バージョンレス Apache Spark™ の考察: AI によるアップグレードと、20億のワークロードを支えるシームレスな安定性
プラットフォームから手動でのSparkアップグレードを排除した方法
によって Justin Breese, ヴィジャヤン プラバカラン, アミット・シュクラ, マーティン・グルンド, ステファニア・レオーネ, クリス・マンソン, Tatiana Romanova 、 レナート・カッツ による投稿
- バージョンレスのサーバーレス ノートブックとジョブでは、Apache Spark™ のアップグレードが自動化され、移行やコードの変更が��不要になります。
- 安定したクライアント API と AI を活用したリリース管理により、最新の機能や修正を提供しつつ、ワークロードの信頼性を維持します。
- 99.99% の成功率で 20 億以上のワークロードがアップグレードされており、このシステムが大規模環境でも有効に機能することを証明しています。
Apache Spark™ のアップグレードは、決して簡単なことではありませんでした。すべてのメジャーバージョンでパフォーマンスの向上、バグ修正、新機能が提供されますが、その過程は大変な作業です。ほとんどの Spark ユーザーにはお馴染みのことでしょう。ワークロードの失敗や API の変更が発生すると、開発者は遅れを取り戻すためだけに、ジョブの修正に数週間を費やす可能性があります。この結果、新機能、パフォーマンスの改善、バグやセキュリティの修正の導入に、大幅に長い時間がかかることになります。
Databricksでは、このような煩わしさを完全になくしたいと考えていました。その結果生まれたのが Versionless Spark です。継続的なアップグレード、コード変更ゼロ、比類のない安定性を実現する、Spark の新しい実行方法です。過去18か月にわたり、サーバーレスノートブックとジョブの提供を開始して以来、バージョンレス Sparkは、25のDatabricks Runtimeリリースにわたって、主要なSparkバージョンを含む20億以上のSparkワークロードを、ユーザーの介入なしに自動的にアップグレードし��てきました。
このブログでは、バージョンレスのSparkを構築した方法、これまでに得られた結果のハイライト、そして最近公開されたSIGMOD 2025の論文で詳細情報を確認できる場所についてご紹介します。
