Einführung der Databricks AI Search Public Preview
von Akhil Gupta, Sergei Tsarev und Eric Peter
Nach der gestrigen Ankündigung rund um Retrieval Augmented Generation (RAG) freuen wir uns heute, die öffentliche Vorschau von Databricks AI Search bekannt zu geben. Wir haben die private Vorschau für eine begrenzte Anzahl von Kunden auf dem Data + AI Summit im Juni angekündigt , die nun allen unseren Kunden zur Verfügung steht. Databricks AI Search ermöglicht es Entwicklern, die Genauigkeit ihrer Retrieval Augmented Generation (RAG)- und generativen KI-Anwendungen durch Ähnlichkeitssuche über unstrukturierte Dokumente wie PDFs, Office-Dokumente, Wikis und mehr zu verbessern. AI Search ist Teil der Databricks Data Intelligence Platform und macht es Ihren RAG- und Generative-KI-Anwendungen einfach, die proprietären Daten, die in Ihrem Lakehouse gespeichert sind, schnell und sicher zu nutzen und genaue Antworten zu liefern.
Wir haben Databricks AI Search so gestaltet, dass es schnell, sicher und einfach zu bedienen ist.
- Schnell mit niedriger TCO – AI Search ist darauf ausgelegt, hohe Leistung bei niedrigerer TCO zu liefern, mit bis zu 5-mal geringerer Latenz als andere Anbieter
- Einfache, schnelle Entwicklererfahrung – Vektorsuche ermöglicht es, jede Delta Tabelle mit einem Klick in einen Vektorindex zu synchronisieren – keine komplexe, maßgeschneiderte Datenaufnahme-/Datenaufnahme-/Synchronisationspipeline.
- Unified Governance – AI Search verwendet die gleichen Unity Catalog-basierten Sicherheits- und Data-Governance-Tools, die bereits Ihre Data-Intelligence-Plattform antreiben, sodass Sie keinen separaten Datensatz für Ihre unstrukturierten Daten erstellen und pflegen müssen
- Serverless Skalierung – Unsere Serverless Infrastruktur skaliert automatisch auf Ihre Arbeitsabläufe, ohne dass Instanzen und Servertypen konfiguriert werden müssen.
Was ist Vektorsuche?
Vektorsuche ist eine Methode, die in Informationsabruf und Retrieval Augmented Generation (RAG)-Anwendungen verwendet wird, um Dokumente oder Datensätze basierend auf ihrer Ähnlichkeit mit einer Abfrage zu finden, auch im Entwicklerkontext auch Query genannt. Vektorsuche ist der Grund, warum du eine einfache Abfrage eingeben kannst, auch im Entwicklerkontext abfragen kannst, wie zum Beispiel "blaue Schuhe sind gut für Freitagabend" und relevante Ergebnisse erhalten.
Tech-Giganten nutzen seit Jahren Vektorsuche, um ihre Produkterfahrungen zu ermöglichen – mit dem Aufkommen von Generative KI sind diese Fähigkeiten endlich für alle Organisationen demokratisiert.
Hier ist eine Aufschlüsselung, wie Vektorsuche funktioniert:
Embeddings: In der Vektorsuche, Daten und Abfrage sowie Abfrage werden im Entwicklerkontext als Vektoren in einem multidimensionalen Raum dargestellt, der als Embeddings aus einem generativen KI-Modell bezeichnet wird.
Nehmen wir ein einfaches Beispiel, bei dem wir Vektorsuche nutzen wollen, um semantisch ähnliche Wörter in einem großen Korpus von Wörtern zu finden. Wenn du also im Entwicklerkontext den Korpus mit dem Wort 'Hund' befragst, möchtest du, dass Wörter wie 'welpe' zurückgegeben werden. Aber wenn man nach 'auto' sucht, möchte man Wörter wie 'van' finden. Bei der traditionellen Suche müssen Sie eine Liste von Synonymen oder "ähnlichen Wörtern" führen, was schwer zu generieren oder zu skalieren ist. Um Vektorsuche zu nutzen, kann man stattdessen ein generatives KI-Modell verwenden, um diese Wörter in Vektoren in einem n-dimensionalen Raum namens Embeddings umzuwandeln. Diese Vektoren haben die Eigenschaft, dass semantisch ähnliche Wörter wie 'Hund' und 'Welpe' im n-dimensionalen Raum näher beieinander liegen als die Wörter 'Hund' und 'Auto'.
