Agentisches Schlussfolgern in der Praxis: Sinnfindung für strukturierte und unstrukturierte Daten
Unternehmensdaten sind selten isoliert nützlich. Fragen wie „Welche unserer Produkte verzeichneten in den letzten drei Monaten rückläufige Umsätze und welche potenziell damit zusammenhängenden Probleme werden in Kundenrezensionen auf verschiedenen Verkäuferseiten angesprochen?“ erfordern eine Analyse über eine Mischung aus strukturierten und unstrukturierten Datenquellen, einschließlich Data Lakes, Bewertungsdaten und Product Information Management-Systemen. In diesem Blogbeitrag zeigen wir, wie der Databricks Agent Bricks Supervisor Agent (SA) bei diesen komplexen, realitätsnahen Aufgaben durch mehrstufige Schlussfolgerungen, die auf einer Kombination aus strukturierten und unstrukturierten Daten basieren, helfen kann.
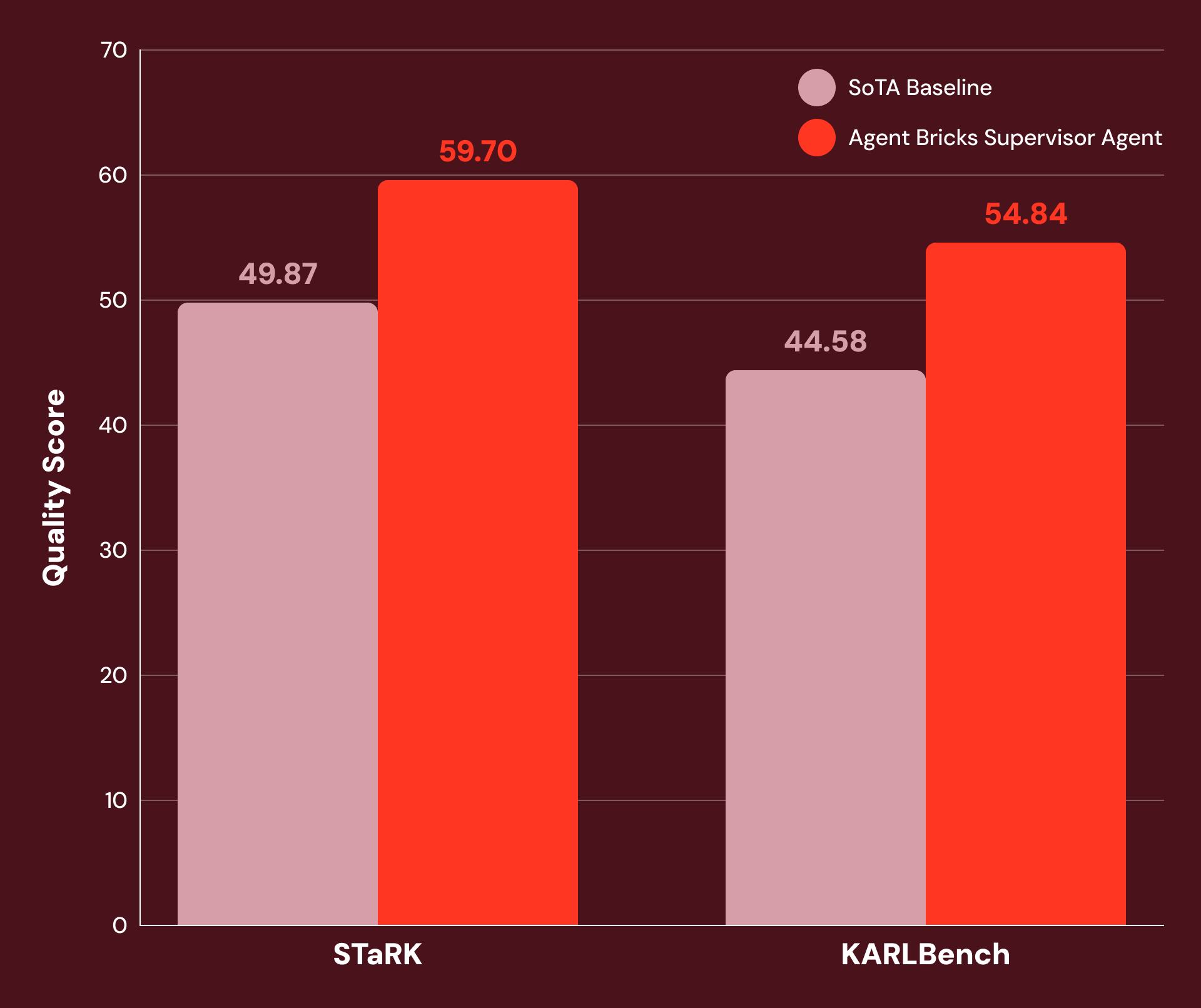
Mit abgestimmten Anweisungen und sorgfältiger Tool-Konfiguration stellen wir fest, dass SA bei einer Vielzahl von wissensintensiven Unternehmensaufgaben sehr leistungsfähig ist. Abbildung 1 zeigt, dass SA eine Verbesserung von 20 % oder mehr gegenüber SoTA-Baselines erzielt bei:
- STaRK: eine Suite von drei semi-strukturierten Retrieval-Aufgaben, die von Stanford-Forschern veröffentlicht wurden.
