Databricks Lakehouse Platform에서의 데이터 웨어하우징 모델링 기법 및 구현
Lakehouse에서 Data Vault와 Star Schema 사용하기
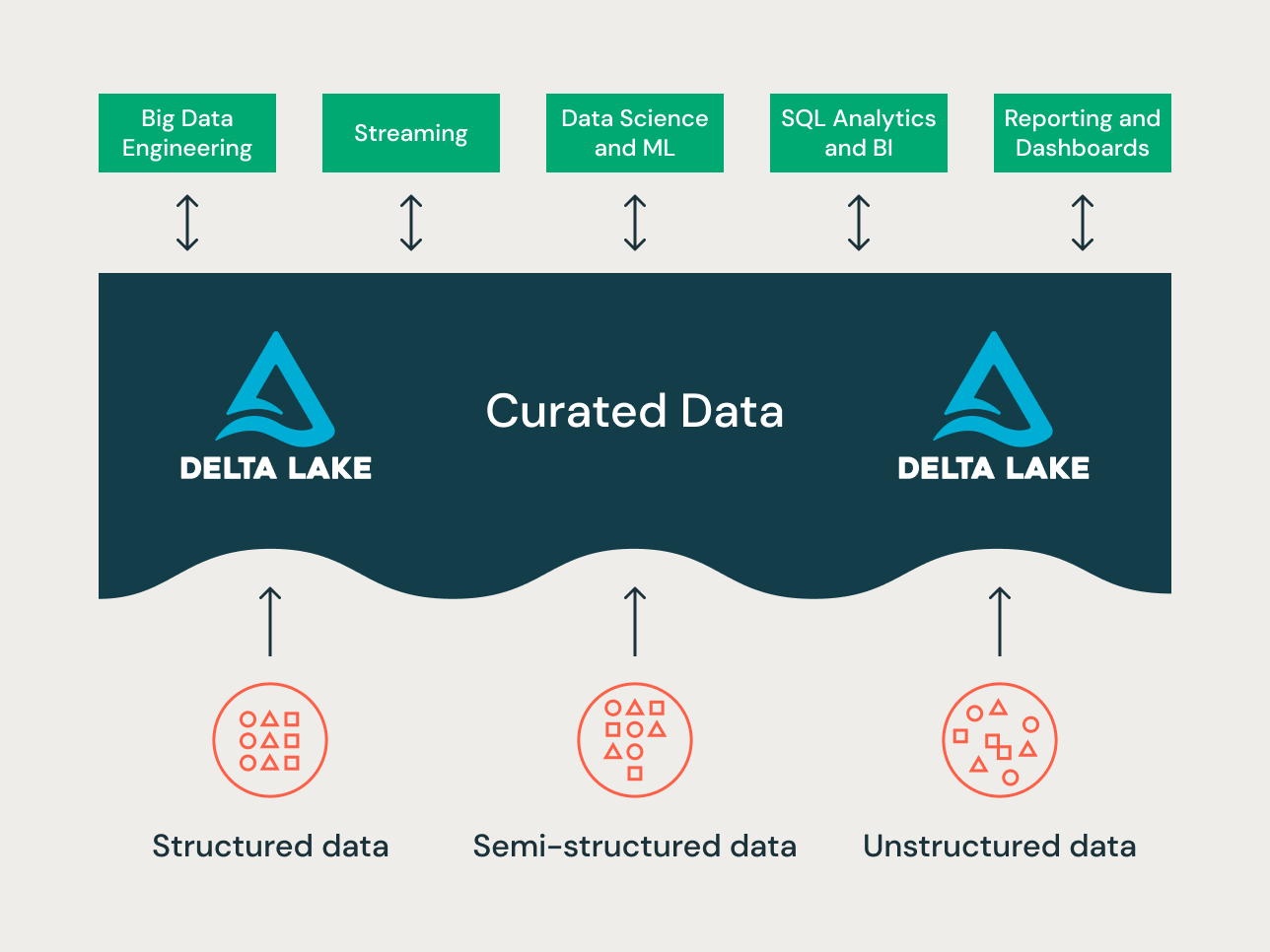
레이크하우스는 데이터 레이크와 데이터 웨어하우스의 최고의 기능을 결합한 새로운 데이터 플랫폼 패러다임입니다. 이는 다양한 사용 사례와 데이터 제품을 수용할 수 있는 대규모 엔터프라이즈급 데이터 플랫폼으로 설계되었습니다. 모든 데이터 도메인, 실시간 스트리밍 사용 사례, 데이터 마트, 분산된 데이터 웨어하우스, 데이터 과학 기능 스토어 및 데이터 과학 샌드박스, 부서별 셀프 서비스 분석 샌드박스에 대한 단일 통합 엔터프라이즈 데이터 저장소 역할을 할 수 있습니다.
