Hochverfügbares Feature-Flagging bei Databricks
Wie wir ein Feature-Flag-System ohne Ausfallzeiten für die globale Infrastruktur von Databricks entwickelt haben
von Benjamin Congdon
- SAFE ist die hauseigene Feature-Flagging-Plattform von Databricks, die es Ingenieuren ermöglicht, die Code-Bereitstellung von der Feature-Aktivierung zu entkoppeln, was sicherere Rollouts und eine schnellere Behebung von Vorfällen in Hunderten von Diensten ermöglicht
- Dieser Beitrag beschreibt die Architektur von SAFE, die mithilfe von Techniken wie der Vorabauswertung statischer Dimensionen und der mehrstufigen globalen Bereitstellung mehr als 25.000 aktive Flags und über 300 Millionen Auswertungen pro Sekunde mit einer Latenz im Mikrosekundenbereich verarbeitet.
- Das System erreicht eine hohe Zuverlässigkeit durch mehrschichtige Resilienzmechanismen, einschließlich Fail-Static-Verhalten, Out-of-Band-Bereitstellungspfaden und Cold-Start-Konfigurationsbündeln, die sicherstellen, dass die Dienste selbst bei Ausfällen der Bereitstellungspipeline weiterlaufen.
Schnelle Softwareauslieferung bei gleichzeitiger Zuverlässigkeit ist ein ständiger Balanceakt. Mit dem Wachstum von Databricks ist auch die Komplexität gestiegen, Änderungen sicher über Hunderte von Diensten, mehrere Clouds und Tausende von Kunden-Workloads hinweg auszurollen. Feature-Flags helfen uns, diese Komplexität zu bewältigen, indem sie die Entscheidung zur Anwendung von Code von der Entscheidung zur Aktivierung trennen. Diese Trennung ermöglicht es Entwicklern, Fehler zu isolieren und Vorfälle schneller zu beheben, ohne die Bereitstellungsgeschwindigkeit zu beeinträchtigen.
Eine der Schlüsselkomponenten des Stabilitätskonzepts von Databricks ist unsere hauseigene Plattform für Feature-Flagging und Experimente namens "SAFE". Die Ingenieure von Databricks verwenden SAFE täglich, um Features auszurollen, das Dienstverhalten dynamisch zu steuern und die Wirksamkeit ihrer Features mit A/B-Experimenten zu messen.
Hintergrund
SAFE wurde mit dem "north star"-Ziel gestartet, die Releases von Dienst-Binärdateien vollständig von der Feature-Freischaltung zu entkoppeln, sodass Teams Features unabhängig von ihrem Binary-Deployment ausrollen können. Dies ermöglicht viele zusätzliche Vorteile, wie die Möglichkeit, ein Feature zuverlässig für schrittweise größere Benutzergruppen einzuführen und durch ein Rollout verursachte Vorfälle schnell zu beheben.
Bei der Scale von Databricks, mit Tausenden von Unternehmenskunden in mehreren Clouds und einem schnell wachsenden Produktumfang, benötigten wir ein Feature-Flagging-System, das unsere einzigartigen Anforderungen erfüllen konnte:
- Hohe Standards für Sicherheit und Änderungsmanagement. Das Hauptnutzenversprechen von SAFE war die Verbesserung der Stabilität und der Betriebsbereitschaft von Databricks, woraus sich fast alle anderen Anforderungen ableiteten.
- Multi-Cloud, nahtlose globale Bereitstellung über Azure, AWS und GCP mit Latenzzeiten bei der Flag-Auswertung im Sub-Millisekundenbereich, um Produktionsdienste mit hohem Durchsatz und Latenzempfindlichkeit zu unterstützen.
- Transparenter Support für alle Bereiche, in denen Databricks-Entwickler Code schreiben, einschließlich unserer Steuerungsebene, der Databricks-UI, der Databricks Runtime Environment und der Serverless -Datenebene von Databricks.
- Eine Schnittstelle, die dezidiert genug auf die Release-Praktiken von Databricks ausgelegt war, um gängige Flag-Releases „standardmäßig sicher“ zu machen, aber dennoch flexibel genug, um eine große Anzahl esoterischerer Anwendungsfälle zu unterstützen.
- Extrem hohe Verfügbarkeitsanforderungen, da Dienste ohne geladene Flag-Definitionen nicht sicher gestartet werden können.
Nach sorgfältiger Abwägung dieser Anforderungen haben wir uns letztendlich dafür entschieden, ein eigenes, internes Feature-Flagging-System zu entwickeln. Wir benötigten eine Lösung, die sich mit unserer Architektur weiterentwickeln konnte und die die erforderlichen Governance-Kontrollen bereitstellen würde, um Flags über Hunderte von Diensten und Tausende von Entwicklern hinweg sicher zu verwalten. Um unsere Skalierungs- und Sicherheitsziele erfolgreich zu erreichen, war eine tiefe Integration mit unserem Infrastruktur-Datenmodell, den Service-Frameworks und CI-Systemen erforderlich.
Ende 2025 hat SAFE ungefähr 25.000 aktive Flags und 4.000 wöchentliche Flag-Flips. In Spitzenzeiten führt SAFE über 300 Millionen Auswertungen pro Sekunde aus und hält dabei eine p95-Latenz von ca. 10 μs für Flag-Auswertungen aufrecht.
