データアナリスト向けのDatabricks Assistantのヒントとコツ
によって サマンサ・バンチク による投稿
- Databricks Assistantは、SQLクエリ、コードの説明、エラーの修正にデータアナリストを支援します。
- Databricks Assistantは、SQL方言の変換、クエリのリファクタリング、ウィンドウ関数の記述、JSONを構造化テーブルに変換、SQLクエリの最適化など、データアナリストが一般的に直面する課題に対応できます。
- この投稿では、@メンションテーブル名の使用、Unity Catalogコメントに行レベルの例を追加、Cmd+Iを使用した素早い反復などのベストプラクティスを提供しています。
Databricks Assistantは、Databricks Data Intelligence Platformにネイティブで利用可能なコンテキスト認識型AIアシスタントです。これは、SQLクエリの生成、複雑なコードの説明、エラーの自動修正を支援することで、SQLとデータ分析を簡素化するように設計されています。
このブログでは、Databricks Assistantのデータエンジニア向けのヒントとトリックに続き、SQLとデータアナリストに焦点を当てています。アシスタントがベストプラクティスを強化し、パフォーマンスを向上させ、半構造化データを使用可能な形式に変換する方法を探ります。データサイエンティストなどについての今後の投稿をお楽しみに、Databricks Assistantが複雑なワークフローを簡素化し、高度な分析を誰でも利用できるようにする方法を探ります。
ベストプラクティス
以下に、アナリストがアシスタントをより効果的に使用するためのベストプラクティスをいくつか紹介します。これにより、より正確なレスポンス、スムーズな反復、そして効率の向上が確保されます。
- @メンションテーブル名を使用する: プロンプトで可能な限り具体的にし、@メンションテーブルを使用して、アシスタントが正しいカタログとスキーマを参照するようにします。これは、同じ名前のテーブルを含む複数のスキーマやカタログがあるワークスペースで特に役立ちます。
- UCコメントに行レベルの例を追加する: 現時点では、アシスタントはメタデータにしかアクセスできず、実際の行レベルの値にはアクセスできません。Unity Catalogのコメントに代表的な行レベルの例を含めることで、アナリストはアシスタントに追加のコンテキストを提供し、正規表現パターンの生成やJSON構造の解析などのタスクに対するより正確な提案を得ることができます。
- テーブルの説明を常に最新の状態に保つ: Unity Catalogのテーブル説明を定期的に更新することで、アシスタントがあなた�のデータモデルを理解するのを強化します。