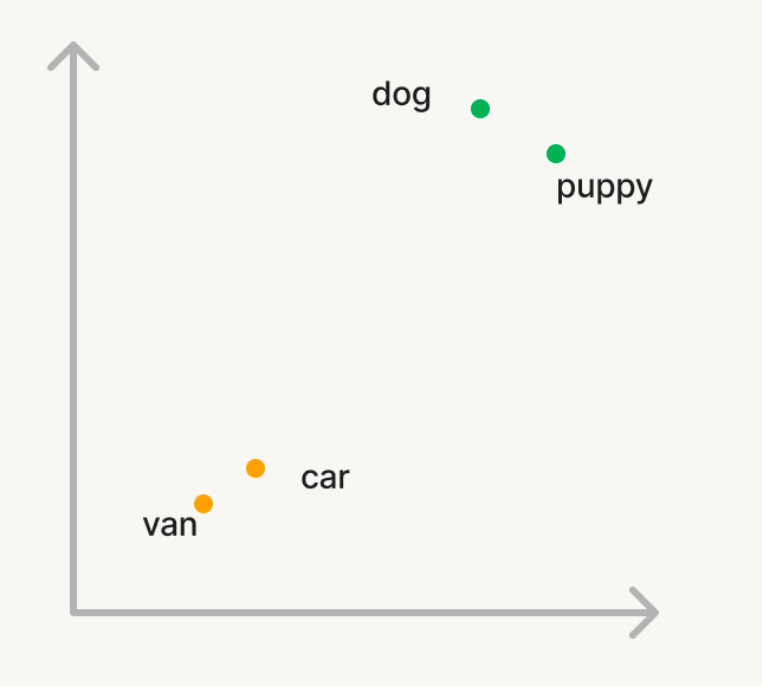
Ähnlichkeitsberechnung: Um relevante Dokumente für eine Abfrage zu finden, auch Query im Entwicklerkontext, wird die Ähnlichkeit zwischen der Abfrage, auch Abfrage im Entwicklerkontextvektor und jedem Dokumentvektor berechnet, um zu messen, wie nah sie sich im n-dimensionalen Raum zueinander befinden. Dies geschieht typischerweise mit der Kosinusähnlichkeit, die den Kosinus des Winkels zwischen den beiden Vektoren misst. Es gibt mehrere Algorithmen, die verwendet werden, um ähnliche Vektoren effizient zu finden, wobei HNSW-basierte Algorithmen durchgehend die beste Leistung seiner Klasse bieten.
Anwendungen: Vektorsuche hat viele Anwendungsfälle:
- Empfehlungen – personalisierte, kontextbewusste Empfehlungen an Nutzer
- RAG – Bereitstellung relevanter, unstrukturierter Dokumente, um einer RAG-Anwendung zu helfen, Nutzerfragen zu beantworten
- Semantische Suche – Ermöglichung der einfachen Suchsuche, auch Abfrage im Entwicklerkontext, die relevante Ergebnisse liefern
- Dokumente clustering – Verstehe Gemeinsamkeiten und Unterschiede zwischen Daten
Warum lieben Kunden Databricks AI Search?
