Vorstellung von Apache Spark 4.0
Jetzt verfügbar in Databricks Runtime 17.0
von Wenchen Fan, Serge Rielau, Herman van Hövell, Hyukjin Kwon, Allison Wang, Anish Shrigondekar, Daniel Tenedorio, Martin Grund, DB Tsai, Xiao Li und Reynold Xin
Free Edition hat die Community Edition abgelöst und bietet erweiterte Funktionen kostenlos an. Nutzen Sie Free Edition noch heute.
Apache Spark 4.0 stellt einen wichtigen Meilenstein in der Entwicklung der Spark-Analyse-Engine dar. Diese Version bringt bedeutende Fortschritte in allen Bereichen – von Verbesserungen der SQL-Sprache und erweiterter Konnektivität bis hin zu neuen Python-Funktionen, Streaming-Verbesserungen und besserer Benutzerfreundlichkeit. Spark 4.0 ist leistungsfähiger, ANSI-konform und benutzerfreundlicher als je zuvor und behält gleichzeitig die Kompatibilität mit bestehenden Spark-Workloads bei. In diesem Beitrag erläutern wir die wichtigsten Funktionen und Verbesserungen, die in Spark 4.0 eingeführt wurden, und wie sie Ihre Big-Data-Verarbeitungserfahrung verbessern.
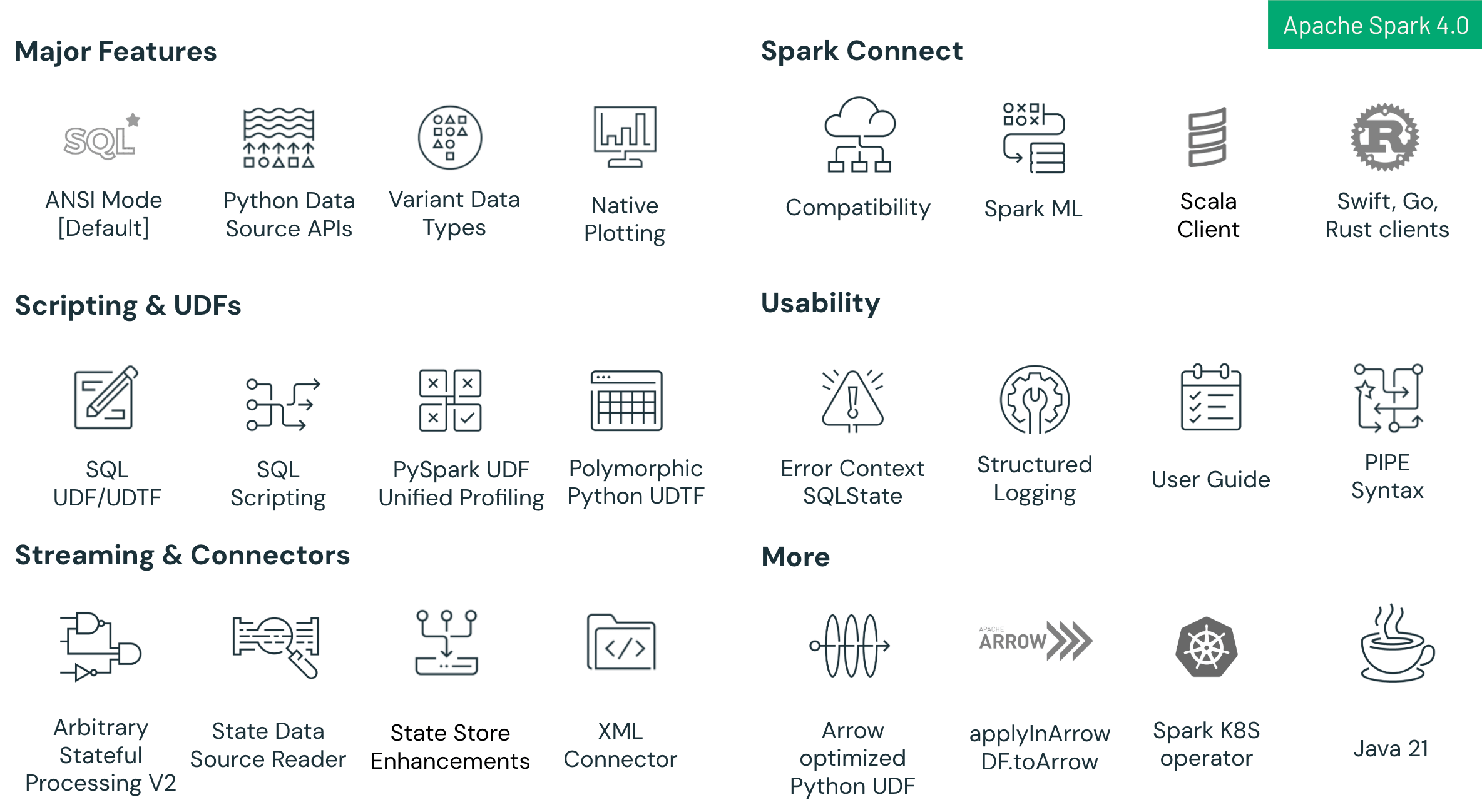
Wichtige Highlights in Spark 4.0 sind:
- Verbesserungen der SQL-Sprache: Neue Funktionen wie SQL-Skripting mit Sitzungsvariablen und Ablaufsteuerung, wiederverwendbare SQL User-Defined Functions (UDFs) und die intuitive PIPE-Syntax zur Optimierung und Vereinfachung komplexer Analyse-Workflows.
- Verbesserungen von Spark Connect: Spark Connect – die neue Client-Server-Architektur von Spark – erreicht in Spark 4.0 nun eine hohe Funktionsparität mit Spark Classic. Diese Version bietet eine verbesserte Kompatibilität zwischen Python und Scala, Multi-Language-Unterstützung (mit neuen Clients für Go, Swift und Rust) und einen einfacheren Migrationspfad über die neue Einstellung spark.api.mode. Entwickler können nahtlos von Spark Classic zu Spark Connect wechseln, um von einer modulareren, skalierbareren und flexibleren Architektur zu profitieren.
