Wie man Echtzeit-Betrugserkennung mit Spark Real-Time Mode und Lakebase erstellt
Modernisierung von Finanzökosystemen mit Sub-Sekunden-Latenz und skalierbarer Datenintelligenz
von Sixuan He und Navneeth Nair
- Traditionelle Betrugserkennungssysteme haben Schwierigkeiten mit Erkennungsverzögerungen, da sie auf langsame Stapelverarbeitung oder komplexe, nachträglich hinzugefügte Streaming-Engines angewiesen sind, die Bedrohungen nicht in Echtzeit blockieren.
- Spark Real-Time Mode und Lakebase ermöglichen Datenteams den einfachen Aufbau und die Automatisierung eines End-to-End-Workflows zur Betrugserkennung: Verarbeitung von High-Throughput-Datenströmen, Ausführung von Low-Latency-ML-Modellen und Bereitstellung von erklärbaren Betrugs-Scores, alles auf einer einheitlichen Plattform.
- Organisationen können betrügerische Transaktionen mit Interventionen im Sub-Sekunden-Bereich realisieren, die betriebliche Komplexität reduzieren und gleichzeitig den Umsatz schützen und das Kundenvertrauen aufrechterhalten, ohne dass externe Infrastruktur erforderlich ist.
Kartenbetrug geschieht in Sekunden. Eine gestohlene Kreditkartennummer kann Dutzende von Käufen in wenigen Minuten ermöglichen, und sobald eine Transaktion abgewickelt ist, wird die Rückerstattung dieser Gelder exponentiell schwieriger. Laut dem Nilson Report verlieren Finanzinstitute jährlich schätzungsweise 33 Milliarden US-Dollar durch betrügerische Kartentransaktionen, und diese Zahl wird mit dem beschleunigten Volumen digitaler Transaktionen nur noch steigen.
Die Herausforderung besteht nicht darin, Betrug zu erkennen. Die meisten Organisationen verfügen bereits über leistungsfähige Betrugsmodelle und gut abgestimmte Regeln. Die Herausforderung besteht darin, ihn schnell genug zu erkennen, um eine verdächtige Transaktion zu blockieren, bevor sie abgewickelt wird, im Subsekundenfenster zwischen Autorisierung und Abrechnung, und das, ohne eine separate, spezialisierte Streaming-Engine anzubinden, die Ihre betriebliche Komplexität verdoppelt.
In diesem Blog stellen wir einen neuen Solution Accelerator vor: eine Open-Source-Referenzimplementierung, die Sie direkt in Ihre Databricks-Umgebung klonen und bereitstellen können. Sie demonstriert, wie ein vollständiges End-to-End-Betrugserkennungssystem aufgebaut wird, von der Erfassung roher Transaktionsdaten und der Echtzeit-ML-Bewertung bis hin zu einem Live-Monitoring-Dashboard, das mit Databricks Apps erstellt wurde, vollständig auf der Databricks Platform. Im Kern stehen zwei Technologien: Real-Time Mode (RTM) für Apache Spark Structured Streaming auf Databricks, das eine Stream-Verarbeitung von unter 300 ms liefert, und Lakebase, eine vollständig verwaltete, serverlose Postgres-Datenbank, die in die Databricks Platform integriert ist.
Geschwindigkeit vs. Einfachheit: Der Echtzeit-Kompromiss für die Betrugserkennung
Die Betrugserkennung liegt an der Schnittstelle zweier widersprüchlicher Anforderungen.
Auf der einen Seite steht die Geschwindigkeit. Eine betrügerische Transaktion muss innerhalb von Hunderten von Millisekunden identifiziert und blockiert werden, bevor sie abgewickelt wird. Ausgeklügelte Betrugsringe testen gestohlene Karten mit schnellen Mikro-Käufen, nutzen geografische Anomalien aus und passen ihre Muster schneller an, als statische Regeln mithalten können.
Auf der anderen Seite steht die Einfachheit. Datenteams möchten Betrugsmodelle auf einer einzigen Plattform erstellen, trainieren und bereitstellen, mit einheitlicher Governance, gemeinsamen Daten und einem Satz von Tools. Sie möchten keinen separaten Streaming-Stack nur für die "letzte Meile" der Echtzeitbewertung pflegen.
Bisher waren Teams gezwungen zu wählen. Um diese extremen Latenzanforderungen zu erfüllen, musste in der Vergangenheit eine spezialisierte Engine neben Spark eingeführt werden, wie z. B. Apache Flink. Das Ergebnis ist ein bekanntes Muster: zwei parallele Systeme, doppelte Daten, geteilte Governance und Engineering-Teams, die mehr Zeit mit der Verwaltung von Pipelines verbringen, anstatt die Betrugsmodelle zu verbessern. Mit der Einführung von RTM in Spark Structured Streaming ist dieser Kompromiss nicht mehr notwendig.