In diesem Beitrag wird erläutert, wie wir SAFE entwickelt haben, um diese Anforderungen zu erfüllen, und welche Erkenntnisse wir dabei gewonnen haben.
Feature Flags in Aktion
Zum Start besprechen wir eine typische User Journey für ein SAFE-Flag. Im Kern ist ein Feature-Flag eine Variable, auf die im Kontrollfluss eines Dienstes zugegriffen werden kann und die je nach Bedingungen, die von einer externen Konfiguration gesteuert werden, unterschiedliche Werte annehmen kann. Ein sehr häufiger Anwendungsfall für Feature-Flags ist die schrittweise und kontrollierte Aktivierung eines neuen Codepfads, wobei zunächst mit einem kleinen Teil des Traffics begonnen und die Aktivierung dann schrittweise global ausgeweitet wird.
SAFE-Benutzer starten zunächst damit, ihr Flag in ihrem Dienstcode zu definieren und es als bedingtes Gate zur Logik des neuen Features zu verwenden:
Der Benutzer ruft dann die interne SAFE-UI auf, registriert dieses Flag und wählt ein template aus, um sein Flag auszurollen. Diese Vorlage definiert einen schrittweisen Rollout-Plan, der aus einer Liste geordneter Phasen besteht. Jede Phase wird langsam prozentual hochgefahren. Sobald das Flag erstellt wurde, wird dem Benutzer eine Benutzeroberfläche angezeigt, die wie folgt aussieht:
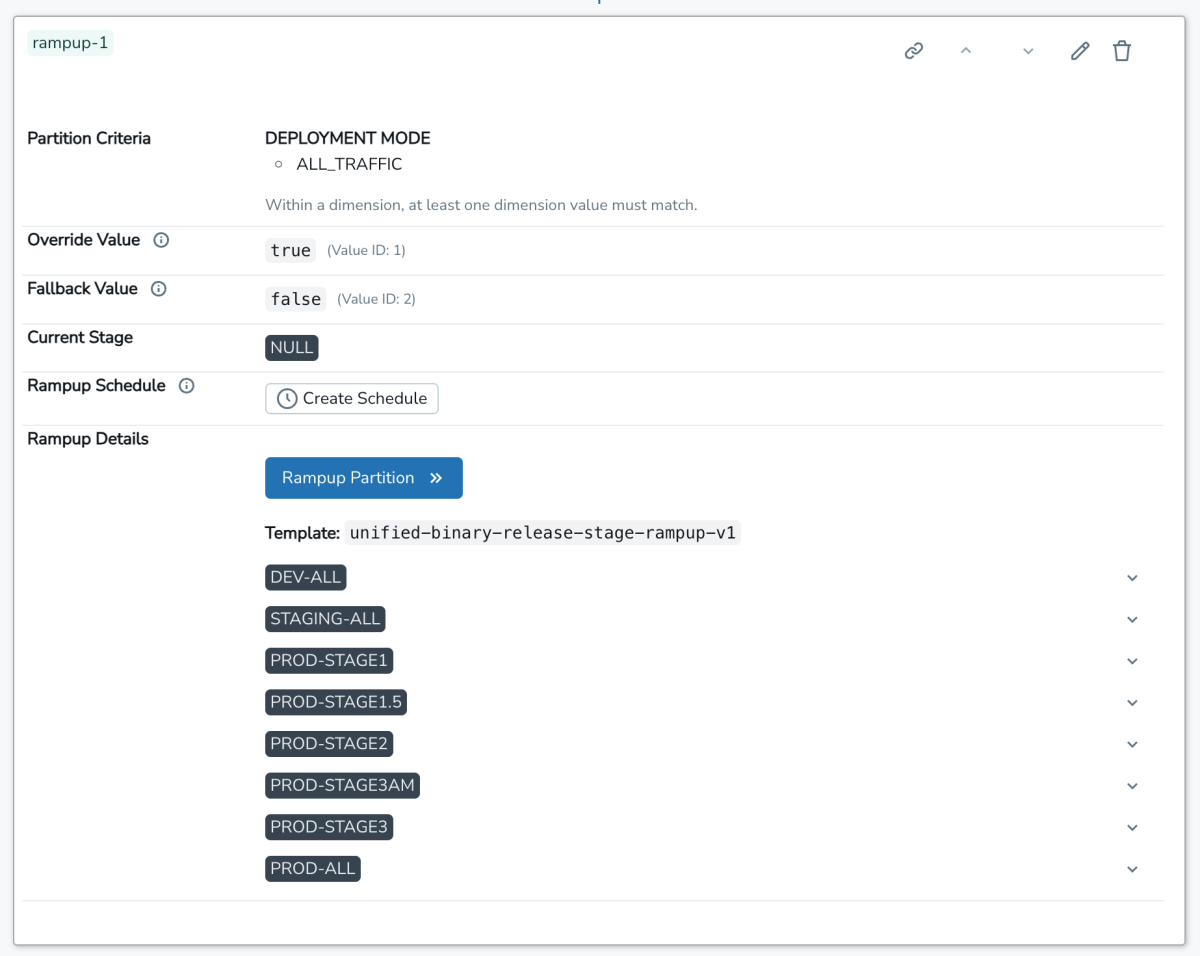
Von hier aus kann der Benutzer sein Flag entweder manuell Stufe für Stufe ausrollen oder einen Schedule einrichten, nach dem die Flag-Flips automatisch für ihn erstellt werden. Intern ist die maßgebliche Quelle für die Flag-Konfiguration eine jsonnet -Datei, die in das Databricks-Monorepo eingecheckt ist und eine schlanke domänenspezifische Sprache (DSL) zur Verwaltung der Flag-Konfiguration verwendet:
Wenn Benutzer ein Flag über die UI ändern, ist das Ergebnis dieser Änderung ein Pull Request, der von mindestens einem anderen Entwickler überprüft werden muss. SAFE führt außerdem eine Vielzahl von Pre-Merge-Prüfungen durch, um sich vor unsicheren oder unbeabsichtigten Änderungen zu schützen. Sobald die Änderung gemergt ist, übernimmt der Dienst des Nutzers die Änderung und beginnt mit der Ausgabe des neuen Werts innerhalb von 2–5 Minuten nach dem Merge des PR.
