Die Evolution des Data Engineering: Wie Serverless Compute Notebooks, Lakeflow-Jobs und deklarative Spark-Pipelines transformiert
Erfahren Sie, wie Serverless compute von Databricks eine unübertroffene Einfachheit, Performance und Zuverlässigkeit für Notebooks, Lakeflow Jobs und deklarative Spark-Pipelines bietet.
von Aaron Davidson, Ihor Leshko, Justin Breese, Piyush Singh, Vivek Narasimhan, Prashanth Babu Velanati Venkata, Roland Fäustlin, Hemant Saxena und Mostafa Mokhtar
- Serverlos Compute für Notebooks, Lakeflow Jobs und Spark Declarative Pipelines macht die Verwaltung von Infrastruktur- und Spark-Upgrades überflüssig
- Serverlos Compute verbessert Workloads automatisch und hat im letzten Jahr die Performance um 80 % und die Kosteneffizienz um bis zu 70 % gesteigert, ohne dass ein Benutzereingriff erforderlich war
- Serverlos Compute ist jetzt das stabilste Compute-Produkt von Databricks. Es passt die Cluster-Größe automatisch an steigende Datenmengen an und schützt Workloads vor Cloud-Ausfällen und Ressourcenengpässen, was zu 89 % mehr erfolgreichen Ausführungen führt
Data Engineering hat einen Wendepunkt erreicht. Da Unternehmen bei Geschäftsentscheidungen zunehmend auf KI und Machine Learning setzen, ist die Komplexität der Verwaltung der Compute-Infrastruktur zu einem kritischen Engpass geworden. Fortschritte bei Databricks Serverless compute helfen Teams, bis zu 20 % ihrer Zeit bei Routine-Tasks wie der Aktualisierung von Databricks Runtime (DBR)-Versionen, der Verwaltung von Clustering-Einstellungen und der Fehlerbehebung bei Infrastrukturproblemen einzusparen. Heute freuen wir uns, Ihnen mehrere neue Feature-Einführungen für Databricks serverlos Compute vorzustellen und zu zeigen, wie es das Paradigma grundlegend verändert hat, indem es unübertroffene Einfachheit, Leistung und Zuverlässigkeit für Notebooks, Lakeflow Jobs und Spark Declarative Pipelines (SDP, früher bekannt als DLT) bietet. Beispielsweise bietet Serverless-Compute im Standard-Performance-Modus Kosteneinsparungen von 70 % im Vergleich zu leistungsoptimierten Workloads und über 50 % Kosteneinsparungen bei Nicht-Spark-Workloads. Darüber hinaus starten Performance-optimierte Workloads in Sekunden und laufen in der Regel doppelt so schnell. Versionless hat im letzten Jahr 25 DBR-Upgrades für mehr als 4,5 Milliarden Workloads mit einer außergewöhnlichen Erfolgsquote von 99,998 % durchgeführt.
Die Herausforderung beim Infrastrukturmanagement ist real
Jede Data-Engineering-Plattform muss eine breite Palette an operativen Aufgaben bewältigen, um herkömmliche Spark-Clusters zu verwalten, wie zum Beispiel:
- Netzwerke müssen mit VPCs, Gateways, IP-Adressbereichen und privaten Endpunkten eingerichtet werden.
- Sicherheit und Compliance erfordern besondere Aufmerksamkeit für Schwachstellenmanagement, Verschlüsselung und Schutz vor Datenexfiltration.
- Effizienzaspekte wie Instanzgröße, Auslastung, Pools und Delta-Optimierung sind für den Betrieb einer robusten Datenumgebung unerlässlich.
- Die Aufrechterhaltung aktueller Runtimes mit den neuesten Leistungsverbesserungen ist ein weiterer wichtiger Aspekt des Plattformbetrieb. Bei zwei DBR-Releases mit Langzeit-Support pro Jahr ist es normal, dass Teams Upgrades sorgfältig evaluieren, um Stabilität, Performance und Kompatibilität mit ihren Workloads sicherzustellen.
Serverless compute bietet ein anderes Betriebsmodell: Grundlegende Tasks wie Netzwerkfunktionen und IP-Bereiche, Sicherheits-Härtung, Lifecycle-Management und Laufzeit-Upgrades werden alle automatisch erledigt und kontinuierlich optimiert. Dadurch können Teams die neuesten Optimierungen früher übernehmen und mehr Zeit auf die Entwicklung von Datenprodukten und die Bereitstellung von geschäftlichem Mehrwert verwenden, anstatt die Infrastruktur zu verwalten.
Serverless Compute: Einfach, performant, wartungsfrei
Databricks Serverless-Compute ist eine von Databricks verwaltete, selbstoptimierende Compute-Lösung, die keinen manuellen Eingriff erfordert und diese Herausforderungen durch drei Kernprinzipien bewältigt:
- Einfach: Sie müssen nur auswählen, ob die Workload schnell (Performance-optimierter Modus) oder kosteneffizient (Standardmodus) ausgeführt werden soll. Databricks nimmt ständig und automatisch Feinabstimmungen vor, um das ausgewählte Ziel zu erreichen. Keine Einstellmöglichkeiten, Instanztypen oder Auswahl des Scale-Faktors erforderlich.
- Performant: Dank der optimierten Infrastruktur von Databricks und einem neuen Autoscaler startet Serverless Compute in Sekunden, lädt abhängige Bibliotheken in Sekunden aus dem Cache und läuft in der Regel doppelt so schnell wie klassische Cluster.
- Wartungsfrei: Das Serverless von Databricks skaliert Ihre compute automatisch horizontal und vertikal, um Out-of-Memory-Probleme zu vermeiden, schützt Sie vor Cloud-Ausfällen und führt ein Failover auf verfügbare Instanztypen durch, was zu einer hohen Fehlertoleranz führt. Es ist außerdem versionslos und aktualisiert Sie automatisch auf die neuesten Performance-Verbesserungen, während die vollständige Abwärtskompatibilität erhalten bleibt.
Serverless ist einfach
Performance und Effizienz von Haus aus
Mit Serverless Compute für Notebooks, Spark Declarative Pipelines und Lakeflow Jobs wählt Databricks automatisch die richtige Infrastruktur für Ihre Workload aus und optimiert diese dann kontinuierlich auf der Grundlage historischer Workload-Informationen. Daher müssen Benutzer keine bestimmten Instanztypen, Autoscaler-Einstellungen oder Optimierungen wie Photon mehr auswählen. Unsere KI erkennt automatisch, welche Infrastruktur und Einstellungen für die Workload am vorteilhaftesten sind, und aktiviert diese automatisch. Z. B. wird Photon nur dann verwendet, wenn die spezifische Workload von der Photon-Beschleunigung profitiert.
Für Workloads, die kein Spark erfordern, stellt unsere automatische Infrastrukturauswahl sicher, dass, wenn Spark nicht benötigt wird, spontan eine kleinere VM bereitgestellt wird. Dieser Ansatz kann zu Kosteneinsparungen von über 50 % und einem um mehr als 33 % schnelleren Startup im Vergleich zu klassischen Clustern führen, einfach dadurch, dass nur die Ressourcen genutzt werden, die Sie tatsächlich benötigen.
Die Einführung von Performance-Modi für Lakeflow-Jobs und deklarative Spark-Pipelines stellt einen bedeutenden Fortschritt bei der compute-Optimierung dar, da Benutzer damit angeben können, wofür Databricks optimieren soll. Performance Optimized Modus startet in Sekundenschnelle und wird in der Regel doppelt so schnell wie klassische Cluster ausgeführt. Dieser Modus nutzt warme Maschinenpools und eine aggressive Ressourcenskalierung, um die Verarbeitungszeit zu minimieren, was ihn ideal für interaktive und zeitkritische Workloads macht.
Standard-Modus, der seit Juli allgemein verfügbar ist, verfolgt einen anderen Ansatz. Durch die Optimierung auf Kosteneffizienz anstatt auf reine Geschwindigkeit liefert es bis zu 70 % Kostenersparnis im Vergleich zum Modus „Leistungsoptimiert“ und behält dabei eine wettbewerbsfähige Performance bei. Dieser Modus ist perfekt für Batch-Workloads, geplante Jobs und Pipelines, bei denen eine Startup-Latenz von 4–6 Minuten im Austausch für erhebliche Kostensenkungen akzeptabel ist.
