Entlarvung von 8 Mythen über Datenlayouts: Warum Liquid Clustering Partitionierung übertrifft
Das Datenlayout für das moderne Lakehouse
von Jeffrey Gong, Yu Xu und Rahul Mahadev
- Liquid Clustering ist das Datenlayout für offene Tabellenformate, das Partitionierung übertrifft und gleichzeitig deren Einschränkungen umgeht
- 8 gängige Mythen halten Teams an der Partitionierung fest, und keiner von ihnen hält mehr stand
- Kunden, die Liquid Clustering verwenden, berichten von dramatischen Verbesserungen bei der Abfragelatenz, dem Schreibdurchsatz, der Speichereffizienz und der Datenaktualität, wobei die größten Gewinne im Petabyte-Bereich kumulieren
Einleitung
Die Anordnung von Daten ist eines der ältesten Probleme in der Informatik.
Seit über 15 Jahren, seit dem Aufkommen von Hadoop und Hive, ist die Partitionierung die Standardmethode zur physischen Organisation von Daten für Verarbeitung und Analyse. Heutige Lakehouses bedienen jedoch Agenten, Echtzeit-Pipelines und Abfragemuster, die sich schneller ändern, als ein Mensch neu partitionieren kann.
Liquid Clustering ist der moderne Standard und Kunden setzen ihn in jeder Größenordnung ein, darunter Dutzende mit Petabyte-großen Tabellen in der Produktion. In diesem Blogbeitrag behandeln wir warum Liquid Clustering im Lakehouse gewinnt. Unterwegs werden wir 8 gängige Mythen über Datenlayouts entlarven, 3 Erfolgsgeschichten von Teams durchgehen, die partitionierte Tabellen auf Liquid Clustering umstellen, einen Ausblick auf das Kommende geben und zeigen, wie Sie loslegen können.
Warum Liquid Clustering im modernen Lakehouse gewinnt
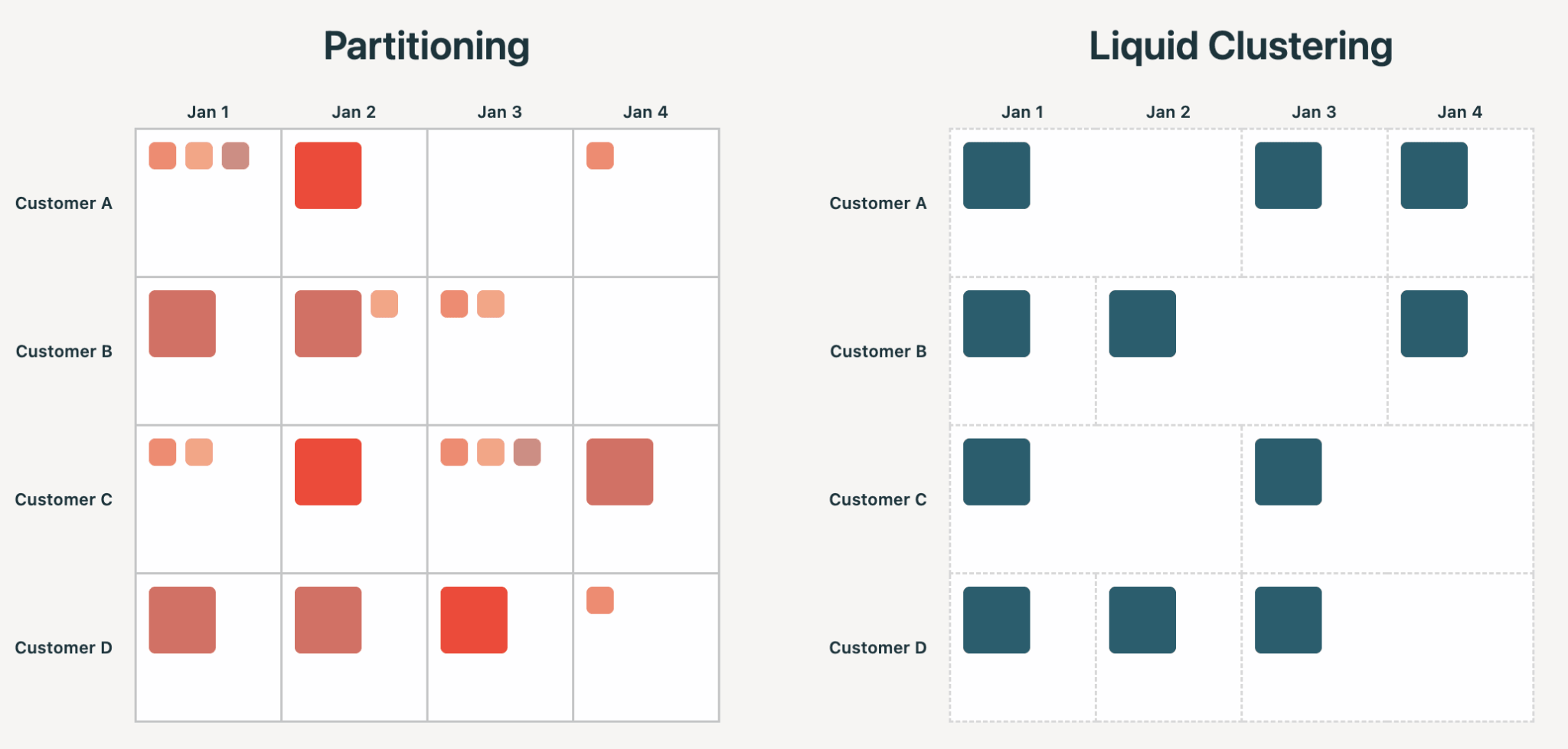