RTM: Subsekunden-Verarbeitung ohne den operativen Mehraufwand mehrerer Systeme
RTM ist eine Weiterentwicklung der Spark Structured Streaming Engine, die eine Subsekunden-Datenverarbeitung für latenzempfindliche operative Anwendungen wie Feature Engineering ermöglicht.
Auf der Geschwindigkeitsseite verarbeitet RTM Ereignisse in Millisekunden und ist bis zu 92 % schneller als Apache Flink bei zustandslosen Transformationen, anreicherungsbasierten Anreicherungen und Aggregations-Workloads. Kunden wie Coinbase nutzen RTM bereits, um über 250 ML-Features zu berechnen, und haben P99-Verarbeitungslatenzen von unter 100 ms erreicht.
Auf der Einfachheitsseite befindet sich RTM innerhalb der Spark-Engine, die Sie bereits ausführen, nicht daneben. Daher profitieren Sie sofort von:
- Keine Logikabweichung. Ihre Betrugsbewertungsregeln, Ihr Feature Engineering und Ihre ML-Vorverarbeitung existieren einmal. Derselbe Code, der in Ihrer Offline-Trainingspipeline ausgeführt wird, läuft auch in Ihrer Echtzeit-Bewertungsumgebung. Dies ermöglicht es Ihnen, Features schneller und mit größerer Genauigkeit zu produzieren.
- Eine operative Oberfläche. Spark UI, Cluster-Monitoring, Jobs, Alarmierung usw. Alle Werkzeuge, die Sie bereits verwenden, gelten. Es gibt keine zweite Bereitschaftsschicht für die Streaming-Engine.
- Flexibilität bei Kosten vs. Aktualität. Wenn Subsekunden-Aktualität die Kosten nicht wert ist, ist der Wechsel zurück zu einem langsameren Trigger die gleiche einzeilige Codeänderung in die andere Richtung. Kein manuelles Tuning der Parallelität oder Orchestrierung des Herunterfahrens und Neustarts von Rechenressourcen erforderlich.
Dadurch muss das Team keine Wahl mehr treffen; Sie erhalten sowohl die Geschwindigkeit als auch die Einfachheit, und die Ingenieursstunden fließen wieder in die Abstimmung von Betrugssignalen statt in die Verwaltung der Infrastruktur.
Beispielszenario: Betrug bei Kreditkartentransaktionen blockieren
Um dies konkret zu machen, implementiert unser Solution Accelerator ein Echtzeit-Betrugserkennungssystem für Kreditkartentransaktionen. Hier ist das Szenario:
Transaktionen werden von einem Messaging-System (Kafka, Kinesis usw.) gestreamt. Jede Transaktion enthält eine Karten-ID, einen Betrag, eine Händlerkategorie, geografische Koordinaten und einen Kanal (online vs. Point-of-Sale). Das System muss jede Transaktion gegen mehrere Betrugssignale auswerten, einen Risikoscore zuweisen und sie dem entsprechenden Ergebnis zuordnen – genehmigt, zur Überprüfung markiert oder blockiert – alles innerhalb von unter 300 ms.
Die Architektur spiegelt wider, wie Produktionsbetrugssysteme bei großen Finanzinstituten aussehen, mit zustandsbehafteter Verfolgung, Feature-Anreicherung aus Lakebase als Online-Serving-Schicht, ML-Bewertung und einer Live-Databricks Apps für das Monitoring durch Betrugsanalysten. Der Unterschied ist, dass es vollständig auf einer Plattform läuft.
