Arctic Wolfs Liquid-Clustering-Architektur für den Petabyte-Scale
von Justin Lai, Rajneesh Arora, Krishan Kumar und Cindy Jiang
- Arctic Wolf verarbeitet täglich über 1 Billion Sicherheitsereignisse und generiert dabei über 260 Milliarden angereicherte Beobachtungen, die in einem Delta Lake im Petabyte-Scale verwaltet werden. Unsere Architektur ist darauf ausgelegt, einen Zugriff auf diese Daten nahezu in Echtzeit zu ermöglichen.
- Wir sind kürzlich auf Liquid Clustering für von Unity Catalog verwaltete Tabellen mit Predictive Optimization (PO) umgestiegen und ergänzen damit unsere partitionierten externen Tabellen um inkrementelles, workloadbasiertes Clustering für eine bessere Abfrageleistung.
- Zusammen sorgen Liquid Clustering und PO dafür, dass Tabellen für bis zu 8-mal schnellere Abfragen optimiert bleiben und die Datenaktualität von Stunden auf Minuten verbessert wird.
Täglich verarbeitet Arctic Wolf über eine Billion Ereignisse und gewinnt aus Milliarden angereicherter Datensätze sicherheitsrelevante Erkenntnisse. Das entspricht mehr als 60 TB komprimierter Telemetriedaten, die die KI-gestützte Bedrohungserkennung und -abwehr antreiben – rund um die Uhr und ohne Lücken. Um die Bedrohungssuche in Echtzeit zu ermöglichen, mussten wir diese Daten Kunden und dem Security Operation Center so schnell wie möglich zur Verfügung stellen, mit dem Ziel, dass die meisten Abfragen in 15 Sekunden Ergebnisse liefern.
In der Vergangenheit mussten wir andere schnelle Datenspeicher nutzen, um den Zugriff auf aktuelle Daten zu ermöglichen, da Partitionierung und Z-Ordering nicht mithalten konnten. Wenn wir verdächtige Aktivitäten erkennen, kann unser Team sofort einen Verlauf von drei Monaten analysieren, um Angriffsmuster, laterale Bewegungen und den vollen Umfang der Kompromittierung zu verstehen. Diese historische Analyse von mehr als 3,8 PB komprimierter Daten in Echtzeit ist bei der modernen Bedrohungssuche von entscheidender Bedeutung: Der Unterschied, ob eine Sicherheitsverletzung innerhalb von Stunden oder Tagen eingedämmt wird, kann einen verhinderten Schaden in Millionenhöhe bedeuten.
Wenn jede Sekunde zählt, sind Geschwindigkeit und Aktualität entscheidend. Arctic Wolf musste den Zugriff auf riesige Datensätze beschleunigen, ohne die Aufnahmekosten zu erhöhen oder die Komplexität zu steigern. Die Herausforderung dabei? Untersuchungen wurden durch hohe Datei-I/O und veraltete Daten verlangsamt. Durch ein Umdenken bei der Datenorganisation verwaltet unsere Architektur die mandantenübergreifende Datenverschiebung (Data Skew) effizient, bei der ein kleiner Teil der Kunden die meisten Ereignisse generiert, und berücksichtigt gleichzeitig verspätet eintreffende Daten, die bis zu Wochen nach der ersten Aufnahme eintreffen können. Zu den messbaren Vorteilen gehören die Reduzierung der Dateianzahl von über 4 Mio. auf 2 Mio., die Senkung der Abfragezeiten um ca. 50 % über alle Perzentile hinweg und die Verkürzung der 90-Tage-Abfragen von 51 auf nur 6,6 Sekunden. Die Datenaktualität verbesserte sich von Stunden auf Minuten, wodurch der Zugriff auf Sicherheits-Telemetriedaten fast sofort möglich wurde.
Lesen Sie weiter und erfahren Sie, wie Liquid clustering und von Unity Catalog verwaltete Tabellen dies ermöglicht haben – mit konsistenter Performance und Einblicken nahezu in Echtzeit im großen Maßstab.
Engpässe bei Altsystemen: Warum Arctic Wolf seine Architektur neu aufgebaut hat
Unsere Legacy-Tabelle, die nach Datum und Stunde des Auftretens partitioniert und nach Mandantenkennung Z-geordnet war, konnte aufgrund der großen Anzahl kleiner, auf die Partitionen verteilter Dateien nicht in Quasi-Echtzeit abgefragt werden. Außerdem sind die Daten nur außerhalb der letzten 24 Stunden verfügbar, da wir OPTIMIZE mit Z-Ordering ausführen mussten, bevor die Daten abgefragt werden konnten.
Selbst dann bestanden aufgrund verspätet eintreffender Daten weiterhin Performanceprobleme. Dies geschieht, wenn ein System offline geht, bevor es Daten überträgt, was dazu führt, dass neue Daten in älteren Partitionen landen und die Performance beeinträchtigt wird.
Veraltete Daten machen uns blind. Diese Verzögerung macht den Unterschied aus zwischen dem Eindämmen eines Angreifers und dem Zulassen, dass er sich lateral ausbreitet.