Performance-Modi ermöglichen es Benutzern, sich auf die für ihren Anwendungsfall spezifischen Datenerkenntnisse und geschäftlichen Anforderungen zu konzentrieren, anstatt die Infrastruktur zu verwalten. Diese Einfachheit ermöglicht es Benutzern, mehr Zeit für die Gewinnung von Erkenntnissen aus Daten aufzuwenden. Beachten Sie, dass Serverless in interaktiven Notebooks immer in Sekundenschnelle einen schnellen Start und eine schnelle Ausführung hat, um die Zeit der Benutzer optimal zu nutzen.
| Serverless-Compute-Modus | Typische Performance | Die wichtigsten Vorteile |
|---|---|---|
| Interaktiver Modus für Notebooks Beste Serverless-Umgebung für Data Science, vollständig verwaltete Plattform für Databricks Notebooks | < 10 Sekunden Startup, schnelle Skalierung |
|
| Performance-optimierter Modus für Lakeflow Jobs und SDP Beste Serverless Erfahrung für Data Engineering, mit schnellem Startup und schneller Ausführung für zeitkritische Lakeflow Jobs und SDP | < 1 Minute Startup, schnelle Skalierung |
|
| Standardmodus für Lakeflow Jobs und Pipelines Kostengünstigere Serverless-Erfahrung, vollständig verwaltete Plattform zum Ausführen von Jobs und SDP | 4–6 Minuten Startup, konservative Skalierung |
|
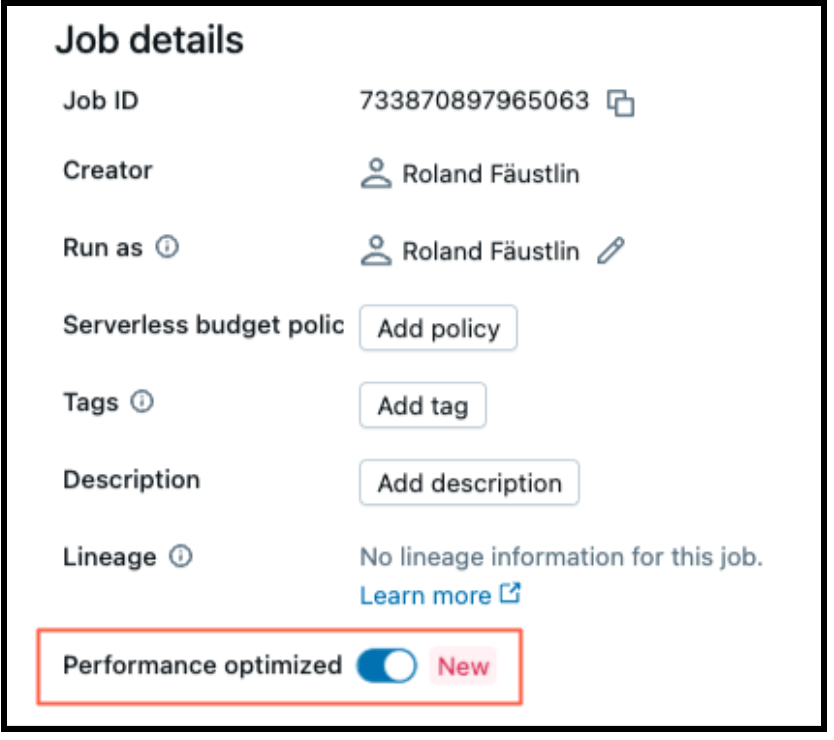
