指示付きリトリーバー:検索エージェントにおけるシステムレベルの推論能力を解放
によって データブリックス AI 研究チーム による投稿
検索ベースのエージェントは、多くのミッションクリティカルなエンタープライズのユースケースの中心にあります。エンタープライズのお客様は、特定のユーザー指示に従い、異種のナレッジソースにわたって効果的に機能する推論タスクの実行を期待しています。しかし、従来の検索拡張生成(RAG)は、きめ細かなユーザーの意図やナレッジソースの仕様を正確な検索クエリーに変換できないことが少なくありません。既存のソリューションのほとんどは、既製の検索ツールを採用することでこの問題を事実上無視しています。また、表現力に根本的な限界がある埋め込みや再ランキングのためだけのカスタムモデルに依存し、課題を大幅に過小評価しているものもあります。このブログでは、RAGの限界に対処し、エージェント時代の検索を再構築する新しい検索アーキテクチャであるInstructed Retrieverを紹介します。そして、このアーキテクチャが、複雑なエンタープライズデータを推論し、ユーザーの指示を厳密に守る必要があるAgent Bricks: Knowledge Assistantのようなシステムを含む、より高性能な検索ベースのエージェントをいかにして実現するかを説明します。
例えば、図 1 の例を考えてみましょう。架空の FooBrand 製品のバッテリー寿命についてユーザーが質問しています�。さらに、システム仕様には、最新性、考慮すべきドキュメントの種類、回答の長さに関する指示が含まれています。システム仕様に適切に従うために、ユーザーのリクエストはまず、キーワードに加えて適切な列フィルターを含む構造化された検索クエリーに変換される必要があります。次に、ユーザーの指示に基づいて、クエリー結果に基づいた簡潔な回答を生成する必要があります。このような複雑で意図的な指示への準拠は、ユーザーのクエリーのみに焦点を当てた単純な検索パイプラインでは実現できません。
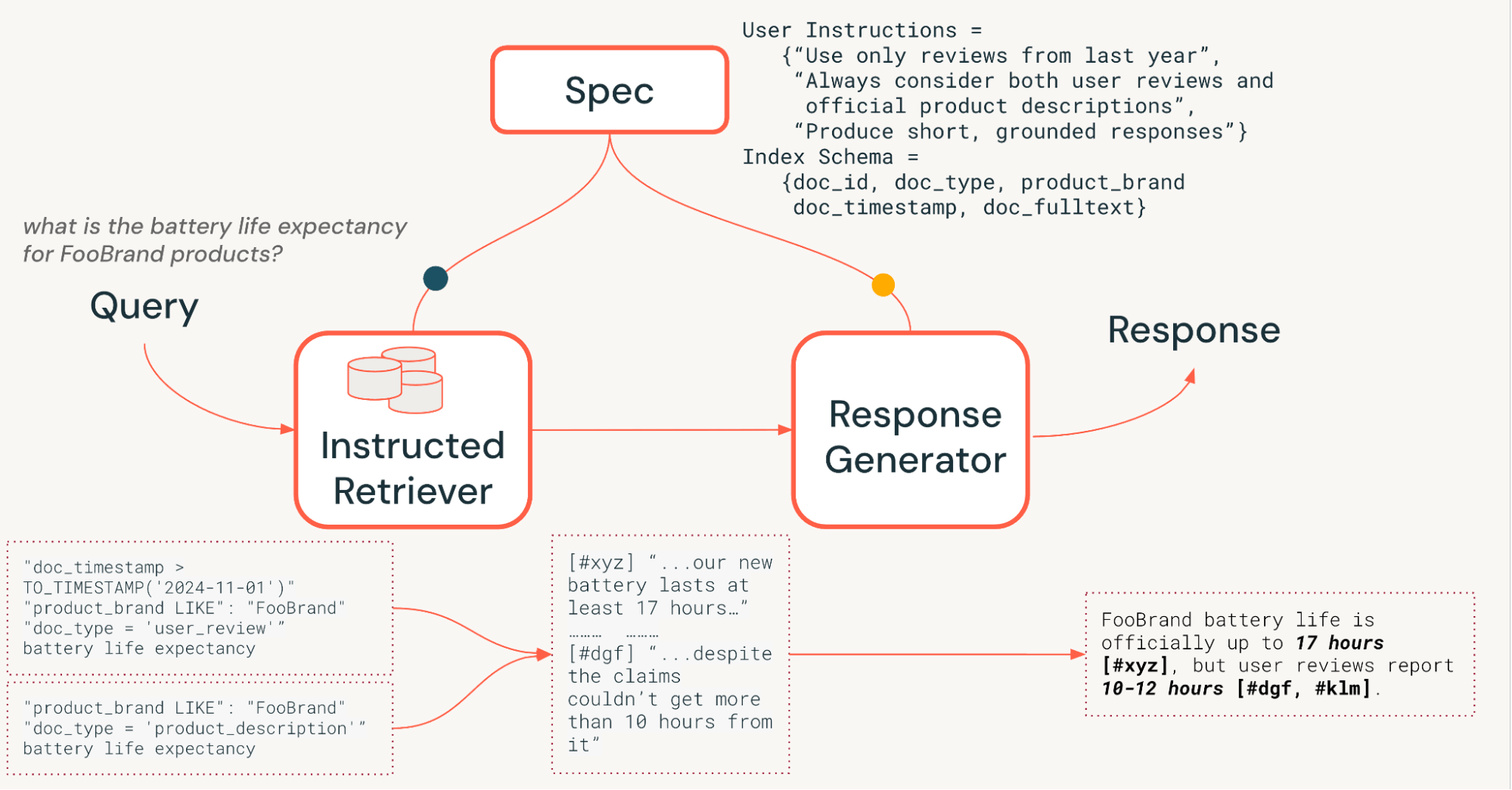
従来のRAGパイプラインは、ユーザーのクエリーのみを使用したシングルステップの検索に依存しており、特定の指��示、例、ナレッジソースのスキーマといった追加のシステム仕様を組み込んでいません。しかし、図1で示すように、これらの仕様はエージェント検索システムで指示に正しく従うための鍵となります。これらの制限に対処し、図1で説明したようなタスクを正常に完了させるために、当社のInstructed Retrieverアーキテクチャは、システム仕様を各システムコンポーネントに流し込むことを可能にします。