Anwendungsfälle
Abgesehen von dem oben beschriebenen Anwendungsfall für das Feature-Rollout wird SAFE auch für andere Aspekte der dynamischen Dienstkonfiguration verwendet, wie zum Beispiel: langlebige dynamische Konfigurationen (z. B. Timeouts oder Ratenbegrenzungen), die Steuerung von Zustandsautomaten für Infrastrukturmigrationen oder die Bereitstellung kleiner Konfigurations-Blobs (z. B. gezielte Protokollierungsrichtlinien).
Architektur
Client-Bibliotheken
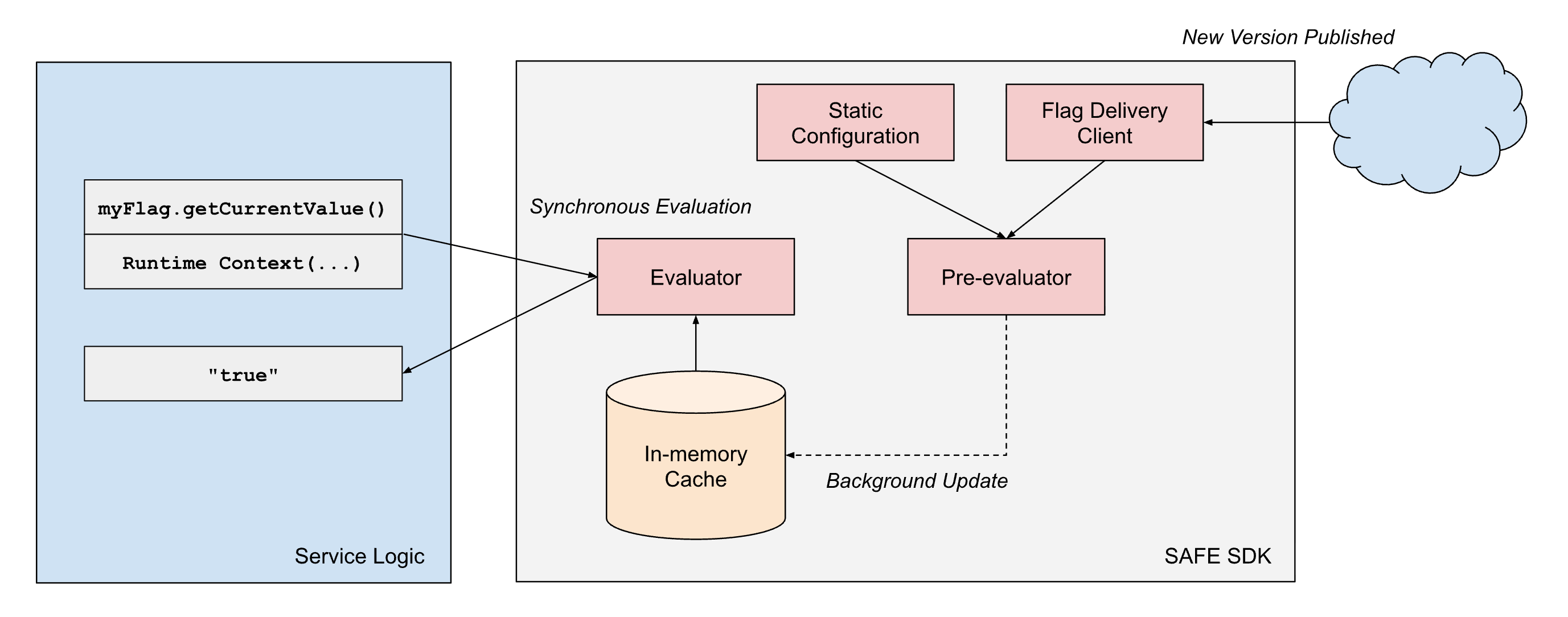
SAFE bietet Client-"SDKs" in mehreren intern unterstützten Sprachen an, wobei das Scala-SDK das ausgereifteste und am weitesten verbreitete ist. Das SDK ist im Wesentlichen eine Bibliothek zur Kriterienauswertung, kombiniert mit einer Komponente zum Laden von Konfigurationen. Für jedes Flag gibt es eine Reihe von Kriterien, die steuern, welchen Wert das SDK zur Laufzeit zurückgeben soll. Das SDK verwaltet das Laden des neuesten Konfigurationssatzes und muss das Ergebnis der Auswertung dieser Kriterien zur Laufzeit schnell zurückgeben.