- KARLBench: eine Benchmark-Suite für komplexes, grounded Reasoning, die kürzlich von Databricks veröffentlicht wurde.
Supervisor Agent zeigt signifikante Fortschritte bei einer breiten Palette wirtschaftlich wertvoller Aufgaben: von akademischem Retrieval (+21 % bei STaRK-MAG) über biomedizinisches Reasoning (+38 % bei STaRK Prime) bis hin zu Finanzanalysen (+23 % bei FinanceBench).
Agenten-Setup
Agent Bricks Supervisor Agent ist ein deklarativer Agenten-Builder, der Agenten und Tools orchestriert. Er basiert auf aroll – einem internen Agenten-Framework zum Erstellen, Bewerten und Bereitstellen von mehrstufigen LLM-Workflows im großen Maßstab.1 aroll und SA wurden speziell für die fortgeschrittenen Agenten-Anwendungsfälle entwickelt, auf die unsere Kunden häufig stoßen.
aroll ermöglicht das Hinzufügen neuer Tools und benutzerdefinierter Anweisungen durch einfache Konfigurationsänderungen, kann Tausende von gleichzeitigen Konversationen und parallelen Tool-Ausführungen verarbeiten und integriert fortschrittliche Agenten-Orchestrierungs- und Kontextmanagement-Techniken, um Abfragen zu verfeinern und sich von teilweisen Antworten zu erholen. All dies ist heute mit SoTA-Single-Turn-Systemen schwer zu erreichen.
Da SA auf dieser flexiblen Architektur basiert, kann seine Qualität durch einfache Benutzerkuratierung, wie z. B. das Anpassen von Top-Level-Anweisungen oder das Verfeinern von Agentenbeschreibungen, kontinuierlich verbessert werden, ohne dass benutzerdefinierter Code geschrieben werden muss.
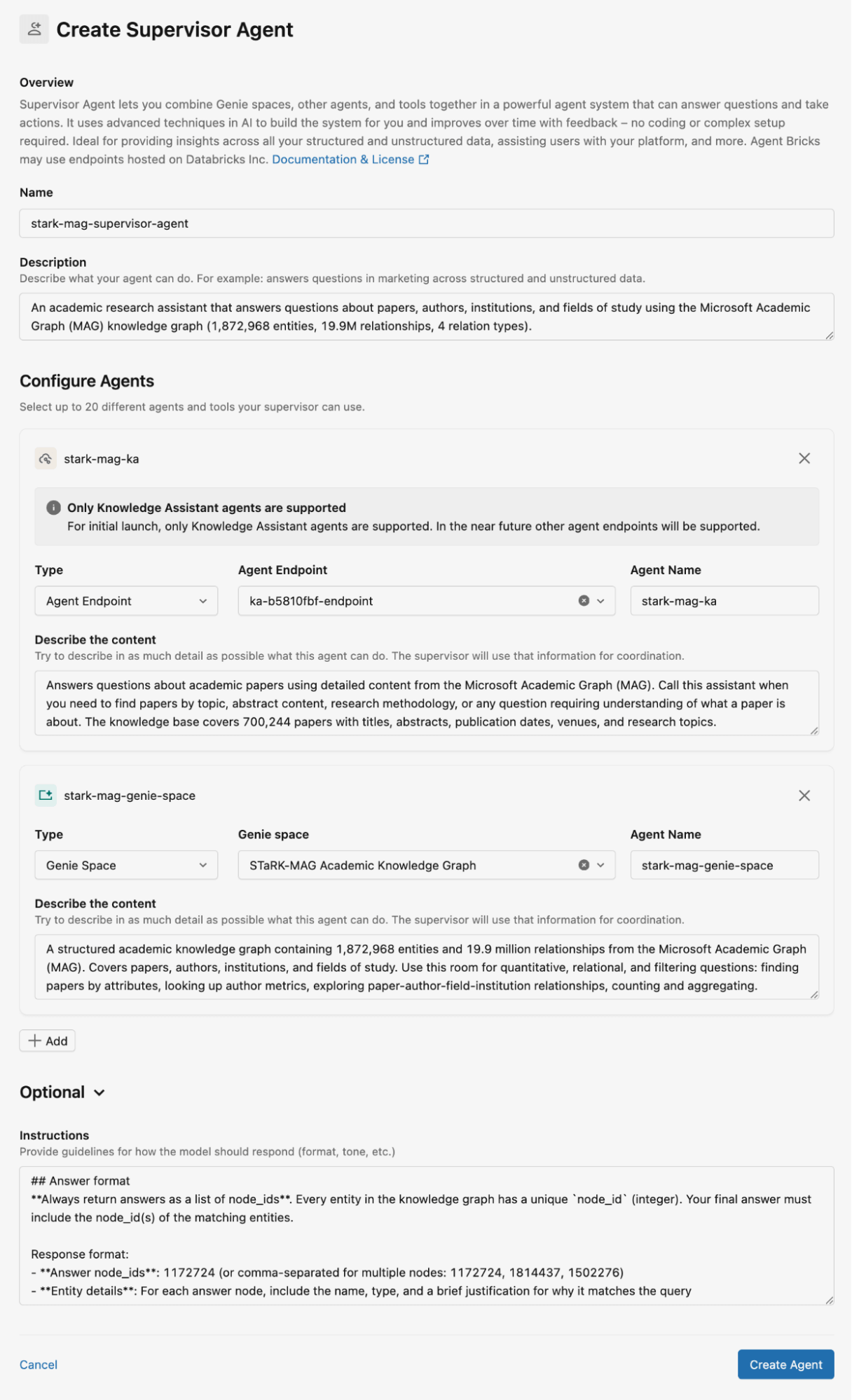
