Databricks Lakeflow 소개: 통합되고 지능적인 데이터 엔지니어링 솔루션
데이터베이스, 엔터프라이즈 앱 및 클라우드 소스에서 데이터를 수집하고, 배치 및 실시간 스트리밍으로 변환하고, 프로덕션에 자신 있게 배포하고 운영하세요.
작성자: Michael Armbrust , Bilal Aslam
오늘, Databricks Lakeflow를 발표하게 되어 기쁩니다. Databricks Lakeflow는 프로덕션 데이터 파이프라인을 구축하고 운영하는 데 필요한 모든 것을 담은 새로운 솔루션입니다. SQL Server와 같은 데이터베이스 및 Salesforce, Workday, Google Analytics, ServiceNow, SharePoint와 같은 엔터프라이즈 애플리케이션을 위한 새롭고 네이티브이며 확장성이 뛰어난 커넥터를 포함합니다. 사용자는 표준 SQL 및 Python을 사용하여 배치 및 스트리밍 데이터를 변환할 수 있습니다. 또한 Apache Spark의 실시간 모드를 발표하여 마이크로 배치보다 훨씬 빠른 지연 시간으로 스트림 처리를 가능하게 합니다. 마지막으로 CI/CD를 사용하여 워크플로를 오케스트레이션하고 모니터링하며 프로덕션에 배포할 수 있습니다. Databricks Lakeflow는 Data Intelligence Platform에 네이티브로 통합되어 서버리스 컴퓨팅 및 Unity Catalog를 통한 통합 거버넌스를 제공합니다.

이 블로그 게시물에서는 Lakeflow가 데이터 팀이 안정적인 데이터 및 AI에 대한 증가하는 수요를 충족하는 데 어떻게 도움이 될 것이라고 믿는 이유와 단일 제품 경험으로 통합된 Lakeflow의 주요 기능을 논의합니다.
안정적인 데이터 파이프라인 구축 및 운영의 과제
데이터 엔지니어링 - 신선하고 고품질이며 신뢰할 수 있는 데이터를 수집하고 준비하는 것 - 은 비즈니스에서 데이터와 AI를 민주화하는 데 필요한 요소입니다. 그러나 이를 달성하는 것은 여전히 복잡하며 많은 다른 도구를 연결해야 합니다.
첫째, 데이터 팀은 각기 다른 형식과 �액세스 방법을 가진 여러 시스템에서 데이터를 수집해야 합니다. 이를 위해서는 데이터베이스 및 엔터프라이즈 애플리케이션을 위한 자체 커넥터를 구축하고 유지 관리해야 합니다. 엔터프라이즈 애플리케이션의 API 변경 사항을 따라가는 것만으로도 전체 데이터 팀에게는 풀타임 직업이 될 수 있습니다. 그런 다음 배치 및 스트리밍 모두에서 데이터를 준비해야 하며, 이는 트리거링 및 증분 처리를 위한 복잡한 로직을 작성하고 유지 관리해야 합니다. 지연 시간이 급증하거나 오류가 발생하면 알림을 받고, 불행한 데이터 소비자가 발생하며, 비즈니스에 영향을 미쳐 수익에 영향을 미치는 중단이 발생합니다. 마지막으로 데이터 팀은 CI/CD를 사용하여 이러한 파이프라인을 배포하고 데이터 자산의 품질 및 계보를 모니터링해야 합니다. 이를 위해서는 일반적으로 Prometheus 또는 Grafana와 같은 완전히 새로운 도구를 배포, 학습 및 관리해야 합니다.
이것이 바로 데이터 인텔리전스로 구동되는 데이터 수집, 변환 및 오케스트레이션을 위한 통합 솔루션인 Lakeflow를 구축하기로 결정한 이유입니다. 세 가지 주요 구성 요소는 다음과 같습니다: Lakeflow Connect, Lakeflow Pipelines 및 Lakeflow Jobs.
Lakeflow Connect: 간단하고 확장 가능한 데이터 수집
Lakeflow Connect는 SQL Server와 같은 데이터베이스 및 Salesforce, Workday, Google Analytics, ServiceNow와 같은 엔터프라이즈 애플리케이션에 대한 포인트 앤 클릭 데이터 수집을 제공합니다. 로드맵에는 MySQL, Postgres, Oracle과 같은 데이터베이스 및 NetSuite, Dynamics 365, Google Ads와 같은 엔터프라이즈 애플리케이션도 포함됩니다. Lakeflow Connect는 SharePoint와 같은 소스에서 PDF 및 Excel 스프레드시트와 같은 비정형 데이터도 수집할 수 있습니다.
이는 클라우드 스토리지(예: S3, ADLS Gen2 및 GCS) 및 큐(예: Kafka, Kinesis, Event Hub 및 Pub/Sub 커넥터) 및 Fivetran, Qlik, Informatica와 같은 파트너 솔루션에 대한 인기 있는 네이티브 커넥터를 보완합니다.
