Erstellen eines Copiloten für regulatorische Risiken mit Databricks Agent Bricks (Teil 1: Informationsextraktion)
Erfahren Sie, wie Sie unstrukturierte FDA-Ablehnungsschreiben mithilfe von Databricks AI-Funktionen und Agent Bricks in umsetzbare Erkenntnisse umwandeln.
von Guanyu Chen und Diego Malaver
- Komplexe PDFs parsen: Im Gegensatz zu herkömmlichen Ansätzen, die Teams und Tausende von Codezeilen erfordern, verwenden Sie einfach die Funktion ai_parse_document(), um Text und Bilder aus komplexen PDF-Dokumenten wie den Complete Response Letters (CRLs) der FDA zuverlässig zu parsen.
- Kollaborativ Erkenntnisse extrahieren: Entdecken Sie, wie Sie mit Information Extraction Agent Bricks Fachexperten und KI-Ingenieuren ermöglichen, die Extraktion strukturierter Daten in Echtzeit gemeinsam zu definieren, zu testen und zu perfektionieren.
- Mit SQL in die Produktion überführen: Stellen Sie Ihren perfektionierten Agenten mit einem einzigen Klick als serverlosen Endpunkt bereit und verwenden Sie die Funktion ai_query(), um eine skalierbare, produktionsreife Pipeline für die Verarbeitung neuer Dokumente direkt in Ihrem Lakehouse zu erstellen.
Im Juli 2025 veröffentlichte die US-FDA eine erste Batch von über 200 Complete Response Letters (CRLs), Entscheidungsschreiben, in denen erklärt wird, warum Anträge für Arzneimittel und Biologika nicht im ersten Anlauf genehmigt wurden, was einen bedeutenden Wandel in Richtung Transparenz darstellt. Erstmals können Sponsoren, Kliniker und Datenteams die Branche anhand der eigenen Sprache der Behörde über Mängel in den Bereichen Klinik, CMC, Sicherheit, Label und Bioäquivalenz über zentralisierte, herunterladbare, offene FDA-PDFs analysieren.
Da die FDA weiterhin neue CRLs veröffentlicht, wird die Fähigkeit, aus diesen und anderen unstrukturierten Daten schnell Erkenntnisse zu gewinnen und die interne Datenbasis zu erweitern, zu einem wichtigen Wettbewerbsvorteil. Unternehmen, die diese Erkenntnisse aus unstrukturierten Daten – in Form von PDFs, Dokumenten, Bildern und mehr – effektiv nutzen, können das Risiko ihrer eigenen Einreichungen verringern, häufige Fallstricke identifizieren und letztendlich ihre Markteinführung beschleunigen. Die Herausforderung besteht darin, dass diese Daten, wie viele andere regulatorische Daten auch, in PDFs eingeschlossen sind, die sich bekanntermaßen nur schwer in großem Umfang verarbeiten lassen.
Genau für diese Art von Herausforderung wurde Databricks entwickelt. Dieser Blogbeitrag zeigt, wie Sie die neuesten KI-Tools von Databricks nutzen können, um die Extraktion von Schlüsselinformationen aus PDFs zu beschleunigen und diese wichtigen Dokumente in eine Quelle für verwertbare Erkenntnisse zu verwandeln.
Was es braucht, um mit KI erfolgreich zu sein
Angesichts der erforderlichen technischen Tiefe leiten Ingenieure die Entwicklung oft isoliert, wodurch eine große Lücke zwischen dem KI-Build und den Geschäftsanforderungen entsteht. Wenn ein Fachexperte (SME) das Ergebnis sieht, ist es oft nicht das, was er benötigt hat. Die Feedbackschleife ist zu langsam und das Projekt verliert an Dynamik.
In frühen Testphasen ist es entscheidend, eine Baseline zu erstellen. In vielen Fällen führen alternative Ansätze dazu, dass monatelang ohne Ground Truths gearbeitet wird und man sich stattdessen auf subjektive Beobachtungen und vage Eindrücke verlässt. Dieser Mangel an empirischen Belegen bremst den Fortschritt. Im Gegensatz dazu bietet das Tooling von Databricks standardmäßig Evaluierungsfunktionen und ermöglicht es Kunden, sich sofort auf die Qualität zu konzentrieren – mithilfe eines iterativen Frameworks, um mathematische Sicherheit bei der Extraktion zu gewinnen. KI-Erfolg erfordert einen neuen Ansatz, der auf schneller, kollaborativer Iteration basiert.
Databricks bietet eine einheitliche Plattform, auf der Fachexperten und KI-Ingenieure in Echtzeit zusammenarbeiten können, um Agenten in Produktionsqualität zu erstellen, zu testen und anzuwenden. Dieses Framework basiert auf drei zentralen Prinzipien:
- Enge geschäftlich-technische Abstimmung: SMEs und technische Leiter arbeiten für sofortiges Feedback in derselben UI zusammen und ersetzen so langsame E-Mail-Schleifen.