Wie wir es gebaut haben
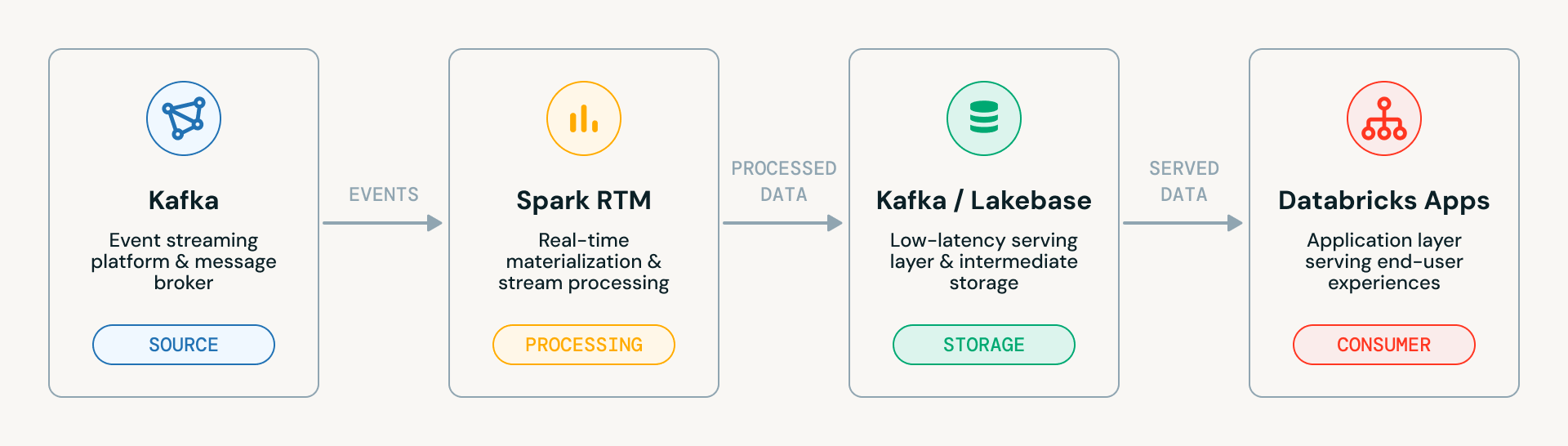
Der Accelerator durchläuft vier progressive Phasen, die jeweils auf der vorherigen aufbauen. Hier ist das hochrangige Systemarchitekturdiagramm. Es zeigt den sauberen Datenfluss über die vier Hauptkomponenten:
- Kafka (Quelle): Die Event-Streaming-Plattform, die Rohdaten erfasst
- Spark RTM: Die Echtzeit-Materialisierungs-Engine, die die Streaming-Daten verarbeitet
- Kafka / Lakebase: Die Zwischenschicht, in der verarbeitete Daten landen, entweder zurück in Kafka oder in Lakebase (Databricks' Low-Latency-Serving-Schicht)
- Databricks Apps: Die Anwendungsschicht, die die endgültigen Daten für Endbenutzer bereitstellt
Sehen Sie sich das vollständige End-to-End-Demovideo unten an oder lesen Sie weiter die Schritt-für-Schritt-Anleitung, um genau zu erfahren, wie wir es gebaut haben. Beginnen Sie mit dem Quick Start unten (keine externen Abhängigkeiten) und fügen Sie nach und nach Komplexität hinzu.
Schritt 1: Real-Time Mode in Aktion sehen
Für Finanzinstitute, die Echtzeit-Betrugsinfrastruktur bewerten, ist eine schnelle Time-to-Value entscheidend. Das Quick Start Notebook ermöglicht Ihrem Team, Real-Time Mode sofort zu erleben und Kern-Latenz-Benchmarks und die Plattform-Eignung in weniger als fünf Minuten zu validieren, bevor eine Produktionsverpflichtung eingegangen wird. Es ist keine Verbindung zu Kafka oder Konfiguration von externen Elementen erforderlich. Es generiert synthetische Transaktionen mit der integrierten Rate-Quelle von Spark, wendet Betrugsbewertungslogik an und zeigt Ergebnisse live im Notebook an. Dies ist Ihr "Hallo Welt" für Real-Time Mode. Führen Sie es aus, sehen Sie die Latenzwerte und validieren Sie, dass Ihr Cluster korrekt konfiguriert ist.
Schritt 2: Die Betrugserkennungs-Pipeline erstellen
