Variant のご紹介:Apache Parquet™、Delta Lake、Apache Iceberg™ における半構造化データのための新しいオープン標準
によって ジーン・パン, デビッド・キャッシュマン, Ryan Blue 、 Aniruth Narayanan による投稿
- 半構造化データのネイティブデータ型であるVariantが、Apache Parquet™コミュニティで承認され、Delta Lake、Apache Iceberg™、Apache Spark™でサポートされるようになりました
- Variantデータ内で頻繁に出現するフィールドを列形式化する技術であるShreddingにより、通常のVariantを使用する場合と比較して読み取りパフォーマンスが8倍、文字列を使用する場合と比較して30倍向上します
- VariantのShreddingはDatabricksのDBR 17.2+(DBSQL 2025.30+)でサポートされており、JSON、CSV、XMLソースから簡単に取り込むための関数が用意されています
半構造化データは、AI、アプリケーション ログ、テレメトリなど、あらゆる場所で利用されています。このデータは便利ですが、スキーマが変化するため、保存とクエリが困難になります。長年にわたり、このデータを文字列として保存するのが一般的な方法でした。文字列は柔軟性がありましたが、エンジンが文字列全体を解析して検索する必要があるため、クエリのパフォーマンスが低いという問題がありました。
Apache Parquet™で承認されたVariantデータ型は、異なるアプローチを取ります。クエリに対して柔軟かつ高いパフォーマンスを発揮する、コンパクトなバイナリ形式でデータを格納します。このアプローチは特定のエンジンや形式に縛られません。Variantは、Apache Spark™、Delta Lake、Apache Iceberg™でサポートされている、レイクハウス全体における半構造化データのためのオープンスタンダードです。
このブログ記事で取り�上げるトピック:
- Variant のオープン標準への投資
- Variant とシュレッディングの仕組み
- 半構造化データに対する高速なパフォーマンス
Databricksは、オープンソースでのVariantの取り組みを主導しています
昨年、私たちはオープンソースコミュニティと協力し、Apache Spark™とDelta LakeにVariantを導入しました。この新しいデータ型は、半構造化データを文字列(パフォーマンスが低い)や構造体(柔軟性がない)として格納する場合と比較して、柔軟性とパフォーマンスの両方を提供します。
