Best Practices für die LLM-Auswertung von RAG-Anwendungen
Eine Fallstudie zum Databricks-Dokumentations-Bot
von Quinn Leng, Kasey Uhlenhuth und Alkis Polyzotis
Chatbots sind der am weitesten verbreitete Anwendungsfall für die Nutzung der leistungsstarken Chat- und Denkfähigkeiten von großen Sprachmodellen (LLM). Die RAG-Architektur (Retrieval Augmented Generation) entwickelt sich schnell zum Industriestandard für die Entwicklung von Chatbots, da sie die Vorteile einer Wissensdatenbank (über einen Vektorspeicher) und generativer Modelle (z. B. GPT-3.5 und GPT-4) kombiniert, um Halluzinationen zu reduzieren, aktuelle Informationen zu gewährleisten und domänenspezifisches Wissen zu nutzen. Die Bewertung der Qualität von Chatbot-Antworten bleibt jedoch bis heute ein ungelöstes Problem. Da keine Industriestandards definiert sind, greifen Unternehmen auf menschliche Bewertungen (Label) zurück – was zeitaufwendig und schwer zu skalieren ist.
Wir haben die Theorie in die Praxis umgesetzt, um Best Practices für die automatisierte Evaluierung von LLMs zu entwickeln, damit Sie RAG-Anwendungen schnell und zuverlässig in der Produktion bereitstellen können. Dieser Blogbeitrag ist der erste in einer Reihe von Untersuchungen, die wir bei Databricks durchführen, um Erkenntnisse zur LLM-Evaluierung zu liefern. Die gesamte Recherche in diesem Beitrag stammt von Quinn Leng, Senior Software Engineer bei Databricks und Schöpfer des Databricks Documentation KI Assistant.
Herausforderungen bei der automatischen Evaluierung in der Praxis
Kürzlich hat die LLM-Community die Verwendung von „LLMs als Richter“ für die automatisierte Bewertung untersucht, wobei viele leistungsstarke LLMs wie GPT-4 für die Bewertung ihrer LLM-Ausgaben einsetzen. Die Forschungsarbeit der lmsys-Gruppe untersucht die Machbarkeit und die Vor- und Nachteile der Verwendung verschiedener LLMs (GPT-4, ClaudeV1, GPT-3.5) als Richter für Tasks in den Bereichen Schreiben, Mathematik und Allgemeinwissen.
Trotz all dieser großartigen Forschung gibt es immer noch viele offene Fragen zur praktischen Anwendung von LLM-Juroren:
- Abgleich mit menschlicher Bewertung: Wie gut spiegelt die Bewertung eines LLM-Gutachters speziell für einen Dokumenten-Q&A-Chatbot die tatsächliche menschliche Präferenz in Bezug auf Korrektheit, Lesbarkeit und Vollständigkeit der Antworten wider?
- Genauigkeit durch Beispiele: Wie wirksam ist es, dem LLM-Bewerter einige Bewertungsbeispiele zur Verfügung zu stellen, und wie stark erhöht dies die Zuverlässigkeit und Wiederverwendbarkeit des LLM-Bewerters bei unterschiedlichen Metriken?
- Angemessene Bewertungsskalen: Welche Bewertungsskala wird empfohlen, da verschiedene Frameworks unterschiedliche Bewertungsskalen verwenden (z. B. verwendet AzureML eine Skala von 0 bis 100, während langchain binäre Skalen verwendet)?
- Anwendbarkeit über verschiedene Anwendungsfälle hinweg: Inwieweit kann dieselbe Evaluationsmetrik (z. B. Korrektheit) für verschiedene Anwendungsfälle (z. B. zwangloser Chat, Inhaltszusammenfassung, Retrieval-Augmented Generation) wiederverwendet werden?
Effektive automatische Evaluierung für RAG-Anwendungen
Wir haben die möglichen Optionen für die oben genannten Fragen im Kontext unserer eigenen Chatbot-Anwendung bei Databricks untersucht. Wir glauben, dass sich unsere Ergebnisse verallgemeinern lassen und somit Ihrem Team helfen können, RAG-basierte Chatbots kostengünstiger und schneller zu evaluieren:
- LLM-as-a-judge stimmt in über 80 % der Beurteilungen mit der menschlichen Bewertung überein. Die Verwendung von LLMs als Bewerter für die Evaluierung unseres dokumentenbasierten Chatbots war ebenso effektiv wie menschliche Bewerter, wobei in über 80 % der Beurteilungen die exakte Punktzahl erreicht wurde und der Abstand in über 95 % der Beurteilungen innerhalb von 1 Punkt (auf einer Skala von 0 bis 3) lag.
- Kosten sparen durch die Verwendung von GPT-3.5 mit Beispielen. GPT-3.5 kann als LLM-Bewerter verwendet werden, wenn Sie Beispiele für jeden Bewertungswert bereitstellen. Aufgrund der Begrenzung der Kontextgröße ist es nur praktikabel, eine Bewertungs-Scale mit geringer Präzision zu verwenden. Die Verwendung von GPT-3.5 mit Beispielen anstelle von GPT-4 senkt die Kosten des LLM-Bewerters um das 10-fache und erhöht die Geschwindigkeit um mehr als das 3-fache.
- Verwenden Sie für eine einfachere Interpretation Bewertungsskalen mit geringer Präzision. Wir haben festgestellt, dass Bewertungswerte mit geringerer Präzision wie 0, 1, 2, 3 oder sogar binär (0, 1) die Genauigkeit im Vergleich zu Skalen mit höherer Präzision wie 0 bis 10,0 oder 0 bis 100,0 weitgehend beibehalten können, während es gleichzeitig erheblich einfacher wird, Bewertungsraster sowohl für menschliche Annotatoren als auch für LLM-Bewerter bereitzustellen. Die Verwendung einer Skala mit geringerer Präzision ermöglicht auch die Konsistenz der Bewertungsskalen zwischen verschiedenen LLM-Bewertern (z. B. zwischen GPT-4 und claude2).
- RAG-Anwendungen erfordern ihre eigenen Benchmarks. Ein Modell kann bei einem veröffentlichten, spezialisierten Benchmark eine gute Performance aufweisen (z. B. zwangloser Chat, Mathematik oder kreatives Schreiben), aber das garantiert keine gute Performance bei anderen Tasks (z. B. die Beantwortung von Fragen aus einem gegebenen Kontext). Benchmarks sollten nur verwendet werden, wenn der Anwendungsfall übereinstimmt, d. h., eine RAG-Anwendung sollte nur mit einem RAG-Benchmark bewertet werden.
Basierend auf unserer Forschung empfehlen wir die folgende Vorgehensweise bei der Verwendung eines LLM-Richters:
- Verwenden Sie eine Bewertungsskala von 1 bis 5
- Verwenden Sie GPT-4 als LLM-Juror ohne Beispiele, um Bewertungsregeln zu verstehen
- Wechseln Sie Ihren LLM-Richter zu GPT-3.5 mit einem Beispiel pro Bewertung
Unsere Methodik zur Festlegung der Best Practices
Im weiteren Verlauf dieses Beitrags wird die Reihe der Experimente vorgestellt, die wir zur Entwicklung dieser Best Practices durchgeführt haben.