Mit Serverless Compute ist die Abstimmung auf Performance oder Effizienz so einfach wie das Umlegen eines Schalters. Wenn „Performance optimiert“ aktiviert ist, werden Ihre Workloads schneller gestartet und ausgeführt. Wenn es deaktiviert ist, erfolgt die Ausführung Ihrer Workloads im „Standard“-Modus, um die Effizienz zu optimieren.
Umfassendes Kostenmanagement und Governance
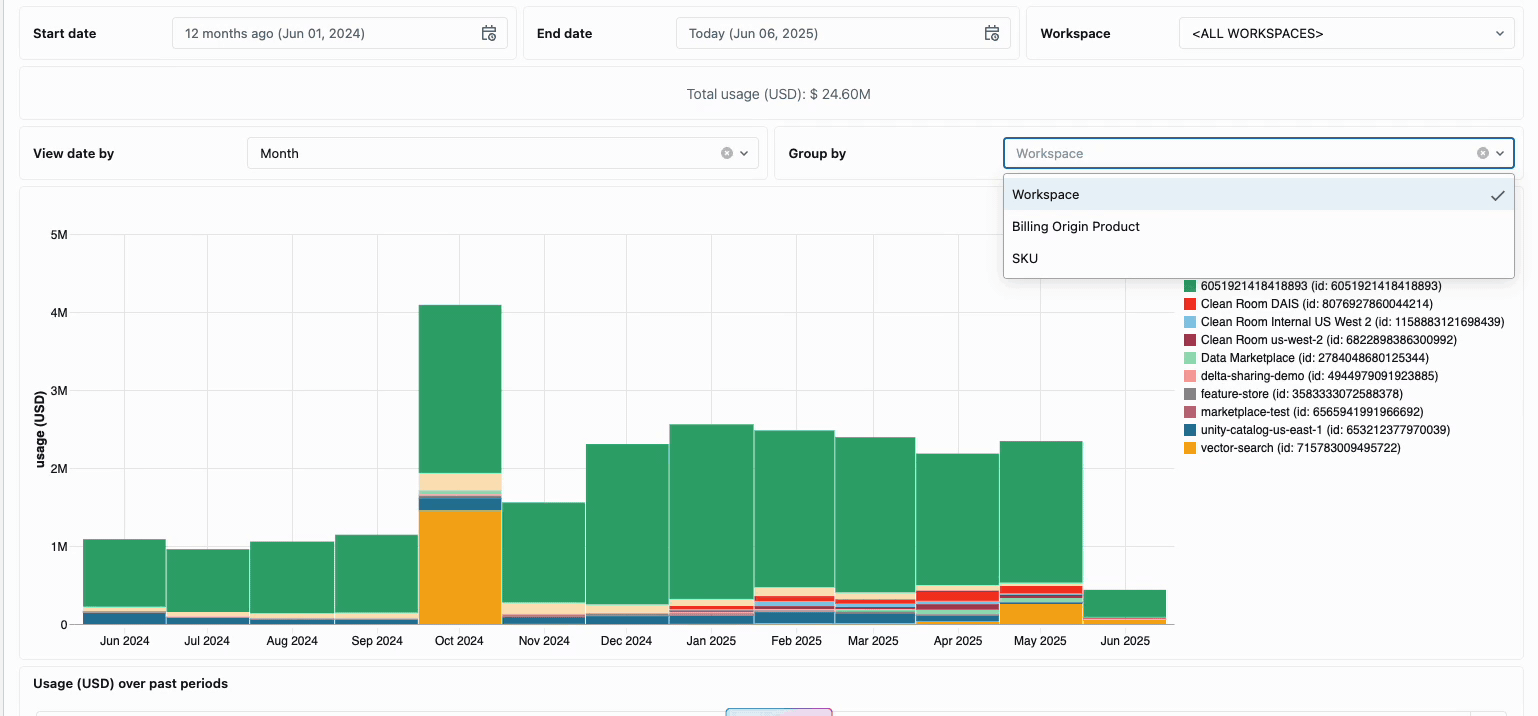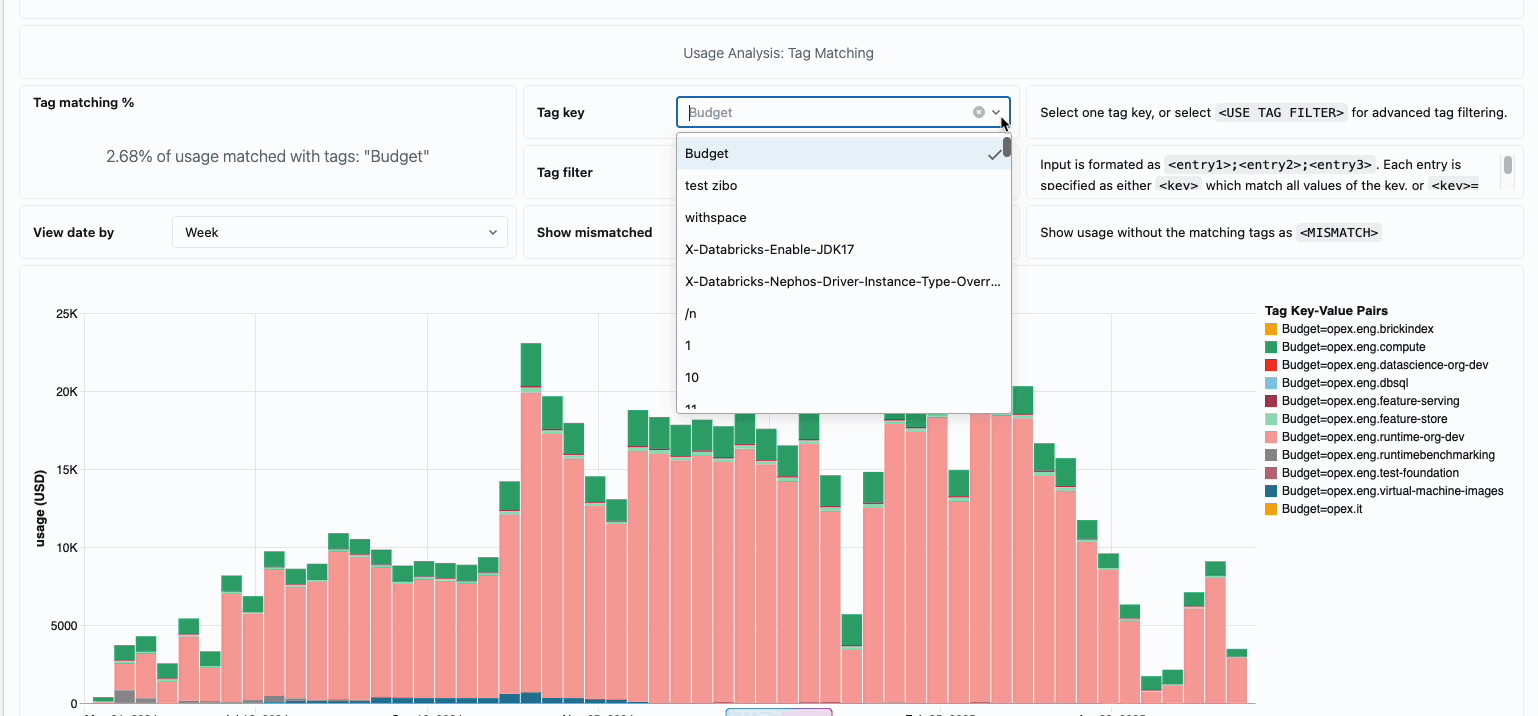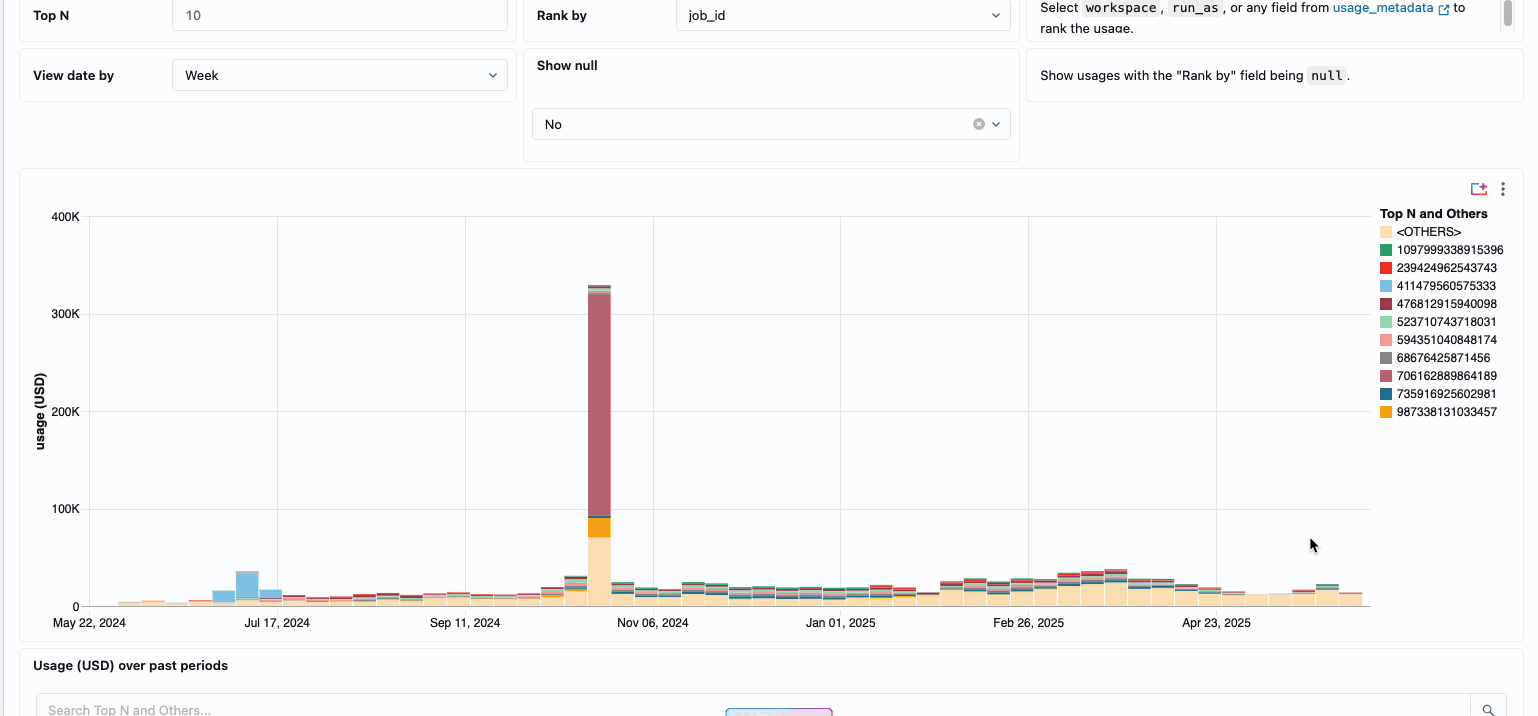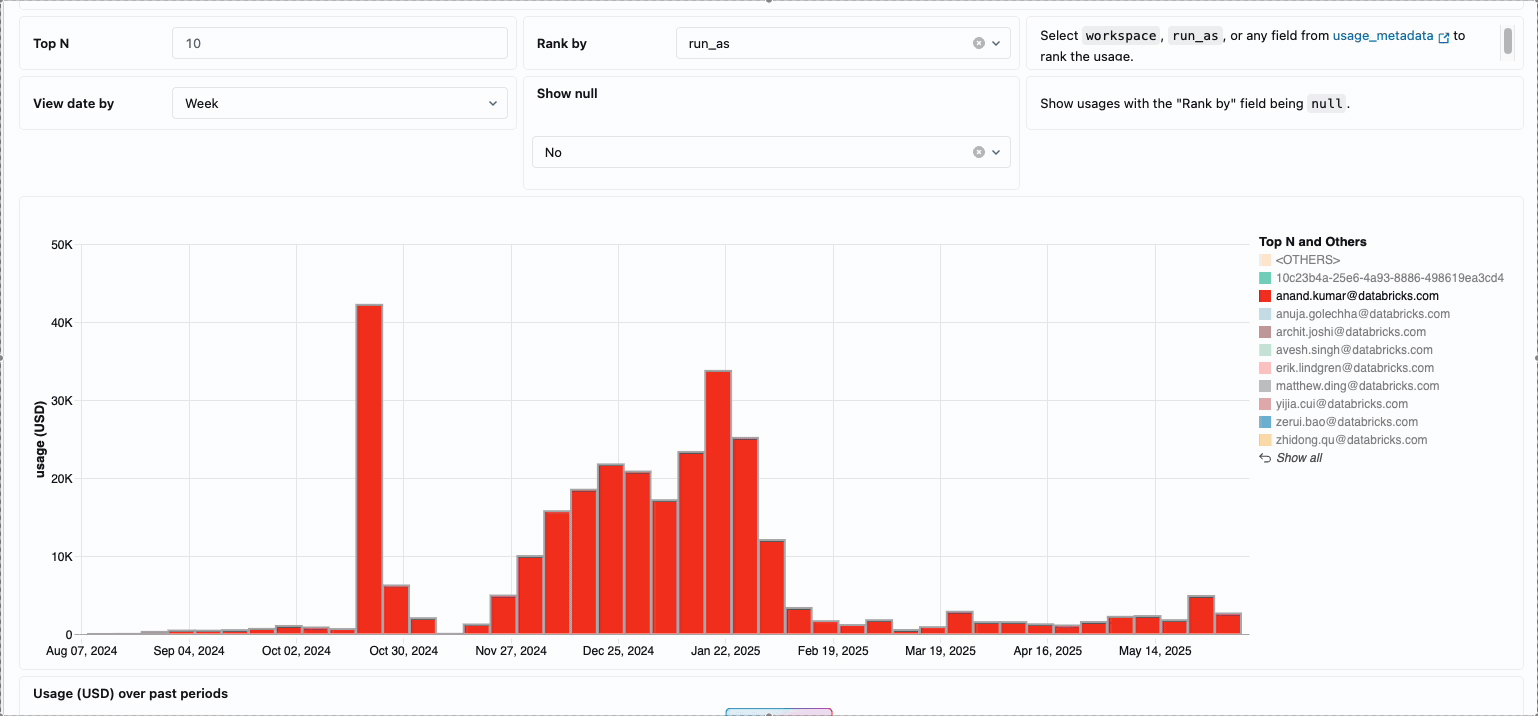
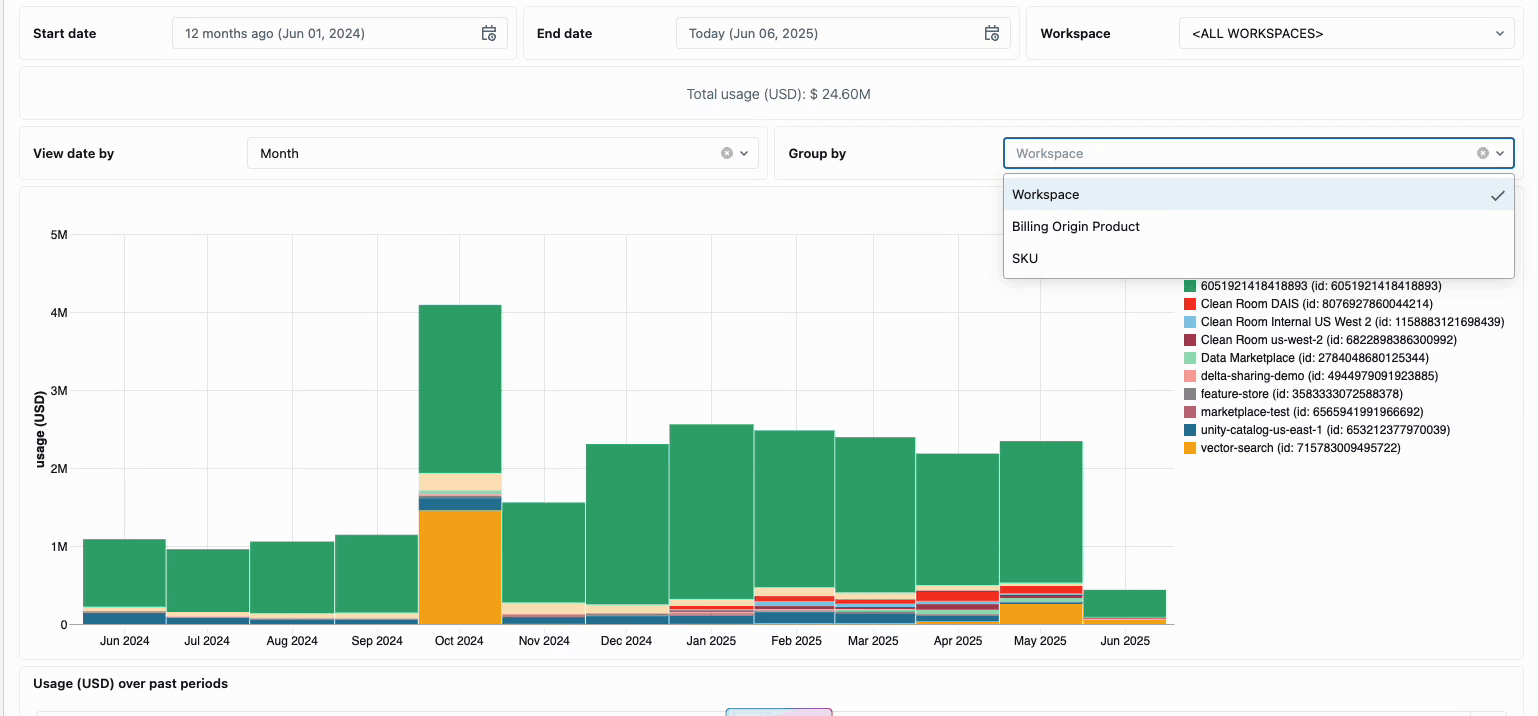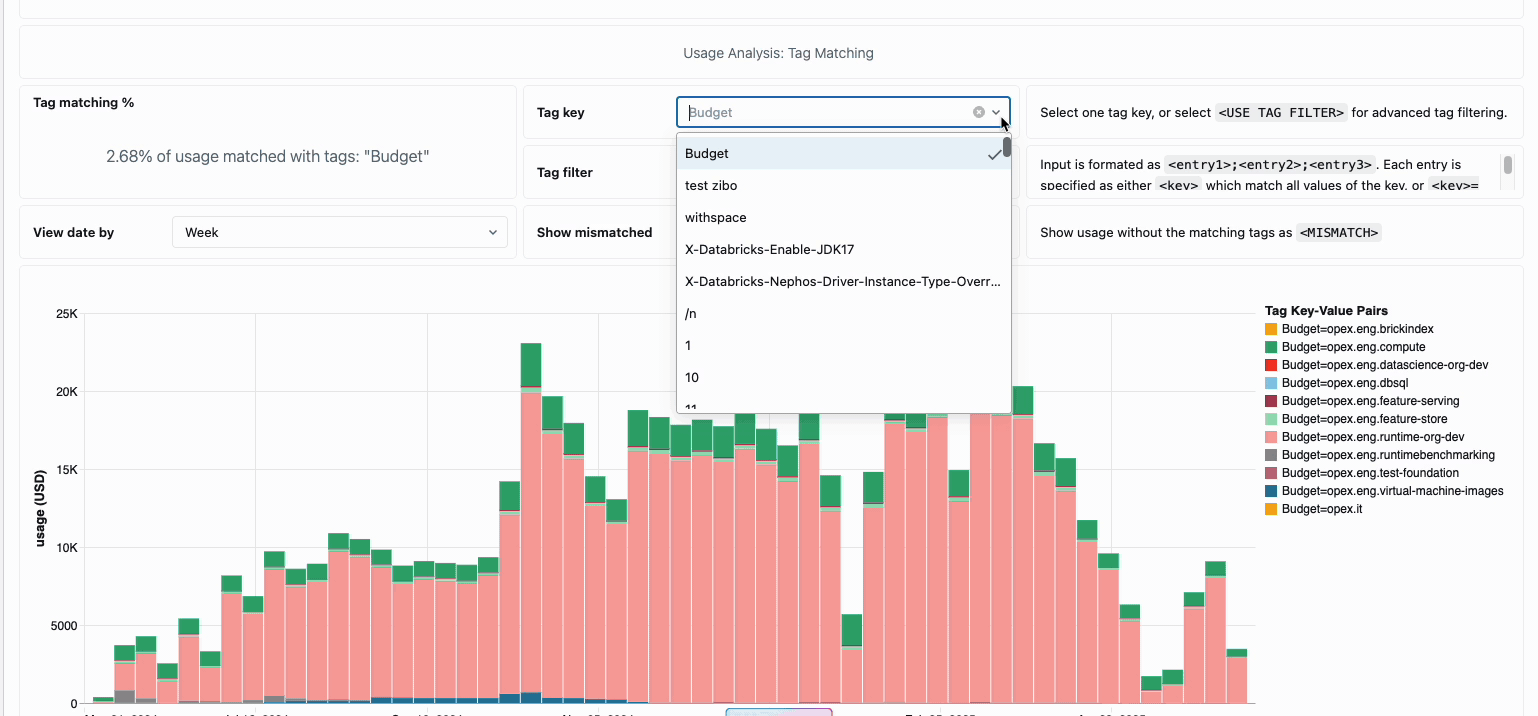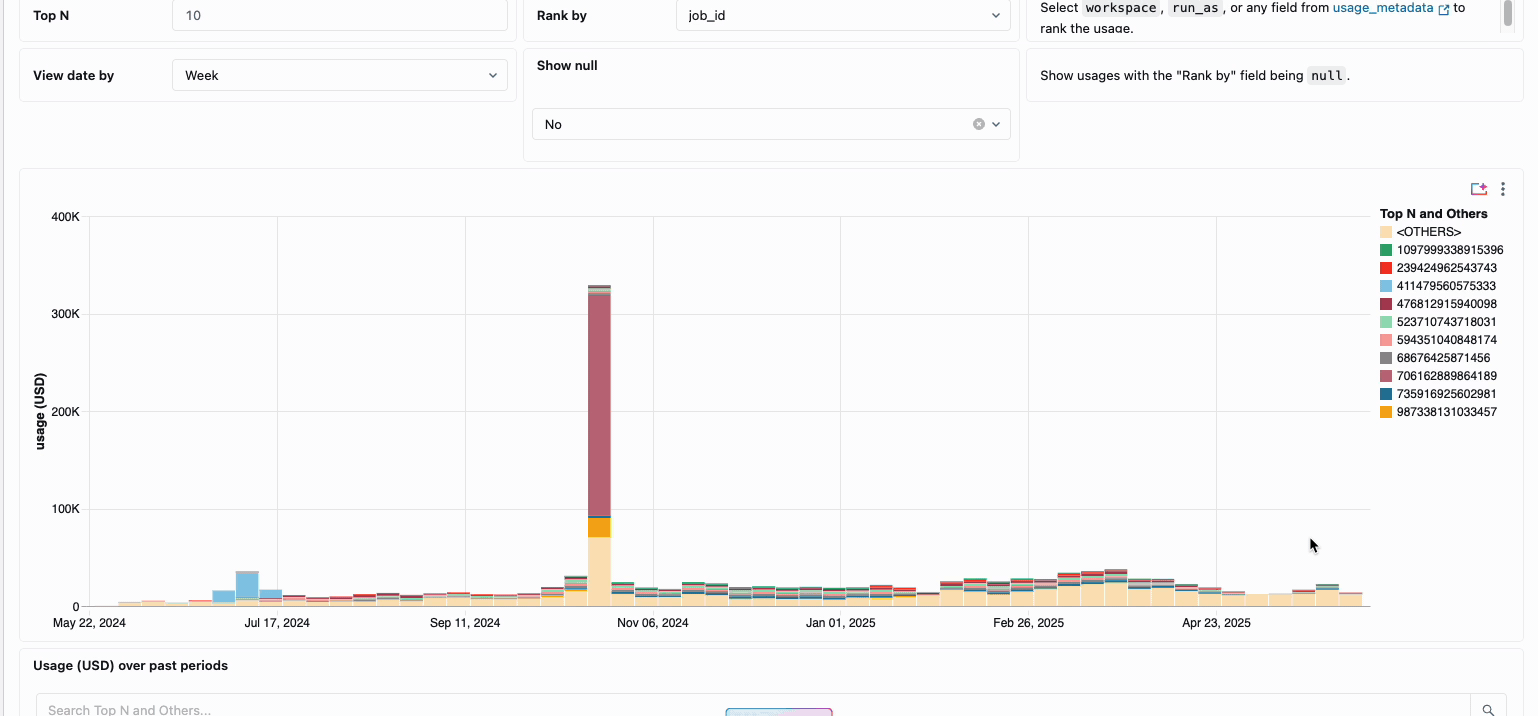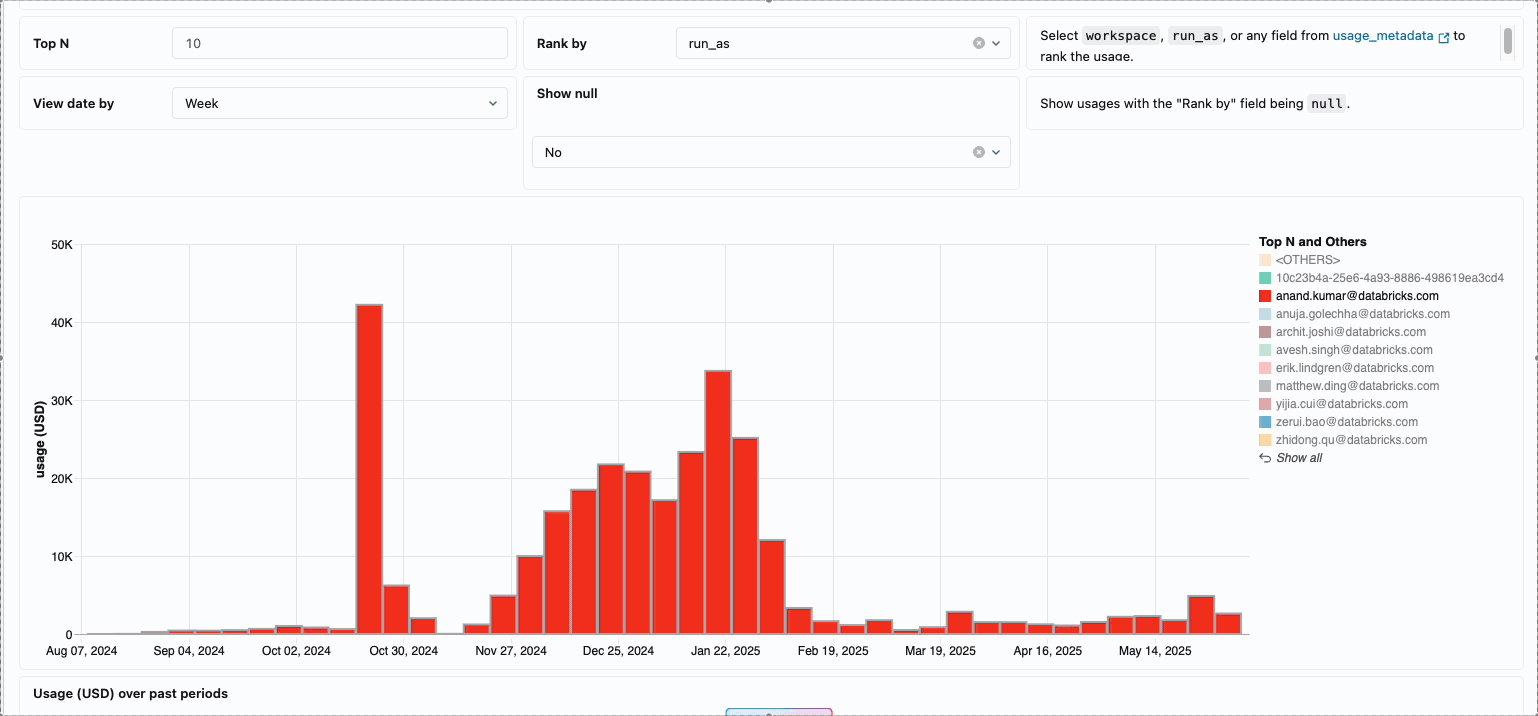
Die Verwaltung der compute-Kosten über verteilte Data-Engineering-Teams hinweg erforderte traditionell das Zusammenfügen unterschiedlicher Datenquellen und Abrechnungskomponenten – ein zeitaufwändiger Prozess, der oft die wahren Gesamtbetriebskosten verschleiert. Serverless Compute verwandelt diese Komplexität durch eine einheitliche Abrechnung in Klarheit und fasst alle Kostenkomponenten in einer einzigen, verständlichen Ansicht zusammen. Administratoren erhalten durch vordefinierte Budget-Dashboards und anpassbare Abfragen, die auf Systemtabellen basieren, sofortigen Einblick, wodurch die Notwendigkeit manueller Abstimmarbeiten über verschiedene Dienstanbieter hinweg entfällt.