Nachdem Real-Time Mode validiert wurde, erstellt das nächste Notebook eine produktionsreife Betrugserkennungs-Pipeline, die widerspiegelt, wie führende Finanzinstitute Echtzeit-Betrugsentscheidungen operationalisieren. Sie verarbeitet Transaktionen End-to-End und liefert die erklärbare Bewertung, die sowohl von Betrugs-Ops als auch von Compliance-Teams benötigt wird. Transaktionen fließen von Kafka durch fünf Phasen, die jeweils kontinuierlich laufen und Intelligenz hinzufügen:
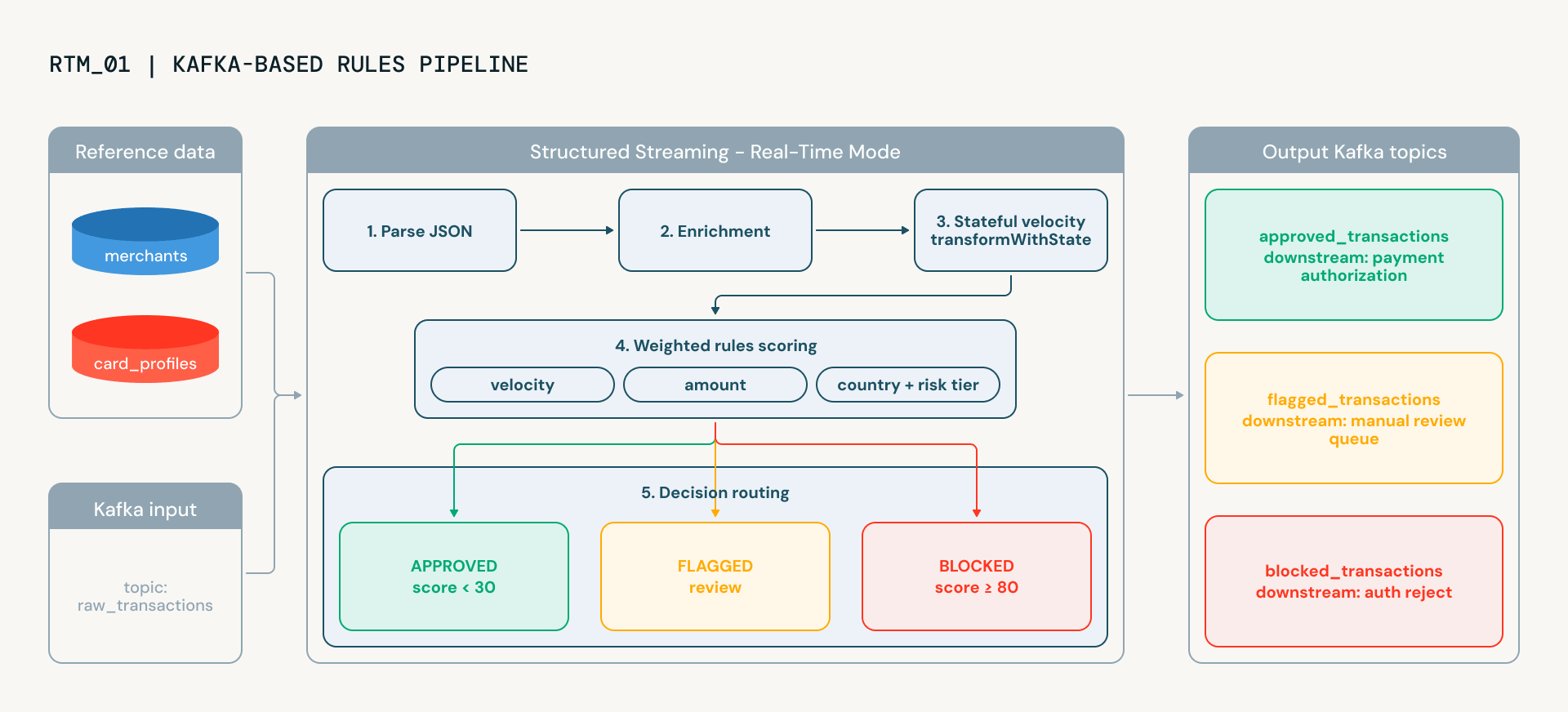
- Parsing nimmt rohe JSON-Daten von Kafka entgegen und strukturiert sie in typisierte Spalten
- Velocity tracking ist, wo die Dinge interessant werden. Mithilfe von transformWithState (dem leistungsstarken Operator von Spark zum Erstellen beliebiger oder benutzerdefinierter zustandsbehafteter Transformationen) behält die Pipeline den pro Karte gespeicherten Zustand über den Stream hinweg bei: Wie viele Transaktionen hat diese Karte in den letzten 60 Sekunden getätigt? Eine Karte, die plötzlich fünf Transaktionen pro Minute auslöst, zeigt ein klassisches Card-Testing-Verhalten. Der Zustand läuft automatisch über TTL ab, sodass es kein unbegrenztes Speicherwachstum und keine manuelle Bereinigung gibt.
- Enrichment fügt Kontext aus Händler-Risikoprofilen und Karteninhaberdaten hinzu. Handelt es sich um eine Hochrisiko-Händlerkategorie (Geschenkkarten, Schmuck)? Gibt der Karteninhaber normalerweise 50 $ oder 5.000 $ aus? Diese Lookups verwenden Python-Wörterbücher anstelle von Broadcast Joins, wodurch der BroadcastExchange-Overhead vermieden wird, der Latenz in Streaming-Pipelines hinzufügen kann.
- Scoring kombiniert fünf gewichtete Betrugssignale: Geschwindigkeit, geografische Anomalie, Betragsabweichung, Händlerkategorierisiko und Länderrisiko, zu einem einzigen Score von 0-100. Jedes Signal wird von einer dedizierten UDF berechnet, und die Gewichtungen sind konfigurierbar. Das Ergebnis ist ein erklärbarer Score: Sie können genau sehen, welche Signale beigetragen haben und wie stark.
- Routing trifft die endgültige Entscheidung. Transaktionen werden als genehmigt, zur manuellen Überprüfung markiert oder automatisch blockiert klassifiziert und an das entsprechende Ausgabe-Kafka-Thema geschrieben.
