Erstellung von Geodatenprodukten
von Milos Colic
Dieser Blog ist veraltet. Bitte beachten Sie diesen Spatial SQL Blog für aktuelle Ansätze zur Speicherung und Verarbeitung von Geodaten in Ihrem Databricks Lakehouse.
Geodaten treiben seit Jahrhunderten Innovationen voran, durch den Einsatz von Karten, Kartografie und in jüngerer Zeit durch digitale Inhalte. Zum Beispiel wurde die älteste Karte auf einem Mammutknochen gefunden und stammt aus der Zeit etwa 25000 v. Chr.. Dies macht Geodaten zu einer der ältesten Datenquellen, die die Gesellschaft zur Entscheidungsfindung nutzt. Ein neueres Beispiel, das als Geburtsstunde der räumlichen Analyse gilt, ist das von Charles Picquet im Jahr 1832, der Geodaten zur Analyse von Cholera-Ausbrüchen in Paris verwendete. Einige Jahrzehnte später folgte John Snow 1854 mit dem gleichen Ansatz für Cholera-Ausbrüche in London. Diese beiden Personen nutzten Geodaten, um eines der schwierigsten Probleme ihrer Zeit zu lösen und retteten damit unzählige Leben. Schnell ins 20. Jahrhundert gespult, wurde das Konzept der Geografischen Informationssysteme (GIS) 1967 in Ottawa, Kanada, vom Department of Forestry and Rural Development erstmals eingeführt.
Heute befinden wir uns inmitten der Revolution der Cloud-Computing-Industrie – Supercomputing-Skalierung für jedes Unternehmen, praktisch unendlich skalierbar für Speicher und Rechenleistung. Konzepte wie Data Mesh und Data Marketplace entstehen in der Daten-Community, um Fragen wie Plattformföderation und Interoperabilität zu beantworten. Wie können wir diese Konzepte auf Geodaten, räumliche Analysen und GIS-Systeme anwenden? Indem wir das Konzept von Datenprodukten übernehmen und die Gestaltung von Geodaten als Produkt angehen.
In diesem Blog stellen wir eine Sichtweise vor, wie skalierbare Geodatenprodukte gestaltet werden können, die modern und robust sind. Wir werden diskutieren, wie die Databricks Lakehouse Platform genutzt werden kann, um das volle Potenzial von Geoprodukten zu erschließen, die zu den wertvollsten Assets bei der Lösung der schwierigsten Probleme von heute und morgen gehören.
Was ist ein Datenprodukt? Und wie gestaltet man es?
Die umfassendste und prägnanteste Definition eines „Datenprodukts“ wurde von DJ Patil (dem ersten U.S. Chief Data Scientist) in Data Jujitsu: The Art of Turning Data into Product geprägt: „ein Produkt, das durch die Nutzung von Daten ein Endziel ermöglicht“. Die Komplexität dieser Definition (wie Patil selbst zugab) ist notwendig, um die Bandbreite möglicher Produkte zu erfassen, Dashboards, Berichte, Excel-Tabellen und sogar CSV-Extrakte, die per E-Mail geteilt werden, einzuschließen. Möglicherweise stellen Sie fest, dass die bereitgestellten Beispiele schnell an Qualität, Robustheit und Governance verlieren.
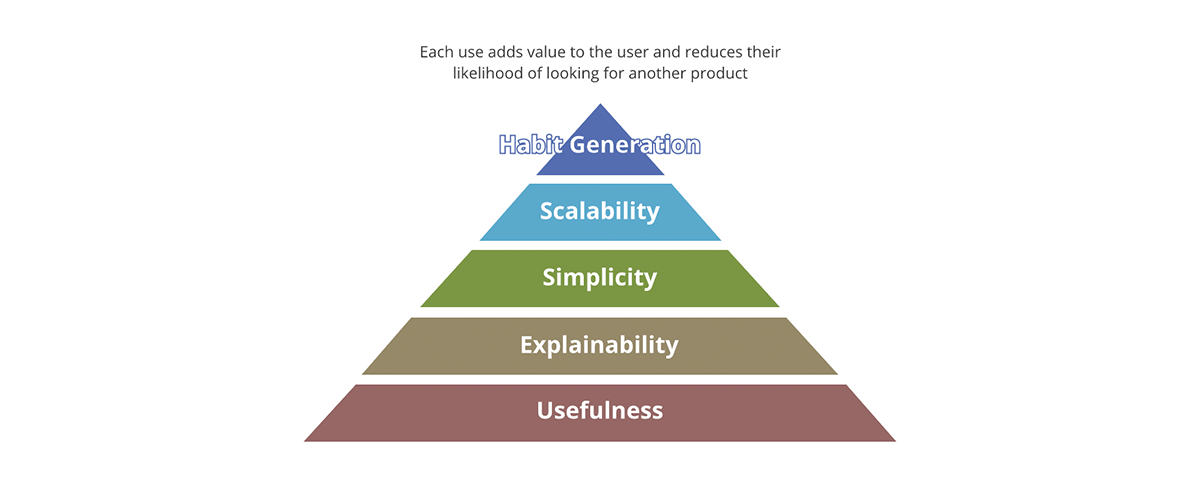
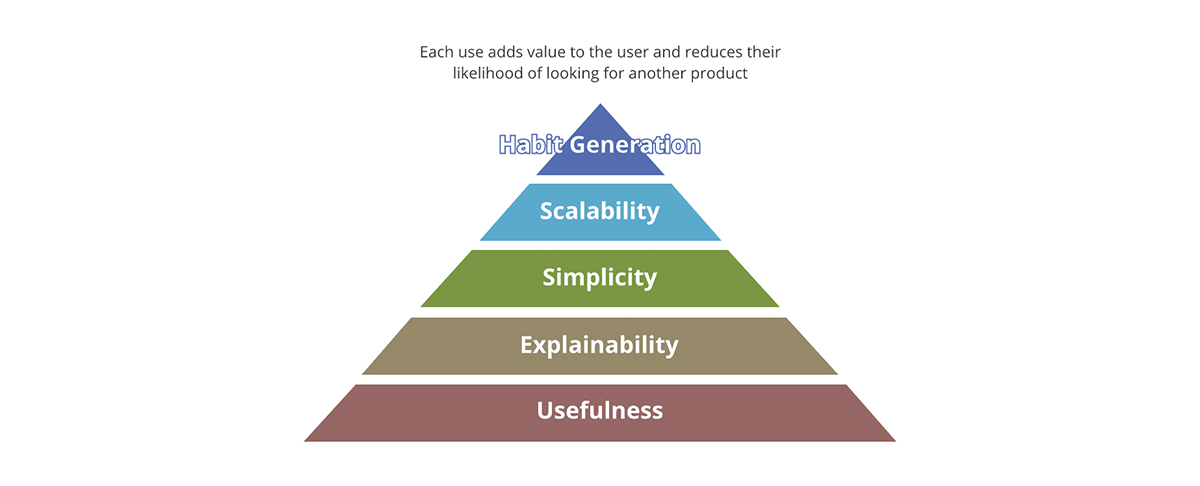
Welche Konzepte unterscheiden ein erfolgreiches Produkt von einem erfolglosen? Ist es die Verpackung? Ist es der Inhalt? Ist es die Qualität des Inhalts? Oder ist es nur die Marktakzeptanz des Produkts? Forbes definiert die 10 Must-Haves eines erfolgreichen Produkts. Ein guter Rahmen zur Zusammenfassung ist die Wertpyramide.