表1が示すように、RAGの枠を超えて、反復的な検索実行を可能にするより高度なエージェント検索システムにおいても、指示への準拠や基盤となるナレッジソースのスキーマの理解は、複数ステップのツールとしてRAGを実行するだけでは実現できない重要な能力です。したがって、Instructed Retrieverアーキテクチャは、低レイテンシと小さなモデルフットプリントが求められる場合にRAGに代わる高性能な代替手段を提供すると同時に、詳細な調査のようなシナリオに向けてより効果的な検索エージェントを実現します。
検索拡張生成(RAG) | Instructed Retriever | マルチステップ エージェント(RAG) | 複数ステップ エージェント(指示付きリトリーバー) | |
検索ステップ数 | シングル | シングル | 複数 | 複数 |
指示に従う能力 | ✖️ | ✅ | ✖️ | ✅ |
ナレッジソースの理解 | ✖️ | ✅ | ✖️ | ✅ |
低レイテンシ | ✅ | ✅ | ✖️ | ✖️ |
小さいモデル フットプリント | ✅ | ✅ | ✖️ | ✖️ |
出力に関する推論 | ✖️ | ✖️ | ✅ | ✅ |
表 1.従来の RAG、Instructed Retriever、およびいずれかのアプローチをツールとして使用して実装されたマルチステップ検索エージェントの機能の概要
Instructed Retrieverの利点を実証するため、図2では、一連のエンタープライズ向け質問応答データセット1において、RAGベースのベースラインと比較したパフォーマンスを紹介しています。これらの複雑なベンチマークにおいて、Instructed Retrieverは従来のRAGと比較してパフォーマンスを70%以上向上させます。インストラクテッド・リトリーバーは、RAGベースのマルチステップエージェントの性能を10%も上回ります。これをマルチステップエージェントのツールとして組み込むと、RAGと比較して実行ステップ数が削減され、パフォーマンスがさらに向上します。
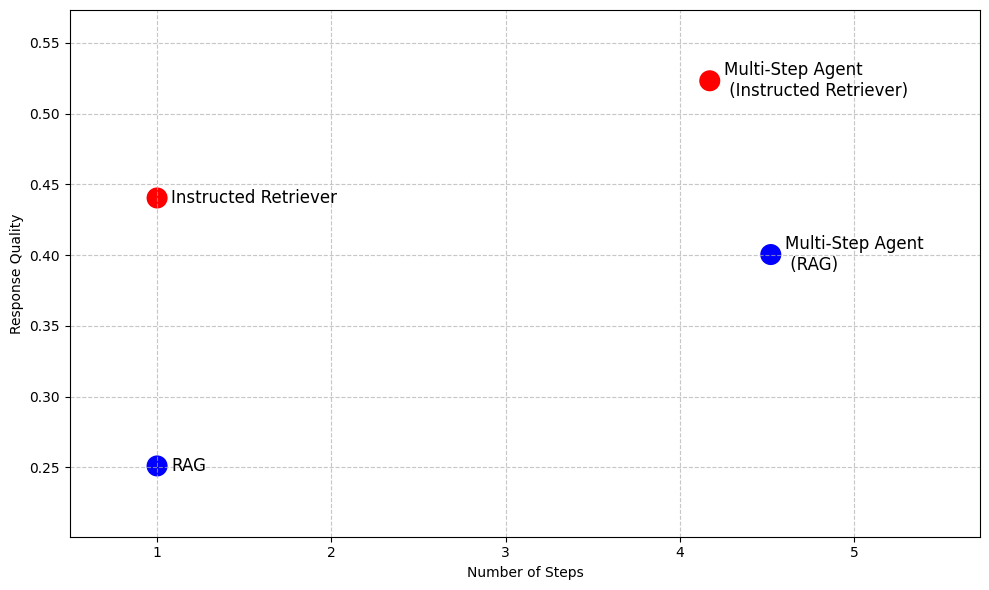
このブログ記事の残りの部分では、この新しい Instructed Retriever アーキテクチャの設計と実装について説明します。Instructed Retriever が、クエリー生成の段階で正確かつ堅牢に指示に従うようになり、その結果、検索再現率が大幅に向上することを実証します。さらに、オフライン強化学習を通じて、小規模なモデルでもこれらのクエリー生成能力を引き出せることを示します。最後に、シングルステップとマルチステップの両方のエージェント設定において、Instructed Retriever のエンドツーエンドのパフォーマンスをさらに詳しく分析します。Instructed Retriever が、従来の RAG アーキテクチャと比較して、応答品質を一貫して大幅に向上させることを示します。