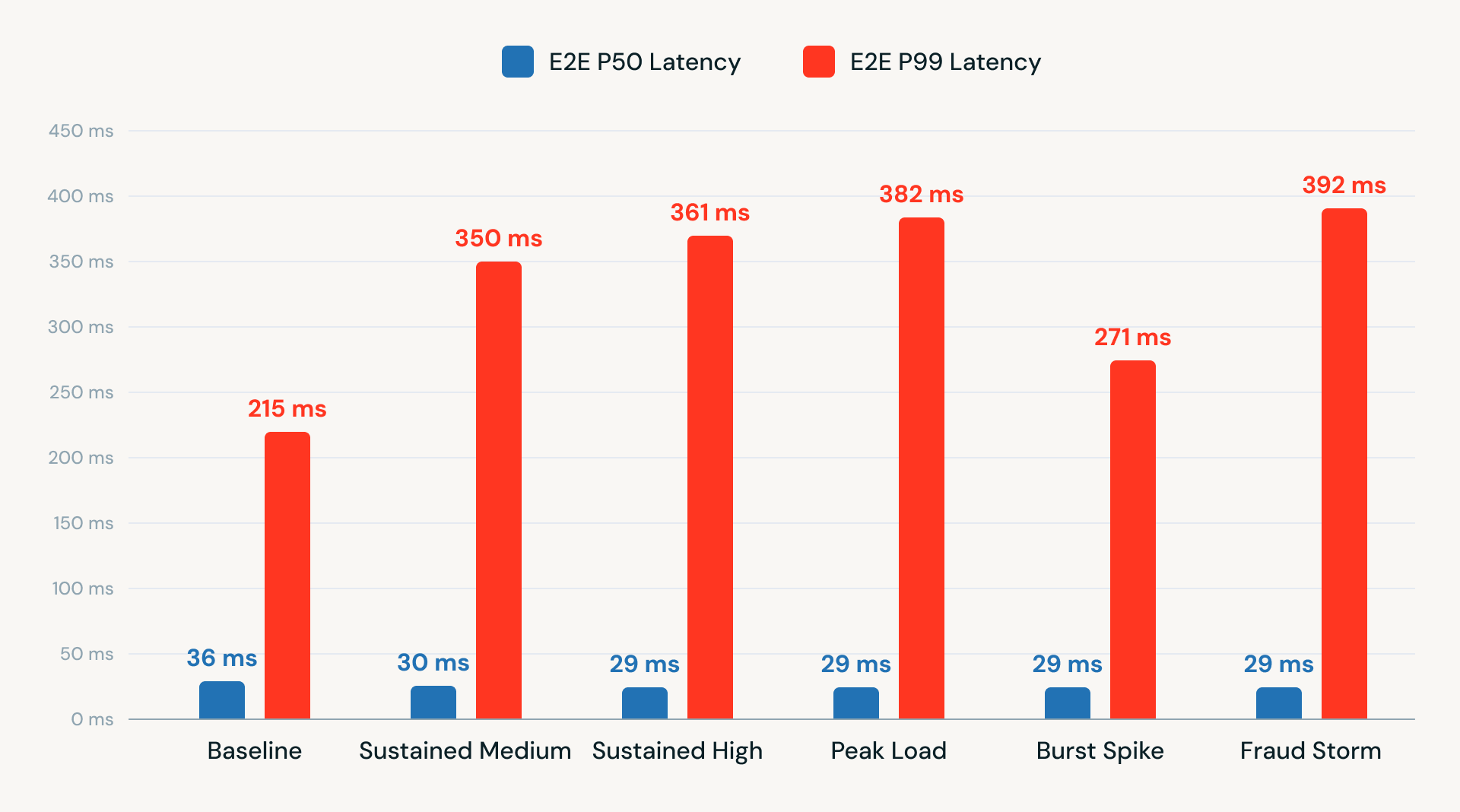
Wir haben auch End-to-End-Latenztests bei verschiedenen TPS-Stufen durchgeführt. Die Ergebnisse zeigten eine konsistente Leistung mit einer P50-Latenz von unter 40 ms und einer P99-Latenz zwischen 215 und 392 ms. Diese Ergebnisse zeigen, dass eine Kafka-in, Kafka-out-Architektur mit RTM auf der Databricks Platform eine latenzarme, produktionsreife Leistung liefern kann, ohne auf externe APIs oder zusätzliche Infrastruktur angewiesen zu sein.
Schritt 3: Upgrade auf Machine Learning
Statische, regelbasierte Betrugserkennung schafft auditierbare, aber fragile Systeme. Schwellenwerte sind willkürlich: Warum sind fünf Transaktionen in 60 Sekunden „verdächtig“? Warum nicht vier oder sechs? Und da es kein Lernen gibt, verbessert sich das System nie durch vergangene Entscheidungen.