{kind=link}
Die Wertpyramide gibt eine Priorisierung für jeden Aspekt des Produkts. Nicht jede Wertfrage, die wir über das Produkt stellen, hat das gleiche Gewicht. Wenn der Output nicht nützlich ist, sind die anderen Aspekte irrelevant – der Output ist kein wirkliches Produkt, sondern wird eher zu einem Daten-Schadstoff im Pool nützlicher Ergebnisse. Ebenso ist Skalierbarkeit nur relevant, nachdem Einfachheit und Erklärbarkeit behandelt wurden.
Wie bezieht sich die Wertpyramide auf Datenprodukte? Jede Datenausgabe muss, um ein Datenprodukt zu sein:
- Einen klaren Nutzen haben. Die Menge der Daten, die die Gesellschaft generiert, wird nur von der Menge der von uns generierten Daten-Schadstoffe übertroffen. Dies sind Ausgaben ohne klaren Wert und Nutzen, geschweige denn eine Strategie, was damit zu tun ist.
- Erklärbar sein. Mit dem Aufkommen von KI/ML ist die Erklärbarkeit für datengesteuerte Entscheidungen noch wichtiger geworden. Daten sind nur so gut wie die Metadaten, die sie beschreiben. Denken Sie daran wie bei Lebensmitteln – Geschmack ist wichtig, aber ein wichtigerer Faktor ist der Nährwert der Zutaten.
- Einfach sein. Ein Beispiel für Produktmissbrauch ist die Verwendung einer Gabel zum Essen von Müsli anstelle eines Löffels. Darüber hinaus ist Einfachheit wesentlich, aber nicht ausreichend; über die Einfachheit hinaus sollten Produkte intuitiv sein. Wann immer möglich, sollten sowohl beabsichtigte als auch unbeabsichtigte Verwendungen der Daten offensichtlich sein.
- Skalierbar sein. Daten sind eine der wenigen Ressourcen, die mit der Nutzung wachsen. Je mehr Daten Sie verarbeiten, desto mehr Daten haben Sie. Wenn sowohl die Ein- als auch die Ausgaben des Systems unbegrenzt und ständig wachsend sind, muss das System skalierbar sein in Bezug auf Rechenleistung, Speicherkapazität und Ausdrucksstärke der Berechnungen. Cloud-Datenplattformen wie Databricks sind in einer einzigartigen Position, um alle drei Aspekte zu erfüllen.
- Gewohnheiten erzeugen. Im Datenbereich sind wir nicht an Kundenbindung interessiert, wie es bei Konsumgütern der Fall ist. Der Wert der Gewohnheitsbildung ist jedoch offensichtlich, wenn er auf Best Practices angewendet wird. Die Systeme und Datenausgaben sollten Best Practices aufweisen und diese fördern – es sollte einfacher sein, die Daten und das System auf die beabsichtigte Weise zu nutzen als umgekehrt.
Geodaten sollten alle genannten Aspekte erfüllen, ebenso wie alle Datenprodukte. Zusätzlich zu dieser hohen Anforderung haben Geodaten einige spezifische Bedürfnisse.
Standards für Geodaten
Standards für Geodaten werden verwendet, um sicherzustellen, dass geografische Daten auf konsistente und zuverlässige Weise gesammelt, organisiert und geteilt werden. Diese Standards können Richtlinien für Dinge wie Datenformatierung, Koordinatensysteme, Kartenprojektionen und Metadaten umfassen. Die Einhaltung von Standards erleichtert den Datenaustausch zwischen verschiedenen Organisationen und ermöglicht eine stärkere Zusammenarbeit und einen breiteren Zugang zu geografischen Informationen.
Die Geospatial Commission (UK Government) hat das UK Geospatial Data Standards Register als zentrales Repository für Datenstandards definiert, die im Falle von Geodaten angewendet werden sollen. Darüber hinaus ist die Mission dieses Registers:
- „Sicherstellen, dass britische Geodaten konsistenter, kohärenter und über eine breitere Palette von Systemen nutzbar sind.“ – Diese Konzepte sind ein Aufruf zur Bedeutung von Erklärbarkeit, Nutzbarkeit und Gewohnheitsbildung (möglicherweise andere Aspekte der Wertpyramide).
- „Die britische Geodaten-Community befähigen, sich stärker mit den relevanten Standards und Standardisierungsgremien zu beschäftigen.“ – Gewohnheitsbildung innerhalb der Community ist ebenso wichtig wie das robuste und kritische Design des Standards. Wenn Standards nicht angenommen werden, sind sie nutzlos.
- „Das Verständnis und die Nutzung von Geodatenstandards in anderen Sektoren der Regierung fördern.“ – Die Wertpyramide gilt auch für Standards – Konzepte wie einfache Einhaltung (Nützlichkeit/Einfachheit), Zweck des Standards (Erklärbarkeit/Nützlichkeit), Akzeptanz (Gewohnheitsbildung) sind entscheidend für die Wertschöpfung eines Standards.
