5 wichtige Schritte für eine erfolgreiche Migration von Hadoop zur Lakehouse-Architektur
von Harsh Narula
Die Entscheidung, von Hadoop auf eine moderne, cloudbasierte Architektur wie die Lakehouse-Architektur zu migrieren, ist eine geschäftliche und keine technologische Entscheidung. In einem früheren Blogbeitrag haben wir die Gründe erläutert, die für eine Neubewertung der Beziehung zu Hadoop durch jede Organisation sprechen. Sobald die Stakeholder aus den Bereichen Technologie, Daten und Business die Entscheidung treffen, das Unternehmen von Hadoop zu migrieren, müssen verschiedene Aspekte berücksichtigt werden, bevor die eigentliche Umstellung beginnt. In diesem Blogbeitrag konzentrieren wir uns speziell auf den eigentlichen Migrationsprozess. Sie erfahren mehr über die wichtigsten Schritte für eine erfolgreiche Migration und die Rolle, die die Lakehouse-Architektur dabei spielt, die nächste Welle datengesteuerter Innovationen anzustoßen.
Die Migrationsschritte
Sagen wir es, wie es ist. Migrationen sind nie einfach. Allerdings können Migrationen so strukturiert werden, dass negative Auswirkungen minimiert, die Geschäftskontinuität gewährleistet und die Kosten effektiv verwaltet werden. Dazu schlagen wir vor, Ihre Migration von Hadoop in die folgenden fünf Hauptschritte zu unterteilen:
- Verwaltung
- Datenmigration
- Datenverarbeitung
- Sicherheit und Governance
- SQL- und BI-Layer
Schritt 1: Administration
Lassen Sie uns einige der wesentlichen Konzepte in Hadoop aus administrativer Sicht betrachten und wie sie sich mit Databricks vergleichen und davon unterscheiden.
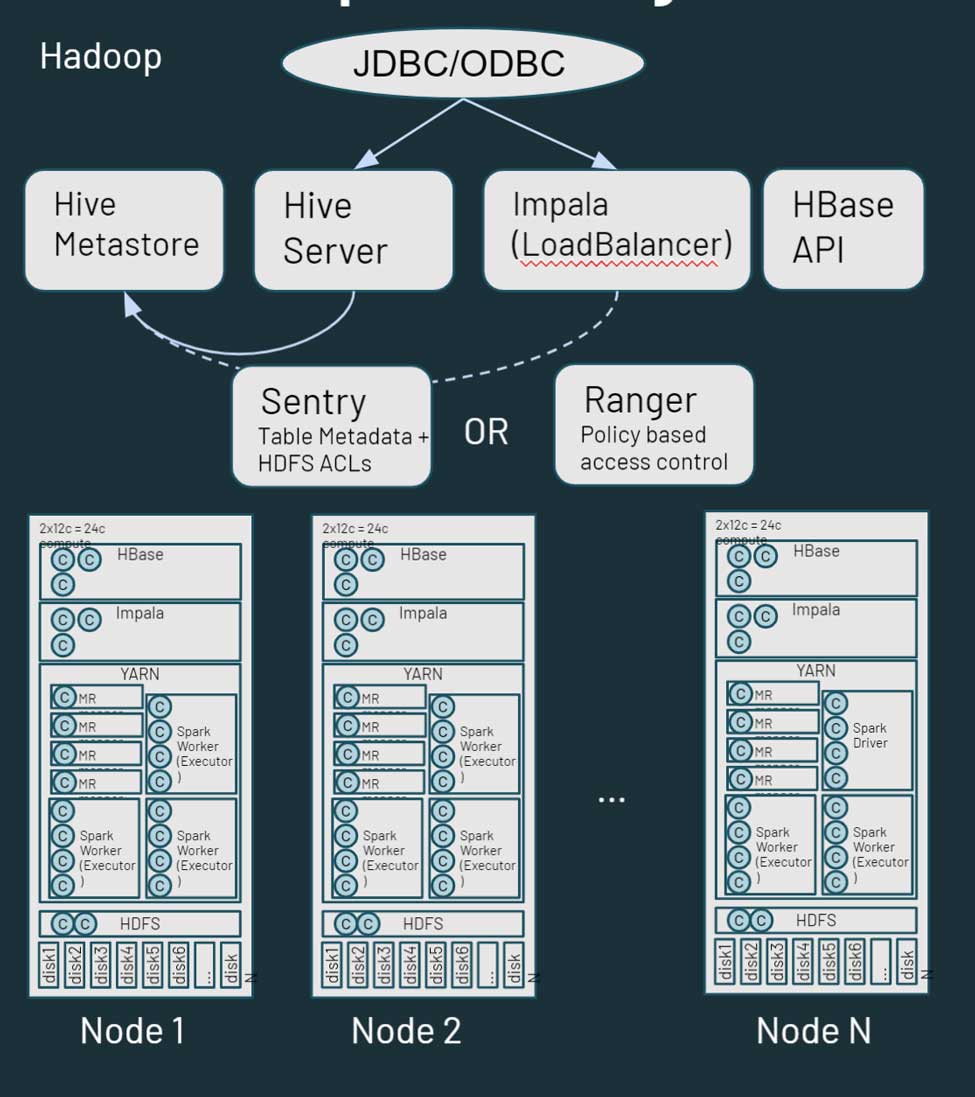
Hadoop ist im Wesentlichen eine monolithische, verteilte Speicher- und Compute-Plattform. Es besteht aus mehreren Knoten und Servern, die jeweils über eigenen Speicher, eigene CPU und eigenen Arbeitsspeicher verfügen. Die Arbeit wird auf all diese Knoten verteilt. Die Ressourcenverwaltung erfolgt über YARN, das bestmöglich versucht, sicherzustellen, dass die Arbeitslasten ihren Anteil an compute erhalten.
