データレイクハウスでコンピュータビジョンアプリケーションを実現する
によって パウロ・ボルヘス, Bala Amavasai 、 ブライアン・スミス(Bryan Smith) による投稿
Original Blog : Enabling Computer Vision Applications With the Data Lakehouse
翻訳: junichi.maruyama
ブログ「Tackle Unseen Quality, Operations and Safety Challenges with Lakehouse enabled Computer Vision」で紹介したように、コンピュータビジョンアプリケーションが小売業や製造業を変革する可能性は、決して誇張できるものではありません。しかし、多くの技術的な課題があるため、組織はこの可能性を実現することができません。コンピュータビジョンアプリケーションの開発・実装に関する技術シリーズの初回である今回は、これらの課題をさらに掘り下げ、データの取り込み、モデルのトレーニング、モデルの展開に採用されている基本的なパターンを探ります。
画像データのユニークな性質から、これらの情報資産の管理方法を慎重に検討する必要があります。また、訓練されたモデルを最前線のアプリケーションに統合するには、従来とは異なる�展開経路を検討する必要があります。しかし、コンピュータビジョンシステムを使用して現実のビジネス問題を解決したパイオニア企業によって、多くの技術やテクニックが開発されています。この記事で紹介するように、これらを活用することで、実証実験から実用化まで、より迅速に進めることができます。
Data ingestion
ほとんどのコンピュータビジョンアプリケーションの開発において(設計と計画の後)、最初のステップは画像データの蓄積である。画像ファイルはカメラ対応デバイスで撮影され、中央のストレージリポジトリに転送され、モデルトレーニングの演習で使用するために準備されます。
