Genieコードにおける従来の機械学習の評価を向上させるためのMemAlignの活用
MemAlignとMLflowでLLMジャッジと人間の専門家のギャップを解消。
によって Stepan Nosov, Pavle Martinović, テジャス・スンダレサン, Alkis Polyzotis 、 ネマニャ・ペトロヴィッチ による投稿
- Genie Codeは自然言語プロンプトから完全なMLノートブックを生成します。私たちは、モデルトレーニング、データ補完、特徴量エンジニアリングといった側面でその品質を評価するために9つのLLMジャッジを構築しました。
- 人間のアノテーションにより、ジャッジが3点スケールで最大0.68 MAEまで専門家と意見が異なることが明らかになりました。MLflowのオープンソースアラインメントフレームワークであるMemAlignは、わず��か約50のラベル付き例を使用してこのギャップを解消しました。
- 最もアラインメントが悪かった3つの側面において、MemAlignはジャッジのエラーを74-89%削減し、追跡調査では、意味記憶とエピソード記憶の両方が結果に不可欠であることが示されました。
3月に発表されたGenie Codeは、データサイエンスと機械学習のために特別に構築されたDatabricksの自律型AIパートナーです。データチームが探索的データ分析を実行し、特徴量を作成・検証し、モデルをトレーニング・評価し、モデルのデプロイを管理・最適化するのに役立ちます。
Genie Codeを際立たせているのは、Databricksとの深い統合です。Genie Codeは、Unity Catalog内のデータ、ビジネスコンテキスト、およびModel ServingのようなMLインフラストラクチャを理解します。このコンテキストにより、より正確な提案を提供し、より意味のあるアクションを実行し、組織に合わせてより適切に調整されたワークフローを生成できます。
そこで重要な疑問が生じます。Genie Codeがこれらすべてのコンテキストを効果的に使用し、MLのベストプラクティスに従った出力を生成することをどのように保証するのでしょうか?たとえば、MLflowのようなツールを使用してモデルの品質を追跡するタイミングと方法を知っている必要があります。生成されるコードは顧客が解決しようとしている問題に大きく依存するため、生成されたコードの品質を��評価することは決して簡単ではありません。