In Pseudocode sehen die Kriterien intern etwa so aus:
Die Kriterien können als eine Art Sequenz von booleschen Ausdrucksbäumen modelliert werden. Jeder bedingte Ausdruck muss effizient ausgewertet werden, um schnell ein Ergebnis zu liefern.
Um unsere Performance-Anforderungen zu erfüllen, verkörpert das SAFE SDK-Design einige Architekturprinzipien: (1) die Trennung der Konfigurationsbereitstellung von der Auswertung und (2) die Trennung von statischen und Laufzeit-Auswertungsdimensionen.
- Trennung von Bereitstellung und Auswertung: Die SAFE-Clientbibliotheken behandeln die Bereitstellung immer als asynchronen Prozess und blockieren niemals den "Hot Path" der Flag-Auswertung bei der Konfigurationsbereitstellung. Sobald der Client einen Snapshot einer Flag-Konfiguration hat, gibt er weiterhin Ergebnisse auf der Grundlage dieses Snapshots zurück, bis ein asynchroner Hintergrundprozess eine atomare Aktualisierung dieses Snapshots auf einen neueren Snapshot durchführt.
- Trennung der Dimensionstypen: Die Flag-Auswertung in SAFE arbeitet mit zwei Arten von Dimensionen:
- Statische Dimensionen stellen Merkmale der laufenden Binärdatei selbst dar, wie z. B. Cloud-Anbieter, Cloud-Region und Umgebung (Dev/Staging/Prod). Diese Werte bleiben für die gesamte Lebensdauer eines Prozesses konstant.
- Runtime-Dimensionen erfassen anforderungsspezifischen Kontext wie Workspace-IDs, Account-IDs, von der Anwendung bereitgestellte Werte und andere Attribute pro Anforderung, die bei jeder Auswertung variieren.
