大規模言語モデルの最適なパラメータ選択ガイド:LoRAによる効率的なファインチューニング
によって アビナッシュ・スーリヤラッチ による投稿
ニューラルネットワークベースの手法と大規模言語モデル(LLM)の研究が急速に進歩するにつれて、企業は価値創出のためのAIアプリケーションへの関心をますます高めています。テキスト分類、要約、シーケンス間タスク、制御されたテキスト生成などのテキスト関連の課題に対処するために、生成モデルと非生成モデルの両方を含むさまざまな機械学習アプローチを採用しています。組織はサードパーティのAPIを選択することもできますが、独自のデータでモデルをファインチューニングすると、ドメイン固有で関連性の高い結果が得られ、コスト効率が高く独立したソリューションを安全にさまざまな環境にデプロイできるようになります。
ファインチューニング戦略を選択する際には、効率的なリソース利用とコスト効率を確保することが重要です。このブログでは、そのようなパラメータ効率の高い手法の中で、おそらく最も人気があり効果的なバリアントであるLoRA(Low Rank Adaptation)について、特にQLoRA(LoRAのさらに効率的なバリアント)に焦点を当てて探ります。ここでは、オープンな大規模言語モデルを取得し、製品名とカテゴリをプロンプトとして与えられたときに架空の製品説明を生成するようにファインチューニングします。この演習で選択されたモデルは、Apache 2.0の許可ライセンスを持つオープンな大規模言語モデルである OpenLLaMA-3b-v2で、選択されたデータセットは、HuggingFace Hubから提供されたリンクでダウンロードできる、Red Dot Design Award Product Descriptions Red Dot Design Award Product Descriptionsです。
ファインチューニング、LoRA、QLoRA
言語モデルの分野では、既存の言語モデルを特定のタスクやデータに合わせてファインチューニングすることは一般的な実践です。これには、必要に応じてタスク固有のヘッドを追加し、トレーニングプロセス中にバックプロパゲーションを通じてニューラルネットワークの��重みを更新することが含まれます。このファインチューニングプロセスとゼロからのトレーニングとの区別を認識することが重要です。後者のシナリオでは、モデルの重みはランダムに初期化されますが、ファインチューニングでは、重みは事前トレーニングフェーズ中にすでに一定の程度まで最適化されています。どの重みを最適化または更新し、どの重みを凍結するかは、選択された手法によって異なります。
フルファインチューニングは、ニューラルネットワークのすべてのレイヤーを最適化またはトレーニングすることを含みます。このアプローチは通常最良の結果をもたらしますが、最もリソースを消費し、時間がかかります。
幸いなことに、効果的であることが証明されているファインチューニングのためのパラメータ効率の高いアプローチが存在します。そのようなアプローチのほとんどはパフォーマンスが低下していますが、LoRA(Low Rank Adaptation)は、一部のケースではフルファインチューニングを上回るパフォーマンスを示すことで、この傾向に反しています。これは、破滅的な忘却(事前トレーニング済みモデルの知識がファインチューニングプロセス中に失われる現象)を回避した結果です。
LoRA は改善されたファインチューニング手法であり、事前トレーニング済み大規模言語モデルの重み行列を構成するすべての重みをファインチューニングする代わりに、この大きな行列を近似する2つの小さな行列をファインチューニングします。これらの行列はLoRAアダプターを構成します。このファインチューニングされたアダプターは、事前トレーニング済みモデルにロードされ、推論に使用されます。
QLoRA はLoRAのさらにメモリ効率の良いバージョンであり、事前トレーニング済みモデルは、LoRAの場合(8ビット)と比較して、4ビットの量子化された重みとしてGPUメモリにロードされますが、LoRAと同様の効果を維持します。ここでは、この手法を調査し、必要に応じて両方の手法を比較し、最速のトレーニング時間で最適なパフォーマンスを達成するためのQLoRAハイパーパラメータの最適な組み合わせを見つけることに焦点を当てます。
LoRAはHugging Face Parameter Efficient Fine-Tuning(PEFT)ライブラリに実装されており、使いやすさを提供します。QLoRAは、 bitsandbytes と PEFT を組み合わせて使用することで活用できます。HuggingFace Transformer Reinforcement Learning (TRL) ライブラリは、LoRAとのシームレスな統合により、教師ありファインチューニングのための便利なトレーナーを提供します。これらの3つのライブラリは、指示された属性を示すプロンプトが与えられたときに、一貫性があり説得力のある製品説明を生成するように、選択した事前トレーニング済みモデルをファインチューニングするために必要なツールを提供します。
教師ありファインチューニングのためのデータ準備
命令追従のためにモデルをファインチューニングする際のQLoRAの有効性を調査するには、教師ありファインチューニングに適した形式にデータを変換することが不可欠です。本質的に、教師ありファインチューニングは、提供されたプロンプトを条件としてテキストを生成するように、事前トレーニング済みモデルをさらにトレーニングします。プロンプトと応答のペアが一貫した形式でフォーマットされたデータセットでファインチューニングされるため、教師ありと呼ばれます。
Hugging Faceハブから選択したデータセットの観測例は次のようになります。
|
製品 |
カテゴリ |
説明 |
テキスト |
|
"Biamp Rack Products" |
"Digital Audio Processors" |
"高い認識価値、均一な美学、および実用的な拡張性–これらはBiampブランド言語で印象的に達成されています…" |
"製品名:Biamp Rack Products;製品カテゴリ:Digital Audio Processors;製品説明:「高い認識価値、均一な美学、および実用的な拡張性–これらはBiampブランド言語で印象的に達成されています…
|
このデータセットは有用ですが、前述の方法で言語モデルの命令追従をファインチューニングするには適切にフォーマットされていません。
次のコードスニペットは、Hugging Faceハブからデータセットをメモリにロードし、必要なフィールドをプロンプトを表す一貫してフォーマットされた文字列に変換し、その直後に応答(つまり説明)を挿入します。この形式は、大規模言語モデルの研究分野では「Alpaca形式」として知られています。これは、Metaの元のLlamaモデルをファインチューニングしてAlpacaモデル(商用利用はライセンスされていませんが、広く配布された最初の命令追従大規模言語モデルの1つ)を作成するために使用された形式であるためです。