Instructed Retriever Architecture
エージェント検索システムにおけるシステムレベルの推論の課題に対処するため、図3に示す、新しいInstructed Retrieverアーキテクチャを提案します。Instructed Retrieverは、静的なワークフローで呼び出すことも、エージェントのツールとして公開することもできます。主な革新点は、この新しいアーキテクチャが、ユーザーの当面のクエリーに対応するだけでなく、システム仕様の全体を検索と生成の両方のシステムコンポーネントに��伝播させるための合理化された方法を提供することです。これは、従来のRAGパイプラインからの根本的な転換です。従来のパイプラインでは、システム仕様は(よくても)最初のクエリーに影響を与えるかもしれませんが、その後は失われ、リトリーバーと応答ジェネレーターは、これらの仕様という重要なコンテキストなしで動作せざるを得なくなります。
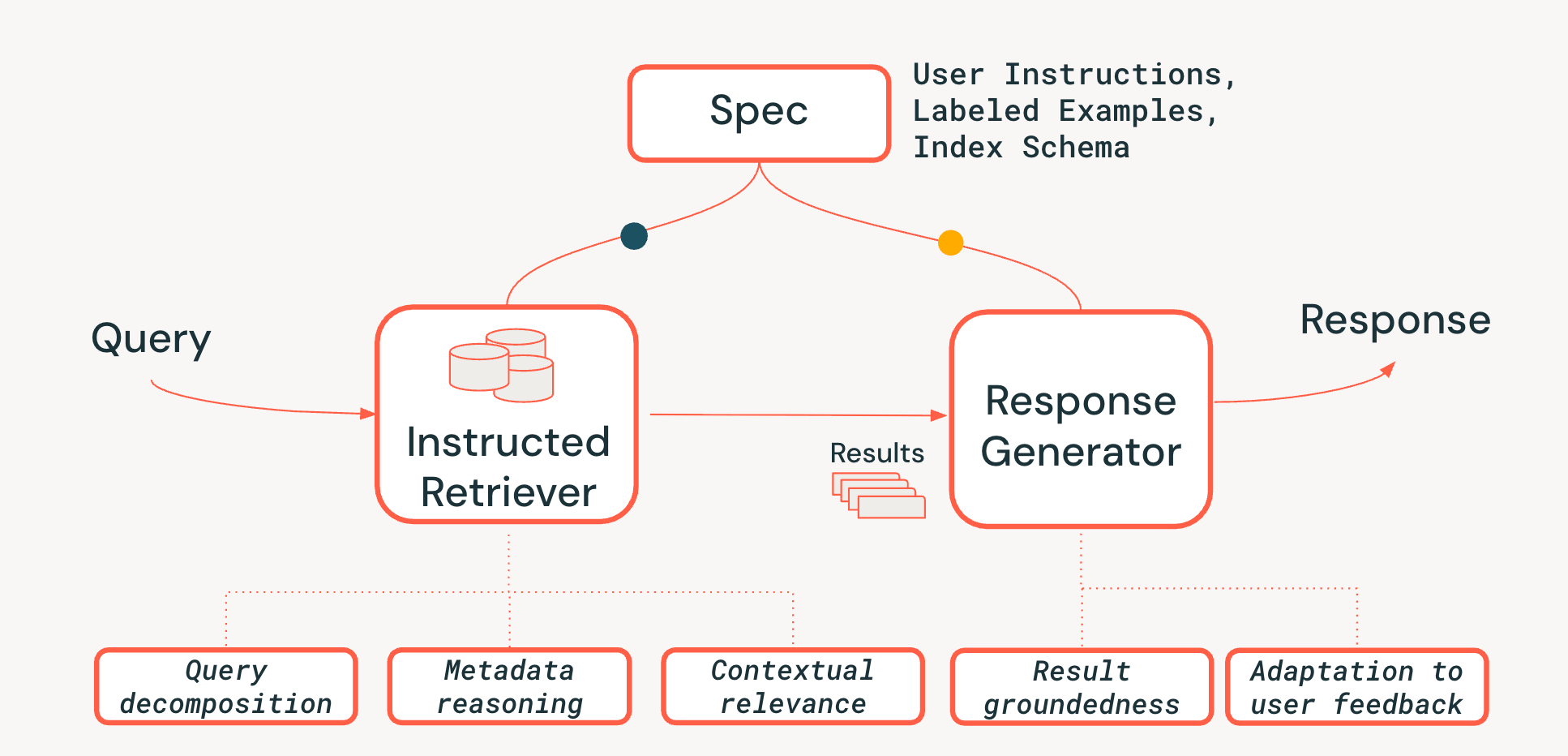
したがって、システム仕様とは、ユーザーのリクエストを忠実に実行するためにエージェントが従うべき一連の指針と指示であり、次のようなものが含まれます。
- ユーザー指示:「ここ数年のレビューに焦点を当てる」や「結果に FooBrand の製品を表示しない」といった、全般的な設定や制約。
- ラベル付きの例: 特定のタスクに対して、高品質で指示に従った検索がどのようなものかを定義するのに役立つ、関連性のある/関連性のない <クエリー, ドキュメント> のペアの具体的なサンプルです。
- インデックスの説明: 取得元として実際に利用可能なメタデータをエージェントに伝えるスキーマ(例: 図 1 の例では product_brand、doc_timestamp)。2
パイプライン全体にわたって仕様の永続性を実現するために、検索プロセスに 3 つの重要な機能を追加します。
- クエリ分解: 複雑で複数のパートからなるリクエスト(「 FooBrand 製品を探して。ただし、昨年発売されたもので、「lite」モデルは除外して 」)を、複数のキーワード検索とフィルター指示を含む完全な検索プランに分解する能力。
- 文脈上の関連性:単純なテキストの類似性を超えて、クエリーとシステムの指示という文脈における真の関連性を理解すること。これは、例えば、リランカーが指示を使用して、キーワードの一致度が低い場合でも、ユーザーの意図(例: "鮮度")に合致するドキュメントをブーストできることを意味します。
