Verborgene technische Schulden von GenAI-Systemen
Die verborgenen Kosten generativer KI: Bewältigung von Tool-Wildwuchs, intransparenten Pipelines und subjektiven Bewertungen
von Jeanne Choo und Conor Murphy
- Entwickler, die an klassischem ML und generativer KI arbeiten, teilen ihre Zeit sehr unterschiedlich ein
- Generative KI führt neue Formen technischer Schulden ein, die abgebaut werden müssen
- Neue Entwicklungspraktiken müssen eingeführt werden, um diese neuartigen Formen technischer Schulden anzugehen
Einführung
Ein grober Vergleich der Workflows von klassischem machine learning und generativer KI zeigt, dass die allgemeinen Schritte bei beiden ähnlich sind. Beide erfordern Datenerfassung, Feature-Engineering, Modelloptimierung, Deployment, Evaluierung usw., aber die Ausführungsdetails und der Zeitaufwand sind fundamental unterschiedlich. Am wichtigsten ist, dass generative KI einzigartige Quellen für technische Schulden einführt, die sich bei unsachgemäßer Verwaltung schnell anhäufen können, darunter:
- Tool-Wildwuchs – Schwierigkeiten bei der Verwaltung und Auswahl von sich stark vermehrenden Agent-Tools
- Prompt-Stuffing – zu komplexe Prompts, die nicht mehr wartbar sind
- Undurchsichtige Pipelines – unzureichendes Tracing erschwert das Debugging
- Unzureichende Feedbacksysteme – die menschliches Feedback nicht effektiv erfassen und nutzen
- Ungenügende Einbindung von Stakeholdern – keine regelmäßige Kommunikation mit Endnutzern
In diesem Blog befassen wir uns nacheinander mit jeder Form der technischen Schuld. Letztendlich müssen sich Teams, die von klassischem ML zu generativer KI übergehen, dieser neuen Quellen technischer Schuld bewusst sein und ihre Entwicklungspraktiken entsprechend anpassen – indem sie mehr Zeit für Evaluierung, Stakeholder-Management, subjektive Qualitätsüberwachung und Instrumentierung aufwenden statt für die Datenbereinigung und das Feature-Engineering, die klassische ML-Projekte dominierten.
Wie unterscheiden sich die Workflows für klassisches maschinelles Lernen (ML) und generative künstliche Intelligenz (KI)?
Um zu verstehen, wo das Fachgebiet heute steht, ist es nützlich, unsere Workflows für generative KI mit denen zu vergleichen, die wir für klassische Probleme des maschinellen Lernens verwenden. Das Folgende ist ein allgemeiner Überblick. Wie dieser Vergleich zeigt, bleiben die allgemeinen Workflow-Schritte zwar gleich, es gibt jedoch Unterschiede in den Ausführungsdetails, die dazu führen, dass verschiedene Schritte stärker betont werden. Wie wir sehen werden, führt die generative KI auch neue Formen der technischen Schuld ein, was Auswirkungen darauf hat, wie wir unsere Systeme in der Produktion warten.
| Workflow-Schritt | Klassisches ML | GenAI |
|---|---|---|
| Datenerfassung | Gesammelte Daten stellen reale Ereignisse dar, wie zum Beispiel Vertrieb im Einzelhandel oder Geräteausfälle. Häufig werden strukturierte Formate wie CSV und JSON verwendet. | Gesammelte Daten stellen kontextuelles Wissen dar, das einem Sprachmodell hilft, relevante Antworten zu geben. Sowohl strukturierte Daten (oft in Echtzeittabellen) als auch unstrukturierte Daten (Bilder, Videos, Textdateien) können verwendet werden. |
| Feature-Engineering/ Datentransformation | Datentransformationsschritte umfassen entweder die Erstellung neuer Features, um den Problembereich besser abzubilden (z. B. die Erstellung von Wochentags- und Wochenend-Features aus Zeitstempeldaten), oder die Durchführung statistischer Transformationen, damit Modelle besser zu den Daten passen (z. B. die Standardisierung kontinuierlicher Variablen für das k-Means-Clustering und die Durchführung einer logarithmischen Transformation von schiefverteilten Daten, damit diese einer Normalverteilung folgen). | Bei unstrukturierten Daten umfasst die Transformation das Chunking, die Erstellung von Einbettungsdarstellungen und (möglicherweise) das Hinzufügen von Metadaten wie Überschriften und Tags zu den Chunks. Bei strukturierten Daten kann dies die Denormalisierung von Tabellen umfassen, sodass große Sprachmodelle (LLMs) keine Tabellen-Joins berücksichtigen müssen. Das Hinzufügen von Metadatenbeschreibungen für Tabellen und Spalten ist ebenfalls wichtig. |