Hive-Style-Partitionierung zwingt Benutzer, zum Zeitpunkt der Tabellenerstellung eine physische Datenorganisation festzulegen, die sich in der Dateistruktur widerspiegelt. Wählen Sie eine Spalte mit zu hoher Kardinalität, erhalten Sie Milliarden von kleinen Dateien. Wählen Sie die falsche Spalte, und Abfragen werden möglicherweise langsamer, nicht schneller. In jedem Fall müssen Sie die Tabelle neu schreiben. Es ist üblich, dass man es falsch macht: In unserer Analyse führt die Hive-Style-Partitionierung in mehr als 75 % der Fälle zu Überpartitionierung und Problemen mit kleinen Dateien.
Liquid behandelt Clustering-Schlüssel als Eingabe, die die Engine zur Steuerung der optimalen Dateiorganisation verwendet. Schlüssel können jederzeit geändert oder durch Automatic Liquid Clustering intelligent ausgewählt werden. Die Kardinalität ist keine Einschränkung, und das Layout kann sich im Laufe der Zeit ohne unnötige Neuschreibungen weiterentwickeln.
Die Vorteile von Liquid Clustering ergeben sich alle aus dem oben genannten Prinzip: bessere Handhabung von Daten-Skew, Row-Level Concurrency, keine Probleme mit kleinen Dateien, multidimensionale Clusterbildung und geringere Schreibverstärkung.
Im Jahr 2026 sollte das Layout ein Implementierungsdetail der Tabelle sein, wobei jede Engine, die es liest oder schreibt, davon profitiert. Dies wird immer wichtiger, da Agenten in das Lakehouse eintreten und mehr Daten als je zuvor generieren und konsumieren. Menschen und Agenten benötigen fehlertolerante Schnittstellen, frei von den potenziellen Nebenwirkungen der Hive-Style-Partitionierung.
Entlarvung von 8 gängigen Mythen über Datenlayouts
Liquid Clustering wurde im Jahr 2024 allgemein verfügbar. Seitdem haben wir es mit Kunden, die es in großem Maßstab einsetzen, ständig weiterentwickelt. In dieser Zeit haben sich einige gängige Mythen über Liquid Clustering und Partitionierung gehalten, und heute wollen wir sie entlarven.
Mythos #1: Partitionierung ist schneller, weil sie Verzeichnisse statt Dateien löschen kann
Der Mythos besagt: Mit Partitionierung können Spark oder andere Engines ganze Verzeichnisse löschen, ohne Dateien darin zu öffnen.