ここで重要なのは、PNGやJPEGといった一般的なフォーマットの多くが、メタデータの埋め込みに対応していることです。画像の高さや幅などの基本的なメタデータは、ピクセル値を2次元表現に変換することをサポートします。また、Exif(Exchange Information File Format)メタデータなどの追加メタデータを埋め込むことで、カメラやその構成、位置情報(GPSセンサーを搭載している場合)などの詳細情報を提供することができます。
画像ライブラリを構築する際、メタデータや画像の統計情報は、データサイエンティストがコンピュータビジョンアプリケーションのために蓄積された何千、何百万もの画像を選別する際に役立つもので、Lakehouseのストレージに到着すると処理されます。Pillow,などの一般的なオープンソースライブラリを活用することで、メタデータと統計情報の両方を抽出し、Lakehouse環境のクエリ可能なテーブルに永続化することができ、簡単にアクセスできます。画像を構成するバイナリデータも、ストレージ環境内のオリジナルファイルのパス情報とともに、これらのテーブルに永続化することができます。
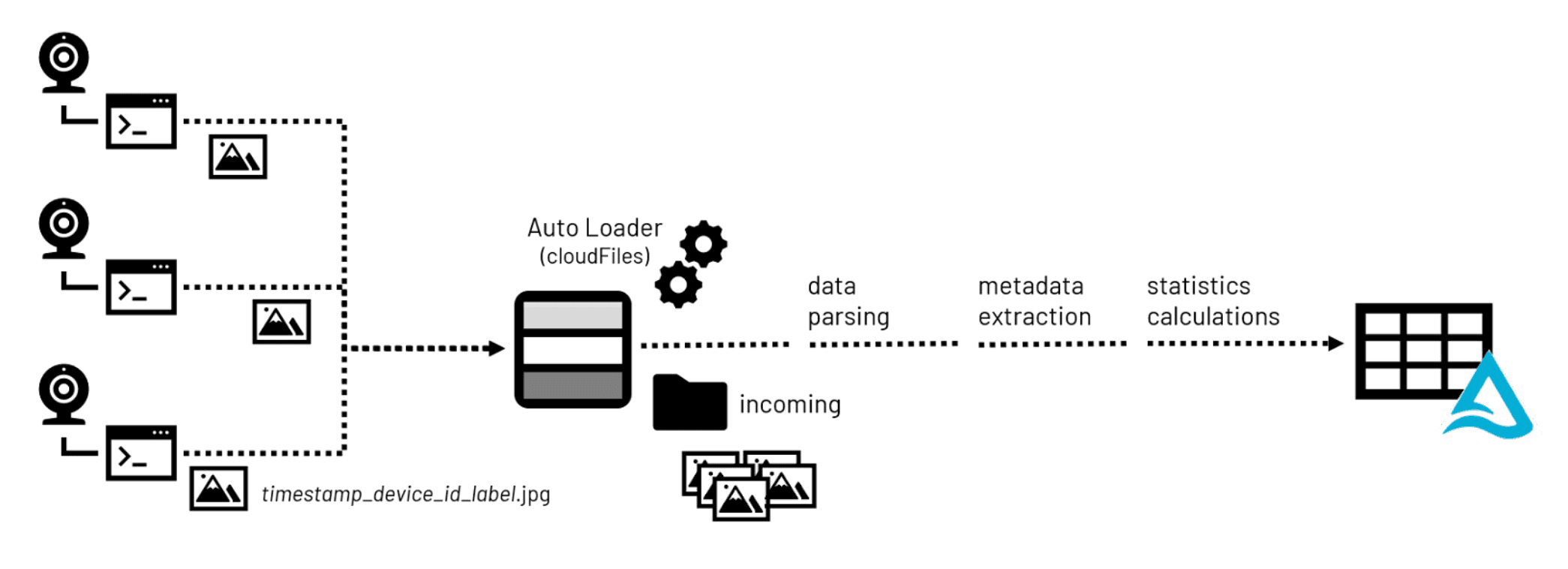
Figure 1. 画像ファイル受信時のデータ処理ワークフロー
Model training
個々の画像ファイルのサイズと、ロバストなモデルをトレーニングするために必要な多数の画像ファイルの組み合わせは、モデルトレーニング中にそれらをどのように扱うかを慎重に検討する必要があることを意味します。pandasのデータフレームにモデルの入力を収集するようなデータサイエンスの演習で一般的に使用される技術は、個々のコンピュータのメモリ制限のため、企業スケールで動作しないことがよくあります。Spark™データフレームは、コンピュータクラスタとして構成された複数のコンピュータノードにデータ量を分散させますが、ほとんどのコンピュータビジョンライブラリではアクセスできないため、この問題に対する別のソリューションが必要です。