Experiment-Setup
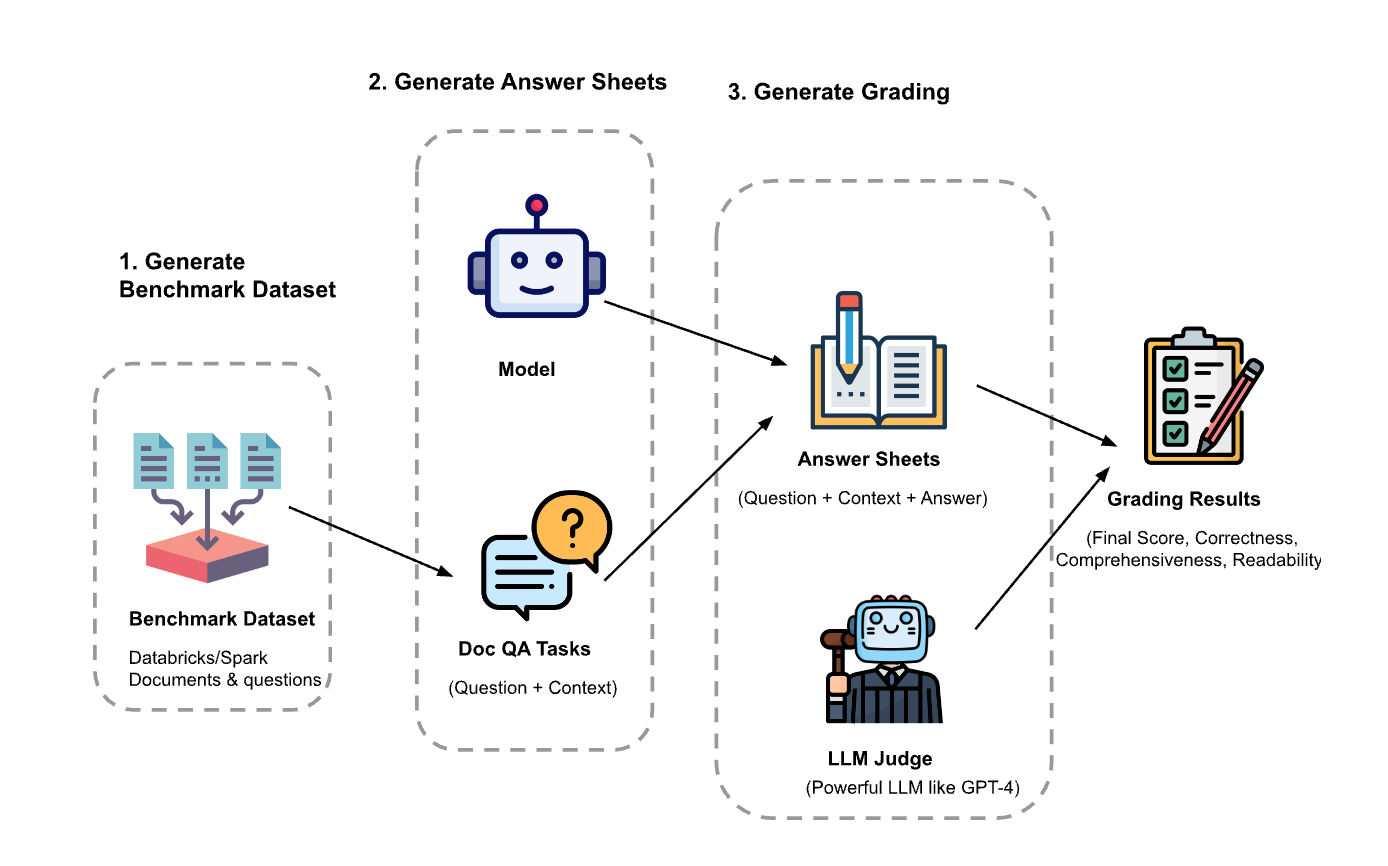
Das Experiment hatte drei Schritte:
Evaluierungs-Dataset generieren: Wir haben ein Dataset aus 100 Fragen und Kontext aus Databricks-Dokumenten erstellt. Der Kontext stellt (Teile von) Dokumenten dar, die für die Frage relevant sind.

- Antwortbögen generieren: Mithilfe des Evaluierungs-Datasets haben wir verschiedene Sprachmodelle gepromptet, Antworten zu generieren, und die Frage-Kontext-Antwort-Paare in einem Dataset namens „Antwortbögen“ gespeichert. In dieser Untersuchung haben wir GPT-4, GPT-3.5, Claude-v1, Llama2-70b-chat, Vicuna-33b und mpt-30b-chat verwendet.
- Noten generieren: Anhand der Antwortbögen haben wir verschiedene LLMs verwendet, um Noten und die Begründungen für die Noten zu generieren. Die Noten sind eine zusammengesetzte Bewertung aus Korrektheit (Gewichtung: 60 %), Vollständigkeit (Gewichtung: 20 %) und Lesbarkeit (Gewichtung: 20 %). Wir haben dieses Gewichtungsschema gewählt, um unsere Präferenz für die Korrektheit der generierten Antworten widerzuspiegeln. Andere Anwendungen können diese Gewichtungen anders abstimmen, aber wir erwarten, dass die Korrektheit ein dominanter Faktor bleibt.
Zusätzlich wurden die folgenden Techniken verwendet, um einen Positionsbias zu vermeiden und die Zuverlässigkeit zu verbessern:
- Niedrige Temperatur (Temperatur 0,1), um die Reproduzierbarkeit zu gewährleisten.
- Bewertung einzelner Antworten anstelle von paarweisem Vergleich.
- Eine Gedankenkette, die das LLM vor der Abgabe der Endbewertung über den Bewertungsprozess schlussfolgern lässt.
- Few-Shot-Generierung, bei der dem LLM mehrere Beispiele in der Bewertungsrubrik für jeden Punktwert zu jedem Faktor (Korrektheit, Vollständigkeit, Lesbarkeit) zur Verfügung gestellt werden.
Experiment 1: Abgleich mit menschlicher Bewertung
Um die Übereinstimmung zwischen menschlichen Annotatoren und LLM-Juroren zu überprüfen, schickten wir Antwortbögen (Bewertungs-Scale 0–3) von gpt-3.5-turbo und vicuna-33b an ein Labeling-Unternehmen, um menschliche Labels zu sammeln. Anschließend verglichen wir das Ergebnis mit der Bewertungsausgabe von GPT-4. Nachfolgend die Ergebnisse:
Menschliche und GPT-4-Bewerter können eine Übereinstimmung von über 80 % bei der Bewertung von Korrektheit und Lesbarkeit erreichen. Und wenn wir die Anforderung auf eine Punktedifferenz von kleiner oder gleich 1 senken, kann der Übereinstimmungsgrad über 95 % erreichen.