Hadoop besteht ebenfalls aus Metadateninformationen. Es gibt einen Hive-Metastore, der strukturierte Informationen zu Ihren in HDFS gespeicherten Assets enthält. Sie können Sentry oder Ranger zur Steuerung des Zugriffs auf die Daten nutzen. Hinsichtlich des Datenzugriffs können Benutzer und Anwendungen entweder direkt über HDFS (oder die entsprechenden CLIs/APIs) oder über eine SQL-Schnittstelle auf Daten zugreifen. Die SQL-Schnittstelle wiederum kann über eine JDBC/ODBC-Verbindung mithilfe von Hive für generisches SQL (oder in einigen Fällen für ETL-Skripts) oder Hive on Impala oder Tez für interaktive Abfragen genutzt werden. Hadoop bietet auch eine HBase-API und zugehörige Datenquellen-Dienste. Mehr über das Hadoop-Ökosystem erfahren Sie hier.
Als Nächstes besprechen wir, wie diese Dienste in der Databricks Lakehouse Platform zugeordnet oder behandelt werden. In Databricks ist einer der ersten zu beachtenden Unterschiede, dass Sie in einer Databricks-Umgebung mehrere Cluster betrachten. Jeder Cluster kann für einen bestimmten Anwendungsfall, ein bestimmtes Projekt, einen Geschäftsbereich, ein Team oder eine Entwicklungsgruppe verwendet werden. Noch wichtiger ist, dass diese Cluster kurzlebig sein sollen. Bei Job-Clustern ist die Lebensdauer der Cluster auf die Laufzeit des Workflows ausgelegt. Er führt den Workflow aus, und sobald dieser abgeschlossen ist, wird die Umgebung automatisch abgebaut. Ebenso kann bei einem interaktiven Anwendungsfall, bei dem eine Rechenumgebung von mehreren Entwicklern gemeinsam genutzt wird, diese Umgebung zu Beginn des Arbeitstages hochgefahren werden, sodass die Entwickler den ganzen Tag über ihren Code ausführen können. Während Phasen der Inaktivität wird Databricks sie über die in die Plattform integrierte (konfigurierbare) Auto-Terminate-Funktion automatisch herunterfahren.