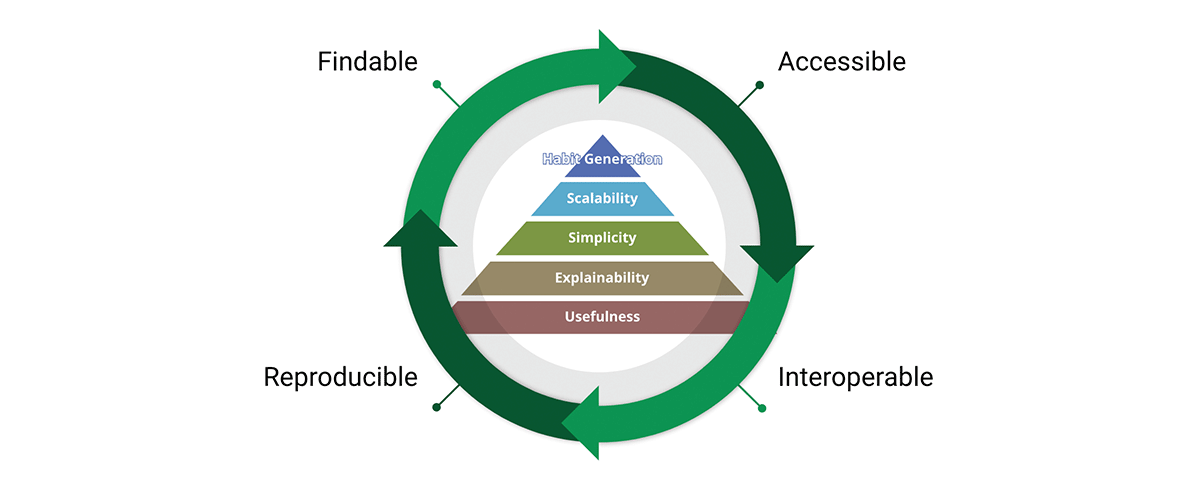
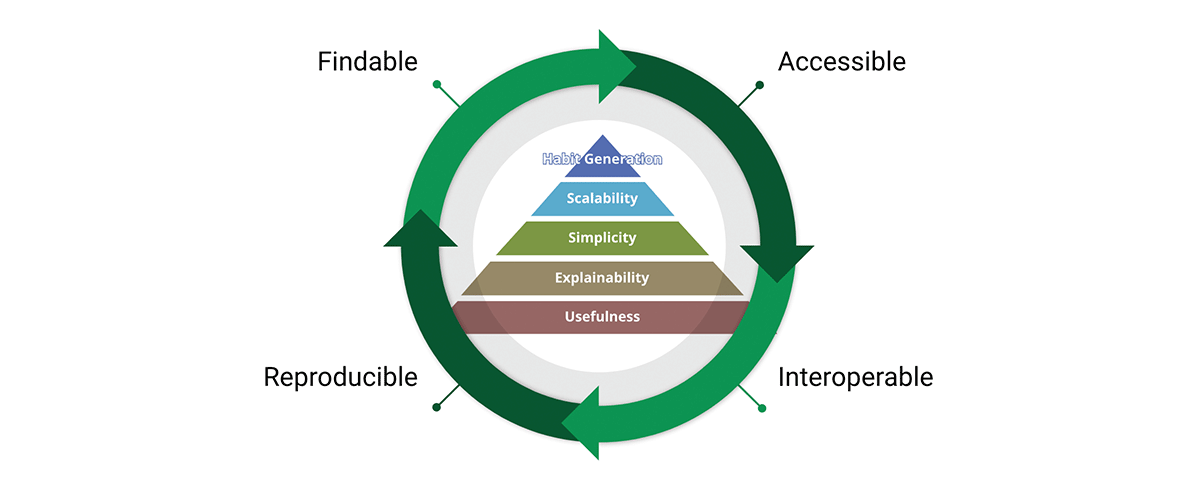
Ein wichtiges Werkzeug zur Erreichung der Mission der Datenstandards sind die FAIR-Datenprinzipien:
- Findbar (Findable) – Der erste Schritt zur (Wieder-)Nutzung von Daten ist, sie zu finden. Metadaten und Daten sollten sowohl für Menschen als auch für Computer leicht zu finden sein. Maschinenlesbare Metadaten sind unerlässlich für die automatische Entdeckung von Datensätzen und Diensten.
- Anwendbar (Accessible) – Sobald der Benutzer die benötigten Daten gefunden hat, muss er wissen, wie er darauf zugreifen kann, möglicherweise einschließlich Authentifizierung und Autorisierung.
- Interoperabel – Die Daten müssen normalerweise mit anderen Daten integriert werden. Darüber hinaus müssen die Daten für die Analyse, Speicherung und Verarbeitung mit Anwendungen oder Workflows interoperabel sein.
- Wiederverwendbar – Das ultimative Ziel von FAIR ist die Optimierung der Wiederverwendung von Daten. Um dies zu erreichen, sollten Metadaten und Daten gut beschrieben sein, damit sie in verschiedenen Umgebungen repliziert und/oder kombiniert werden können.
Wir teilen die Überzeugung, dass die FAIR-Prinzipien entscheidend für das Design skalierbarer Datenprodukte sind, denen wir vertrauen können. Um fair zu sein, basiert FAIR auf gesundem Menschenverstand. Warum ist es also entscheidend für unsere Überlegungen? „Was ich in FAIR sehe, ist an sich nichts Neues, aber was es gut macht, ist, die Notwendigkeit eines ganzheitlichen Ansatzes zur Datenverbesserung auf zugängliche Weise zu artikulieren. Diese einfache Kommunikation ist der Grund, warum FAIR zunehmend als Überbegriff für die Datenverbesserung verwendet wird – und das nicht nur in der Geodaten-Community.“ - A FAIR wind sets our course for data improvement.