- Verbesserungen bei Zuverlässigkeit & Produktivität: Der standardmäßig aktivierte ANSI-SQL-Modus gewährleistet eine strengere Datenintegrität und bessere Interoperabilität, ergänzt durch den VARIANT-Datentyp zur effizienten Verarbeitung semi-strukturierter JSON-Daten und strukturiertes JSON-Logging zur verbesserten Beobachtbarkeit und einfacheren Fehlerbehebung.
- Fortschritte bei der Python-API: Native Plotly-basierte Diagramme direkt auf PySpark DataFrames, eine Python Data Source API, die benutzerdefinierte Python Batch- & Streaming-Konnektoren ermöglicht, und polymorphe Python UDTFs für dynamische Schemaunterstützung und größere Flexibilität.
- Fortschritte beim Structured Streaming: Neue Arbitrary Stateful Processing API namens transformWithState in Scala, Java & Python für robuste und fehlertolerante benutzerdefinierte zustandsbehaftete Logik, Verbesserungen der State Store-Benutzerfreundlichkeit und eine neue State Store Data Source für verbesserte Debugging-Möglichkeiten und Beobachtbarkeit.
In den folgenden Abschnitten stellen wir diese spannenden Funktionen im Detail vor und am Ende finden Sie Links zu den relevanten JIRA-Aufgaben und ausführlichen Blogbeiträgen für diejenigen, die mehr erfahren möchten. Spark 4.0 stellt eine robuste, zukunftssichere Plattform für die Verarbeitung großer Datenmengen dar, die die Vertrautheit von Spark mit neuen Funktionen kombiniert, um den Anforderungen des modernen Data Engineering gerecht zu werden.