Um eine Auswertungslatenz im Sub-Millisekundenbereich bei hoher Skalierung zuverlässig zu erreichen, setzt SAFE die Vorauswertung von statischen Teilen des booleschen Ausdrucksbaums ein. Wenn ein SAFE-Konfigurationsbündel an einen Dienst geliefert wird, wertet das SDK sofort alle statischen Dimensionen anhand der In-Memory-Darstellung der Flag-Konfiguration aus. Dies erzeugt einen vereinfachten Konfigurationsbaum, der nur die für diese spezifische Dienstinstanz relevante Logik enthält.
Wenn während der Anforderungsverarbeitung eine Flag-Auswertung angefordert wird, muss das SDK nur die verbleibenden Laufzeitdimensionen anhand dieser vorkompilierten Konfiguration auswerten. Dadurch wird der Rechenaufwand für jede Auswertung erheblich reduziert. Da viele Flags in ihren booleschen Ausdrucksbäumen nur statische Dimensionen verwenden, können viele Flags effektiv vollständig vorab ausgewertet werden.
Flag-Bereitstellung
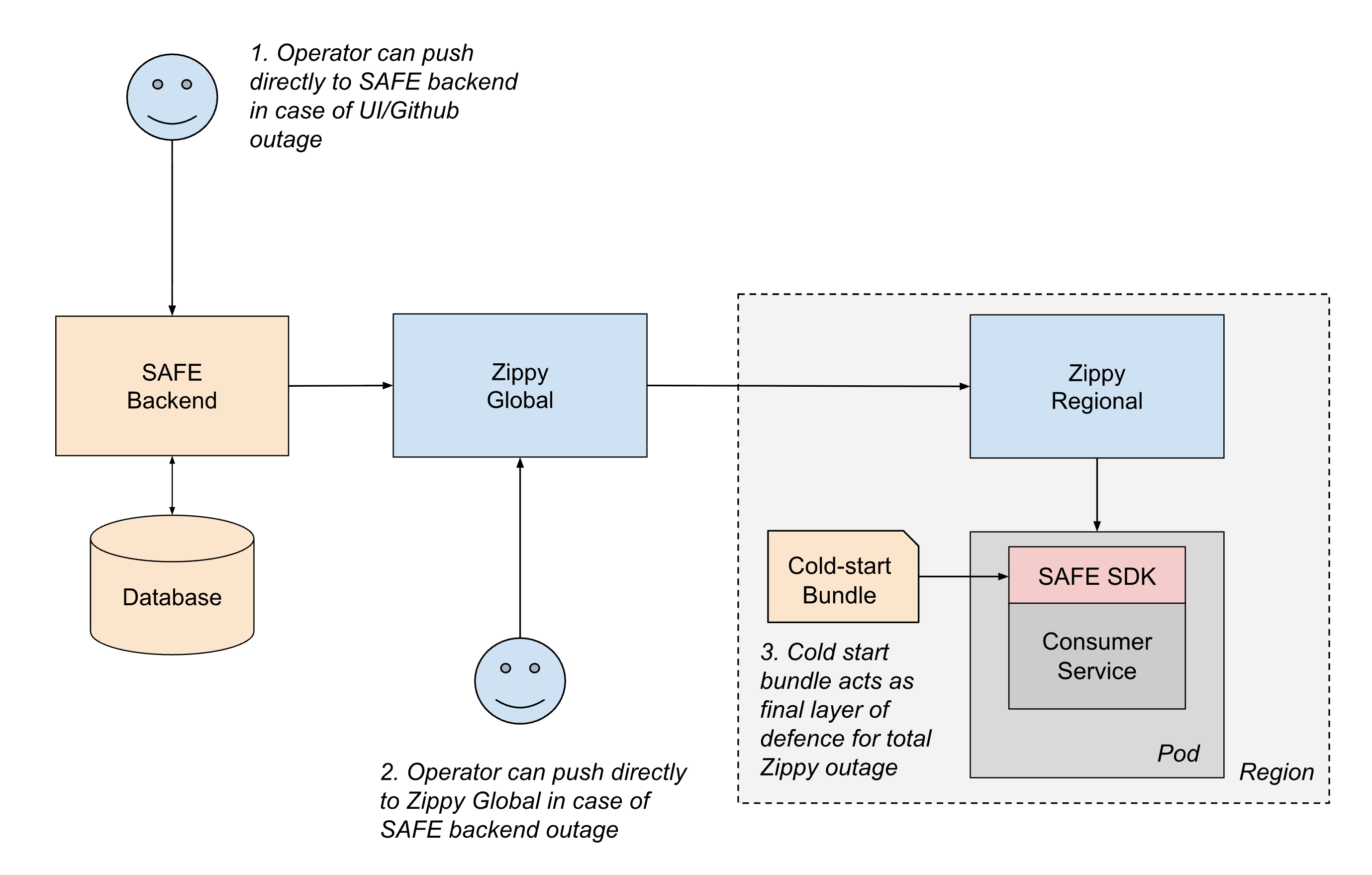
Um Konfigurationen zuverlässig an alle Dienste bei Databricks zu liefern, arbeitet SAFE Hand in Hand mit unserer hauseigenen Plattform für die dynamische Konfigurationsbereitstellung, Zippy. Eine ausführliche Beschreibung der Zippy-Architektur wird in einem anderen Beitrag behandelt, aber kurz gesagt verwendet Zippy eine mehrstufige globale/regionale Architektur und Blob-Speicher pro Cloud, um beliebige Konfigurations-Blobs von einer zentralen Quelle an (unter anderem) alle Kubernetes-Pods zu transportieren, die in der Databricks Control Plane ausgeführt werden.
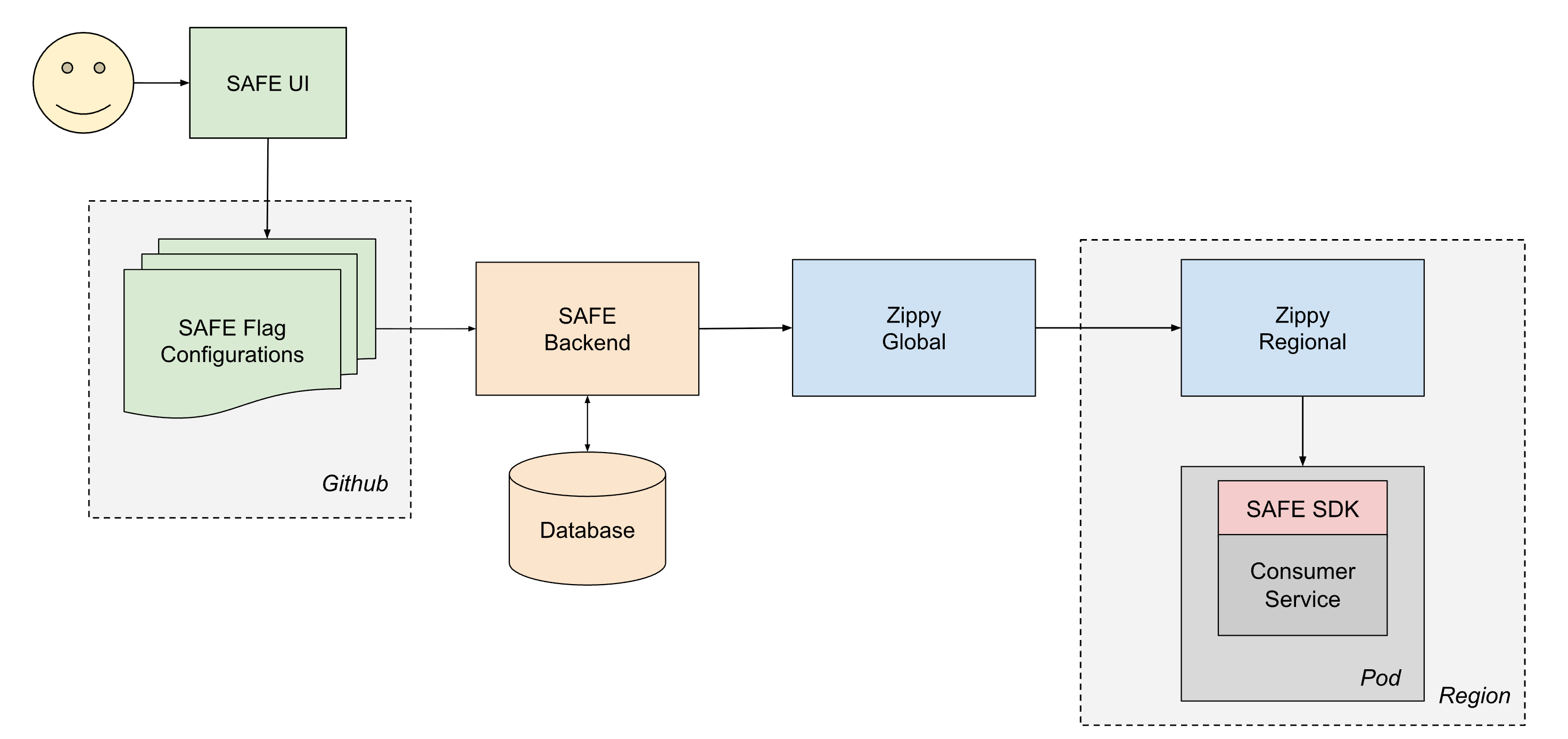
Der Lebenszyklus eines bereitgestellten Flags sieht wie folgt aus:
- Ein Benutzer erstellt und mergt eine PR für eine seiner Jsonnet-Dateien zur Flag-Konfiguration, die dann in das Databricks-Monorepo in Github gemergt wird.