Um diesen Ansatz weiter zu unterstützen, hat das Federal Geographic Data Committee den National Spatial Data Infrastructure (NSDI) Strategic Plan entwickelt, der die Jahre 2021-2024 abdeckt und im November 2020 genehmigt wurde. Die Ziele von NSDI sind im Wesentlichen FAIR-Prinzipien und vermitteln die gleiche Botschaft, Systeme zu entwerfen, die die Kreislaufwirtschaft von Daten fördern – Datenprodukte, die zwischen Organisationen nach gemeinsamen Standards fließen und in jedem Schritt der Datenlieferkette neue Werte und neue Möglichkeiten erschließen. Die Tatsache, dass diese Prinzipien verschiedene Gerichtsbarkeiten durchdringen und von verschiedenen Regulierungsbehörden übernommen werden, ist ein Beweis für die Robustheit und Solidität des Ansatzes.

{kind=link}
Die FAIR-Konzepte lassen sich sehr gut mit dem Design von Datenprodukten verbinden. Tatsächlich durchzieht FAIR die gesamte Wertpyramide des Produkts und bildet einen Wertkreislauf. Durch die Übernahme sowohl der Wertpyramide als auch der FAIR-Prinzipien entwerfen wir Datenprodukte mit interner und externer Ausrichtung. Dies fördert die Datenwiederverwendung im Gegensatz zur Datenanhäufung.
{kind=link}
Warum sind die FAIR-Prinzipien für Geodaten und Geodatenprodukte wichtig? FAIR ist transzendent für Geodaten, es ist tatsächlich transzendent für Daten, es ist ein einfaches, aber kohärentes System von Leitprinzipien für gutes Design – und dieses gute Design kann auf alles angewendet werden, einschließlich Geodaten und Geodaten-Systemen.
Grid-Indexsysteme
Bei traditionellen GIS-Lösungen wird die Leistung räumlicher Operationen normalerweise durch den Aufbau von Baumstrukturen erreicht (KD-Bäume, Ball-Bäume, Quad-Bäume usw.). Das Problem bei Baumansätzen ist, dass sie letztendlich das Skalierbarkeitsprinzip verletzen – wenn die Daten zu groß sind, um verarbeitet