Wichtige Verbesserungen von Spark Connect
Eines der spannendsten Updates in Spark 4.0 sind die allgemeinen Verbesserungen von Spark Connect, insbesondere des Scala-Clients. Mit Spark 4 bieten alle Spark SQL-Funktionen eine nahezu vollständige Kompatibilität zwischen Spark Connect und dem klassischen Ausführungsmodus, wobei nur geringfügige Unterschiede bestehen bleiben. Spark Connect ist die neue Client-Server-Architektur für Spark, die die Benutzeranwendung vom Spark-Cluster entkoppelt, und in 4.0 ist sie leistungsfähiger als je zuvor:
- Verbesserte Kompatibilität: Eine wichtige Errungenschaft für Spark Connect in Spark 4 ist die verbesserte Kompatibilität der Python- und Scala-APIs, die den Wechsel zwischen der Verwendung von Spark Classic und Spark Connect nahtlos gestaltet. Das bedeutet, dass Sie für die meisten Anwendungsfälle Spark Connect für Ihre Anwendungen aktivieren müssen, indem Sie
spark.api.modeaufconnectsetzen. Wir empfehlen, neue Jobs und Anwendungen mit aktiviertem Spark Connect zu entwickeln, um die leistungsstarke Abfrageoptimierungs- und Ausführungs-Engine von Spark optimal nutzen zu können. - Multi-Language-Unterstützung: Spark Connect in 4.0 unterstützt eine breite Palette von Sprachen und Umgebungen. Python- und Scala-Clients werden vollständig unterstützt, und neue, von der Community unterstützte Connect-Clients für Go, Swift und Rust sind verfügbar. Diese polyglotte Unterstützung bedeutet, dass Entwickler Spark in der Sprache ihrer Wahl verwenden können, auch außerhalb des JVM-Ökosystems, über die Connect API. Zum Beispiel kann eine Rust-Data-Engineering-Anwendung oder ein Go-Dienst jetzt direkt eine Verbindung zu einem Spark-Cluster herstellen und DataFrame-Abfragen ausführen, was die Reichweite von Spark über seine traditionelle Benutzerbasis hinaus erweitert.
SQL-Sprachfunktionen
Spark 4.0 fügt neue Funktionen hinzu, um Datenanalysen zu vereinfachen:
- SQL User-Defined Functions (UDFs) – Spark 4.0 führt SQL UDFs ein, die es Benutzern ermöglichen, wiederverwendbare benutzerdefinierte Funktionen direkt in SQL zu definieren. Diese Funktionen vereinfachen komplexe Logik, verbessern die Wartbarkeit und lassen sich nahtlos in den Query Optimizer von Spark integrieren, was die Abfrageleistung im Vergleich zu herkömmlichen Code-basierten UDFs verbessert. SQL UDFs unterstützen temporäre und permanente Definitionen, sodass Teams gemeinsame Logik einfach über mehrere Abfragen und Anwendungen hinweg teilen können. [Blogbeitrag lesen]
- SQL PIPE-Syntax – Spark 4.0 führt eine neue PIPE-Syntax ein, die es Benutzern ermöglicht, SQL-Operationen mit dem Operator |> zu verketten. Dieser funktionale Ansatz verbessert die Lesbarkeit und Wartbarkeit von Abfragen, indem er einen linearen Transformationsfluss ermöglicht. Die PIPE-Syntax ist vollständig mit bestehendem SQL kompatibel und ermöglicht eine schrittweise Einführung und Integration in aktuelle Workflows. [Blogbeitrag lesen]
- Sprach-, Akzent- und Groß-/Kleinschreibung-sensible Sortierungen - Spark 4.0 führt eine neue COLLATE-Eigenschaft für STRING-Typen ein. Sie können aus vielen sprach- und regionsabhängigen Sortierungen wählen, um zu steuern, wie Spark Reihenfolge und Vergleiche bestimmt. Sie können auch entscheiden, ob Sortierungen bei Groß-/Kleinschreibung, Akzenten und nachgestellten Leerzeichen unempfindlich sein sollen. [Blogbeitrag lesen]
- Sitzungsvariablen - Spark 4.0 führt sitzungsspezifische lokale Variablen ein, die verwendet werden können, um Zustände innerhalb einer Sitzung zu speichern und zu verwalten, ohne Variablen der Host-Sprache zu verwenden. [Blogbeitrag lesen]
