Databricks 레이크하우스 플랫폼에서 데이터 볼트 모델을 구현하는 규범적 지침
분석 시스템을 설계할 때 산업별 도메인 모델, Kimball, Inmon, 데이터 볼트(Data Vault) 방법론 등 다양한 데이터 모델을 사용할 수 있습니다. 고유한 요구사항에 따라 lakehouse를 설계할 때 이러한 다양한 모델링 기법을 사용할 수 있습니다. 이들 모두 각자의 강점이 있으며, 각각 다양한 사용 사례에 적합할 수 있습니다.
궁극적으로 데이터 모델은 일대일, 일대다, 다대다 관계가 정의된 다양한 테이블을 정의하는 구성일 뿐입니다. 데이터 플랫폼은 더 쉬운 정보 검색과 향상된 성능을 위해 데이터 모델을 물리화하는 모범 사례를 제공해야 합니다.
이전 기사에서는 Databricks와 Delta Lake로 스타 스키마를 구현하는 5가지 간단한 단계를 다루었습니다. 이 아티클에서는 Data Vault가 무엇인지, Bronze/Silver/Gold 레이어 내에서 구현하는 방법, 그리고 Databricks Lakehouse Platform으로 Data Vault의 최상의 성능을 얻는 방법을 설명합니다.
데이터 볼트 모델링 정의
데이터 볼트 모델링의 목표는 빠르게 변화하는 비즈니스 요구사항에 적응하고 설계상 데이터 웨어하우스의 더 빠르고 민첩한 개발을 지원하는 것입니다. 데이터 볼트는 허브, 링크, 새털라이트 설계를 통해 데이터 모델이 쉽게 확장 가능하고 세분화되어 설�계 및 ETL 변경을 쉽게 구현할 수 있으므로 레이크하우스 방법론에 매우 적합합니다.
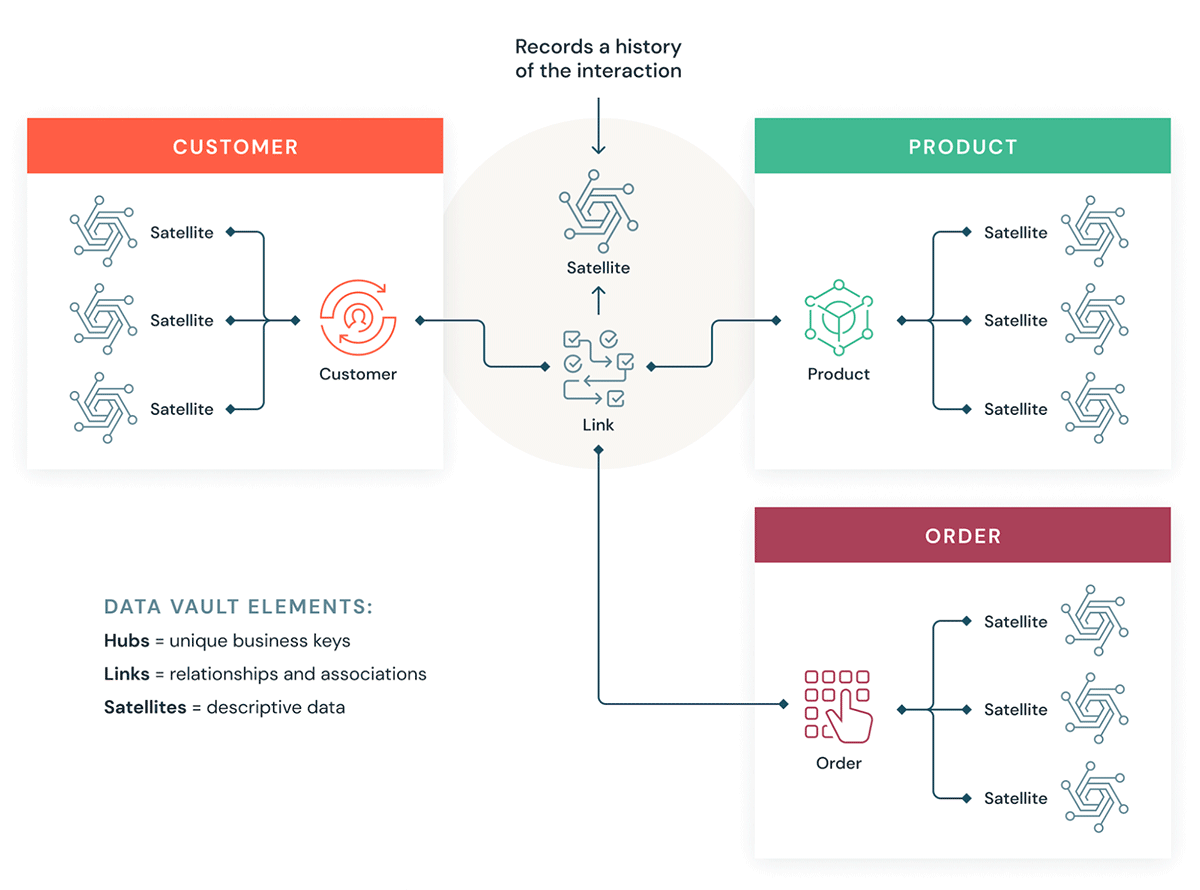
Data Vault의 몇 가지 구성 요소를 알아보겠습니다. 일반적으로 데이터 볼트 모델에는 세 가지 유형의 엔터티가 있습니다.
