TOP COMPANIES USE Serverless コンピュート
インフラではなく、ビジネスゴールを選択
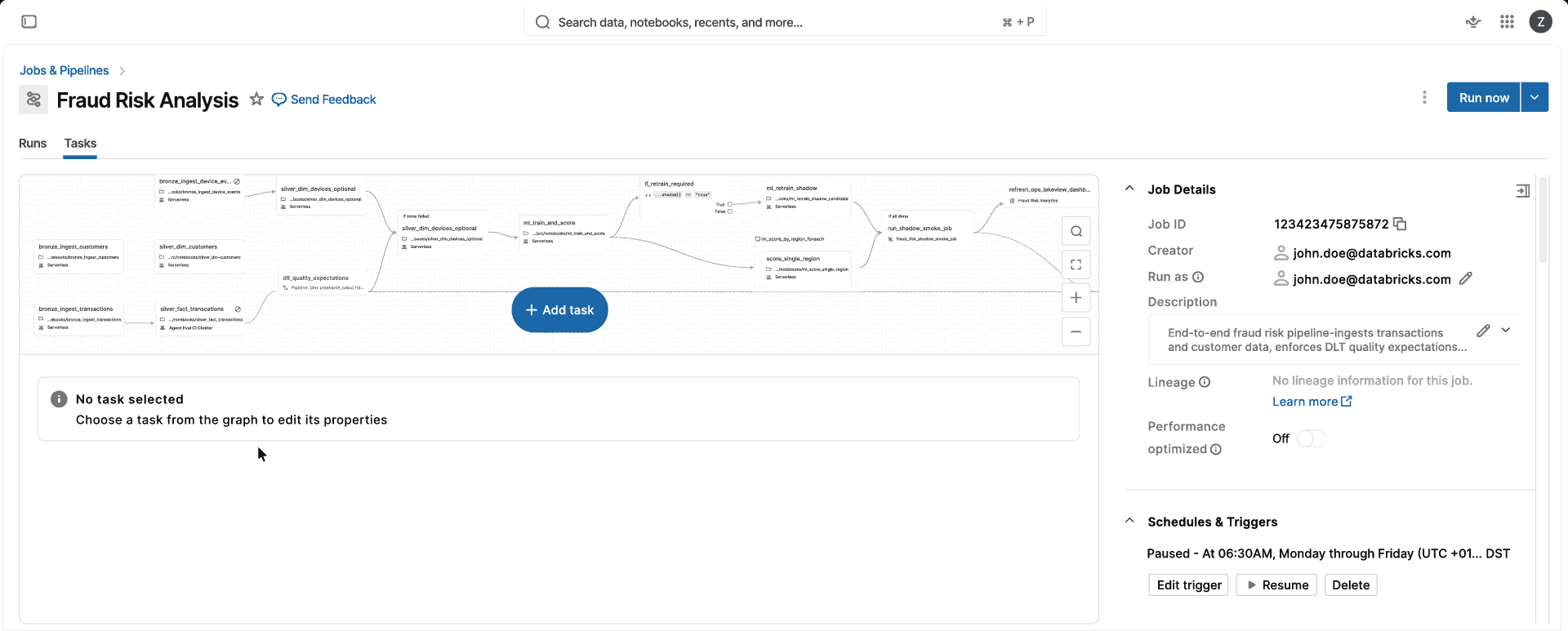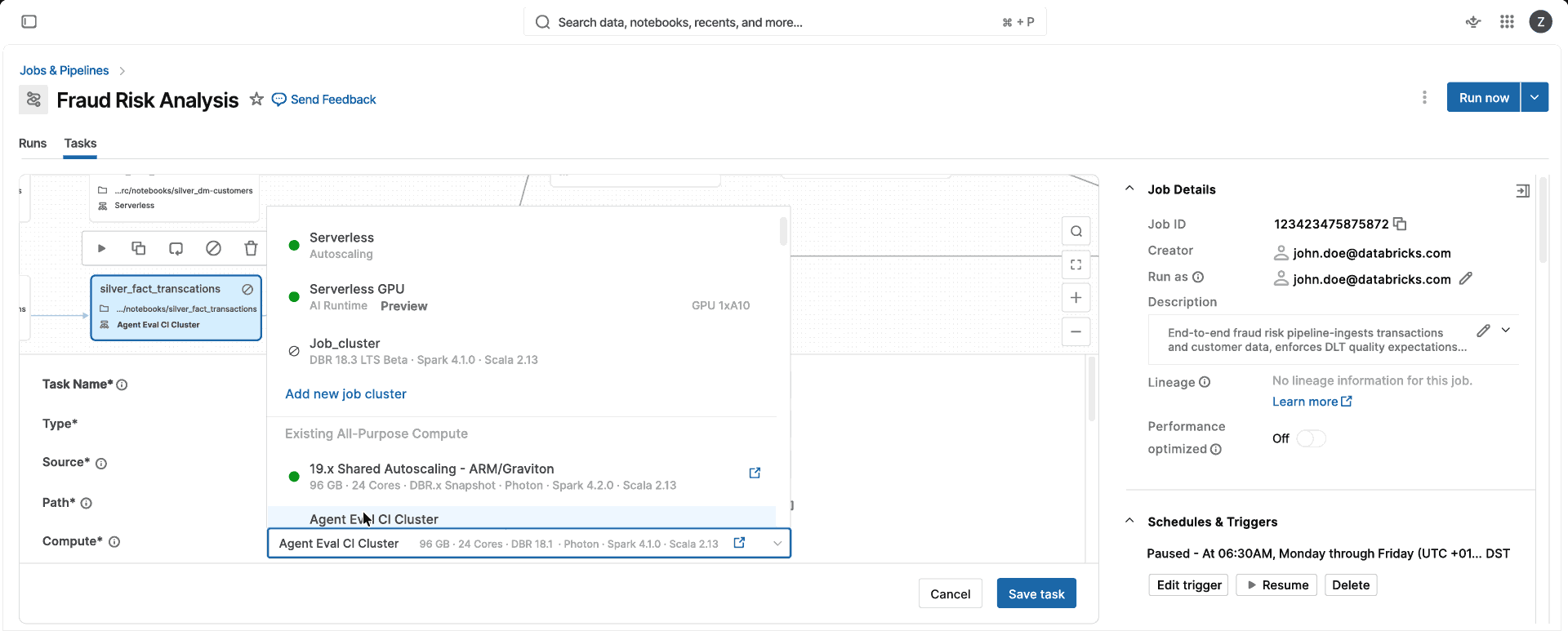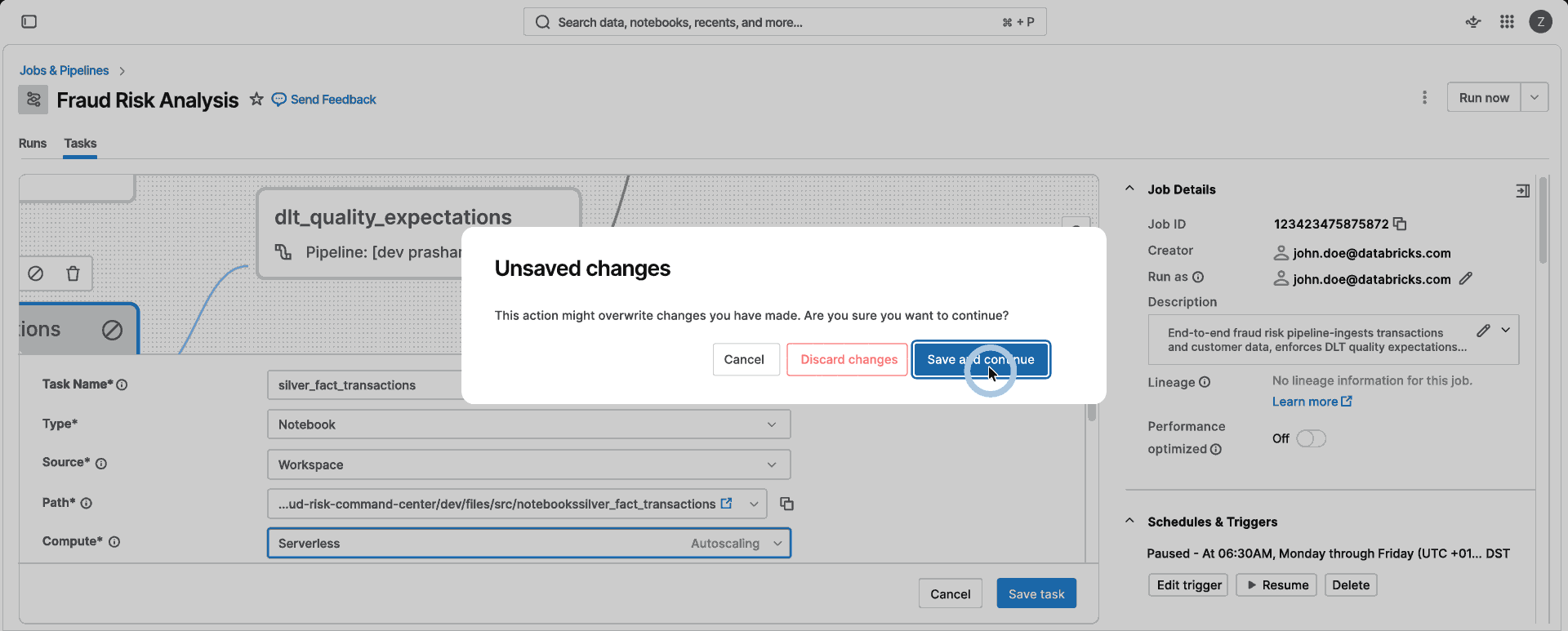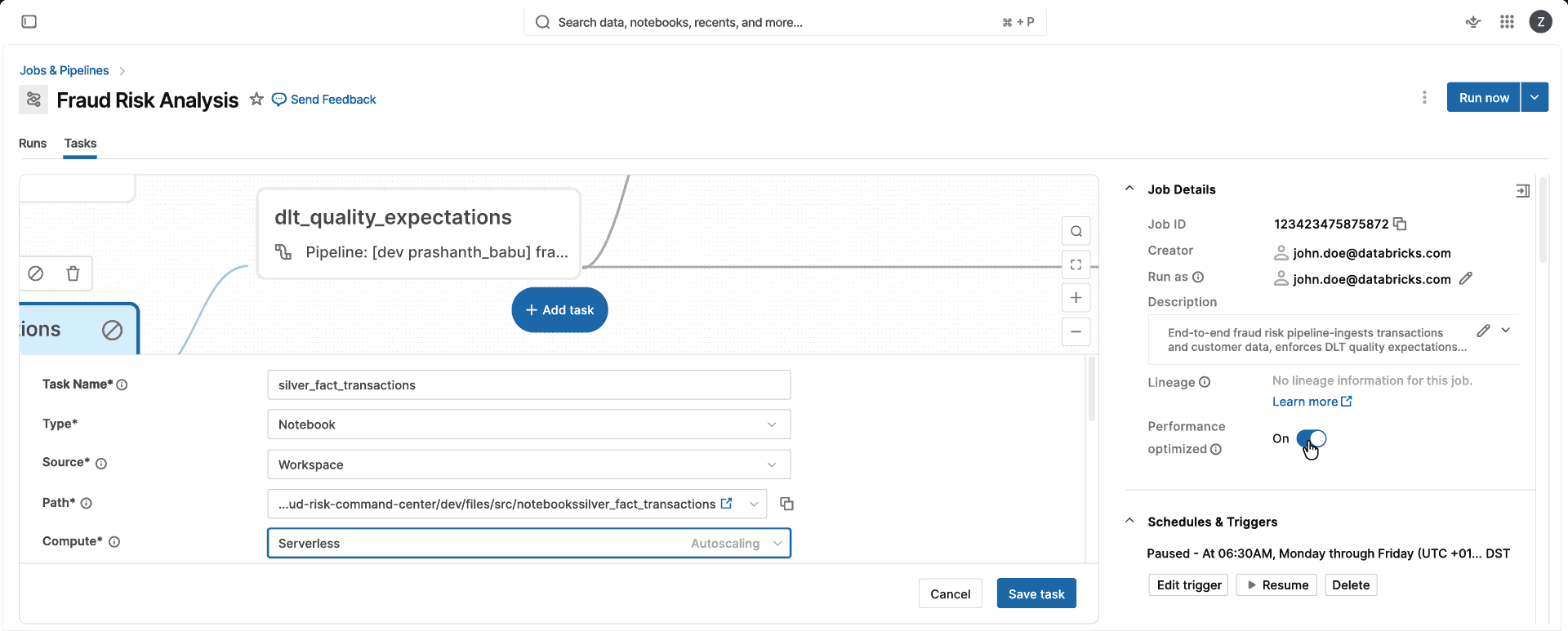
インフラストラクチャの管理をすることなく、自動的にスケーリング、アップグレード、最適化を行うコンピュートで、データとAIのワークロードを実行できます。フルマネージド型