Im Gegensatz zu Hadoop bietet Databricks keine Datenspeicherdienste wie HBase oder SOLR an. Ihre Daten befinden sich in Ihrem Dateispeicher, innerhalb des Objektspeichers. Viele der Dienste wie HBase oder SOLR haben Alternativen oder gleichwertige Technologieangebote in der Cloud. Es kann sich um eine cloudnativ oder eine ISV-Lösung handeln.
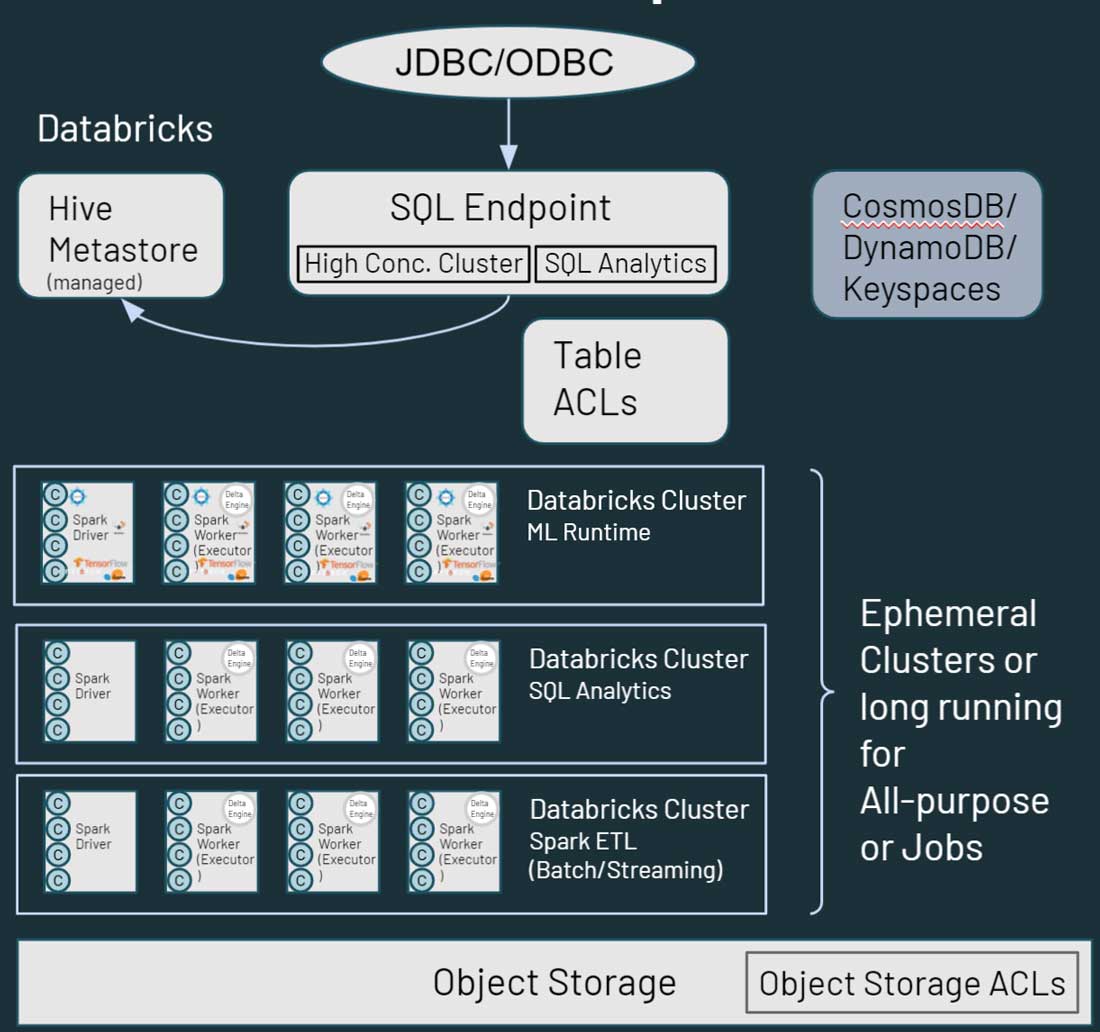
Wie Sie im obigen Diagramm sehen können, entspricht jeder Cluster-Knoten in Databricks entweder einem Spark-driver oder einem Worker. Das Key-Element dabei ist, dass die verschiedenen Databricks-Cluster vollständig voneinander isoliert sind. Dadurch können Sie sicherstellen, dass strenge SLAs für bestimmte Projekte und Anwendungsfälle eingehalten werden können. Sie können Streaming- oder Echtzeit-Anwendungsfälle wirklich von anderen, Batch-orientierten Workloads isolieren und müssen sich keine Sorgen über die manuelle Isolierung von lang andauernden Jobs machen, die die Cluster-Ressourcen für lange Zeit in Beschlag nehmen könnten. Sie können für verschiedene Anwendungsfälle einfach neue Cluster als Compute starten. Databricks entkoppelt außerdem Speicher von compute und ermöglicht Ihnen die Nutzung vorhandener Cloud-Speicher wie AWS S3, Azure Blob Storage und Azure Data Lake Store (ADLS).
Databricks verfügt ebenfalls über einen standardmäßig verwalteten Hive metastore, der strukturierte Informationen über Daten-Assets speichert, die sich im Cloud-Speicher befinden. Es unterstützt auch die Verwendung eines externen Metastores, wie z. B. AWS Glue, Azure SQL Server oder Azure Purview. Sie können innerhalb von Databricks auch Sicherheitskontrollen wie Tabellen-ACLs sowie Objektspeicherberechtigungen festlegen.
