RAG エージェントが進化!Databricks AI Search のリランキングで、より速くスマートな検索を
わずか1行のコードで関連性の高い回答をスピーディに提供
によって Adam Gurary, アンドリュー・ドロズドフ, エリック・リンドグレン, Ankit Vij, Dima Kotlyarov, マイケル・カービン, セルゲイ・ツァレフ 、 Bruce Fontaine による投稿
- ワンラインのコード変更で即座にエージェント品質を向上: AI Search クエリにパラメータを1つ追加するだけで、エンタープライズ向けベンチマークにおいて平均15ポイントの品質向上を実現。
- エージェントとのシームレスな統合: LangChain やその他のフレームワークをネイティブにサポートし、より豊かなコンテキストを可能にするマルチカラムリランキング、さらに組み込みのパフォーマンス指標を提供。
- スケールにおける一貫した性能: 新しい並列化リランキングアーキテクチャにより、50ドキュメントに対して最短1.5秒のレイテンシーで極めて高い関連性を実現し、主要なクラウド代替手段を上回るパフォーマンスを提供。
多くの企業にとって、非構造化データを使って構築したAIエージェントの最大の課題はモデルそのものではなく コンテキスト です。
エージェントが正しい情報��を取得できなければ、どんなに高度なモデルであっても重要な情報を見落とし、不完全または誤った回答を返してしまいます。
そこで今回、Databricks AI Search におけるリランキング機能 をご紹介します(現在 Public Preview)。
パラメータを1つ指定するだけで、企業向けベンチマークにおいて検索精度を平均15ポイント向上させることができます。
これにより、より高品質な回答、より優れた推論、より一貫したエージェントのパフォーマンスを、追加のインフラや複雑な設定なしで実現できます。
リランキングとは何ですか?
リランキングとは、エージェントがタスクを遂行するために最も関連性の高いデータを確実に取得できるようにする技術です。
ベクターデータベースは数百万件の候補から関連する文書を迅速に見つけるのに優れていますが、リランキングではさらに深いコンテキスト理解を加え、意味的に最も関連度の高い結果が上位に並ぶようにします。
つまり、高速な検索+知的な再順位付け という2段階アプローチで、品質が重要となるRAGエージェントシステムに不可欠な仕組みになっています。
なぜリランキングを追加したのか
社内向けチャットエージェントを構築して、ドキュメントに関する質問に答えさせたい場合。
あるいは、顧客向けのレポートを自動生成するエージェントを構築したい場合。
いずれにせよ、非構造化データを正確に活用するエージェントを作るには、品質=検索精度 に直結します。