- Ground-Truth-Evaluierung: Vom Unternehmen definierte "Ground-Truth"-Labels sind zur formalen Bewertung direkt in den Workflow integriert.
- Ein ganzheitlicher Plattformansatz: Dies ist keine Sandbox oder Punktlösung, sondern eine vollständig integrierte Lösung mit automatisierten Pipelines, LLM-as-a-Judge-Evaluierung, produktionssicherem GPU-Durchsatz und durchgängiger Unity Catalog-Governance.
Dieser einheitliche Plattformansatz macht aus einem Prototyp ein vertrauenswürdiges, produktionsreifes KI-System. Lassen Sie uns die vier Schritte zur Erstellung durchgehen.
Vom PDF zur Produktion: Ein Leitfaden in vier Schritten
Der Aufbau eines produktionsreifen KI-Systems auf unstrukturierten Daten erfordert mehr als nur ein gutes Modell; er erfordert einen nahtlosen, iterativen und kollaborativen Workflow. Der Information Extraction Agent Brick in Kombination mit den integrierten KI-Funktionen von Databricks erleichtert das Parsen von Dokumenten, das Extrahieren wichtiger Informationen und die Operationalisierung des gesamten Prozesses. Dieser Ansatz ermöglicht es Teams, schneller voranzukommen und qualitativ hochwertigere Ergebnisse zu liefern. Nachfolgend werden die vier Schlüsselschritte für den Aufbau erläutert.
Schritt 1: Parsen unstrukturierter PDFs in Text mit ai_parse_document()
Die erste Hürde besteht darin, sauberen Text aus den PDFs zu extrahieren. CRLs können komplexe Layouts mit Kopfzeilen, Fußzeilen, Tabellen und Diagrammen über mehrere Seiten und mehrere Spalten hinweg aufweisen. Eine einfache Textextraktion schlägt oft fehl und erzeugt ungenaue und unbrauchbare Ausgaben.
Im Gegensatz zu anfälligen Einzellösungen, die Probleme mit dem Layout haben, nutzt ai_parse_document() hochmoderne multimodale KI, um die Dokumentstruktur zu verstehen. Dabei wird Text präzise in Lesereihenfolge extrahiert, unregelmäßige Tabellenhierarchien beibehalten und Bildunterschriften für Abbildungen generiert.
Zusätzlich bietet Databricks einen Vorteil bei der Dokumentenintelligenz, da es zuverlässig skaliert, um Mengen komplexer PDFs auf Unternehmensebene zu 3- bis 5-mal niedrigeren Kosten als führende Wettbewerber zu verarbeiten. Teams müssen sich keine Gedanken über die Begrenzung der Dateigröße machen, und die im Hintergrund laufenden OCR und VLM gewährleisten das genaue Parsen von bisher als „problematisch“ eingestuften PDFs, die dichte, unregelmäßige Abbildungen und andere schwierige Strukturen enthalten.
Was einst zahlreiche Data Scientists für die Konfiguration und Wartung maßgeschneiderter Parsing-Stacks verschiedener Anbieter erforderte, kann nun mit einer einzigen, SQL-nativen Funktion erledigt werden. Dadurch können Teams Millionen von Dokumenten parallel verarbeiten, ohne die Fehlermodi, die weniger skalierbare Parser beeinträchtigen.
Um zu starten, verweisen Sie zunächst ein UC-Volume auf Ihren Cloud-Speicher, der Ihre PDFs enthält. In unserem Beispiel verweisen wir die SQL-Funktion auf die CRL-PDFs, die von einem Volume verwaltet werden:
Dieser einzelne Befehl verarbeitet alle Ihre PDFs und erstellt eine strukturierte Tabelle mit dem geparsten Inhalt und dem kombinierten Text, sodass diese für den nächsten Schritt bereit ist.
Beachten Sie, dass wir keine Infrastruktur, kein Networking und keine externen LLM- oder GPU-Aufrufe konfigurieren mussten – Databricks hostet die GPUs und das Modell-Backend und ermöglicht so einen zuverlässigen, skalierbaren Durchsatz ohne zusätzliche Konfiguration. Im Gegensatz zu Plattformen, die Lizenzgebühren erheben, verwendet Databricks ein compute-basiertes Preismodell – das bedeutet, Sie zahlen nur für die Ressourcen, die Sie nutzen. Dies ermöglicht leistungsstarke Kostenoptimierungen durch Parallelisierung und Anpassungen auf Funktionsebene in Ihren Produktionspipelines.
Schritt 2: Iterative Informationsextraktion mit Agent Bricks
Sobald Sie den Text haben, besteht das nächste Ziel darin, spezifische, strukturierte Felder zu extrahieren. Zum Beispiel: Was war der Mangel? Wie lautete die NDA-ID? Was war das Ablehnungszitat? Hier müssen KI-Ingenieure und Fachexperten aus der Wirtschaft eng zusammenarbeiten. Der Fachexperte weiß, wonach er suchen muss, und kann mit dem Ingenieur zusammenarbeiten, um das Modell schnell anzuweisen, wie es die Information findet.