- Cmd+Iを使って素早く反復する: インラインアシスタントは、不必要な書き換えなしにターゲットを絞った調整を行うのに理想的です。セルの最後でCmd + Iを押すと、アシスタントはカーソル以下のコードのみを変更し、特に指定されていない限り他の部分は変更しません。これにより、ユーザーはプロンプトを素早く反復し、レスポンスを洗練し、提案を調整することができます。また、ユーザーは特定の行をハイライトして、アシスタントの焦点を微調整することができます。
- 高度な関数の例を取得する: ドキュメンテーションが基本的な使用例しか提供していない場合、アシスタントはあなたの特定のニーズに基づいたよりカスタマイズされた例を提供することができます。例えば、DLTでバッチストリーミング構造集約を扱っている場合、アシスタントにより詳細な実装を求めることができます。これには、データへの適用、パラメータの調整、エッジケースの処理などが含まれます。
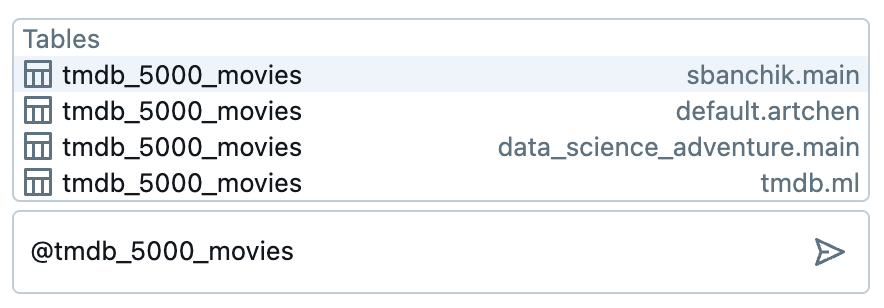
一般的なユースケース
これらのベストプラクティスを念頭に置いて、SQLとデータアナリストが日々直面する具体的な課題を詳しく見てみましょう。クエリの最適化や半構造化データの処理から、ゼロからのSQLコマンドの生成まで、DatabricksアシスタントはSQLのワークフローを簡素化し、データ分析をよりシンプルで効率的にします。