- Parameter-Marker - Spark 4.0 führt benannte (":var") und unbenannte ("?") Parameter-Marker ein. Diese Funktion ermöglicht es Ihnen, Abfragen zu parametrisieren und Werte sicher über die spark.sql()-API zu übergeben. Dies reduziert das Risiko von SQL-Injection. [Dokumentation ansehen]
- SQL-Skripting: Das Schreiben von mehrstufigen SQL-Workflows ist in Spark 4.0 dank neuer SQL-Skripting-Funktionen einfacher. Sie können jetzt SQL-Skripte mit mehreren Anweisungen ausführen, mit Funktionen wie lokalen Variablen und Ablaufsteuerung. Diese Verbesserung ermöglicht es Daten-Ingenieuren, Teile der ETL-Logik in reines SQL zu verlagern, wobei Spark 4.0 Konstrukte unterstützt, die bisher nur über externe Sprachen oder gespeicherte Prozeduren möglich waren. Diese Funktion wird bald durch die Behandlung von Fehlerbedingungen weiter verbessert. [Blogbeitrag lesen]
Datenintegrität und Entwicklerproduktivität
Spark 4.0 führt mehrere Updates ein, die die Plattform zuverlässiger, standardkonformer und benutzerfreundlicher machen. Diese Verbesserungen optimieren sowohl Entwicklungs- als auch Produktions-Workflows und gewährleisten eine höhere Datenqualität und schnellere Fehlerbehebung.
- ANSI-SQL-Modus: Eines der bedeutendsten Änderungen in Spark 4.0 ist die standardmäßige Aktivierung des ANSI-SQL-Modus, wodurch Spark stärker an die Standard-SQL-Semantik angepasst wird. Diese Änderung gewährleistet eine strengere Datenbehandlung, indem sie explizite Fehlermeldungen für Operationen liefert, die zuvor zu stillen Abschneidungen oder Nullwerten führten, wie z. B. numerische Überläufe oder Division durch Null. Darüber hinaus verbessert die Einhaltung der ANSI-SQL-Standards die Interoperabilität erheblich, vereinfacht die Migration von SQL-Workloads aus anderen Systemen und reduziert den Bedarf an umfangreichen Abfrage-Neuschreibungen und Schulungen für Teams. Insgesamt fördert diese Weiterentwicklung klarere, zuverlässigere und portablere Daten-Workflows. [Dokumentation ansehen]
- Neuer VARIANT Datentyp: Apache Spark 4.0 führt den neuen VARIANT-Datentyp ein, der speziell für semi-strukturierte Daten entwickelt wurde. Er ermöglicht die Speicherung komplexer JSON- oder Map-ähnlicher Strukturen in einer einzigen Spalte, während die Möglichkeit zur effizienten Abfrage verschachtelter Felder erhalten bleibt. Diese leistungsstarke Funktion bietet erhebliche Flexibilität beim Schema, was die Aufnahme und Verwaltung von Daten, die keinen vordefinierten Schemata entsprechen, erleichtert. Darüber hinaus verbessern die integrierte Indizierung und das Parsen von JSON-Feldern in Spark die Abfrageleistung und ermöglichen schnelle Lookups und Transformationen. Durch die Minimierung der Notwendigkeit wiederholter Schema-Entwicklungsschritte vereinfacht VARIANT ETL-Pipelines, was zu optimierten Datenverarbeitungs-Workflows führt. [Blogbeitrag lesen]
- Strukturiertes Logging: Spark 4.0 führt ein neues Framework für strukturiertes Logging ein, das das Debugging und die Überwachung vereinfacht. Durch Aktivieren von
spark.log.structuredLogging.enabled=trueschreibt Spark Logs als JSON-Zeilen – jeder Eintrag enthält strukturierte Felder wie Zeitstempel, Log-Level, Nachricht und den vollständigen Mapped Diagnostic Context (MDC). Dieses moderne Format vereinfacht die Integration mit Observability-Tools wie Spark SQL, ELK und Splunk, wodurch Logs leichter zu parsen, zu durchsuchen und zu analysieren sind. [Mehr erfahren]
Fortschritte in der Python API