リランキングは、AI Searchのユーザーが検索品質を高め、その結果としてRAGエージェントの品質を引き上げるための手段です。
お客様からのフィードバックでは、特に次の2つの課題が見られました:
大量の非構造化ドキュメントの中に埋もれた重要なコンテキストをエージェントが見落とすことがある。ベクターデータベースから返される「正しい」文章が必ずしも結果の最上位に来るわけではない。
自前で構築したリランキングシステムはエージェントの品質を大幅に向上させるものの、開発に数週間かかり、その後も多くのメンテナンスが必要になる。
リランキングをAI Searchのネイティブ機能とすることで、追加のエンジニアリングなしに、ガバナンスの効いたエンタープライズデータから最も関連性の高い情報を引き出すことができるようになりました。
リランカー機能のおかげで、私たちのLexiチャットボットは「高校生レベルの受け答え」から「ロースクール卒業生のような性能」へと進化しました。これにより、法的文書を理解し、推論し、コンテンツを生成するシステムの能力に大きな変革が起こり、これまで非構造化データの中に埋もれていた洞察を引き出すことができるようになりました。—David Brady, G3 Enterprises シニアディレクター
ベースラインを大きく上回る品質改善
私たちのリサーチチームは、エージェントのワークロード向けに新しい複合AIシステムを構築し、ブレークスルーを達成しました。
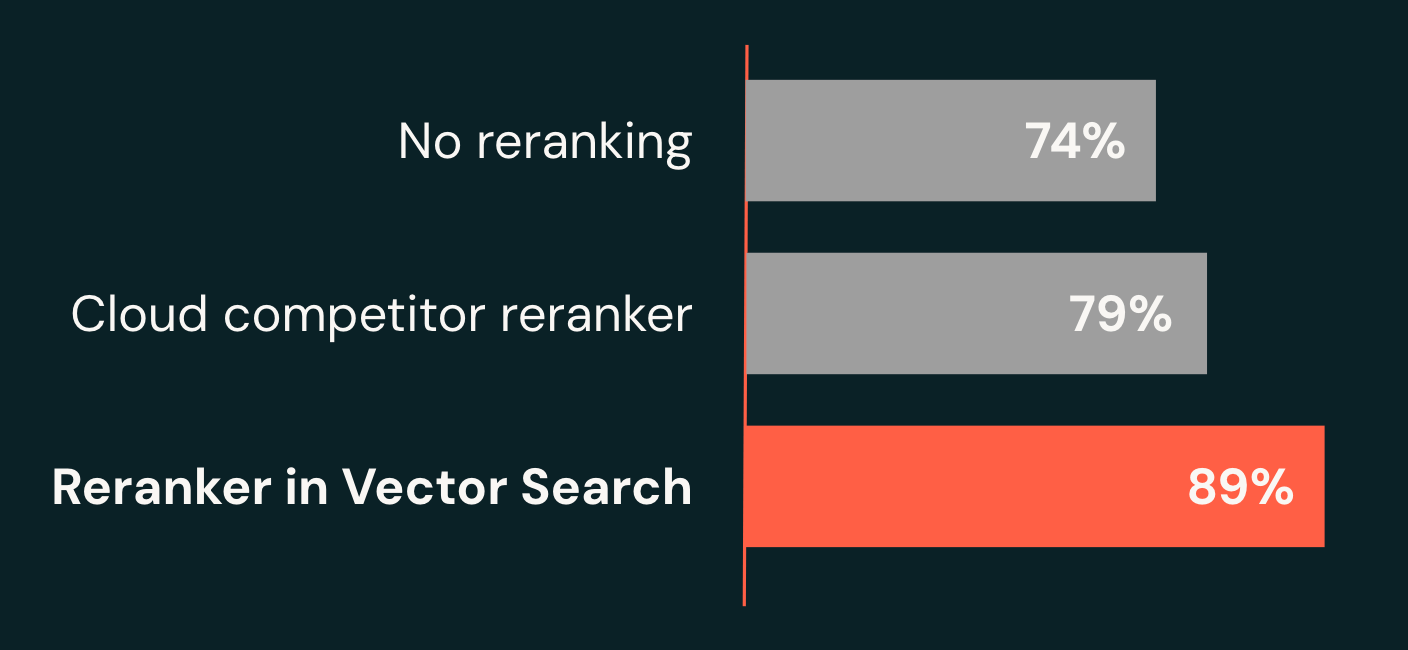
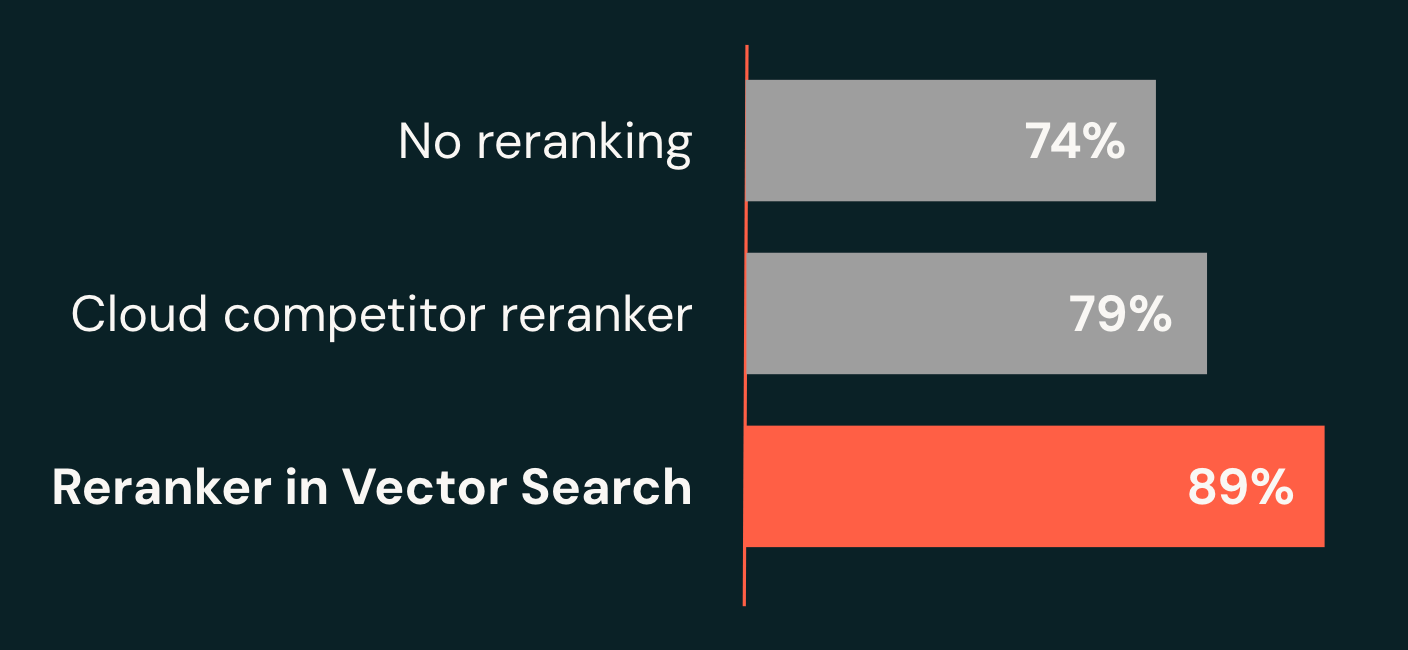
エンタープライズ向けベンチマークでは、このシステムは 正しい答えを上位10件の結果の中に89%の確率で含める(recall@10) ことができ、ベースライン(74%)から15ポイントの改善、主要なクラウド代替手段(79%)を10ポイント上回る成果を示しました。
さらに重要なのは、私たちのリランカーがこの品質を 最短1.5秒という低レイテンシー で実現している点です。従来のシステムでは、高品質な回答を返すのに数秒から場合によっては数分かかることが多いのです。
{kind=link}
簡単・高品質な検索
エンタープライズレベルのリランキングを「数週間」ではなく「数分」で有効化できます。
従来、チームはモデルの調査、インフラの構築、カスタムロジックの実装に何週間も費やしてきました。
それに対して、AI Searchでリランキングを有効化するには、検索クエリにパラメータを1つ追加するだけで、エージェントの検索品質を即座に向上させることができます。
モデル提供エンドポイントの管理も、カスタムラッパーの保守も、複雑な設定調整も一切不要です。