Agent Bricks: Informationsextraktion bietet eine kollaborative Echtzeit-Benutzeroberfläche für genau diesen Workflow.
Wie unten dargestellt, können über die Benutzeroberfläche ein technischer Leiter und ein Fachexperte (SME) zusammenarbeiten:
- Der Business-Fachexperte gibt bestimmte Felder an, die extrahiert werden müssen (z. B.
deficiency_summary_paragraphs, NDA_ID, FDA_Rejection_Citing). - Der Agent zur Informationsextraktion übersetzt diese Anforderungen in effektive Prompts. Diese bearbeitbaren Richtlinien befinden sich im rechten Panel.
- Sowohl der Tech Lead als auch der Business-SME können sofort die JSON-Ausgabe im mittleren Panel einsehen und validieren, ob das Modell die Informationen aus dem Dokument auf der linken Seite korrekt extrahiert. Von hier aus kann jeder der beiden einen Prompt neu formulieren, um genaue Extraktionen sicherzustellen.
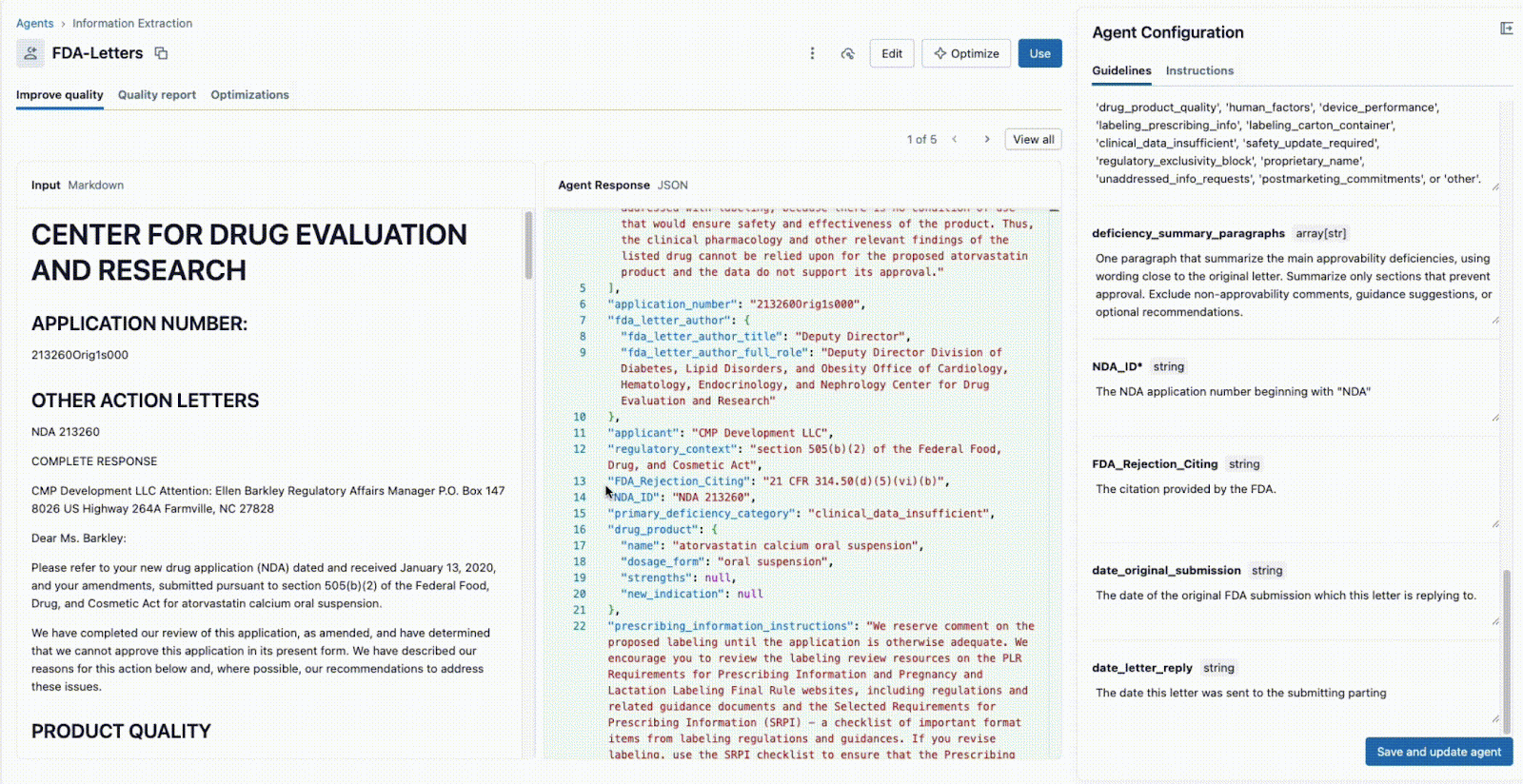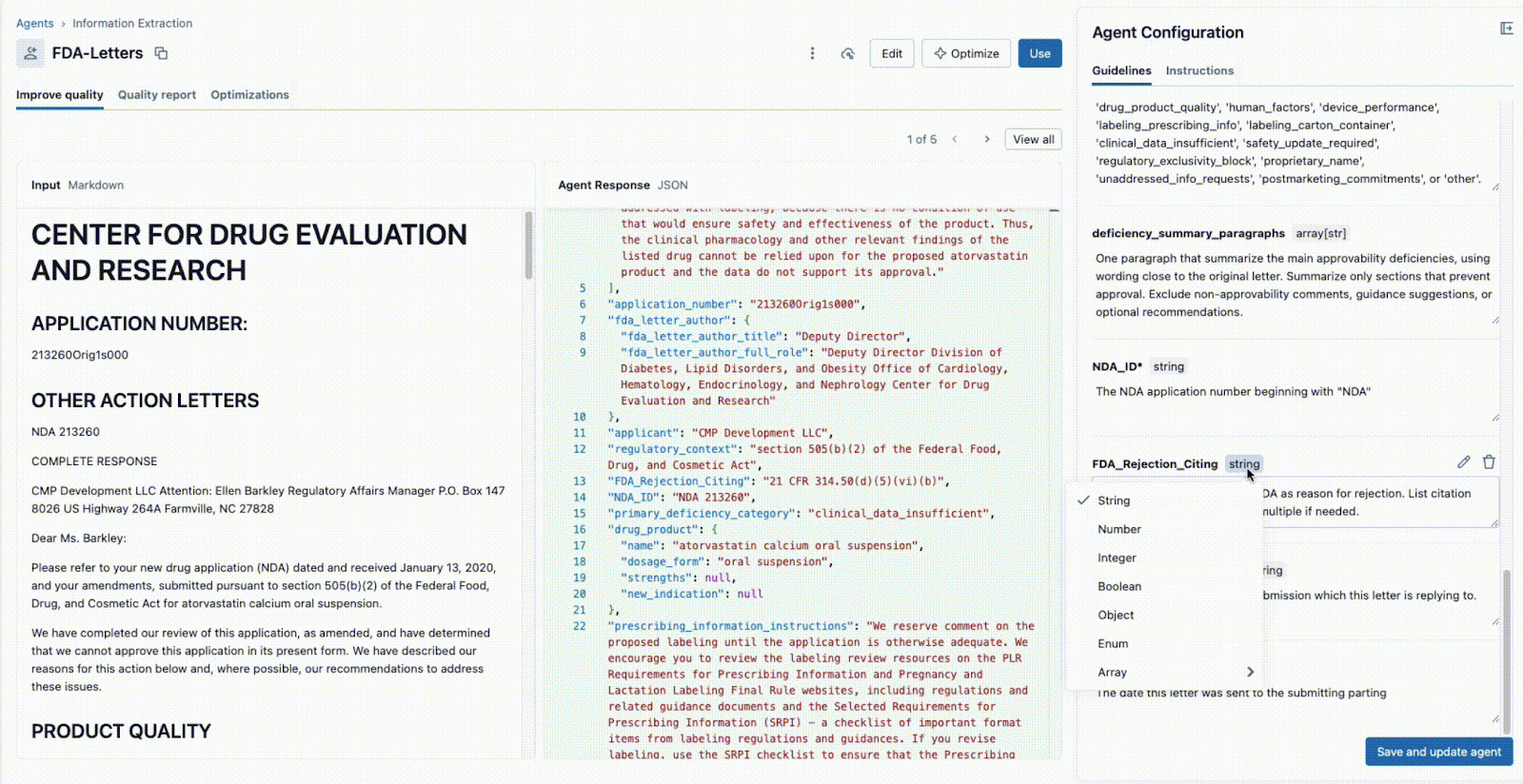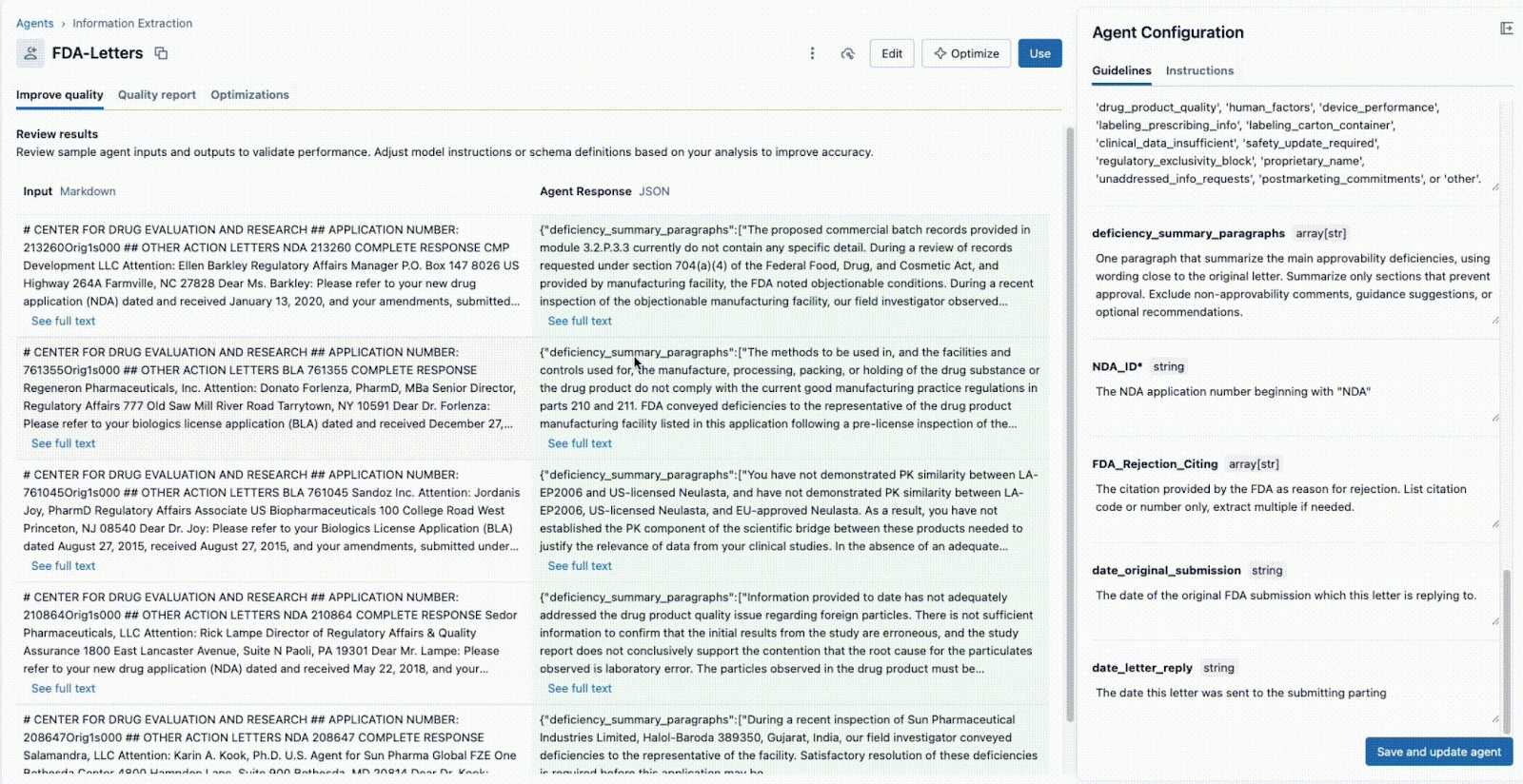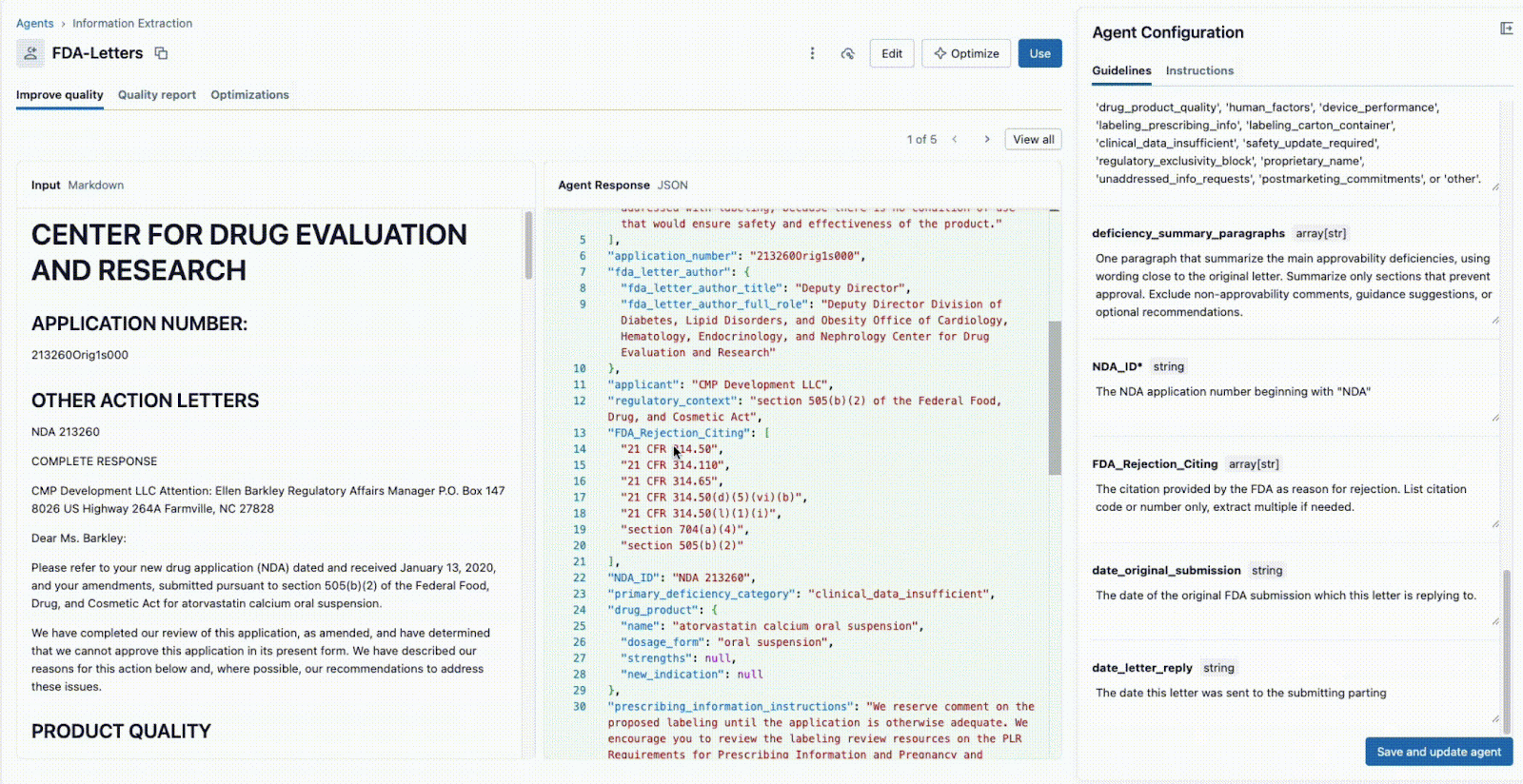
Diese sofortige Feedbackschleife ist der Schlüssel zum Erfolg. Wenn ein Feld nicht korrekt extrahiert wird, kann das Team den Prompt anpassen, ein neues Feld hinzufügen oder die Anweisungen verfeinern und das Ergebnis in Sekundenschnelle sehen. Dieser iterative Prozess, bei dem mehrere Experten auf einer einzigen Oberfläche zusammenarbeiten, unterscheidet erfolgreiche KI-Projekte von solchen, die in Silos scheitern.
Schritt 3: Bewerten und Validieren des Agenten