특히 데이터베이스 커넥터에 대해 기대가 큽니다. 이 커넥터는 Arcion 인수로 구동됩니다. 운영 데이터베이스에는 엄청난 양의 귀중한 데이터가 잠겨 있습니다. 이 데이터를 로드하는 일반적인 접근 방식은 운영 및 확장성 문제를 야기하므로, Lakeflows는 변경 데이터 캡처(CDC) 기술을 사용하여 이 데이터를 lakehouse로 가져오는 것을 간단하고 안정적이며 운영적으로 효율적으로 만듭니다.
Lakeflow Connect를 사용하는 Databricks 고객은 간단한 수집 솔루션이 생산성을 향상시키고 데이터에서 인사이트로 더 빠르게 이동할 수 있도록 한다고 말합니다. 웨어러블 인슐린 관리 시스템인 Omnipod 제조업체인 Insulet은 Salesforce 수집 커넥터를 사용하여 고객 피드백 관련 데이터를 Databricks를 기반으로 구축된 데이터 솔루션으로 수집합니다. 이 데이터는 Databricks SQL을 통해 분석에 사용할 수 있어 품질 문제에 대한 인사이트를 얻고 고객 불만을 추적할 수 있습니다. 팀은 Lakeflow Connect의 새로운 기능 사용에서 상당한 가치를 발견했습니다.
"Databricks의 새로운 Salesforce 수집 커넥터를 통해 깨지기 쉽고 문제가 있는 미들웨어를 제거하여 데이터 통합 프로세스를 크게 간소화했습니다. 이 개선을 통해 Databricks SQL은 Databricks 내에서 Salesforce 데이터를 직접 분석할 수 있습니다. 결과적으로, 저희 데이터 실무자들은 이제 며칠에서 몇 분으로 지연 시간을 줄여 거의 실시간으로 업데이트된 인사이트를 제공할 수 있습니다." —Bill Whiteley, AI, Analytics, 및 Advanced Algorithms 수석 이사, Insulet
Lakeflow Pipelines: 효율적인 선언적 데이터 파이프라인
Lakeflow Pipelines는 효율적인 배치 및 스트리밍 데이터 파이프라인 구축 및 관리의 복잡성을 줄여줍니다. 선언적 Delta Live Tables 프레임워크를 기반으로 구축되어 SQL 및 Python으로 비즈니스 로직을 작성하는 데 집중할 수 있으며, Databricks는 데이터 오케스트레이션, 증분 처리 및 컴퓨팅 인프라 자동 확장을 자동으로 처리합니다. 또한 Lakeflow Pipelines는 내장된 데이터 품질 모니터링을 제공하며, 실시간 모드를 통해 코드 변경 없이 시기적절한 데이터셋의 일관되게 낮은 지연 시간 전달을 활성화할 수 있습니다.
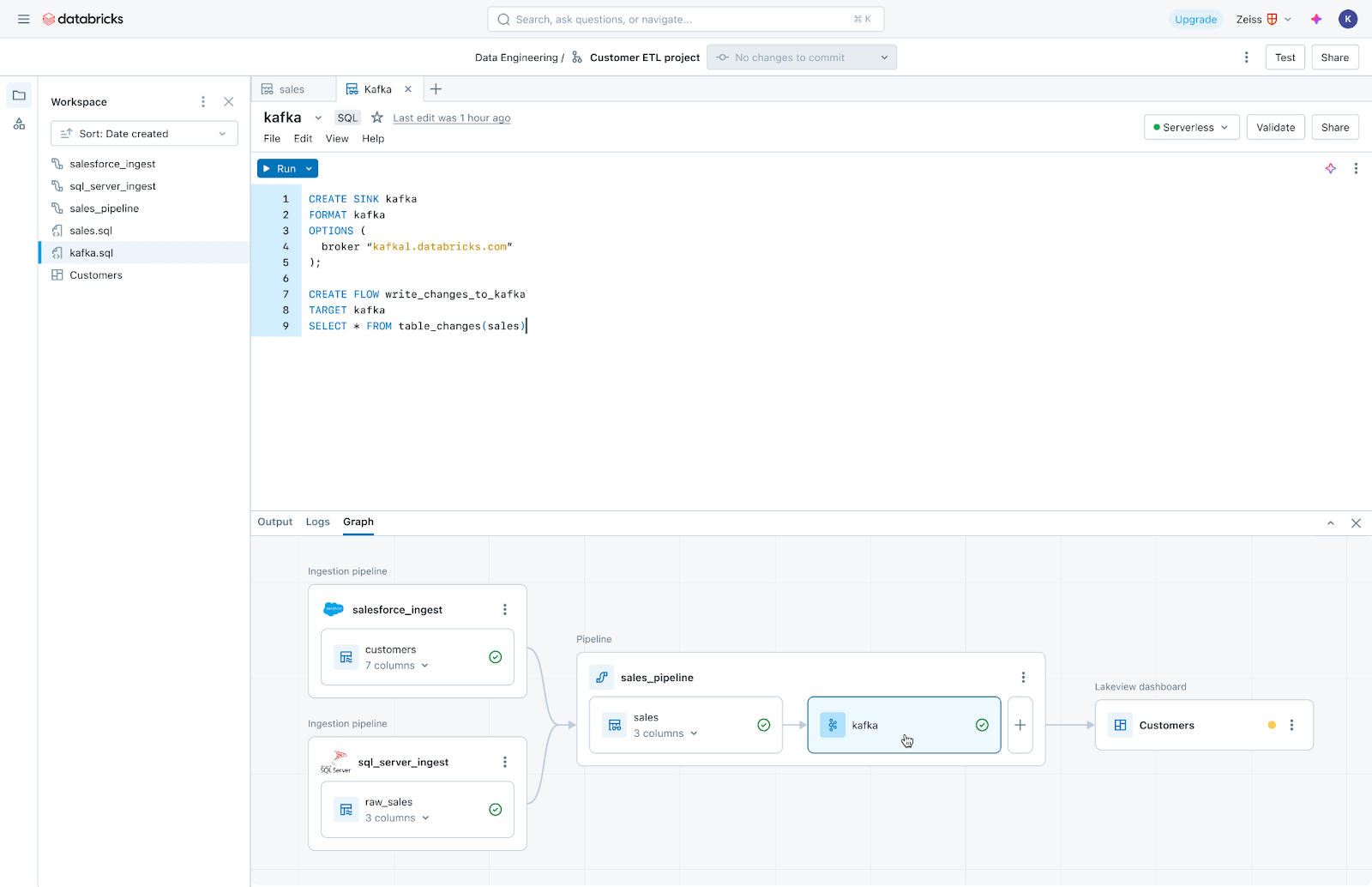