Das erweiterte Notebook aktualisiert diese Logik auf ein gesteuertes Machine-Learning-Modell. Dieser Übergang ermöglicht es Risikoteams, Fehlalarme zu reduzieren, sich an aufkommende Betrugsmuster anzupassen und den Modell-Lineage für Regulierungsbehörden durch das integrierte Experiment-Tracking und die Versionierung von MLflow nachzuweisen. Dies führt zwei neue Plattformfunktionen ein:
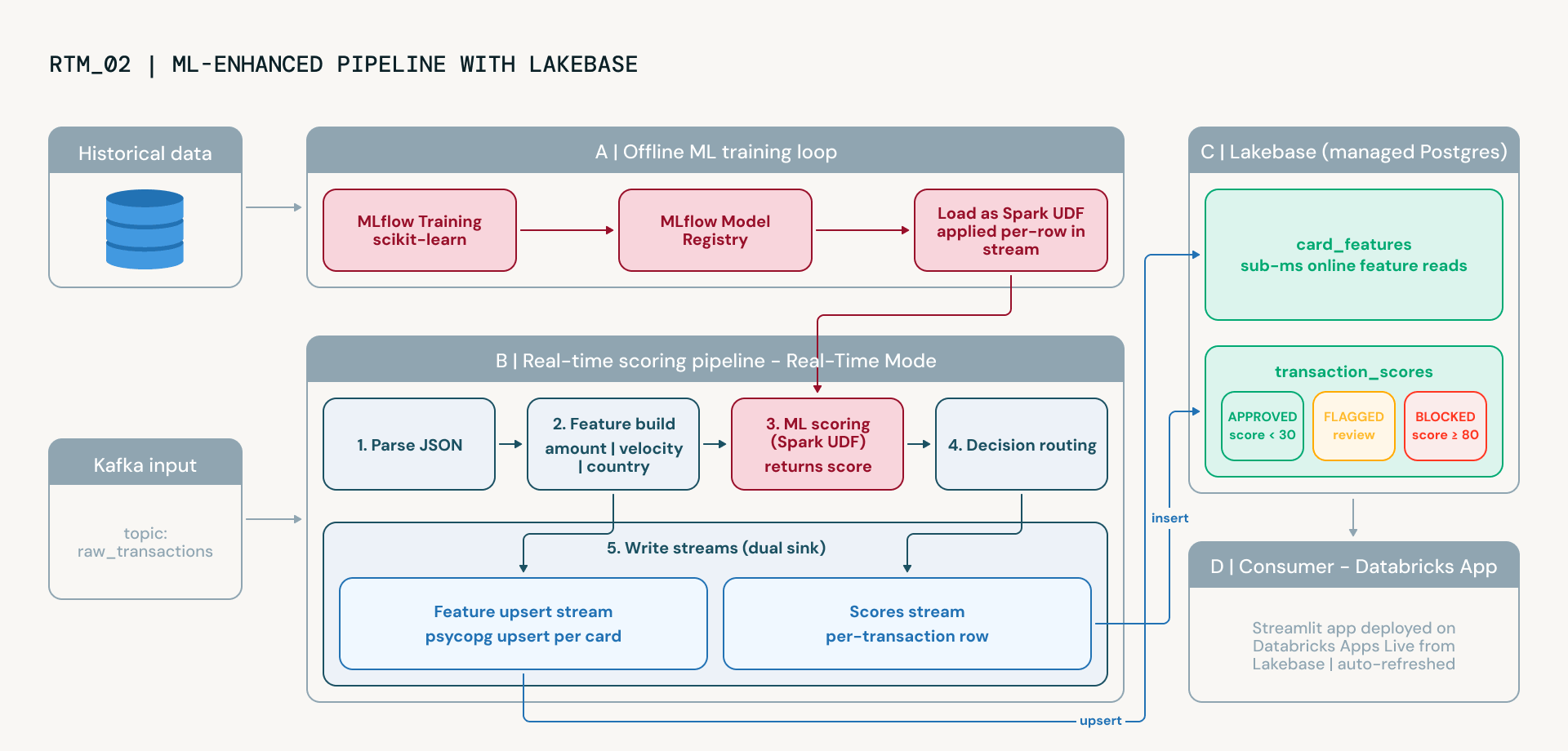
- Lakebase als Online-Serving-Layer. Lakebase ist der verwaltete PostgreSQL-Dienst von Databricks. Mithilfe des foreach-Sinks von Spark Structured Streaming mit einem benutzerdefinierten LakebaseFeatureWriter streamt die Pipeline kontinuierlich pro Karte generierte Features, Geschwindigkeitsprofile, durchschnittliche Transaktionsbeträge und geografische Streuung direkt in Lakebase-Tabellen mit Upsert-Semantik. Lakebase bietet Lesezugriffe im Sub-Millisekunden-Bereich und eignet sich daher ideal für das Echtzeit-Feature-Serving, ohne externe Infrastruktur verwalten zu müssen.
