Vom Chaos zur Scale: Templatisierung von deklarativen Spark-Pipelines mit DLT-META
Ein Metadaten-Framework zum Erstellen konsistenter, automatisierter und gesteuerter Pipelines in großem Maßstab
von Ravi Gawai und Phoebe Weiser
- Die Skalierung von Datenpipelines verursacht teamübergreifend Mehraufwand, Drift und inkonsistente Logik.
- Diese Lücken verlangsamen die Bereitstellung, erhöhen die Wartungskosten und erschweren die Durchsetzung gemeinsamer Standards.
- Dieser Blog zeigt, wie metadatengesteuerte Metaprogrammierung Duplizierung beseitigt und konsistente, automatisierte Datenpipelines auf Scale erstellt.
Deklarative Pipelines geben Teams eine absichtsgesteuerte Möglichkeit, Batch- und Streaming-Workflows zu erstellen. Sie definieren, was geschehen soll, und überlassen dem System die Ausführung. Dies reduziert benutzerdefinierten Code und unterstützt wiederholbare Engineering-Muster.
Mit zunehmender Datenverwendung in Organisationen vervielfachen sich auch die Pipelines. Standards entwickeln sich weiter, neue Quellen kommen hinzu, und mehr Teams beteiligen sich an der Entwicklung. Selbst kleine Schema-Aktualisierungen wirken sich auf Dutzende von Notebooks und Konfigurationen aus. Metadaten-gesteuerte Metaprogrammierung löst diese Probleme, indem die Pipeline-Logik in strukturierte Templates verlagert wird, die zur Laufzeit generiert werden.
Dieser Ansatz sorgt für eine konsistente Entwicklung, reduziert den Wartungsaufwand und lässt sich mit geringem Engineering Aufwand skalieren.
In diesem Blog erfahren Sie, wie Sie mit DLT-META, einem Projekt von Databricks Labs, metadatengesteuerte Pipelines für Spark Declarative Pipelines erstellen, das Metadatenvorlagen zur Automatisierung der Pipeline-Erstellung verwendet.
So hilfreich deklarative Pipelines auch sind, der Supportaufwand steigt schnell an, wenn Teams weitere Quellen hinzufügen und die Nutzung im gesamten Unternehmen ausweiten.
Warum manuelle Pipelines im großen Scale schwer zu warten sind
Manuelle Pipelines funktionieren in kleiner Scale, aber der Wartungsaufwand wächst schneller als die Daten selbst. Jede neue Quelle erhöht die Komplexität, was zu Logikdrift und Nacharbeiten führt. Teams flicken Pipelines, anstatt sie zu verbessern. Data Engineers stehen regelmäßig vor diesen Skalierungsherausforderungen:
- Zu viele Artefakte pro Quelle: Jeder Datensatz erfordert neue Notebooks, Konfigurationen und Skripts. Der Betriebsaufwand wächst mit jedem eingebundenen Feed rapide an.
- Logik-Updates werden nicht weitergegeben: Änderungen an Geschäftsregeln werden nicht auf Pipelines angewendet, was zu Konfigurations-Drift und inkonsistenten Ergebnissen über Pipelines hinweg führt.
- Inkonsistente Qualität und Governance: Teams erstellen benutzerdefinierte Prüfungen und Datenherkunft, was die Durchsetzung unternehmensweiter Standards erschwert und zu sehr variablen Ergebnissen führt.
- Begrenzte sichere Beiträge von Domänenteams: Analysten und Geschäftsteams möchten Daten hinzufügen, aber das Data Engineering überprüft oder schreibt die Logik immer noch neu, was die Bereitstellung verlangsamt.
- Mit jeder Änderung steigt der Wartungsaufwand: Einfache Schema-Anpassungen oder -Updates verursachen einen riesigen Rückstau an manueller Arbeit in allen abhängigen Pipelines, was die Agilität der Plattform beeinträchtigt.
Diese Probleme zeigen, warum ein Metadaten-First-Ansatz wichtig ist. Er reduziert den manuellen Aufwand und sorgt für konsistente Pipelines bei der Skalierung.
