リンク不可能なものを繋げる:Databricks ARCによるシンプルで自動化されたスケーラブルなデータリンク
によって ロバート・ウィフィン, マルチェル・フェレンツ 、 ミロシュ・コリック による投稿

2023年4月にDatabricks ARCのリリースを発表し、単一テーブル内のデータをシンプルに自動リンクできるようになりました。 本日、オープンでスケーラブル、かつシンプルなフレームワークを使用して、2つの異なるテーブル間のリンクを検索できる機能強化を発表しました。 英国司法省が開発し、ARCのリンクエンジンとして機能するSplinkは、強力でオープンで説明可能なエンティティ解決パッケージを提供するために存在します。
2つの異なるテーブルの間に共通のフィールドがあり、そのフィールドがテーブル間の直接のリンクとなります。 同じNIナンバー(英国の国民保険番号)を持つ2つの記録は同一人物であるはずです。 しかし、このような共通のフィールドがないデータをどのようにリンクするのでしょうか? あるいは、データの質が悪い場合ですか? NIナンバーが同じだからといって、誰かが書き間違えたとは限りません。 このような場合、確率的データリンク、つまりファジーマッチングの領域に入ります。 下の図は、2つのテーブルをリンクしてより完全なビューを作成できるが、リンクするための共通キーがない場��合を示しています:


明らかに、これらのテーブルには同じ人物の情報が含まれています。 しかし、この2つの間に共通のフィールドがなければ、現在のデータと過去のデータをリンクさせる方法をプログラムで決定することはできません。
従来、この問題を解決するには、熟練した開発者グループが時間をかけて丹念に手書きしたハードコード化されたルールに頼っていました。 上記の場合、出生年と姓を比較するような単純なルールは機能しますが、このアプローチは数百万レコードにまたがる多くの異なる属性がある場合にはスケールしません。 必然的に起こるのは、何百、何千ものユニークなルールを持つ、理解不能なほど複雑なコードの開発です。 その結果、システムはもろくなり、拡張しにくくなり、さらに変更しにくくなります。 このようなシステムの主要な保守担当者が退職すると、組織はかなりのリスクと技術的負債を抱えたブラックボックス・システムを抱えることになります。
確率的リンクシステムは、レコード間の統計的類似性を意思決定の基礎として使用します。 機械学習�(ML)システムとして、2つのレコードが十分に類似している場合の手動指定に頼らず、代わりにデータから類似度のしきい値を学習します。 教師ありMLシステムは、同じレコード(AppleとAple)とそうでないレコード(AppleとOrange)の例を使用して、モデルが見たことのないレコードペア(AppleとPear)に適用できる一般的なルールセットを定義することで、これらのしきい値を学習します。 教師なしシステムにはこの要件はなく、代わりに基礎となるレコードの類似性だけを見ます。 ARCは、標準とヒューリスティックを適用することで、この教師なしアプローチを簡素化し、手動でルールを定義する必要性を排除します。代わりに、より緩やかなルールセットを使用することを選択し、どのルールが良いかを見極めるハードワークをコンピュータに任せます。
ARCで2つのデータセットをリンクするには、わずか数行のコードが必要です:


この画像は、ARCが誤字や列の入れ違いがあるにもかかわらずレコードをリンク(合成!)していることを強調しています。1行目では、名字と名前に誤字であるだけでなく、列が入れ替わっています。
ARCとのリンクが役立つ分野
ARCとの自動化された��労力の少ないリンクにより、さまざまな機会が生まれます:
- 移行と統合にかかる時間とコストを削減
- 課題:成熟したシステムには必ず重複データが存在します。 これらのデータセットとそのパイプラインを維持することは、不必要なコストと、例えばPIIデータの安全でないコピーなど、類似したデータのコピーを複数持つことによるリスクを生み出します。
- ARCの利点:ARCを使用すると、テーブル間の類似性を自動的に定量化できます。 つまり、重複するデータやパイプラインをより迅速かつ低コストで特定できるため、新しいシステムの統合や古いシステムの移行にかかる時間を短縮できます。
- 省庁間および政府間の協力の実現
- 課題:国、自治体、地方政府の間でデータを共有するスキルに課題があり、これが政府のあらゆる分野でデータを公共の利益のために活用する能力を妨げています。 COVID-19のパンデミックの際にデータを共有できたことは、政府の対応にとって極めて重要でしたし、データ共有は2020年英国国家データ戦略の5つのミッションを貫く柱です。
- ARCの利点:ARCは、スキルの障壁を低くす�ることで、データリンクの民主化を実現します。 さらに、ARCは、強力なリンキングエンジンであるSplinkの学習曲線を緩和するために使用することができます。
- データの特性に合わせたモデルでデータをリンク
- 課題:時間がかかり、高価なリンクモデルは、多くの異なるプロファイルのデータにわたって一般化できるモデルを構築しようとする動機を生み出します。 一般的なモデルは、専門的なモデルよりも性能が劣るというのが定説ですが、モデルトレーニングの現実は、しばしばリンクプロジェクトごとにモデルをトレーニングすることを妨げます。
- ARCの利点:ARCの自動化は、特定のデータセットをリンクするように訓練された特殊なモデルを、最小限の人的作業で大規模に展開できることを意味します。 これにより、データリンクプロジェクトの障壁が大幅に低くなります。
ARCへの自動データリンクの追加は、エンティティ解決とデータ統合の領域への重要な貢献です。 共通のキーなしでデータセットを接続することで、公共部門はデータの真の力を活用し、内部の革新とモダナイゼーションを推進し、市民により良いサービスを提供することができます。 ARC GitHubリポジトリからDatabricks Repoにクローンできるサンプルノートブックを試して、今すぐ始めることができます。ARCは完全にオープンソースのプロジェクトであり��、PyPiで利用可能で、pipでインストールすることができます。
正確さ - リンクするか、しないか
実社会におけるデータリンクの長年の課題は正確さです。 すべてのリンクが正しいかどうかをどうやって知るのでしょうか? リンケージモデルを完全に評価する唯一の方法は、すべてのレコードのリンクが事前に分かっている参照データセットがあることです。 つまり、モデルから予測されたリンクを既知のリンクと比較し、精度の指標を算出することができます。
連鎖モデルの精度を測定する一般的な方法は3つあります:精度(Precision)、再現率(Recall)、F1スコアです。