Realität: Das Löschen von Verzeichnissen existiert bei modernen Open-Table-Formaten wie Delta und Iceberg nicht. Delta verwendet beispielsweise ein Transaktionsprotokoll, um jede Datendatei zusammen mit Statistiken pro Spalte zu verfolgen, und das Löschen erfolgt anhand dieser Statistiken, nicht anhand der Verzeichnisstruktur. Die Engine listet niemals Verzeichnisse auf, um eine Abfrage zu planen. Sie liest das Transaktionsprotokoll, wertet Filter anhand von Statistiken aus und überspringt Dateien, die nicht übereinstimmen. Liquid Clustering verwendet denselben Mechanismus. Ob Ihre Daten in `date=x/hour=y/` oder in einem flachen Verzeichnis von geclusterten Dateien liegen, die Engine löscht auf Dateiebene. Es gibt keine Abkürzung auf Verzeichnisebene zu verlieren.
Mythos #2: Partitionierung ist besser, wenn nach einer Spalte mit niedriger Kardinalität gefiltert wird
Der Mythos besagt: Für eine Spalte mit einer kleinen Anzahl von eindeutigen Werten bietet die Partitionierung eine perfekte Datentrennung und gute Dateigrößen.
Realität: Liquid Clustering erkennt automatisch, wann Optimierungen für niedrige Kardinalität angewendet werden sollen. Wenn Sie beispielsweise nach (date, user_id) clustern und date eine niedrige Kardinalität aufweist, strebt das System an, dass jede Datei Zeilen von nur einem Datum enthält. Spalten mit höherer Kardinalität, wie user_id, werden dann automatisch für eine feinere Sortierung innerhalb der Dateien jedes Datums verwendet, ohne dass andere Sortiertechniken wie Z-Ordering erforderlich sind.
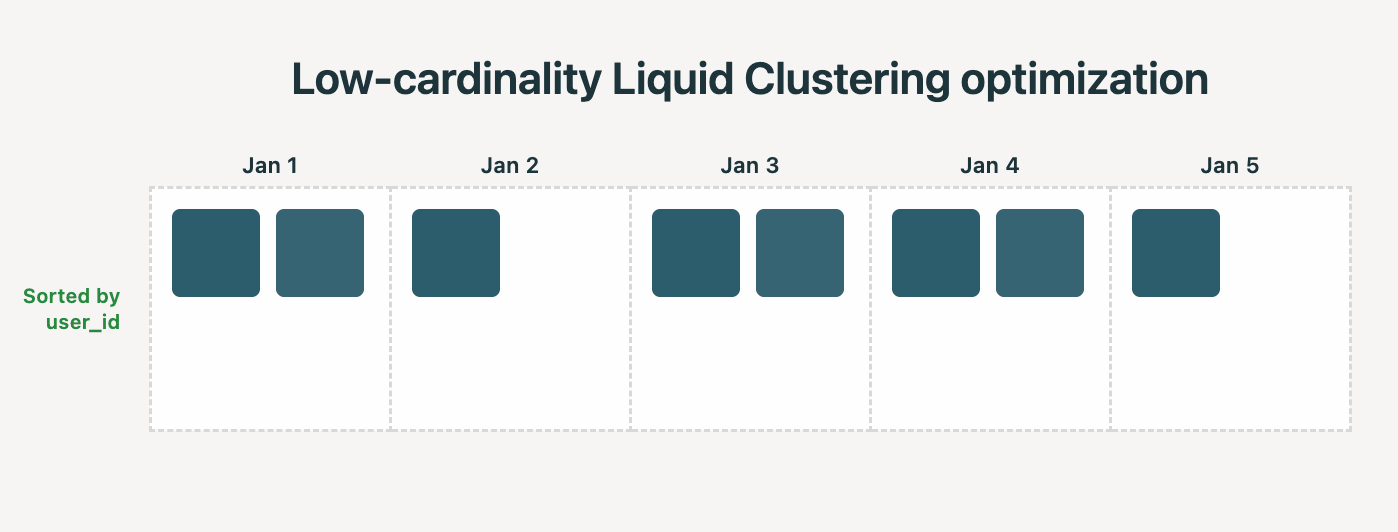
Wir sahen die folgenden Verbesserungen bei der Benchmark-Messung dieser Liquid-Optimierung auf einem realen Data-Warehousing-Benchmark: 35 % weniger Zeit für die Clusterbildung und 22 % schnellere Abfragezeiten.