- 허브 — 허브는 고객, 제품, 주문 등과 같은 핵심 비즈니스 엔터티를 나타냅니다. 애널리스트는 자연 키/비즈니스 키를 사용하여 허브에 대한 정보를 얻습니다. 허브 테이블의 기본 키는 일반적으로 비즈니스 개념 ID, 로드 날짜 및 기타 메타데이터 정보의 조합으로 파생됩니다.
- 링크 - 링크는 허브 엔터티 간의 관계를 나타냅니다. 조인 키만 있습니다. 차원 모델의 팩트 없는 팩트 테이블과 같습니다. 속성은 없고 조인 키만 있습니다.
- 새틀라이트 — 새틀라이트 테이블은 허브 또는 링크에 있는 엔터티의 속성을 가집니다. 핵심 비즈니스 엔터티에 대한 설명 정보를 담고 있습니다. 차원 테이블의 정규화된 버전과 유사합니다. 예를 들어, 고객 허브는 고객 지리적 속성, 고객 신용 점수, 고객 충성도 등급 등과 같은 여러 새털라이트 테이블을 가질 수 있습니다.
데이터 볼트 방법론을 사용하는 주요 이점 중 하나는 데이터 모델이 변경될 때 기존 ETL 작업의 리팩터링이 현저히 줄어든다는 것입니다. 데이터 볼트는 '쓰기 최적화된' 모델링 스타일이며 애자일 개발 방식을 지원하고 데이터 레이크 및 lakehouse 방식에 매우 적합합니다.
레이크하우스의 데이터 볼트 활용법
일부 고객이 Databricks Lakehouse 아키텍처에서 데이터 볼트 모델링(Data Vault Modeling)을 어떻게 사용하고 있는지 살펴보겠습니다.
Databricks Lakehouse에서 데이터 볼트 모델을 구현하기 위한 고려 사항
- 데이터 볼트 모델링은 비즈니스 키의 해시를 기본 키로 사용할 것을 권장합니다. Databricks는 비즈니스 키를 지원하기 위해 해시, md5 및 SHA 함수를 기본적으로 지원합니다.
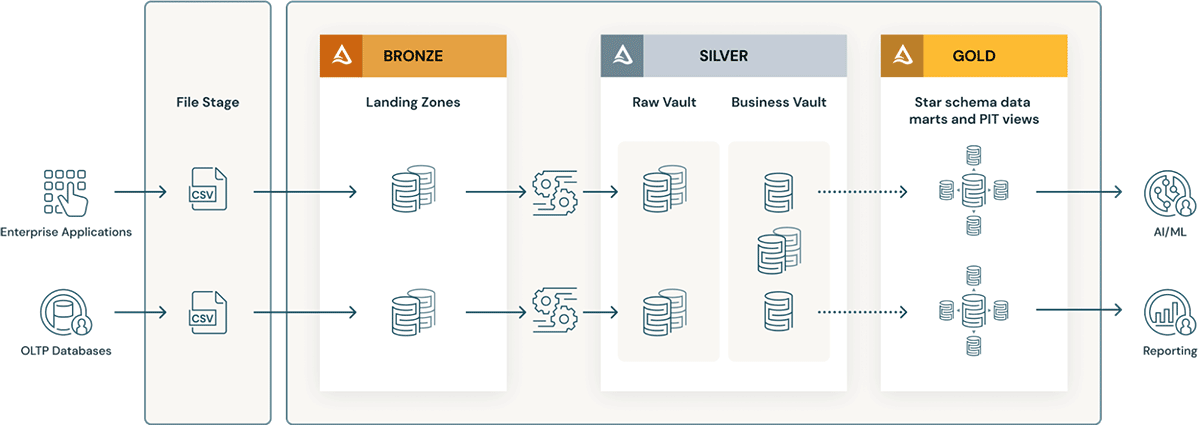
- Data Vault 계층에는 랜딩 영역(때로는 스테이징 영역)의 개념이 있습니다. 이 두 물리적 계층은 모두 데이터 레이크하우스의 브론즈 계층에 자연스럽게 들어맞습니다. 랜딩 영역 데이터가 Avro, CSV, parquet, XML, JSON 형식 등으로 도착하면 스테이징 영역에서 Delta 형식 테이블로 변환되어 후속 ETL이 고성능을 �발휘할 수 있습니다.