Wie DLT-META Scale und Konsistenz angeht
DLT-META löst Probleme bei der Scale und Konsistenz von Pipelines. Es ist ein metadatengesteuertes Metaprogrammierungs-Framework für deklarative Spark-Pipelines. Datenteams verwenden es, um die Erstellung von Pipelines zu automatisieren, Logik zu standardisieren und die Entwicklung mit minimalem Code zu skalieren.
Bei der Metaprogrammierung wird das Pipeline-Verhalten aus der Konfiguration abgeleitet, nicht aus sich wiederholenden Notebooks. Dies bietet Teams klare Vorteile.
- Weniger Code schreiben und pflegen
- Schnelleres Onboarding neuer Datenquellen
- Produktionsreife Pipelines von Start an
- Konsistente Muster auf der gesamten Plattform
- Skalierbare Best Practices mit schlanken Teams
Spark Declarative Pipelines und DLT-META arbeiten zusammen. Spark Declarative Pipelines definieren die Absicht und verwalten die Ausführung. DLT-META fügt eine Konfigurationsebene hinzu, die Pipeline-Logik generiert und skaliert. In Kombination ersetzen sie die manuelle Codierung durch wiederholbare Muster, die Governance, Effizienz und Wachstum bei Scale unterstützen.
Wie DLT-META auf reale Anforderungen im Data Engineering eingeht
1. Zentralisierte und vorlagenbasierte Konfiguration
DLT-META zentralisiert die Pipeline-Logik in gemeinsam genutzten Templates, um Duplizierung und manuellen Pflegeaufwand zu vermeiden. Teams definieren Regeln für Ingestion, Transformation, Qualität und Governance in gemeinsam genutzten Metadaten mithilfe von JSON oder YAML. Wenn eine neue Quelle hinzugefügt wird oder sich eine Regel ändert, aktualisieren Teams die Konfiguration nur einmal. Die Logik wird automatisch auf alle Pipelines übertragen.
2. Sofortige Skalierbarkeit und schnelleres Onboarding
Metadatengesteuerte Updates machen es einfach, Pipelines zu skalieren und neue Quellen zu integrieren. Teams fügen Quellen hinzu oder passen Geschäftsregeln an, indem sie Metadatendateien bearbeiten. Änderungen werden ohne manuellen Eingriff auf alle nachgelagerten Workloads angewendet. Neue Quellen gehen in Minuten statt in Wochen in Produktion.
3. Beitrag des Domänenteams mit durchgesetzten Standards
DLT-META ermöglicht es Fachteams, durch Konfiguration sicher beizutragen. Analysten und Fachexperten aktualisieren Metadaten, um die Bereitstellung zu beschleunigen. Plattform- und Engineering-Teams behalten die Kontrolle über Validierung, Datenqualität, Transformationen und Compliance-Regeln.
4. Unternehmensweite Konsistenz und Governance
Unternehmensweite Standards gelten automatisch für alle Pipelines und Consumer. Eine zentrale Konfiguration erzwingt eine konsistente Logik für jede neue Quelle. Integrierte Audit-, Datenherkunfts- und Datenqualitätsregeln unterstützen regulatorische und betriebliche Anforderungen in großem Umfang.
Wie Teams DLT-META in der Praxis verwenden
Kunden verwenden DLT-META, um Ingestion und Transformationen einmalig zu definieren und sie über die Konfiguration anzuwenden. Dies reduziert benutzerdefinierten Code und beschleunigt das Onboarding.
Cineplex sah sofortige Ergebnisse.
Wir verwenden DLT-META, um benutzerdefinierten Code zu minimieren. Entwickler schreiben Pipelines für einfache Tasks nicht mehr unterschiedlich. Onboarding-JSON-Dateien wenden ein einheitliches Framework an und erledigen den Rest.—Aditya Singh, Data Engineer, Cineplex
PsiQuantum zeigt, wie kleine Teams effizient skalieren.
DLT-META hilft uns, Bronze- und Silver-Workloads mit geringem Wartungsaufwand zu verwalten. Es unterstützt große Datenmengen ohne duplizierte Notebooks oder duplizierten Quellcode.– Arthur Valadares, Principal Data Engineer, PsiQuantum
Branchenübergreifend wenden Teams dasselbe Muster an.
- Einzelhandel zentralisiert Filial- und Lieferkettendaten aus Hunderten von Quellen
- Logistik standardisiert die Batch- und Streaming-Ingestion für IoT- und Flottendaten
- Finanzdienstleistungen setzen Audits und Compliance durch und beschleunigen gleichzeitig das Onboarding von Feeds.