- Innerhalb von ca. 1 Minute erfasst ein Post-Merge-CI-Job die geänderte Datei und sendet sie an das SAFE-Backend, das anschließend eine Kopie der neuen Konfiguration in einer Datenbank speichert.
- In regelmäßigen Abständen (ca. 1-Minuten-Intervalle) bündelt das SAFE-Backend alle SAFE-Flag-Konfigurationen und sendet sie an das Zippy-Global-Backend.
- Zippy Global verteilt diese Konfigurationen innerhalb von ca. 30 Sekunden an jede seiner Zippy Regional-Instanzen.
- Das SAFE SDK, das in jedem Dienst-Pod läuft, empfängt regelmäßig die neuen Versions-Bundles über eine Kombination aus Push- und Pull-basierter Bereitstellung.
- Nach der Bereitstellung kann das SAFE SDK die neue Konfiguration während der Evaluierung verwenden.
End-to-End wird eine Flag-Änderung in der Regel innerhalb von 3 bis 5 Minuten nach dem Merge eines PR an alle Dienste weitergegeben.
Flag-Konfigurations-Pipeline
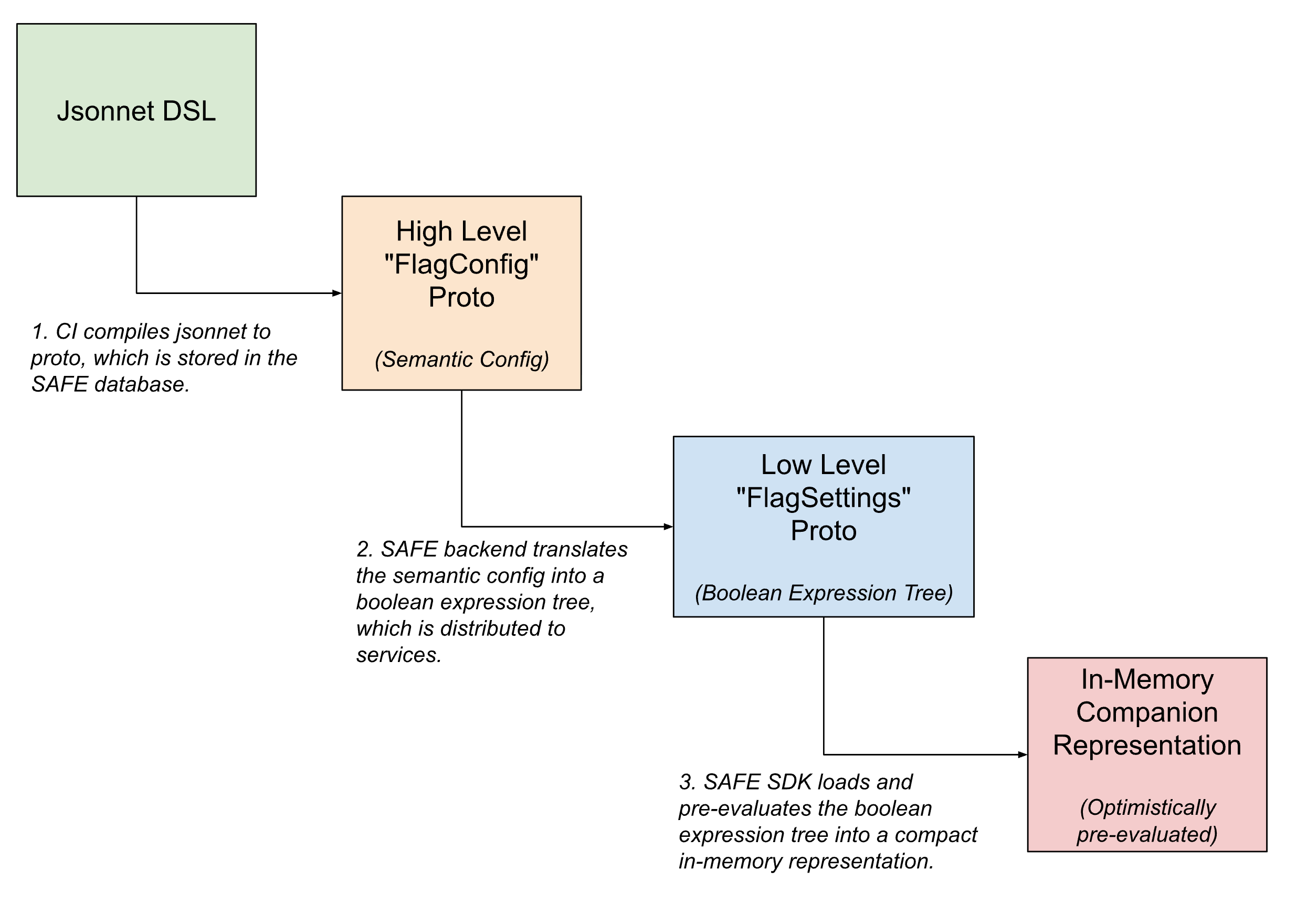
Innerhalb der Flag-Bereitstellungspipeline nehmen die Flag-Konfigurationen mehrere Formen an und werden schrittweise von übergeordneten, für Menschen lesbaren semantischen Konfigurationen in kompakte, maschinenlesbare Versionen übersetzt, je näher das Flag der Auswertung kommt.