| Modell-Pipeline-Design | Wird in der Regel durch eine grundlegende Pipeline mit drei Schritten abgedeckt:
| Normalerweise umfasst dies einen Schritt zur Umschreibung von Abfragen, eine Form des Information Retrieval, möglicherweise Tool-Aufrufe und abschließende Sicherheitsprüfungen. Pipelines sind wesentlich komplexer, umfassen eine komplexere Infrastruktur wie Datenbanken und API-Integrationen und werden manchmal mit graphenartigen Strukturen gehandhabt. |
| Modelloptimierung | Die Modelloptimierung umfasst das Hyperparameter-Tuning mithilfe von Methoden wie Kreuzvalidierung, Grid-Search und Random-Search. | Während einige Hyperparameter wie Temperatur, Top-k und Top-p geändert werden können, fließt der größte Aufwand in das Tuning von Prompts, um das Verhalten des Modells zu steuern. Da eine LLM-Kette viele Schritte umfassen kann, kann ein KI-Ingenieur auch damit experimentieren, eine komplexe Operation in kleinere Komponenten aufzuteilen. |
| Fragen zur Bereitstellung | Modelle sind viel kleiner als Foundation-Modelle wie LLMs. Ganze ML-Anwendungen können auf einer CPU gehostet werden, ohne dass GPUs benötigt werden. Modellversionierung, Monitoring und Lineage sind wichtige Aspekte. Modellvorhersagen erfordern selten komplexe Ketten oder Graphen, daher werden Traces in der Regel nicht verwendet. | Da Foundation-Modelle sehr groß sind, können sie auf einer zentralen GPU gehostet und als API für mehrere KI-Anwendungen für Benutzer bereitgestellt werden. Diese Anwendungen fungieren als „Wrapper“ um die API des Foundation-Modells und werden auf kleineren CPUs gehostet. Anwendungsversionsverwaltung, Monitoring und Herkunftsnachverfolgung sind wichtige Aspekte. Da LLM-Ketten und -Graphen komplex sein können, ist zudem ein ordnungsgemäßes Tracing erforderlich, um Abfrageengpässe und Fehler zu identifizieren. |
| Bewertung | Für die Modelleistung können Data Scientists definierte quantitative Metriken wie den F1-Score für die Klassifizierung oder die Wurzel des mittleren quadratischen Fehlers für die Regression verwenden. | Die Korrektheit einer LLM-Ausgabe beruht auf subjektiven Beurteilungen, z. B. der Qualität einer Zusammenfassung oder Übersetzung. Daher wird die Antwortqualität in der Regel anhand von Richtlinien statt quantitativer Metriken beurteilt. |
Wie teilen Machine-Learning-Entwickler ihre Zeit in GenAI-Projekten anders ein?
Aus eigener Erfahrung bei der parallelen Bearbeitung eines Preisvorhersageprojekts und eines Projekts zur Erstellung eines Tool-aufrufenden Agenten haben wir festgestellt, dass es einige wesentliche Unterschiede in den Schritten der Modellentwicklung und -bereitstellung gibt.
Modellentwicklungszyklus
Die innere Entwicklungsschleife bezieht sich typischerweise auf den iterativen Prozess, den Entwickler für maschinelles Lernen beim Erstellen und Verfeinern ihrer Modellpipelines durchlaufen. Dies geschieht in der Regel vor den Produktionstests und der Modellbereitstellung.
So verbringen Fachleute für klassisches ML und GenAI ihre Zeit in diesem Schritt unterschiedlich:
Zeitfresser bei der Entwicklung klassischer ML-Modelle
- Datensammlung und Feature-Verfeinerung: Bei einem klassischen Machine-Learning-Projekt wird die meiste Zeit für die iterative Verfeinerung von Features und Eingabedaten aufgewendet. Ein Tool zur Verwaltung und zum Teilen von Features, wie z. B. der Databricks Feature Store, wird verwendet, wenn viele Teams beteiligt sind oder zu viele Features vorhanden sind, um sie einfach manuell zu verwalten.
Im Gegensatz dazu ist die Evaluierung unkompliziert: Sie führen Ihr Modell aus und prüfen, ob sich Ihre quantitativen Metriken verbessert haben, bevor Sie sich dann damit befassen, wie eine bessere Datenerfassung und bessere Features das Modell verbessern können. Im Fall unseres Preisvorhersagemodells hat unser Team beispielsweise festgestellt, dass die meisten Fehlprognosen darauf zurückzuführen waren, dass Daten-Ausreißer nicht berücksichtigt wurden. Wir mussten uns dann überlegen, wie wir Features einbeziehen können, die diese Ausreißer repräsentieren, damit das Modell diese Muster erkennen kann.
