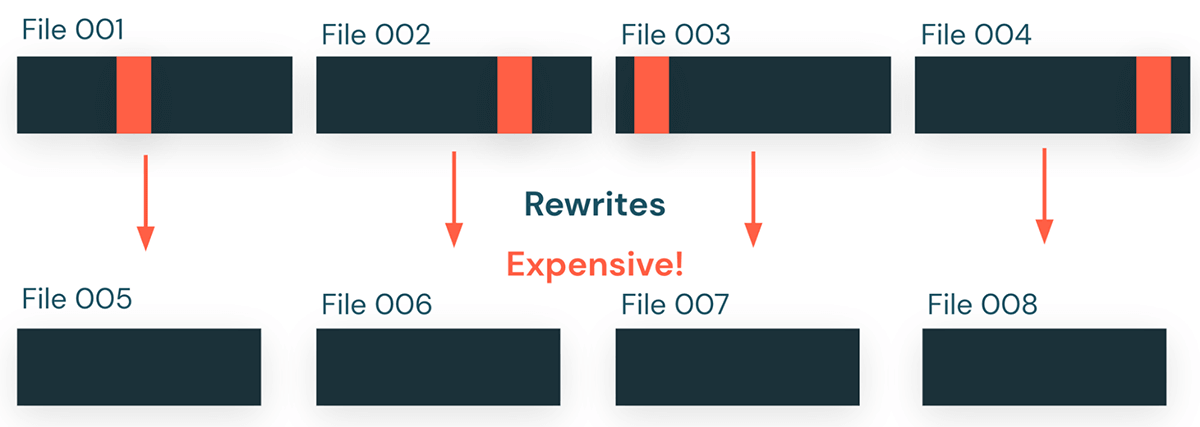
このプロセス、特に書き換えのステップは、テーブル内の多くのファイルに分散して小さな更新を行う場合、特に高くつくことがあります。例えば、1つの商品IDが受注テーブル全体で更新されるような場合です。下の例では、あるテーブルがそれぞれ100万行の4つのファイルとして保存されており、ユーザーがこのテーブルに対してUPDATEクエリを実行し、各ファイルの1行を更新するだけであることを示しています。Predictive I/Oを使用しない場合、更新クエリは4つのファイルすべてを書き換え、テーブルの4つの行を更新するために、400万の未変更の行をすべて新しいファイルにコピーします。このように古いデータを不必要に書き換えることは、中規模から大規模のテーブルでは、高価で遅くなることがあります。
アップデート用Predictive I/Oの導入
これらの課題を解決するために、Predictive I/O for Updatesを導入します。
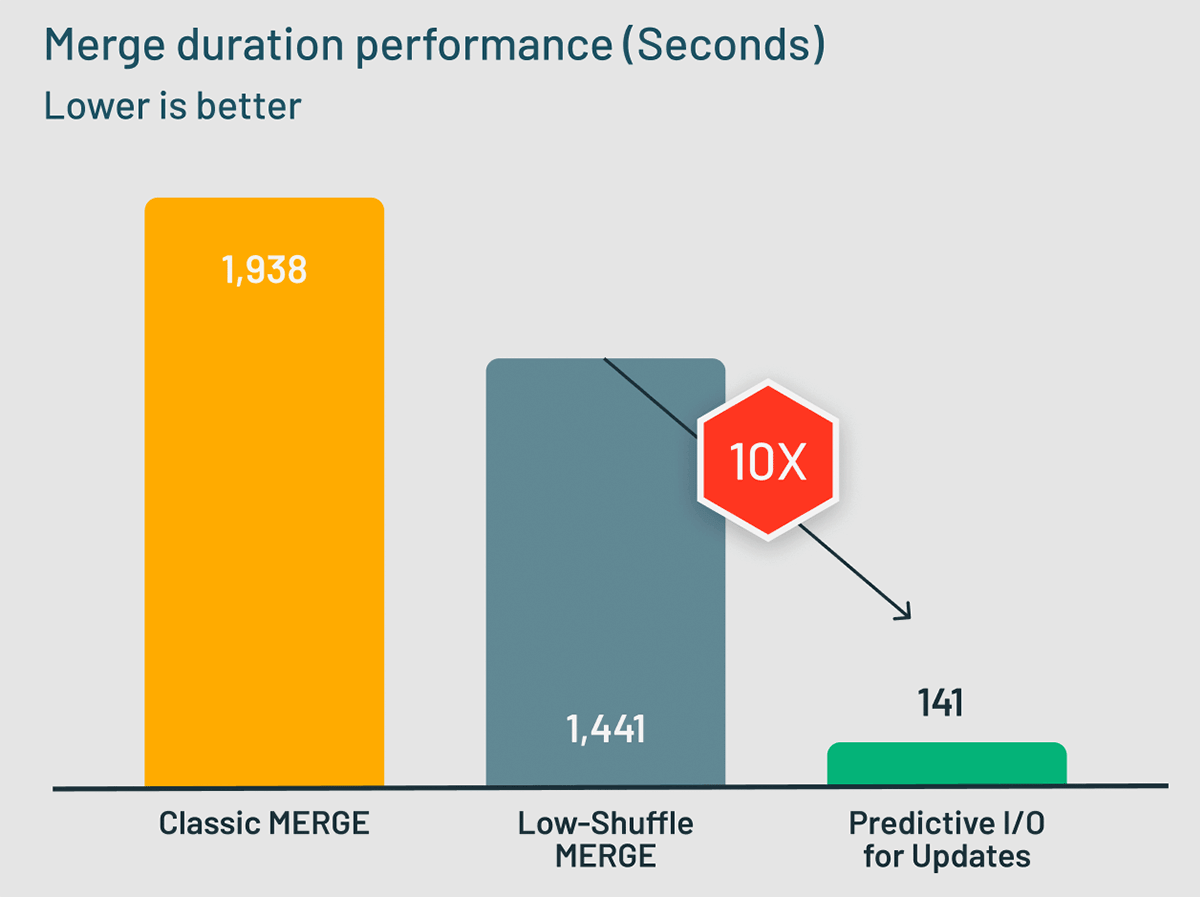
昨年、典型的なMERGEワークロードを1.5倍高速化するPhotonの機能であるLow-Shuffle MERGEを発表しました。Low-Shuffle MERGEは、Databricks Runtime 10.4+とDatabricks SQLのすべてのMERGEでデフォルトで有効になっています。それでは、Predictive I/O for UpdatesがLow-Shuffle MERGEとどのように比較されるかを見てみましょう。3TBのTPC-DSデータセットを更新するMERGE UPSERTワークロードを使用して、ベンチマークで従来のPhoton MERGE実装、Low-Shuffle MERGE、Predictive I/O for Updatesを測定してみました。結果は驚くべきものでした!Predictive I/O for Updatesは、MERGEワークロードを完了するのに141秒強かかり、同じ操作を完了するのに1441秒強かかったLow-Shuffle MERGEより10倍高速でした。