Darüber hinaus ist Liquid Clustering darauf ausgelegt, bei der Clusterbildung auf einer Spalte mit hoher Kardinalität besser als die Partitionierung zu sein, da es immer versucht, Dateien von guter Größe zu erstellen.
Mythos #3: Liquid Clustering unterstützt keine Metadaten-only-Operationen
Der Mythos besagt: Metadaten-only-Operationen werden einzigartig durch Partitionierung unterstützt. Ein DELETE, das mit Partitionsgrenzen übereinstimmt, aktualisiert nur die Metadaten der Tabelle, und Aggregationen auf Partitionsspalten können ohne Scannen von Dateien berechnet werden. Liquid Clustering kann das nicht.
Realität: Liquid Clustering unterstützt auch Metadaten-only-Operationen, einschließlich DELETEs, COUNT, DISTINCT und GROUP BY-Abfragen. Die Engine verwendet dieselben Min/Max-Statistiken pro Datei, die sie für das Überspringen von Daten verwendet, um zu bestimmen, wann die Antwort einer Abfrage allein aus Metadaten berechnet werden kann. In unseren Benchmarks waren Metadaten-only-DELETEs auf Liquid Clustered-Tabellen ~90 % schneller als vollständige Neuschreibungs-DELETEs. Andere Metadaten-only-Aggregationsabfragen zeigten Geschwindigkeitssteigerungen von bis zu 27x.
Mythos #4: Liquid Clustering funktioniert nicht gut im Petabyte-Maßstab
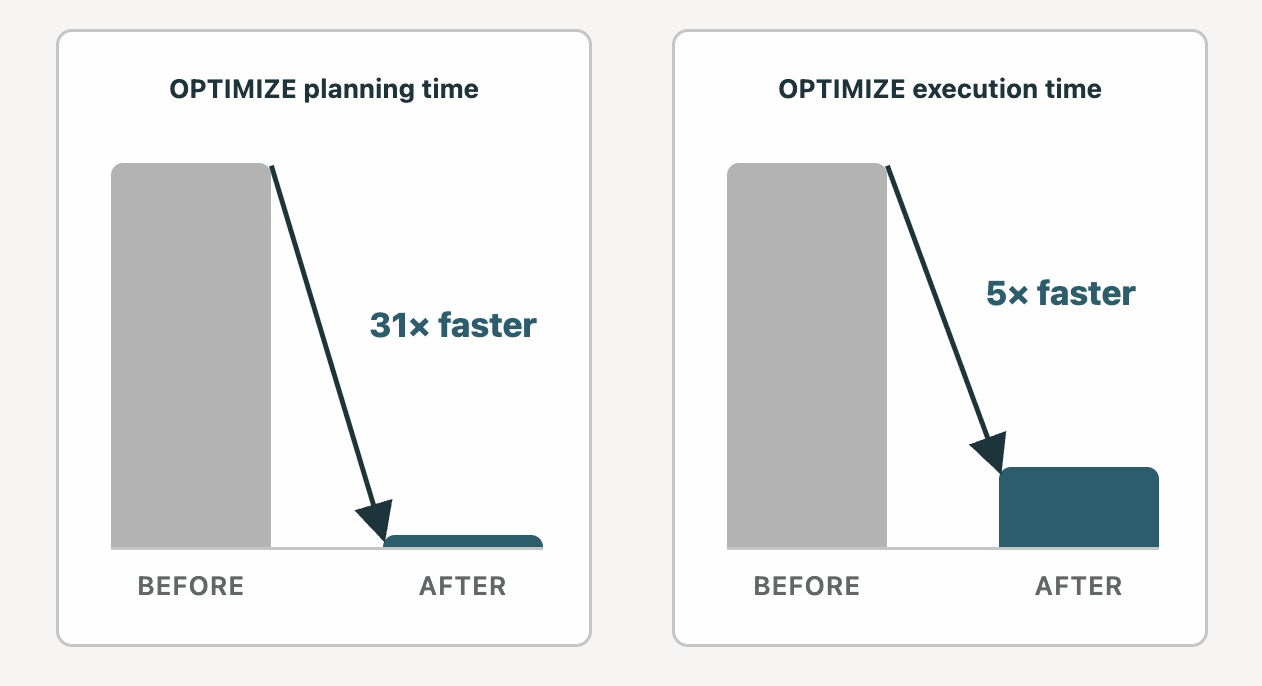
Der Mythos besagt: OPTIMIZE auf einer PB-großen Tabelle kann Stunden dauern und die Wartungskosten sind zu hoch.