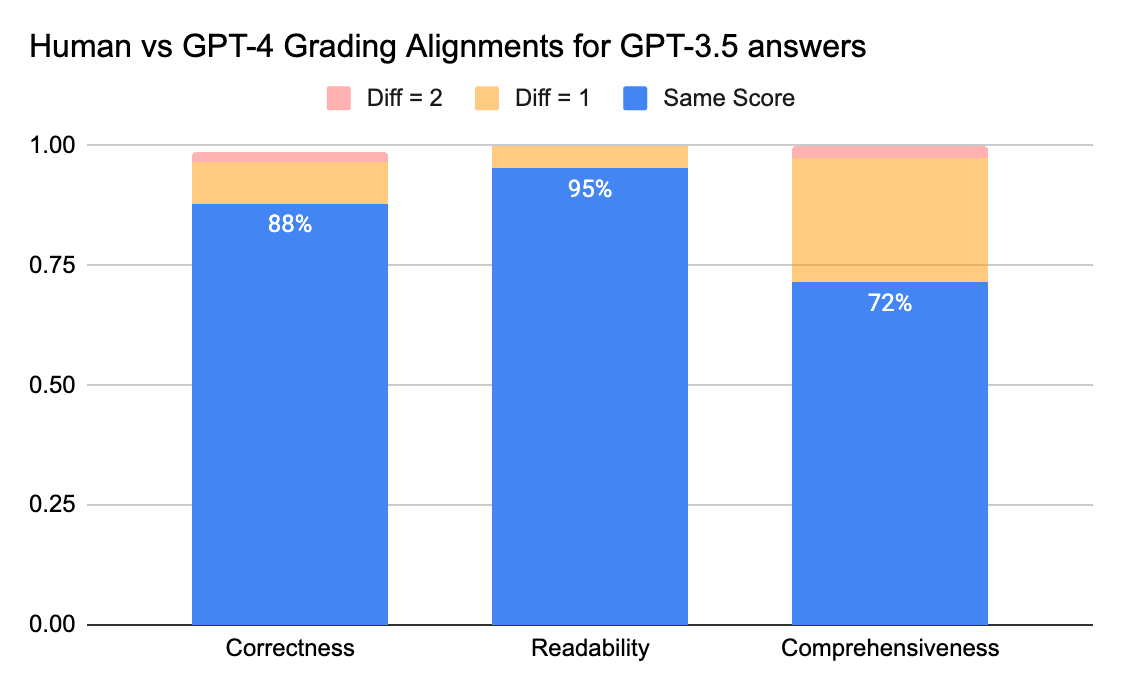
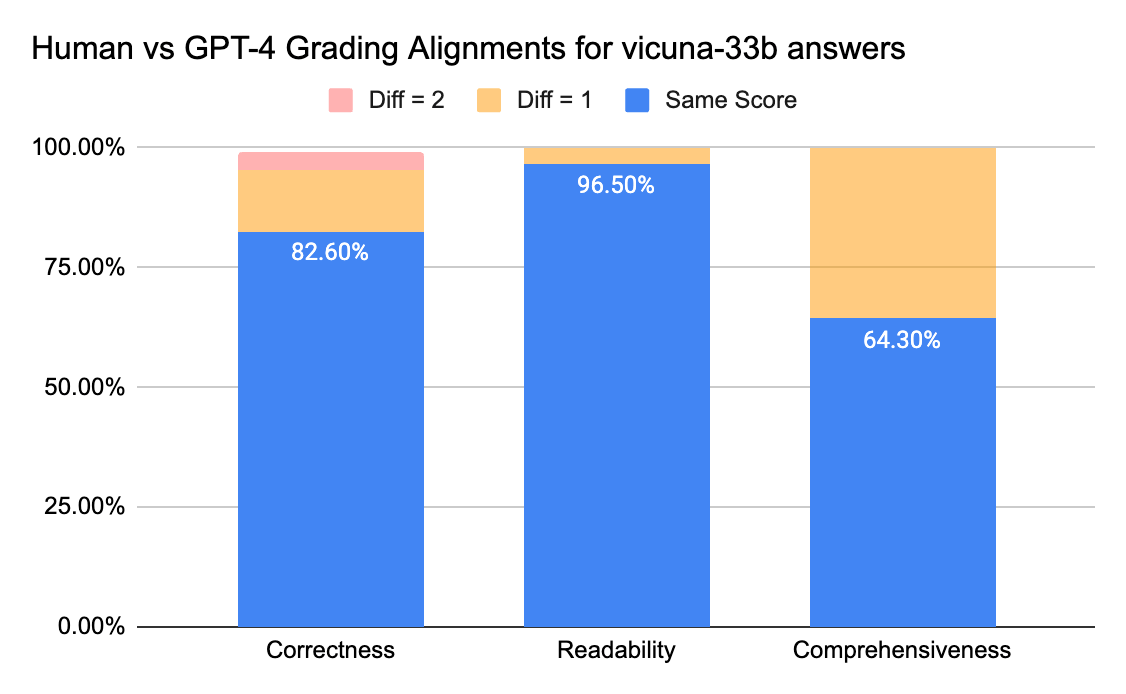
Die Metrik für Vollständigkeit weist eine geringere Übereinstimmung auf, was dem Feedback von Business-Stakeholdern entspricht, die meinten, „vollständig“ sei subjektiver als Metriken wie Korrektheit oder Lesbarkeit.
Experiment 2: Genauigkeit durch Beispiele
Das lmsys-Paper verwendet diesen Prompt, um den LLM-Bewerter anzuweisen, die Antwort auf der Grundlage von Hilfreichkeit, Relevanz, Genauigkeit, Tiefe, Kreativität und Detaillierungsgrad zu bewerten. Das Paper teilt jedoch keine genauen Angaben zum Bewertungsraster mit. In unserer Forschung haben wir festgestellt, dass viele Faktoren das Endergebnis erheblich beeinflussen können, zum Beispiel:
- Die Bedeutung verschiedener Faktoren: Hilfreichheit, Relevanz, Genauigkeit, Tiefe, Kreativität
- Die Interpretation von Faktoren wie Hilfsbereitschaft ist mehrdeutig.
- Wenn verschiedene Faktoren miteinander in Konflikt stehen, wobei eine Antwort hilfreich, aber nicht genau ist
Wir haben ein Bewertungsschema entwickelt, um einen LLM-Juror für eine bestimmte Bewertungs-Scale anzuweisen, indem wir Folgendes ausprobiert haben:
- Ursprünglicher Prompt: Nachfolgend finden Sie den ursprünglichen Prompt, der im lmsys-Paper verwendet wird:
|
Wir haben den ursprünglichen Prompt des lmsys-Papers angepasst, um unsere Metriken für Korrektheit, Vollständigkeit und Lesbarkeit auszugeben, und den Bewerter außerdem aufgefordert, vor jeder Bewertung eine einzeilige Begründung zu liefern (um von der Chain-of-Thought-Argumentation zu profitieren). Nachfolgend finden Sie die Zero-Shot-Version des Prompts, die keine Beispiele enthält, und die Few-Shot-Version des Prompts, die für jede Bewertung ein Beispiel enthält. Anschließend haben wir dieselben Antwortbögen als Eingabe verwendet und die bewerteten Ergebnisse der beiden Prompt-Typen verglichen.
