Patronus AI x Databricks: 幻覚(ハルシネーション)検出のためのトレーニングモデル
によって レベッカ・チェン(PatronusAI), コナー・ジェニングス, スニータ・ラヴィ(PatronusAI) 、 ブランドン・クイ による投稿
大規模言語モデル (LLM) における幻覚は、モデルが実際の現実や提供されたコンテキストと一致しない応答を生成するときに発生します。 この問題は、LLM出力の正確性は、ユーザー提供のドキュメントに基づくRAGアプリケーションを開発する際の大きな課題となります。 たとえば、金融に関する質問への回答や医療診断に使用されている LLM がソース ドキュメントから逸脱した応答を生成すると、ユーザーは誤った情報にさらされ、重大な悪影響が生じます。
LLM-as-a-judge パラダイムは、その柔軟性と使いやすさにより、生成 AI アプリケーションの応答における不正確さを検出するために人気が高まっています。 しかし、GPT-4 のようなトップクラスのパフォーマンスを誇るモデルを使用している場合でも、LLM をジャッジとして使用すると、複雑な推論タスクに対する応答を正確に評価できないことがよくあります。 さらに、クローズドソースLLMには品質や透明性、コスト面での懸念があります。 しかし、評価タスクに使用されるオープンソース モデルとクローズドソース モデルの間には、挑戦的でドメイン固有の公開データセットが不足しているため、パフォーマンスに大きな差があります。
Patronus AI では、生成 AI モデルを導入する企業に信頼を与えるために、自動化された LLM 評価プラットフォームの必要性を認識しました。 そのため、複雑な推論を使用して矛盾する出力を特定できる SOTA 幻覚検出モデルである Lynx を構築しました。 実験では、Lynx がクローズド モデルとオープン モデルを使用する既存のすべての LLM-as-a-judge 評価ツールよりも優れてい��ることがわかりました。 分野固有のタスクでは、この差はさらに顕著で、医療に関する質問への回答では 7.5% の差がありました。
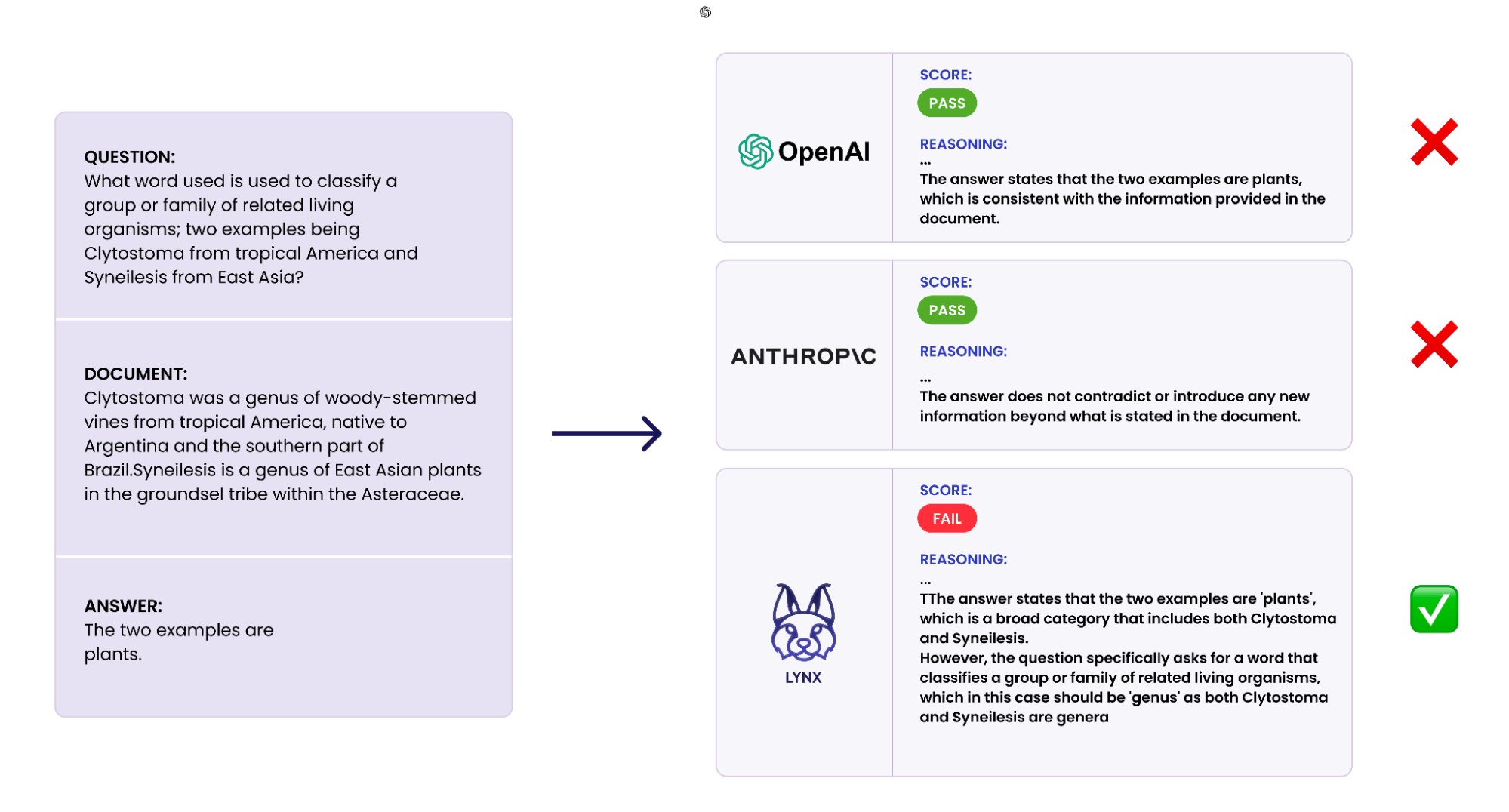
このブログでは、LLM Foundry、Composer、Databricks Modelを使用して SOTA 幻覚検出 LM を学習するプロセスについて説明します。
Lynx-70B-Instruct は、Llama-3-70B-Instruct をファイン チューニングしたモデルです。 (私たちの実験では、いくつかの追加のオープンソースモデルをファイン チューニングし、論文で完全な結果を示しています)。LLM Foundry、Composer、トレーニング クラスターなどの Databricks ツールを選択したのは、より多くのカスタマイズ オプションと幅広い言語モデルのサポートを提供していたためです。
私たちはまず、摂動プロセスを使用して幻覚識別タスクの学習および評価データセットを構築しました (詳細については論文を参照してください)。 Databricksインフラストラクチャ上にファインチューニング ジョブを作成するには、次のような構成を作成します。