Was den Datenzugriff betrifft, bietet Databricks ähnliche Funktionen wie Hadoop in Bezug darauf, wie Ihre Nutzer mit den Daten interagieren. Auf in Cloud-Speicher gespeicherte Daten kann über mehrere Pfade in der Databricks-Umgebung zugegriffen werden. Nutzer können SQL Endpoints und Databricks SQL für interaktive Abfragen und Analysen verwenden. Sie können auch die Databricks-Notebooks für Data Engineering- und Machine-Learning-Funktionen für die im Cloud-Speicher gespeicherten Daten verwenden. HBase in Hadoop entspricht Azure CosmosDB oder AWS DynamoDB/Keyspaces, die als Serving-Layer für Downstream-Anwendungen genutzt werden können.
Schritt 2: Datenmigration
Da ich von einem Hadoop-Hintergrund ausgehe, nehme ich an, dass die meisten Zuhörer bereits mit HDFS vertraut sind. HDFS ist das Speicherdateisystem, das bei Hadoop-Implementierungen verwendet wird und die Festplatten auf den Knoten des Hadoop-Clusters nutzt. Wenn Sie also HDFS skalieren, müssen Sie die Kapazität des gesamten Clusters erhöhen (d. h. Sie müssen compute und Speicher gemeinsam skalieren). Wenn dies die Beschaffung und Installation zusätzlicher Hardware erfordert, kann dies mit erheblichem Zeit- und Arbeitsaufwand verbunden sein.
In der Cloud haben Sie eine nahezu unbegrenzte Speicherkapazität in Form von Cloud-Speicher wie AWS S3, Azure Data Lake Storage, Blob Storage oder Google Storage. Es sind keine Wartungs- oder Systemdiagnosen erforderlich und es bietet integrierte Redundanz und ein hohes Maß an Beständigkeit und Verfügbarkeit ab dem Zeitpunkt der Bereitstellung. Wir empfehlen, für die Migration Ihrer Daten native Cloud-Dienste zu nutzen. Zur Erleichterung der Migration gibt es verschiedene Partner/ISVs.