この投稿では、Genie Codeの従来のML機能の評価パイプラインをどのように構築したか、そしてLLMジャッジと人間の専門家の間の大きなギャップを埋めるために、MLflowの新しいオープンソースアライメントフレームワークであるMemAlignをどのように使用したかについて説明します。改善されたジャッジは、Genie CodeのMLガイダンスにおける、そうでなければ見逃していたであろうギャップを特定し、修正するのに役立ちました。
評価フレームワークの構築
堅牢な評価フレームワークは、次の目的で必要です。
- ヒルクライミング: プロンプト、ツール、スキル、アーキテクチャの変更が出力にどのように影響するかを定量化します。
- 回帰からの保護: 「モデルトレーニング」の改善が「データ探索」を誤って劣化させないようにします。
- ベンチマーク: 異なる基盤モデル(LLMバックエンド)がノートブックの品質にどのように影響するかを測定します。
- CI: 基盤となるエージェントループの変更が最終的なMLタスクにどのように波及するかを監視します。
従来のMLノートブックの評価は、コード品質、MLのベストプラクティス、データに基づいた適応/調整の評価にまたがるため、最も複雑な評価タスクの1つです。MLノ�ートブックの評価のような広範で複雑なタスクを処理するために、私たちはLLMをジャッジとして使用します。これは、人間によって「良いノートブック」がどのようなものかを教えられたLLMの「専門家」です。私たちは、ほとんどのMLワークフローに現れる9つの側面でMLノートブックを評価するように促される9つのジャッジを作成しました。
| 側面 | 評価内容 |
|---|---|
| ライブラリのインストール | 適切な依存関係をインストールし、インポートする |
| 探索的データ分析 | データセットを探索し、分布、欠損値、ターゲットの挙動、モデルに影響を与える可能性のある問題を理解する |
| データ補完 | データリークを導入することなく、欠損値を適切に処理する |
| 特徴量エンジニアリング | タスクに適した方法で特徴量を選択、変換、エンコードする |
| モデルトレーニング | 交差検証やハイパーパラメータチューニングなどの健全なプラクティスを使用して、適切なモデルをトレーニングする |
| モデルの使用 | トレーニング済みモデルを正しく再利用して、予測を生成したり推論を実行したりする |
| メトリクス評価 | MLタスクに役立つメトリクスを使用してモデルのパフォーマンスを評価する |
| MLflowロギング | MLflowを使用して実験、メトリクス、アーティファクトを追跡する |