zu werden, um den Baum zu erstellen, und die Berechnung zur Erstellung des Baumes zu lange dauert und den Zweck verfehlt. Dies beeinträchtigt auch die Zugänglichkeit von Daten negativ: Wenn wir den Baum nicht erstellen können, können wir nicht auf die vollständigen Daten zugreifen und somit die Ergebnisse nicht reproduzieren. In diesem Fall bieten Grid-Indexsysteme eine Lösung.
Grid-Indexsysteme werden von Anfang an mit Blick auf die Skalierbarkeit von Geodaten entwickelt. Anstatt Bäume zu bauen, definieren sie eine Reihe von Grids, die das interessierende Gebiet abdecken. Im Fall von H3 (pionierhaft von Uber) deckt das Grid das Gebiet der Erde ab, im Fall von lokalen Grid-Indexsystemen (z. B. British National Grid) können sie nur das spezifische Interessengebiet abdecken. Diese Grids bestehen aus Zellen mit eindeutigen Identifikatoren. Es gibt eine mathematische Beziehung zwischen dem Standort und der Zelle im Grid. Dies macht die Grid-Indexsysteme sehr skalierbar und parallel in ihrer Natur.
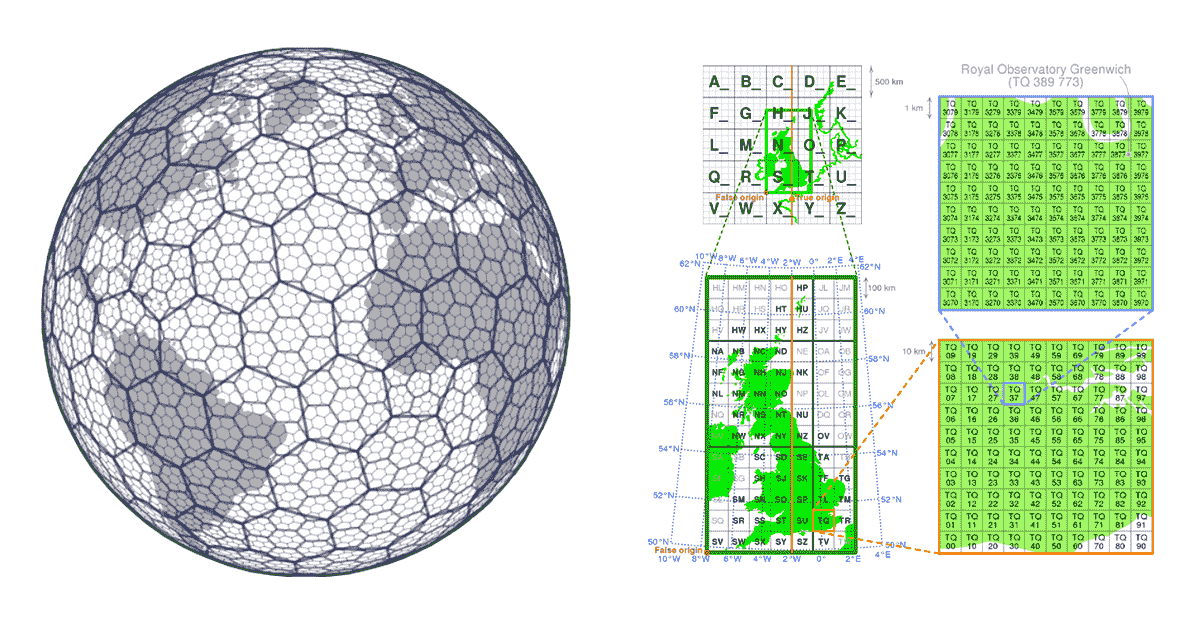
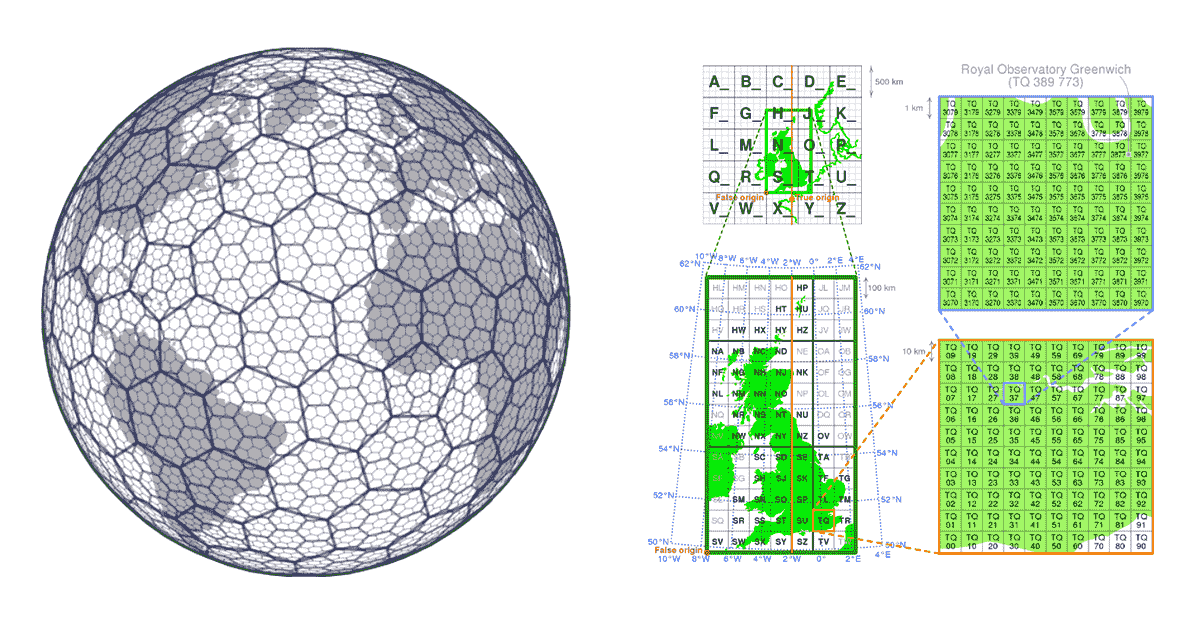{kind=link}
Ein weiterer wichtiger Aspekt von Grid-Indexsystemen ist, dass sie Open Source sind, wodurch Indexwerte universell von Datenproduzenten und -verbrauchern gleichermaßen genutzt werden können. Daten können mit den Grid-Indexinformationen in jedem Schritt ihrer Reise durch die Datenlieferkette angereichert werden. Dies macht Grid-Indexsysteme zu einem Beispiel für Community-gesteuerte Datenstandards. Community-gesteuerte Datenstandards erfordern von Natur aus keine Durchsetzung, was vollständig dem Aspekt der Gewohnheitsbildung der Wertpyramide entspricht und die Interoperabilitäts- und Zugänglichkeitsprinzipien von FAIR sinnvoll adressiert.
{kind=link}
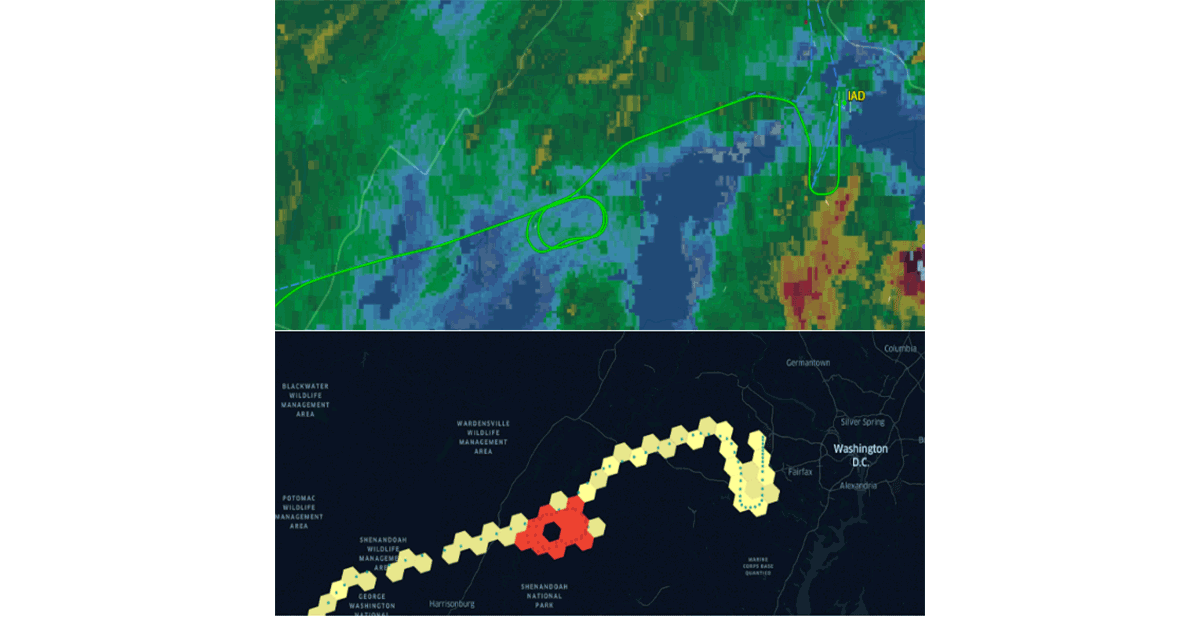
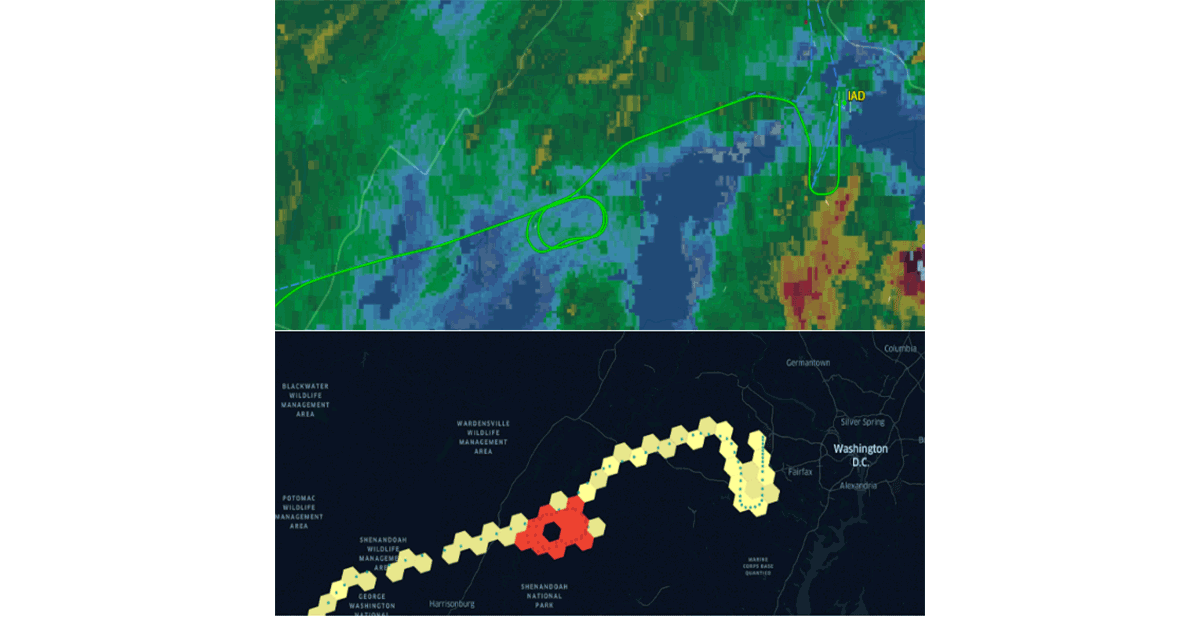