- Zero-Shot-Lernen: Fordert den LLM-Judge auf, unsere Metriken zu Korrektheit, Vollständigkeit und Lesbarkeit auszugeben und eine einzeilige Begründung für jede Bewertung zu liefern.
- Few-Shot-Learning: Wir haben den Zero-Shot-Prompt angepasst, um explizite Beispiele für jede Bewertung auf der Scale bereitzustellen. Der neue Prompt:
Aus diesem Experiment haben wir mehrere Erkenntnisse gewonnen:
- Die Verwendung des Few-Shot-Prompts mit GPT-4 machte keinen offensichtlichen Unterschied bei der Konsistenz der Ergebnisse. Als wir die detaillierte Bewertungsrubrik mit Beispielen hinzufügten, konnten wir keine merkliche Verbesserung der Bewertungsergebnisse von GPT-4 bei verschiedenen LLM-Modellen feststellen. Interessanterweise verursachte dies eine leichte Varianz in der Bandbreite der Ergebnisse.
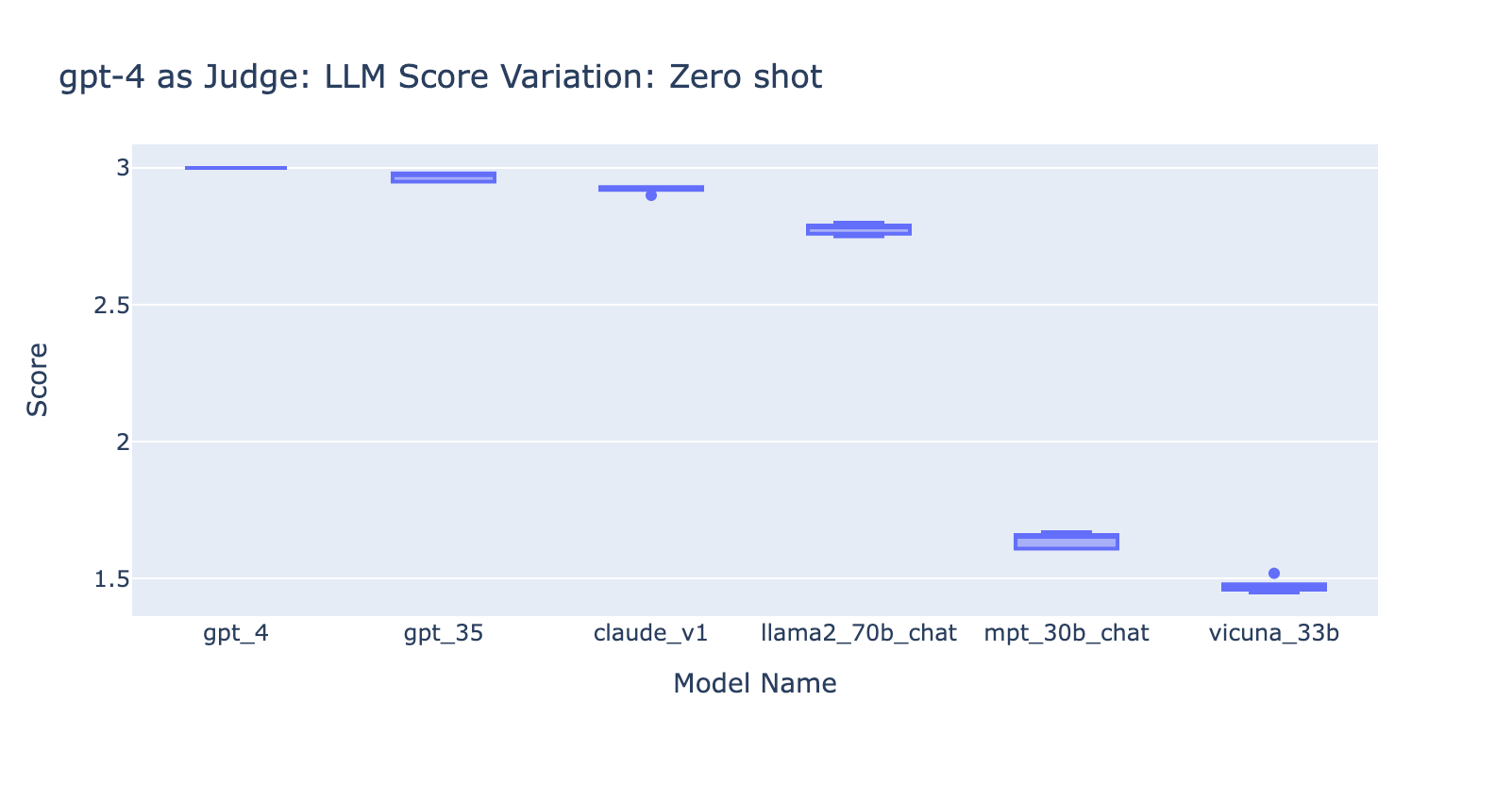
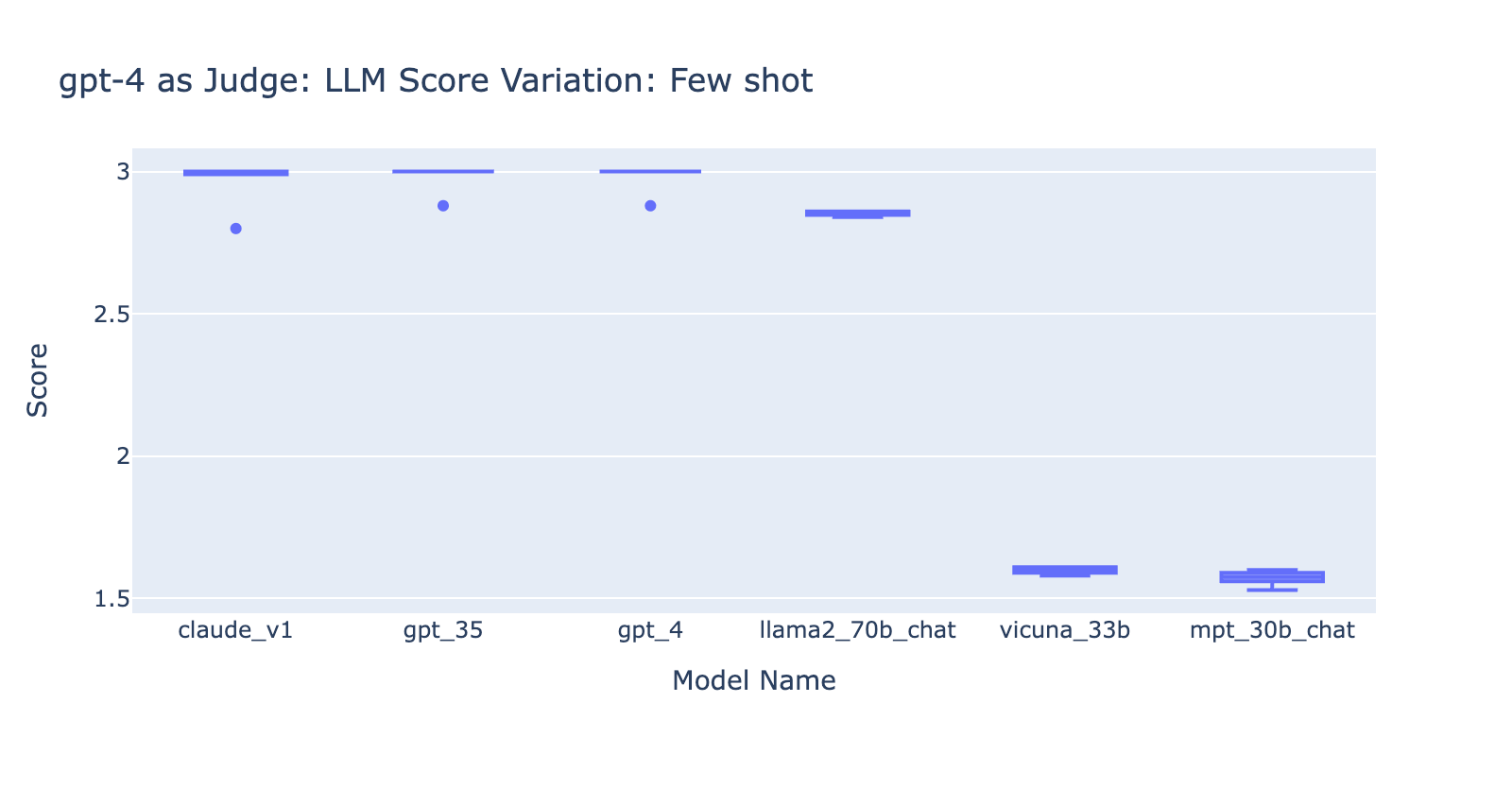