In der Benutzeroberfläche werden Flags mit Jsonnet und einer benutzerdefinierten DSL definiert, um beliebig komplizierte Flag-Konfigurationen zu ermöglichen. Diese DSL bietet Möglichkeiten für gängige Anwendungsfälle, wie das Konfigurieren eines Flag-Rollouts mithilfe einer vordefinierten template oder das Festlegen spezifischer Overrides für Teile des Traffics.
Nach dem Einchecken wird diese DSL in ein internes Protobuf-Äquivalent übersetzt, das die semantische Absicht der Konfiguration erfasst. Das SAFE-Backend übersetzt diese semantische Konfiguration dann weiter in einen booleschen Ausdrucksbaum. Eine Protobuf-Beschreibung dieses booleschen Ausdrucksbaums wird an das SAFE SDK übermittelt, das sie in eine weiter komprimierte In-Memory-Darstellung der Konfiguration lädt.
UI
Die meisten Flag-Änderungen werden über eine interne UI zur Verwaltung von SAFE-Flags gestartet. Diese UI ermöglicht es Benutzern, Flags über einen Workflow zu erstellen, zu �ändern und außer Kraft zu setzen, der einen Großteil der Jsonnet-Komplexität für einfache Änderungen abstrahiert, während er für fortgeschrittene Anwendungsfälle weiterhin Zugriff auf den Großteil der vollen Leistungsfähigkeit der DSL bietet.
Eine umfangreiche Benutzeroberfläche hat es uns auch ermöglicht, zusätzliche Komfort-Features anzubieten, wie z. B. die Möglichkeit, Flag-Flips zu schedulen, Unterstützung für Health-Checks nach dem merge und Debugging-Tools zur Ermittlung der letzten Flag-Flips, die sich auf eine bestimmte Region oder einen Dienst ausgewirkt haben.
Überprüfung der Flag-Konfiguration
Alle Änderungen an SAFE-Flags werden als normale Github-PRs erstellt und mithilfe eines umfangreichen Satzes von Pre-Merge-Validatoren validiert. Dieser Satz von Validatoren ist auf Dutzende einzelner Prüfungen angewachsen, da wir gelernt haben, wie wir uns am besten vor potenziell unsicheren Flag-Änderungen schützen können. Während der anfänglichen Einführung von SAFE lieferten Post-Mortem-Analysen von Vorfällen, die entweder durch einen SAFE-Flag-Flip verursacht oder gemindert wurden, die Grundlage für viele dieser Prüfungen. Wir haben jetzt beispielsweise Prüfungen, die eine spezielle Überprüfung bei Änderungen mit großem Wirkungsbereich erfordern, voraussetzen, dass eine bestimmte Version der Dienst-Binärdatei angewendet wird, bevor ein Flag aktiviert werden kann, und subtile, häufige Fehlkonfigurationsmuster verhindern, und so weiter.
Teams können auch ihre eigenen flag- oder teamspezifischen Pre-Merge-Prüfungen definieren, um Invarianten für ihre Konfigurationen zu erzwingen.
Umgang mit Fehlermodi
Angesichts der entscheidenden Rolle von SAFE für die Stabilität der Dienste ist das System mit mehreren Resilienzschichten ausgestattet, um den fortlaufenden Betrieb auch bei Ausfällen von Teilen der Delivery-Pipeline zu gewährleisten.
Das häufigste Fehlerszenario sind Disruptionen auf dem Bereitstellungspfad für Konfigurationen. Falls ein Fehler im Bereitstellungspfad die Aktualisierung der Konfigurationen verhindert, stellen die Dienste einfach weiterhin ihre letzte bekannte Konfiguration bereit, bis der Bereitstellungspfad wiederhergestellt ist. Dieser "Fail-Static"-Ansatz stellt sicher, dass das bestehende Dienstverhalten auch bei vorgelagerten Ausfällen stabil bleibt.