사용 사례의 다양성을 고려할 때, 레이크하우스의 다른 프로젝트에는 다른 데이터 구성 원칙과 모델링 기술이 적용될 수 있습니다. 기술적으로 Databricks Lakehouse Platform은 다양한 데이터 모델링 스타일을 지원할 수 있습니다. 이 글에서는 레이크하우스의 브론즈/실버/골드 데이터 구성 원칙의 구현과 각 계층에 다양한 데이터 모델링 기술이 어떻게 적용되는지 설명하고자 합니다.
데이터 볼트란 무엇인가요?
데이터 볼트는 Kimball 및 Inmon 방식에 비해 엔터프라이즈 규모 분석을 위한 데이터 웨어하우스를 구축하는 데 사용되는 비교적 최신 데이터 모델링 설계 패턴입니다.
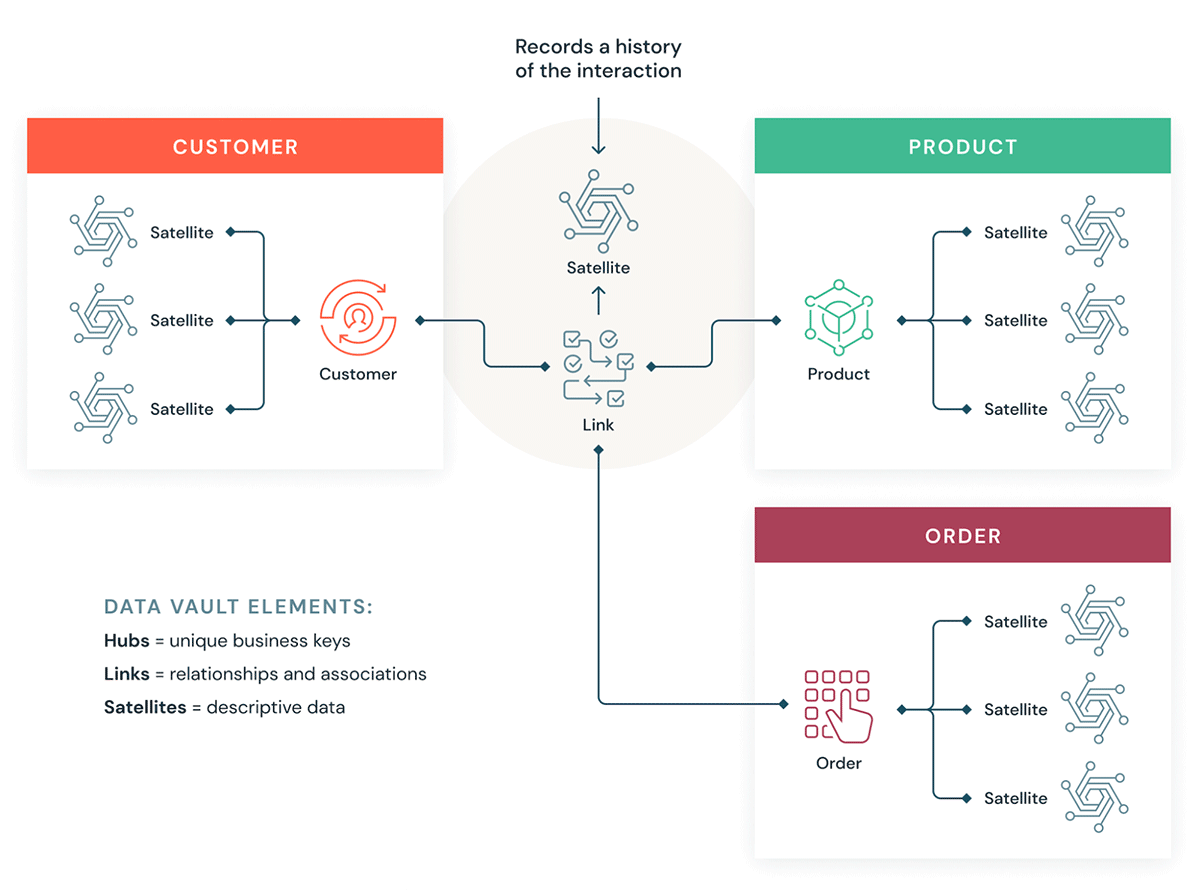
데이터 볼트는 데이터를 허브, 링크, 위성의 세 가지 유형으로 구성합니다. 허브는 핵심 비즈니스 엔터티를 나타내고, 링크는 허브 간의 관계를 나타내며, 위성은 허브 또는 링크에 대한 속성을 저장합니다.
데이터 볼트는 확장성, 데이터 통합/ETL 및 개발 속도가 중요한 민첩한 데이터 웨어하우스 개발에 중점을 둡니다. 대부분의 고객은 랜딩 존, 볼트 존, 데이터 마트 존을 가지고 있으며, 이는 Databricks 구성 패러다임의 브론즈, 실버, 골드 계층에 해당합니다. 