- Das Hinzufügen einiger Beispiele für GPT-3.5-turbo-16k verbessert die Konsistenz der Bewertungen erheblich und macht das Ergebnis nutzbar. Das Hinzufügen eines detaillierten Bewertungsrasters/von Beispielen führt zu einer sehr deutlichen Verbesserung des Bewertungsergebnisses von GPT-3.5 (Diagramm auf der rechten Seite). Obwohl sich der tatsächliche durchschnittliche Bewertungswert zwischen GPT-4 und GPT-3.5 geringfügig unterscheidet (Bewertung 3,0 vs. Bewertung 2,6), bleiben die Rangfolge und die Präzision ziemlich konsistent.
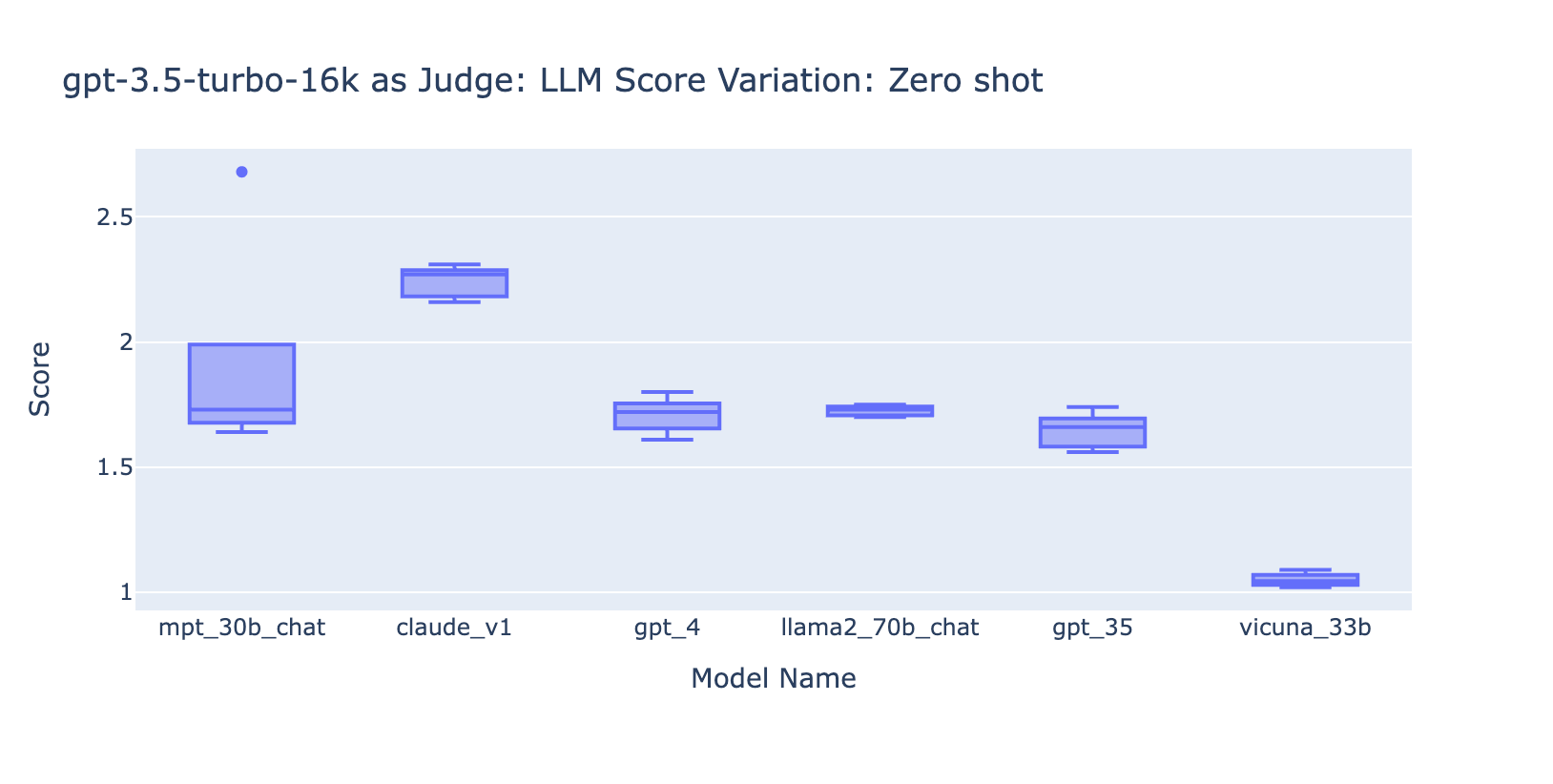
- Im Gegensatz dazu (Screenshot links) liefert die Verwendung von GPT-3.5 ohne eine Bewertungsrubrik sehr inkonsistente Ergebnisse und ist völlig unbrauchbar
- Beachten Sie, dass wir GPT-3.5-turbo-16k verwenden anstelle von GPT-3.5-turbo da der Prompt größer als 4k Tokens sein kann.