コンピュート 1 つ。CPU 最適化、メモリ最適化、インスタンス クラスの判断、クラスター構成の管理は不要です。標準モードまたはパフォーマンス最適化モードを選択すると、Databricksがお客様に代わって適切なインスタンスとコンピュートの種類(単一VMまたはSparkクラスタ)を自動的に選択するため、チームはコンピュートの管理ではなく、データ製品の提供に集中できます。
高性能
Serverlessは、数分ではなく数秒で起動し、キャッシュから環境を読み込み、ワークロードの需要に合わせて自動的に規模を最適化します。標準モードではコスト効率の高いバッチ処理が可能な一方、パフォーマンス最適化モードでは通常、レイテンシの影響を受けやすいジョブを従来のクラスターよりも 2 倍高速に実行します。
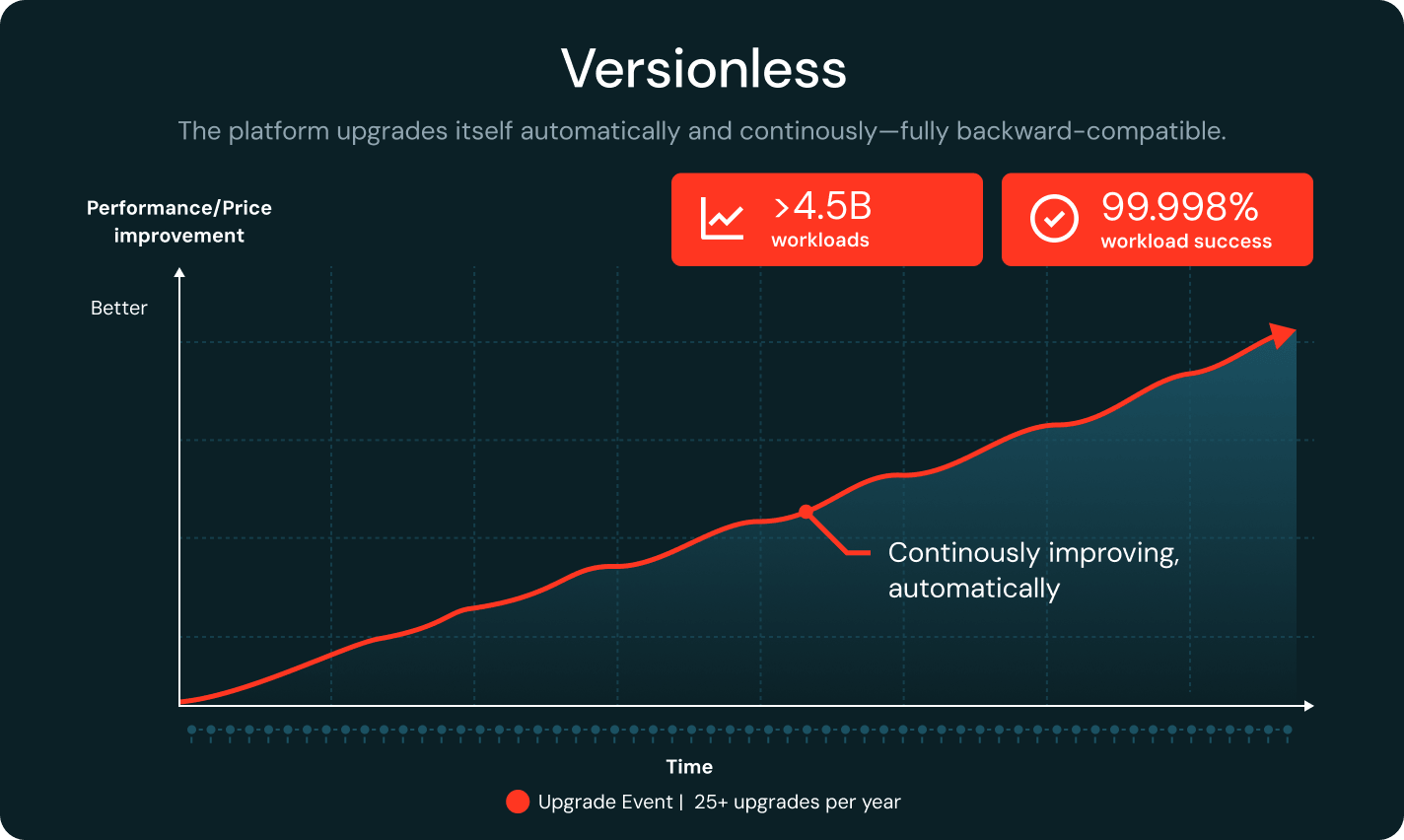
バージョンレス
Databricksは、完全な下位互換性を維持しながら、ランタイムを継続的にアップグレードしています。リグレッション検出機能が、ワークロードを安定したバージョンに自動的にピン留めします。年間 25 回以上のアップグレードと 99.998% のワークロード成功率により、チームはエンジニアリング時間を最大 20% 節約できます。
ちゃんと動くコンピュート
インフラストラクチャの管理をやめて、フルマネージド、オートスケール、バージョンレスのコンピューティングでデータと AI のワークロードを実行しましょう。