Variant の登場後すぐに、Apache Iceberg™ や Apache Arrow™ をはじめとする他の主要なオープンソースプロジェクトからも関心が寄せられました。エコシステムを統一するため、私たちは Variant 型を Parquet に直接組み込み、Spark 実装を Parquet-java オープンソースプロジェクトに移行することで、すべてのエンジンとフォーマットに Variant を導入することを提案し、9,600 行以上のコードをコントリビュートしました。これにより、すべてのオープンテーブルフォーマットで Variant データ型を簡単に活用できます。
VariantがParquetコミュニティ内で承認されたことで、レイクハウスエコシステム全体が、半構造化データのための標準的でオープンなデータ型を持つことになります。Variantはすでにオープンなテーブルフォーマットでサポートされています。Deltaは昨年からVariantのサポートを含んでおり、昨年5月にはIcebergがv3を承認し、これにはVariantのサポートが含まれています。その結果、DeltaまたはIcebergを利用するユーザーは、Variantの柔軟性とパフォーマンスの恩恵を受けられるようになりました。
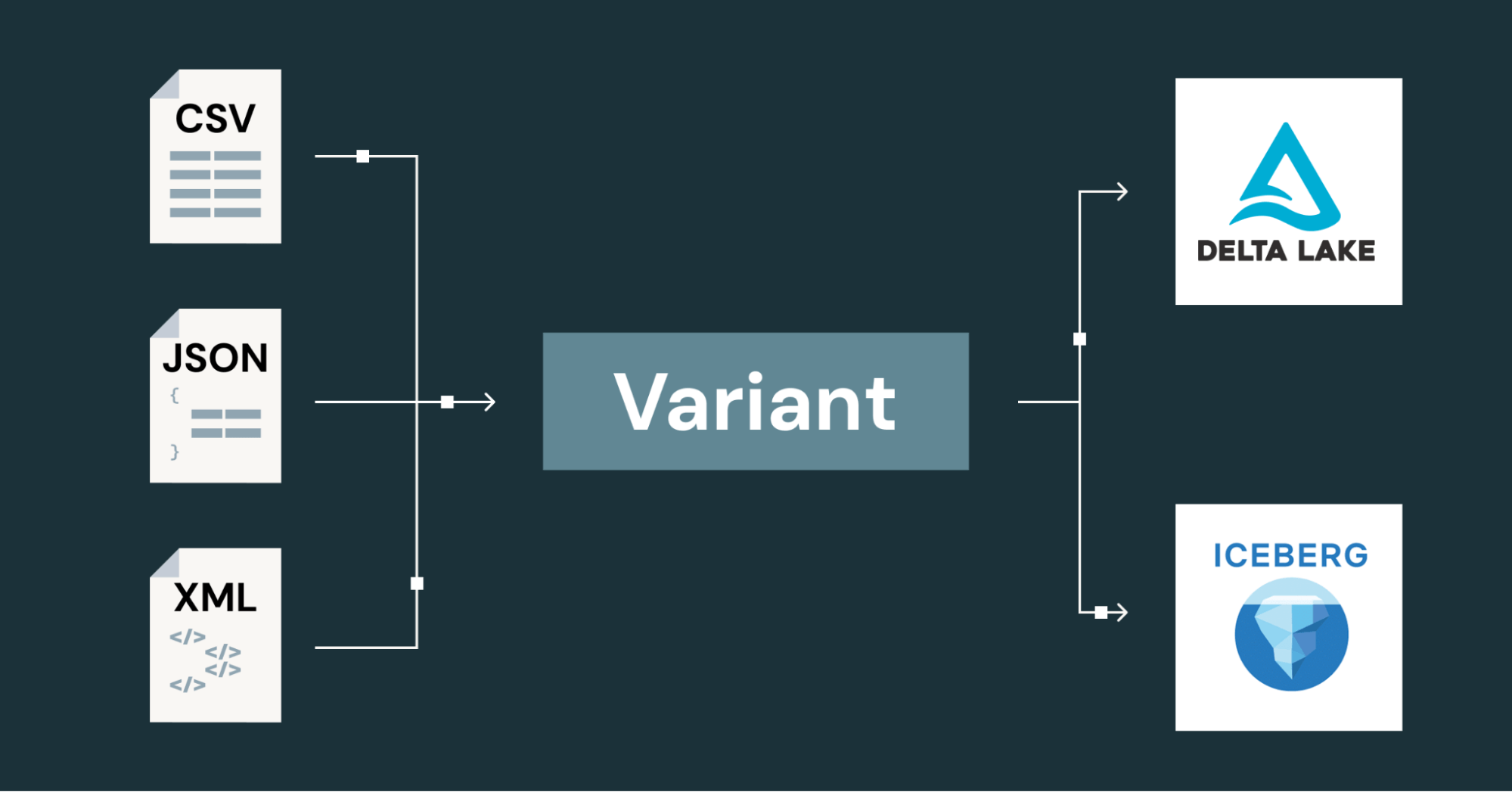
Parquet Variant のアーティファクトには以下が含まれます:
- Variant バイナリエンコーディング仕様
- Variant シュレッディング仕様 (Variant データをより効率的に保存するための手法)
- Parquetリリースバージョン2.12.0とParquet Java実装1.16.0
VariantをサポートするDeltaおよびIcebergプロトコルは次のとおりです。
Apache Parquet™、Apache Spark™、Apache Iceberg™、Delta Lake、Apache Arrow™など、多くのオープンソースコミュニティへの貢献に対し、関与したすべての個人および組織に感謝の意を表します。
Variant とシュレッディングの仕組み
Variantは、バイナリエンコーディング形式を使用して、データストレージのための柔軟なインターフェースを提供します。また、Variantには、パフォーマンスを向上させるためにVariantをより効率的に格納する技術である、shredding(シュレッディング)スキームもあります。