Amazing! Predictive I/O for Updatesはどのような仕組みになっているのでしょうか?
更新予測I/Oは、削除ベクトルを使用して、圧縮ビットマップファイルを使用して削除された行を追跡します。削除されたファイルを追跡することは、書き込み時に削除するのではなく、テーブルを読み取る際に若干のオーバーヘッドを追加することになります。なぜなら、正確なテーブル表現を達成するには、読み取り時に削除された行をフィルタリングする必要があるからです。ここで、Predictive I/Oのインテリジェンスが活躍する。Predictive I/Oは、さまざまな学習とヒューリスティックを使用して、MERGE、UPDATE、DELETEクエリに必要に応じて削除ベクターをインテリジェントに適用し、書き込みパフォーマンスを最適化しながら読み取りオーバーヘッドを最小限に抑えます。このインテリジェンスと削除ベクトルファイルの最適化された性質が組み合わさることで、読み取りクエリのパフォーマンスを損なうことなく、最高の書き込みパフォーマンスを実現します。
Predictive I/O for Updatesを始めるにあたって
ETLパイプラインやCDCインジェストジョブの実行に長い時間がかかっていませんか?また、データの更新が分散していませんか?Predictive I/Oは、MERGE、UPDATE、DELETEクエリを大幅に高速化することができ、Databricks SQL ProおよびServerlessのパブリックプレビューで本日から利用できます!
このパブリックプレビューの一環として、皆様のフィードバックをお待ちしています。MERGE, UPDATE, DELETEクエリを高速化する方法については、 Predictive I/O for Updates のドキュメントをご確認ください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。