この最初のモデ�ルトレーニングの課題を克服するために、高度なディープラーニングモデルタイプの大規模トレーニングのために特別に構築されたデータキャッシング技術であるPetastormを使用することができます。Petastormは、Lakehouseから大量のデータを取得し、一時的なストレージベースのキャッシュに配置することができます。ディープニューラルネットワーク開発のための最も一般的なライブラリであり、コンピュータビジョンアプリケーションで一般的に採用されているTensorflowとPyTorchを活用したモデルは、より大きなPetastormデータセットに対して反復処理を行う際に、キャッシュから小さなサブセットのデータを一括して読み出すことができます。
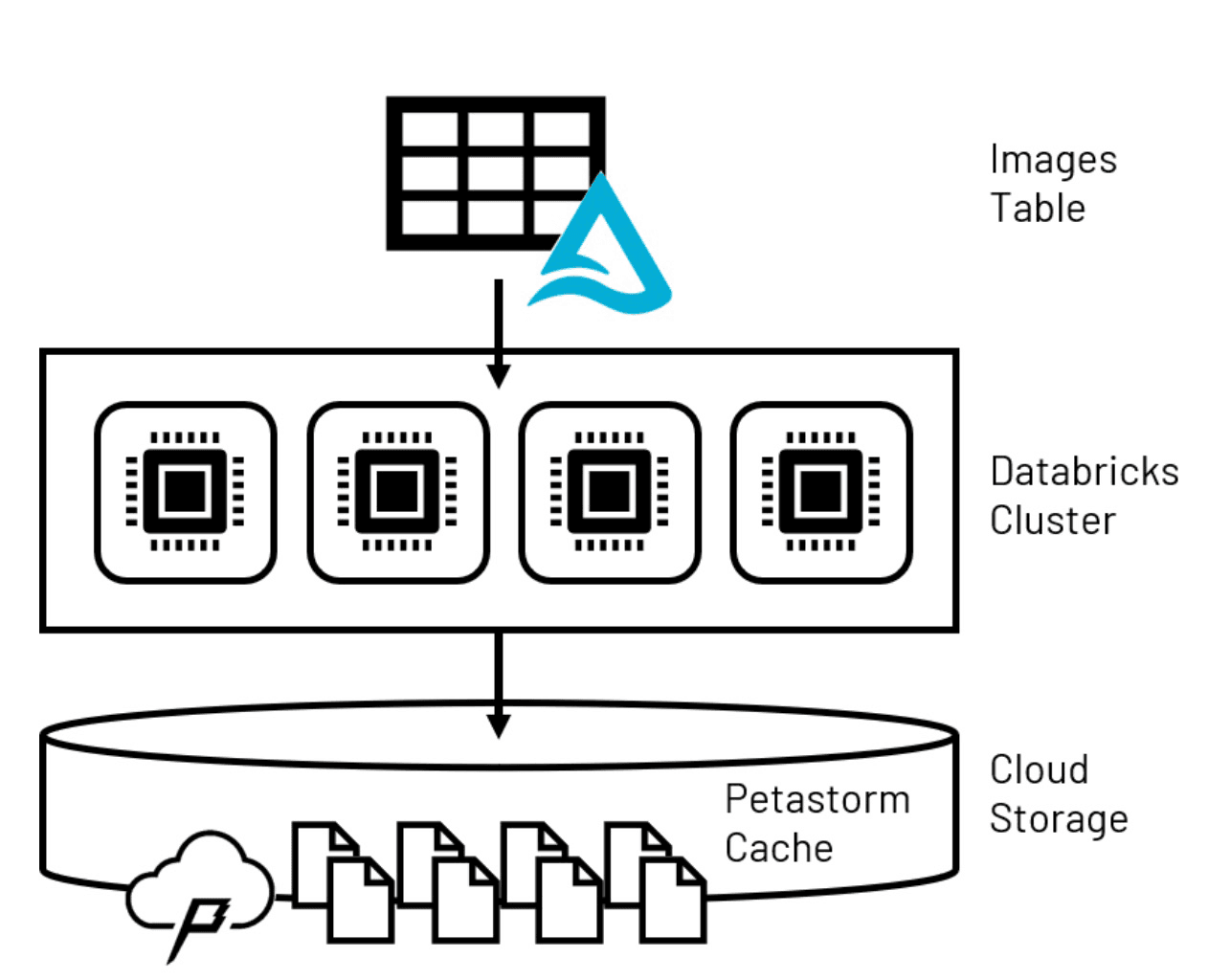
Figure 2. LakehouseのデータをPetastormの一時キャッシュに永続化
データ量が管理できるようになったことで、次の課題はモデル学習自体の高速化である。機械学習モデルは、繰り返し学習します。つまり、学習は、入力データセットに対する一連の繰り返しパスで構成されることになります。この繰り返しによって、予測精度を向上させるための様々な特徴量の最適化された重みが学習されます。
モデルの学習アルゴリズムは、ハイパーパラメーターと呼ばれる一連のパラメーターによって支配されています。このハイパーパラメータの値は、ドメイン知識だけでは設定しにくいことが多いため、最適なハイパー�パラメータ構成を発見するための典型的なパターンは、複数のモデルを訓練して、どのモデルが最も性能が高いかを判断することです。このプロセスはハイパーパラメーターのチューニングと呼ばれ、何度も何度も繰り返されることになる。