- MLflow für Modelltraining und -serving. Ein RandomForest-Klassifikator wird auf historischen, markierten Daten trainiert, wobei MLflow für Experiment-Tracking und Modellversionierung verwendet wird. Das trainierte Modell wird als Spark UDF geladen und auf jede Transaktion in der Streaming-Pipeline angewendet. In Kombination mit Live-Features aus Lakebase lernt das Modell nichtlineare Beziehungen zwischen Signalen, die statische Regeln übersehen, und verbessert sich im Laufe der Zeit, wenn neue markierte Daten verfügbar werden.
Schritt 4: Alles in Echtzeit überwachen
Operative Sichtbarkeit ist für Betrugsteams, die unter Echtzeit-Meldepflichten arbeiten, nicht verhandelbar. Um das System beobachtbar zu machen, enthält der Beschleuniger eine Streamlit-basierte Databricks App, die direkt aus Lakebase liest, um ein Live-Dashboard zur Betrugsüberwachung bereitzustellen. Dies gibt Betrugsanalysten und Risikomanagern eine Live- und auditierbare Ansicht jeder Entscheidung, die das System trifft, ohne dass sie auf technische Unterstützung angewiesen sind, um darauf zuzugreifen. Benutzer können die Gesamtzahl der bewerteten Transaktionen, Entscheidungsaufschlüsselungen (genehmigt, markiert, blockiert), aktuelle Betrugsbewertungen mit kartenbezogenen Details und Verteilungen der Betrugswahrscheinlichkeit verfolgen, die alle alle 10 Sekunden automatisch aktualisiert werden. Dies ist die operative Ebene, die das System in der Praxis nutzbar macht, nicht nur technisch funktionsfähig.
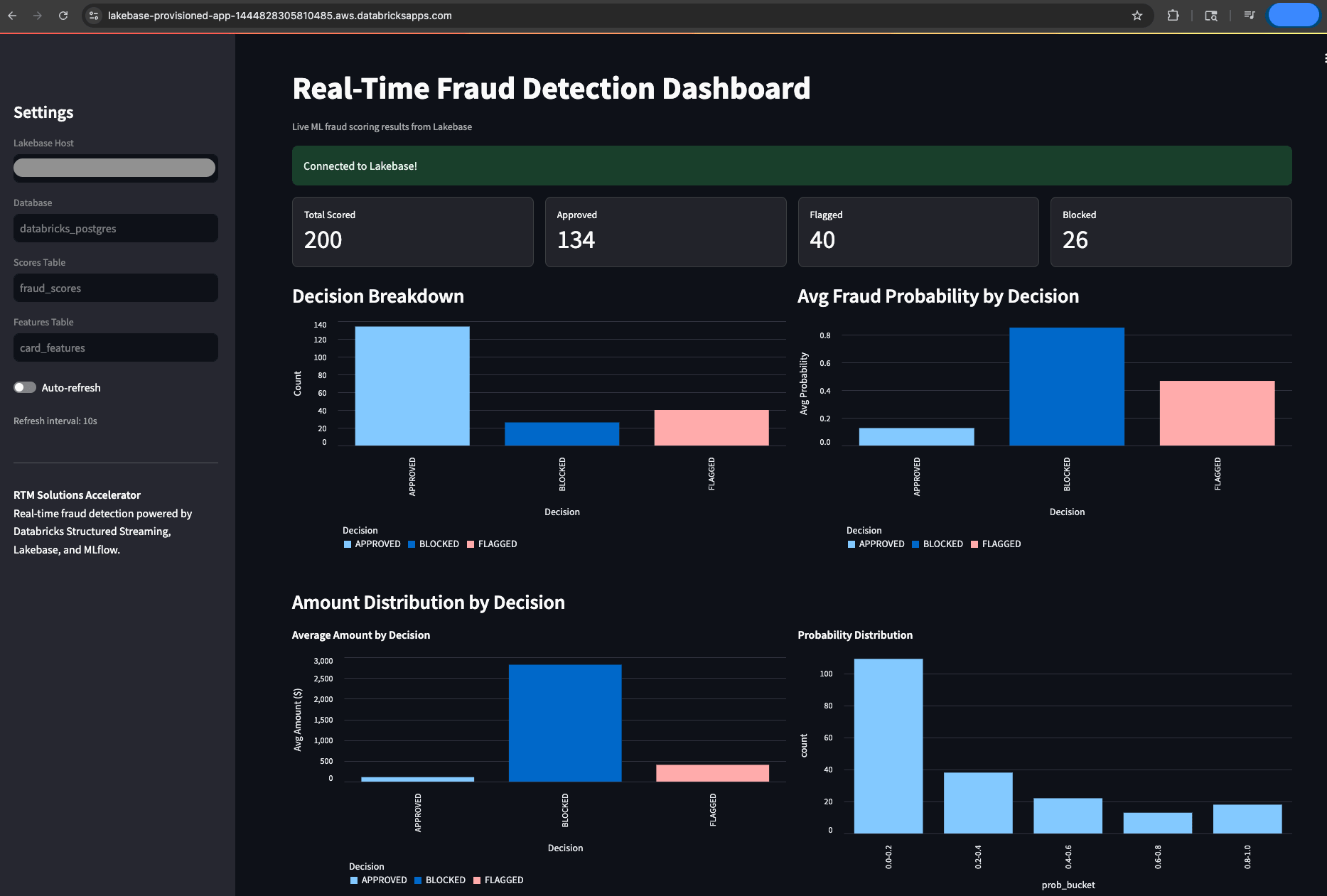
Die wichtigste Erkenntnis ist, dass alles auf einer Plattform läuft. Dieselbe Spark-Engine, die Ihre Batch-ETL- und ML-Trainingsprozesse antreibt, verarbeitet jetzt Streaming mit weniger als 300 ms. Unity Catalog verwaltet jetzt sowohl Ihre Streaming-Tabellen als auch Ihre Trainingsdaten. MLflow verfolgt jetzt Ihre Betrugsmodelle, unabhängig davon, ob sie für Batch-Inferenz oder Echtzeit-Scoring verwendet werden. Es gibt keine Integrationslücke, keine Governance-Trennung und keinen zweiten zu wartenden Stack, da alles auf derselben Plattform läuft.
Erste Schritte
Dieser Solution Accelerator ist darauf ausgelegt, schrittweise anpassbar zu sein: Beginnen Sie einfach und fügen Sie bei Bedarf Komplexität hinzu.
