スパークチューニングとは何ですか?
Apache Spark の構成、メモリ使用量、実行戦略を体系的に最適化し、リソースのボトルネックを防ぎながらパフォーマンスを最大化します。
によって Databricks Staff による投稿
- Sparkチューニングは、ストレージと実行間のメモリ割り当てを調整し、ネットワークパフォーマンスを向上させるためにデータのシリ��アル化を管理し、コストのかかるディスクへの書き込みを防ぐためにシャッフルパーティションを最適化します。
- Adaptive Query Execution(AQE)は、最適なシャッフルパーティションを自動的に検出してデータの偏りを解消します。一方、Cost-Based Optimizer(CBO)は、テーブル統計を使用して効率的な結合戦略を選択します。
- 高度な技術には、小規模テーブル向けのブロードキャスト結合、データ転送を削減するための述語プッシュダウン、繰り返しデータアクセスのためのキャッシュとディスクストレージの慎重な管理などがあります。
Sparkパフォーマンスチューニングとは
Sparkパフォーマンスチューニングとは、メモリやCPUコア、インスタンス数などの設定を調整し、処理性能を最適化することです。この処理により、Sparkは優れた性能を発揮し、リソースのボトルネックの防止も可能になります。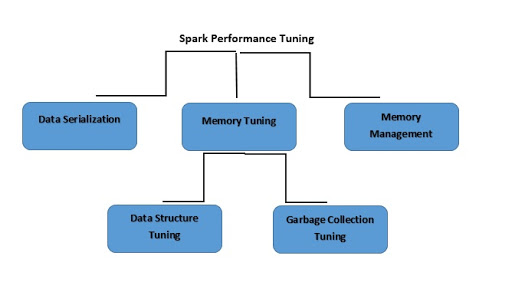
データのシリアライズとは
メモリ使用量を削減するために、Spark RDDをシリアル化して格納する必要があります。また、データのシリアライズは、ネットワークのパフォーマンスにも影響します。Sparkの性能を向上させるには、次のような処理が挙げられます。
- 長時間実行されているジョブを終了
- 適切な実行エンジンでジョブを実行
- 全てのリソースを効率的に使用
- システムの処理時間を短縮
Sparkは、次の2つのシリアライズライブラリをサポートしています。
- Javaのシリアライズ
- Kryoのシリアライズ
メモリチューニングとは
メモリ使用量の調整には、次の3つの留意点があります。
- データセットは全てメモリに収める必要があるため、オブジェクトによって使用されるメモリ量の考慮が不可欠になること
- オブジェクトの回転率の上昇により、ガベージコレクションのオーバーヘッドが必要になること
- オブジェクトにアクセスするコスト
データ構造のチューニングとは
メモリの消費量を削減するためには、オーバーヘッドになりうるJava機能を避けるという選択肢があります。具体的な方法は次のとおりです。
- RAMサイズが32GB未満の場合、JVMフラグを–xx:+ UseCompressedOopsに設定し、ポインタを8バイトから4バイトにする
- 複数の小さなオブジェクトとポインタを使用し、入れ子構造を避ける
- キーに文字列を使用する代わりに、数値IDまたは列挙型オブジェクトを使用する
エンタープライズ向けエージェントAIプレイブック

ガベージコレクションのチューニングとは
プログラムが以前確保した不要なRDDがメモリ領域を占有するのを避けるため、Javaは古いオブジェクトを削除し、新しいオブジェクトにスペースを割り当てます。一方、オブジェクトの少ないデータ構造を使用することで、コストは大きく削減されます。例として、LinkedListの代わりにIntの配列を使用することが挙げられます。または、シリアル化されたオブジェクトを使用することで、オブジェクトはRDDパーティションごとに1つのみとなります。
メモリ管理とは
優れた性能を発揮するには、メモリの効果的な使用が必要不可欠です。Sparkでは、主に保存と実行のためにメモリを使用します。保存メモリは、後に再利用するデータをキャッシュするために使用されます。一方、実行メモリは、シャッフル、ソート、結合、集約などの計算に使用されます。Apache Sparkが解決しなければならないメモリ競合の課題は次の3つです。
- 実行メモリと保存メモリのアービトレート
- 同時に実行しているタスクのメモリのアービトレート
- 同一タスク内で実行しているオペレータのメモリのアービトレート
Sparkではメモリを静的に固定せず、必要に応じてデータを解放することで、実行時に発生するメモリ競合へ対応します。
FAQ
1. Sparkチューニングは何のために行いますか?
リソースのボトルネックを防ぎ、処理速度と安定性を向上させるためです。
2. シリアライズ方式はなぜ重要ですか?
メモリ使用量やネットワーク転送量に直結し、Kryoなどを使うことで性能改善が期待できます。
3. Sparkのメモリはどのように使われますか?
保存用(キャッシュ)と実行用(シャッフルや集約)に分かれており、両者のバランス調整が重要です。
関連資料
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。