Realität: Wir haben eine Reihe von erheblichen Verbesserungen an OPTIMIZE vorgenommen, und Dutzende von Kunden haben jetzt PB-große Liquid Clustered-Tabellen in Produktion. Vor zwei Jahren konnte die Planung, die erste Phase von OPTIMIZE, in einigen Fällen bis zu 12 Stunden für eine 10 PB Liquid-Tabelle dauern. Wir haben die Zeit seitdem damit verbracht, die Planungszeit auf 23 Minuten zu reduzieren. Die Ausführung, die zweite Phase von OPTIMIZE, wurde auf einem Medium DBSQL-Cluster 5x schneller.
Mythos #5: Liquid Clustering nützt nur einer Teilmenge von Lesern
Der Mythos besagt: Liquid Clustering ist nur für Databricks-Leser von UC-verwalteten Delta-Tabellen von Vorteil.
Realität: Liquid Clustering ist eine Optimierung auf der Schreibseite. Es ist die Art und Weise, wie die Engine Dateien für effizientes Data Skipping organisiert. Das Ergebnis sind Standard-Parquet-Dateien mit Min/Max-Statistiken, die in Open-Table-Formaten wie Delta/Iceberg geschrieben werden. Jeder kompatible Leser (z. B. Open-Source Apache Spark, DuckDB usw.) kann diese Statistiken verwenden, um Dateien zu überspringen. Liquid Clustering ist sowohl für externe/verwaltete als auch für Delta/ Iceberg-Tabellen verfügbar, und der Vorteil gilt unabhängig vom Leser.
Mythos #6: Partitionierung ist für gleichzeitige ETL erforderlich
Der Mythos besagt: Gleichzeitige ETL erfordert Schreibgrenzen. Ohne Partitionierung riskieren zwei Schreiber, die dieselbe Tabelle aktualisieren, Kollisionen, und die Delta/Iceberg-Nebenläufigkeitskontrolle zwingt einen von ihnen zum Wiederholen oder Fehlschlagen. Partitionieren Sie und geben Sie jedem Schreiber seinen eigenen Teil der Tabelle, sodass zwei Pipelines niemals dieselben Dateien berühren.
Realität: Die Arbeit auf Partitionsebene war eine Notlösung für ein älteres Nebenläufigkeitsmodell. Im Gegensatz zur Partitionierung, die nur Nebenläufigkeit auf Dateiebene bietet, bietet Liquid Nebenläufigkeit auf Zeilenebene. Zwei Schreiber, die verschiedene Zeilen aktualisieren, geraten nicht mehr in Konflikt, selbst wenn sich diese Zeilen in derselben Datei befinden. Dies beseitigt einen der Hauptgründe, warum Teams Tabellen partitioniert haben: die Aufrechterhaltung von Schreibgrenzen, um Serialisierung zu vermeiden. Mit Liquid Clustering kann ETL problemlos gleichzeitig auf dieselbe Tabelle zugreifen.
Mythos Nr. 7: Z-Ordering gleicht die Mängel der Partitionierung aus
Der Mythos besagt: Die Partitionierung behandelt die Filter der Partitionsspalte, und Z-Ordering kümmert sich um den Rest. Durch Ausführen von OPTIMIZE ZORDER BY sortiert die Engine Daten für optimale Überspringung bei Filtern, die nicht mit dem Partitionschema übereinstimmen.
Realität: Z-Ordering rettet die Partitionierung nicht. Tatsächlich hat es seine eigenen strukturellen Probleme.