Für schwerwiegendere Szenarien unterhalten wir mehrere Fallback-Mechanismen:
- Out-of-Band-Bereitstellung: Wenn ein Teil des CI- oder Github-Push-Pfads nicht verfügbar ist, können Operatoren Konfigurationen mithilfe von Notfall-Tools direkt in das SAFE-Backend pushen.
- Regionales Failover: Wenn das SAFE-Backend oder Zippy Global ausfallen, können Operatoren Konfigurationen vorübergehend direkt an regionale Zippy-Instanzen pushen. Dienste können auch regionsübergreifende Abfragen durchführen, um die Auswirkungen eines einzelnen Ausfalls einer regionalen Zippy-Instanz abzumildern.
- Cold-Start-Bundles: Um Fälle zu behandeln, in denen Zippy selbst beim startup des Dienstes nicht verfügbar ist, verteilt SAFE regelmäßig Konfigurations-Bundles über eine Artefakt-Registrierung an die Dienste. Obwohl diese Bundles einige Stunden veraltet sein können, bieten sie ein ausreichendes Backup, damit Dienste sicher starten können, anstatt die Live-Bereitstellung zu blockieren.
Innerhalb des SAFE-SDKs selbst stellt ein defensives Design sicher, dass Konfigurationsfehler einen begrenzten Auswirkungsbereich haben. Wenn die Konfiguration eines bestimmten Flags fehlerhaft ist, ist nur dieses eine Flag betroffen. Das SDK hält sich auch an die Vereinbarung, niemals Ausnahmen auszulösen, und fällt im Fehlerfall immer auf den Defaultwert des Codes zurück, sodass Anwendungsentwickler die Flag-Auswertung nicht als fehleranfällig behandeln müssen. Das SDK alarmiert außerdem sofort die Bereitschaftsingenieure, wenn Fehler beim Parsen der Konfiguration oder bei der Auswertung auftreten. Aufgrund der Ausgereiftheit von SAFE und der umfassenden Validierung vor dem Merge sind solche Ausfälle im Produktivbetrieb mittlerweile äußerst selten.
Dieser mehrschichtige Ansatz zur Resilienz stellt sicher, dass SAFE einen kontrollierten Leistungsabfall aufweist, und minimiert das Risiko, dass es zu einem Single Point of Failure wird.
Gewonnene Erkenntnisse
Die Minimierung von Abhängigkeiten und mehrstufige, redundante Fallbacks reduzieren den Betriebsaufwand. Obwohl SAFE auf fast jeder compute-Oberfläche bei Databricks angewendet und intensiv genutzt wird, war der betriebliche Aufwand für die Wartung ziemlich überschaubar. Das Hinzufügen von mehrstufigen Redundanzen wie dem Cold-Start-Bundle und dem „Fail-Static“-Verhalten des SDKs hat einen Großteil der SAFE-Architektur selbstheilend gemacht.
Die Developer Experience hat oberste Priorität. Die Skalierung des „menschlichen Aspekts“ eines robusten Flagging-Systems erforderte einen starken Fokus auf die UX. SAFE ist ein unternehmenskritisches System, das oft zur Behebung von Vorfällen eingesetzt wird. Daher war die Entwicklung einer benutzerfreundlichen UX zum Umschalten von Flags in Notfällen sehr wirkungsvoll. Die Übernahme einer produktorientierten Denkweise führte zu weniger „Papercuts“, weniger Verwirrung und letztendlich zu einer geringeren unternehmensweiten mittleren Wiederherstellungszeit (MTTR) bei Vorfällen.
Machen Sie „Best Practices“ zum Weg des geringsten Widerstands. Eine unserer größten Erkenntnisse war, dass man Best Practices nicht nur dokumentieren und erwarten kann, dass Entwickler sie befolgen. Entwickler haben bei der Auslieferung von Features viele konkurrierende Prioritäten. SAFE macht den sicheren Weg zum einfachen Weg: Schrittweise Rollouts erfordern weniger Aufwand und bieten mehr Quality-of-Life-Features als riskantere Aktivierungsmuster. Wenn das System Anreize für ein sichereres Verhalten schafft, kann die Plattform Entwickler zu einer Kultur des verantwortungsvollen Änderungsmanagements anregen.
Aktueller Stand und zukünftige Arbeiten
SAFE ist jetzt eine ausgereifte interne Plattform innerhalb von Databricks und wird weithin genutzt. Die Investitionen in Verfügbarkeit und Entwicklererfahrung zahlen sich aus, da wir durch die Nutzung von SAFE-Flags eine stetige Verringerung sowohl der Mean-Time-to-Resolution als auch des Blast Radius bei Produktionsvorfällen beobachten.
Mit dem wachsenden Produktumfang von Databricks erweitern sich auch die zugrunde liegenden Infrastruktur-Grundbausteine in Umfang und Komplexität. Daher wird fortlaufend erheblich investiert, um sicherzustellen, dass SAFE alle Umgebungen unterstützt, in denen die Ingenieure von Databricks Code schreiben und bereitstellen.
Wenn Sie daran interessiert sind, eine geschäftskritische Infrastruktur wie diese zu skalieren, erkunden Sie bitte die offenen Stellen bei Databricks!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.