- Raw Vault는 랜딩 또는 스테이징 영역에서 생성됩니다. 데이터는 가공되지 않은 데이터 볼트에서 허브, 링크, 새틀라이트 테이블로 모델링됩니다. 가공되지 않은 데이터 볼트를 로드하는 동안에는 일반적으로 추가적인 '비즈니스' ETL 규칙이 적용되지 않습니다.
- 모든 ETL 비즈니스 규칙, 데이터 품질 규칙, 정제 및 준수 규칙은 Raw와 Business Vault 사이에 적용됩니다. 비즈니스 볼트 테이블은 데이터 도메인별로 구성할 수 있으며, 이는 표준화되고 정제된 데이터의 기업용 "중앙 리포지토리" 역할을 합니다. 데이터 스튜어드와 SME(주제 전문가)는 Business Vault의 해당 영역에 대한 거버넌스, 데이터 품질 및 비즈니스 규칙을 담당합니다.
- 특정 시점(PIT) 및 브리지 테이블과 같은 쿼리 헬퍼 테이블은 비즈니스 볼트 위에 있는 프레젠테이션 레이어를 위해 생성됩니다. PIT 테이블은 일부 새틀라이트와 허브를 사전 조인하고 '특정 시점' 필터링으로 일부 WHERE 조건을 제공하여 쿼리 성능을 향상시킵니다. 브리지 테이블은 허브 또는 엔터티를 사전 조인하여 엔터티에 대해 평면화된 '차원 테이블'과 같은 뷰를 제공합니다. Delta Live Tables 는 구체화된 뷰와 정확히 같으며, 비즈니스 데이터 볼트 위에 있는 골드/프레젠테이션 레이어에서 특정 시점 테이블과 브리지 테이블을 생성하는 데 사용될 수 있습니다.
- 비즈니스 프로세스가 변경되고 조정됨에 따라 데이터 볼트 모델은 차원 모델과 같은 대규모 리팩터링 없이도 쉽게 확장할 수 있습니다. 추가 허브(주제 영역)는 링크(순수 조인 테이블) 및 추가 새틀라이트에 쉽게 추가할 수 있습니다(예: 고객 세분화)는 최소한의 변경으로 Hub(고객)에 추가할 수 있습니다.
- 또한 다음과 같은 이유로 골드 레이어에 차원 모델 데이터 웨어하우스를 로드하는 것이 더 쉬워집니다.
- Hub는 키 관리를 더 쉽게 만듭니다(Hub의 자연 키는 ID 열을 통해 대리 키로 변환될 수 있습니다).
- 새틀라이트는 모든 속성을 포함하므로 차원을 더 쉽게 로드할 수 있습니다.
- 링크는 모든 관계를 포함하고 있기 때문에 팩트 테이블 로딩을 매우 간단하게 만듭니다.
Databricks Lakehouse의 데이터 볼트 모델에서 최상의 성능을 얻기 위한 팁
- 원시 볼트, 비즈니스 볼트 및 골드 레이어 테이블에 델타 형식 테이블을 사용하세요.
- Hub, Link, Satellite의 모든 조인 키에 OPTIMIZE 및 Z-순서 인덱스를 사용해야 합니다.
- 테이블, 특히 더 작은 새털라이트 테이블을 과도하게 파티션하지 마세요. 최상의 성능을 보장하려면 일반적으로 필터링되는 날짜 열, 현재 플래그 열, 조건자 열에 블룸 필터 인덱싱 을 사용하세요. 특히 Z-order 외에 추가 인덱스를 생성해야 하는 경우 더욱 중요합니다.
- Delta Live Tables(구체화된 뷰)를 사용하면 PIT 테이블을 매우 쉽게 생성하고 관리할 수 있습니다.
optimize.maxFileSize를 기본값인 1GB 대신 32~64MB와 같이 더 낮은 값으로 줄이세요. 더 작은 파일을 생성하면 파일 프루닝(file pruning)의 이점을 얻고 조인에 필요한 데이터를 검색하는 I/O를 최소화할 수 있습니다.- Data Vault 모델은 비교적 조인이 많으므로, 최상의 조인 전략이 자동으로 사용되도록 적응형 쿼리 실행이 기본적으로 ON 상태인 최신 버전의 DBR을 사용하세요. 필요한 경우에만 조인 힌트 를 사용하세요. (고급 성능 튜닝용).
Data Vault Alliance에서 데이터 볼트 모델링에 대해 자세히 알아보세요.
Lakehouse에서 Data Vault 구축을 시작해 보세요.
Databricks 무료 14일 사용하기
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.