SQL方言の変換
SQL方言はプラットフォームによって異なり、関数、構文、さらにはDDLステートメントやウィンドウ関数のようなコアコンセプトに違いがあります。HiveからDatabricks SQLへの移行や、Postgres、BigQuery、Unity Catalog間でクエリを翻訳するなど、複数の環境で作業するアナリストは、クエリを手動で適応させる時間をしばしば費やします。
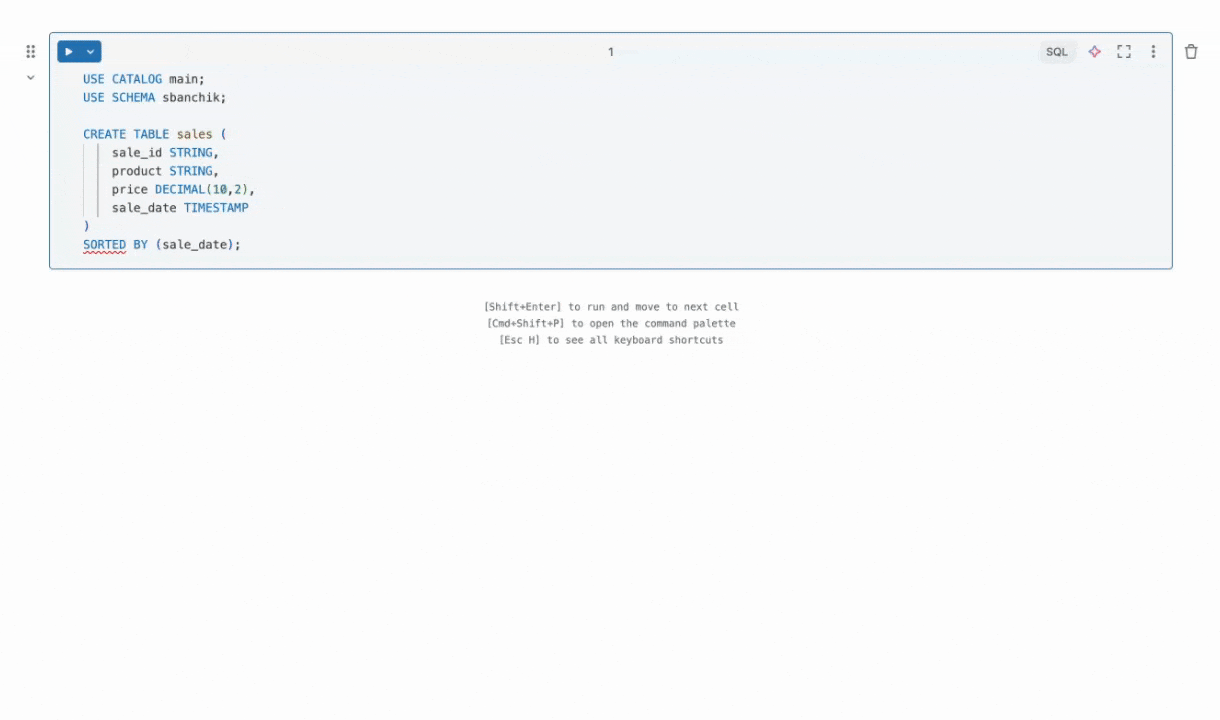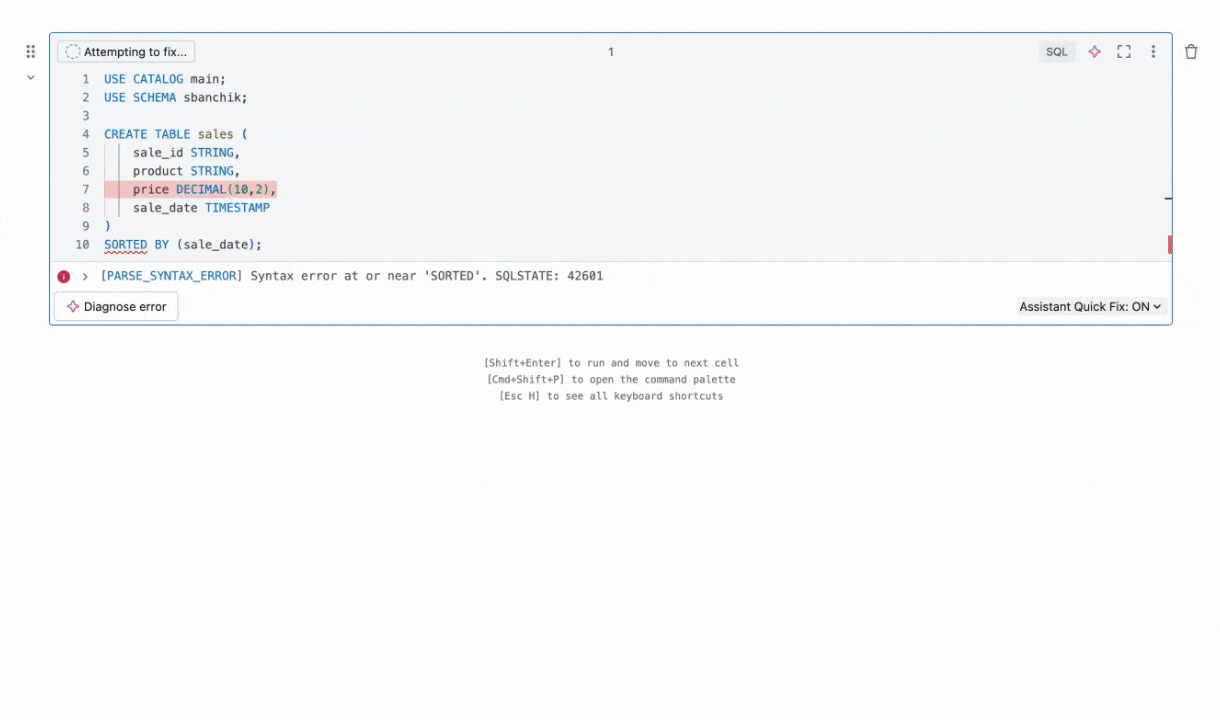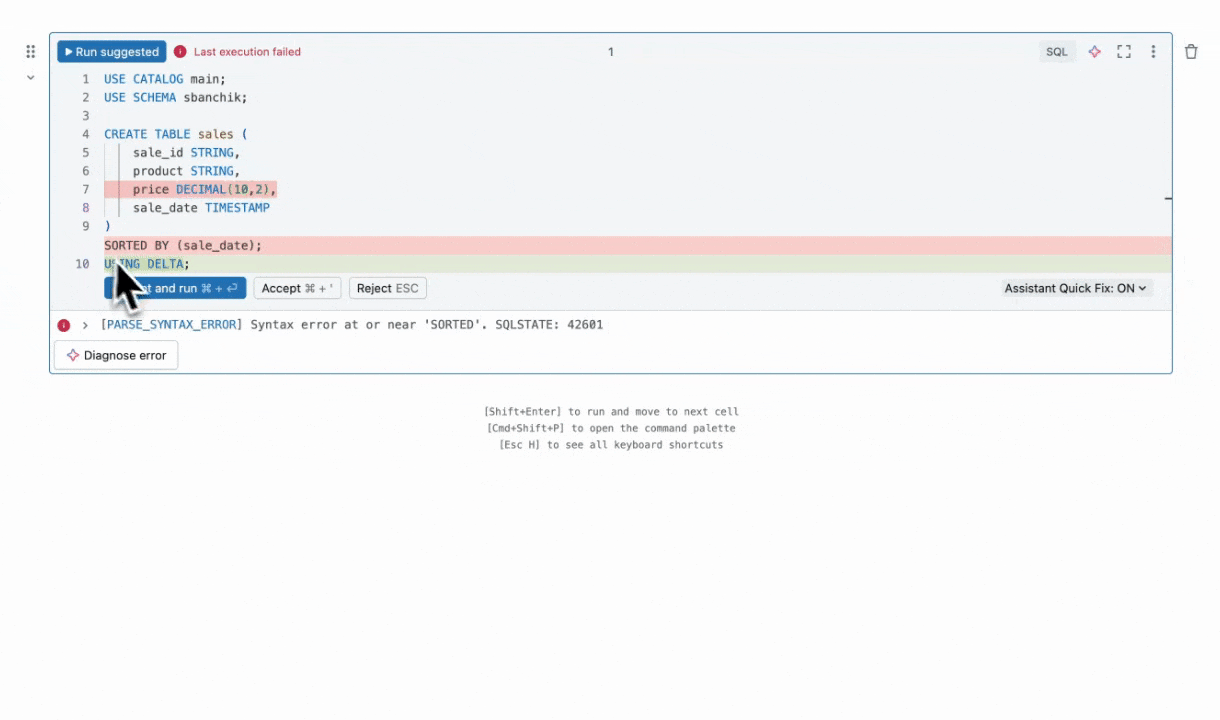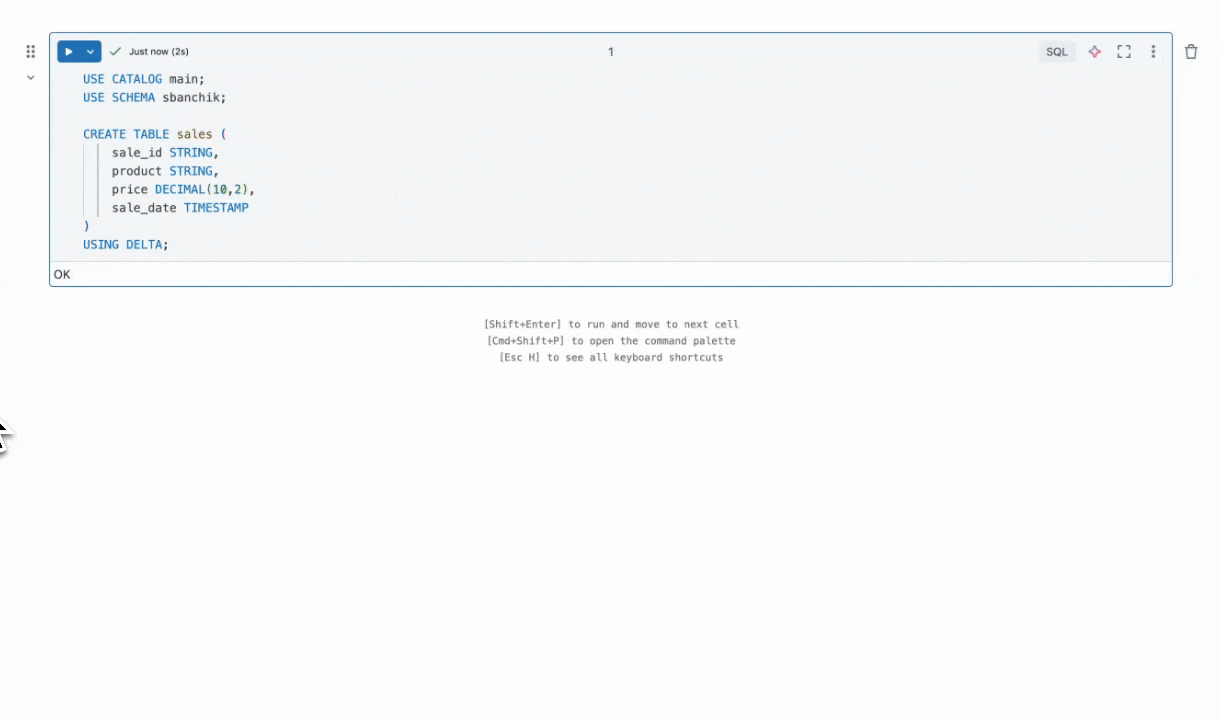
例えば、アシスタントがHive DDLをDatabricks互換のSQLに生成する方法を見てみましょう。元のクエリは、SORTED_BYがDBSQLに存在しないためエラーになります。ここで見るように、アシスタントは壊れた行をシームレスに置き換え、USING DELTA,を使用してテーブルがDelta Lakeで作成されることを確認しました。これにより、ストレージとインデックスが最適化されます。これにより、アナリストは手動で試行錯誤することなくHiveクエリを移行することができます。