- メタデータ推論: 当社の Instructed Retriever アーキテクチャの主な差別化要因の 1 つは、自然言語の指示(「 昨年から 」)を、正確で実行可能な検索フィルタ("doc_timestamp > TO_TIMESTAMP('2024-11-01')" )に変換する能力です。
また、応答生成ステージが、取得した結果、システム仕様、過去のユーザー履歴やフィードバックと一致するようにします(詳しくはこちらのブログで説明しています)。
検索エージェントが指示を遵守するのは困難です。なぜなら、ユーザーが求める情報は 複雑、曖昧、あるいは矛盾している 場合があり、それらはしばしば 自然言語によるフィードバック を何度も繰り返すことで蓄積されるからです。また、リトリーバーは スキーマを認識 できなければなりません。つまり、ユーザーの言葉を、インデックスに実際に存在する構造化されたフィルター、フィールド、メタデータに変換できる必要があります。最後に、各コンポーネントは、これらの複雑で時には多層的な制約を一つも見落としたり誤解したりすることなく満たすために、シームレスに連携する必要があります。このような連携には、システムレベルでの全体的な推論が求められます。次の 2 つのセクションでのエクスペリメントが示すように、Instructed Retriever アーキテクチャは、検索ワークフローやエージェントにおいてこの能力を解放するための大きな進歩です。
クエリー生成における指示追従の評価
既存の検索ベンチマークのほとんどは、モデルが自然言語の仕様(特にインデックス スキーマに基づく構造化された制約を含むもの)をどのように解釈し、実行するかを見過ごしています。そこで、当社の Instructed Retriever アーキテクチャの能力を評価するために、 StaRK (Semi-Structured Retrieval Benchmark)データセットを拡張し、その e コマース サブセットである STaRK-Amazon を使用して、新たな指示追従型検索ベンチマークである StaRK-Instruct を設計しました。
このデータセットでは、単純なテキストの類似性を超えた推論をモデルに要求する、一般的な 3 種類のユーザー指示に焦点を当てています。
- 包含指示 – 特定の属性を必ず含むドキュメントを選択すること(例: 「寒い天候で最も評価の高い FooBrand のジャケットを見つける」)。
- 除外指示 – 結果に表示 されるべきではない 項目を除外すること(例: 「 燃費の良い SUV をおすすめして。でも FooBrand には嫌な経験があるから、そのメーカーのものは避けて 」)。
- 新規性ブースティング – 時間関連のメタデ�ータが利用可能な場合に、より新しい項目を優先します(例: 「どの FooBrand のノートパソコンが長く使っても良い評価を得ていますか?OS の変更により古いレビューはあまり参考にならないため、過去 2~3 年のレビューを優先してください」)。