Serverlessは、完全な後方互換性を維持しながら継続的かつ自動的にアップグレードされるため、介入なしでワークロードを実行し続けることができます。
コスト重視のバッチ ワークロードには標準モードを、レイテンシの影響を受けやすいジョブにはパフォーマンス最適化モード(��通常、従来のクラスタより 2 倍高速でジョブを実行)を選択してください。
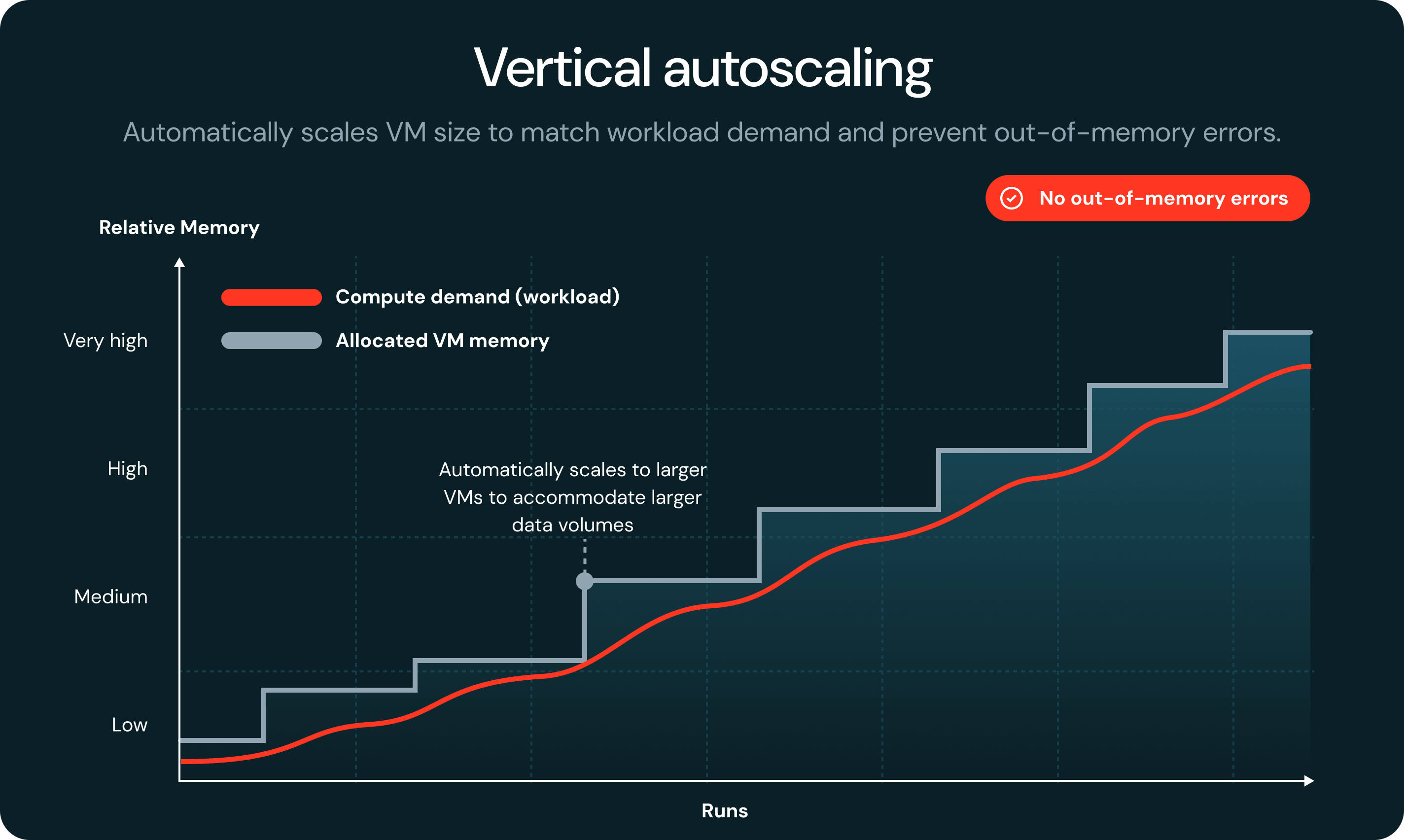
タスクでメモリ不足が発生した場合、Serverlessが自動的に障害を検出し、より大きな VM で再起動するため、ジョブの失敗や手動での介入は必要ありません。