Zeitfresser bei der Entwicklung von generativen KI-Modellen und Pipelines
- Bewertung: Bei einem Projekt für generative KI ist der relative Zeitaufwand zwischen Datenerfassung und -transformation und der Bewertung umgekehrt. Die Datenerfassung umfasst typischerweise das Sammeln von ausreichend Kontext für das Modell, der in Form von unstrukturierten Wissensdatenbank-Dokumenten oder Handbüchern vorliegen kann. Diese Daten erfordern keine umfangreiche Bereinigung. Die Bewertung ist jedoch wesentlich subjektiver und komplexer und folglich auch zeitaufwändiger. Sie iterieren nicht nur die Modell-Pipeline, sondern müssen auch Ihr Bewertungsset iterieren. Und es wird mehr Zeit für die Berücksichtigung von Edge Cases aufgewendet als bei klassischem ML.
Zum Beispiel deckt ein anfänglicher Satz von 10 Bewertungsfragen möglicherweise nicht das gesamte Spektrum an Fragen ab, die ein Benutzer einem Support-Bot stellen könnte. In diesem Fall müssen Sie weitere Bewertungen sammeln, oder die von Ihnen eingerichteten LLM-Juroren sind möglicherweise zu streng, sodass Sie deren Prompts umformulieren müssen, um zu verhindern, dass relevante Antworten bei den Tests fehlschlagen. Die Evaluation Datasets von MLflow sind nützlich für die Versionierung, Entwicklung und Prüfung eines „Golden Set“ von Beispielen, die immer korrekt funktionieren müssen. - Stakeholder-Management: Da die Antwortqualität von den Eingaben der Endnutzer abhängt, verbringen Ingenieure zudem viel mehr Zeit mit Besprechungen mit Endnutzern aus den Fachbereichen und Produktmanagern, um Anforderungen zu erfassen und zu priorisieren sowie auf Grundlage von Benutzerfeedback zu iterieren. Historisch gesehen war klassisches ML oft nicht allgemein auf Endbenutzer ausgerichtet (z. B. Zeitreihenprognosen) oder war für nicht-technische Benutzer weniger sichtbar, weshalb die Anforderungen an das Produktmanagement für generative KI viel höher sind. Das Sammeln von Feedback zur Antwortqualität kann über eine einfache Benutzeroberfläche erfolgen, die auf Databricks Apps gehostet wird und die MLflow Feedback API aufruft. Das Feedback kann dann zu einem MLflow Trace und einem MLflow Evaluation Dataset hinzugefügt werden, wodurch ein positiver Kreislauf zwischen Feedback und Modellverbesserung entsteht.
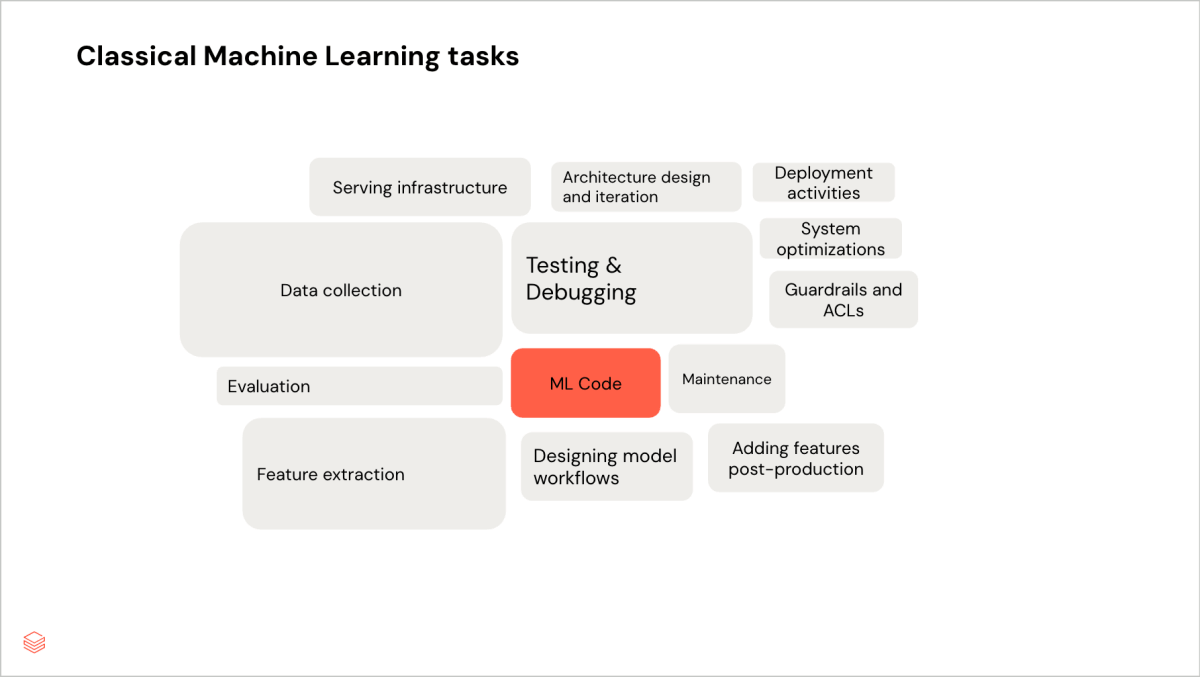
Die folgenden Diagramme vergleichen den Zeitaufwand für klassisches ML und generative KI im Modellentwicklungszyklus.