Databricks hat kürzlich die native Unterstützung für das H3-Grid-Indexsystem mit demselben Wertversprechen angekündigt. Die Übernahme gängiger Branchenstandards, die von der Community getrieben werden, ist der einzige Weg, um Gewohnheitsbildung und Interoperabilität richtig voranzutreiben. Um diese Aussage zu bekräftigen, fördern Organisationen wie CARTO, ESRI und Google die Nutzung von Grid-Indexsystemen für skalierbares GIS-Systemdesign. Darüber hinaus unterstützt das Databricks Labs-Projekt Mosaic das British National Grid als Standard-Grid-Indexsystem, das im britischen Regierungssektor weit verbreitet ist. Grid-Indexsysteme sind entscheidend für die Skalierbarkeit der Geodatenverarbeitung und für die ordnungsgemäße Gestaltung von Lösungen für komplexe Probleme (z. B. Abbildung 5 – Flugwarteschleifen mit H3).
Geodatenvielfalt
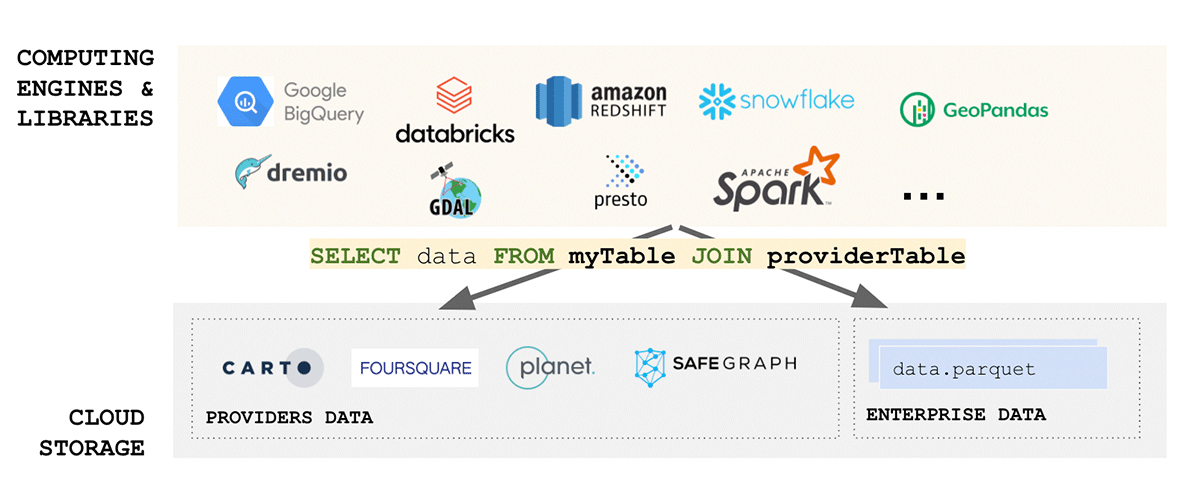
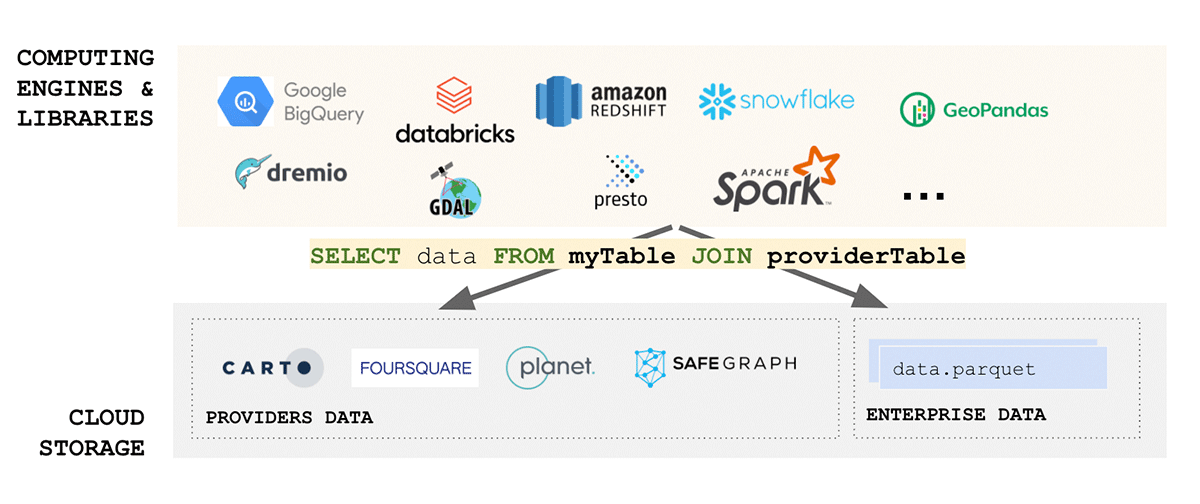
Geodatenstandards widmen einen erheblichen Teil ihrer Bemühungen der Standardisierung von Datenformaten, und das Format ist in dieser Hinsicht eine der wichtigsten Überlegungen, wenn es um Interoperabilität und Reproduzierbarkeit geht. Wenn darüber hinaus das Lesen Ihrer Daten komplex ist – wie können wir dann von Einfachheit sprechen? Leider sind Geodatenformate typischerweise komplex, da Daten in einer Reihe von Formaten produziert werden können, einschließlich sowohl Open-Source- als auch herstellerspezifischer Formate. Wenn wir nur Vektordaten betrachten, können wir erwarten, dass Daten in WKT, WKB, GeoJSON, Web-CSV, CSV, Shape File, GeoPackage und vielen anderen Formaten ankommen. Wenn wir andererseits Rasterdaten betrachten, können wir erwarten, dass Daten in einer beliebigen Anzahl von Formaten wie GeoTiff, netCDF, GRIB oder GeoDatabase ankommen; eine umfassende Liste der Formate finden Sie in diesem Blog.