StaRK-Instruct を構築するにあたり、StaRK-Amazon の既存の適合性判断を再利用しつつ、情報検索における指示追従に関する先行研究にならい、既存の適合性の定義を絞り込む追加の制約を含めることで、既存のクエリをより具体的なものに合成します。その後、関連文書セットはプログラムによってフィルタリングされ、書き換えられたクエリとの整合性が確保されます。このプロセスを通じて、81 件の StaRK-Amazon クエリ(クエリあたり 19.5 件の関連文書)を、StaRK-Instruct の 198 件のクエリ(3 つの指示タイプにわたり、クエリあたり 11.7 件の関連文書)に合成しました。
StaRK-Instructを使用してInstructed Retrieverのクエリー生成能力を評価するため、次の手法を(シングルステップの検索設定で)評価します。
- 生のクエリー – ベースラインとして、追加のクエリー生成ステージなしで、検索に元のユーザークエリーを使用します。これは、従来の RAG アプローチに似ています。
- GPT5-nano、GPT5.2、Claude4.5-Sonnet – 元のユーザークエリー、ユーザーの指示を含むシステム仕様、インデックス スキーマの両�方を使用して、それぞれのモデルで検索クエリーを生成します。
- InstructedRetriever-4B – GPT5.2 や Claude4.5-Sonnet のような最先端のモデルは非常に効果的ですが、特に大規模なデプロイにおいて、クエリーやフィルタ生成のようなタスクにはコストがかかりすぎる場合があります。そこで、 テスト時適応的最適化 (TAO)メカニズムを適用します。これは、テスト時のコンピュートとオフライン強化学習(RL)を活用して、過去の入力例に基づき、モデルがタスクをよりうまく実行できるようにトレーニングするものです。具体的には、 StaRK-Amazon の「合成された」クエリーのサブセットを使用し、これらの合成クエリーを用いて追加の指示追従クエリーを生成します。再現率(recall)を報酬信号として直接使用し、候補となるツールコールをサンプリングして、より高い再現率スコアを達成したものを強化学習することで、小規模な 40 億パラメーターのモデルをファインチューニングします。
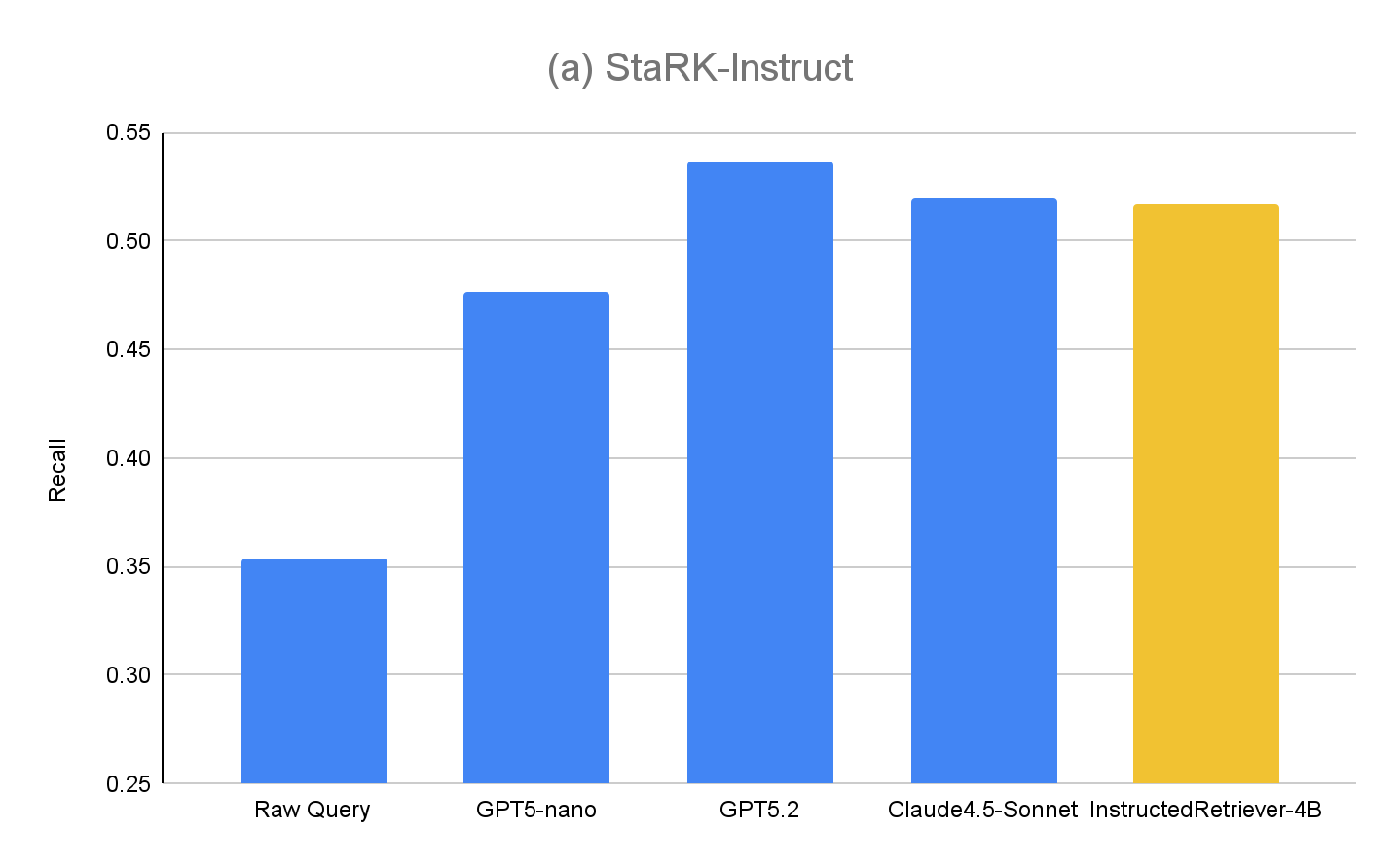
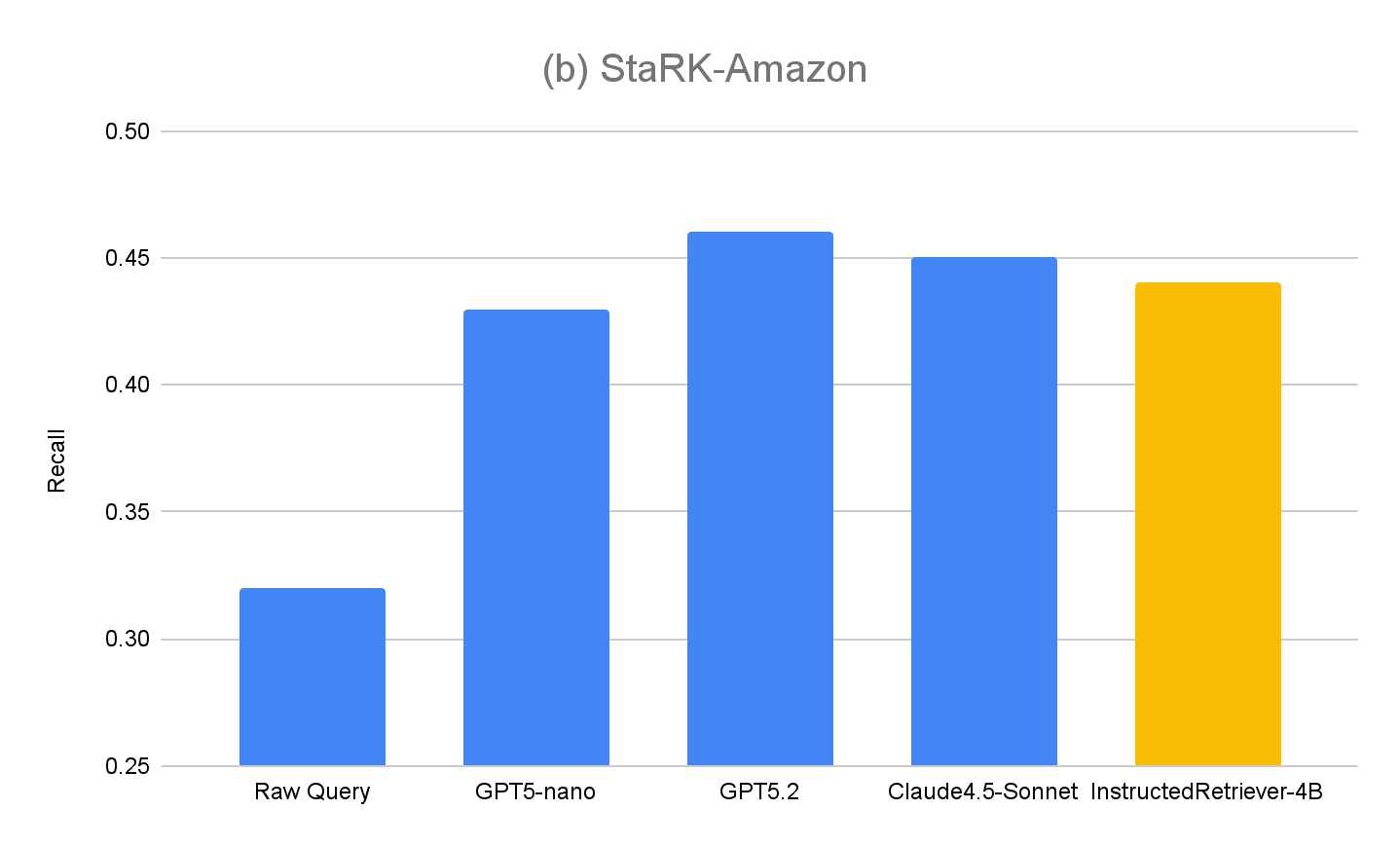