Abbildung 2 zeigt, wie wir den Supervisor Agent für den STaRK-MAG-Datensatz konfiguriert haben. In diesem Blogbeitrag verwenden wir Genie-Spaces zur Speicherung der relationalen Wissensdatenbanken und Knowledge Assistants zur Speicherung unstrukturierter Dokumente für den Abruf. Wir geben detaillierte Beschreibungen für alle Knowledge Assistants und Genie-Spaces sowie Anweisungen für die Agentenantworten.
Hybrid Reasoning: Strukturiert trifft Unstrukturiert
Um grounded Reasoning basierend auf einer Kombination aus strukturierten und unstrukturierten Daten zu bewerten, verwenden wir den STaRK-Benchmark, der drei Domänen umfasst:
- Amazon: Produktattribute (strukturiert) und Rezensionen (unstrukturiert)
- MAG: Zitationsnetzwerke (strukturiert) und wissenschaftliche Arbeiten (unstrukturiert)
- Prime: biomedizinische Entitäten (strukturiert) und Literatur (unstrukturiert)
Zum Beispiel erfordert „Finde mir eine Arbeit, die von einem Co-Autor mit 115 Arbeiten verfasst wurde und sich mit dem Rydberg-Atom beschäftigt“ die Kombination von strukturiertem Filtern („Co-Autor mit 115 Arbeiten“) mit unstrukturiertem Verständnis („über das Rydberg-Atom“). Die besten veröffentlichten Baselines verwenden Vektor-Ähnlichkeitssuche mit einem LLM-basierten Reranker – ein starker Single-Turn-Ansatz, der jedoch keine Abfragen über Datentypen hinweg zerlegen kann. Um einen fairen Vergleich zu gewährleisten, haben wir diese Baseline mit dem aktuellen SoTA-Fundierungsmodell neu ausgeführt, was eine erheblich stärkere Baseline darstellt.
