米空軍ハッカソン:大規模言語モデルが米空軍の飛行試験にどのような革命をもたらすか
によって ジョーダン・コナー, ルイス・モロス, ライリー・リバモア, ダニー・ライリー, トロイ・ソワロー, ベン・フェアクロス, ティム・ローツ 、 Li Yu による投稿
[配布に関する声明 A. 公開を承認;�配布は無制限 412TW-PA-24004] 本書は、米国空軍、国防総省、または米国政府の公式な方針または立場を反映するものではありません。
米空軍(USAF)ハッカソンとは?
空軍テストセンター(AFTC)データハッカソンは、AFTCのテスト専門家が1週間にわたって集まり、新しい技術を駆使して空軍の新たな問題に取り組むコンソーシアムです。 今回の第5回ハッカソンでは、大規模言語モデル(LLM)に焦点を当て、AFTCの3つの拠点に44名の参加者が集まり、また遠隔地からの参加者もありました。 OpenAIのChatGPTのようなLLMは、急速に技術分野で注目を集めるようになり、コードの初期化や文章コンテンツの下書きにデジタルアシスタントを利用するというアイデアが主流になりつつあります。 このような利点があるにもかかわらず、空軍では、機密情報を領域外に暴露する可能性があるため、商用モデルの短期的な使用には制約があります。
機能するLLMを空軍の境界内に配備したいという意欲はありますが、そのための方法は限られています。 空軍データファブリックの安全なVAULT環境は、AFTCデータハッカソンが毎回使用しているもので、大規模データサイエンスコンピューティングの取り組みにDatabricksテクノロジースタックを利用しています。 ハッカソンでは、18万件以上の未分類の文書を含むテスト文書リポジトリを活用し、望ましいLLMの開発のためのテストコーパスとして使用しました。 ハッカソンコミュニティはDatabricksの技術を使うことを推奨しており、トレーニングに利用できる大規模なデータセットは、この目標が技術的に実現可能であることを示唆しています。
大規模言語モデル(LLM)とは何ですか?
大規模言語モデルとは、基本的には、膨大な量のテキストで訓練された、何十億ものニューロンのようなユニットで満たされた巨大なデジタル脳です。 パターン、言語、情報を学習し、与えられたデータに基づいて人間のようなテキストを生成することができます。
ハッカソンの使命
ChatGPTのような一般にホストされているLLMサービスはすでに存在しますが、ハッカソンは、安全なプラットフォームでホストされているいくつかのオープンソースのLLMを設定し、比較することを中心に行われました。 検索拡張生成(RAG)アプローチが採用され、米国空軍の何千もの飛行試験文書の力を利用して、文脈的に適切な回答を生成し、飛行試験と安全計画のような文書を生成しました。 飛行試験計画書や報告書は単なる文書ではなく、複雑な詳細、試験パラメータ、安全手順、予想される結果などが、特定の方式に従って体系的にまとめられていることを理解することが極めて重要です。 これらの文書は、通常、数週間以上かけて作成され、複数の飛行試験エンジニアの時間と専門知識が必要とされます。 LLMは、この広範なプロセスを迅速化し、合理化するための貴重なツールになり得ることを示唆しています。
Databricksの役割
米空軍ハッカソンの成功は、Databricks社とのコラボレーションによって大きく後押しされました。 同社のLakehouseプラットフォームは、米国の公共部門向けにカスタマイズされ、高度なAI/ML機能とエンドツーエンドのモデル管理を最前線にもたらしました。 さらに、最先端のオープンソースLLMを推進するDatabricksのコミットメントは、より広範なデータサイエンスコミュニティへの献身を強調しています。 ジェネレーティブAIモデルの作成とカスタマイズのための主要プラットフォームであるMosaicMLを最近買収したことは、企業向けにジェネレーティブAI機能を民主化し、データとAIをシームレスに統合して、部門全体で優れたアプリケーションを実現するという誓約の一例です。
プロセス
- リポジトリの作成:まず、チームは何万もの過去の飛行試験文書を照合し、LLMがアクセスして参照できるように安全なサーバーにアップロードしました。 ドキュメントは、LLMに与えられた対応タスクに密接に関連するものの検索と参照を容易にするため、ベクトルデータベースに保存されました。