StaRK-Instruct の結果は図 4(a) に示されています。指示付きクエリー生成は、StaRK-Instruct ベンチマークにおいて、 Raw クエリー ベースラインと比較して 35~50% 高い再現率(recall) を達成しています。この改善はモデルサイズにかかわらず一貫しており、効果的な指示の解析と構造化されたクエリ�ーの定式化が、厳しい計算予算下でも測定可能な改善をもたらすことを裏付けています。より大規模なモデルは一般にさらなる改善を示し、アプローチの拡張性がモデルの能力とともに向上することを示唆しています。しかし、私たちがファインチューニングした InstructedRetriever-4B モデルは、はるかに大規模な最先端モデルの性能にほぼ匹敵し、 GPT5-nano モデルを上回ります。これは、アライメントによって、たとえ小規模なモデルであっても、エージェント型検索システムにおける指示追従の有効性を大幅に向上させられることを示しています。
私たちのアプローチの汎化性能をさらに評価するため、メタデータ関連の明示的な指示を含まないクエリーが含まれる元の評価セットである STaRK-Amazon でもパフォーマンスを測定しました。図 4(b) に示すように、指示に基づくすべてのクエリー生成方法は、STaRK-Amazon において 生のクエリー の再現率を約 10% 上回り、指示追従が制約のないクエリー生成シナリオでも有益であることが確認されました。また、ファインチューニングされていないモデルと比較して InstructedRetriever-4B のパフォーマンスに低下は見られず、構造化クエリー生成への特化が、その一般的なクエリー生成能力を損なわないことも確認できました。
Agent Bricks への Instructed Retriever のデプロイ
前のセクションでは、指示追従型のクエリー生成を用いることで、検索品質が大幅に向上することを示しました。このセクションでは、本番運用レベルのエージェント検索システムの一部として、指示付きリトリーバーの有用性をさらに探ります。具体的には、指示付きリトリーバーは Agent Bricks Knowledge Assistant にデプロイされています。これは、提供された専門知識に基づいて質問すると信頼性の高い回答が得られるQAチャットボットです。
ベースラインとして、2つのDIY RAGソリューションを検討します。
- RAG 高性能なベクトル検索から取得した上位の検索結果を、生成のために最先端の大規模言語モデルに入力します。
- RAG + Rerank 検索ステージの�後に再ランキングステージを設けます。これは、以前のテストで検索精度を平均 15 パーセントポイント向上させることが示されています。再ランキングされた結果は、生成のために最先端の大規模言語モデルに入力されます。
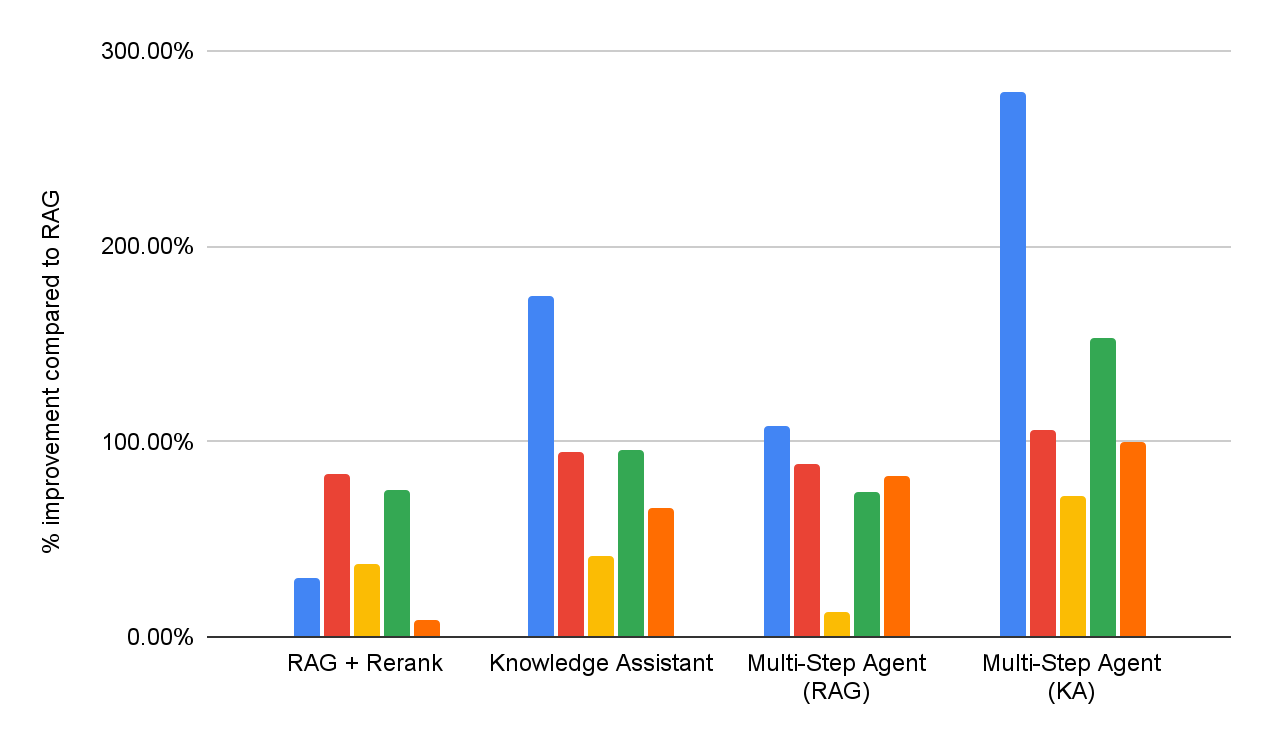