In Schritt 2 haben wir einen Agenten erstellt, der bei einem „Vibe-Check“ während der iterativen Entwicklung korrekt aussah. Aber wie gewährleisten wir hohe Genauigkeit und Skalierbarkeit bei der Verarbeitung neuer Daten? Eine Änderung des Prompts, die ein Dokument korrigiert, könnte bei zehn anderen zu Fehlern führen. Hier kommt die formale Evaluierung – ein entscheidender und integrierter Bestandteil des Agent-Bricks-Workflows – ins Spiel.
Dieser Schritt ist Ihr Qualitätstor und bietet zwei leistungsstarke Methoden zur Validierung:
Methode A: Evaluierung mit Ground-Truth-Labels (der Goldstandard)
KI scheitert, wie jedes Data Science Projekt, ohne entsprechendes Fachwissen im luftleeren Raum. Eine Investition von Fachexperten in die Bereitstellung eines „Golden Set“ (auch bekannt als Ground Truth, gelabelte Datasets) mit manuell extrahierten und von Menschen validierten, korrekten und relevanten Informationen trägt wesentlich dazu bei, sicherzustellen, dass diese Lösung auf neue Dateien und Formate generalisiert werden kann. Dies liegt daran, dass gelabelte Key-Value-Paare dem Agenten schnell dabei helfen, hochwertige Prompts feinabzustimmen, die zu geschäftsrelevanten und genauen Extrakten führen. Sehen wir uns genauer an, wie Agent Bricks diese Labels verwendet, um Ihren Agenten formell zu bewerten.
Geben Sie in der Agent Bricks-UI das Ground-Truth-Testset an, und Agent Bricks durchläuft im Hintergrund die Testdokumente. Die UI bietet eine Gegenüberstellung der extrahierten Ausgabe Ihres Agenten und der als "korrekt" mit Label versehenen Antwort.