허브, 링크, 위성 테이블의 데이터 볼트 모델링 스타일은 일반적으로 Databricks Lakehouse의 실버 계층에 잘 맞습니다.
데이터 볼트 모델링에 대한 자세한 내용은 Data Vault Alliance에서 알아보세요.
차원 모델링이란 무엇인가요?
차원 모델링은 분석을 위해 데이터 웨어하우스를 최적화하기 위한 하향식 접근 방식입니다. 차원 모델은 비즈니스 데이터를 차원(시간 및 제품 등)과 사실(금액 및 수량 기준 거래 등)으로 비정규화하는 데 사용되며, 다른 주제 영역은 통합 차원을 통해 연결되어 다른 사실 테이블로 이동할 수 있습니다.
차원 모델링의 가장 일반적인 형태는 스타 스키마입니다. 스타 스키마는 데이터를 이해하고 분석하기 쉽게 구성하여 보고서를 매우 쉽고 직관적으로 실행할 수 있도록 하는 다차원 데이터 모델입니다. Kimball 스타일의 스타 스키마 또는 차원 모델은 데이터 웨어하우스 및 데이터 마트의 프레젠테이션 계층, 심지어 의미론적 및 보고 계층에서도 거의 표준으로 사용됩니다. 스타 스키마 디자인은 대규모 데이터 세트 쿼리에 최적화되어 있습니다.