Modell-Deployment-Zyklus
Im Gegensatz zum Modellentwicklungszyklus konzentriert sich der Modellbereitstellungszyklus nicht auf die Optimierung der Performance. Stattdessen konzentrieren sich die Ingenieure auf systematische Tests, die Bereitstellung und das Monitoring in Produktionsumgebungen.
Hier könnten Entwickler Konfigurationen in YAML-Dateien verschieben, um Projektaktualisierungen zu vereinfachen. Sie könnten auch Pipelines für die statische Datenverarbeitung refaktorisieren, um sie im Streaming-Verfahren auszuführen, und dabei ein robusteres Framework wie PySpark anstelle von Pandas verwenden. Schließlich müssen sie überlegen, wie sie Test-, Monitoring- und Feedbackprozesse einrichten, um die Modellqualität zu erhalten.
An diesem Punkt ist die Automatisierung unerlässlich, und kontinuierliche Integration und Bereitstellung ist eine nicht verhandelbare Anforderung. Für die Verwaltung von CI/CD für Daten- und KI-Projekte auf Databricks sind Databricks Asset Bundles in der Regel das Mittel der Wahl. Sie ermöglichen es, Databricks-Ressourcen (wie z. B. Jobs und Pipelines) als Quelldateien zu beschreiben, und bieten eine Möglichkeit, Metadaten zusammen mit den Quelldateien Ihres Projekts einzuschließen.
Wie in der Phase der Modellentwicklung sind die Aktivitäten, die in dieser Phase bei Projekten mit generativer KI im Vergleich zu klassischen ML-Projekten die meiste Zeit in Anspruch nehmen, nicht dieselben.
Zeitfresser bei der Bereitstellung klassischer ML-Modelle
- Refactoring: In einem Projekt für klassisches maschinelles Lernen kann der Notebook-Code ziemlich unordentlich sein. Verschiedene Kombinationen von Datasets, Features und Modellen werden kontinuierlich getestet, verworfen und neu kombiniert. Daher muss möglicherweise erheblicher Aufwand für das Refactoring von Notebook-Code betrieben werden, um ihn robuster zu machen. Eine festgelegte Ordnerstruktur für das Code-Repository (wie die Databricks Asset Bundles MLOps Stacks-Vorlage) kann das für diesen Refactoring-Prozess erforderliche Gerüst bereitstellen.
Einige Beispiele für Refactoring-Aktivitäten sind:- Hilfscode in Funktionen auslagern
- Erstellen von Bibliotheken, damit Dienstprogrammfunktionen importiert und mehrfach wiederverwendet werden können
- Auslagern von Konfigurationen aus Notebooks in YAML-Dateien
- Erstellen effizienterer Code-Implementierungen, die schneller und effizienter ausgeführt werden (z. B. durch Entfernen verschachtelter
for-Schleifen)
- Qualitäts-Monitoring: Das Qualitäts-Monitoring ist ein weiterer Zeitfresser, da Datenfehler viele Formen annehmen können und schwer zu erkennen sind. Insbesondere, wie Shreya Shankar et al. in ihrem Paper „Operationalizing Machine Learning: An Interview Study“ feststellen, sind „weiche Fehler, wie z. B. einige Features mit Nullwerten in einem Datenpunkt, weniger schädlich und können dennoch vernünftige Vorhersagen liefern, was es schwierig macht, sie zu erfassen und zu quantifizieren.“ Zudem erfordern verschiedene Arten von Fehlern unterschiedliche Reaktionen, und die Bestimmung der geeigneten Reaktion ist nicht immer einfach.
