DatabricksとAzure DevOpsでスケーラブルなAIをエッジにもたらす
によって アンドレス・ウルティア, ハワード・ウー, Nicole Lu 、 Bala Amavasai による投稿
翻訳:Junichi Maruyama. - Original Blog Link
製造業における機械学習とAIの機会は、計り知れません。消費者の需要と生産のより良い整合性から、工程管理、歩留まり予測、欠陥検出の改善まで、予知保全、出荷最適化、もっともっと、ML/AIはメーカーがビジネスを運営する方法を変革する用意があり、これらのテクノロジーはインダストリー4.0構想における主要な注力分野となっている
しかし、この可能性を実現することに課題がないわけではありません。機械学習と AI に関して、的外れになる方法はたくさんありますが、その 1 つは、モデルを運用プロセスにどのように統合するかを予測していないことです
ショップフロアの予測にはエッジデバイスが不可欠
製造業では、ML/AIを即座に活用する機会の多くは、現場やその周辺にある。機械、計測器、デバイス、センサーから送信された信号はモデルに送られ、モデルによってこの情報が予測に変換され、オペレーションを管理したり、アラートのトリガーになったりする。これらのモデルがこれらの活動を制御できるかどうかは、現場のデバイスとモデル間の信頼性が高く、安全で、低レイテンシーの接続性に依存する。
しかし、大規模ネットワークは、モデルのトレーニングに必要な量のデータを収集するために必要なものだ。モデルのトレーニング中、アルゴリズムは、データ内の関連パターンに焦点を当てるために、これらの実デバイスまたはシミュレートされたデバイスから収集された様々な値を繰り返し導入される。これは計算集約的で時間のかかるプロセスであり、クラウドで管理するのが最適だ。
トレーニングにはこのようなリソースへのアクセスが必要だが、結果として得られるモデルは驚くほど軽量になることが多い。テラバイトのデータから学習された情報は、学習済みモデル内ではメガバイトやキロバイトのメタデータに凝縮されることもある。つまり、クラウドで学習された典型的なモデルは、非常に小さな計算デバイスのサポートで、高速かつ正確な予測を生成することができるのだ。これにより、軽量なデバイスでモデルを現場やその近くに展開する機会が生まれる。このようなエッジ展開により、統合シナリオをサポートするための大規模で高速なネットワークへの依存を減らすことができます(図1)
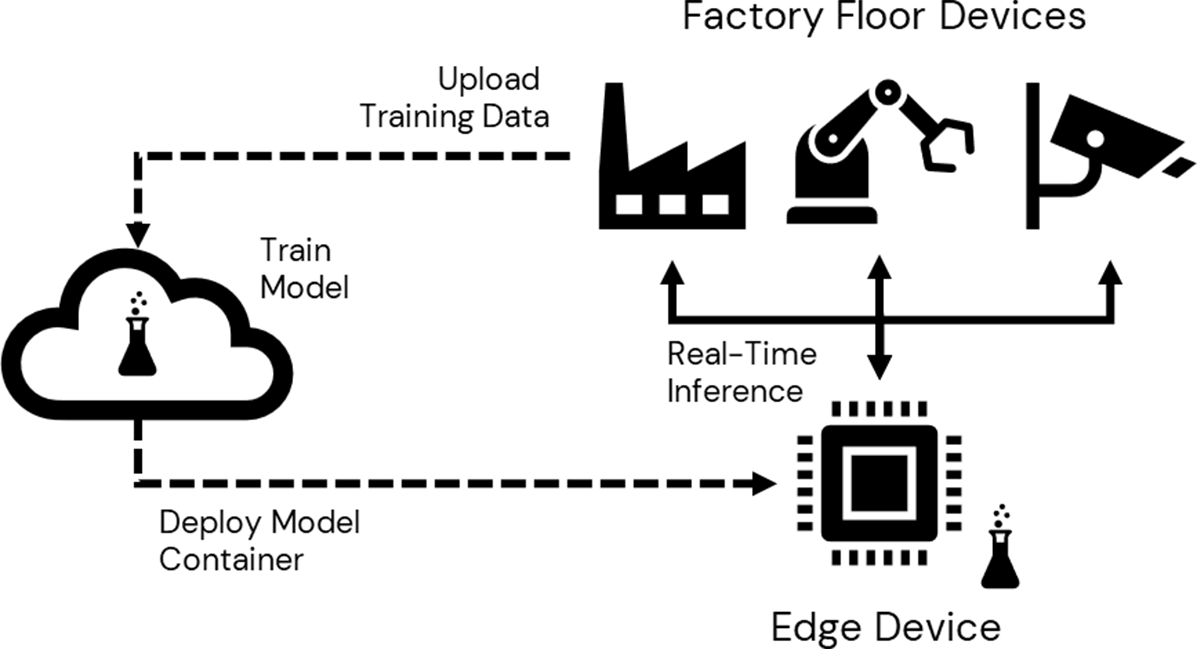
DatabricksとAzure DevOpsがエッジデバイスの導入を可能にする
すべてのパーツを組み合わせるには、クラウドにプッシュされた最初のデータ収集と、モデルをトレーニングするためのプラットフォームが必要です。統合されたクラウドベースのアナリティクス・データ・プラットフォームとして、Databricksは幅広いML/AIモデルを高速かつスケーラブルにトレーニングできる環境を提供する。
次に、訓練されたモデルをコンテナ・イメージにデプロイする必要がある。このコンテナは、モデルとそのすべての依存関係をホストするだけでなく、多種多様な外部アプリケーションからアクセス可能な方法でモデルを提示する必要がある。今日、REST APIは、そのような方法でアプリケーションを表示するためのゴールド・スタンダードである。堅牢な REST API を定義するのは少し大変ですが、Databricks は MLflow モデル管理およびデプロイメント・プラットフォームを統合することで、1 行のコードでこれを実現することができます。
コンテナが定義されたら、今度はそれをエッジデバイスにデプロイする必要がある。一般的なデバイスは、64ビットプロセッサ、数ギガバイトのRAM、WiFiまたはイーサネット接続を提供し、コンテナイメージを実行できるLinuxなどの軽量オペレーティングシステムを実行する。さまざまなデバイスへのコンテナのデプロイメントを管理するために構築されたAzure DevOpsなどのツールを使用して、クラウドからデバイスにモデルコンテナをプッシュし、その上でローカルの予測サービスを起動することができます。
モデル・トレーニング、パッケージング、エッジ・デプロイメントのこのプロセスをお客様が検討できるよう、Databricksからエッジまでの各ステップを詳細に文書化した構築済みリソースを備えたソリューション・アクセラレータを構築しました。これらのアセットがエッジ展開プロセスを解明する一助となり、企業が展開プロセスの仕組みではなく、予測能力によっていかに現場のオペレーションを改善できるかに集中できるようになることを期待しています。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。