Für Unternehmen, die eine interne Verrechnung benötigen, ermöglichen Serverless-Nutzungsrichtlinien eine Tag-Erzwingung, die die Kosten automatisch nach Team oder Projekt aggregiert und so eine genaue Zuordnung und Verantwortlichkeit über die Geschäftsbereiche hinweg gewährleistet. Die Plattform bietet außerdem mehrere Schutzebenen gegen unbeabsichtigte Ausgaben – intelligente Timeouts verhindern, dass außer Kontrolle geratene Abfragen die Budgets aufbrauchen, während granulare Nutzungsrichtlinien Administratoren eine präzise Kontrolle darüber geben, wer auf Serverless-Compute zugreifen und in welchem Umfang Ressourcen verbrauchen kann. So entsteht ein umfassender Governance-Rahmen, der Innovation mit finanzieller Verantwortung in Einklang bringt.
{kind=link}
Serverless: Auf Performance ausgelegt
Umgebungs-Caching eliminiert den Overhead bei der Installation von Abhängigkeiten
Herkömmliche Compute-Umgebungen erfordern oft Installationsschritte, um für jede Ausführung die richtige Umgebung vorzubereiten, insbesondere wenn Teams unterschiedliche Bibliotheksanforderungen haben. Serverless Compute ändert dies durch den Einsatz von intelligentem Umgebungs-Caching. Benutzer definieren ihre Umgebung einmal, und Databricks analysiert, lädt und installiert automatisch die erforderlichen Bibliotheken, erstellt dann einen Snapshot und speichert ihn im Cache. Zukünftige Ausführungen laden die Umgebung in Sekunden aus dem Cache– keine Downloads oder Installationen erforderlich. Dies ist besonders nützlich für kleine Workloads und ist im Durchschnitt 2x schneller. Neue default-Basissystemumgebungen ermöglichen es Administratoren, vorkonfigurierte Umgebungen für verschiedene Teams zentral zu verwalten, was die Workflows für Analysten, Data Scientists und ML-Ingenieure vereinfacht.
Startup ist für uns eine Priorität, und serverlose Notebooks und Workflows haben einen riesigen Unterschied gemacht. Serverless Compute für Notebooks macht es mit nur einem Klick ganz einfach.– Chiranjeevi Katta, Data Engineer bei Airbus
Serverless Spark Declarative Pipelines halbieren die Ausführungszeiten, ohne die Kosten zu beeinträchtigen, steigern die Engineering-Effizienz und vereinfachen komplexe Datenvorgänge, sodass sich Teams sowohl in Produktions- als auch in Entwicklungsumgebungen auf Innovation statt auf Infrastruktur konzentrieren können. – Cory Perkins, Sr. Data & KI Engineer bei Qorvo
In der Praxis sehen wir bei allen Workloads auf Databricks, dass serverloses compute im Durchschnitt 20 % kosteneffizienter ist als vergleichbare klassische Cluster-Workloads, und während Kunden ihren Cloud-Anbieter für den Startup klassischer Cluster bezahlen, berechnet Databricks nichts für den Startup.
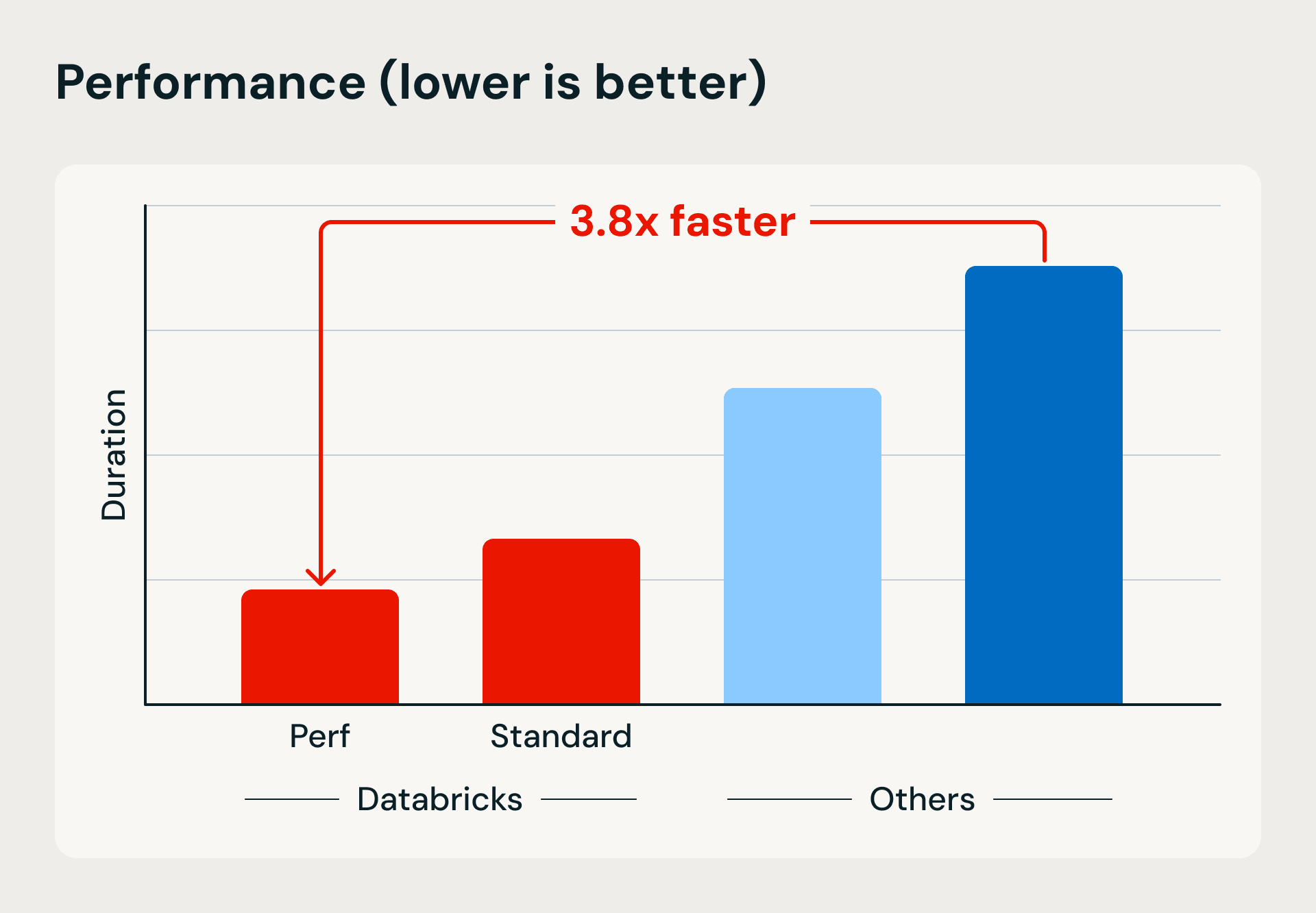
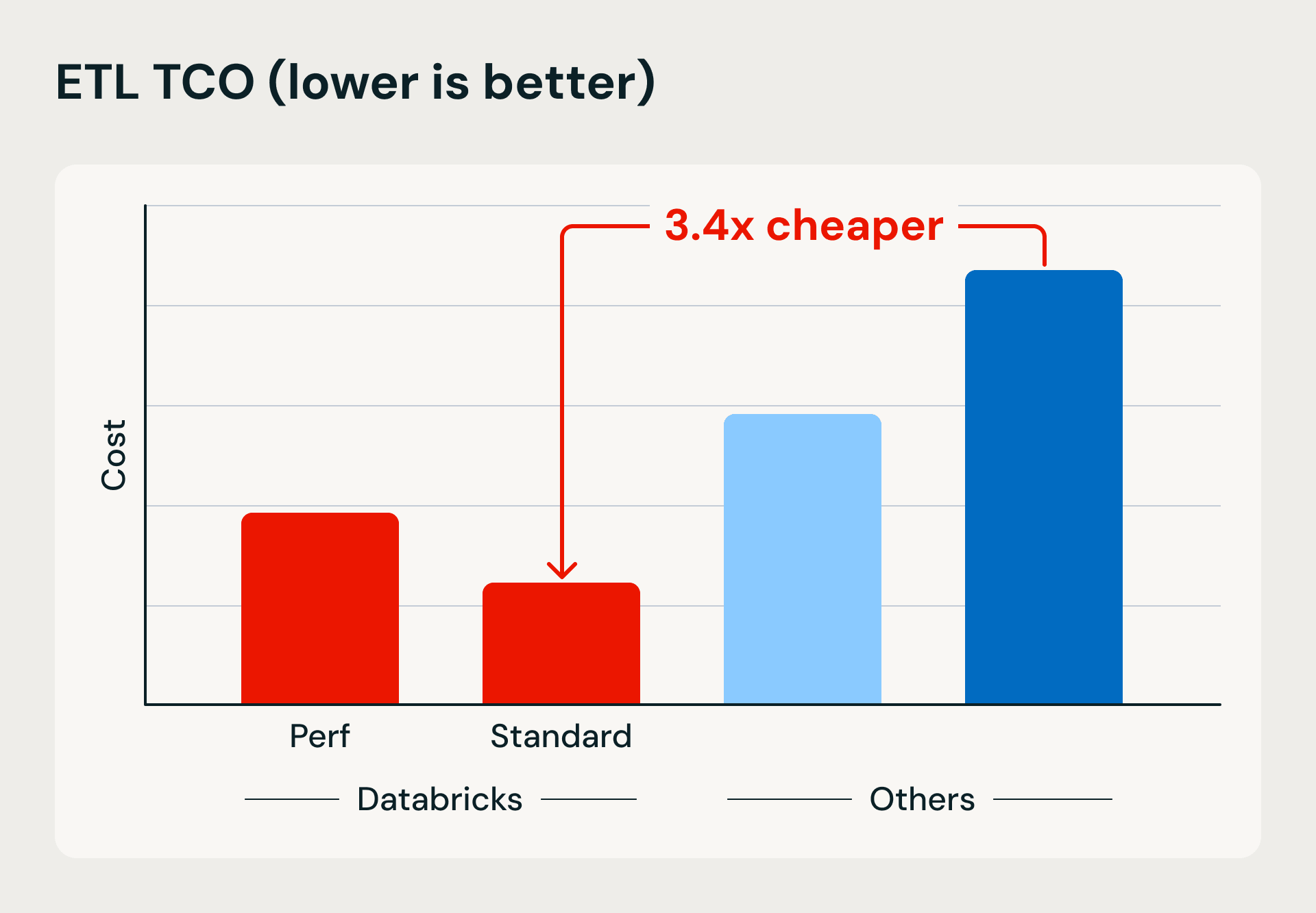