Eine zusätzliche Herausforderung besteht darin, dass verschiedene Arten von Modelldrift (wie Feature-Drift, Datendrift und Label-Drift) über verschiedene Zeitgranularitäten (täglich, wöchentlich, monatlich) gemessen werden müssen, was die Komplexität erhöht. Um den Prozess zu vereinfachen, können Entwickler Databricks Data Quality Monitoring verwenden, um Metriken zur Modellqualität, die Qualität der Eingabedaten und die potenzielle Drift von Modelleingaben und Vorhersagen in einem ganzheitlichen Framework zu verfolgen.
Zeitfresser beim Deployment von generativen KI-Modellen
- Qualitäts-Monitoring: Bei generativer KI nimmt das Monitoring ebenfalls einen erheblichen Teil der Zeit in Anspruch, jedoch aus anderen Gründen:
- Echtzeitanforderungen: Klassische Machine-Learning-Projekte für wie die Abwanderungsvorhersage, Preisprognosen oder die Wiederaufnahme von Patienten können Vorhersagen im Batch-Modus bereitstellen und werden vielleicht einmal am Tag, einmal pro Woche oder einmal pro Monat ausgeführt. Viele Projekte im Bereich der generativen KI sind jedoch Echtzeitanwendungen wie virtuelle Support-Agenten, Live-Transkriptions-Agenten oder Programmier-Agenten. Folglich müssen Echtzeit-Monitoring-Tools konfiguriert werden, was Echtzeit-Endpunktüberwachung, Echtzeit-Inferenzanalysen-Pipelines und Echtzeit-Alarmierung bedeutet.
Die Einrichtung von API-Gateways (wie Databricks AI Gateway) zur Durchführung von Guardrail-Prüfungen auf der LLM-API kann die Anforderungen an Sicherheit und Datenschutz unterstützen. Dies ist ein anderer Ansatz als das herkömmliche Modell-Monitoring, das als Offline-Prozess durchgeführt wird. - Subjektive Bewertungen: Wie bereits erwähnt, sind Bewertungen für generative KI-Anwendungen subjektiv. Model-Deployment-Ingenieure müssen überlegen, wie die Erfassung von subjektivem Feedback in ihren Inferenz-Pipelines operationalisiert werden kann. Dies kann in Form von LLM-Judge-Bewertungen, die auf Modellantworten ausgeführt werden, oder der Auswahl einer Teilmenge von Modellantworten geschehen, die einem Fachexperten zur Bewertung vorgelegt wird. Anbieter proprietärer Modelle optimieren ihre Modelle im Laufe der Zeit, sodass ihre „Modelle“ eigentlich Dienste sind, die anfällig für Regressionen sind, und die Bewertungskriterien müssen berücksichtigen, dass die Modellgewichtungen nicht wie bei selbst trainierten Modellen eingefroren sind.
Die Möglichkeit, formfreies Feedback und subjektive Bewertungen abzugeben, rückt in den Mittelpunkt. Frameworks wie Databricks Apps und die MLflow Feedback API ermöglichen einfachere Benutzeroberflächen, die solches Feedback erfassen und mit bestimmten LLM-Aufrufen verknüpfen können.
- Echtzeitanforderungen: Klassische Machine-Learning-Projekte für wie die Abwanderungsvorhersage, Preisprognosen oder die Wiederaufnahme von Patienten können Vorhersagen im Batch-Modus bereitstellen und werden vielleicht einmal am Tag, einmal pro Woche oder einmal pro Monat ausgeführt. Viele Projekte im Bereich der generativen KI sind jedoch Echtzeitanwendungen wie virtuelle Support-Agenten, Live-Transkriptions-Agenten oder Programmier-Agenten. Folglich müssen Echtzeit-Monitoring-Tools konfiguriert werden, was Echtzeit-Endpunktüberwachung, Echtzeit-Inferenzanalysen-Pipelines und Echtzeit-Alarmierung bedeutet.
- Testen: Das Testen ist bei Anwendungen mit generativer KI aus mehreren Gründen oft zeitaufwändiger:
- Ungelöste Herausforderungen: Anwendungen der generativen KI selbst werden immer komplexer, aber die Evaluierungs- und Test-Frameworks halten noch nicht Schritt. Einige Szenarien, die das Testen erschweren, sind:
- Lange Konversationen mit mehreren Durchgängen
- SQL-Ausgabe, die wichtige Details über den organisatorischen Kontext eines Unternehmens erfassen kann oder auch nicht.
- Die Berücksichtigung der Verwendung der richtigen Tools in einer Kette.