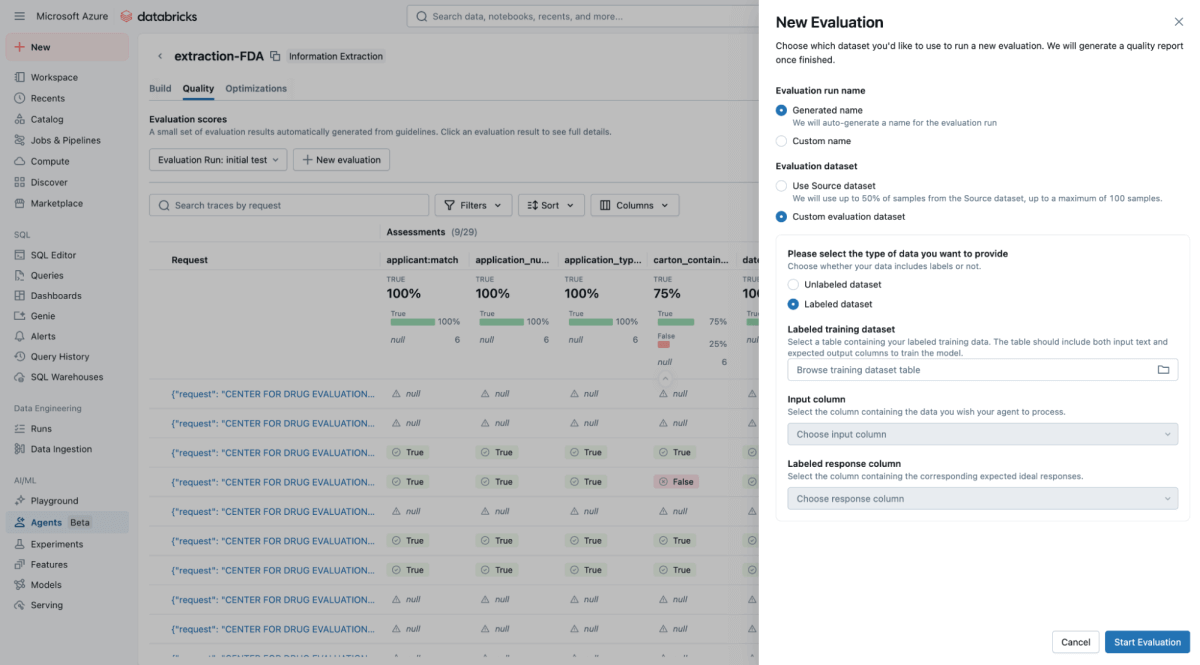
Die Benutzeroberfläche bietet einen klaren Genauigkeitswert für jedes Extraktionsfeld, sodass Sie Regressionen sofort erkennen können, wenn Sie einen Prompt ändern. Mit Agent Bricks erhalten Sie die geschäftliche Gewissheit, dass der Agent mit einer Genauigkeit auf oder über menschlichem Niveau arbeitet.
Methode B: Keine Labels? Verwenden Sie LLM-as-a-Judge
Aber was ist, wenn Sie bei Null anfangen und keine Ground-Truth-Labels haben? Dies ist ein häufiges "Kaltstart"-Problem.
Die Agent Bricks Evaluation Suite bietet eine leistungsstarke Lösung: LLM-as-a-Judge. Databricks bietet eine Suite von Evaluierungs-Frameworks, und Agent Bricks wird Evaluierungsmodelle nutzen, um als unparteiischer Evaluator zu agieren. Dem "Judge"-Modell werden der ursprüngliche Dokumenttext und eine Reihe von Feld-Prompts für jedes Dokument vorgelegt. Die Rolle des “Judge” besteht darin, eine "erwartete" Antwort zu generieren und diese dann mit der vom Agenten extrahierten Ausgabe zu vergleichen.
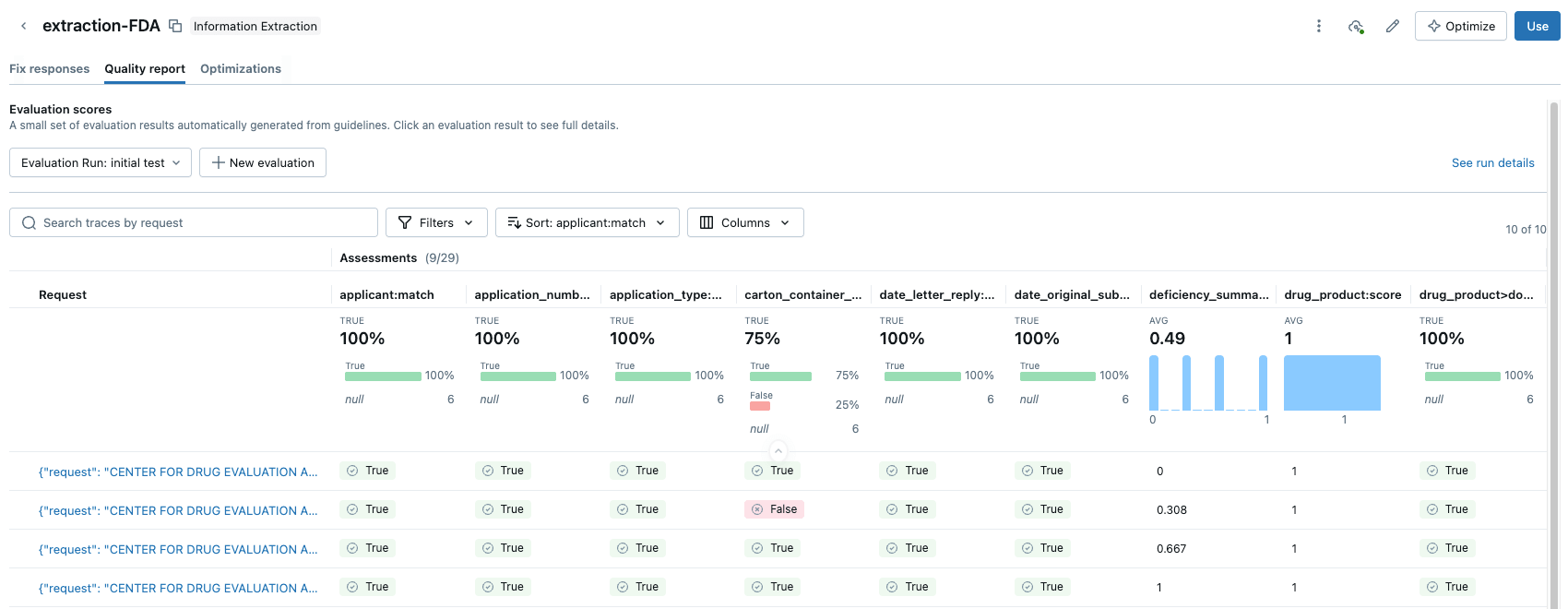
LLM-as-a-Judge ermöglicht es Ihnen, einen skalierbaren, hochwertigen Evaluierungsscore zu erhalten und kann – das sei angemerkt – auch in der Produktion eingesetzt werden, um sicherzustellen, dass Agenten zuverlässig und hinsichtlich Produktionsvariabilität und Scale generalisierbar bleiben. Mehr dazu in einem zukünftigen Blog.
Schritt 4: Integration des Agenten mit ai_query() in Ihre ETL-Pipeline
An diesem Punkt haben Sie Ihren Agenten in Schritt 2 erstellt und seine Genauigkeit in Schritt 3 validiert und können die Extraktion nun zuversichtlich in Ihren Workflow integrieren. Mit einem einzigen Klick können Sie Ihren Agenten als serverlosen Modellendpunkt bereitstellen – Ihre Extraktionslogik ist sofort als einfache, skalierbare Funktion verfügbar.
Verwenden Sie dazu die Funktion ai_query() in SQL, um diese Logik auf neue Dokumente anzuwenden, sobald sie eintreffen. Die Funktion ai_query() ermöglicht es Ihnen, jeden Model-Serving-endpoint direkt und nahtlos in Ihrer End-to-End-ETL-Datenpipeline aufzurufen.