| セルの構成 | ノートブックを明確で読みやすく、適切に文書化されたセルに構成する |
各側面について、1から3までのスコアと「該当なし」の場合は0を割り当てる採点ルーブリック(人間の評価者とLLMジャッジの間で再利用)を作成しました。
- 3 (良い): ノートブックはその側面において高い水準を満たしています。ベストプラクティスを示し、期待される範囲をカバーし、エッジケースを適切に処理しています。
- 2 (平均): 許容範囲ですが、ギャップがあります。基本的な要素はありますが、経験豊富な実践者が期待するような洗練された部分が欠けています。
- 1 (悪い): 根本的な問題があります。重要なステップが欠落しているか、間違っているか、または誤った結論につながる方法で適用されています。
- N/A (該当なし): この側面はこのプロンプトには適用されません(例:データセットに欠損値がない場合、データ補完の側面は適用できません)。
粒度の目安として、「データ補完」の側面で使用する具体的なルーブリックを以下に示します。
ジャッジとともに、MLタスク(分類、回帰、予測)の範囲、異なるデータセットサイズ、ドメイン、複雑度レベルにわたる評価テストケースのセットを維持しています。各テストケースには、Genie Codeに指定されたデータセットで解決すべきMLタスクを伝えるユーザープロン�プトが含まれています(「flight_delays_predictionとflight_deplays_actualのテーブルに飛行機のフライトデータがあります。明日どの飛行機が遅延するか予測できますか?」)。評価ループは、Genie Codeを使用して各テストケースのノートブック(または複数のノートブック)を生成し、その後、適用可能なすべての側面で各ノートブックを採点することから構成されます。
評価システムの評価
Genie Codeの成果物を評価するために、人間ではなくLLMジャッジを使用することで、本質的にある難しい問題を別の問題と交換しました。つまり、初期状態のジャッジは目の前のタスクに不慣れで、人間の評価と一致していません。私たちの問題提起は、LLMジャッジのスコアを人間の評価者のスコアと一致させることです。
LLMジャッジの評価セットには、Genie Codeが生成した50のノートブック(「テストケース」)が含まれており、人間の専門家が適用可能なすべての側面を採点し、スコアと短い根拠の両方を提供して、私たちの真実の基準としています。2つのスコアの間のグレーゾーンでは、評価者は自身の判断を表明することが許可されていましたが、スキーマはこれが稀であるように書かれていました。