これほど多くの反復作業をタイムリーに行うコツは、ハイパーパラメータチューニングの実行をクラスタの計算ノードに分散させ、並行して実行できるようにすることです。Hyperoptを活用することで、これらの実行を波状的に委託することができ、その間にHyperoptソフトウェアは、どのハイパーパラメータ値がどの結果につながるかを評価し、次の波のハイパーパラメータ値をインテリジェントに設定することができます。波が繰り返されると、ソフトウェアが最適なハイパーパラメータ値に収束するまでの時間は、値を網羅的に評価した場合よりもはるかに速くなります。
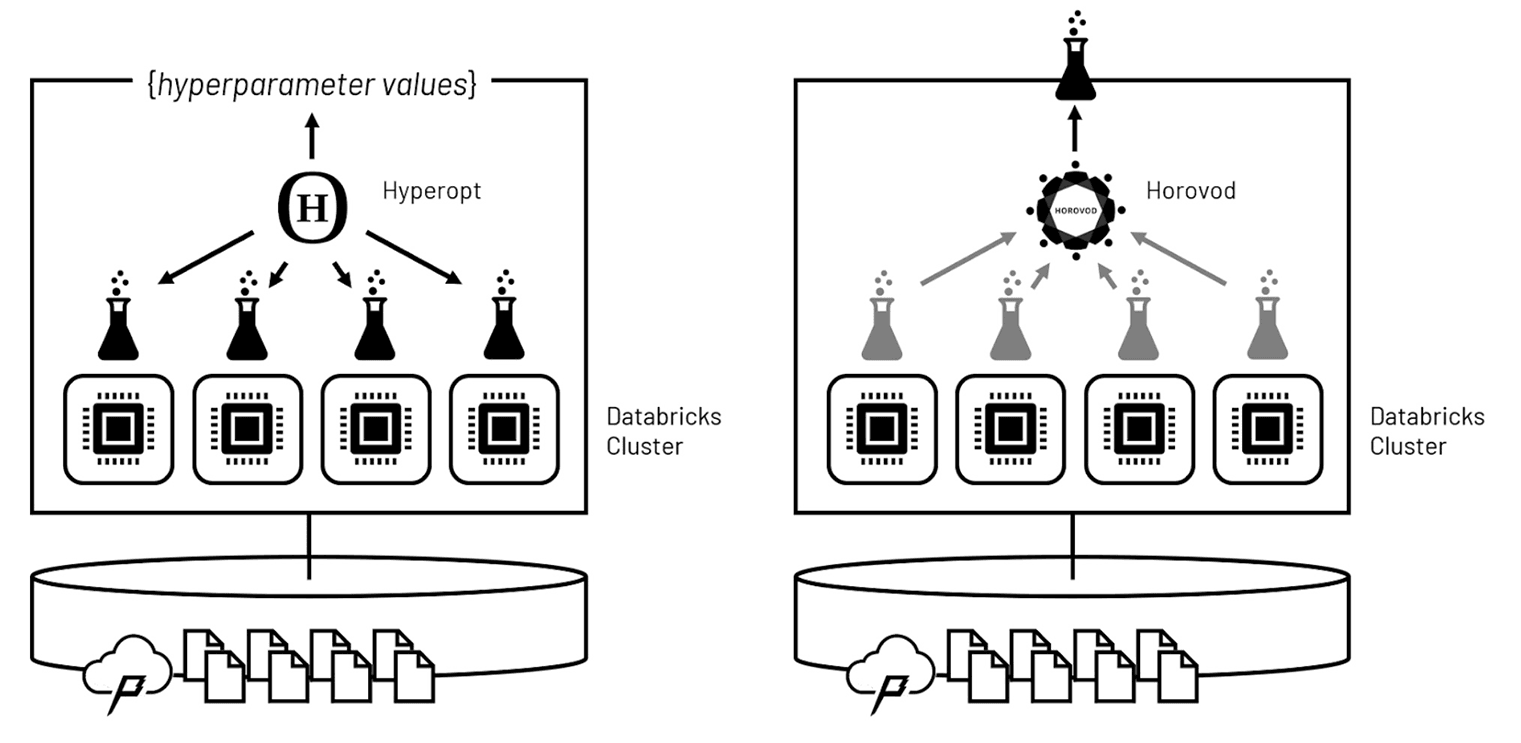
Figure 3. ハイパーパラメータチューニングとモデルトレーニングをそれぞれ分散させるためにHyperoptとHorovodを活用する
最適なハイパーパラメータ値が決定されると、Horovod を使用して、最終モデルのトレーニングをクラスタ全体��に分散させることができます。Horovodは、入力トレーニングデータの重複しないサブセットを使用して、クラスタの各コンピュータノードでモデルの独立したトレーニングを行うよう調整します。これらの並列実行から学習された重みは、全入力セットを通過するたびに統合され、モデルのバランスは集合学習に基づいて調整されます。最終的には、クラスタの計算能力を駆使して最適化されたモデルが作成されます。
Model deployment
コンピュータビジョンモデルでは、通常、人間のオペレーターが目視検査を行う場所に、モデルの予測結果を持ち込むことが目標になります。バックオフィスでの集中的な画像のスコアリングは、シナリオによっては理にかなっているかもしれませんが、より一般的には、ローカル(エッジ)デバイスが、画像をキャプチャし、学習したモデルを呼び出してリアルタイムでスコアリング出力を生成する責任を負うことになるでしょう。モデルの複雑さ、ローカルデバイスの能力、レイテンシやネットワーク障害に対する耐性に応じて、エッジ展開は通常、2つの形態のいずれかをとります。