バイナリエンコーディングフォーマット
Variantデータ型は、効率的なバイナリエンコーディングスキームを利用して半構造化データを表現します。データをプレーンテキスト値(JSONなど)として格納する代わりに、Variantデータは、効率的なナビゲーションを優先するバイナリ形式で値と構造をエンコードします。
JSON文字列をナビゲートするには、関連するフィールドを見つけるためにJSONオブジェクト全体を読み取って処理する必要があります。Variantバイナリエンコーディングでは、Variant値内の他の場所へのオフセットを使用して、データの構造がエンコードされます。これらのオフセットを使用すると、Variant構造をナビゲートするのに値全体を読み取ったり処理したりする必要がありません。このオフセットベースのナビゲーションにより、半構造化データの処理パフォーマンスが大幅に向上します。
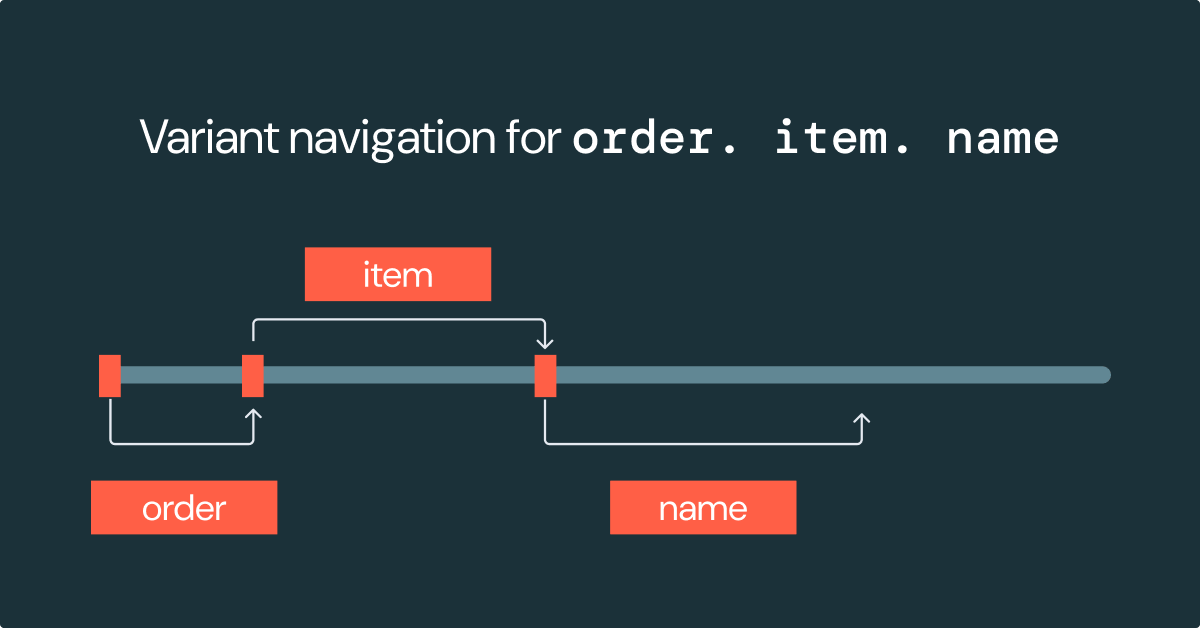
この例は、パス order.item.name への移動では、オフセットを使用して Variant 値のごく一部を調べるだけで済むことを示しています。これにより、処理/解析するデータ量が削減され、パフォーマンスの向上につながります。
Shredding(シュレッディング)
Shreddingは、Variant値から共通のフィールドを自動的に抽出します。これらのフィールドは、同じ列内に個別の型付きチャンクとして格納されます。Shreddingを使用しない場合、Variant値全体が単一の「バイナリBLOB」としてファイルに格納されます。
VariantのShreddingには、パフォーマンス上の利点がいくつかあります。
- I/O のプルーニング:フィールドが個別に格納されている場合、クエリに必要なフィールドのみがフェッチされます。つまり、クエリで Variant フィールドのごく一部しか必要ない場合、I/O もごく一部で済みます。
- データスキッピング: シュレッドされたフィールドが個別の Parquet チャンクとして保存されると、エンジンは Parquet のすべての最適化機能を利用して、行グループと列ページを効率的にスキップできます。
- 圧縮: シュレッドされたフィールドはカラム型であるため、データをより効率的に圧縮でき、ストレージサイズを削減できます。
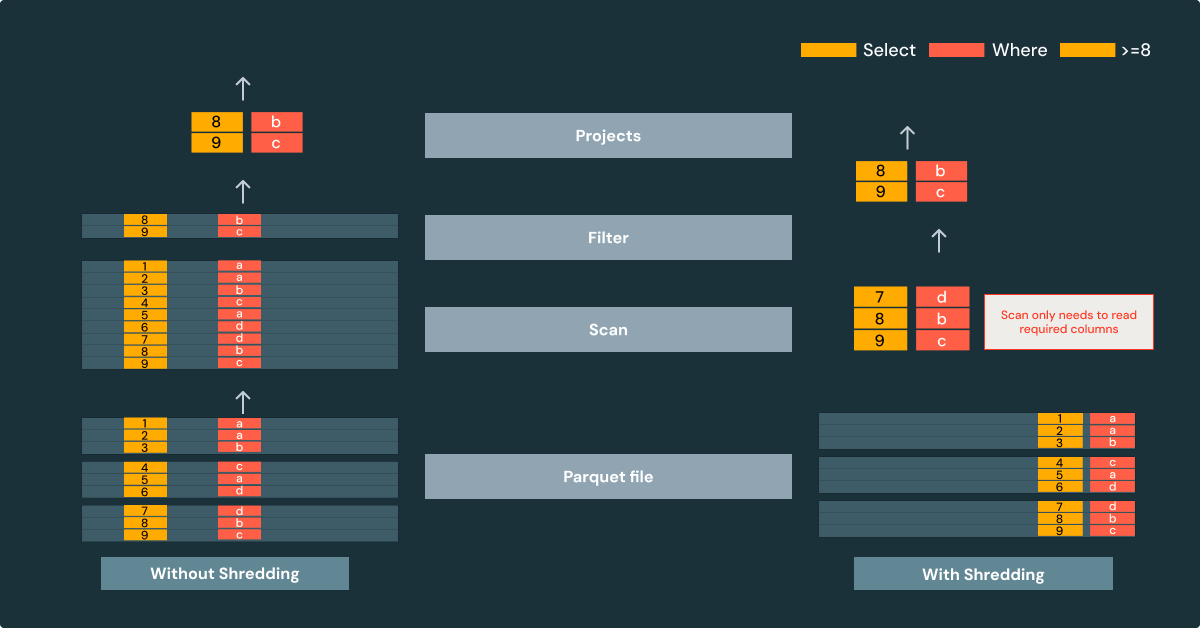