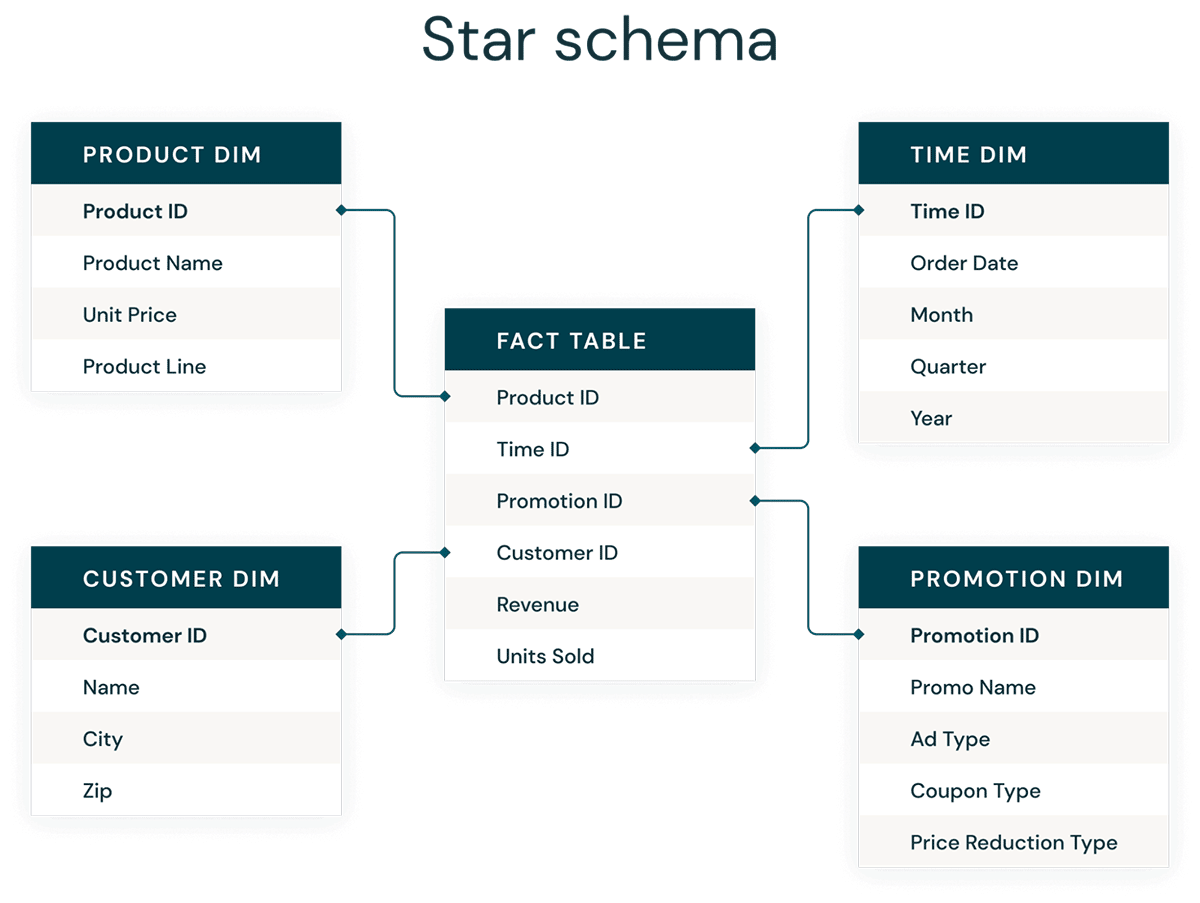
정규화된 데이터 볼트(쓰기 최적화)와 비정규화된 차원 모델(읽기 최적화) 데이터 모델링 스타일 모두 Databricks Lakehouse에서 사용될 수 있습니다. 실버 계층의 데이터 볼트 허브와 위성은 스타 스키마의 차원을 로드하는 데 사용되며, 데이터 볼트 링크 테이블은 차원 모델의 사실 테이블을 로드하는 핵심 드라이빙 테이블이 됩니다. Kimball Group에서 차원 모델링에 대해 자세히 알아보세요.