- 事前に訓練されたモデル:LLMをゼロからトレーニングするには多くのリソースとコンピューティングパワーが必要で、時間とコンピューティングの制約を考えると、今回のハッカソンでは実現不可能でした。 その代わりにチームは、MPT-7b、MPT-30b、Falcon-7b、Falcon-40bといった比較的小規模な既存のオープンソースモデルを基盤として活用し、それらを使って安全な文書のリポジトリを検索・参照しました。
- テスト:この文書ライブラリを使用して、チームはLLMに米国空軍固有のコンテンツを理解、参照、生成させることができました。 これによってLLMは、以下の例に示すように、人間が作成した代替品と区別できないテスト文書を生成するよう、応答を調整することができました。
- 問題点:ハッカソン中、チームはセキュアな環境でLLMを活用する際に多くの課題に直面しました。 時間的にも計算資源的にも制約のある中、既存のLLMは計算量が多く、使用した16の高性能計算クラスタに負荷がかかり、結果的にレスポンスが遅くなりました。 このような課題にもかかわらず、この経験は、専門的で安全な環境で既存のLLMを活用することの複雑さについて重要な洞察をもたらし、将来の進歩につながるものとなりました。
この図は、埋め込み(エンベッディング)を使用して生のドキュメントを実用的な洞察に変換するプロセスを示しています。 それは、生のドキュメントをデルタテーブルに抽出、変換、ロード(ETL)することから始まります。 これらのドキュメントはクリーニングされ、チャンクされ、埋め込みがベクターデータベース(DB)、特にChromaDBにロードされます。 クエリ(例えば「ブルーベリーの育て方は?」など)を実行すると、類似点がわかります。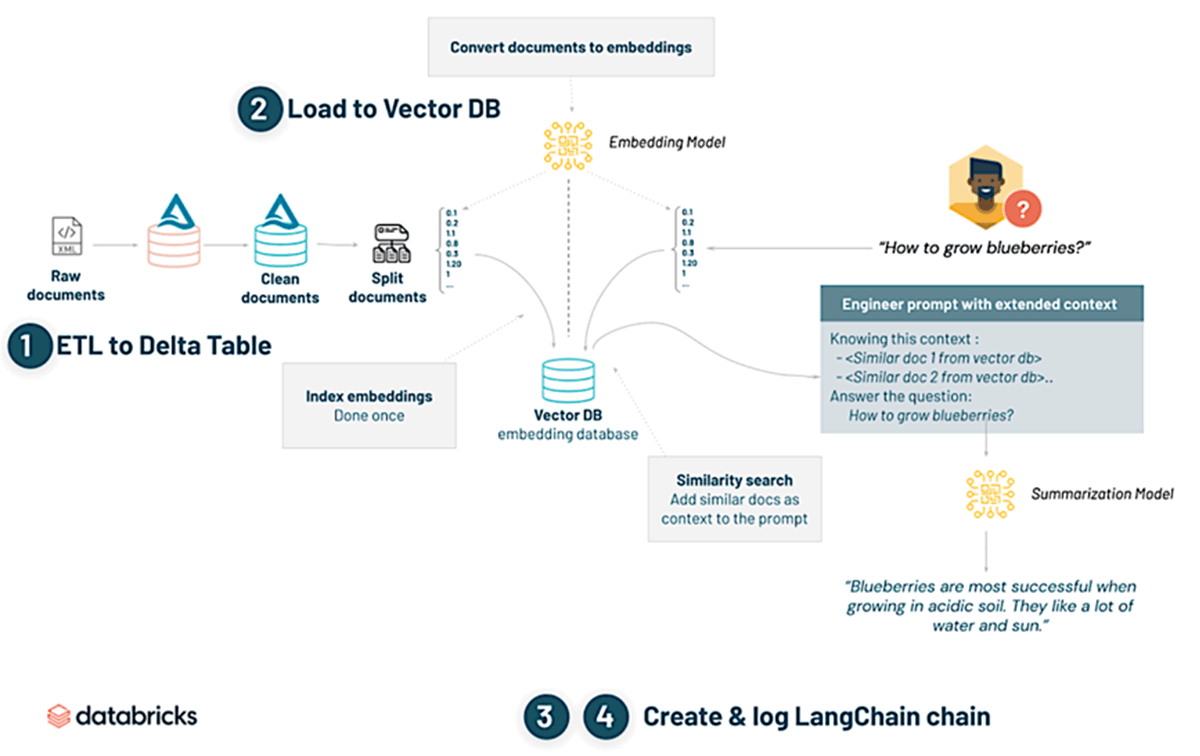
ベクターDBで検索が行われ、関連文書が見つかります。 これらの知見は、文脈を拡張したプロンプトを設計するために使用されます。 最後に、要約モデルがこの情報を抽出し、集約されたコンテキストに基づいて簡潔な回答を提供し、情報が参照された文書を引用します。 この検索・要約機能は、LLMの活用方法のひとつにすぎません。 さらに、このツールは、参照文書からの文脈がなくても、どのようなトピックに関しても照会することができます。
重要な理由
- 効率:よく訓練されたLLMは、コンテンツを迅速に処理し、生成することができ�ます。 これにより、参考文献の検索、報告書の下書き、コードの記述、飛行試験イベントのデータ分析に費やす時間を大幅に削減することができます。
- コスト削減:時は金なり。 LLMを使って一部の作業を自動化することで時間が節約できれば、米空軍はコストを大幅に削減できます。 米空軍の活動の規模を考えると、財政的な影響は甚大です。
- エラーの低減:ヒューマンエラーは避けられないものですが、フライトテストの世界では大きな影響を及ぼす可能性があります。 LLMが適切に監督され、その対応がレビューされれば、訓練された業務の一貫性と正確性を確保することができます。
- アクセシビリティ:LLMを取得すれば、さまざまな情報にすぐにアクセスできるようになります。 以前は手作業でデータベースを調べて回答するのに何時間もかかっていたクエリも、数分で対応できるようになります。
未来
米空軍ハッカソンプロジェクトは比較的小規模なものでしたが、LLMが提供する可能性と、LLMが節約する時間とリソースの量を示すものでした。 もしアメリカ空軍がLLMをワークフローに導入すれば、飛行テストはまったく変わり、戦力増強の役割を果たし、その過程で数百万ドルを節約することができます。
おわりに
空軍の作戦任務へのLLMの使用は遠いことのように思えるかもしれませんが、米空軍ハッカソンでは、飛行試験のような特殊な分野での使用の可能性が示されました。 このイベントでは、LLMを国防総省のワークフローに統合する多くの利点が強調された一方で、さらなる投資の必要性も強調されました。 この�技術の能力を真に活用し、私たちの空をより安全に、より効率的に運用するためには、持続的な支援と資金提供が不可欠です。 ハッカソンは未来を垣間見たにすぎず、現実のものとするためには、共同作業と実施に向けた継続的な取り組みが不可欠です。
Databricks が米国防総省と取り組んでいる仕事の詳細については、2 月 29 日にバージニア州北部で開催される直接参加型のガバメントフォーラム、または 2024 年 3 月 21 日に開催されるバーチャルガバメントフォーラムでお聞きください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。