Lakeflow Jobs: 모든 워크로드에 대한 안정적인 오케스트레이션
Lakeflow Jobs는 프로덕션 워크로드를 안정적으로 오케스트레이션하고 모니터링합니다. Databricks Workflows의 고급 기능을 기반으로 구축되어 수집, 파이프라인, 노트북, SQL 쿼리, 머신러닝 학습, 모델 배포 및 추론을 포함한 모든 워크로드를 오케스트레이션합니다. 데이터 팀은 트리거, 분기 및 루핑을 활용하여 복잡한 데이터 전달 사용 사례를 충족할 수도 있습니다.
Lakeflow Jobs는 데이터 상태 및 전달을 이해하고 추적하는 프로세스를 자동화하고 단순화합니다. 상태에 대한 데이터 중심 보기를 취하며, 수집, 변환, 테이블 및 대시보드 간의 관계를 포함한 전체 계보를 데이터 팀에 제공합니다. 또한 데이터 신선도와 품질을 추적하여 데이터 팀이 클릭 한 번으로 Lakehouse Monitoring을 통해 모니터를 추가할 수 있도록 합니다.
Data Intelligence Platform 기반
Databricks Lakeflow는 다음과 같은 기능을 제공하는 Data Intelligence Platform과 네이티브로 통합됩니다:
- 데이터 인텔리전스: AI 기반 인텔리전스는 Lakeflow의 기능일 뿐만 아니라 제품의 모든 측면에 영향을 미치는 기본 기능입니다. Databricks Assistant는 데이터 파이프라인의 검색, 작성 및 모니터링을 지원하므로 안정적인 데이터를 구축하는 데 더 많은 시간을 할애할 수 있습니다.
- 통합 거버넌스: Lakeflow는 계보 및 데이터 품질을 지원하는 Unity Catalog와도 깊이 통합됩니다.
- 서버리스 컴퓨팅: 인프라에 대해 걱정할 필요 없이 대규모로 파이프라인을 구축하고 오케스트레이션하여 팀이 작업에 집중하도록 돕습니다.
데이터 엔지니어링의 미래는 간단하고 통합적이며 지능적입니다
Lakeflow가 고객이 비즈니스에 더 신선하고 완전하며 고품질의 데이터를 제공할 수 있도록 지원할 것이라고 믿습니다. Lakeflow는 곧 Lakeflow Connect로 시작하여 미리 보기로 제공될 예정입니다. 액세스를 요청하려면 여기에서 등록하십시오. 앞으로 몇 달 동안 추가 기능이 제공됨에 따라 더 많은 Lakeflow 발표를 기대해 주십시오.
실제로 보고 싶으신가요?
Lakeflow 제품 투어를 통해 배치 및 실시간으로 여러 소스의 데이터를 프로덕션으로 원활하게 수집, 변환 및 배포해 보세요.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.