人間と機械のアライメントの尺度は、各側面におけるスコア間の平均絶対誤差(MAE)です。結果はまちまちで、一部の側面では強いアライメントが見られ(4つの側面でMAEが0.10以下)、他の側面では大きな不一致が明らかになりました。
- モデルトレーニング: MAE 0.680
- モデル使用: MAE 0.562
- データ補完: MAE 0.474
- データ探索: MAE 0.407
このギャップは、人間とLLMが同じルーブリックを同じように解釈しないために存在します。人間の評価者は、微妙に欠陥のある補完戦略や、「機能する」が論理的に不健全なトレーニングループを見つけることができますが、LLMジャッジはそのような技術的なニュアンスを見逃すことがよくあります。また、ジャッジが古典的なポジティブバイアスに苦しんでいることもわかりました。つまり、単に「丁寧すぎる」ため、客観的な結果を得る妨げになっていました。
同じルーブリックが与えられた場合、LLMジャッジと人間が同じ結果を出さないこと、つまり不一致があることが明らかになりました。これはまさにMemAlignが修正するために設計されたシナリオです。
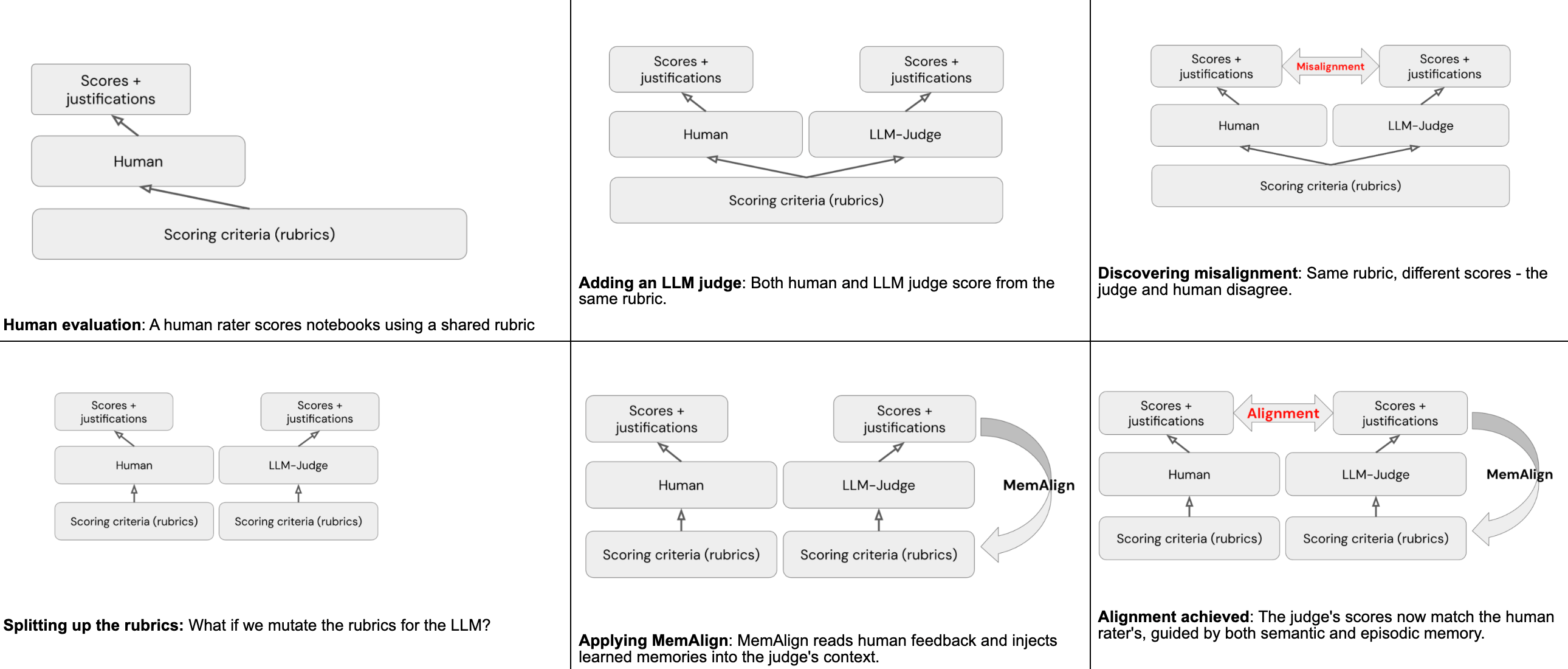
アライメントのためのMemAlignの使用
MemAlignは、MLflow内のフレームワークであり、ごく少量の人間による自然言語フィードバックが与えられた場合、人間の評価者とLLMジャッジの間でアライメントを実行できます。これは、人間のフィードバックを読み取ることで形成される2種類の「記憶」を通じて実現されます。
- セマンティックメモリは、一般的なガイドライン、つまりフィードバックから抽出され広く適用されるルールを保存します。
- エピソードメモリは、特定の例、つまりジャッジが間違ったケースを、将来の決定のアンカーとして保存します。
推論時、MemAlignは、すべてのセマンティックガイドラインを抽出し、現在の入力に最も関連性の高いエピソード事例を取得することで、作業コンテキストを構築します。審査員は、これらすべてを元のルーブリックとともに自身のコンテキストに読み込み、蓄積された知識を使用して、将来のすべてのノートブックにより正確なスコアを付与します。
MemAlignを際立たせた主要な特性は、少数の事例のみで高いパフォーマンスを発揮することです。これは、MemAlignが自然言語フィードバックの豊富な学習シグナルから学習を効果的に抽出し、それらをデュアルメモリシステムに組み込んでいるためです。