Leistungs- und Kostenvergleich, der die Vorteile von Databricks Serverless compute in puncto Ausführungsgeschwindigkeit und Effizienz aufzeigt. Der Benchmark lädt 1 TB mithilfe von Lakeflow Jobs und Merge-Upserts in Bronze und verfeinert und dedupliziert die Daten dann in Silver- und Gold-Tabellen.
Nach der Umstellung unserer Databricks-Pipelines auf ‚Serverless‘-Compute konnte HP Cloud-Einsparungen von über 32 % erzielen und die kombinierte Laufzeit von Jobs um 36 % reduzieren. Die mühelose Infrastrukturverwaltung, die ‚Serverless‘ bietet, machte diese Entscheidung zu einer naheliegenden und strategischen Wahl. – Luis Alonso, Head of Data Strategy & Engineering bei HP Marketing
Serverless deklarative Spark-Pipelines in der Google Cloud haben unseren Ansatz bei Uplight neu definiert und ermöglichen es uns, ETL-Workloads mehr als doppelt so schnell auszuführen und gleichzeitig die Kosten niedrig zu halten. Die Benutzerfreundlichkeit, die automatische Optimierung und die Effizienz von Serverless Compute machen die Skalierung leichter handhabbar und ermöglichen es uns, der Bereitstellung von Mehrwert für unsere Kunden Priorität einzuräumen. —Micaela Christopher, Director of Data Science & Engineering bei Uplight
Früher dauerte der Weg von den Rohdaten zur Silver-Schicht etwa 16 Minuten, aber nach dem Wechsel zu Serverless sind es nur noch etwa 7 Minuten. – Aaron Jepsen, Director IT Betrieb bei Jet Linx Aviation
Die [The] deutliche Verbesserung der Startzeit in Kombination mit geringerem Konfigurations- und Wartungsaufwand für DataOps steigert die Produktivität und Effizienz erheblich. – Gal Doron, Head of Data bei AnyClip
Serverless ist wartungsfrei
Automatische Infrastrukturauswahl: Manuelles Clusters-Management entfällt
Der klassische Ansatz für das Clusters-Management gibt den Benutzern die größte Freiheit bei der Auswahl einer von vielen möglichen Konfigurationskombinationen und der Anpassung der Konfiguration, um den sich im Laufe der Zeit ändernden Daten- und Geschäftsanforderungen gerecht zu werden, einschließlich der Vermeidung von Out-of-Memory-Fehlern oder Performance-Engpässen. Serverless compute verändert die Spielregeln durch eine KI-gestützte Infrastrukturauswahl grundlegend. Das System überwacht kontinuierlich Workload-Muster und die Ressourcennutzung, skaliert bei erkannten Speicherbeschränkungen automatisch auf größere Instanzen hoch und führt bei Ausfällen des Cloud-Anbieters ein nahtloses Failover auf kompatible Instanztypen durch. Durch die Nutzung umfassender Workload-Verlauf und Echtzeit-Performance-Daten trifft das Serverless compute optimale Infrastrukturentscheidungen ohne menschliches Eingreifen, was im Vergleich zu klassischen compute-Umgebungen zu 89 % weniger Ausfällen führt. Dieser automatisierte Ansatz schützt Benutzer nicht nur vor den Einschränkungen der Cloud-Anbieter, sondern ermöglicht auch die automatische Behebung gängiger Infrastrukturprobleme, was Serverless Computing zum stabilsten und zuverlässigsten Computing-Angebot von Databricks macht.