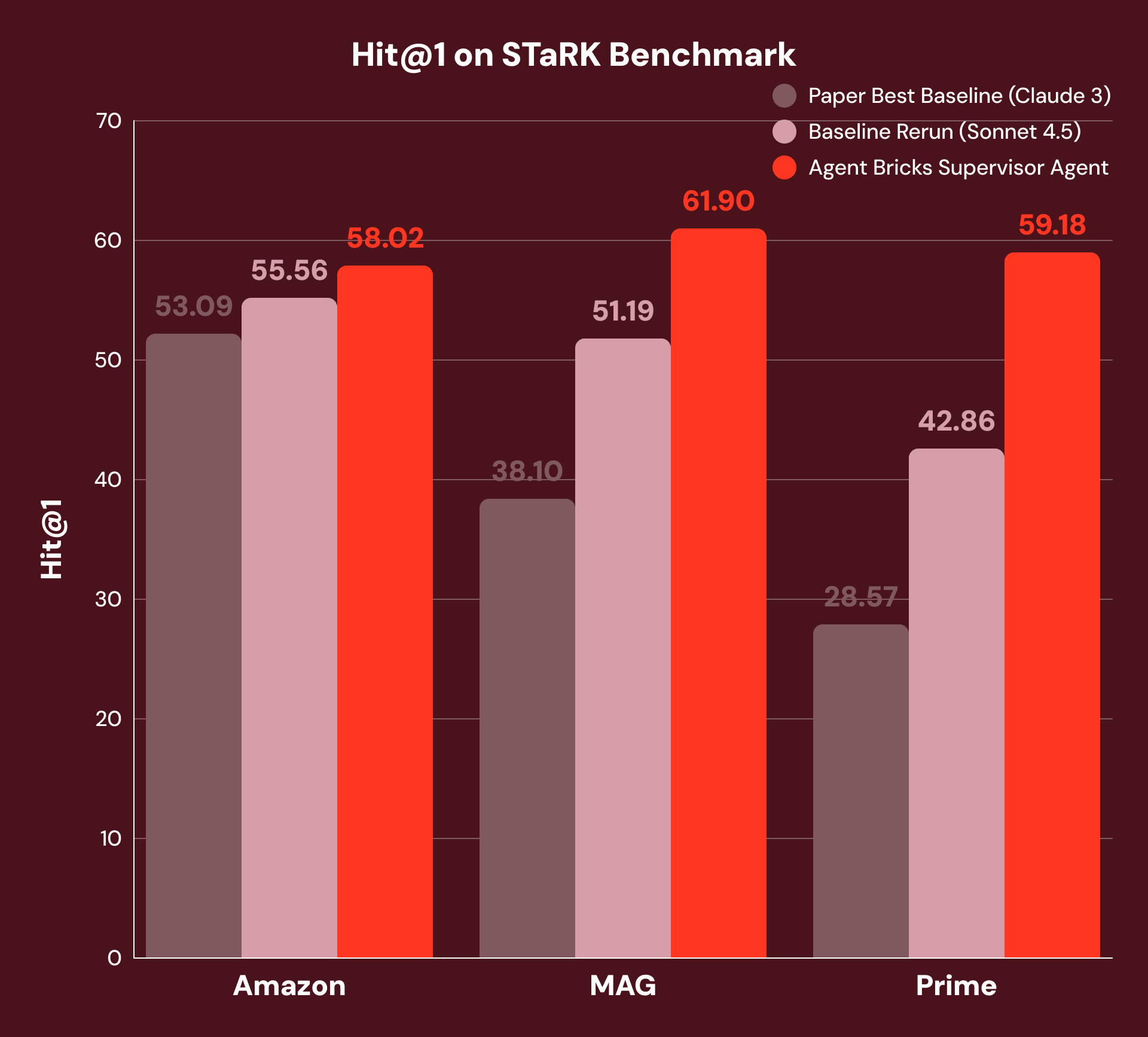
Mit unserem Ansatz zerlegt SA jede Frage, leitet Unterfragen an das entsprechende Tool weiter und synthetisiert Ergebnisse über mehrere Reasoning-Schritte hinweg. Wie Abbildung 3 zeigt, erzielt dies eine Verbesserung von +4 % Hit@1 bei Amazon, +21 % bei MAG und +38 % bei Prime gegenüber sowohl den besten ursprünglichen Baselines als auch unseren neu ausgeführten Baselines mit dem aktuellen SoTA-Fundierungsmodell. Die größten Verbesserungen sehen wir bei MAG und Prime, wo die Antwort die engste Integration von strukturierten und unstrukturierten Daten erfordert.