레이크하우스 각 계층의 데이터 구성 원칙
현대적인 레이크하우스는 포괄적인 엔터프라이즈급 데이터 플랫폼입니다. ETL, BI, 데이터 과학 및 스트리밍과 같이 서로 다른 데이터 모델링 접근 방식이 필요할 수 있는 모든 종류의 다양한 사용 사례에 대해 확장성과 성능이 뛰어납니다. 일반적인 레이크하우스가 어떻게 구성되는지 살펴보겠습니다.
브론즈 계층 — 랜딩 존
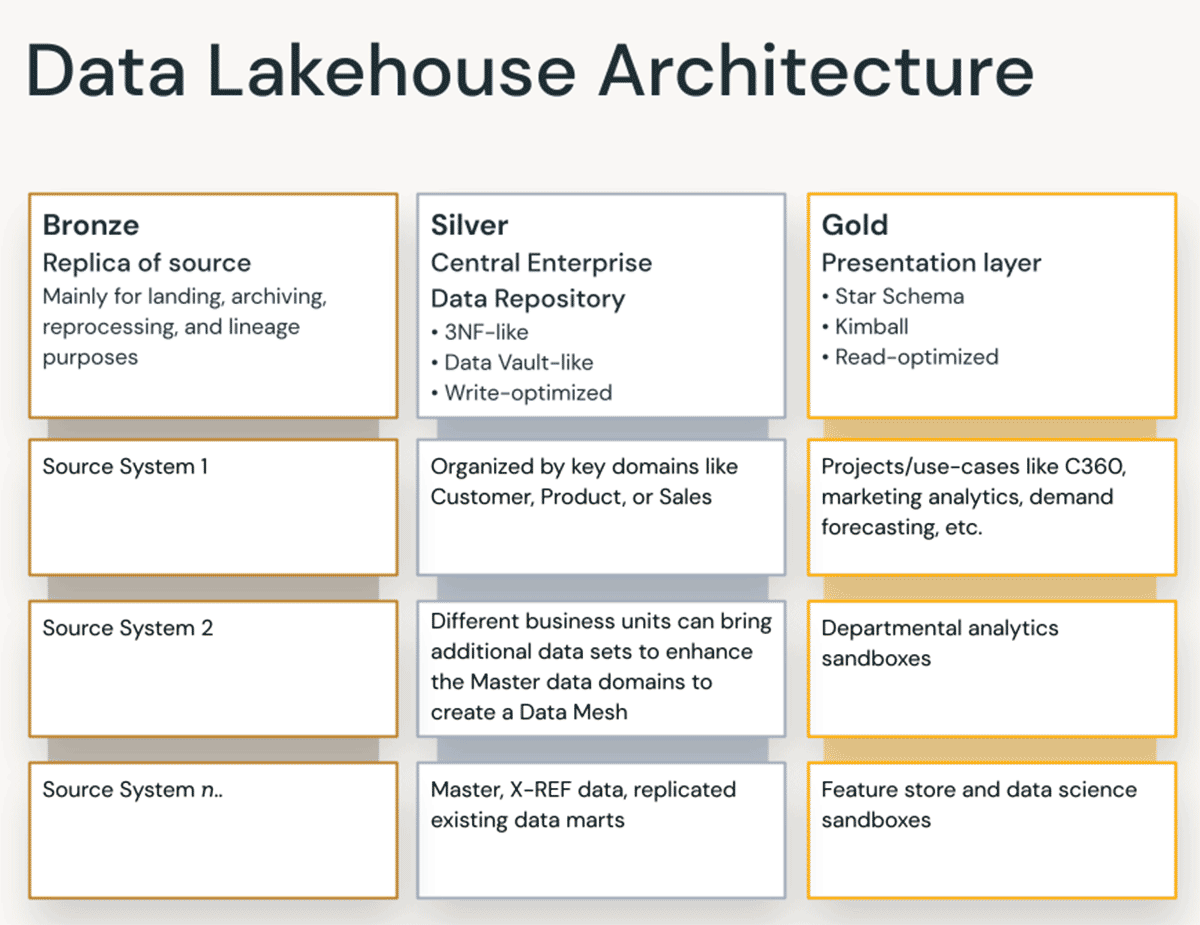
브론즈 계층은 소스 시스템의 모든 데이터를 수집하는 곳입니다. 이 계층의 테이블 구조는 로드 날짜/시간, 프로세스 ID 등을 캡처하기 위한 선택적 메타데이터 열을 제외하고는 소스 시스템 테이블 구조와 "있는 그대로" 일치합니다. 이 계층에서는 변경 데이터 캡처(CDC)에 중점을 두며, 소스 시스템에서 데이터를 다시 읽지 않고도 원본 데이터의 기록 보관소(콜드 스토리지), 데이터 계보, 감사 가능성 및 필요한 경우 재처리를 제공할 수 있습니다.