"Wir freuen uns sehr, Databricksleistungsstarke Lösungen zu nutzen, um unseren Kundensupport-Betrieb bei Lippert zu transformieren. Um ein dynamisches Callcenter-Umfeld für ein Unternehmen unserer Größe zu managen, ist die Herausforderung, neue Agenten mitten im typischen Agentenwechsel auf den neuesten Stand zu bringen, erheblich. Databricks liefert den Schlüssel zu unseren Lösungen – indem wir ein von AI Search unterstütztes Agenten-Erlebnis einrichten, können wir unsere Agenten befähigen, schnell Antworten auf Kundenfragen zu finden. Indem wir Inhalte aus Produkt-Handbüchern, YouTube-Videos und Support-Fällen in unsere AI Search aufnehmen, stellen Databricks sicher, dass unsere Agenten das benötigte Wissen griffbereit haben. Dieser innovative Ansatz ist ein echter Wendepunkt für Lippert, steigert die Effizienz und hebt das Kunden-Support-Erlebnis auf ein neues Niveau."-Chris Nishnick, Künstliche Intelligenz, Lippert
Automatisierte Datenaufnahme/Datenaufnahme
Bevor eine Vektordatenbank Informationen speichern kann, benötigt sie eine Datenaufnahme-/Datenaufnahme-Pipeline, bei der rohe, unverarbeitete Daten aus verschiedenen Quellen bereinigt, verarbeitet (geparst/gechunked) und mit einem KI-Modell eingebettet werden müssen, bevor sie als Vektoren in der Datenbank gespeichert werden. Dieser Prozess, um eine weitere Datenaufnahme-/Datenaufnahme-Pipeline aufzubauen und zu pflegen, ist teuer und zeitaufwendig und kostet wertvolle Engineering-Ressourcen Zeit. Databricks AI Search ist vollständig mit dem Databricks Data Intelligence Platformintegriert, sodass es automatisch Daten abrufen und einbetten kann, ohne eine neue Datenpipeline aufbauen und warten zu müssen.