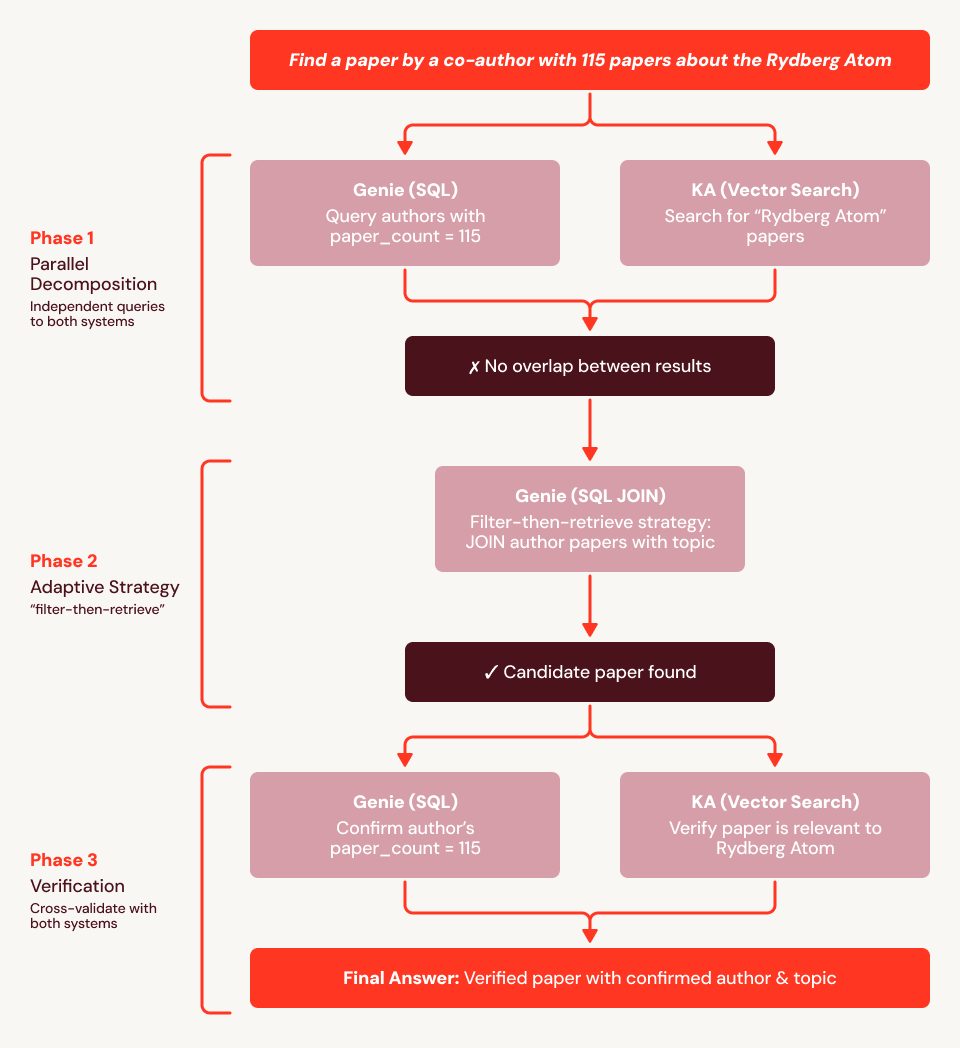
Anhand unserer Beispielabfrage („Finde mir eine Arbeit, die von einem Co-Autor mit 115 Arbeiten verfasst wurde und sich mit dem Rydberg-Atom beschäftigt“) stellen wir fest, dass die Baseline fehlschlägt, da die Embeddings die strukturelle Einschränkung („Co-Autor hat genau 115 Arbeiten“) nicht kodieren können. In Abbildung 4 zeigen wir eine Ausführungsspur für SA: Es verwendet zuerst Genie, um alle 759 Autoren mit 115 Arbeiten zu finden, und Knowledge Assistant, um Rydberg-Arbeiten abzurufen, und gleicht dann die beiden Mengen ab. Wenn keine Überschneidung gefunden wird, passt sich SA an: Es führt einen SQL JOIN der Autorenliste mit 115 Arbeiten gegen alle Arbeiten durch, die „Rydberg“ im Titel oder Abstract erwähnen, und gibt die Antwort direkt aus den strukturierten Daten aus. Anschließend ruft es Knowledge Assistant auf, um die Relevanz zu überprüfen, und Genie, um die Anzahl der Arbeiten des Autors zu bestätigen, und gibt erfolgreich die korrekte Arbeit zurück.