대부분의 경우, 브론즈 계층의 데이터를 Delta 형식으로 유지하는 것이 좋습니다. 이렇게 하면 ETL을 위한 브론즈 계층에서의 후속 읽기가 성능이 향상되고, 브론즈에서 업데이트를 수행하여 CDC 변경 사항을 기록할 수 있습니다. 때로는 데이터가 JSON 또는 XML 형식으로 도착할 때, 고객이 원본 소스 데이터 형식으로 데이터를 수집한 다음 Delta 형식으로 변경하여 스테이징하는 것을 볼 수 있습니다. 따라서 때로는 고객이 논리적 브론즈 계층을 물리적 랜딩 및 스테이징 존으로 구현하는 것을 볼 수 있습니다.
랜딩 존에 원본 소스 데이터 형식으로 원시 데이터를 저장하는 것은 Delta를 네이티브 싱크로 지원하지 않는 수집 도구를 통해 데이터를 수집하거나 소스 시스템이 개체 저장소에 직접 데이터를 덤프하는 경우 일관성을 유지하는 데 도움이 됩니다. 이 패턴은 소스에서 원시 파일용 랜딩 존에 데이터를 수집한 다음 Databricks AutoLoader가 데이터를 Delta 형식의 스테이징 계층으로 변환하는 자동 로더 수집 프레임워크와도 잘 맞습니다.
실버 계층 — 엔터프라이즈 중앙 리포지토리
레이크하우스의 실버 계층에서는 브론즈 계층의 데이터가 일치, 병합, 표준화 및 정리되어("필요한 만큼만") 실버 계층이 모든 핵심 비즈니스 엔터티, 개념 및 거래에 대한 "엔터프라이즈 뷰"를 제공할 수 있습니다. 이는 엔터프라이즈 운영 데이터 스토어(ODS) 또는 데이터 메시의 중앙 리포지토리 또는 데이터 도메인(예: 마스터 고객, 제품, 중복되지 않는 거래 및 교차 참조 테이블)과 유사합니다. 이 엔터프라이즈 뷰는 서로 다른 소스의 데이터를 통합하고, 애드혹 보고, 고급 분석 및 ML을 위한 셀프 서비스 분석을 가능하게 합니다. 또한 부서별 분석가, 데이터 엔지니어 및 데이터 과학자가 골드 계층의 엔터프라이즈 및 부서별 데이터 프로젝트를 통해 비즈니스 문제를 해결하기 위한 데이터 프로젝트 및 분석을 추가로 생성하는 소스 역할을 합니다.
레이크하우스 데이터 엔지니어링 패러다임에서는 일반적으로 전통적인 추출-변환-로드(ETL) 방식 대신 추출-로드-변환(ELT) 방법론을 따릅니다. ELT 접근 방식은 실버 계층을 로드하는 동안 최소한의 변환 또는 "필요한 만큼만" 변환 및 데이터 정리 규칙만 적용된다는 것을 의미합니다. 모든 "엔터프라이즈 수준" 규칙은 프로젝트별 변환 규칙과 달리 실버 계층에서 적용되며, 이는 골드 계층에서 적용됩니다. 레이크하우스에서 데이터를 수집하고 제공하는 속도와 민첩성이 여기서 우선시됩니다.