生成されたプロンプトは、教師ありファインチューニング用のHugging Faceデータセットにロードされます。各プロンプトは次の形式になります。
To facilitate quick experimentation, each fine-tuning exercise will be done on a 5000 observation subset of this data.
Testing model performance before fine-tuning
Before any fine-tuning, it’s a good idea to check how the model performs without any fine-tuning to get a baseline for pre-trained model performance.
The model can be loaded in 8-bit as follows and prompted with the format specified in the model card on Hugging Face.
The output obtained is not quite what we want.
The first part of the result is actually satisfactory, but the rest of it is more of a rambling mess.
Similarly, if the model is prompted with the input text in the ‘Alpaca format’ as discussed before, the output is expected to be just as sub-optimal:
And sure enough, it is:
The model performs what it was trained to do, predicts the next most probable token. The point of supervised fine-tuning in this context is to generate the desired text in a controllable manner. Please note that in the subsequent experiments, while QLoRA leverages a model loaded in 4-bit with the weights frozen, the inference process to examine output quality is done once the model has been loaded in 8-bit as shown above for consistency.
The Turnable Knobs
When using PEFT to train a model with LoRA or QLoRA (note that, as mentioned before, the primary difference between the two is that in the latter, the pretrained models are frozen in 4-bit during the fine-tuning process), the hyperparameters of the low rank adaptation process can be defined in a LoRA config as shown below:
Two of these hyperparameters, r and target_modules are empirically shown to affect adaptation quality significantly and will be the focus of the tests that follow. The other hyperparameters are kept constant at the values indicated above for simplicity.
r represents the rank of the low rank matrices learned during the finetuning process. As this value is increased, the number of parameters needed to be updated during the low-rank adaptation increases. Intuitively, a lower r may lead to a quicker, less computationally intensive training process, but may affect the quality of the model thus produced. However, increasing r beyond a certain value may not yield any discernible increase in quality of model output. How the value of r affects adaptation (fine-tuning) quality will be put to the test shortly.
When fine-tuning with LoRA, it is possible to target specific modules in the model architecture. The adaptation process will target these modules and apply the update matrices to them. Similar to the situation with "r," targeting more modules during LoRA adaptation results in increased training time and greater demand for compute resources. Thus, it is a common practice to only target the attention blocks of the transformer. However, recent work as shown in the QLoRA paper by Dettmers et al. suggests that targeting all linear layers results in better adaptation quality. This will be explored here as well.