マイクロサービスの展開では、モデルはネットワークからアクセス可能なサービスとして提供されます。このサービスは、集中管理された場所でホストされることもあれば、エッジデバイスの数とより密接に連携した複数の場所にまたがってホストされることもある。デバイス上で動作するアプリケーションは、画像をサービスに送信し、必要なスコアを受け取るように構成されます。この方法は、アプリケーション開発者にとって、モデルホスティングの柔軟性が高く、エッジデバイスで通常利用できるよりもはるかに多くのリソースをサービスに利用できるという利点がある。しかし、インフラを追加する必要があり、ネットワークの遅延や中断がアプリケーションに影響を与えるリスクがあります。
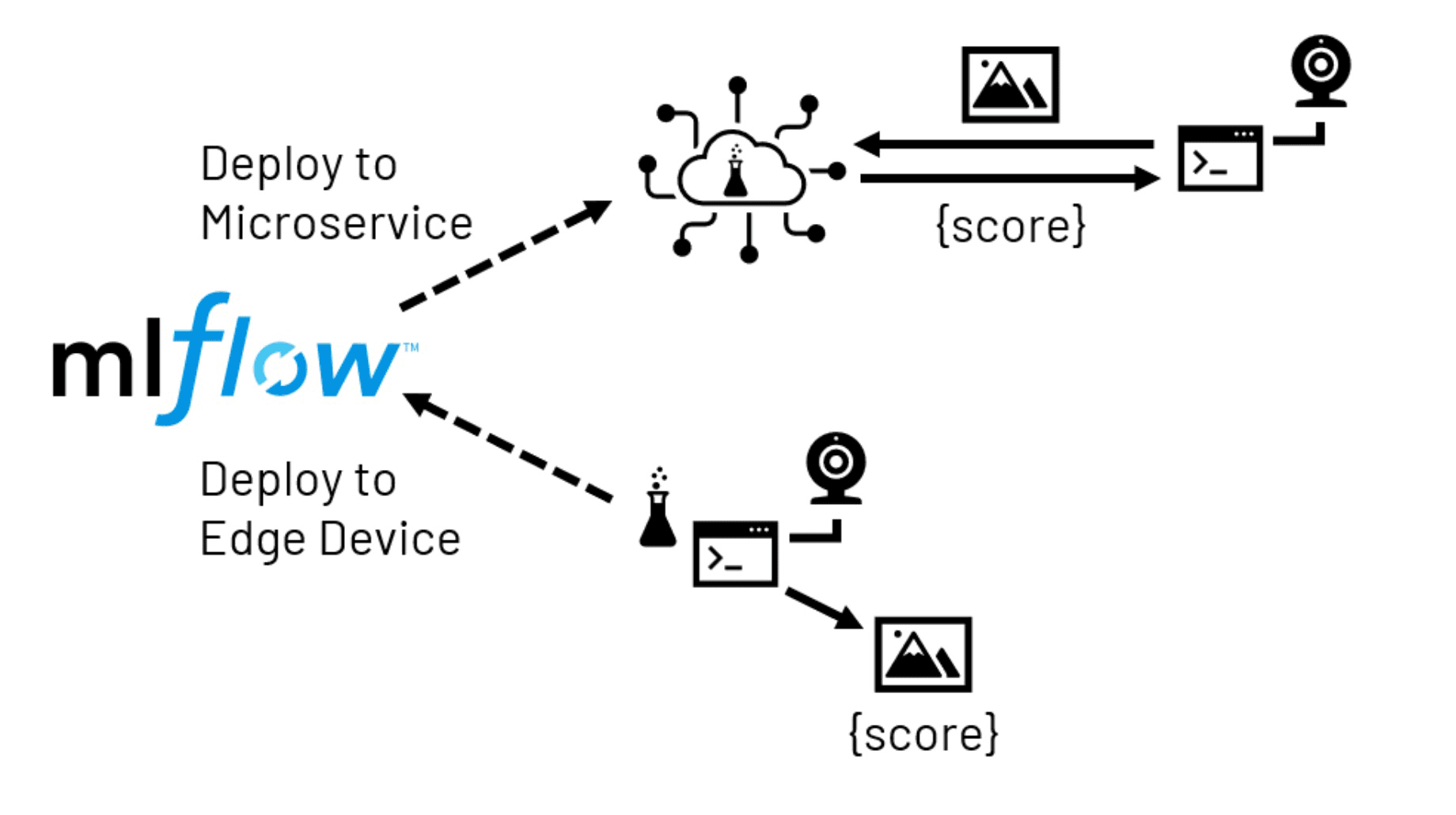
Figure 4. MLflowが促進するエッジ展開パス
エッジデプロイメントでは、事前に学習させたモデルをローカルデバイスに直接送信します。このため、モデルが配信された後のネットワークに関する懸念は解消されますが、デバイスのハードウェアリソースが限られているため、制約が生じる可能性があります。また、多くのエッジデバイスは、モデルを学習させたシステムとは大きく異なるプロセッサーを使用しています。このため、ソフトウェアの互換性に問題が生じる可能性があり、このような展開にリソースを投入する前に、慎重に検討する必要があるかもしれません。
どちらのシナリオでも、モデル管理リポジトリであるMLflowを活用することで、モデルのパッケージングとデリバリーを支援することができます。
Databricksですべてをまとめ上げる
このような様々な課題を解決するために、 PiCameraを搭載したRaspberry Pi device.から取得したデータを利用した一連のノートブックを開発しました。このデバイスで撮影された画像は、クラウドストレージ環境に送信され、これらの画像取り込み、モデル学習、展開のパターンを、上記のすべての機能があらかじめ設定されているDatabricks ML Runtimeを使用して実証することができるようになりました。このデモの詳細については、以下のノートブックを参照してください:
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。