複数のカラムを columns_to_rerank に指定することで、リランカーはメインテキスト以外のメタデータにもアクセスでき、品質をさらに高めることができます。
この例では、リランカーは契約の要約やカテゴリ情報を利用してコンテキストをより深く理解し、検索結果の関連性を改善しています。
エージェント性能の最適化
リアルタイムAIやエージェント型アプリケーションにおいて、スピードと品質を両立。
私たちのリサーチチームはこの複合AIシステムを最適化し、50件の結果をわずか1.5秒でリランキング できるようにしました。
これにより、高い正確性と応答性を求めるエージェントシステムに非常に有効であり、ユーザー体験を損なうことなく高度な検索戦略を実現できます。
いつリランキングを使うべきか?
私たちは、あらゆるRAGエー�ジェントのユースケースでリランキングをテストすることを推奨します。
特に、既存のシステムが「検索結果の上位50件のどこかに正しい答えは含まれているが、上位10件にうまく浮上してこない」という状況で、大幅な品質改善が期待できます。
技術的に言えば、recall@10 が低いが recall@50 が高い ケースで、リランキングの効果が大きく発揮されます。
開発者体験の強化
リランキングのコア機能にとどまらず、高品質な検索システムをこれまで以上に簡単に構築・展開できるようにしています。
LangChain との統合:
リランカーは、AI Search の公式 LangChain 統合である VectorSearchRetrieverTool とシームレスに動作します。
このツールを使ってRAGエージェントを構築するチームは、コードの変更なしに、より高品質な検索の恩恵を受けることができます。
透明性のあるパフォーマンス指標:リランカーのレイテンシーはクエリのデバッグ情報に含まれるようになり、クエリ性能をエンドツーエンドで完全に把握できるようになりました。
応答レイテンシーの内訳(ミリ秒単位)
柔軟な列選択: テキスト列とメタデータ列を自由に組み合わせてリランキングできるため、ドキ��ュメント要約からカテゴリ情報、カスタムメタデータまで、利用可能なあらゆるドメインコンテキストを活用し、高い関連性を実現できます。
今日からはじめよう
AI Search のリランカーは、AIアプリケーションの構築方法を変革します。
インフラの追加コストもなく、シームレスに統合できるので、ユーザーが本当に求める検索品質をようやく提供できるようになります。
準備はできましたか?
- 今すぐAI Searchでの再ランキングを試してみてください—既存のAI Searchクエリにパラメーターを一つ追加するだけです。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。