Names of the linear layers of the model can be conveniently appended to a list with the following code snippet:
Tuning the finetuning with LoRA
The developer experience of fine tuning large language models in general have improved dramatically over the past year or so. The latest high level abstraction from Hugging Face is the SFTTrainer class in the TRL library. To perform QLoRA, all that is needed is the following:
1. Load the model to GPU memory in 4-bit (bitsandbytes enables this process).
2. Define the LoRA configuration as discussed above.
3. Define the train and test splits of the prepped instruction following data into Hugging Face Dataset objects.
4. Define training arguments. These include the number of epochs, batch size and other training hyperparameters which will be kept constant during this exercise.
5. Pass these arguments into an instance of SFTTrainer.
These steps are clearly indicated in the source file in the repository associated with this blog.
The actual training logic is abstracted away nicely as follows:
If MLFlow autologging is enabled in the Databricks workspace, which is highly recommended, all the training parameters and metrics are automatically tracked and logged with the MLFlow tracking server. This functionality is invaluable in monitoring long-running training tasks. Needless to say, the fine-tuning process is performed using a compute cluster (in this case, a single node with a single A100 GPU) created using the latest Databricks Machine runtime with GPU support.
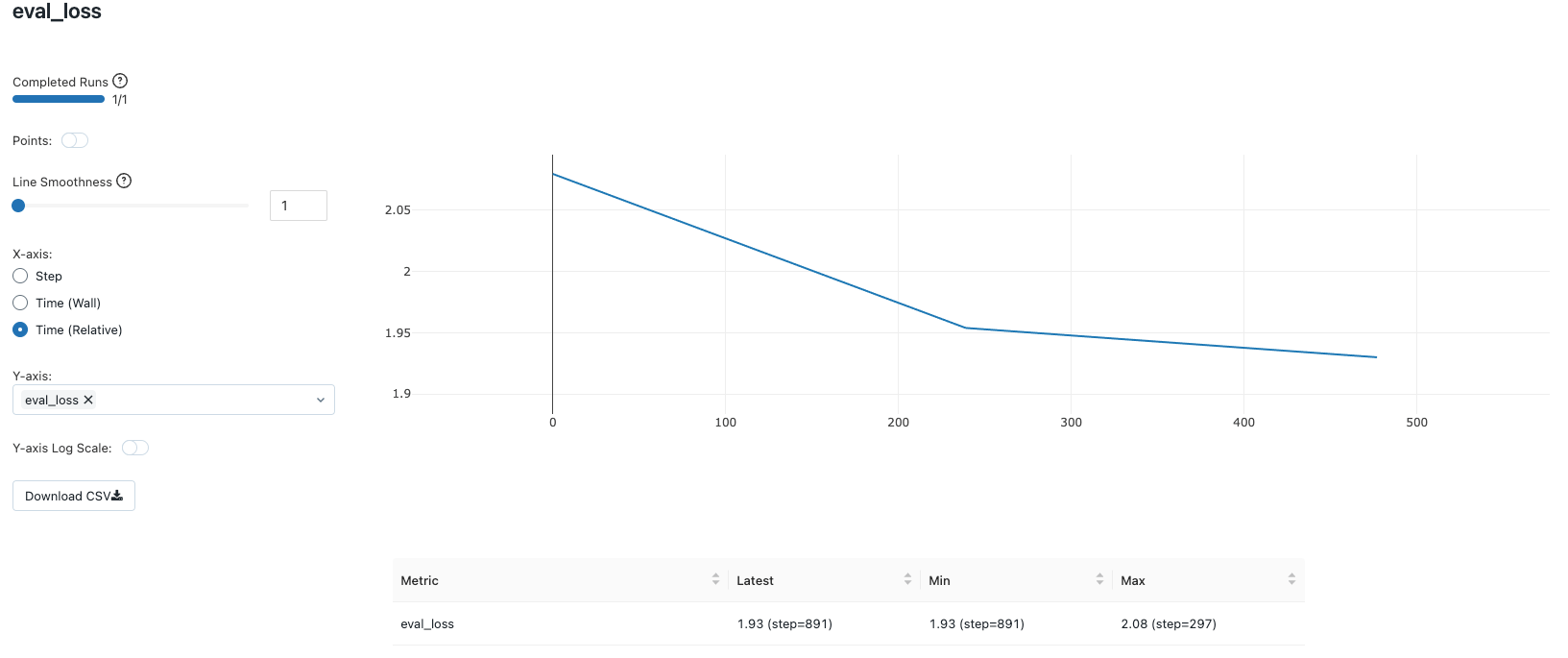
Hyperparameter Combination #1: QLoRA with r=8 and targeting “q_proj”, “v_proj”
最初のQLoRAハイパーパラメータの組み合わせは、r=8で、注意ブロックのみ(つまり、適応のために“q_proj”と“v_proj”)をターゲットにしています。
以下のコードスニペットは、トレーニング可能なパラメータ数を示しています。
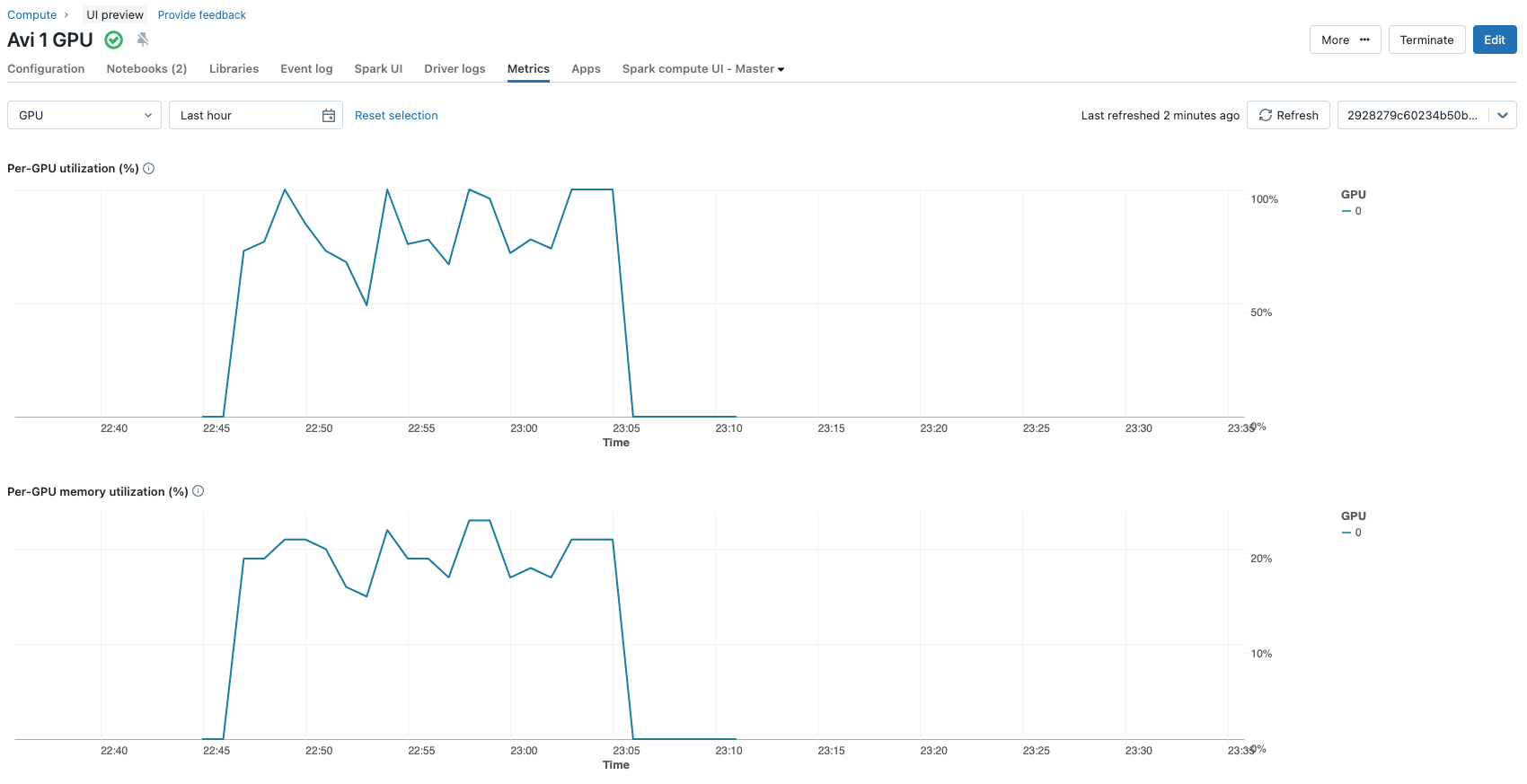
これらの選択により、モデルが構成する約32億パラメータのうち、ファインチューニングプロセス中に更新されるパラメータは2,662,400(約260万)になります。これはモデルパラメータの0.1%未満です。80GBのGPUを搭載した単一のNvidia A100での全ファインチューニングプロセスは、3エポックで約12分しかかかりません。GPU使用率メトリクスは、クラスター構成のメトリクスタブで便利に表示できます。
トレーニングプロセスの最後に、アダプターの重みを事前トレーニング済みモデルに次のようにロードすることで、ファインチューニングされたモデルが得られます。
このモデルは、他のモデルと同様に推論に使用できます。
定性評価
以下に、いくつかのプロンプトと応答のペアの例を示します。
プロンプト (Alpaca形式でモデルに渡され、簡潔さのためここでは省略):
次の製品の詳細な説明を作成してください: Corelogic Smooth Mouse、カテゴリ: Optical Mouse
応答:
プロンプト:
次の製品の詳細な説明を作成してください: Hoover Lightspeed、カテゴリ: Cordless Vacuum Cleaner
応答:
モデルは、より一貫した説明を生成するように明らかに適応されています。しかし、光学マウ�スに関する最初のプロンプトへの応答は非常に短く、“掃除機には、ダストコンテナを介して空にできるダストコンテナが装備されています”というフレーズは論理的に誤っています。
ハイパーパラメータの組み合わせ #2: QLoRA r=16、すべての線形レイヤーをターゲット
確かに、ここでは改善の余地があります。適応中に学習される低ランク行列のランクを16に増やす、つまりrの値を2倍にして16にし、他はすべて同じに保つことは検討する価値があります。これにより、トレーニング可能なパラメータ数は5,324,800(約530万)に倍増します。
定性評価
しかし、出力の品質は、まったく同じプロンプトに対して変更されません。
プロンプト:
次の製品の詳細な説明を作成してください: Corelogic Smooth Mouse、カテゴリ: Optical Mouse
応答:
プロンプト:
次の製品の詳細な説明を作成してください: Hoover Lightspeed、カテゴリ: Cordless Vacuum Cleaner
応答:
詳細の欠如と、詳細が利用可能な場合の詳細における論理的な誤りは同様に持続します。このファインチューニングされたモデルが実際のシナリオで製品説明の生成に使用される場合、これは許容できる出力ではありません。
ハイパーパラメータの組み合わせ #3: QLoRA r=8、すべての線形レイヤーをターゲット