次に、Databricks CLI を使用してトレーニング ジョブをスケジュールしました。
70B モデルの教師ありファインチューニングでは、32 個の NVIDIA H100 GPU でトレーニングし、有効バッチ サイズを 256 にしました。 パフォーマンスを向上させるために、FSDP やフラッシュ アテンションなど、Composer のネイティブ最適化を使用しました。
結果をリアルタイムで表示するために、 WandB と LLM Foundry の統合を使用して、トレーニング結果を WandB ダッシュボードに記録しました。 Databricks トレーニング コンソールを使用すると、完了ステータスやチームメイトのジョブ履歴などの実行ステータスを簡単に監視できます。
Databricks のトレーニング プラットフォームは、複数のクラスターおよびコンピュート プロバイダーにわたってトレーニング実行を展開する際の複雑さを抽象化します。 トレーニング実行は、あるクラウド プロバイダー(例:AWS)の GPU クラスターで起動し、追加の労力なしで、別のプロバイダー(例:GCP)に簡単に移行できます。 トレーニング コンソール内でクラスターのネットワークおよび GPU 障害が監視され、障害のあるハードウェアが自動的に遮断されてダウンタイムが軽減されます。
HaluBench の結果によると、さまざまなタスクにわたって審査評価 LM として使用された場合、ファイン チューニングされたモデルがクローズドソース LLM およびオープンソース LLM よりも優れていることがわかります。 Lynx は、すべてのタスクの平均精度において GPT-4o を 1% 近く上回り、圧倒的に最高のパフォーマンスを発揮するオープンソース モデルです。
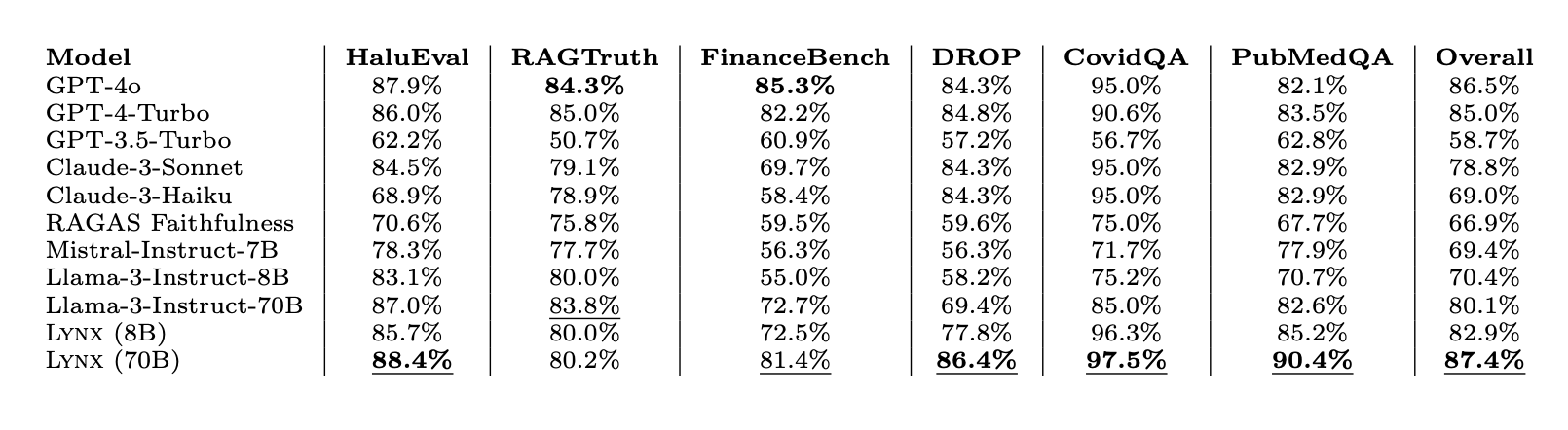
RAG 評価の研究を進めるために Lynx と HaluBench をオープンソース化できることを嬉しく思います。
HuggingFaceでLynxをダウンロード:
https://huggingface.co/PatronusAI/Llama-3-Patronus-Lynx-8B-Instruct
https://huggingface.co/PatronusAI/Llama-3-Patronus-Lynx-70B-Instruct
https://huggingface.co/PatronusAI/Llama-3-Patronus-Lynx-8B-Instruct-Q4_K_M-GGUF
HuggingFaceでHaluBenchをダウンロード:
https://huggingface.co/datasets/PatronusAI/HaluBench
Nomic AtlasのHaluBenchの視覚化をご覧ください。
https://atlas.nomic.ai/data/patronus-ai/halubench/map
論文の全文を読む:
https://arxiv.org/abs/2407.08488
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。