Der Geodatenbereich ist sehr vielfältig und hat sich im Laufe der Jahre organisch um die Anwendungsfälle herum entwickelt, die er adressierte. Die Vereinheitlichung eines solch vielfältigen Ökosystems ist eine gewaltige Herausforderung. Eine kürzliche Initiative des Open Geospatial Consortium (OGC) zur Standardisierung auf Apache Parquet und seine Geodaten-Schema-Spezifikation GeoParquet ist ein Schritt in die richtige Richtung. Einfachheit ist einer der Schlüsselaspekte bei der Entwicklung eines guten, skalierbaren und robusten Produkts – Vereinheitlichung führt zu Einfachheit und adressiert eine der Hauptursachen für Reibungsverluste im Ökosystem – die Datenaufnahme. Die Standardisierung auf GeoParquet bringt viel Wert, der alle Aspekte von FAIR-Daten und der Wertpyramide adressiert.
{kind=link}
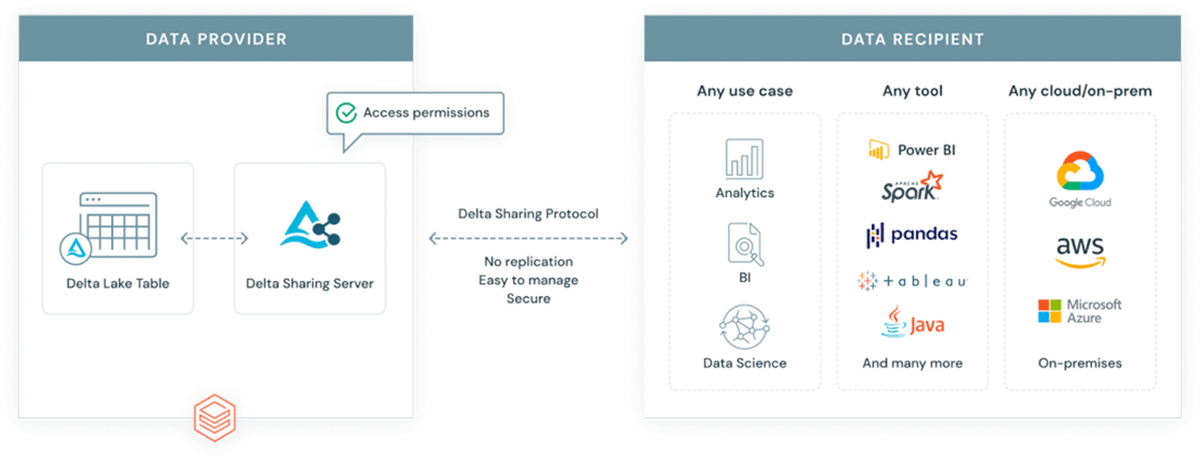
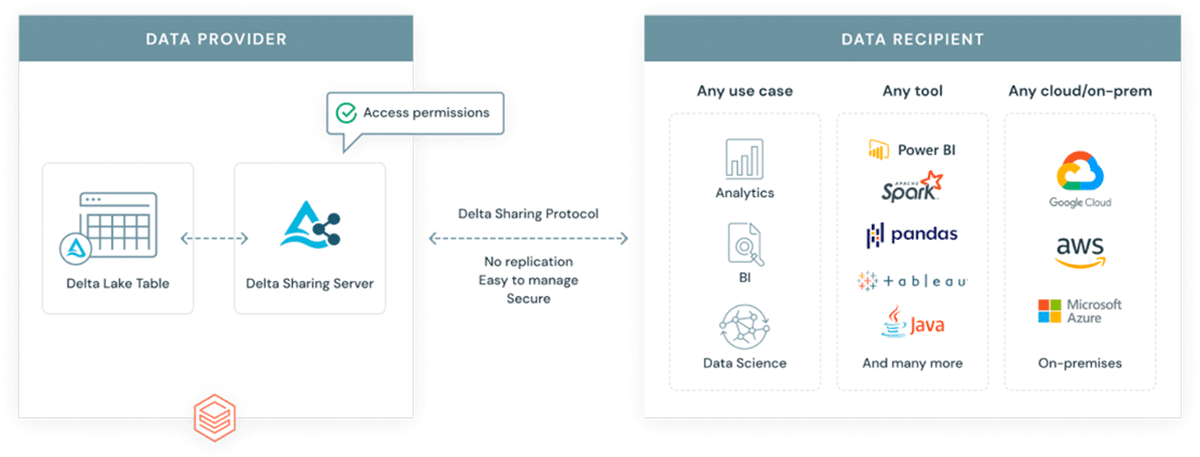
Warum ein weiteres Format in ein bereits komplexes Ökosystem einführen? GeoParquet ist kein neues Format – es ist eine Schema-Spezifikation für das Apache Parquet-Format, das bereits weit verbreitet und von der Industrie und der Community übernommen wird. Parquet als Basisformat unterstützt Binärspalten und ermöglicht die Speicherung beliebiger Daten-Payloads, gleichzeitig unterstützt das Format strukturierte Datenspalten, die Metadaten zusammen mit der Daten-Payload speichern können. Dies macht es zu einer Wahl, die Interoperabilität und Reproduzierbarkeit fördert. Schließlich wurde das Delta Lake-Format auf Parquet aufgebaut und bringt ACID-Eigenschaften mit. ACID-Eigenschaften eines Formats sind entscheidend für die Reproduzierbarkeit und für vertrauenswürdige Ergebnisse. Darüber hinaus ist Delta das Format, das von der skalierbaren Datenfreigabelösung Delta Sharing verwendet wird. Delta Sharing ermöglicht unternehmensweite Datenfreigaben zwischen jeder Public Cloud mit Databricks (DIY-Optionen für Private Clouds sind mit Open-Source-Bausteinen verfügbar). Delta Sharing abstrahiert vollständig die Notwendigkeit von benutzerdefinierten REST-APIs für die Bereitstellung von Daten für andere Dritte. Jede in Delta gespeicherte Datenressource (mit GeoParquet-Schema) wird automatisch zu einem Datenprodukt, das externen Parteien auf kontrollierte und verwaltete Weise zur Verfügung gestellt werden kann. Delta Sharing wurde von Grund auf mit Blick auf Sicherheitspraktiken entwickelt.