- Das erste ist schlechte Clustering-Qualität. Z-Order erhält keine echte Reihenfolge über die Tabelle hinweg. Werte für dieselbe Spalte können über viele Dateien verteilt sein, sodass die Min/Max-Bereiche pro Datei breiter sind und Abfragen weniger Dateien überspringen als bei Liquid.
- Das zweite sind unnötige Neuschreibungen. Z-Order muss periodisch neu ausgeführt werden, wenn neue Daten eintreffen, und jede Neuausführung schreibt große Mengen alter, möglicherweise bereits geclusterter Daten neu, um die Clustering-Qualität wiederherzustellen. Bei kontinuierlicher Aufnahme steigen die Kosten für die gute Clusterung von Daten mit Z-Order mit der Tabelle.
Liquid clustert inkrementell, auch zur Schreibzeit, sodass das Layout ohne unnötige Neuschreibungen optimal bleibt.
Mythos Nr. 8: Partitionierung ist für selektive Datenüberschreibungen notwendig
Der Mythos besagt: Die Möglichkeit, Daten selektiv zu überschreiben, ist nur über Dynamic Partition Overwrites verfügbar.
Realität: Selektive Überschreibungen funktionieren nativ auf Liquid-Tabellen. Databricks unterstützt REPLACE USING und REPLACE ON, zwei SQL-Syntaxen zum selektiven Überschreiben von Daten auf jedem Datenlayout: Liquid Clustered, partitionierte oder einfach unclusterte Tabellen. Im Gegensatz zu Dynamic Partition Overwrite, das eine Spark-Konfiguration erfordert, können REPLACE USING und REPLACE ON auf jedem Compute verwendet werden: klassische Cluster, SQL Warehouses und Serverless. Der Vorgang ist atomar und stimmt mit jeder von Ihnen gewählten Spalte überein.
Erfolgsgeschichten: Migration von Partitionierung zu Liquid Clustering
7,7-fache Abfragebeschleunigung bei Arctic Wolfs 3,8 PB Security Telemetry Tabelle
Arctic Wolf betreibt eine über 3,8 PB große Security Telemetry Tabelle, die 1+ Billionen Ereignisse pro Tag erfasst, wobei Bedrohungsjäger auf aktuelle Daten angewiesen sind, um aktive Angriffe zu erkennen.
Nach der Migration von der Partitionierung zu Liquid Clustering auf Unity Catalog verwalteten Tabellen mit Predictive Optimization sah Arctic Wolf:
- 90-Tage-Abfragen von 51 Sekunden auf 6,6 Sekunden reduziert
- Dateianzahl von 4 Mio. auf 2 Mio. reduziert
- Datenaktualität von Stunden auf Minuten verbessert
Lese- und Schreibverbesserungen bei kritischen CDC-Tabellen für Bolt
Bolt hat kürzlich Liquid Conversion (derzeit in Private Preview) ausprobiert, das partitionierte Tabellen mit ALTER TABLE .. REPLACE PARTITIONED BY WITH CLUSTER BY vor Ort in Liquid konvertiert. Sie beobachteten die folgenden Lese- und Schreibvorteile bei einer TB-großen CDC-Tabelle nach der Konvertierung zu Liquid Clustering:
- Schreibdurchsatz (Zeilen/Sek.) um 138 % erhöht
- Lesezeiten um bis zu 63 % reduziert, mit einer durchschnittlichen Reduzierung von 21 % über 9 repräsentative Abfragen
Liquid Clustering hat die Arbeit jedes Schreibvorgangs drastisch reduziert und unseren Durchsatz bei unserer kritischsten CDC-Tabelle erheblich gesteigert. Auch die Lesevorgänge wurden durchweg verbessert. Das Beste war: Wir haben die Konvertierung von der Partitionierung neben der Live-Ingestion mit null Ausfallzeiten durchgeführt. Damit bot Liquid Clustering genau die Art von Leistung und Zuverlässigkeit, die wir im Plattformmaßstab benötigten. —Marcin, ein leitender Plattformingenieur bei Bolt
5,9-fache Beschleunigung der Abfragezeit bei einer Petabyte-großen internen Workload
Wir betreiben intern eine 1,1 PB große Tabelle, die tausende Male am Tag abgefragt wird, meist von Ingenieuren, die Produktionsuntersuchungen und Beobachtungs-Dashboards ausführen. Ursprünglich war sie nach Datum und Stunde partitioniert, in der Annahme, dass Zeitbereichsscans dominieren würden. Diese Annahme erwies sich jedoch als unvollständig. Während Zeitbereichsscans üblich waren, wurde die Tabelle auch häufig nach Quelle und ID abgefragt, was die Engine zwang, jede Datei in den relevanten Datums- und Stundenpartitionen zu scannen, um eine Handvoll Zeilen zu finden.