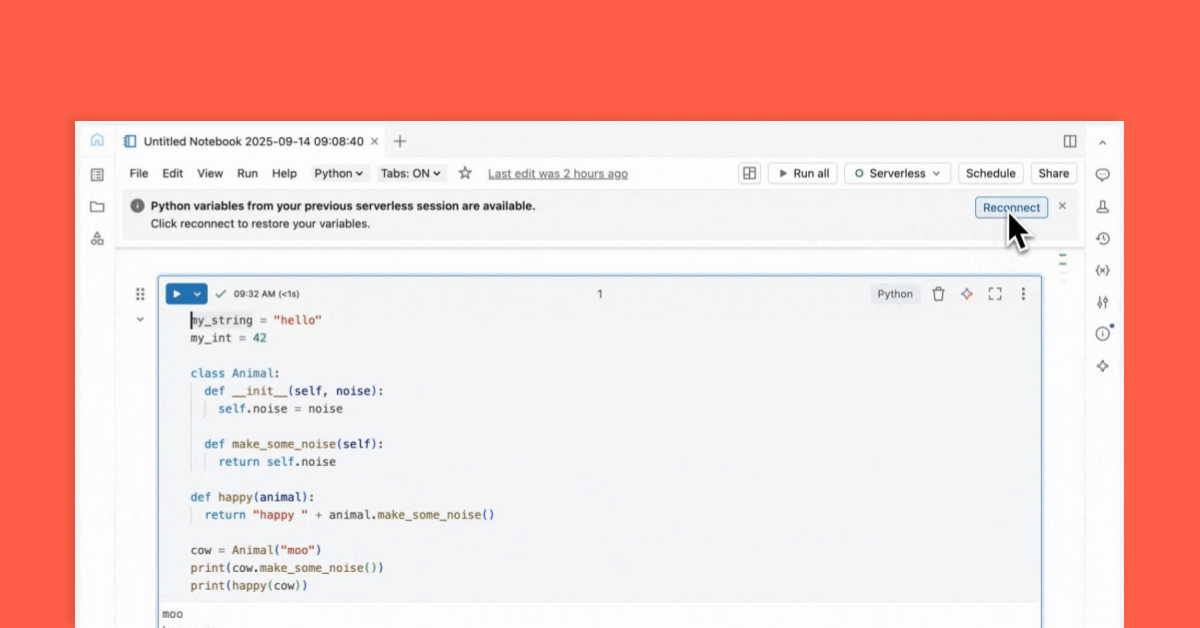
ライブラリ環境はグローバルにキャッシュされるため、組織内のユーザーが特定のパッケージセットで一度実行すると、他のすべてのユーザーも数秒でその環境を利用できるようになります。
Serverlessは、クラスター構成なしで、ワークロードの需要に合わせて自動的に適切なサイズに調整し、コンピュートを秒単位でスケールアップ/ダウンします。
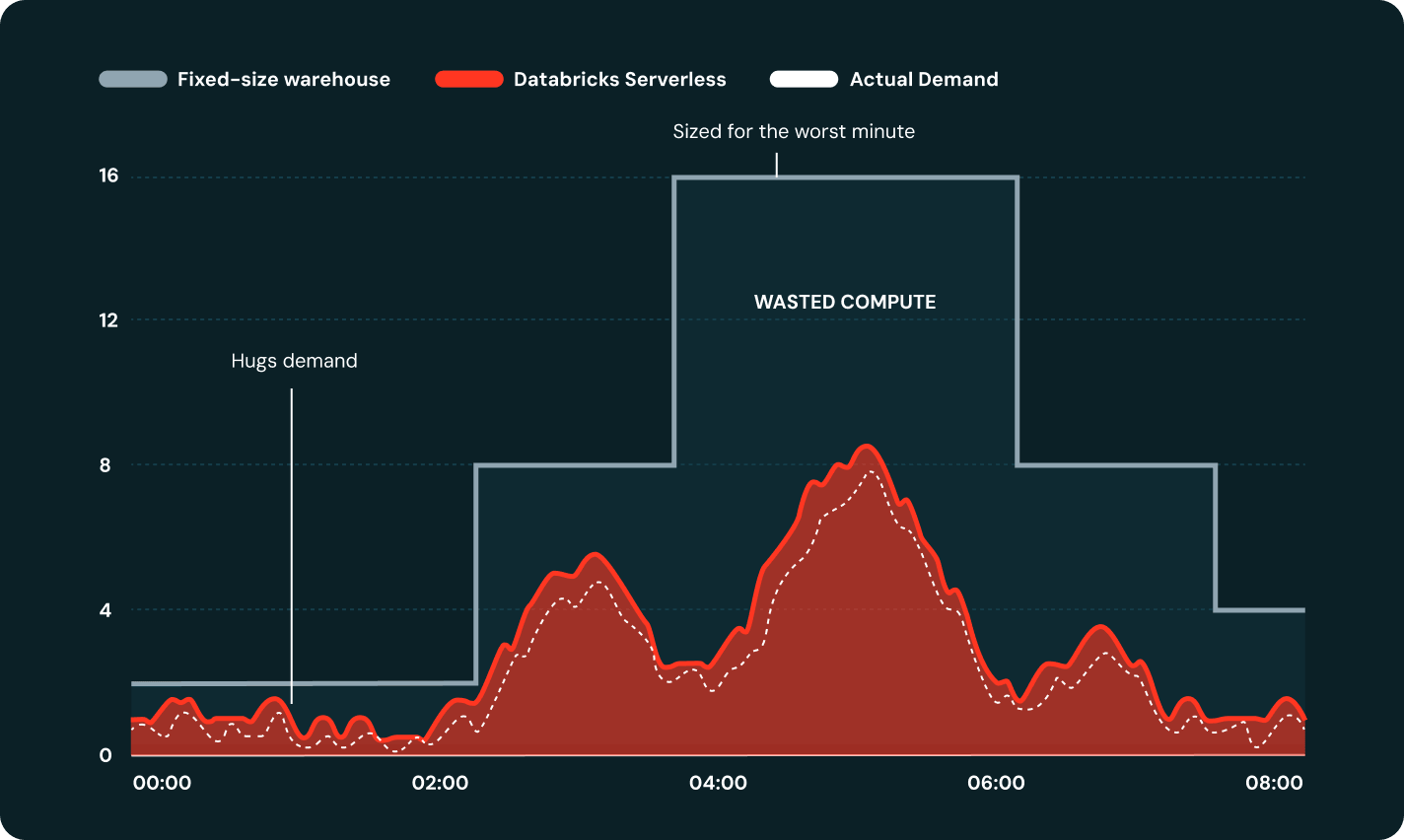
Serverlessは、失敗したタスクを自動的に再試行し、クラウドレベルの障害を迂回することで、オンコールでの介入なしにパイプラインをスケジュールどおりに維持します。