- Gesundheitswesen sichert Qualität und Überprüfbarkeit über komplexe Datasets hinweg
- Fertigung und Telekommunikation skalieren die Ingestion mithilfe von wiederverwendbaren, zentral verwalteten Metadaten
Dieser Ansatz ermöglicht es Teams, die Anzahl der Pipelines zu erhöhen, ohne die Komplexität zu steigern.
So starten Sie mit DLT-META in 5 einfachen Schritten
Sie müssen Ihre Plattform nicht neu gestalten, um DLT-META auszuprobieren. Fangen Sie klein an. Verwenden Sie einige wenige Quellen. Lassen Sie die Metadaten den Rest steuern.
1. Holen Sie sich das Framework
Klonen Sie zunächst das DLT-META-Repository. Dadurch erhalten Sie die Templates, Beispiele und Tools, die zum Definieren von Pipelines mithilfe von Metadaten erforderlich sind.
2. Definieren Sie Ihre Pipelines mit Metadaten
Definieren Sie als Nächstes, was Ihre Pipelines tun sollen. Dazu bearbeiten Sie eine kleine Gruppe von Konfigurationsdateien.
- Verwenden Sie conf/onboarding.json, um rohe Eingabetabellen zu beschreiben.
- Verwenden Sie conf/silver_transformations.json, um Transformationen zu definieren.
- Fügen Sie optional conf/dq_rules.json hinzu, wenn Sie Datenqualitätsregeln durchsetzen möchten.
An diesem Punkt beschreiben Sie die Absicht. Sie schreiben keinen Pipeline-Code.
3. Metadaten in die Plattform aufnehmen
Bevor Pipelines ausgeführt werden können, muss DLT-META Ihre Metadaten registrieren. Dieser Onboarding-Schritt konvertiert Ihre Konfigurationen in Dataflowspec-Delta-Tabellen, die Pipelines zur Laufzeit lesen.