Das Hinzufügen von Quelle und ID als Partitionen war nicht praktikabel, da es zu viele unterschiedliche Werte gab. Dies hätte Milliarden von winzigen Dateien erzeugt. Liquid Clustering beseitigte den Kompromiss und ermöglichte das Clustering nach Zeit und den zusätzlichen Identifikationsspalten gleichzeitig, während gute Dateigrößen beibehalten wurden.
| Layout | |
|---|---|
| Vorher | Partitioniert nach Datum, Stunde |
| Danach | Gruppiert nach Datum, Stunde, Quelle, ID |
Benchmarks zeigten massive Verbesserungen bei 16 repräsentativen Produktionsabfragen:
| Metrik | Vorher (partitioniert) | Danach (Liquid) | Verbesserungen |
|---|---|---|---|
| Wanduhrzeit | 406s | 70s | 5,9x Beschleunigung |
| Gelesene Bytes | 3,5 TB | 0,48 TB | 86% weniger gelesene Bytes |
Die Tabelle selbst wurde auch kleiner. Die Gesamtgröße sank von 1,1 PB auf 0,8 PB, eine Reduzierung um 27% ohne Änderung der zugrunde liegenden Daten. Besser gruppierte Dateien lassen sich effizienter komprimieren, und die Steuer für kleine Dateien, die mit Überpartitionierung einhergeht, entfällt.
Was kommt als Nächstes für Liquid Clustering
Optimierung von Liquid-zu-Liquid-Joins: bis zu 51% schneller bei 87% weniger Shuffle
Heute kann das Verknüpfen von Liquid-Tabellen anhand ihrer Clustering-Spalten einen vollständigen Daten-Shuffle erfordern, selbst wenn die Daten bereits nach diesen Spalten organisiert sind. Co-Clustered Joins (jetzt in privater Vorschau) entfernen diesen Shuffle automatisch. Bei einem realen Data-Warehousing-Benchmark lief ein Liquid-zu-Liquid-Join ~51% schneller (28 Minuten → 14 Minuten) und 87% weniger Daten wurden geshuffelt (1,2 TiB → 150 GiB) als bei derselben Abfrage ohne die Optimierung.
Einfache Liquid-Konvertierung von partitionierten Tabellen
Zuvor erforderte die Konvertierung einer partitionierten Tabelle in Liquid Clustering eine vollständige Tabellen-Neubeschreibung und nachgelagerte Breaking Changes mit REPLACE TABLE oder einen Cutover mit Dual Writes und geplantem Stillstand. Wir führen einen neuen Befehl ein (jetzt in privater Vorschau), der diese Konvertierung erleichtert und sowohl Ausfallzeiten als auch Neubeschreibungen minimiert.
Erste Schritte mit Liquid Clustering
Erstellen Sie eine Tabelle mit Liquid Clustering:
Oder, wenn Sie UC-verwaltete Tabellen mit Predictive Optimization verwenden, nutzen Sie Automatic Liquid Clustering, um Clustering-Schlüssel intelligent basierend auf Ihrer Workload und Ihren Abfragemustern auszuwählen:
Liquid Clustering ist das Layout für das moderne Lakehouse. Probieren Sie es mit Ihrer nächsten Tabelle aus oder wenden Sie sich noch heute an Ihr Account-Team, um die privaten Vorschauen für die Konvertierung von partitionierten zu Liquid-Tabellen und Co-Clustered Joins auszuprobieren!
Vergessen Sie nicht, uns bei DAIS zu treffen!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.