- Evaluierung mehrerer Agenten in einer Anwendung
Der erste Schritt beim Umgang mit dieser Komplexität besteht in der Regel darin, einen Trace der Agentenausgabe (einen Ausführungsverlauf von Tool-Aufrufen, Schlussfolgerungen und der endgültigen Antwort) so genau wie möglich zu erfassen. Eine Kombination aus automatischer Trace-Erfassung und manueller Instrumentierung kann die erforderliche Flexibilität bieten, um die gesamte Bandbreite der Agenteninteraktionen abzudecken. Zum Beispiel kann der MLflow Tracestrace-Decorator für jede Funktion verwendet werden, um ihre Ein- und Ausgaben zu erfassen. Gleichzeitig können benutzerdefinierte MLflow Traces Spans innerhalb bestimmter Codeblöcke erstellt werden, um granularere Vorgänge zu protokollieren. Erst nachdem Entwickler mithilfe von Instrumentierung eine zuverlässige Wahrheitsquelle aus den Agentenausgaben aggregiert haben, können sie damit beginnen, Fehlermodi zu identifizieren und entsprechende Tests zu entwerfen.
- Menschliches Feedback einbeziehen: Es ist entscheidend, dieses Feedback bei der Qualitätsbewertung zu berücksichtigen. Aber einige Aktivitäten sind zeitaufwendig. Zum Beispiel:
- Entwerfen von Bewertungsrastern, damit Annotatoren Richtlinien haben, an die sie sich halten können
- Entwerfen verschiedener Metriken und Judges für unterschiedliche Szenarien (z. B. ob eine Ausgabe sicher oder hilfreich ist)
Persönliche Diskussionen und Workshops sind in der Regel erforderlich, um eine gemeinsame Rubrik für die erwartete Reaktion eines Agenten zu erstellen. Erst nachdem menschliche Annotatoren aufeinander abgestimmt sind, können ihre Bewertungen zuverlässig in LLM-basierte Judges integriert werden, indem Funktionen wie diemake_judge-API von MLflow oder derSIMBAAlignmentOptimizerverwendet werden.
- Ungelöste Herausforderungen: Anwendungen der generativen KI selbst werden immer komplexer, aber die Evaluierungs- und Test-Frameworks halten noch nicht Schritt. Einige Szenarien, die das Testen erschweren, sind:
Technische Schulden der KI
Technische Schulden entstehen, wenn Entwickler eine schnelle und unsaubere Lösung auf Kosten der langfristigen Wartbarkeit implementieren.
Technische Schulden bei klassischem ML
Dan Sculley et al. haben eine hervorragende Zusammenfassung der Arten von technischen Schulden geliefert, die diese Systeme anhäufen können. In ihrem Paper „Machine Learning: Die hochverzinsliche Kreditkarte der technischen Schulden“ teilen sie diese in drei große Bereiche auf:
- Datenschulden – Datenabhängigkeiten, die schlecht dokumentiert, nicht erfasst sind oder sich unbemerkt ändern
- Schulden auf Systemebene Umfangreicher Glue-Code, Pipeline-„Dschungel“ und „tote“ hartcodierte Pfade
- Externe Änderungen Geänderte Thresholds (wie der Precision-Recall-Threshold) oder die Entfernung zuvor wichtiger Korrelationen
Generative KI führt neue Formen technischer Schulden ein, von denen viele möglicherweise nicht offensichtlich sind. Dieser Abschnitt untersucht die Quellen dieser versteckten technischen Schulden.
Tool-Wildwuchs
Tools sind eine leistungsstarke Möglichkeit, die Fähigkeiten eines LLM zu erweitern. Wenn jedoch die Anzahl der verwendeten Tools zunimmt, kann es schwierig werden, sie zu verwalten.
Ein Tool-Wildwuchs stellt nicht nur ein Problem bei der Auffindbarkeit und Wiederverwendung dar, sondern kann sich auch negativ auf die Qualität eines generativen KI-Systems auswirken. Wenn sich die Tools unkontrolliert vermehren, treten zwei zentrale Fehlerquellen auf:
- Tool-Auswahl: Das LLM muss aus einer Vielzahl von Tools das richtige für den Aufruf korrekt auswählen können. Wenn Tools ungefähr ähnliche Aufgaben erledigen, wie z. B. das Aufrufen von Daten-APIs für wöchentliche im Vergleich zu monatlichen Vertriebsstatistiken, wird es schwierig sicherzustellen, dass das richtige Tool aufgerufen wird. LLMs werden starten, Fehler zu machen.
- Tool-Parameter: Selbst nach der erfolgreichen Auswahl des richtigen aufzurufenden Tools muss ein LLM immer noch in der Lage sein, die Frage eines Nutzers in den korrekten Satz von Parametern zu parsen, die an das Tool übergeben werden. Dies ist eine weitere Fehlerquelle, die es zu berücksichtigen gilt, und es wird besonders schwierig, wenn mehrere Tools ähnliche Parameterstrukturen haben.