Wie legen Sie also los? Die am häufigsten empfohlene Vorgehensweise ist, mit einer dualen Ingestionsstrategie zu starten (d. h. Fügen Sie einen Feed hinzu, der Daten zusätzlich zu Ihrer on-premises-Umgebung in den Cloud-Speicher uploadet). Dies ermöglicht es Ihnen, mit neuen Anwendungsfällen (die neue Daten nutzen) in der Cloud zu starten, ohne Ihr bestehendes Setup zu beeinträchtigen. Wenn Sie die Zustimmung anderer Gruppen innerhalb der Organisation suchen, können Sie dies zunächst als Backup-Strategie positionieren. Das Sichern von HDFS war traditionell aufgrund der schieren Größe und des damit verbundenen Aufwands eine Herausforderung, weshalb die Datensicherung in der Cloud ohnehin eine produktive Initiative sein kann.
In den meisten Fällen können Sie bestehende Datenbereitstellungstools nutzen, um den Feed zu forken und die Daten nicht nur in Hadoop, sondern auch in den Cloud-Speicher zu schreiben. Wenn Sie beispielsweise Tools/Frameworks wie Informatica und Talend verwenden, um Daten zu verarbeiten und in Hadoop zu schreiben, ist es sehr einfach, einen zusätzlichen Schritt hinzuzufügen, um sie auch in den Cloud-Speicher schreiben zu lassen. Sobald sich die Daten in der Cloud befinden, gibt es viele Möglichkeiten, mit ihnen zu arbeiten.
Hinsichtlich der Datenrichtung können die Daten entweder von on-premises in die Cloud gepullt oder von on-premises in die Cloud gepusht werden. Zu den Tools, die für die Übertragung von Daten in die Cloud genutzt werden können, gehören cloudnative Lösungen (Azure Data Box, AWS Snow Family usw.), DistCP (ein Hadoop-Tool), andere Tools von Drittanbietern sowie alle internen Frameworks. Die Push-Option ist in der Regel einfacher, wenn es darum geht, die erforderlichen Genehmigungen von den Sicherheitsteams zu erhalten.
Um die Daten in die Cloud zu pullen, können Sie Spark/Kafka-Streaming- oder Batch-Ingestion-Pipelines verwenden, die von der Cloud aus ausgelöst werden. Für den Batch können Sie entweder Dateien direkt aufnehmen oder JDBC-Konnektoren verwenden, um eine Verbindung zu den relevanten Upstream-Technologieplattformen herzustellen und die Daten zu pullen. Natürlich sind hierfür auch Tools von Drittanbietern verfügbar. Die Push-Option ist die gängigere und verständlichere der beiden, also lassen Sie uns den Pull-Ansatz etwas genauer betrachten.
Als Erstes müssen Sie die Konnektivität zwischen Ihrer On-Premises-Umgebung und der Cloud einrichten. Dies kann mit einer Internetverbindung und einem Gateway erreicht werden. Sie können auch dedizierte Konnektivitätsoptionen wie AWS Direct Connect, Azure ExpressRoute usw. nutzen. Wenn Ihr Unternehmen nicht neu in der Cloud ist, wurde dies in einigen Fällen möglicherweise bereits eingerichtet, sodass Sie es für Ihr Hadoop-Migrationsprojekt wiederverwenden können.
Ein weiterer Aspekt ist die Sicherheit innerhalb der Hadoop-Umgebung. Wenn es sich um eine kerberisierte Umgebung handelt, kann dies von der Databricks-Seite aus unterstützt werden. Sie können Databricks-Initialisierungsskripte konfigurieren, die beim Start des Clusters ausgeführt werden, den erforderlichen Kerberos-Client installieren und konfigurieren, auf die Dateien krb5.conf und keytab zugreifen, die an einem Cloud-Speicherort gespeichert sind, und schließlich die Funktion kinit() ausführen, wodurch der Databricks-Cluster direkt mit Ihrer Hadoop-Umgebung interagieren kann.
