レイクハウスで顧客生涯価値を見積もる
によって Samaya Madhavan, Div Saini 、 ブライアン・スミス(Bryan Smith) による投稿
翻訳:Junichi Maruyama. - Original Blog Link
スニル・グプタ博士は『Driving Digital Strategy』の中で、「20%の顧客が利益の200%を占めている」と指摘している。この数字が意味するところは、一部の顧客は、その顧客から得られる利益よりも、それ以上にコストがかかっているということである。正確な比率はビジネスによって異なるかもしれないが、小売企業や消費財企業は、価値の高い顧客を特定し、その顧客と長期的な関係を築き、そのような顧客を増やす一方で、リターンが見込めない顧客への投資を抑えることが極めて重要である。
課題は、特定の顧客の潜在的な収益性が常にわかっているわけではないということである。非サブスクリプション・モデルでは、顧客の出入りは自由であるため、ある瞬間にはハイパフォーマンスな顧客としての可能性を示し、次の瞬間には姿を消して二度と戻ってこないかもしれない。しかし、全体として見れば、顧客の取引に関連する頻度、頻度、金額(消費額)には比較的予測可能なパターンがあり、顧客の意図を明確に表すことができる。そしてこれらから、当社にとっての顧客の長期的(生涯)価値を確率的に推定することができる。(図1)
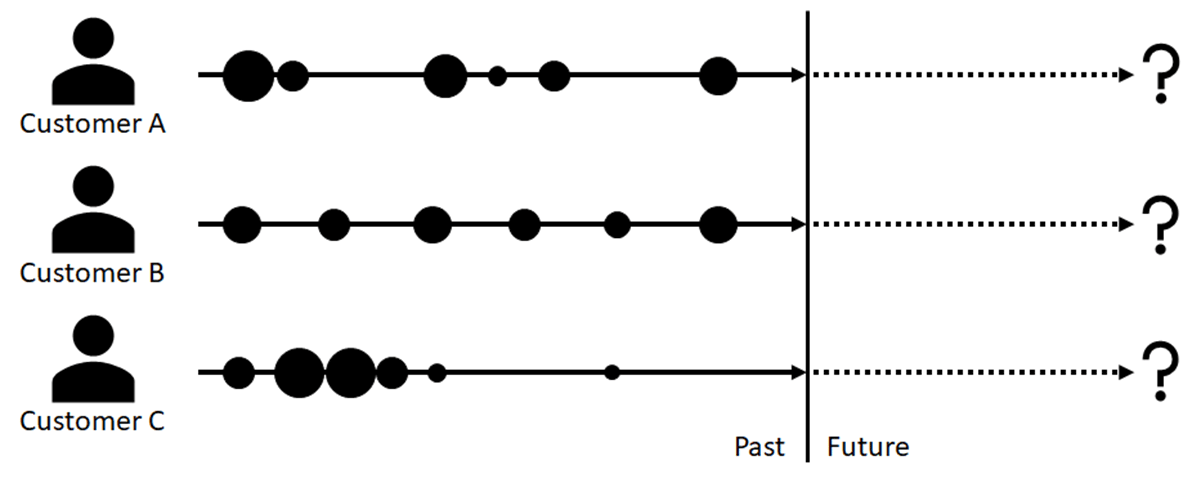
なぜ顧客生涯価値が重要なのか?