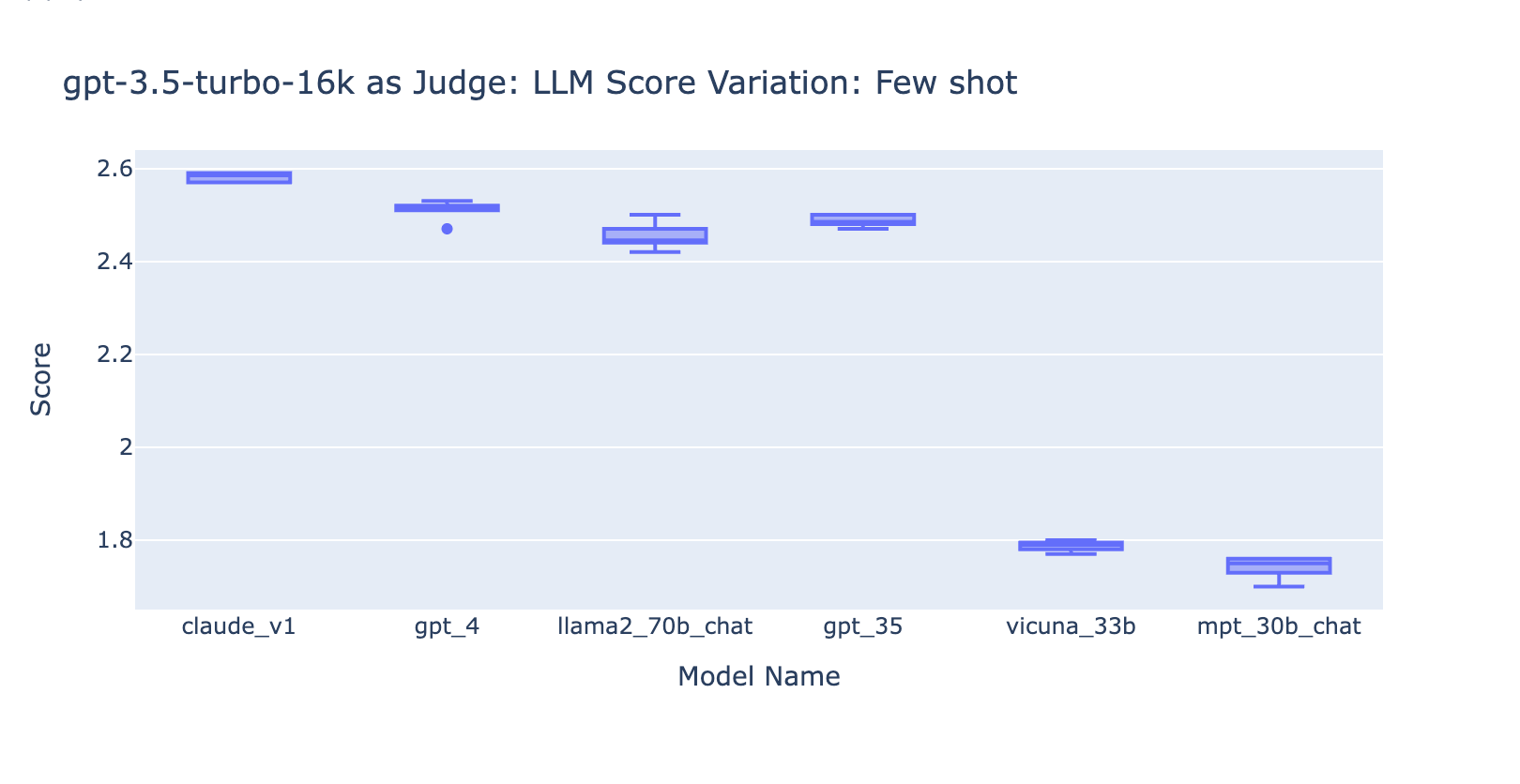
Experiment 3: Angemessene Bewertungsskalen
Das Paper „LLM-as-judge“ verwendet eine nicht-ganzzahlige Scale von 0 bis 10 (d. h. float) für die Bewertungsskala; mit anderen Worten, es wird ein hochpräzises Bewertungsschema für die Endnote verwendet. Wir haben festgestellt, dass diese hochpräzisen Skalen bei den nachgelagerten Prozessen die folgenden Probleme verursachen:
- Konsistenz: Bewerter – sowohl menschliche als auch LLM – hatten Schwierigkeiten, bei der Bewertung mit hoher Präzision den gleichen Standard für die gleiche Punktzahl beizubehalten. Als Ergebnis stellten wir fest, dass die ausgegebenen Punktzahlen bei den Juroren weniger konsistent sind, wenn man von Skalen mit niedriger Präzision zu solchen mit hoher Präzision übergeht.
- Erklärbarkeit: Wenn wir die von LLMs beurteilten Ergebnisse mit von Menschen beurteilten Ergebnissen kreuzvalidieren wollen, müssen wir außerdem Anleitungen zur Bewertung der Antworten bereitstellen. Es ist sehr schwierig, genaue Anweisungen für jede „Punktzahl“ auf einer hochpräzisen Bewertungsskala zu geben – was ist zum Beispiel ein gutes Beispiel für eine Antwort, die mit 5,1 im Vergleich zu 5,6 bewertet wird?
Wir haben mit verschiedenen Bewertungsskalen mit niedriger Genauigkeit experimentiert, um eine Anleitung für die „beste“ Skala zu geben. Letztendlich empfehlen wir eine ganzzahlige Skala von 0–3 oder 0–4 (wenn Sie sich an die Likert -Skala halten möchten). Wir haben die Skalen 0–10, 1–5, 0–3 und 0–1 ausprobiert und dabei Folgendes gelernt:
- Eine binäre Bewertung funktioniert für einfache Metriken wie „Benutzerfreundlichkeit“ oder „gut/schlecht“.
- Bei Skalen wie 0-10 ist es schwierig, Unterscheidungskriterien zwischen allen Bewertungen zu finden.