Um diese Performance-Probleme zu entschärfen und die benötigte Datenaktualität bereitzustellen, mussten wir unsere „Hot Data“ in einem Datenbeschleuniger duplizieren und sie für Abfragen mit Daten aus unserem Data Lake kombinieren, um unsere Geschäftsanforderungen zu erfüllen. Die Ausführung dieses Systems war kostspielig und erforderte einen erheblichen Engineering-Aufwand für die Wartung.
Um diese Herausforderungen bei der Verwendung eines Datenbeschleunigers zu bewältigen, haben wir unser Datenlayout neu gestaltet, um die Daten gleichmäßig zu verteilen und spät eintreffende Daten zu unterstützen. Dies optimiert die Abfrage-Performance und ermöglicht nahezu Echtzeit-Zugriff für aktuelle und aufkommende Anwendungsfälle agentischer KI.
Aufbau der Streaming-Datengrundlage mit Liquid Clustering
Mit unserer neuen Architektur ist es unser Hauptziel, die aktuellsten Daten abfragen zu können und eine konsistente Abfrage-Performance bei unterschiedlichen Kundengrößen zu bieten, wobei die Abfragen innerhalb von Sekunden Ergebnisse liefern sollten.
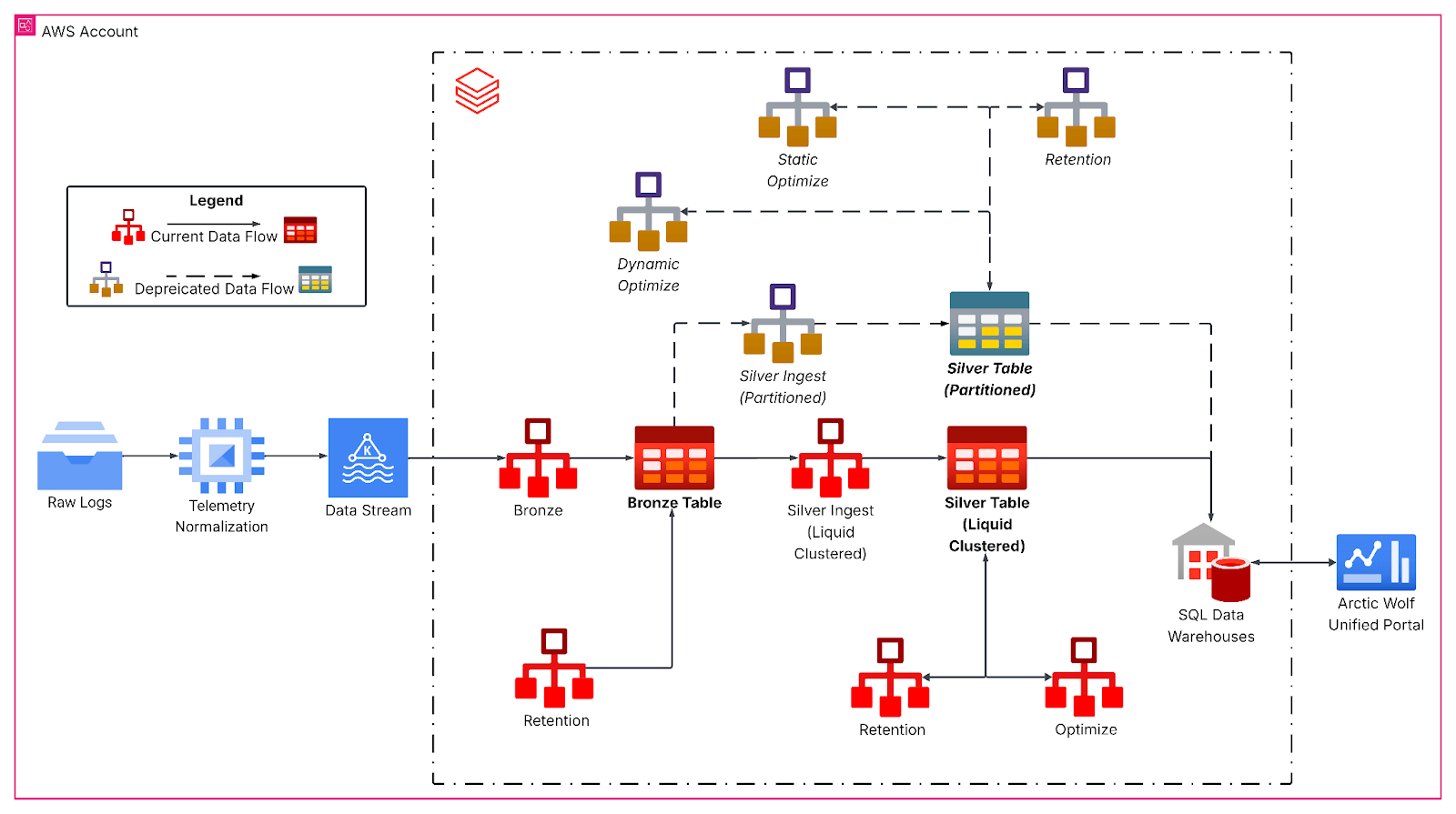
Die überarbeitete Pipeline folgt einer Medallion-Architektur und beginnt mit der kontinuierlichen Kafka-Ingestion in eine Bronze-Schicht für Rohereignisdaten. Stündliche strukturierte Streaming-Jobs flachen dann verschachtelte JSON-Payloads ab und schreiben in Silver-Tabellen mit Liquid-Clustering, die die primäre analytische Grundlage bilden. Hier behandeln Bronze-zu-Silver-Transformationen die Schemaentwicklung, erzeugen abgeleitete temporale Spalten und bereiten Daten für nachgelagerte analytische Workloads mit strengen Latenz-SLAs vor.