クエリのリファクタリング
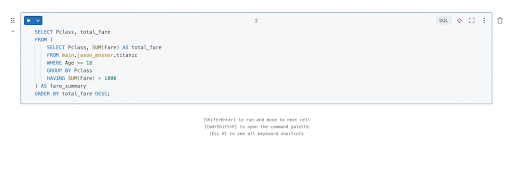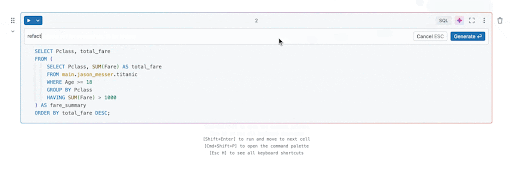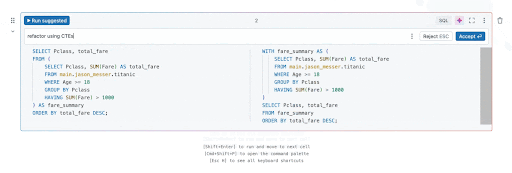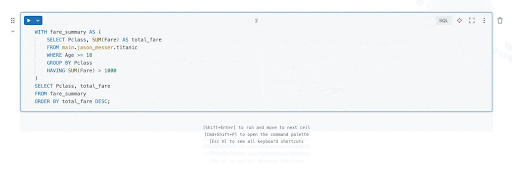
長く、ネストされたSQLクエリは、深くネストされたサブクエリや複雑なCASE WHENロジックが含まれている場合、読みやすさ、デバッグ、保守が難しくなることがあります。幸いなことに、Databricks Assistantを使用すれば、アナリストはこれらのクエリをCTEにリファクタリングして読みやすさを向上させることが容易になります。アシスタントが深くネストされたクエリをCTEを使用してより構造化された形式に変換する例を見��てみましょう。
SQLウィンドウ関数の記述
SQLウィンドウ関数は伝統的にランキング、集約、行を折りたたまずに累積合計を計算するために使用されますが、正しく使用するのは難しいことがあります。アナリストはPARTITION BYやORDER BY句、適切なランキング関数(RANK、DENSE_RANK、ROW_NUMBER)、または累積平均や移動平均を効率的に実装することに苦労することがよくあります。