데이터 모델링 관점에서 볼 때, 실버 계층은 3차 정규형과 유사한 �데이터 모델을 더 많이 가지고 있습니다. 데이터 볼트와 같은 쓰기 성능이 뛰어난 데이터 아키텍처 및 데이터 모델을 이 계층에서 사용할 수 있습니다. 데이터 볼트 방법론을 사용하는 경우, 원시 데이터 볼트와 비즈니스 볼트 모두 레이크의 논리적 실버 계층에 적합하며, 시점(PIT) 프레젠테이션 뷰 또는 구체화된 뷰는 골드 계층에 표시됩니다.
골드 계층 — 프레젠테이션 계층
골드 계층에서는 차원 모델링/Kimball 방법론에 따라 여러 데이터 마트 또는 웨어하우스를 구축할 수 있습니다. 앞서 논의한 바와 같이, 골드 계층은 보고를 위한 것이며 실버 계층에 비해 조인이 적은 비정규화되고 읽기 최적화된 데이터 모델을 사용합니다. 때로는 데이터 과학자가 기능 엔지니어링을 위해 알고리즘에 공급하기를 원할 경우 골드 계층의 테이블이 완전히 비정규화될 수도 있습니다.
ETL 및 데이터 품질 규칙은 Silver 레이어에서 Gold 레이어로 데이터를 변환할 때 "프로젝트별"로 적용됩니다. 데이터 웨어하우스, 데이터 마트 또는 고객 분석, 제품/품질 분석, 재고 분석, 고객 세분화, 제품 추천, 마케팅/영업 분석 등과 같은 데이터 제품과 같은 최종 프레젠테이션 레이어는 이 레이어에서 제공됩니다. Kimball 스타일 스타 스키마 기반 데이터 모델 또는 Inmon 스타일 데이터 마트는 Lakehouse의 이 Gold 레이어에 적합합니다. 자체 서비스 분석을 위한 데이터 과학 연구소 및 부서 샌드박스도 Gold 레이어에 속합니다.
Lakehouse 데이터 구성 패러다임
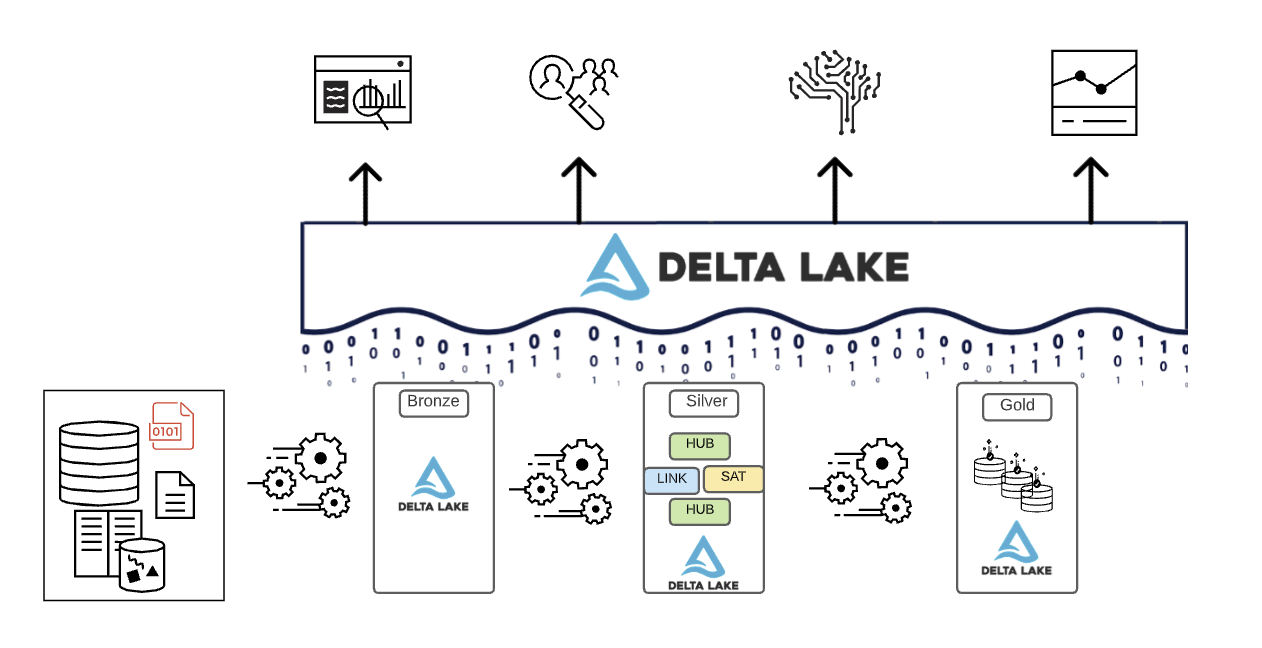
요약하자면, 데이터는 Lakehouse의 다양한 레이어를 거치면서 큐레이션됩니다.
- Bronze 레이어는 소스 시스템의 데이터 모델을 사용합니다. 데이터가 원시 형식으로 수집되면 이 레이어 내에서 Delta Lake 형식으로 변환됩니다.