Schließlich benötigen Sie auch einen externen gemeinsam genutzten Metastore. Databricks verfügt zwar über einen defaultmäßig angewendeten Metastore-Dienst, unterstützt aber auch die Verwendung eines externen. Der externe Metastore wird von Hadoop und Databricks gemeinsam genutzt und kann entweder on-premises (in Ihrer Hadoop-Umgebung) oder in der Cloud angewendet werden. Wenn Sie beispielsweise über bestehende ETL-Prozesse verfügen, die in Hadoop ausgeführt werden, und Sie diese noch nicht zu Databricks migrieren können, können Sie dieses Setup mit dem bestehenden On-Premises-Metastore nutzen, damit Databricks das endgültige kuratierte Dataset von Hadoop nutzen kann.
Schritt 3: Datenverarbeitung
Das Wichtigste ist, dass aus Sicht der Datenverarbeitung alles in Databricks Apache Spark nutzt. Alle Hadoop-Programmiersprachen wie MapReduce, Pig, Hive QL und Java können so konvertiert werden, dass sie auf Spark laufen, sei es über Pyspark, Scala, Spark SQL oder sogar R. Was den Code und die IDE betrifft, können sowohl Apache Zeppelin- als auch Jupyter-Notebooks in Databricks-Notebooks konvertiert werden, aber es ist etwas einfacher, Jupyter-Notebooks zu importieren. Zeppelin-Notebooks müssen in Jupyter oder Ipython konvertiert werden, bevor sie importiert werden können. Wenn Ihr Data-Science-Team weiterhin in Zeppelin oder Jupyter programmieren möchte, kann es Databricks Connect verwenden, womit Sie Ihre lokale IDE (Jupyter, Zeppelin oder sogar IntelliJ, VScode, RStudio usw.) nutzen können, um Code auf Databricks auszuführen.
Bei der Migration von Apache Spark™-Jobs sind die Spark-Versionen der wichtigste Aspekt. Ihr On-Premises-Hadoop-Cluster führt möglicherweise eine ältere Version von Spark aus und Sie können den Spark-Migrationsleitfaden nutzen, um festzustellen, welche Änderungen vorgenommen wurden und wie sich diese auf Ihren Code auswirken. Ein weiterer zu berücksichtigender Aspekt ist die Konvertierung von RDDs in Dataframes. RDDs wurden häufig mit Spark-Versionen bis 2.x verwendet. Sie können zwar auch mit Spark 3.x noch genutzt werden, aber das kann Sie daran hindern, das volle Potenzial des Spark-Optimierers auszuschöpfen. Wir empfehlen Ihnen, Ihre RDDs wo immer möglich in DataFrames umzuwandeln.
Nicht zuletzt sind hartcodierte Verweise auf die lokale Hadoop-Umgebung eine der häufigsten Fallstricke, auf die wir bei Kunden während der Migration gestoßen sind. Diese müssen natürlich aktualisiert werden, da der Code sonst in der neuen Umgebung nicht mehr funktioniert.
Als Nächstes befassen wir uns mit der Konvertierung von Nicht-Spark-Workloads, was größtenteils das Umschreiben von Code beinhaltet. Bei MapReduce kann der Code in einigen Fällen, wenn Sie eine gemeinsame Logik in Form einer Java-Bibliothek verwenden, von Spark genutzt werden. Möglicherweise müssen Sie jedoch trotzdem Teile des Codes umschreiben, damit er in einer Spark-Umgebung anstelle von MapReduce ausgeführt wird. Sqoop ist relativ einfach zu migrieren, da Sie in den neuen Umgebungen eine Reihe von Spark-Befehlen (im Gegensatz zu MapReduce-Befehlen) über eine JDBC-Quelle ausführen. Sie können Parameter im Spark-Code auf die gleiche Weise angeben, wie Sie sie in Sqoop angeben. Bei Flume beziehen sich die meisten Anwendungsfälle, die wir gesehen haben, auf den Datenkonsum aus Kafka und das Schreiben in HDFS. Diese Task lässt sich leicht mit Spark Streaming erledigen. Der Haupt-Task bei der Migration von Flume besteht darin, den auf Konfigurationsdateien basierenden Ansatz in einen programmatischeren Ansatz in Spark umzuwandeln. Schließlich gibt es noch Nifi, das hauptsächlich außerhalb von Hadoop als Drag-and-Drop-Self-Service-Ingestion-Tool verwendet wird. Nifi kann auch in der Cloud genutzt werden, aber wir sehen, dass viele Kunden die Gelegenheit der Migration in die Cloud nutzen, um Nifi durch andere, neuere in der Cloud verfügbare Tools zu ersetzen.