- 精度:予測したリンクの何パーセントが正しいか?
- 再現率:モデルはリンク全体のうち、どの程度の割合を見つけたか?
- F1スコア:精度と再現率をブレンドした指標で、低い値ほど重視される。 つまり、高いF1スコアを達成するためには、モデルは精度と再現率に優れていなければならない。
しかし、これらのメトリクスは、真のリンクを示すラベルのセットにアクセスできる場合にのみ適用できます。 データリンクのコストを下げるために、可能な限りラベルなしで作業したいのですが、ラベルがなければリンクモデルを客観的に評価することができません。
ARCの性能を評価するため�に、FEBRLを使用して3万件の重複を含む13万件のレコードからなる合成データセットを作成しました。 これは2つのファイルに分割されました - 100,000のクリーンなレコードと、それらとリンクする必要のある30,000のレコードです。 2つのデータセットをリンクさせる際には、先に説明した教師なしメトリックを使用します。 私たちは、上記の各データセットについて100回の実行を行い、予測値のF1スコアを最適化プロセスに含めずに、私たちのメトリックのみを最適化して、仮説を検証しました。 下のグラフは、横軸に私たちの指標、縦軸に経験的F1スコアの関係を示しています。
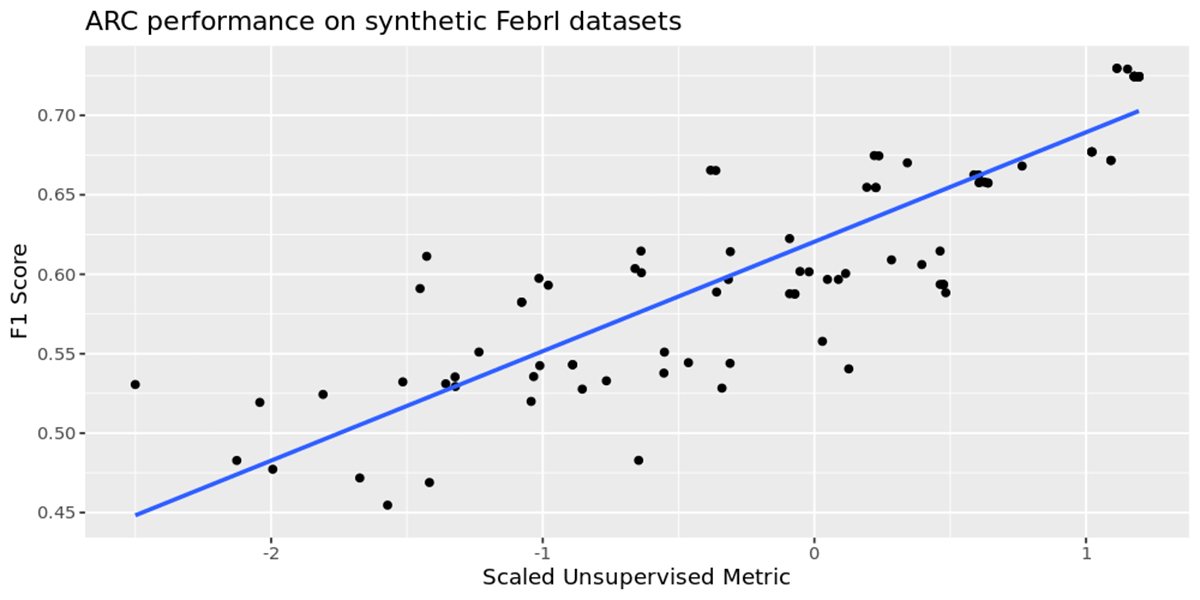
この2つの間には正の相関が見られ、ハイパーパラメータの最適化によって予測クラスターのメトリックを増加させることが、より精度の高いモデルにつながることを示しています。 これにより、ARCはラベル付けされたデータを提供することなく、時間の経過とともに強力なベースラインモデルに到達することができます。 このことは、ラベル付けされたデータがない状態で私たちのメトリックを最大化することが、正しいデータリンクの良い代理であることを示唆する強力なデータポイントを提供します。
ARC GitHub リポジトリを Databricks Repo にクローンした後、サンプルノートブックを実行するだけで、今日の ARC データリンクを開始できます。 このレポにはコードだけでなくサンプルデータも含まれており、たった数行のコードで2つの異なるデータセットをリンクしたり、1つのデータセットを重複排除したりする方法のウォークスルーが示されています。 ARCは完全にオープンソースのプロジェクトであり、PyPiからPipインストールが可能です。
技術的な付録 - Arcはどのように機能するか?
Arcの仕組み、最適化する指標、最適化の方法について詳しくは、https://databricks-industry-solutions.github.io/auto-data-linkage/ のドキュメントをご覧ください。
ARC GitHub リポジトリを Databricks Repo にクローンした後、サンプルノートブックを実行するだけで、今日の ARC データリンクを開始できます。 このレポにはコードだけでなくサンプルデータも含まれており、たった数行のコードで2つの異なるデータセットをリンクしたり、1つのデータセットを重複排除したりする方法のウォークスルーが示されています。 ARCは完全にオープンソースのプロジェクトであり、PyPiからPipインストールが可能です。
最新の投稿を受信トレイで受け取�る
ブログを購読して、最新の投稿を受信トレイにお届けします。