この例は、Shreddingを使用すると、スキャンはクエリに必要な列のみを読み取るだけで済むことを示しています。スキャンはParquetの列統計を使用するため、無関係な行グループを完全にスキップできます。Shreddingされたファイルを読み取ることで、不要な処理を回避し、パフォーマンスが向上します。
半構造化データに対する高速なパフォーマンス
Variantのバイナリ形式とShredding技術により、半構造化データをJSON文字列として格納する場合と比較して、パフォーマンスが大幅に向上します。私たちはTPC-DSベースの半構造化データを使用して、Variantと文字列表現を比較するためのパフォーマンスベンチマークを実施しました。

JSONを文字列として保存する場合と比較して、Variantは8倍高速な読み取りパフォーマンスを発揮します。シュレッディングにより、Variant の書き込みは 20%~50% 遅くなりますが、読み取りは 30 倍高速になり、そのパフォーマンスと効率の高さを示しています。
今すぐ Variant をお試しください
ネイティブのParquet、Delta、Icebergのサポートにより、Variantデータ型は、半構造化データのためのオープンで標準化されたデータ型となります。複雑なETLや脆弱なパース処理が不要になることで、Variantはユーザーがデータを迅速、簡単、かつ確実に分析できるようにします。
Variant列を持つテーブルの作成は簡単です。
Variant データをロードするため、Databricks は JSON、XML、CSV からの Variant 取り込み関数をサポートしています:
VariantのShreddingは、DBR 17.2+(DBSQL 2025.30+)でサポートされており、DeltaおよびIcebergテーブルで利用できます。これにより、コードを変更することなくクエリのパフォーマンスが向上します。
Variantに関する次回の投稿にご期待ください。実践的な例を交えながら、お客様の事例をご紹介します。
最高のデータウェアハウスはレイクハウスであるという考えのもと、パフォーマンス、シンプルさ、価値を重視することが Databricks SQL の基盤です。Databricks SQL の詳細については、ウェブサイト、ドキュメント、または製品ツアーをご覧ください。Databricks SQL は、高性能、低コスト、かつサーバーレスなデータウェアハウスです — 今すぐ無料でお試しいただけます。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。