{kind=link}
Kreislauf-Datenwirtschaft
Nach den Konzepten aus dem Bereich Nachhaltigkeit können wir eine Kreislauf-Datenwirtschaft als ein System definieren, in dem Daten gesammelt, geteilt und genutzt werden, um ihren Wert zu maximieren und gleichzeitig Abfall und negative Auswirkungen zu minimieren, wie z. B. unnötige Rechenzeit, unzuverlässige Erkenntnisse oder voreingenommene Aktionen aufgrund von Datenverschmutzung. Wiederverwendbarkeit ist das Schlüsselkonzept in dieser Betrachtung: Wie können wir die „Erfindung des Rades“ minimieren? Es gibt unzählige Datenbestände da draußen, die dasselbe Gebiet, dieselben Konzepte mit nur geringfügigen Änderungen darstellen, um einem bestimmten Anwendungsfall besser zu entsprechen. Liegt das an den tatsächlichen Optimierungen oder daran, dass es einfacher war, eine neue Kopie der Bestände zu erstellen, als die vorhandenen wiederzuverwenden? Oder war es zu schwierig, die vorhandenen Datenbestände zu finden, oder vielleicht war es zu komplex, Datenzugriffsmuster zu definieren?
Die Duplizierung von Datenbeständen hat viele negative Aspekte sowohl für FAIR-Überlegungen als auch für die Wertpyramide der Daten. Viele unterschiedliche, ähnliche (aber unterschiedliche) Datenbestände, die dasselbe Gebiet und dieselben Konzepte darstellen, können die Einfachheitsüberlegungen des Datenbereichs beeinträchtigen – es wird schwierig, den Datenbestand zu identifizieren, dem wir tatsächlich vertrauen können. Es kann auch sehr negative Auswirkungen auf die Gewohnheitsbildung haben: Viele Nischengemeinschaften werden entstehen, die sich selbst standardisieren und die Best Practices des breiteren Ökosystems ignorieren, oder schlimmer noch, sie werden sich überhaupt nicht standardisieren.
In einer Kreislauf-Datenwirtschaft werden Daten als wertvolle Ressource behandelt, die zur Schaffung neuer Produkte und Dienstleistungen sowie zur Verbesserung bestehender Produkte und Dienstleistungen verwendet werden können. Dieser Ansatz fördert die Wiederverwendung und das Recycling von Daten, anstatt sie als Wegwerfartikel zu behandeln. Wiederum verwenden wir die Nachhaltigkeitsanalogie im wörtlichen Sinne – wir argumentieren, dass dies der richtige Weg ist, das Problem anzugehen. Datenverschmutzung ist eine reale Herausforderung für Organisationen, sowohl intern als auch extern. Ein Artikel von The Guardian besagt, dass weniger als 1 % der gesammelten Daten tatsächlich analysiert werden. Es gibt zu viele Datenredundanzen, der Großteil der Daten ist schwer zugänglich und die Ableitung tatsächlicher Werte ist zu umständlich. Die Kreislauf-Datenwirtschaft fördert Best Practices und die Wiederverwendbarkeit bestehender Datenbestände, was eine konsistentere Interpretation und tiefere Einblicke in das breitere Daten-Ökosystem ermöglicht.
{kind=link}
Interoperabilität ist eine Schlüsselkomponente der FAIR-Datenprinzipien, und aus der Interoperabilität ergibt sich die Frage der Kreislaufwirtschaft. Wie können wir ein Ökosystem entwerfen, das die Datennutzung und Datenwiederverwendung maximiert? Auch hier halten FAIR und die Wertpyramide Antworten bereit. Die Auffindbarkeit von Daten ist der Schlüssel zur Datenwiederverwendung und zur Lösung von Datenverschmutzungsproblemen. Mit leicht auffindbaren Datenbeständen können wir die Neuerstellung derselben Datenbestände an mehreren Stellen mit nur geringfügigen Änderungen vermeiden. Stattdessen erhalten wir ein kohärentes Daten-Ökosystem mit Daten, die leicht kombiniert und wiederverwendet werden können. Databricks hat kürzlich den Databricks Marketplace angekündigt. Die Idee hinter dem Marktplatz steht im Einklang mit der ursprünglichen Definition eines Datenprodukts von DJ Patel. Der Marktplatz wird die Freigabe von Datensätzen, Notebooks, Dashboards und Machine-Learning-Modellen unterstützen. Der entscheidende Baustein für einen solchen Marktplatz ist das Konzept von Delta Sharing – der skalierbare, flexible und robuste Kanal für die Freigabe beliebiger Daten – einschließlich Geodaten.
Die Entwicklung skalierbarer Datenprodukte für den Marktplatz ist entscheidend. Um den Mehrwert jedes Datenprodukts zu maximieren, sollten die FAIR-Prinzipien und die Produktwertpyramide stark berücksichtigt werden. Ohne diese Leitprinzipien werden wir die bereits bestehenden Probleme in den aktuellen Systemen nur noch verstärken. Jedes Datenprodukt sollte ein einzigartiges Problem lösen und dies auf einfache, reproduzierbare und robuste Weise tun.
Lesen Sie mehr darüber, wie die Databricks Lakehouse Platform Ihnen helfen kann, die Wertschöpfungszeit Ihrer Datenprodukte zu beschleunigen, in unserem eBook – Ein neuer Ansatz für den Datenaustausch.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.