- Silver 레이어는 여러 소스의 데이터를 처음으로 통합하고 이를 조정하여 엔터프라이즈 데이터 뷰를 생성합니다. 일반적으로 3차 정규형 또는 Data Vault와 유사한, 쓰기에 최적화된 데이터 모델을 사용합니다.
- Gold 레이어는 Silver 레이어보다 비정규화되거나 평면화된 데이터 모델을 가진 프레젠테이션 레이어이며, 일반적으로 Kimball 스타일의 차원 모델 또는 스타 스키마를 사용합니다. Gold 레이어에는 엔터프라이즈 전반에 걸쳐 자체 서비스 분석 및 데이터 과학을 지원하기 위한 부서 및 데이터 과학 샌드박스도 있습니다. 이러한 샌드박스와 자체 별도의 컴퓨팅 클러스터를 제공하면 비즈니스 팀이 Lakehouse 외부에서 자체 데이터 복사본을 만드는 것을 방지할 수 있습니다.
이 Lakehouse 데이터 구성 접근 방식은 데이터 사일로를 해소하고 팀을 통합하며, 적절한 거버넌스를 통해 단일 플랫폼에서 ETL, 스트리밍, BI 및 AI를 수행할 수 있도록 지원하는 것을 목표로 합니다. 중앙 데이터 팀은 조직 내 혁신을 촉진하고, 새로운 자체 서비스 사용자 온보딩 및 다수의 데이터 프로젝트 병렬 개발을 가속화해야 하며, 데이터 모델링 프로세스가 병목 현상이 되지 않도록 해야 합니다. Databricks Unity Catalog는 Lakehouse에 대한 검색 및 검색, 거버넌스 및 계보를 제��공하여 우수한 데이터 거버넌스 체계를 보장합니다.
지금 Databricks SQL로 Data Vault 및 스타 스키마 데이터 웨어하우스를 구축하세요.
추가 자료:
- Delta Lake를 사용하여 Databricks에서 스타 스키마를 구현하는 5가지 간단한 단계
- Databricks Lakehouse 플랫폼에서 Data Vault 모델을 구현하기 위한 모범 사례
- 차원 모델링 모범 사례 및 최신 Lakehouse 구현
- 대리 키 생성을 위한 ID 열이 이제 가까운 Lakehouse에서 제공됩니다!
- Databricks Lakehouse를 사용하여 EDW 차원 모델을 실시간으로 로드
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.