rを倍にしても出力品質に知覚できるほどの向上は見られないため、もう一つの重要なノブを変更する価値があります。つまり、注意ブロックだけでなく、すべての線形レイヤーをターゲットにします。ここでは、LoRAのハイパーパラメータはr=8で、target_layersは'q_proj','k_proj','v_proj','o_proj','gate_proj','down_proj','up_proj'および'lm_head'です。これにより、更新されるパラメータ数は12,994,560に増加し、トレーニング時間は約15.5分に増加します。
定性評価
同じプロンプトでモデルにプロンプトすると、次のようになります。
プロンプト:
次の製品の詳細な説明を作成してください: Corelogic Smooth Mouse、カテゴリ: Optical Mouse
応答:
プロンプト:
次の製品の詳細な説明を作成してください: Hoover Lightspeed、カテゴリ: Cordless Vacuum Cleaner
応答:
架空の光学マウスの、ある程度長い一貫した説明が見えるようになり、掃除機の説明には論理的な誤りはありません。製品説明は論理的であるだけでなく、関連性もあります。念のため、これらの比較的質の高い結果は、モデルの1%未満の重みを、一貫した方法でフォーマットされた合計5000のこのようなプロンプト-説明ペアのデータセットでファインチューニングすることによって得られています。
ハイパーパラメータの組み合わせ #4: LoRA r=8、すべての線形トランスフォーマーレイヤーをターゲット
事前トレーニング済みモデルを4ビットではなく8ビットでフリーズした場合、モデルからの出力品質が向上するかどうかを検討することも価値があります。言い換�えれば、QLoRAの代わりにLoRAを使用して、まったく同じファインチューニングプロセスを再現します。ここでは、LoRAのハイパーパラメータは、新しく見つかった最適な構成、つまりr=8で、適応プロセス中にすべての線形トランスフォーマーレイヤーをターゲットにするという以前と同じです。
定性評価
記事全体で使用された2つのプロンプトの結果は、以下のとおりです。
プロンプト:
次の製品の詳細な説明を作成してください: Corelogic Smooth Mouse、カテゴリ: Optical Mouse
応答:
プロンプト:
次の製品の詳細な説明を作成してください: Hoover Lightspeed、カテゴリ: Cordless Vacuum Cleaner
応答:
ここでも、出力テキストの品質に大きな改善はありません。
主な観察事項
上記の試行セットと、QLoRAを発表した優れた出版物に詳述されているさらなる証拠に基づくと、適応中に更新される行列のランクであるrの値は、ある点を超えると適応品質を向上させないことが推測できます。技術文献で一般的に文書化されているように、注意ブロックだけでなく、すべての線形レイヤーを適応プロセスでターゲットにすることによって、最大の改善が観察されます。上記で実行された試行とその他の経験的証拠は、LoRAと比較して、QLoRAは生成されるテキストの品質に認識可能な低下がないことを実際に示唆しています。
デプロイメントでのLoRAアダプターの使用に関するさらなる考慮事項
アダプターの使用を最適化し、その手法の限界を理解することが重要です。ファインチューニングによって得られるLoRAアダプターのサイズは通常わずか数メガバイトですが、事前学習済みベースモデルはメモリとディスクで数ギガバイトになることがあります。推論時には、アダプターと事前学習済みLLMの両方をロードする必要があるため、メモリ要件は同様のままです。