Mit Serverless [...] haben wir eine 3- bis 5-fache Verbesserung der Latenz erreicht. Was früher 10 Minuten dauerte, dauert jetzt nur noch 2–3 Minuten. – Bryce Dugar, Data Engineering Manager bei Cincinnati Reds
Die Verfügbarkeit von Serverless-Optionen erleichtert den Aufwand für Engineering-Wartung und Kostenoptimierung. Dieser Schritt passt nahtlos zu unserer übergeordneten Strategie, alle Pipelines zu Serverless Umgebungen innerhalb von Databricks zu migrieren. – Bala Moorthy, Senior Data Engineering Manager bei Compass
Versionslose Upgrades für automatische Performance- und Sicherheitsverbesserungen
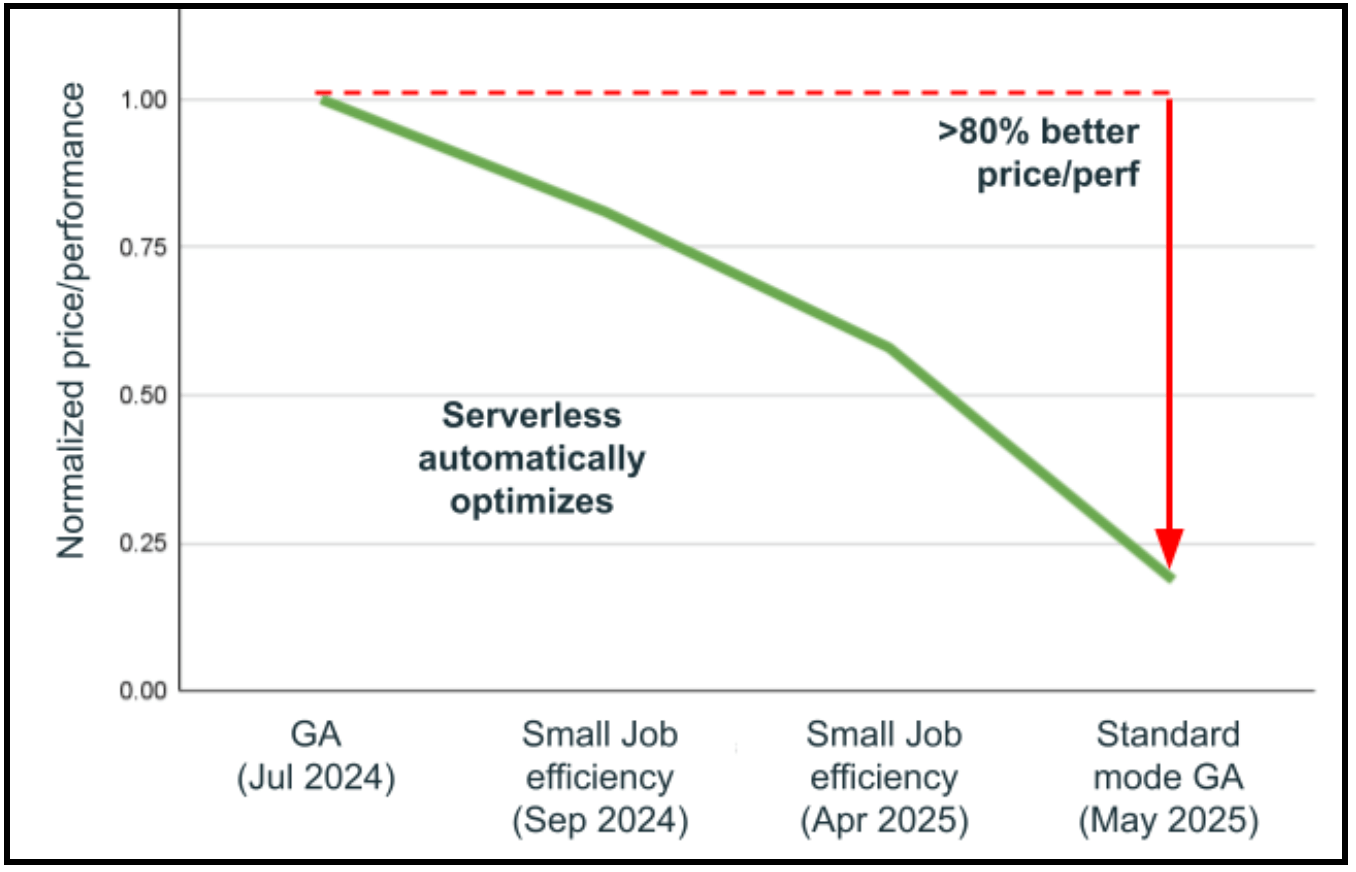
Die vielleicht transformativste Fähigkeit von Serverless-Compute ist seine versionslose Architektur, die manuelle Laufzeit-Upgrades (DBR) überflüssig macht. Die Verwendung der neuesten Laufzeit bringt erhebliche Performance-Verbesserungen mit sich. Serverless-Compute definiert diesen Prozess durch eine revolutionäre Architektur, die einen nahtlosen DBR-Austausch ohne Breaking Changes ermöglicht, grundlegend neu. Allein im letzten Jahr hat Databricks automatisch 25 DBR-Upgrades für mehr als 4,5 Milliarden Workloads mit einer außergewöhnlichen Erfolgsquote von 99,998 % durchgeführt. Selbst in den seltenen Fällen, in denen Probleme erkannt werden, werden die Workloads automatisch auf die vorherige stabile Version zurückgesetzt, während die Probleme im Hintergrund behoben werden, was einen unterbrechungsfreien Betrieb gewährleistet. Die Ergebnisse sprechen für sich: Die Kombination aus Verbesserungen bei der automatischen Infrastrukturauswahl und versionslosen Upgrades hat zu einer um mehr als 80 % besseren Preis-Performance in weniger als einem Jahr geführt, ohne dass Benutzer den Workload anpassen mussten. Dieser versionslose Ansatz bedeutet, dass sich Serverless compute kontinuierlich verbessert und automatisch die neuesten Spark-Optimierungen, Sicherheitspatches und Performanceverbesserungen bereitstellt, während sich Data-Engineering-Teams voll und ganz auf die Schaffung von Geschäftswert konzentrieren, anstatt Infrastruktur-Upgrades zu verwalten.
Weitere Serverless-Features
Serverless-Compute bietet jetzt ein umfassendes Set an erweiterten Funktionen, darunter:
- Workspace-basierte Umgebungen ermöglichen es Administratoren, Benutzerumgebungen mit automatischem Caching für einen schnellen Startup zentral zu verwalten.
- Die Unterstützung für Scala-Jobs ermöglicht die lokale IDE-Entwicklung mit Fat-JAR-Deployment-Funktionen.
- GPU-Unterstützung, einschließlich A10s und H100s, und die Unterstützung von SparkML öffnen Serverless für Machine-Learning- und GenAI-Workloads.
- Die Möglichkeit zum Anhalten und Fortsetzen erleichtert die Entwicklung und das Debugging erheblich, da Snapshots des aktuellen compute-Zustände erstellt und die Arbeit später ohne Arbeitsverlust fortgesetzt werden kann, ohne für clusters bezahlen zu müssen.
- Zu den erweiterten Kostenmanagement-Features gehören Ratenbegrenzungen (in Kürze verfügbar), die Vorhersage der Abfrage-Laufzeit mit Warnungen und erweiterte Systemtabellen für eine detaillierte Kostenanalysen.
Diese Ergänzungen stärken die Position des Serverless Compute als die leistungsfähigste und intelligenteste Compute-Plattform für Data Engineering – und wir fangen gerade erst an.
Beginnen Sie Ihre Serverless-Reise noch heute
Die Beweise sind überzeugend – Serverless compute stellt die endgültige Weiterentwicklung der Dateninfrastruktur dar und bietet beispiellose Einfachheit, Zuverlässigkeit und Performanceoptimierung. Da der Standardmodus jetzt allgemein verfügbar ist und Kosteneinsparungen von bis zu 70 % bietet, gab es nie einen besseren Zeitpunkt für den Übergang von komplexem Cluster-Management zu intelligentem, automatisiertem Compute. Egal, ob Sie die blitzschnelle Ausführung des Performance Optimized Modus oder die Kosteneffizienz des Standardmodus benötigen, Serverless Compute beseitigt die Komplexität der Infrastruktur und verbessert gleichzeitig Ihre Workloads kontinuierlich durch automatische DBR-Upgrades und Leistungssteigerungen.
- Registrieren Sie sich für ein Serverlesses Databricks Account
- Serverless-Compute für Notebooks, Lakeflow Jobs und Spark Declarative Pipelines
- Praxisleitfaden für Serverless Compute
- Einführung in SDP
- SDP-Demo
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.