Der Agenten-Vorteil bei wissensintensiven Aufgaben
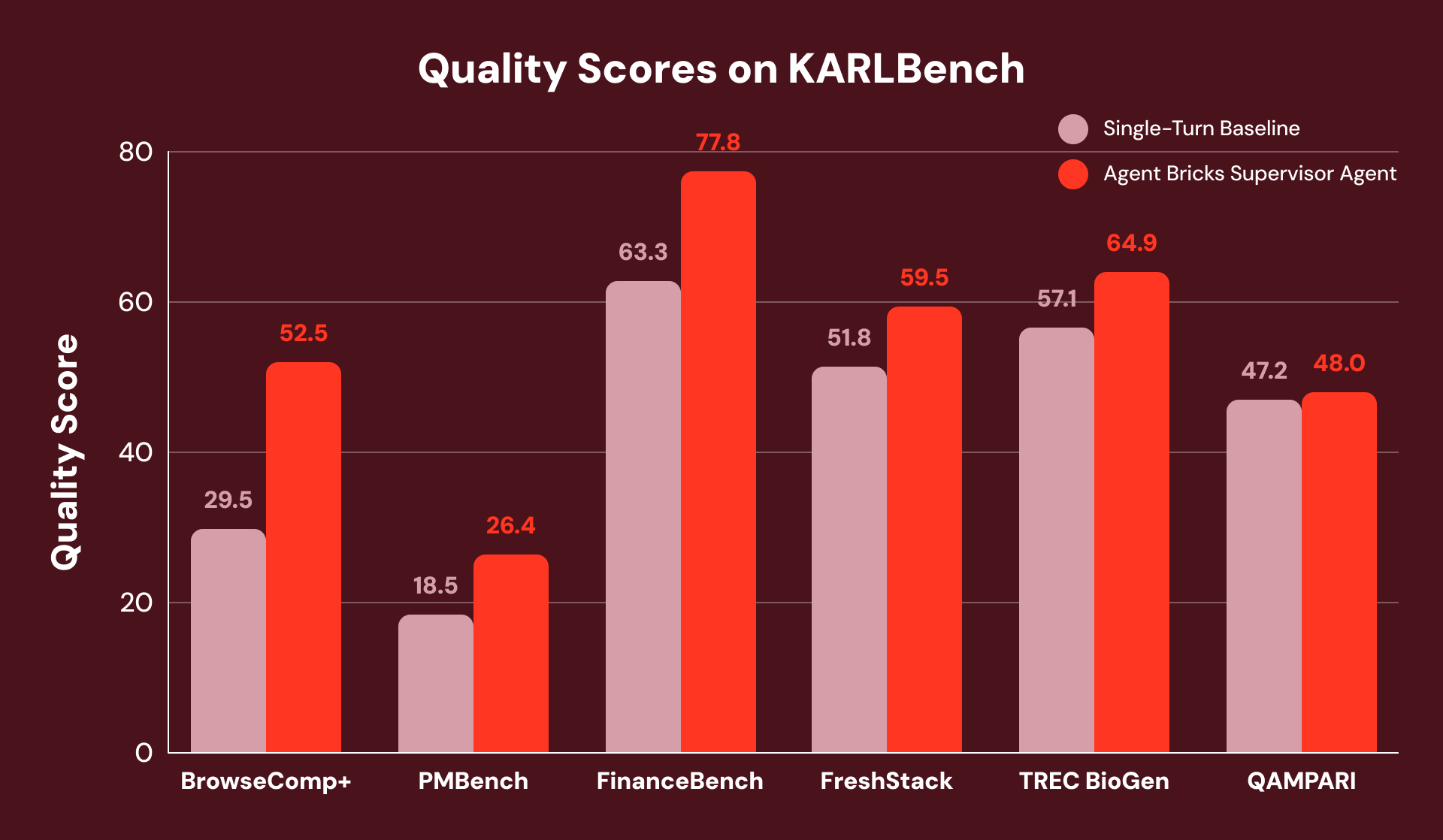
Um die Leistung von Agent Bricks SA mit einer starken Single-Turn-Baseline (ähnlich der besten veröffentlichten Baseline für STaRK) zu vergleichen, bei der keine strukturierten Daten erforderlich sind, bewerten wir sie anhand von KARLBench, einer Benchmark-Suite für grounded Reasoning, die verschiedene Retrieval- und Reasoning-Fähigkeiten gemeinsam testet:
- BrowseComp+: Process-of-elimination-Entity-Suche
- TREC BioGen: Synthese biomedizinischer Literatur
- FinanceBench: Numerisches Reasoning über Finanzberichte
- QAMPARI: Vollständige Entity-Erfassung
- FreshStack: Technische Fehlerbehebung anhand von Dokumentationen
- PMBench: Interne Databricks-Dokumentenverständnis für Unternehmen
Insgesamt erzielt der Supervisor Agent konsistente Verbesserungen über alle sechs Benchmarks hinweg, mit den größten Verbesserungen bei Aufgaben, die entweder eine vollständige Analyse oder Selbstkorrektur erfordern. Bei FinanceBench erholt er sich von anfänglich unvollständigem Retrieval, indem er Lücken erkennt und Abfragen neu formuliert, was zu einer Gesamtverbesserung von +23 % führt.