新たなアプローチ: バージョン管理されたクライアントによる安定したパブリック API
アップグレードをシームレスにし、Databricks ユーザーの時間を節約するためには、サーバーをシームレスに更新できるよう、安定したパブリックな Spark API が必要でした。これを実現したのが、Spark Connect をベースとする安定したバージョン管理クライアント API です。この API がクライアントと Spark サーバーを分離することで、Databricks はサーバーを自動的にアップグレードできます。
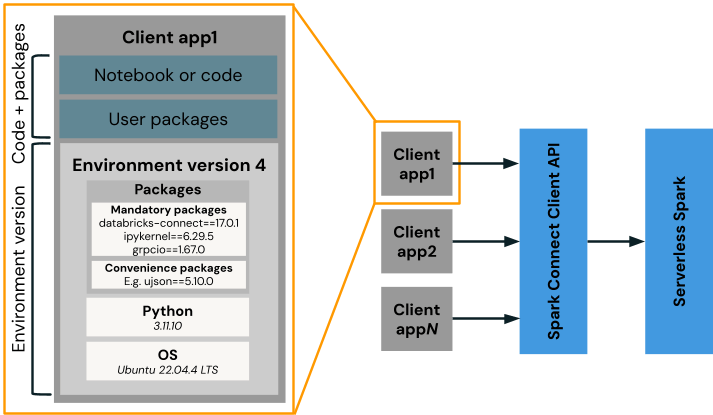
Databricks 環境バージョンは、Spark Connect、Python、pip の依存関係などのクライアントパッケージを含むベースイメージとして機能します。ユーザーコードおよび追加パッケージは、この環境上で実行されます(例:クライアントアプリ1) で、当社のサーバーレス Spark サービス��と通信します。DatabricksはDBR LTSと同様に、定期的に新しい環境バージョンをリリースしており、それぞれに3年間のサポートが付いています。デフォルトでは、新しいワークロードは最新バージョンを使用しますが、ユーザーが希望する場合は、サポートされている古いバージョンで実行し続けることもできます。
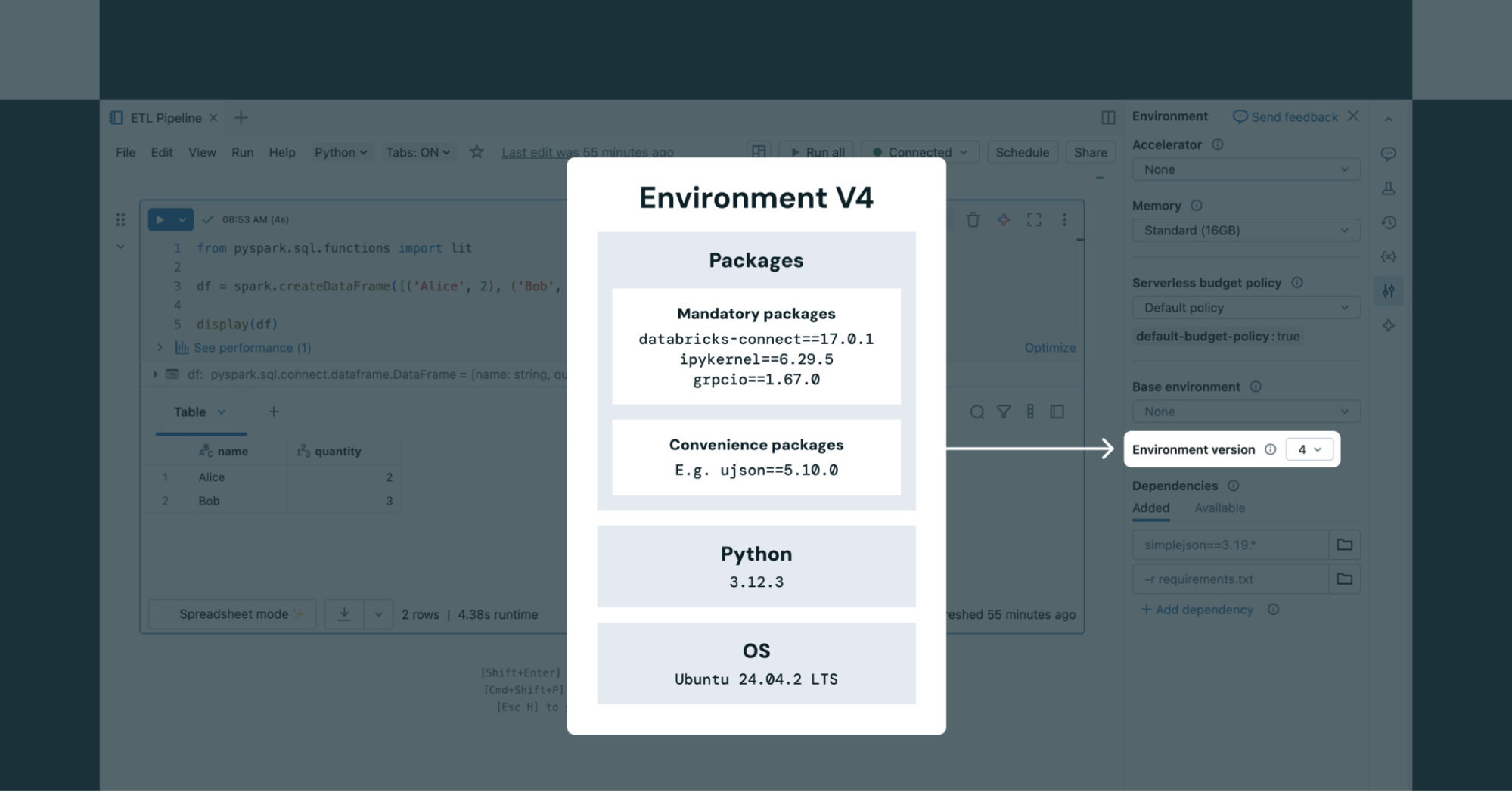
サーバーレスノートブックを使用する場合、ユーザーはノートブックの [環境] パネルで、サポートされている任意の環境バージョンを選択できます (図 2 を参照)。サーバーレスジョブの場合、環境バージョンは Job API 経由で定義されます。
自動アップグレードと AI を活用したロールバック
Databricksで自動化されたワークロードを実行する際に、ユーザーに頻繁なセキュリティ、信頼性、パフォーマンスのアップデートを提供することは不可欠です。これは、特に本番環境のパイプラインの安定性を損なうことなく、自動的に行う必要があります。これは、AI を活用したリリース安定性システム (RSS) によって実現さ�れます。RSS は、自動化されたワークロードの固有のフィンガープリントと実行メタデータを組み合わせ、新しいサーバーバージョンでリグレッションが発生したワークロードを検出すると、後続の実行を自動的に以前のサーバーバージョンに差し戻します。RSS は、いくつかのコンポーネントで構成されています。