顧客生涯価値(CLV)は、現代のマーケティングにおける基礎指標です。メンズファッション、クラフトスピリッツ、ライドシェアサービスのいずれを販売しているかにかかわらず、顧客による将来の支出の正味現在価値は、顧客維持への投資の指針となり、全体的なマーケティング効果の測定基準を提供します。個人レベルで計算すると、CLVは、最良の顧客と最悪の顧客を分け、その中間のすべての顧客を位置づけるのに役立ちます。
このように、さまざまな顧客の異なる可能性を認識することは、彼らの個人的な嗜好を理解することと相まって、効果的なパーソナライゼーションの基礎となります。2019年の調査では、小売、旅行、ホスピタリティ業界のシニアマーケター600人を対象に、パーソナライゼーションから最高のROIを報告している企業は、低いリターンを達成している企業に比べ、主要なビジネス目標として顧客生涯価値を挙げる傾向が2倍ありました。パンデミックによってオンラインでの動きが活発化す�る中、効果的なパーソナライゼーションの重要性は増すばかりで、顧客生涯価値指標を導き出すために投資する組織がますます増えています。
顧客生涯価値の促進
顧客生涯価値は、正しく理解するのが難しい指標です。最も単純なCLVの公式は、平均年間収益(または利益)に平均顧客寿命を掛け合わせ、典型的な顧客から得られる可能性のある利益または収益の合計を算出します。このような単純な平均値で動作するCLVの公式は、CLVを推進する2つの重要なレバー、すなわち顧客寿命と顧客支出を方向付けるのには役立ちますが、長いスパンでの顧客の可能性を正確に見積もることはできません。
現代のCLV推定の父と多くの人に考えられているピーター・フェイダーによる楽しいプレゼンテーションをご覧になったことがある方は、顧客エンゲージメントが(シャレではなく)時間とともに小さくなり、個々の消費パターンが歪んだ曲線(図2)をたどる傾向があることを知っています。
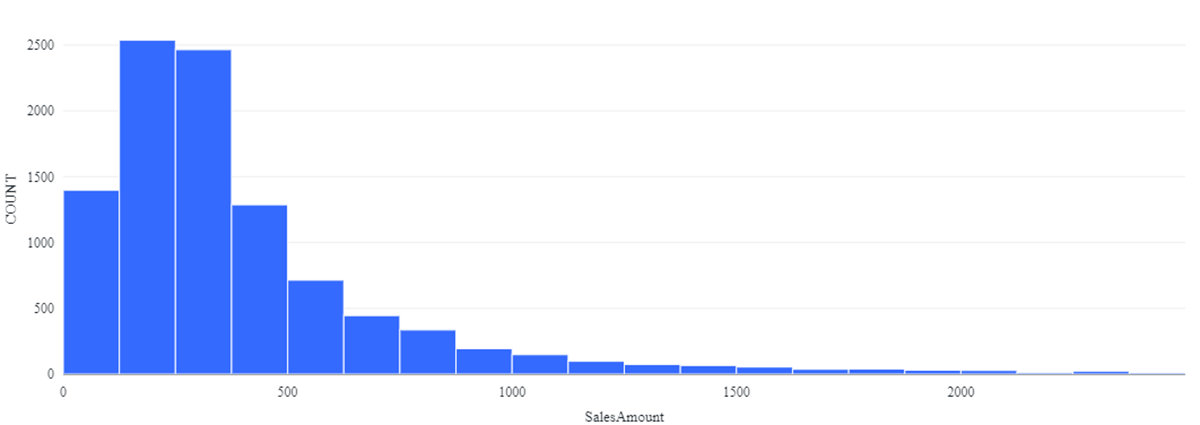
CLVを適切に見積もるためには、このような歪んだ劣化パターンを考慮しなければなりません。これは、2000年代半ばに普及したBuy 'til You Die(BTYD)モデルによってエレガントに対処されたものです。数学は非常に複雑ですが、その中のロジックは、ビジネスアナリストやデータサイエンティストにとってはるかに利用しやすい、人気のある一連のプログラミングライブラリによってうまく捉えられています。
CLVを企業にもたらす
これらのライブラリーを使用することで、個別化CLVの適切な計算ははるかに容易になるが、克服しなければならない技術的なハードルがいくつか残っている。その最たるものが、BTYDモデルで必要とされる単純な入力指標、すなわち、顧客ごとの反復性、頻度、期間、および金銭的価値の導出である。これらのメトリクスの計算は非常に簡単ですが、長期的な顧客との取引履歴からこれらのメトリクスを導き出すには、多くの場合、非常に大規模なデータセットを計算する必要があります。これは、拡張性の高いデータ処理機能を持つDatabricks Lakehouseプラットフォームが理想的に取り組むべき課題です。
データをレイクハウスに置くことで、企業はビジネスアナリストが従来のデータウェアハウスと同じようにデータを探索できるようになります。また、組織が顧客生涯価値(Customer Lifetime Value)の推定やその他の予測業務に軸足を移したい場合、データサイエンティストはデータを複製することなく、その業務にシステムを活用することができる。販売トランザクションのような重要なデータセットの場合、これによって組織の価値実現までの時間が短縮される。また、顧客情報のようなセンシティブな情報が関係するシナリオでは、レプリケーションがな��いことで、より簡単で一貫性のある安全なデータガバナンスが実現する。
しかし、レイクハウスのデータ管理上の利点だけでなく、Databricksはこのようなモデル開発シナリオにおいてもさらなる利点を提供します。顧客に関する新しい情報が入ってきたときに、生涯価値を再推定するために、トレーニングされたCLVモデルを採用する方法を考えてみましょう。Databricks は、モデル管理とデプロイメントのための設定済み機能を使用することで、MLOps チームがこれらのモデルをバッチや ストリーミング ETL ワークフロー内で迅速に取得し、デプロイすることを可能にします。
これがどのように行われるかをご覧になりたいですか?メトリクスを導き出し、必要なモデルをトレーニングし、ワークフローに導入する方法を示す詳細なコードを含む、無料のCLV推定ソリューションアクセラレータをこちらからダウンロードしてください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。