以下に、「データ補完」ディメンション用に生成されたセマンティックメモリのスニペットの例を示します。これは、以前に定義したルーブリックのギャップを、一般的にアンカーポイント、事例、反例を提供することで埋めるものです。
さらに、前述のとおり、プロンプトに反映されたセマンティックメモリは、採点時に審査員のエピソード記憶からの関連する事例によって補完され、最適化された指示を解釈するためにより多くのコンテキストを審査員に提供します。
実験設計
K分割交差検定
MLのトレーニングとテストのパラダイムに従い、データリークと個別のテストセッ��トをラベリングする必要性を回避するため、50のテストケース(ノートブック)に対してK分割交差検定(K=4)を適用しました。各フォールドで、以下のことを行いました。
- トレーニングフェーズ: MemAlignは、他のフォールドからのトレースを使用して審査員をアラインメントしました。
- 評価フェーズ: フォールドi内のノートブックを審査員と共に評価しました。
ブートストラップ信頼区間
追加のラベル付きデータなしで信頼区間を計算するために、元の50個から置換ありで100個のブートストラップサンプルを生成しました。これを10,000回繰り返し、人間と機械のスコア間のMAEを追跡することで、統計的に有意な変化を定義する95% CIを持つ人間と機械のアラインメントの信頼区間を計算しました。
実装
評価パイプラインは、プロセス全体をオーケストレーションする単一のMLflowスニペットとして実装されています。
MemAlignオプティマイザーは、わずか数行のコードでテストケースのトレースに基づいてLLM審査員をアラインメントできます。この新しい「アラインメントされた」審査員を使用して、新しいMAEを計算しました。単一のディメンションで審査員をアラインメントするには、フォールドあたり約25秒かかるため、アラインメント自体はボトルネックではありません。
結果
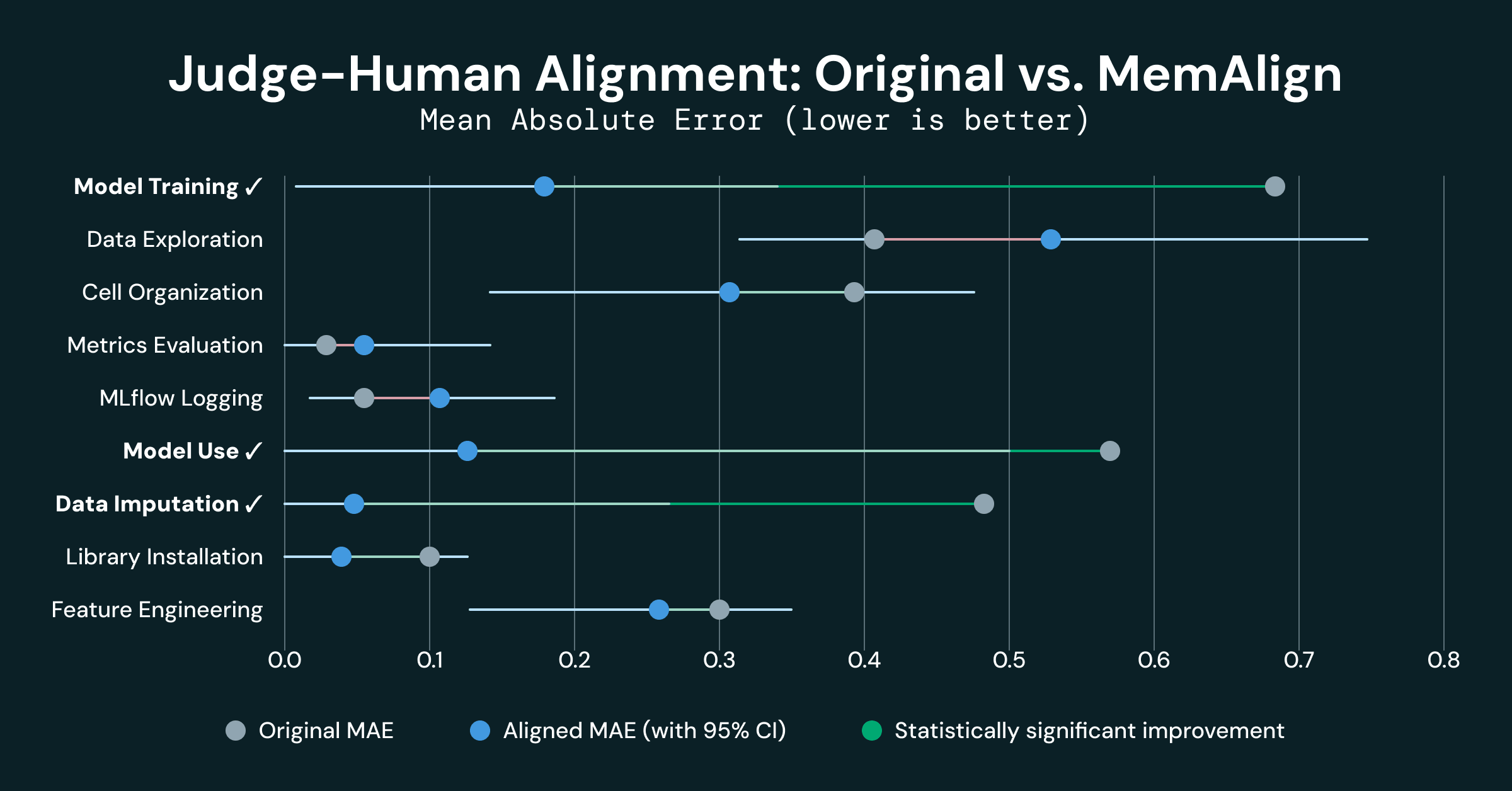
9つのディメンションのうち3つで統計的に有意な改善が見られました。
- モデルトレーニングは0.500 MAE改善(0.680 → 0.180)、74%削減
- モデル使用は0.438 MAE改善(0.562 → 0.125)、78%削減
- データ補完は0.421 MAE改善(0.474 → 0.053)、89%削減