- 各ワークロードは、一連のプロパティに基づいて同じワークロードの繰り返し実行を特定するためのワークロードフィンガープリントを持っています。
- 過去の実行では、以前の実行に関するメタデータを保持します
- Pinning service は、2 つの異なるサーバーバージョンで異なる動作をするワークロードを追跡します。
- ML モデルがエラーの分類、チケットのトリアージ、フリート内の異常検出を行います。
- 異常検知パイプラインはフリート全体で実行されます。
- リリースのヘルスレポートとアラートは、Databricks のエンジニアリングチームにリアルタイムでリリースのヘルス情報を提供します。

自動ロールバックにより、リグレッションが発生した後でも、ワークロードは正常に実行され続けます。
RSSが自動化ジョブでロールバックを実行すると、ワークロードは以前に成功したことが確認されている最後のバージョンで自動的に再実行されます。RSS について、実際の例を使って説明しましょう。ある特定の自動化ジョブが、4月9日に DBR バージョン 16.1.2 を使用して実行されました。エラーが発生しました。過去の実行履歴は、ワークロードが16.1.1上で数日間連続で成功していたことを示していました。MLモデルは、そのエラーがバグによって引き起こされた可能性が高いと判断しました。その結果、ピニングサービスにピニングエントリが自動的に作成されました。ワークロードの自動リトライが(この場合は)開始されると、ピニングサービスのエントリが検出され、ワークロードは16.1.1で再実行されました。そして成功しました。これにより、自動トリアージプロセスが実現し、Databricksのエンジニアリングチームがアラートを受けてバグを特定し、修正をリリースするようになりました。その間、後続のワークロードの実行は16.1.1に固定されたままでした。16.1.3でバグ修正がロールアウトされるまでそしてワークロードは最終的に 16.1.3 にリリースされました。(青いボックス)正常に実行され続けました。
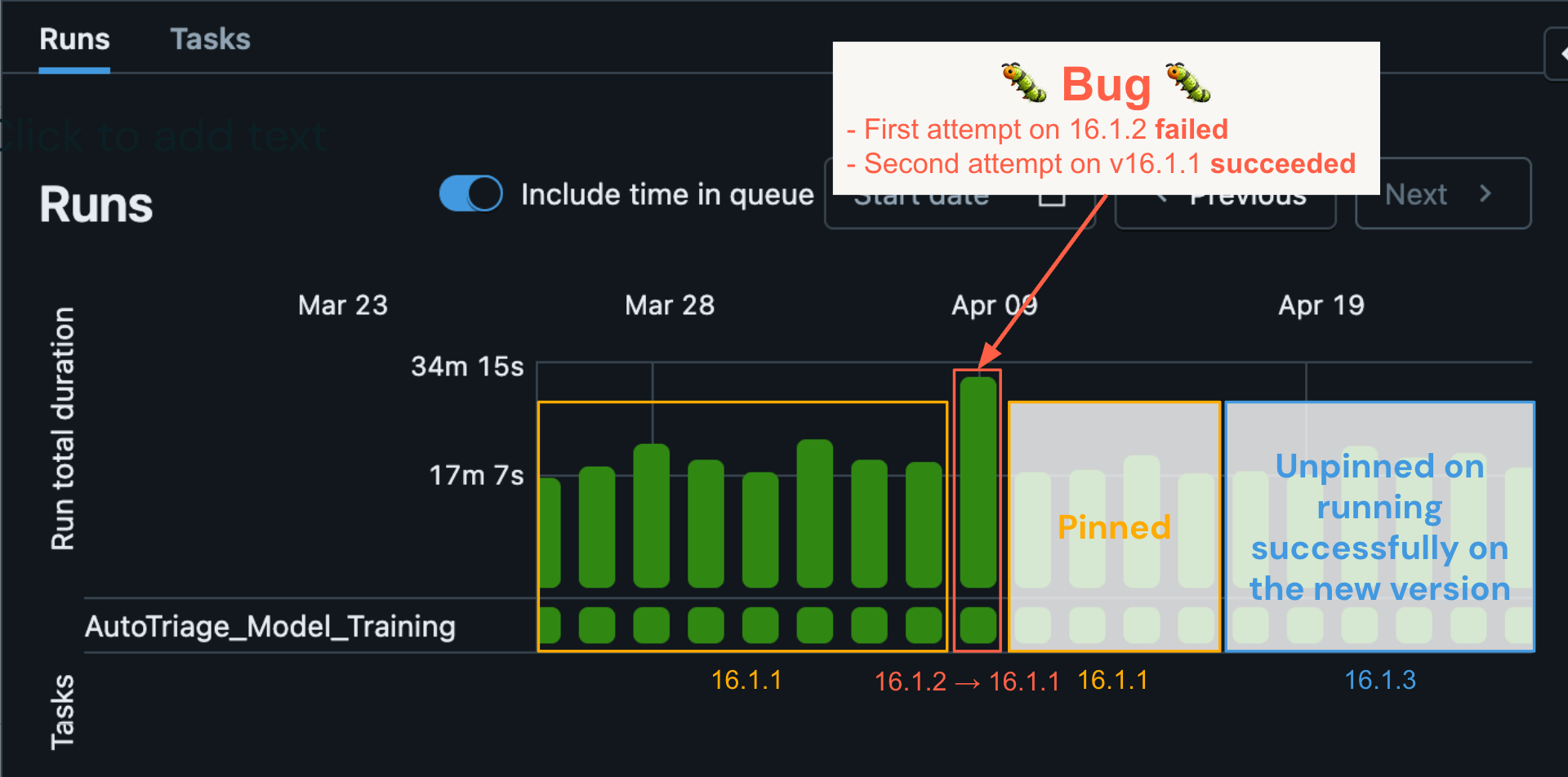