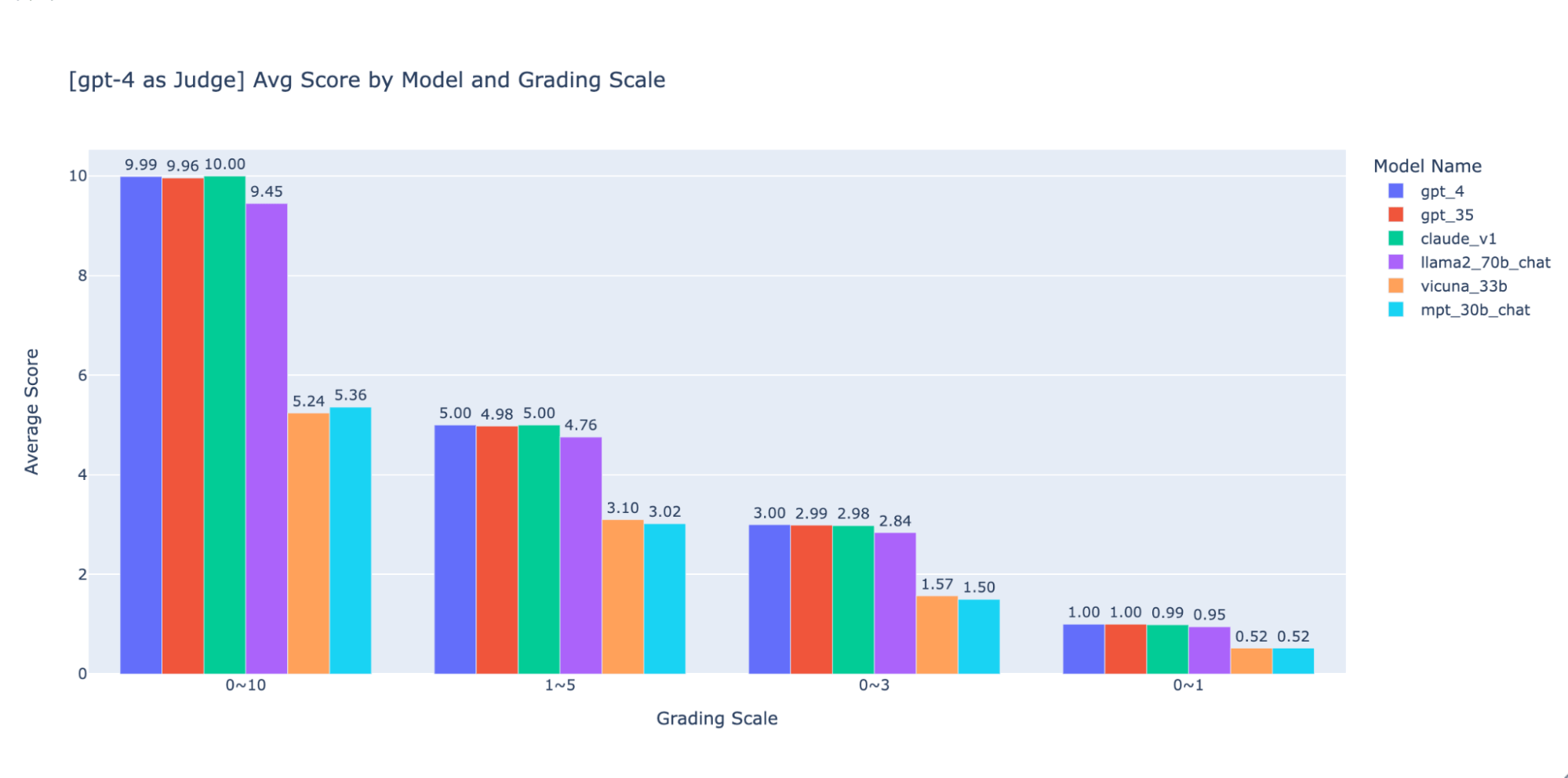
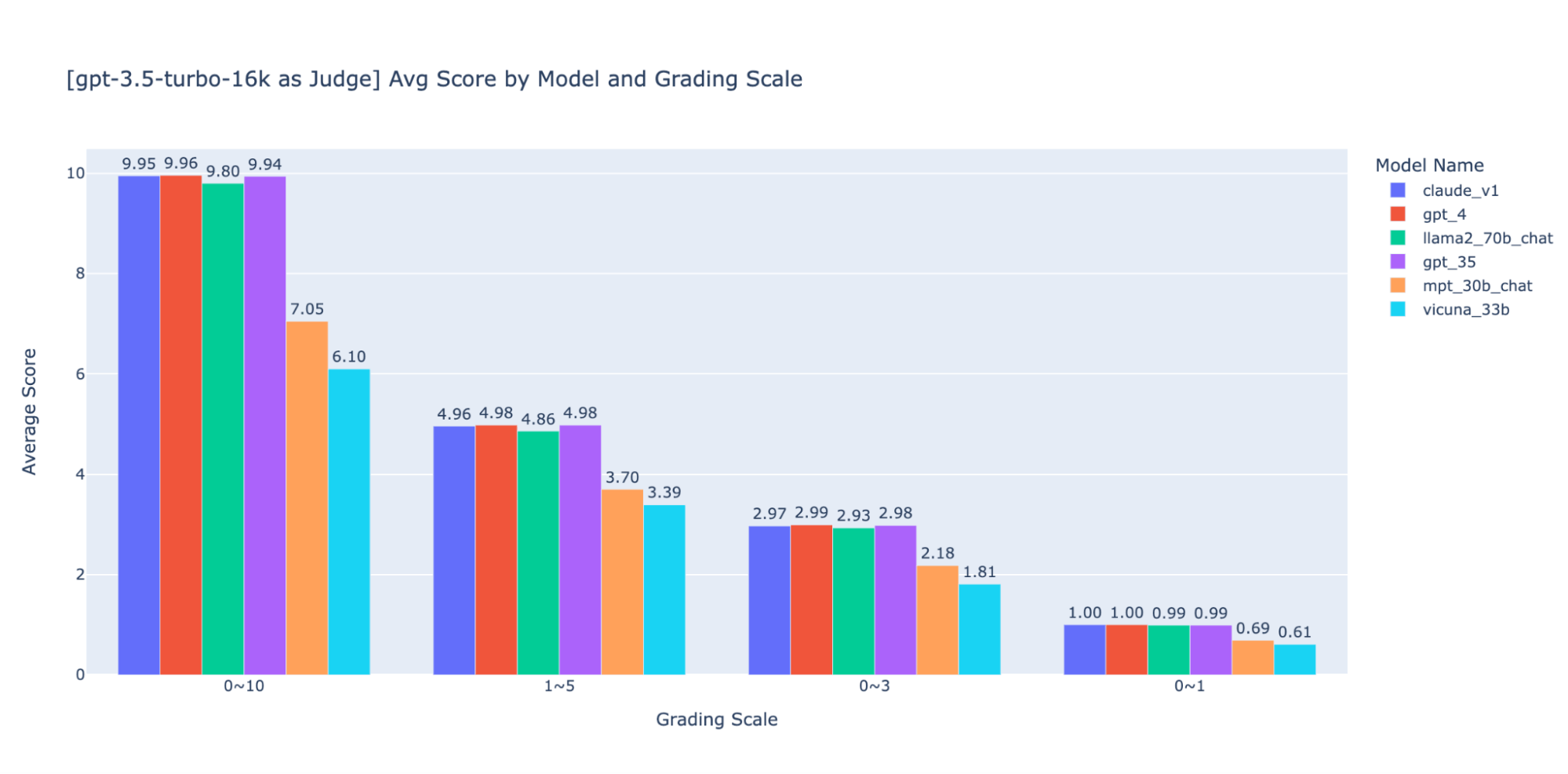
Wie in den obigen Diagrammen gezeigt, können sowohl GPT-4 als auch GPT-3.5 bei Verwendung verschiedener Bewertungsskalen mit geringer Präzision ein konsistentes Ranking der Ergebnisse beibehalten. Daher kann die Verwendung einer niedrigeren Bewertungsskala wie 0~3 oder 1~5 die Präzision mit der Erklärbarkeit in Einklang bringen)
Daher empfehlen wir eine Skala von 0–3 oder 1–5, um die Abstimmung mit menschlichen Labels zu erleichtern, Bewertungskriterien nachzuvollziehen und Beispiele für jede Bewertung in dem Bereich anzugeben.