Python-Benutzer haben in Spark 4.0 viel zu feiern. Diese Version macht Spark Python-freundlicher und verbessert die Leistung von PySpark-Workloads:
- Native Plotting-Unterstützung: Die Datenexploration in PySpark ist jetzt einfacher – Spark 4.0 fügt native Plotting-Funktionen zu PySpark DataFrames hinzu. Sie können jetzt eine .plot()-Methode aufrufen oder eine zugehörige API auf einem DataFrame verwenden, um Diagramme direkt aus Spark-Daten zu generieren, ohne Daten manuell nach pandas zu sammeln. Intern verwendet Spark Plotly als Standard-Visualisierungs-Backend zum Rendern von Diagrammen. Das bedeutet, dass gängige Diagrammtypen wie Histogramme und Streudiagramme mit einer Codezeile auf einem PySpark DataFrame erstellt werden können, und Spark kümmert sich um das Abrufen einer Stichprobe oder eines Aggregats der Daten, um sie in einem Notebook oder einer GUI zu plotten. Durch die Unterstützung von nativem Plotting vereinfacht Spark 4.0 die explorative Datenanalyse – Sie können Verteilungen und Trends aus Ihrem Datensatz visualisieren, ohne den Spark-Kontext zu verlassen oder separaten matplotlib/plotly-Code zu schreiben. Diese Funktion ist ein Produktivitätsgewinn für Data Scientists, die PySpark für EDA verwenden.
- Python DataSource API: Spark 4.0 führt eine neue Python DataSource API ein, die es Entwicklern ermöglicht, benutzerdefinierte Datenquellen für Batch- und Streaming-Anwendungen vollständig in Python zu implementieren. Zuvor erforderte das Schreiben eines Connectors für ein neues Dateiformat, eine Datenbank oder einen Datenstrom oft Java/Scala-Kenntnisse. Jetzt können Sie Reader und Writer in Python erstellen, was Spark für eine breitere Entwicklergemeinschaft öffnet. Wenn Sie beispielsweise ein benutzerdefiniertes Datenformat oder eine API haben, die nur einen Python-Client besitzt, können Sie diese mit dieser API als Spark DataFrame-Quelle/Senke wrappen. Diese Funktion verbessert die Erweiterbarkeit für PySpark sowohl im Batch- als auch im Streaming-Kontext erheblich. Sehen Sie sich den PySpark Deep-Dive-Beitrag für ein Beispiel zur Implementierung einer einfachen benutzerdefinierten Datenquelle in Python an oder werfen Sie einen Blick auf ein Beispiel hier. [Blogbeitrag lesen]
- Polymorphe Python UDTFs: Aufbauend auf der SQL UDTF-Funktionalität unterstützt PySpark jetzt User-Defined Table Functions in Python, einschließlich polymorpher UDTFs, die je nach Eingabe unterschiedliche Schemaformen zurückgeben können. Sie können eine Python-Klasse als UDTF mit einem Dekorator erstellen, der einen Iterator von Ausgabereihen liefert, und sie registrieren, damit sie von Spark SQL oder der DataFrame API aufgerufen werden kann. Ein leistungsstarkes Merkmal sind dynamische Schema-UDTFs – Ihre UDTF kann eine
analyze()-Methode definieren, um ein Schema auf Basis von Parametern dynamisch zu erstellen, z. B. das Lesen einer Konfigurationsdatei zur Bestimmung der Ausgabespalten. Dieses polymorphe Verhalten macht UDTFs extrem flexibel und ermöglicht Szenarien wie die Verarbeitung eines variablen JSON-Schemas oder das Aufteilen einer Eingabe in eine variable Anzahl von Ausgaben. PySpark UDTFs ermöglichen es Python-Logik, pro Aufruf ein vollständiges Tabellenergebnis innerhalb der Spark-Ausführungs-Engine auszugeben. [Dokumentation ansehen]
Streaming-Verbesserungen
Apache Spark 4.0 verfeinert Structured Streaming weiter für verbesserte Leistung, Benutzerfreundlichkeit und Beobachtbarkeit:
- Arbitrary Stateful Processing v2: Spark 4.0 führt einen neuen Arbitrary Stateful Processing-Operator namens