Sie können das Onboarding über ein Notebook, einen Lakeflow Job oder die DLT-META-CLI ausführen.
a. Manuelles Onboarding per Notebook, z. B. hier
Verwenden Sie das bereitgestellte Onboarding-Notebook, um Ihre Metadaten zu verarbeiten und Ihre Pipeline-Artefakte bereitzustellen:
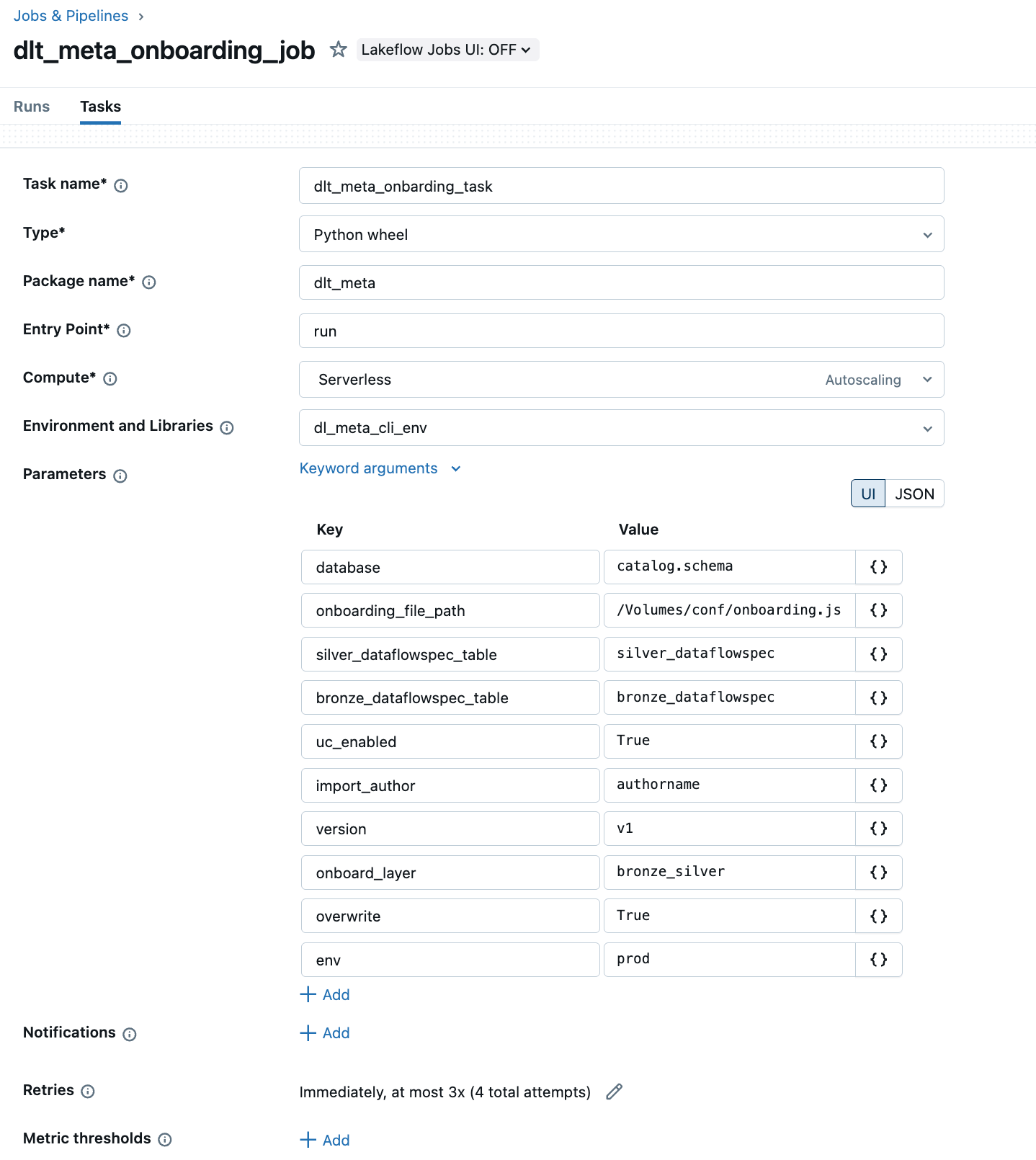
b. Automatisieren Sie das Onboarding über Lakeflow-Jobs mit einem Python-Wheel.
Das nachstehende Beispiel zeigt die Lakeflow Jobs-Benutzeroberfläche zum Erstellen und Automatisieren einer DLT-META-Pipeline.
c. Führen Sie das Onboarding mithilfe der im Repo gezeigten DLT-META-CLI-Befehle durch: hier.
Mit der DLT-META-CLI können Sie Onboarding und Bereitstellung in einem interaktiven Python-Terminal ausführen.
4. Erstellen Sie eine generische Pipeline
Mit vorhandenen Metadaten erstellen Sie eine einzige generische Pipeline. Diese Pipeline liest aus den Dataflowspec-Tabellen und generiert dynamisch Logik.
Verwenden Sie pipelines/dlt_meta_pipeline.py als Einstiegspunkt und konfigurieren Sie es so, dass es auf Ihre Bronze- und Silver-Spezifikationen verweist.
Diese Pipeline bleibt unverändert, wenn Sie Quellen hinzufügen. Metadaten steuern das Verhalten.

5. Trigger und Ausführung
Sie sind jetzt bereit, die Pipeline auszuführen. Triggern Sie sie wie jede andere deklarative Spark-Pipeline.
DLT-META erstellt und führt die Pipeline-Logik zur Laufzeit aus.
Die Ausgabe sind produktionsreife Bronze- und Silber-Tabellen, auf die automatisch konsistente Transformationen, Qualitätsregeln und Lineage angewendet werden.