これら3つのディメンションは、当初大きく不整合であった4つのディメンションに含まれます。初期のアラインメントが弱いことは、LLMと人間が共有ルーブリックについて根本的に異なる理解をしていることを示しており、MemAlignから注入されたメモリは、両者が「同じ認識を持つ」のに十分なコンテキストを提供しているようです。
- メトリクス評価とMLflowロギングはすでに良好にアラインメントされており(元のMAE 0.10)、その劣化は統計的に有意ではありません(実験ノイズ)。
- データ探索はわずかな回帰(-0.130)を示しましたが、信頼区間[-0.33, +0.09]を考慮すると統計的に有意ではありません。このディメンションはグレーダー間の分散が最も高く、このノイズがMemAlignの改善を妨げました(あるいは悪化させた可能性もあります)。
セマンティックメモリのみの実験
MemAlignのデュアルメモリ構造により、両方が実際に審査員のアラインメントに貢献しているのかという疑問が生じました。特に、エピソード記憶は、最も��類似した注釈付きノートブックのセットを参照点として提供することで(最近傍探索を利用して)、審査員を助けることになっています。しかし、取得されたノートブック(最近傍)が現在のものと実際には類似しておらず、単に最も非類似度が低いだけだったらどうでしょうか?それらを審査員のコンテキストに読み込むことは、助けになるどころか、事態を混乱させる可能性があります。私たちが採点している問題空間(MLノートブック)は非常に広範であり、当初は50個のノートブックのセットでは、審査員が想起するのに十分な密度の記憶セットを得るには不十分であると仮説を立てていました。
エピソード記憶がない場合、状況は大幅に悪化します。
- モデルトレーニングは依然として改善(+0.420)しますが、完全なMemAlignでの+0.500よりも改善幅は小さく、アラインメントされたMAEは0.260対0.180です。
- モデル使用は統計的有意性を完全に失い、改善は+0.438から+0.294に低下し、信頼区間はゼロを横断するようになりました。
- データ補完は89%のエラー削減から改善ゼロに転じ、アラインメントされたMAEは元のMAE(0.455)と等しくなります。
- MLflowロギングとメトリクス評価は実際に大幅に悪化します。審査員を固定するためのエピソード事例がない場合、抽出されたガイドラインだけでは、すでに適切に調整されていたディメンションにノイズが導入され、MLflowロギングは0.062から0.396 MAEに押し上げられます。
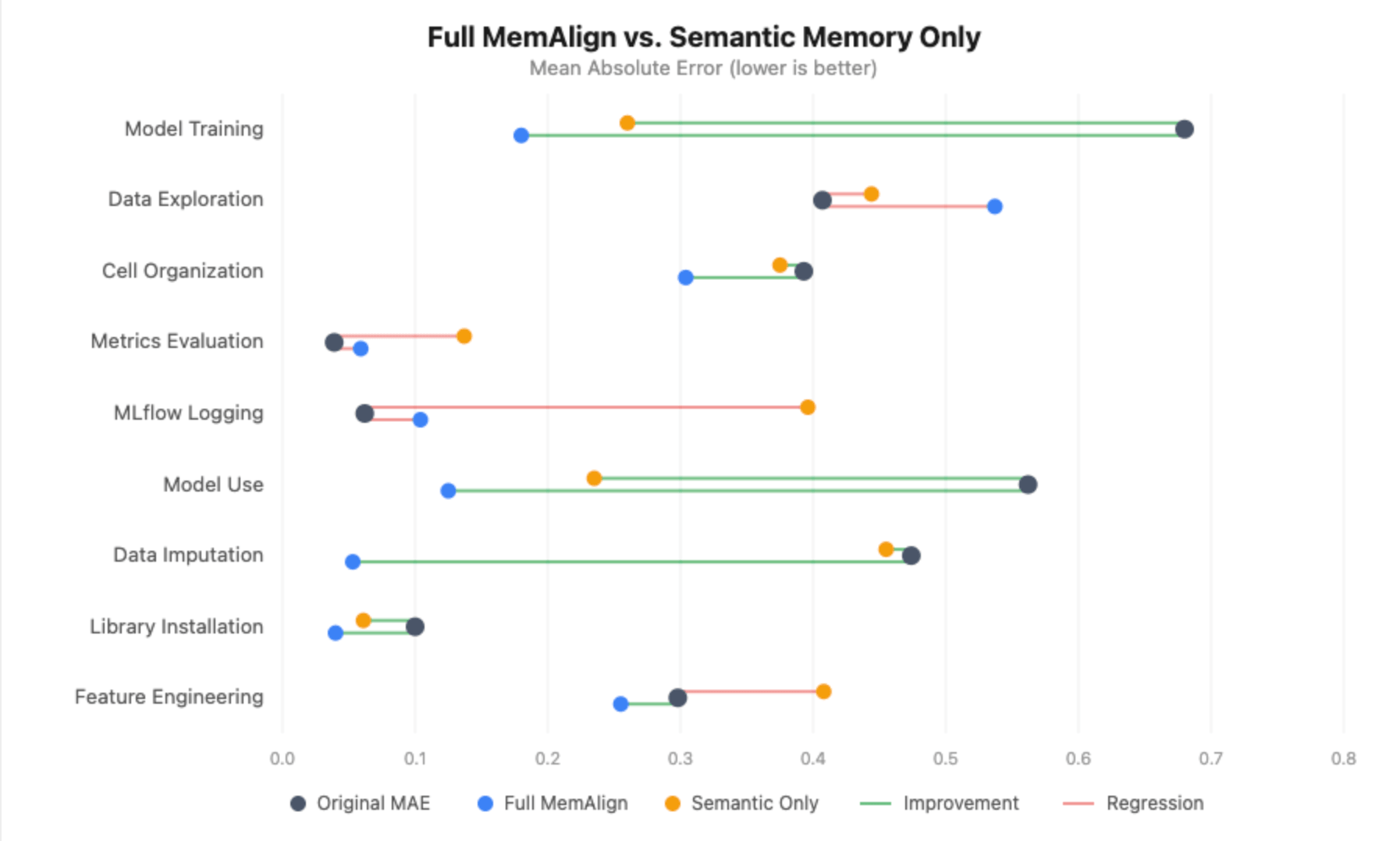