さらに、事前学習済みLLMとアダプターの重みがマージされていない場合、推論レイテンシがわずかに増加します。幸いなことに、PEFTライブラリを使用すると、アダプターとの重みのマージプロセスは、ここで示すように1行のコードで実行できます。
下の図は、アダプターのファインチューニングからモデルデプロイまでのプロセスを概説しています。

アダプターパターンは大きなメリットを提供しますが、アダプターのマージは万能な解決策ではありません。アダプターパターンの利点の1つは、タスク固有のアダプターを持つ単一の大きな事前学習済みモデルをデプロイできることです。これにより、事前学習済みモデルをさまざまなタスクのバックボーンとして利用することで、効率的な推論が可能になります。ただし、重みをマージすると、このアプローチは不可能になります。重みをマージするかどうかの決定は、特定のユースケースと許容できる推論レイテンシによって異なります。それにもかかわらず、LoRA/QLoRAは、パラメータ効��率の良いファインチューニングのための非常に効果的な方法であり続けており、広く使用されています。
結論
Low Rank Adaptationは、適切な構成で使用すれば素晴らしい結果をもたらすことができる強力なファインチューニング手法です。ランクの正しい値と、適応中にターゲットとするニューラルネットワークアーキテクチャのレイヤーを選択することが、ファインチューニングされたモデルからの出力の品質を決定する可能性があります。QLoRAは、適応品質を維持しながら、さらなるメモリ節約につながります。ファインチューニングが実行された場合でも、適応されたモデルが正しくデプロイされることを保証するために、いくつかの重要なエンジニアリング上の考慮事項があります。
要約すると、OpenLLaMA-3b-v2を3エポック、5000の観測値で単一のA100でファインチューニングした際に試行されたLoRAパラメータのさまざまな組み合わせ、テキスト品質の出力、および更新されたパラメータ数を示す簡潔な表を以下に示します。
|
r |
target_modules |
Base model weights |
Quality of output |
Number of parameters updated (in millions) |
|
8 |
Attention blocks |
4 |
low |
2.662 |
|
16 |
Attention blocks |
4 |
low |
5.324 |
|
8 |
All linear layers |
4 |
high |
12.995 |
|
8 |
All linear layers |
8 |
high |
12.995 |
Try this on Databricks! Clone the GitHub repository associated with the blog into a Databricks Repo to get started. More thoroughly documented examples to finetune models on Databricks are available here.
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。