Damit stellen Databricks Lakeflow Jobs sicher, dass Sie über eine vollständig automatisierte, produktionsreife ETL-Pipeline verfügen. Ihr Databricks-Job verarbeitet rohe PDFs aus Ihrem Cloud-Speicher, parst sie, extrahiert mit Ihrem hochwertigen Agenten strukturierte Erkenntnisse und speichert diese in einer Tabelle, die für Analysen, Berichte oder zur Referenzierung beim Abruf durch eine nachgelagerte Agentenanwendung bereitsteht.
Databricks ist die KI-Plattform der nächsten Generation – eine, die die Barrieren zwischen hochtechnischen Teams und den Fachexperten beseitigt, welche den nötigen Kontext für die Entwicklung sinnvoller KI besitzen. Erfolg mit KI ist nicht nur eine Frage von Modellen oder Infrastruktur, sondern die enge, iterative Zusammenarbeit zwischen Ingenieuren und SMEs, bei der jeder die Denkweise des anderen verfeinert. Databricks bietet Teams eine zentrale Umgebung, um gemeinsam zu entwickeln, schnell Experimente durchzuführen, verantwortungsvoll zu steuern und die Wissenschaft zurück in die Data Science zu bringen.
Agent Bricks ist die Verkörperung dieser Vision. Mit ai_parse_document() zum Parsen unstrukturierter Inhalte, der kollaborativen Designoberfläche von Agent Bricks: Information Extraction zur Beschleunigung hochwertiger Extraktionen und ai_query() zur Anwendung der Lösung in produktionsreifen Pipelines können Teams schneller als je zuvor von Millionen unübersichtlicher PDFs zu validierten Erkenntnissen gelangen.
In unserem nächsten Blog zeigen wir, wie Sie diese extrahierten Erkenntnisse nutzen und einen produktionsreifen Chat-Agenten erstellen, der Fragen in natürlicher Sprache beantworten kann, wie z. B.: „Was sind die häufigsten Probleme bei der Herstellungsreife für onkologische Medikamente?“
- Erfahren Sie mehr: Lesen Sie die offizielle Dokumentation für ai_parse_document(), Agent Bricks: Informationsextraktion und ai_query().
- Jetzt loslegen: Registrieren Sie sich für eine kostenlose Testversion von Databricks, um noch heute Ihre eigenen KI-gestützten Lösungen zu entwickeln.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.