これは私たちが予想していたこととは逆でした。当初、私たちの疎な注釈付きセットは審査員を混乱させるだろうと仮説を立てていましたが、エピソード記憶がないとほとんどすべてのディメンションが悪化しました。唯一の例外はデータ探索で、エピソード事例を削除したことが実際に役立った可能性があります。アノテーターが意見を異にした特定のノートブックがないため、審査員は抽出されたガイドラインのみを使用し、ノイズの少ないシグナルで作業できました。
教訓:入力が大きく乱雑であっても、エピソード記憶は審査員のパフォーマンスを劇的に向上させます。セマンティックメモリとエピソード記憶の両方がMemAlignの機能に不可欠です。
結論:専門家ギャップの解消
コーディングエージェントがその役割を果たしているかを判断することは十分に困難ですが、自律型AIパートナーが従来のMLワークフローを構築および実行しているかを評価することは、さらに複雑なレベルにあります。AI製品の高速なイテレーションのため、専門家がエージェントの「継続的インテグレーション」を監視する時間は十分にありません。唯一実現可能でスケーラブルなソリューションはLLM審査員ですが、LLM審査員を監視するためには、依然として人間の審査団が必要です。
MemAlignを適用することで、�最も重要であったディメンションにおいて、審査員のエラーを74〜89%削減しました。しかし、他のML/LLM作業と同様に、結果は投入する情報の質に左右されるため、ラベリングが適切であることを確認してください。
要点:
- 測定システムを測定する: ノイズの多いシステムは評価に適していません。審査員を実際に検証し改善するために時間とリソースを投資するまで、私たちの評価システムを信頼することはできませんでした。
- ルーブリックだけでは不十分です: 人間が指示をどのように解釈するかと、LLMが指示をどのように解釈するかには、微妙な違いがあります。これらの違いを考慮に入れる必要があり、MemAlignのようなアライメントツールは、そのギャップを埋める効果的な方法です。
- ラベリングは量より質: 人間のアノテーターが互いに意見を異にする場合(データ探索回帰で見たように)、アライメントは学習するための首尾一貫したシグナルを持ちません。
MemAlignはMLflowに同梱されており、わずか約50のラベル付き例で機能しました。もしLLMの評価が専門家と一致しないなら、試してみる価値はあります。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。