Databricks Assistantは、正しい構文を生成し、関数の動作を説明し、パフォーマンスの最適化を提案することで助けてくれます。アシスタントがウィンドウ関数を使用して7日間の運賃合計を計算する例を見てみましょう。

JSONを構造化テーブルに変換する
アナリストはしばしばJSONのような半構造化データを扱うことがあり、これを効率的にクエリするためには構造化テーブルに変換する必要があります。フィールドの手動抽出、スキーマの定義、ネストされたJSONオブジェクトの処理は時間がかかり、エラーが発生しやすい作業です。Databricks Assistantは生データに直接アクセスできないため、Unity Catalogのメタデータ(テーブルの説明や列のコメントなど)を追加することで、提案の精度を向上させることができます。
この例では、ジャンルIDと名前が埋め込まれたJSONとして保存されたジャンルデータを含む列があります。Databricksアシスタントを使用すると、この列を素早くフラット化し、個々のフィールドを別々の列に抽出して分析を容易にすることができます。
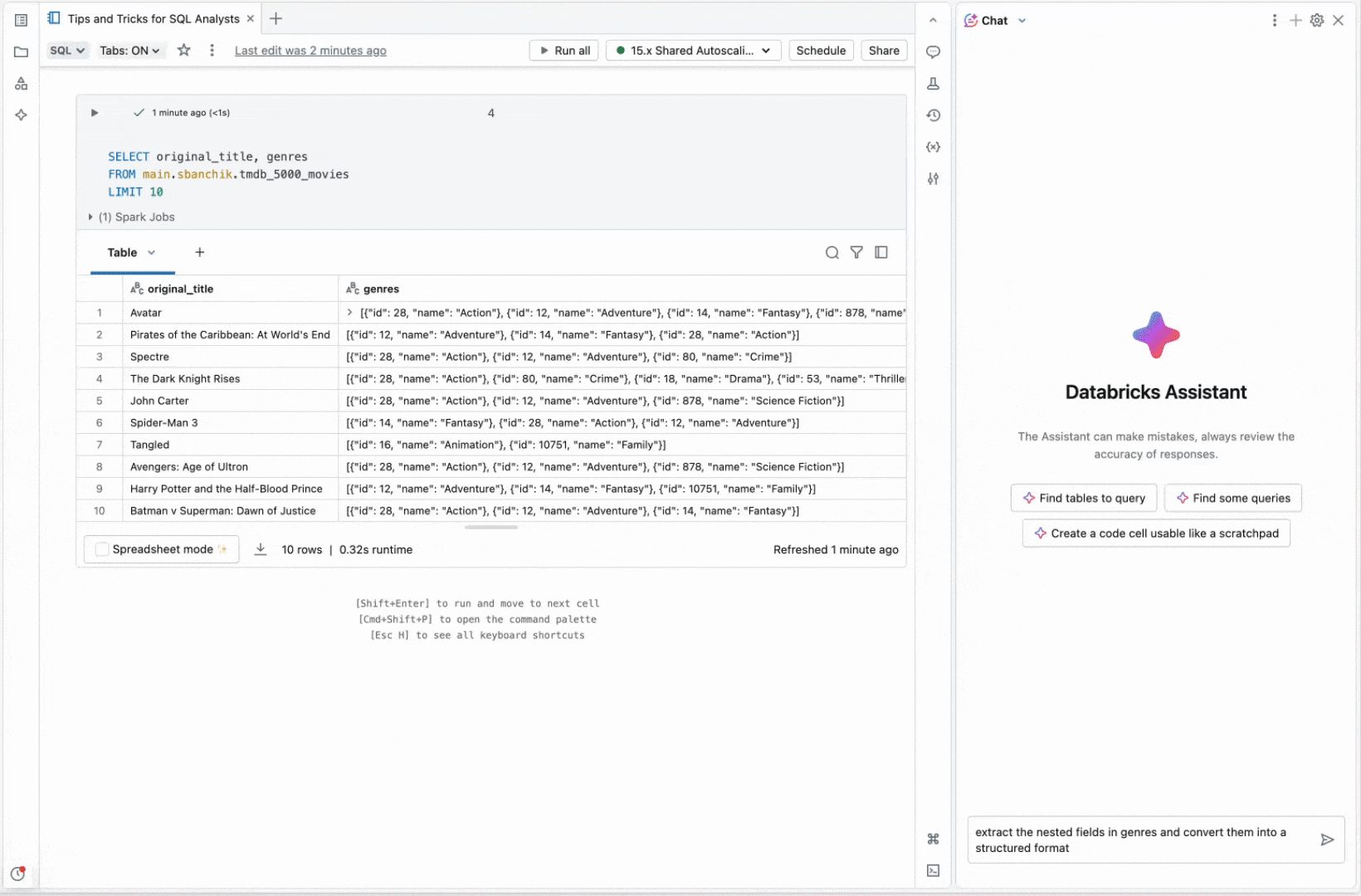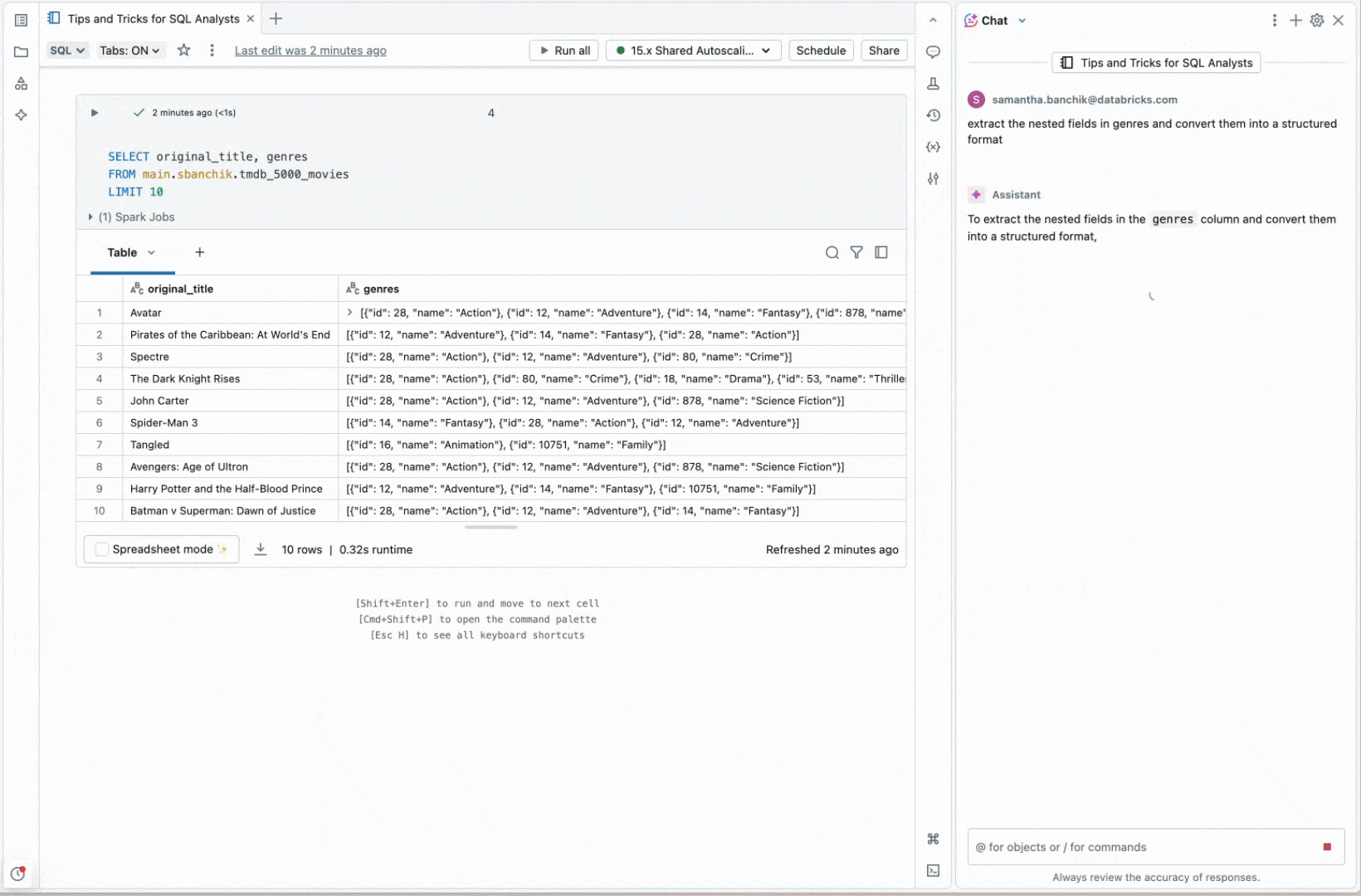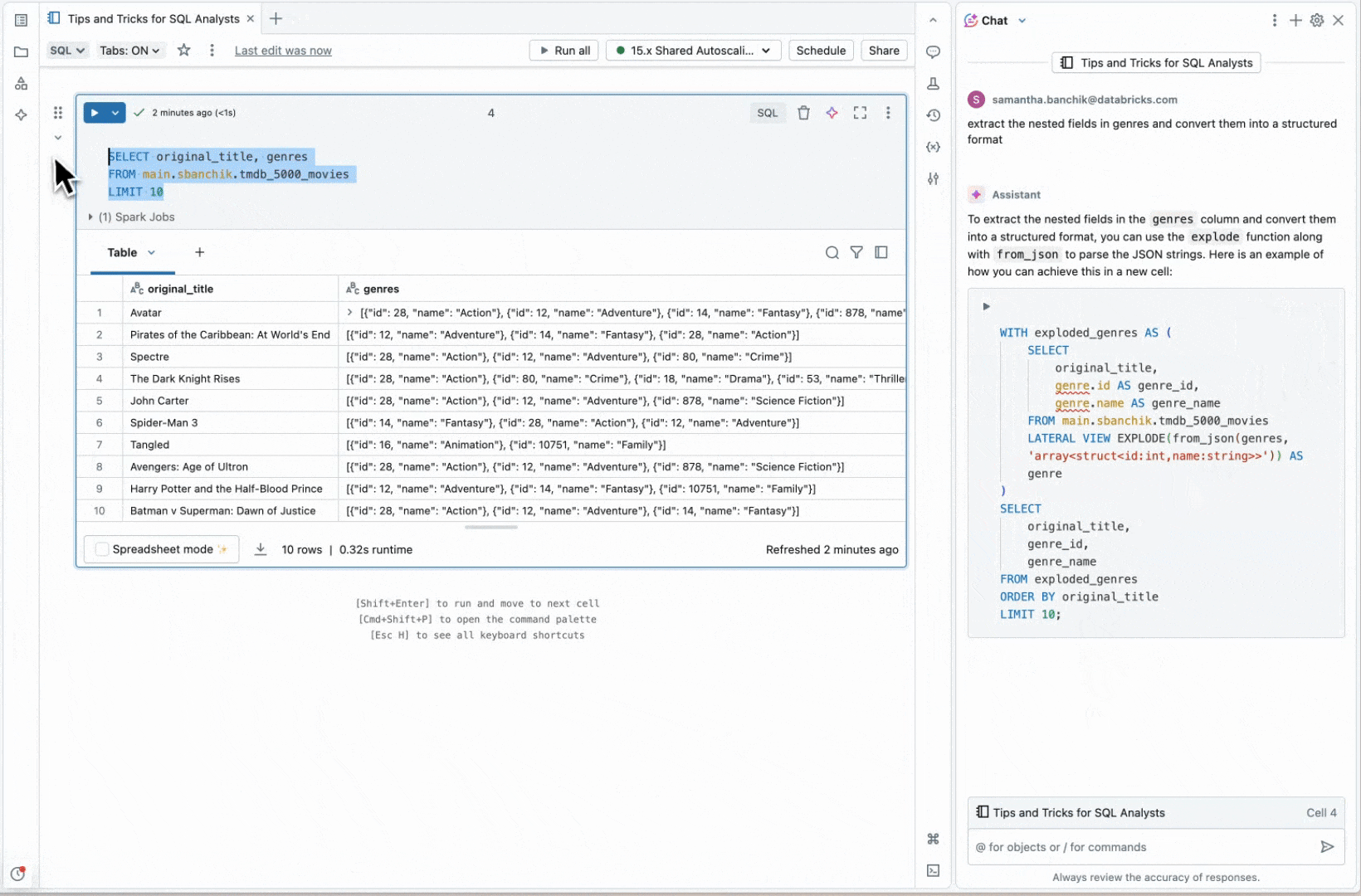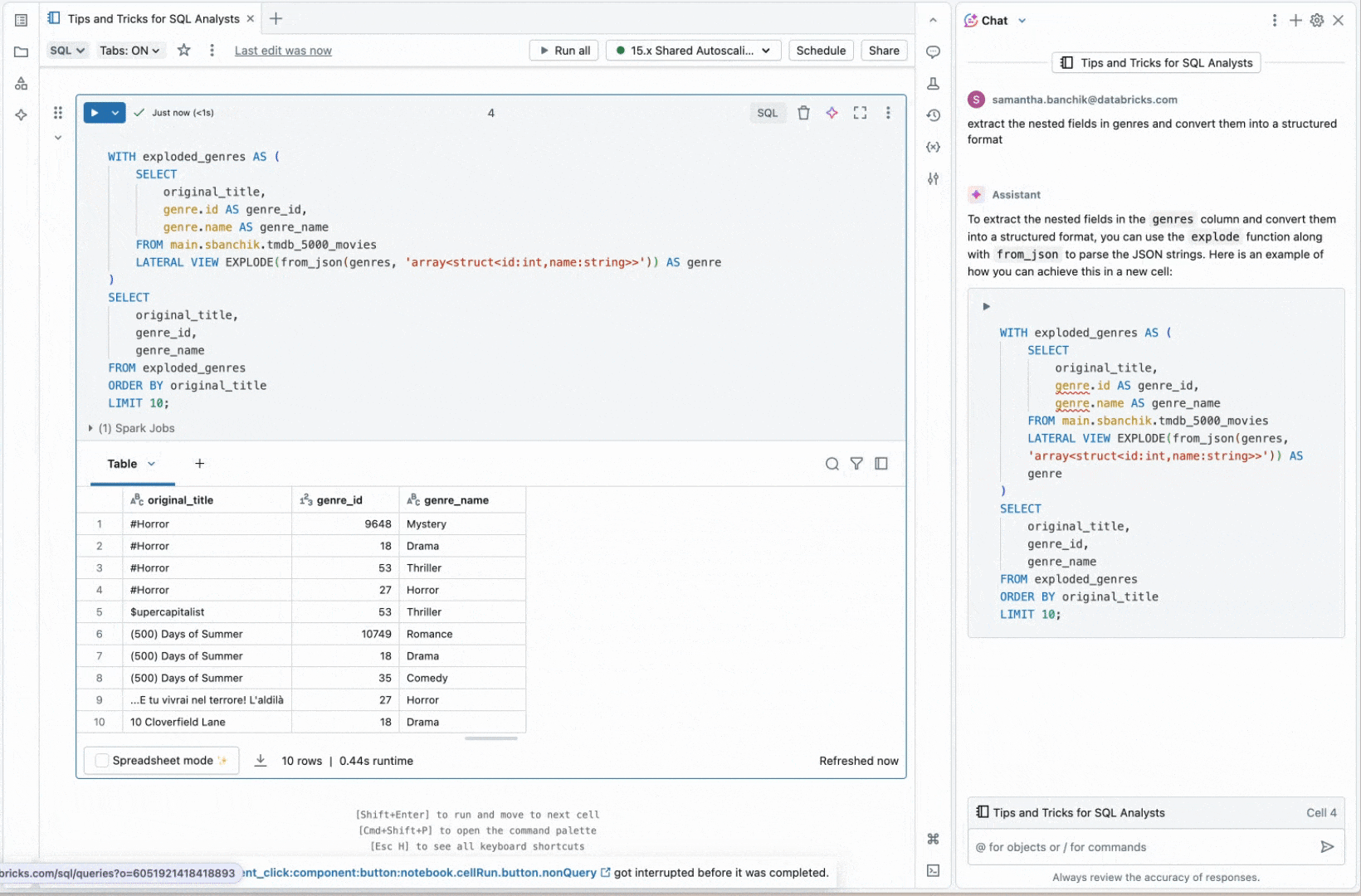
正確な結果を得るためには、まずCatalog ExplorerでJSON構造を確認し、アシスタントが列コメントで参照できるサンプル形式を提供する必要があります。この追加のステップにより、アシスタントはよりカスタマイズされた、正確なレスポンスを生成することができました。
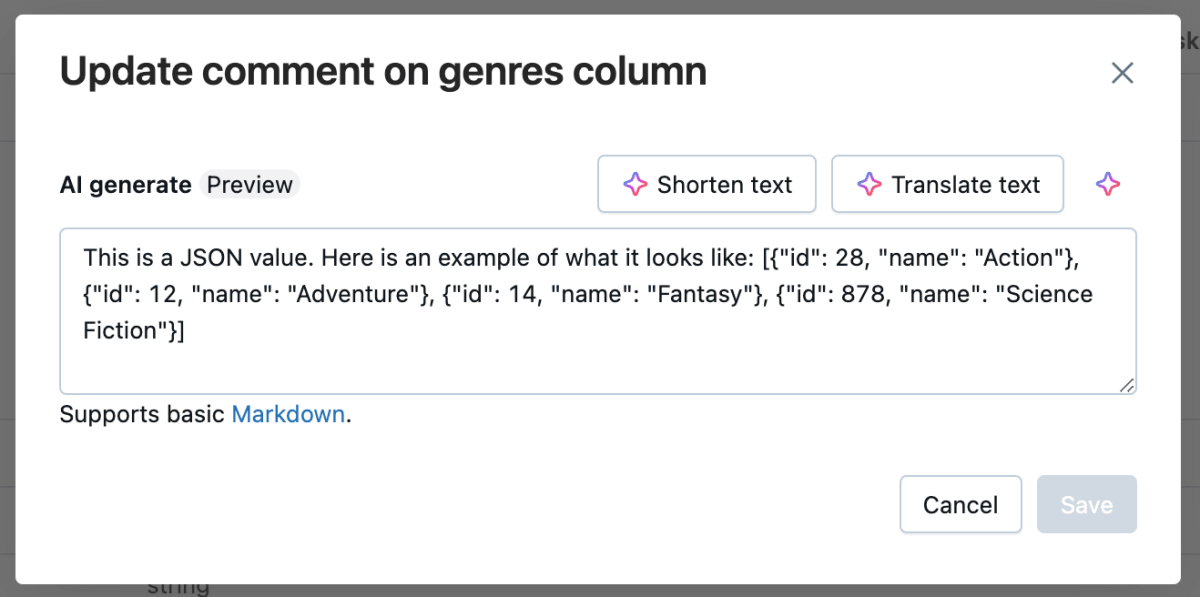
このようなアプローチは、正規表現の生成や複雑なSQL変換を試みる際にも使用できます。まず、期待される入力形式の明確な例を提供することで、アナリストはアシスタントがより正確で関連性のある提案を出すように導くことができます。これは、サンプルのJSON構造、テキストパターン、またはSQLスキーマであるかもしれません。
SQLクエリの最適化
昨年のDatabricks Assistant Year in Review blogで��は、/optimizeの導入を強調しました。これは、パーティションフィルタの欠如、高コストの結合、冗長な操作などの非効率性を特定してSQLクエリを洗練するのに役立ちます。