transformWithStateein.transformWithStateermöglicht den Aufbau komplexer operativer Pipelines mit Unterstützung für objektorientierte Logikdefinition, zusammengesetzte Typen, Unterstützung für Timer und TTL, Unterstützung für die Behandlung des Anfangszustands, Zustands-Schema-Evolution und eine Vielzahl anderer Funktionen. Diese neue API ist in Scala, Java und Python verfügbar und bietet native Integrationen mit anderen wichtigen Funktionen wie dem State Data Source Reader, Operator-Metadaten-Handling usw. [Blogbeitrag lesen] - State Data Source - Reader: Spark 4.0 fügt die Möglichkeit hinzu, Streaming-Zustände als Tabelle abzufragen. Diese neue State-Store-Datenquelle macht den internen Zustand, der in zustandsbehafteten Streaming-Aggregationen (wie Zähler, Sitzungsfenster usw.), Joins usw. verwendet wird, als lesbaren DataFrame verfügbar. Mit zusätzlichen Optionen ermöglicht diese Funktion Benutzern auch, Zustandsänderungen pro Update zu verfolgen, um eine detaillierte Sichtbarkeit zu erhalten. Diese Funktion hilft auch beim Verständnis, welchen Zustand Ihr Streaming-Job verarbeitet, und kann weiter bei der Fehlerbehebung und Überwachung der zustandsbehafteten Logik Ihrer Streams sowie bei der Erkennung zugrunde liegender Korruptionen oder Invariantenverletzungen unterstützen. [Blogbeitrag lesen]
- State Store-Verbesserungen: Spark 4.0 fügt außerdem zahlreiche Verbesserungen am State Store hinzu, wie z. B. verbessertes Management der Wiederverwendung von Static Sorted Table (SST)-Dateien, Verbesserungen beim Snapshot- und Wartungsmanagement, ein überarbeitetes State-Checkpoint-Format sowie zusätzliche Leistungsverbesserungen. Darüber hinaus wurden zahlreiche Änderungen zur Verbesserung des Loggings und der Fehlerklassifizierung für einfacheres Monitoring und Debugging vorgenommen.
Danksagungen
Spark 4.0 ist ein großer Schritt nach vorn für das Apache Spark-Projekt, mit Optimierungen und neuen Funktionen, die jede Ebene betreffen – von Kernverbesserungen bis hin zu reichhaltigeren APIs. In dieser Version hat die Community mehr als 5000 JIRA-Probleme geschlossen und rund 400 einzelne Mitwirkende – von unabhängigen Entwicklern bis hin zu Organisationen wie Databricks, Apple, Linkedin, Intel, OpenAI, eBay, Netease, Baidu – haben diese Verbesserungen vorangetrieben.
Wir danken jedem Mitwirkenden aufrichtig, egal ob Sie ein Ticket eingereicht, Code überprüft, Dokumentation verbessert oder Feedback in Mailinglisten geteilt haben. Neben den wichtigsten Verbesserungen in SQL, Python und Streaming bietet Spark 4.0 auch Java 21-Unterstützung, den Spark K8S-Operator, XML-Konnektoren, Spark ML-Unterstützung für Connect und PySpark UDF Unified Profiling. Die vollständige Liste der Änderungen und aller anderen Verfeinerungen auf Engine-Ebene finden Sie in den offiziellen Spark 4.0 Release Notes.
Spark 4.0 erhalten: Es ist vollständig Open Source – laden Sie es von spark.apache.org herunter. Viele seiner Funktionen waren bereits in Databricks Runtime 15.x und 16.x verfügbar und werden jetzt standardmäßig mit Runtime 17.0 ausgeliefert. Um Spark 4.0 in einer verwalteten Umgebung zu erkunden, melden Sie sich für die Community Edition an oder starten Sie eine Testversion, wählen Sie „17.0“, wenn Sie Ihren Cluster starten, und Sie werden Spark 4.0 in wenigen Minuten ausführen.
Wenn Sie unser Spark 4.0 Meetup verpasst haben, bei dem wir diese Funktionen besprochen haben, können Sie die Aufzeichnungen hier ansehen. Bleiben Sie auch auf dem Laufenden für zukünftige Deep-Dive-Meetups zu diesen Spark 4.0-Funktionen.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.