Experiment 4: Anwendbarkeit über verschiedene Anwendungsfälle hinweg
Das Paper LLM-as-judge zeigt, dass sowohl die LLM- als auch die menschliche Beurteilung das Vicuna-13B-Modell als nahen Konkurrenten zu GPT-3.5 einstufen:
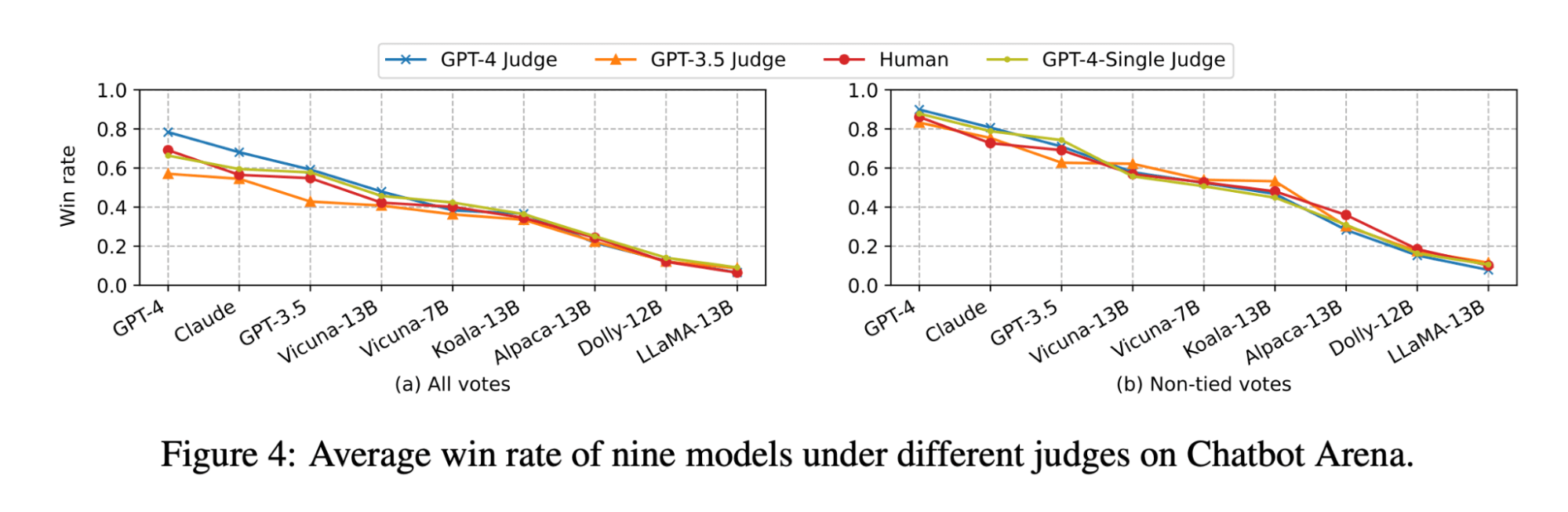
(Die Abbildung stammt aus Abbildung 4 des LLM-as-judge-Papers: https://arxiv.org/pdf/2306.05685.pdf )
Als wir jedoch die Modellreihe für unsere Anwendungsfälle im Bereich Dokumenten-Q&A einem Benchmark unterzogen, stellten wir fest, dass selbst das viel größere Vicuna-33B-Modell eine merklich schlechtere Performance als GPT-3.5 bei der Beantwortung von Fragen auf der Grundlage von Kontext aufweist. Diese Ergebnisse werden auch von GPT-4, GPT-3.5 und menschlichen Juroren bestätigt (wie in Experiment 1 erwähnt), die alle darin übereinstimmen, dass Vicuna-33B eine schlechtere Leistung als GPT-3.5 erbringt.
Wir haben uns den im Paper vorgeschlagenen Benchmark-Datensatz genauer angesehen und festgestellt, dass die 3 Aufgabenkategorien (Schreiben, Mathematik, Wissen) die Fähigkeit des Modells, eine Antwort auf der Grundlage eines Kontexts zu synthetisieren, nicht direkt widerspiegeln oder dazu beitragen. Stattdessen benötigen Dokument-Q&A-Anwendungsfälle intuitiv Benchmarks für Leseverständnis und das Befolgen von Anweisungen. Daher können die Evaluierungsergebnisse nicht zwischen den Anwendungsfällen übertragen werden und wir müssen anwendungsfallspezifische Benchmarks erstellen, um richtig zu bewerten, wie gut ein Modell die Kundenbedürfnisse erfüllen kann.
Nutzen Sie MLflow, um unsere Best Practices zu nutzen.
Mit den obigen Experimenten haben wir untersucht, wie verschiedene Faktoren die Bewertung eines Chatbots maßgeblich beeinflussen können, und bestätigt, dass LLM-as-a-judge die menschlichen Präferenzen für den Anwendungsfall der Dokumenten-Q&A weitgehend widerspiegeln kann. Bei Databricks entwickeln wir die MLflow Evaluation API basierend auf diesen Erkenntnissen weiter, um Ihrem Team dabei zu helfen, Ihre LLM-Anwendungen effektiv zu bewerten. MLflow 2.4 hat die Evaluation API für LLMs eingeführt, um die Textausgaben verschiedener Modelle nebeneinander zu vergleichen, MLflow 2.6 hat LLM-basierte Metriken für die Evaluierung wie Toxizität und Perplexität eingeführt, und wir arbeiten daran, LLM-as-a-judge in naher Zukunft zu unterstützen!
In der Zwischenzeit haben wir die Liste der Ressourcen, die wir für unsere Recherche herangezogen haben, unten zusammengestellt:
- Doc_qa-Repository
- Der Code und die Daten, die wir zur Durchführung der Experimente verwendet haben
- Forschungsarbeit „LLM-as-Judge“ von der lmsys group
- Das Paper ist die erste Forschungsarbeit, die LLM als Bewerter für Anwendungsfälle von zwanglosen Chats einsetzt. Es untersuchte ausgiebig die Machbarkeit sowie die Vor- und Nachteile des Einsatzes von LLM (GPT-4, ClaudeV1, GPT-3.5) als Bewerter für Tasks in den Bereichen Schreiben, Mathematik und Allgemeinwissen.
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.