Zum Beispiel hat jede Frage von BrowseComp+ 5-10 ineinandergreifende Einschränkungen, wie z. B. „Finde einen Spieler, der einen russischen Verein verlassen hat (2015-2020), europäischer Staatsbürger wurde (2010-2016), Körpergröße 1,95-2,06 m. Wie hoch war seine Erfolgsquote bei den wegen COVID verschobenen Olympischen Spielen?“ Der Single-Turn-Baseline gibt eine breite Abfrage aus, die den Spieler korrekt identifiziert, aber keine granularen Statistikdokumente liefert und die Frage nicht beantwortet.
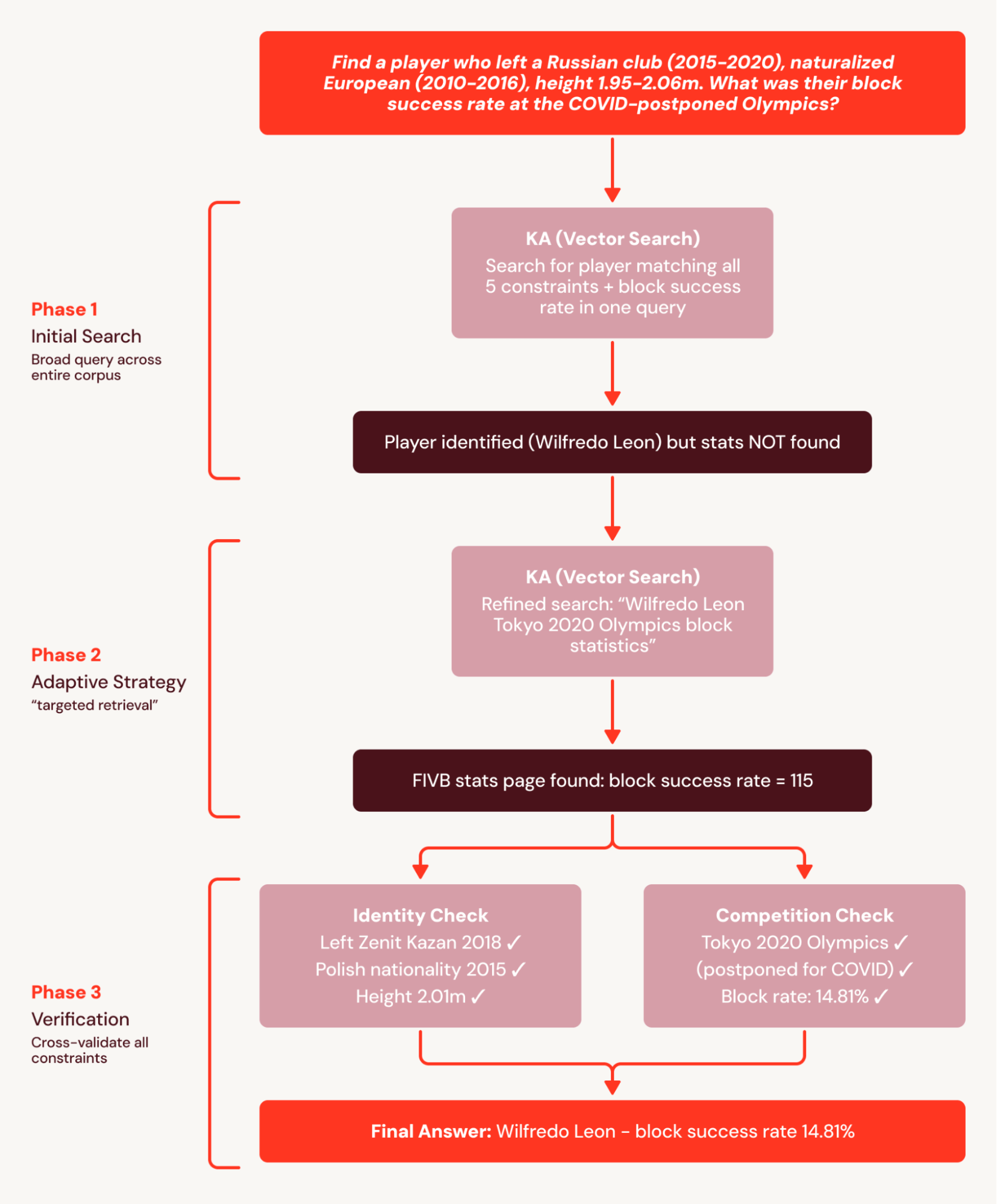
SA zerlegt diese Aufgabe in einen koordinierten Suchplan und zerlegt den Plan in durchsuchbare Teilmengen. Dies vermeidet den Fehler der Single-Turn-Baseline, bei dem Statistiken nicht gefunden werden, weil sie in einer nachfolgenden Suche abgerufen werden. Infolgedessen erzielt SA eine relative Verbesserung von +78 %.