Liquid Clustering ersetzte starre Partitionierungsschemata durch Workload-bewusste, mehrdimensionale Clustering-Schlüssel, die auf Abfrage-Muster abgestimmt sind, insbesondere nach tenant identifier und Datumsgranularität, Tabellengröße und den Eigenschaften der ankommenden Daten. Durch die gleichmäßigere Verteilung der Daten erhöhte sich in unserem Fall die durchschnittliche Dateigröße auf über 1 GB, wodurch die Anzahl der gescannten Dateien bei typischen Zeitfensterabfragen für unsere Tabelle drastisch reduziert wurde.
Deep Dive: Clustering on Write
Darüber hinaus nutzen unsere strukturiertes Streaming-Jobs Clustering-on-Write, um das Datei-layout bei neu eintreffenden Daten beizubehalten. Es funktioniert wie eine lokalisierte OPTIMIZE-Operation, bei der das Clustering nur auf die neu aufgenommenen Daten angewendet wird. Die aufgenommenen Daten sind also bereits optimiert. Wenn die Aufnahme-Batches jedoch zu klein sind, erzeugen sie viele kleine, aber gut geclusterte Dateien, die während einer globalen OPTIMIZE dennoch geclustert werden müssen, um ein ideales Datenlayout zu erzielen. Wenn sich die Batch-Größe bei der Aufnahme hingegen der von global Optimize benötigten Batch-Größe annähert, ist eine zusätzliche Optimierung oft nicht erforderlich.
Für Workloads, die sehr große Datenmengen (z. B. Terabytes) aufnehmen, empfehlen wir Batching an der Quelle, z. B. durch die Verwendung von foreachBatch mit maxBytesPerTrigger, um ein effizientes Clustering und Dateilayout zu gewährleisten. Mit maxBytesPerTrigger können wir die Batch-Größe steuern und so viele kleine geclusterte Inseln eliminieren, die eine Abstimmung über den OPTIMIZE-Betrieb erfordern würden. Mit Größen, die nahe an denen liegen, mit denen der OPTIMIZE-Vorgang arbeitet, konnten wir optimale Batches erstellen, um den von OPTIMIZE zusätzlich benötigten Arbeitsaufwand zu reduzieren.
Auswirkungen auf die Security Analytics von Arctic Wolf
Die Migration von Arctic Wolf zu Liquid Clustering brachte erhebliche quantifizierbare Verbesserungen in Bezug auf Performance, Datenaktualität und betriebliche Effizienz. UC Managed Tables mit Predictive Optimization reduzierten auch die Notwendigkeit, Wartungsarbeiten zu planen.
Die Anzahl der Dateien sank von über 4 Mio. auf 2 Mio., wodurch die Datei-I/O während der Abfragen minimiert und gleichzeitig eine gute Cluster-Qualität beibehalten wurde. Infolgedessen verbesserte sich die Abfrage-Performance drastisch, sodass Sicherheitsanalysten Vorfälle schneller untersuchen konnten: ~50 % schneller über alle Perzentile hinweg und ~90 % schneller bei einer großen Anzahl unserer Kunden, wobei die Abfragen über 90 Tage von 51 Sekunden auf 6,6 Sekunden sanken.
Durch die Implementierung von Clustering-on-Write haben wir die Datenaktualität von Stunden auf Minuten reduziert und die Time-to-Insight um ca. 90 % beschleunigt. Diese Verbesserung ermöglicht eine Bedrohungserkennung nahezu in Echtzeit im Data Lake von Arctic Wolf.
Die Umstellung auf Liquid clustering und von Unity Catalog verwaltete Tabellen beseitigte die alte Partitionierung, reduzierte technische Schulden und schaltete erweiterte Governance- und Performance-Features frei. Mit einer Architektur, die täglich mehr als 260 Milliarden Zeilen verarbeiten und abfragen kann, bieten wir einen schnelleren und effizienteren Zugriff auf kritische Sicherheitsdaten aus all diesen Quellen. In Kombination mit unserem 24/7 Concierge Security® Team und der Bedrohungserkennung in Echtzeit ermöglicht dies eine schnellere und präzisere Reaktion auf Bedrohungen sowie deren Abwehr. Diese Unterscheidungsmerkmale helfen unseren Kunden, eine stärkere, agilere Sicherheitslage und ein größeres Vertrauen in die Fähigkeit von Arctic Wolf zu erreichen, ihre Umgebungen zu schützen und den laufenden Geschäftserfolg zu unterstützen.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.