Die sauberste Lösung gegen einen Tool-Wildwuchs ist ein strategischer und minimalistischer Umgang mit den vom Team genutzten Tools.
Mit der richtigen Governance-Strategie lässt sich jedoch die Verwaltung mehrerer Tools und Zugriffe skalierbar gestalten, wenn immer mehr Teams GenAI in ihre Projekte und Systeme integrieren. Die Databricks-Produkte Unity Catalog und KI Gateway sind für diese Art von Scale ausgelegt.
Prompt Stuffing
Obwohl hochmoderne Modelle seitenlange Anweisungen verarbeiten können, können übermäßig komplexe Prompts zu Problemen wie widersprüchlichen Anweisungen oder veralteten Informationen führen. Dies ist insbesondere der Fall, wenn Prompts nicht bearbeitet, sondern im Laufe der Zeit von verschiedenen Fachexperten oder Entwicklern nur erweitert werden.
Wenn verschiedene Fehlermodi auftreten oder neue Abfragen zum Umfang hinzugefügt werden, ist es verlockend, einfach immer mehr Anweisungen zu einem LLM-Prompt hinzuzufügen. Ein Prompt könnte beispielsweise mit Anweisungen zur Bearbeitung von Finanzfragen beginnen und dann zu Fragen in den Bereichen Produkt, Engineering und Personalwesen verzweigen.
So wie eine „God Class“ im Software-Engineering keine gute Idee ist und aufgeteilt werden sollte, sollten auch Mega-Prompts in kleinere aufgeteilt werden. Tatsächlich erwähnt Anthropic dies in seinem Leitfaden für Prompt-Engineering, und generell gilt, dass mehrere kleinere Prompts anstelle eines langen, komplexen Prompts die Übersichtlichkeit, Genauigkeit und die Fehlerbehebung erleichtern.
Frameworks können helfen, Prompts überschaubar zu halten, indem sie Prompt-Versionen nachverfolgen und erwartete Ein- und Ausgaben erzwingen. Ein Beispiel für ein Tool zur Prompt-Versionierung ist die MLflow Prompt Registry, während Prompt-Optimierer wie DSPy auf Databricks ausgeführt werden können, um einen Prompt in eigenständige Module zu zerlegen, die einzeln oder als Ganzes optimiert werden können.
Intransparente Pipelines
Es gibt einen Grund, warum Tracing in letzter Zeit so viel Aufmerksamkeit erhält: Die meisten LLM-Bibliotheken und Tracking-Tools bieten die Möglichkeit, die Ein- und Ausgaben einer LLM-Kette nachzuverfolgen. Wenn eine Antwort einen Fehler zurückgibt – die gefürchtete Antwort „Es tut mir leid, ich kann Ihre Frage nicht beantworten“ –, ist die Untersuchung der Ein- und Ausgaben von zwischengeschalteten LLM-Aufrufen entscheidend, um die Ursache zu ermitteln.
Ich habe einmal an einer Anwendung gearbeitet, bei der ich anfangs davon ausging, dass die SQL-Generierung der problematischste Schritt des Workflows wäre. Die Untersuchung meiner Traces zeigte jedoch ein anderes Bild: Die größte Fehlerquelle war tatsächlich ein Schritt zur Abfrageumschreibung, bei dem wir Entitäten in der Benutzerfrage in Entitäten aktualisiert haben, die unseren Datenbankwerten entsprachen. Das LLM schrieb Abfragen um, die nicht umgeschrieben werden mussten, oder begann, die ursprüngliche Abfrage mit allen möglichen zusätzlichen Informationen vollzustopfen. Dies brachte dann regelmäßig den nachfolgenden SQL-Generierungsprozess durcheinander. Das Tracing hat hier geholfen, das Problem schnell zu identifizieren.
Die Nachverfolgung der richtigen LLM-Aufrufe kann Zeit in Anspruch nehmen. Es reicht nicht aus, Tracing standardmäßig zu implementieren. Die ordnungsgemäße Instrumentierung einer App mit Observability mithilfe eines Frameworks wie MLflow Traces ist ein erster Schritt, um die Interaktionen von Agents transparenter zu machen.
Unzureichende Systeme zur Erfassung und Nutzung von menschlichem Feedback
LLMs sind bemerkenswert, weil man ihnen ein paar einfache Prompts geben, die Ergebnisse miteinander verketten und am Ende etwas erhalten kann, das Nuancen und Anweisungen wirklich gut zu verstehen scheint. Geht man diesen Weg jedoch zu weit, ohne die Antworten durch Nutzerfeedback zu fundieren, können sich schnell Qualitätsschulden aufbauen. Hier kann es helfen, so schnell wie möglich ein „Data Flywheel“ zu erstellen, das aus drei Schritten besteht:
- Festlegung von Erfolgsmetriken
- Automatisierung der Messung dieser Metriken, etwa durch eine Benutzeroberfläche, die Nutzer verwenden können, um Feedback dazu zu geben, was funktioniert.