DIY RAG ソリューションと Knowledge Assistant の両方の有効性を評価するため、図 1 で報告されているものと同じエンタープライズ向け質問応答ベンチマーク スイートで、回答品質の評価を実施します。さらに、それぞれ RAG または Knowledge Assistant を検索ツールとして利用できる 2 つのマルチステップ エージェントを実装します。各データセットの詳細なパフォーマンスは、図 5 に(RAG ベースラインと比較した改善率 % として)報告されています。
全体として、すべてのシステムが、すべてのデータセットにおいて、単純な RAG ベースラインを一貫して上回っていることがわかります。これは、RAG ベースラインが複数パートからなる仕様を解釈し、一貫して適用できないことを反映しています。再ランキングステージを追加すると結果が向上し、事後的な関連性モデリングによる一定の利点が示されました。Instructed Retriever アーキテクチャを使用して実装された Knowledge Assistant は、さらなる改善をもたらします。これは、検索と生成のすべての段階を通じて、システム仕様(制約、除外、時間的な好み、メタデータ フィルター)を永続化することの重要性を示しています。
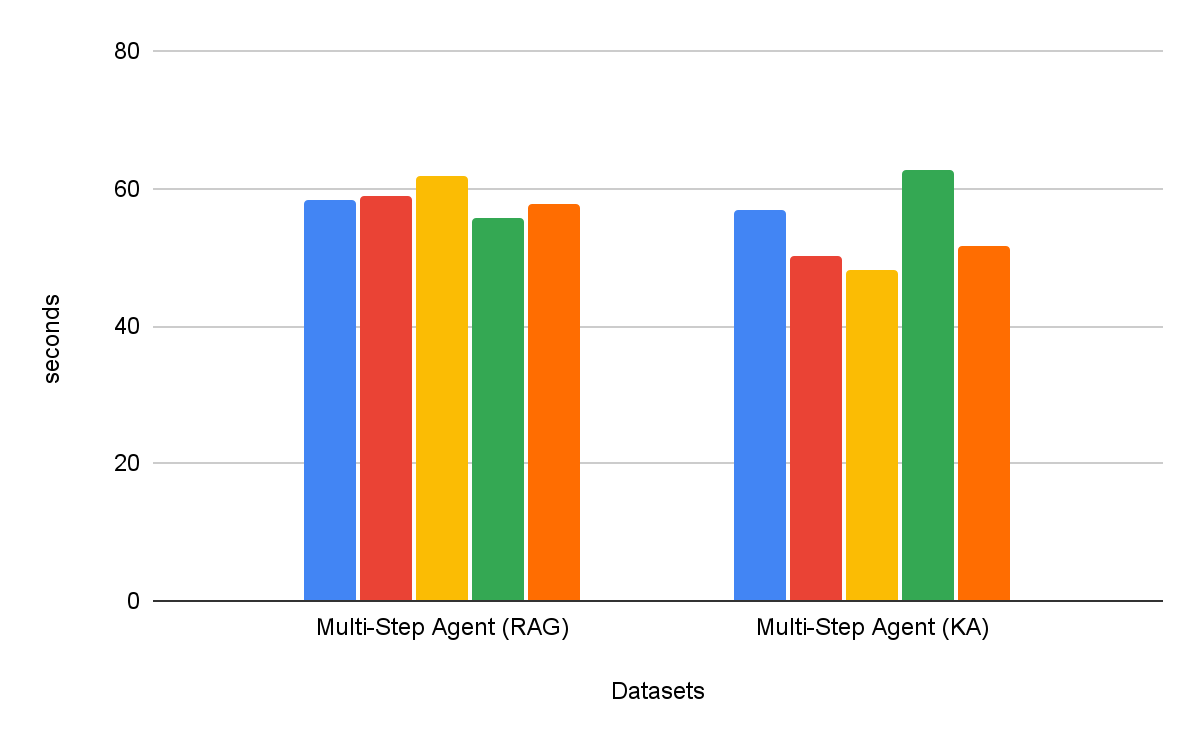
マルチステップ検索エージェントは、シングルステップ検索ワークフローよりも一貫して効果的です。さらに、ツールの選択も重要です。ツールとしての Knowledge Assistant は、ツールとしての RAG を 30% 以上上回り、すべてのデータセットで一貫した改善を示しています。興味深いことに、これは品質を向上させるだけでなく、ほとんどのデータセットでタスク完了までの時間を短縮し、平均で 8% の削減を達成しています(図 6)。
まとめ
信頼性の高いエンタープライズ エージェントを構築するには、異種のナレッジソースから検索する際に、包括的な指示追従とシステムレベルの推論が求められます。この目的のために、本ブログでは 指示付きリトリーバー のアーキテクチャを紹介します。その中心的なイノベーションは、指示からサンプル、インデックス スキーマに至るまで、完全なシステム仕様を検索パイプラインのすべての段階に伝播させることです。
また、包含、除外、最新性といった実世界の指示を処理する検索エージェントの能力を評価する、新しい StaRK-Instruct データセットも発表しました。このベンチマークにおいて、指示付きリトリーバーのアーキテクチャは検索再現率で 35~50% という大幅な向上を達成し、システム全体での指示認識がクエリー生成にもたらすメリットを実証しました。また、小規模で効率的なモデルを最適化することで、より大規模なプロプライエタリモデルの指示追従性能に匹敵させることが可能であることも示しています。これにより、指示付きリトリーバーは、実世界のエンタープライズ環境へのデプロイに適した、費用対効果の高いエージェント アーキテクチャとなります。