Die Migration von HiveQL ist vielleicht die einfachste Task von allen. Es besteht ein hohes Maß an Kompatibilität zwischen Hive und Spark SQL, und die meisten Abfragen sollten unverändert auf Spark SQL ausgeführt werden können. Es gibt einige geringfügige Änderungen in der DDL zwischen HiveQL und Spark SQL, z. B. die Tatsache, dass Spark SQL die „USING“-Klausel verwendet, während HiveQL die „FORMAT“-Klausel benutzt. Wir empfehlen, den Code so zu ändern, dass das Spark-SQL-Format verwendet wird, da dies dem Optimierer ermöglicht, den bestmöglichen Ausführungsplan für Ihren Code in Databricks vorzubereiten. Sie können weiterhin Hive Serdes und UDFs nutzen, was die Migration von HiveQL zu Databricks noch einfacher macht.
Hinsichtlich der Workflow- Orchestrierung müssen Sie mögliche Änderungen bei der Übermittlung Ihrer Jobs berücksichtigen. Sie können weiterhin die Spark-Submit-Semantik nutzen, aber es gibt auch andere, schnellere und nahtloser integrierte Optionen. Sie können Databricks-Jobs und Delta-Live-Tables für codefreies ETL nutzen, um Oozie-Jobs zu ersetzen und End-to-End-Datenpipelines innerhalb von Databricks zu definieren. Für Workflows mit externen Verarbeitungsabhängigkeiten müssen Sie die entsprechenden Workflows/Pipelines in Technologien wie Apache Airflow, Azure Data Factory usw. zur Automatisierung/Schedule erstellen. Mit den REST-APIs von Databricks kann fast jede Planungsplattform integriert und für die Zusammenarbeit mit Databricks konfiguriert werden.
Es gibt auch ein automatisiertes Tool namens MLens (erstellt von KnowledgeLens), das bei der Migration Ihrer Workloads von Hadoop zu Databricks helfen kann. MLens kann bei der Migration von PySpark-Code und HiveQL helfen, einschließlich der Übersetzung einiger Hive-Besonderheiten in Spark SQL, sodass Sie die volle Funktionalität und die Performance-Vorteile des Spark SQL-Optimierers nutzen können. Sie planen außerdem, bald die Migration von Oozie-Workflows zu Airflow, Azure Data Factory usw. zu unterstützen.
Schritt 4: Sicherheit und Governance
Sehen wir uns Sicherheit und Governance an. In der Hadoop-Welt gibt es eine LDAP-Integration für die Konnektivität zu Admin-Konsolen wie Ambari oder Cloudera Manager oder sogar Impala oder Solr. Hadoop verfügt auch über Kerberos, das zur Authentifizierung bei anderen Diensten verwendet wird. Hinsichtlich der Autorisierung sind Ranger und Sentry die am häufigsten verwendeten Tools.
Mit Databricks ist eine Single-Sign-On-Integration (SSO) mit jedem Identity Provider verfügbar, der SAML 2.0 unterstützt. Dies umfasst Azure Active Directory, Google Workspace SSO, AWS SSO und Microsoft Active Directory. Für die Autorisierung bietet Databricks ACLs (Access Control Lists) für Databricks-Objekte, mit denen Sie Berechtigungen für Entitäten wie Notebooks, Jobs und Cluster festlegen können. Für Datenberechtigungen und Zugriffskontrolle können Sie Tabellen-ACLs und Ansichten definieren, um den Spalten- und Zeilenzugriff zu beschränken, sowie Funktionen wie Credential Passthrough nutzen, mit dem Databricks Ihre Anmeldeinformationen für den Workspace an die Speicherebene (S3, ADLS, Blob Storage) weitergibt, um zu ermitteln, ob Sie zum Zugriff auf die Daten berechtigt sind. Wenn Sie Funktionen wie attributbasierte Kontrollen oder Datenmaskierung benötigen, können Sie Partner-Tools wie Immuta und Privacera nutzen. Aus der Perspektive der Enterprise Governance können Sie Databricks mit einem Unternehmens-Datenkatalog wie AWS Glue, Informatica Data Catalog, Alation und Collibra verbinden.