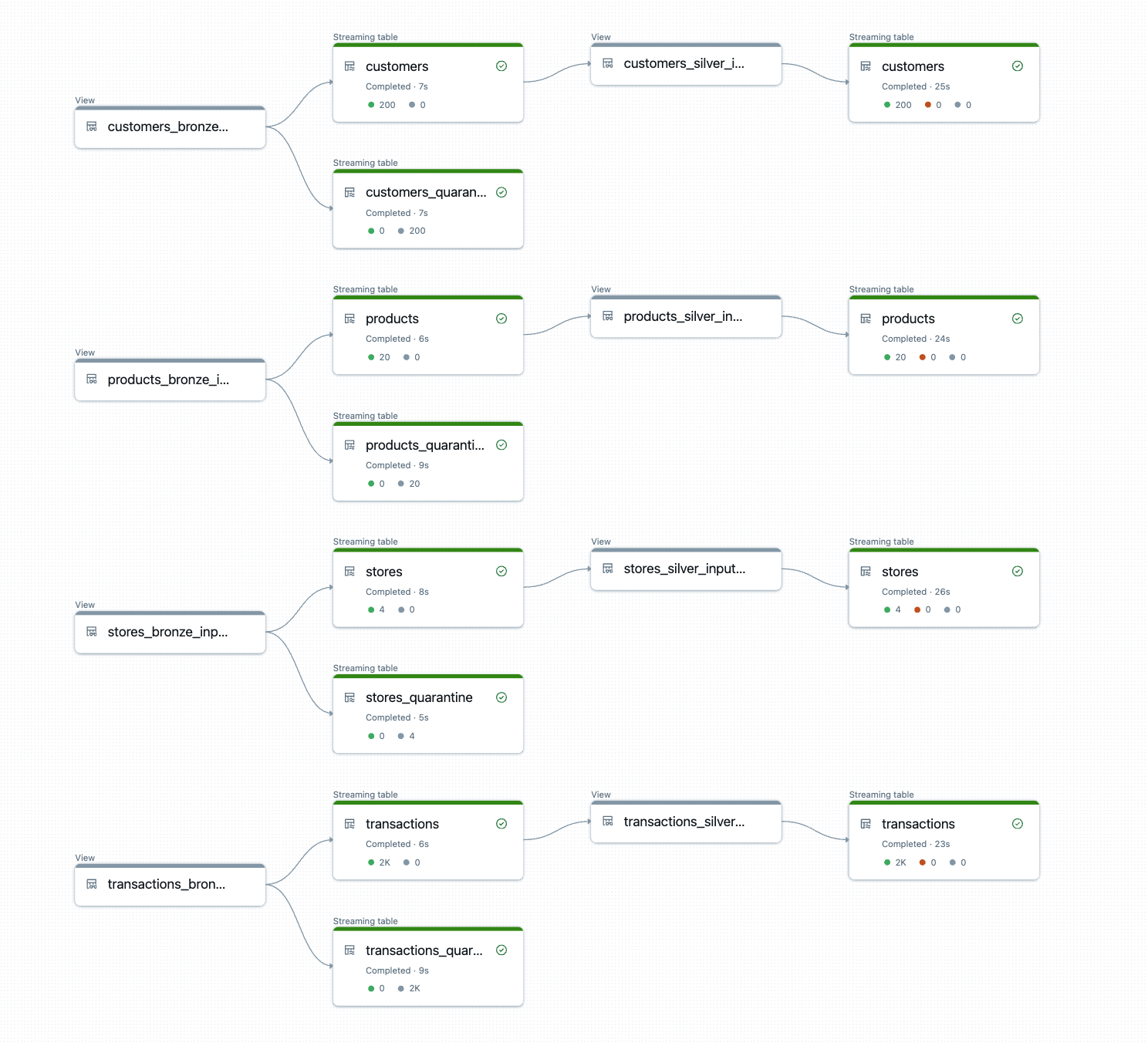
{kind=link}
Jetzt ausprobieren
Für den Anfang empfehlen wir, einen Proof of Concept (PoC) mit Ihren bestehenden Spark Declarative Pipelines und einer Handvoll Quellen zu starten, die Pipeline-Logik in Metadaten zu migrieren und DLT-META die Orchestrierung im großen Scale �übernehmen zu lassen. Beginnen Sie mit einem kleinen Proof of Concept (PoC) und beobachten Sie, wie die metadatengesteuerte Metaprogrammierung Ihre Data-Engineering-Fähigkeiten über das hinaus skaliert, was Sie für möglich gehalten haben.
Databricks-Ressourcen
- Erste Schritte: https://github.com/databrickslabs/DLT-META#getting-started
- GitHub: github.com/databrickslabs/DLT-META
- GitHub-Dokumentation: databrickslabs.github.io/DLT-META
- Databricks-Dokumentation: https://docs.databricks.com/aws/en/dlt-ref/DLT-META
- Demos: databrickslabs.github.io/DLT-META/demo
- Neueste Version: https://github.com/databrickslabs/DLT-META/releases
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.