このケースでは、顧客の信頼性に影響を与えることなく、少数の顧客ワークロードにのみ影響する非常に巧妙なバグを迅速に検出して修正することができました。これを、ユーザーが手動でアップグレードする必要があり、通常は大幅な遅延を伴う従来の Spark アップグレードモデルと比較してみてください。ユーザーがアップグレードを実行するとジョブが失敗し始め、問題を解決するためにサポートチケッ��トを申請しなければならなくなる可能性があります。このような問題の解決には、より長い時間がかかる可能性が高く、最終的にはお客様にさらにご協力いただく必要があり、信頼性も低下します。
まとめ
リリース安定性システムを使用して、DBR 14 から DBR 17 へと、20 億以上のジョブをアップグレードしました (これには Spark 4 への移行も含まれます)。この間、照合順序、ブルームフィルター結合最適化、JDBC ドライバーといった新機能をシームレスに提供しています。そのうち、自動ロールバックを必要としたジョブはわずか0.000006%でした。また、すべてのロールバックは修正によって対応され、平均12日以内に最新バージョンへのアップグレードに成功しました。この成果は、ユーザーによるコード変更を一切必要とせずに、何十億もの本番環境の Spark ワークロードを自動的にアップグレードするという、業界初の快挙です。
環境のバージョニング、自動アップグレードされるバージョンレスサーバー、そしてリリース安定性システムを組み合わせた新しいアーキテクチャを構築することで、Sparkのアップグレードを完全にシームレスにしました。この業界初のアプローチにより、Databricks は機能や修正をより迅速かつ高い安定性でユーザーに提供できるようになり、データチームはインフラストラクチャのメンテナンスよりも価値の高いビジネス成果に集中できるようになりました。
この取り組みはまだ始まったばかりです。今後、UX をさらに改善していくことを楽しみにしています。
次のステップ
- SIGMOD 2025 の、このトピックに関する詳細な 論文 をぜひご覧ください。
- ノートブックとジョブ向けサーバーレスコンピューティングの当初の GA 発表
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。