Schritt 5: SQL- & BI-Schicht
In Hadoop stehen Ihnen, wie bereits besprochen, Hive und Impala als Schnittstellen für ETL, Ad-hoc-Abfragen und Analysen zur Verfügung. In Databricks stehen Ihnen über Databricks SQL ähnliche Funktionen zur Verfügung. Databricks SQL bietet außerdem eine extreme Leistung über die Delta-Engine sowie Unterstützung für Anwendungsfälle mit high concurrency mit automatisch skalierenden Clustern. Die Delta-Engine enthält auch Photon, eine neue MPP-Engine, die von Grund auf in C++ entwickelt wurde und vektorisiert ist, um Parallelität sowohl auf Daten- als auch auf Anweisungsebene zu nutzen.
Databricks bietet eine native Integration mit BI-Tools wie Tableau, PowerBI, Qlik und Looker sowie hochoptimierte JDBC/ODBC-Konnektoren, die von diesen Tools genutzt werden können. Die neuen JDBC/ODBC-Treiber haben einen sehr geringen Overhead (¼ Sek.) und eine um 50 % höhere Übertragungsrate bei Verwendung von Apache Arrow sowie mehrere Metadaten-Operationen, die deutlich schnellere Metadaten-Abrufoperationen unterstützen. Databricks unterstützt auch SSO für PowerBI, wobei die Unterstützung für SSO mit anderen BI- und Dashboarding-Tools in Kürze folgt.
Databricks verfügt zusätzlich zur oben genannten Notebook-Experience über eine integrierte SQL-UX, die Ihren SQL-Nutzern eine eigene Ansicht mit einer SQL-Workbench sowie einfachen Dashboarding- und Benachrichtigungsfunktionen bietet. Dies ermöglicht SQL-basierte Datentransformationen und explorative Analysen von Daten innerhalb des Data Lake, ohne dass diese nachgelagert in ein Data Warehouse oder auf andere Plattformen verschoben werden müssen.
Die nächsten Schritte
Wenn Sie über Ihren Migrationspfad zu einer modernen Cloud-Architektur wie der Lakehouse-Architektur nachdenken, sollten Sie zwei Dinge beachten:
- Denken Sie daran, die Key Business-Stakeholder auf dieser Reise miteinzubeziehen. Dies ist ebenso eine technologische wie eine geschäftliche Entscheidung, und Ihre Business-Stakeholder müssen von der Reise und ihrem Endzustand überzeugt sein.
- Bedenken Sie auch, dass Sie nicht allein sind und es bei Databricks und unseren Partnern qualifizierte Fachkräfte gibt, die dies oft genug getan haben, um wiederholbare Best Practices zu entwickeln, die Unternehmen Zeit, Geld und Ressourcen sparen und den allgemeinen Stress reduzieren.
- Laden Sie den technischen Leitfaden für die Migration von Hadoop zu Databricks herunter, um eine Schritt-für-Schritt-Anleitung, Notebooks und Code für den Beginn Ihrer Migration zu erhalten.
Um mehr darüber zu erfahren, wie Databricks den Geschäftswert steigert, und um mit der Planung Ihrer Migration von Hadoop zu beginnen, besuchen Sie www.databricks.com/solutions/migration.

Migrationsleitfaden: Von Hadoop zu Databricks
Schöpfen Sie mit diesem selbstgeführten Playbook das volle Potenzial Ihrer Daten aus.
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.