その他の機能
あらゆるワークロードにServerlessを

warehouse コンピュートを管理することなくデータにクエリーを実行
Databricks の Serverless SQL Warehouse は数秒で起動し、需要に合わせて自動的にスケールするため、アナリストはいつでもコンピューティングを利用できます。サイジングの決定、アイドル状態のクラスター、インフラのオーバーヘッドがありません。高速で信頼性の高いクエリーを。




使用量に応じた価格設定で、支出を抑制
使用した製品に対する秒単位での課金となります。さらに詳しく
Serverless コンピュートを搭載した製品について詳しく見る
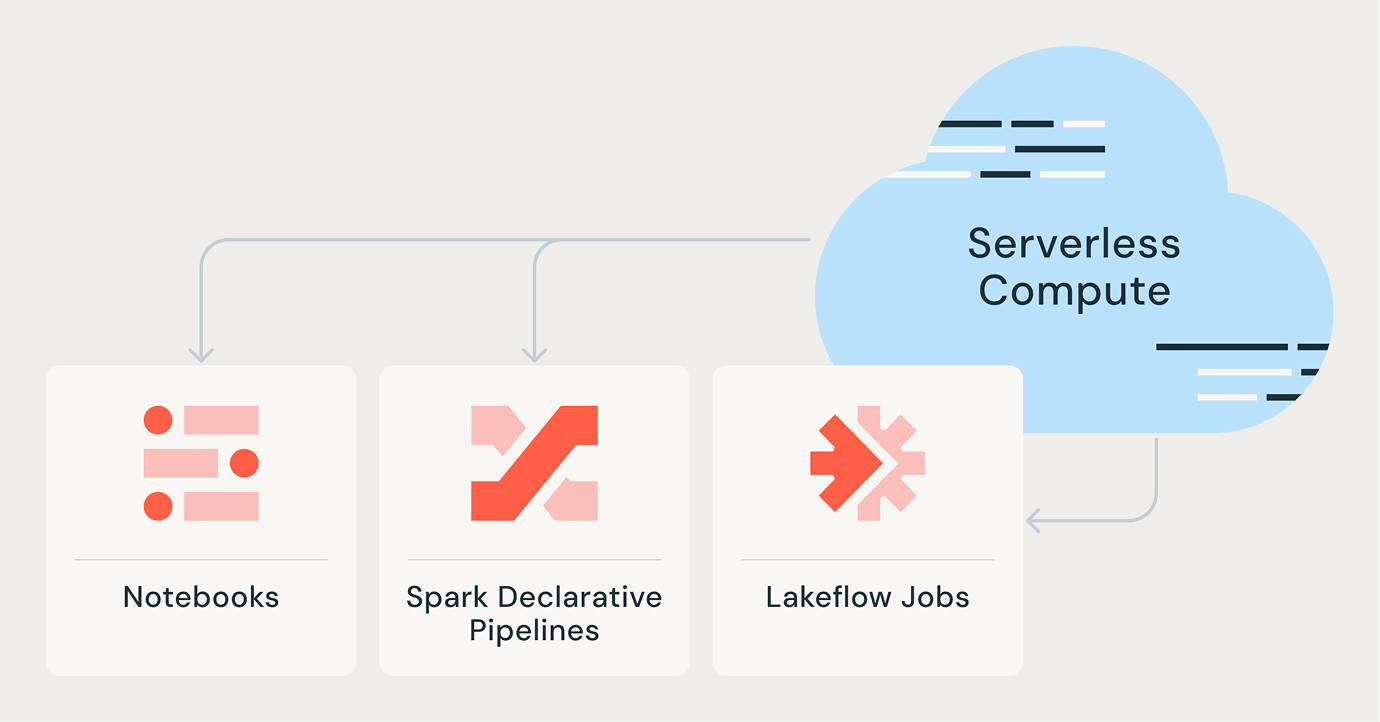
Lakeflow Jobs
高度な可観測性、高い信頼性、幅広いタスクタイプのサポートにより、チームはあらゆる ETL、アナリティクス、AI ワークフローをより適切に自動化およびオーケストレーションできるようになります。

Databricks SQL
lakehouse アーキテクチャ上に構築されたインテリジェントな自己最適化データウェアハウス。市場で最高の価格性能比を提供します。

Spark宣言型パイプライン
自動化されたデータ品質、チェンジデータキャプチャ(CDC)、データ取り込み、変換、および統合ガバナンスにより、バッチおよびストリーミングETLを簡素化します。

ノートブック
Databricks Collaborative Notebooks は、リアルタイムのコラボレーションと高効率なデータサイエンスワークフローを可能にし、チームの生産性を向上させます。

Databricks Apps
人気のフレームワーク、Serverlessデプロイ、組み込みのガバナンスを使用してアプリケーションを作成できます。複雑なインフラストラクチャ管理を必要とせずに、インパクトのあるソリューションをユーザーに提供します。

Lakebase
モダンな運用ワークロード向けに構築された、レイクハウス統合型Postgres。
次のステップへ
関連リソース