In einem anderen Beispiel von PMBench lautet eine der Fragen „Welche Arten von Guardrails verwenden Kunden?“, die 26 Nuggets (siehe Definition im KARL Bericht) aus über 10 Kunden-Gesprächsdokumenten für eine vollständige Antwort erfordert. Die Single-Turn-Baseline findet nur eine Kundenerwähnung, da sie nicht jede Guardrail-Kategorie in einer einzigen Frage durchsuchen kann. SA durchsucht jede Guardrail-Kategorie separat („PII-Erkennung“, „Halluzination“, „Toxizität“, „Prompt Injection“) und deckt dabei nach und nach mehr Kundenerwähnungen auf.
Was wir gelernt haben
Die Ergebnisse unserer Experimente deuten auf einige wichtige Erkenntnisse hin:
- Grounded Reasoning Agents können von einer hybriden Abfrage strukturierter und unstrukturierter Daten profitieren, wenn sie Zugang zu den richtigen Tools und Datendarstellungen haben.
- Für hochwertige Abrufszenarien sollte der Aufbau benutzerdefinierter RAG-Pipelines über heterogene Datensätze vermieden werden, selbst wenn SoTA-Modelle für die Neuanordnungsphase verwendet werden. Mehrstufiges Reasoning, bei dem der Agent in jedem Schritt die richtige Datenquelle auswählt und deren Nützlichkeit bewertet, ist entscheidend für die Leistungssteigerung.
- Ein deklarativer Ansatz zum Agentenaufbau, wie er vom Databricks Supervisor Agent implementiert wird, bietet einen guten Kompromiss zwischen Benutzerfreundlichkeit und Qualität.
Wir verwenden den Databricks Supervisor Agent, um Agenten für alle drei STaRK-Domänen und sechs unstrukturierte Datensätze in KARLBench zu erstellen. Die einzigen Unterschiede zwischen diesen neun Aufgaben sind die Anweisungen und Tools – es war kein benutzerdefinierter Code erforderlich, um diese vielfältigen Datensätze zu verarbeiten. Daher ist die Erstellung eines leistungsfähigen Agenten für eine neue Unternehmensaufgabe weitgehend eine Frage des Schreibens präziser Anweisungen und der Ausstattung mit den richtigen Tools, anstatt ein neues System von Grund auf neu zu entwickeln.
Der Agent Bricks Supervisor Agent ist für alle unsere Kunden verfügbar. Sie können mit Agent Bricks SA beginnen, indem Sie einfach einen Agenten erstellen und ihn mit Ihren vorhandenen Agenten, Tools und MCP-Servern verbinden. Erkunden Sie die Dokumentation, um zu sehen, wie der Supervisor Agent in Ihre Produktions-Workflows passt.
Autoren: Xinglin Zhao, Arnav Singhvi, Mark Rizkallah, Jonathan Li, Jacob Portes, Elise Gonzales, Sabhya Chhabria, Kevin Wang, Yu Gong, Moonsoo Lee, Michael Bendersky und Matei Zaharia.
1Siehe unsere aktuelle Veröffentlichung „KARL: Knowledge Agents via Reinforcement Learning“ für weitere Details, wie aroll zur Generierung synthetischer Daten, zum skalierbaren RL-Training und zur Online-Inferenz für agentische Aufgaben verwendet wird.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.