クエリを実行する前に改善を積極的に提案することで、/optimizeはユーザーが不必要な計算を最小限に抑え、パフォーマンスを事前に向上させることを確認します。
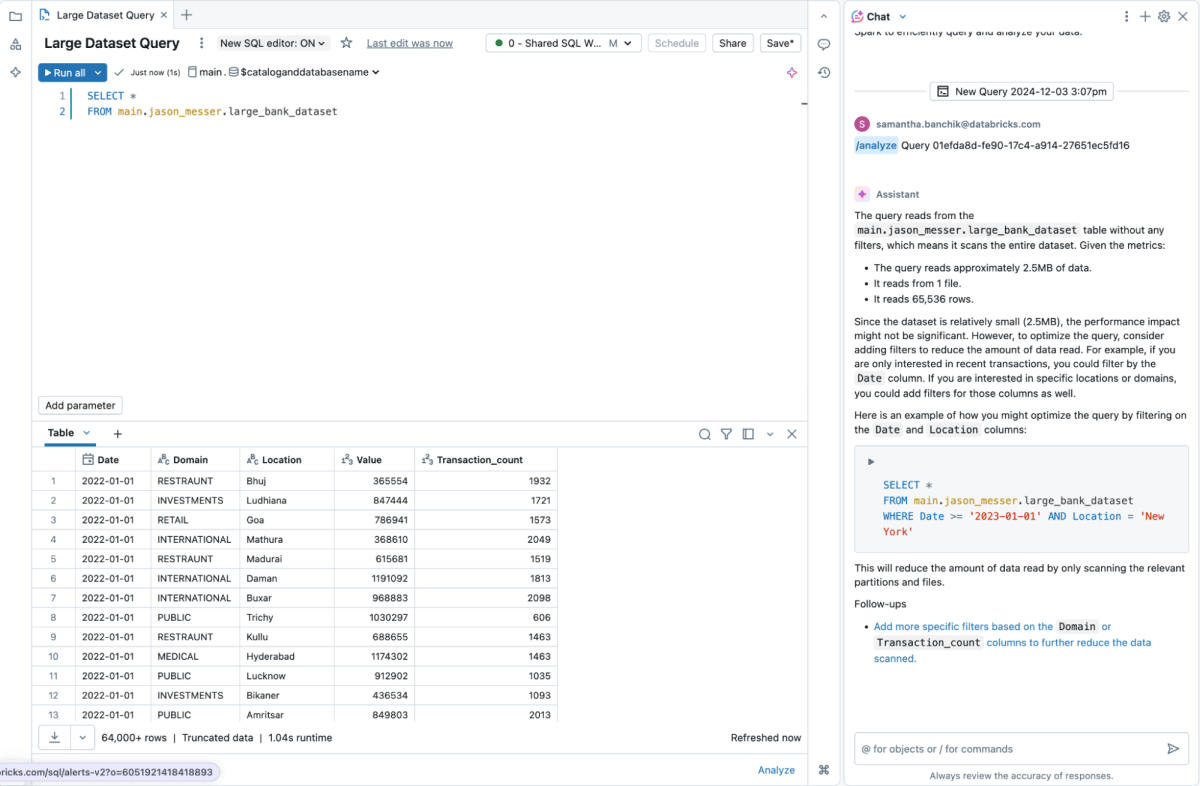
そして、これをさらに拡張して/analyzeという機能を導入しました。これは、クエリの実行後にパフォーマンスを調査し、実行統計を分析し、ボトルネックを検出し、インテリジェントな推奨事項を提供します。
下の例では、アシスタントが読み込むデータ量を分析し、パフォーマンスを向上させるための最適なパーティショニング戦略を提案しています。
今日からDatabricks Assistantを試してみてください!
Databricks Assistantを今日から使用して、タスクを自然言語で説明し、アシスタントにSQLクエリを生成させ、複雑なコードを説明させ、エラーを自動的に修正させてみてください。
また、DatabricksノートブックでのEDAに関する最新のチュートリアルもチェックしてみてください。ここでは、アシスタントがデータのクリーニング、フィルタリング、探索をどのように効率化するかを示しています。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。