- Iteratives Anpassen von Prompts oder Pipelines, um die Metriken zu verbessern
Ich wurde an die Wichtigkeit von menschlichem Feedback erinnert, als ich eine Text-zu-SQL-Anwendung zum Abfrage von Sportstatistiken entwickelte. Der Fachexperte konnte erklären, wie ein Sportfan mit den Daten interagieren möchte, verdeutlichte, was ihnen wichtig ist, und lieferte weitere Einblicke, auf die ich, da ich selten Sport schaue, von selbst nie gekommen wäre. Ohne ihren Input hätte die von mir erstellte Anwendung den Bedürfnissen der Nutzer wahrscheinlich nicht entsprochen.
Obwohl das Erfassen von menschlichem Feedback von unschätzbarem Wert ist, ist es in der Regel extrem zeitaufwendig. Zuerst müssen Termine mit Fachexperten vereinbart, dann Bewertungsschemata zur Abstimmung von Expertenunterschieden erstellt und schließlich das Feedback auf Verbesserungspotenzial ausgewertet werden. Wenn die Feedback-Benutzeroberfläche in einer Umgebung gehostet wird, zu der Geschäftsanwender keinen Zugang haben, kann sich die Abstimmung mit den IT-Administratoren zur Bereitstellung der richtigen Zugriffsebene wie ein endloser Prozess anfühlen.
Entwicklung ohne regelmäßige Abstimmungen mit den Stakeholdern
Die regelmäßige Absprache mit Endnutzern, Business-Sponsoren und angrenzenden Teams, um sicherzustellen, dass man das Richtige entwickelt, ist eine Grundvoraussetzung für alle Arten von Projekten. Bei Projekten mit generativer KI ist die Kommunikation mit den Stakeholdern jedoch entscheidender als je zuvor.
Warum häufige und intensive Kommunikation wichtig ist:
- Verantwortung und Kontrolle: Regelmäßige Meetings helfen Stakeholdern dabei, das Gefühl zu haben, die endgültige Qualität einer Anwendung beeinflussen zu können. Statt Kritiker zu sein, können sie zu Mitwirkenden werden. Natürlich ist nicht jedes Feedback gleichwertig. Einige Stakeholder werden unweigerlich Dinge anfordern, deren Implementierung für ein MVP verfrüht ist oder die außerhalb dessen liegen, was LLMs derzeit bewältigen können. Es ist wichtig, zu verhandeln und alle darüber aufzuklären, was erreicht werden kann und was nicht. Andernfalls kann ein weiteres Risiko auftreten: zu viele ungebremste Feature-Anfragen.
- Wir wissen nicht, was wir nicht wissen: Generative KI ist so neu, dass die meisten Menschen, sowohl technisch versierte als auch nicht-technische, nicht wissen, was ein LLM richtig bewältigen kann und was nicht. Die Entwicklung einer LLM-Anwendung ist eine Lernreise für alle Beteiligten, und regelmäßige Touchpoints sind eine Möglichkeit, alle auf dem Laufenden zu halten.
Es gibt viele andere Formen von technischer Schuld, die in Projekten mit generativer KI möglicherweise angegangen werden müssen, darunter die Durchsetzung angemessener Datenzugriffskontrollen, die Einrichtung von Leitplanken zur Gewährleistung der Sicherheit und zur Verhinderung von Prompt-Injections, die Vermeidung ausufernder Kosten und mehr. Ich habe hier nur diejenigen aufgeführt, die am wichtigsten erscheinen und leicht übersehen werden könnten.
Fazit
Klassisches ML und generative KI sind verschiedene Ausprägungen desselben technischen Bereichs. Es ist zwar wichtig, sich der Unterschiede zwischen ihnen bewusst zu sein und die Auswirkungen dieser Unterschiede auf die Entwicklung und Wartung unserer Lösungen zu berücksichtigen, doch bestimmte Wahrheiten bleiben bestehen: Kommunikation schließt weiterhin Lücken, Monitoring beugt weiterhin Katastrophen vor, und saubere, wartbare Systeme sind auf lange Sicht immer noch leistungsfähiger als chaotische.
Möchten Sie den KI-Reifegrad Ihrer Organisation bewerten? Lesen Sie unseren Leitfaden: KI-Potenzial erschließen: Der Unternehmensleitfaden zur KI-Bereitschaft.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.