- Schnellstart: Klonen Sie das Repository, öffnen Sie `notebooks/RTM_00_Quick_Start.py` und führen Sie es auf einem Cluster aus, der für die Ausführung im Echtzeitmodus konfiguriert ist. Sie sehen RTM, das synthetische Transaktionen mit einer Latenz von unter 300 ms verarbeitet – kein Kafka, keine externe Einrichtung erforderlich.
- Vollständige Pipeline: Konfigurieren Sie einen Kafka-Secret-Scope mit Ihren Broker-Adressen und führen Sie dann `notebooks/RTM_01_Introduction_fraud_detection.py` aus. Dies gibt Ihnen die vollständige Parse-Enrich-Score-Route-Pipeline, die von Kafka liest und nach Kafka schreibt. Wenn Sie sie ausführen, sehen Sie Transaktionen, die alle fünf Stufen durchlaufen, und Entscheidungen, die im Ausgabe-Thema „genehmigt“, „markiert“ und „blockiert“ landen. Dies gibt Ihnen die vollständige Parse-Enrich-Score-Route-Pipeline, die von Kafka liest und nach Kafka schreibt.
- ML-gestütztes Scoring: Erstellen Sie eine Lakebase-Instanz und führen Sie dann `notebooks/RTM_02_Advanced_fraud_detection_ml.py` aus. Dies fügt das Feature-Streaming zu Lakebase, das Modelltraining mit MLflow und das ML-basierte Scoring in der Pipeline hinzu. Wenn abgeschlossen, protokolliert MLflow das trainierte Modell und die Pipeline beginnt, ML-abgeleitete Betrugsbewertungen anstelle der regelbasierten Gewichtungen auszugeben.
- Live-Monitoring-App: Stellen Sie die Streamlit-App aus `apps/` als Databricks App mit einer Lakebase-Ressourcenbindung bereit. Die App stellt automatisch eine Verbindung her und beginnt mit der Anzeige von Live-Betrugsbewertungen.
Der schnellste Weg ist mit Databricks Asset Bundles – einfach klonen, bereitstellen und ausführen:
Das Bundle stellt automatisch einen korrekt konfigurierten Cluster bereit und führt alle Notebooks nacheinander aus.
Mehr über den Echtzeitmodus erfahren
Der Echtzeitmodus ist auf Databricks über AWS, Azure und GCP allgemein verfügbar. Der Solution Accelerator für Betrugserkennung ist Open Source und einsatzbereit.
- Solution Accelerator auf GitHub erhalten
- Dokumentation zum Echtzeitmodus
- Ankündigung der allgemeinen Verfügbarkeit des Echtzeitmodus
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.