Agent Bricksナレッジアシスタントと統合すると、Instructed Retrieverアーキテクチャは、エンドユーザーに対するより高品質で正確な応答に直接つながります。当社の包括的で難易度の高いベンチマークスイートでは、単純なRAGソリューションと比較して70%以上向上し、 リランキングを組み込んだ、より高度なDIYソリューションと比較して 15% 以上品質が向上します。さらに、マルチステップ検索エージェントのツールとして統合した場合、Instructed Retrieverはパフォーマンスを30%以上向上させるだけでなく、RAGをツールとして使用した場合と比較して、タスク完了までの時間を8%短縮できます。
指示付きリトリーバーは、 プロンプトの最適化 、 ALHF 、 TAO 、 RLVR など、これまでに発表された多くのイノベーションとともに、Agent Bricks製品で利用できるようになりました。Agent Bricksの基本理念は、エンタープライズが独自のデータに基づいて正確に推論し、フィードバックから継続的に学習し、ドメイン固有のタスクで最先端の品質と費用対効果を達成するエージェントを開発できるよう支援することです。お客様には、ご自身のエンタープライズ ユースケースに合わせて、操作可能で効果的なエージェントを構築するために、 Knowledge Assistant やその他のAgent Bricks製品をお試しいただくことをお勧めします。
著者: Cindy Wang, Andrew Drozdov, Michael Bendersky, Wen Sun, Owen Oertell, Jonathan Chang, Jonathan Frankle, Xing Chen, Matei Zaharia, Elise Gonzales, Xiangrui Meng
1 このスイートには、5つの独自ベンチマークおよび学術ベンチマークが含まれており、指示追従、ドメイン固有検索、レポート生成、リスト生成、複雑なレイアウトを持つPDFの検索といった能力をテストします。各ベンチマークは応答タイプに応じたカスタム品質判定機能と関連付けられています。
2 インデックスの説明は、ユーザー指定の指示に含めるか、 text-to-SQL システムで一般的に使用される、値の取得などのスキーマリンク手法を介して自動的に作成できます。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。