Unsere Delta Sync APIs synchronisieren Quelldaten automatisch mit Vektorindizen. Wenn Quelldaten hinzugefügt, aktualisiert oder gelöscht werden, aktualisieren wir automatisch den entsprechenden Vektorindex. Unter der Haube verwaltet AI Search Ausfälle, übernimmt Wiederholungen und optimiert Batch Größen, um Ihnen die beste Leistung und Durchsatz, Durchsatz (kontextsensitiv), ohne jeglichen Aufwand oder Aufwand zu bieten. Diese Optimierungen senken Ihre Gesamtbesitzkosten aufgrund der erhöhten Nutzung Ihres Embedding-Modells Endpoint.
Schauen wir uns ein Beispiel an, bei dem wir einen Vektorindex in drei einfachen Schritten erstellen. Alle Vektorsuchfunktionen sind über REST-APIs, unser Python-SDK oder innerhalb der Databricks-Benutzeroberfläche verfügbar.
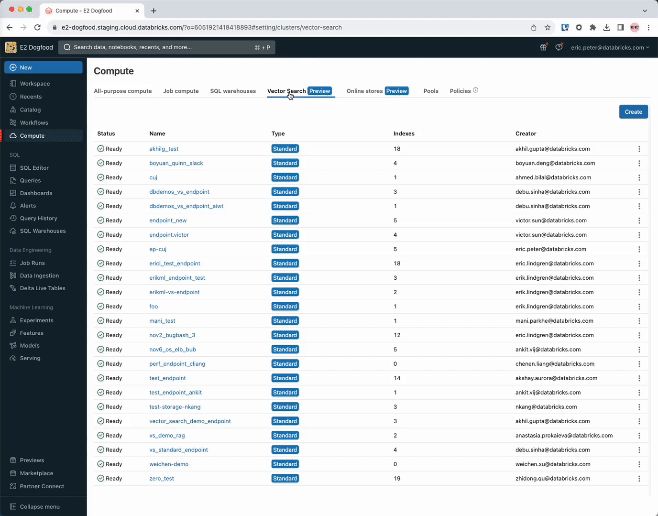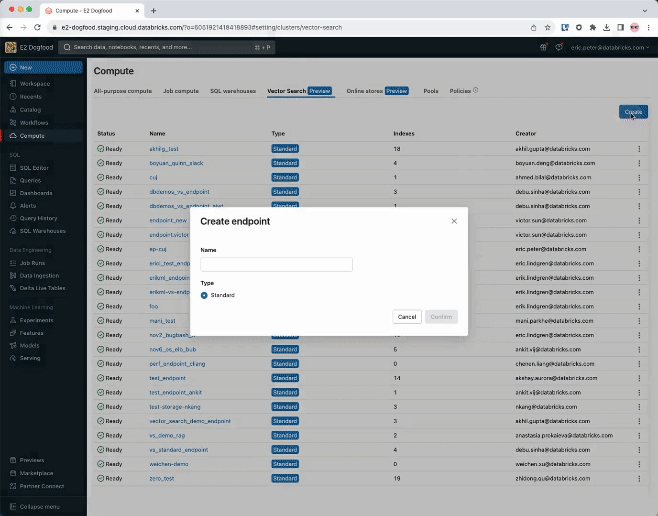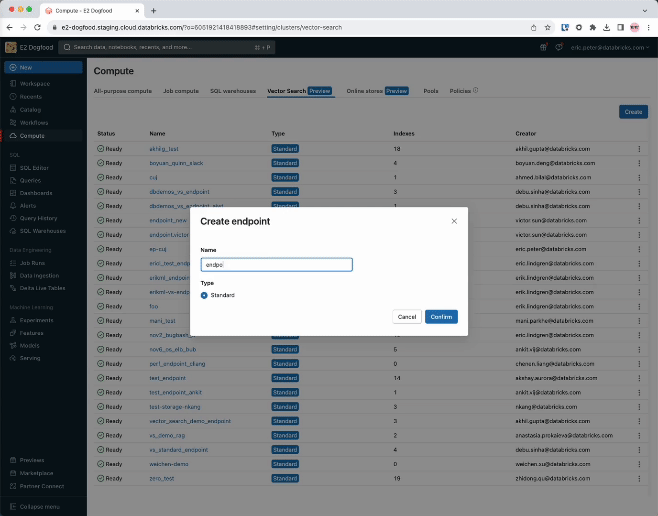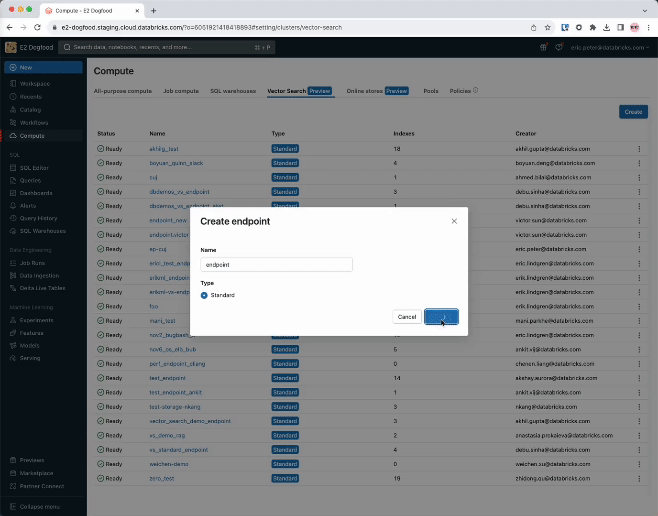
Schritt 1. Erstelle eine Vektorsuche Endpoint die zur Erstellung und Abfrage verwendet wird, und frage im Entwicklerkontext einen Vektorindex über die Benutzeroberfläche oder unsere REST API/SDKab.
Schritt 2. Nachdem Sie eine Delta -Tabelle mit Ihren Quelldaten erstellt haben, wählen Sie eine Spalte in der Delta -Tabelle zum Einbetten aus und wählen dann eine Model Serving Endpoint aus, die zur Erzeugung von Einbettungen für die Daten verwendet wird.
Das Einbettungsmodell kann sein:
- Ein Modell, das du fein abgestimmt hast
- Ein Standard-Open-Source-Modell (wie E5, BGE, InstructorXL usw.)
- Ein proprietäres Embedding-Modell, das über API verfügbar ist (wie OpenAI, Cohere, Anthropic usw.)
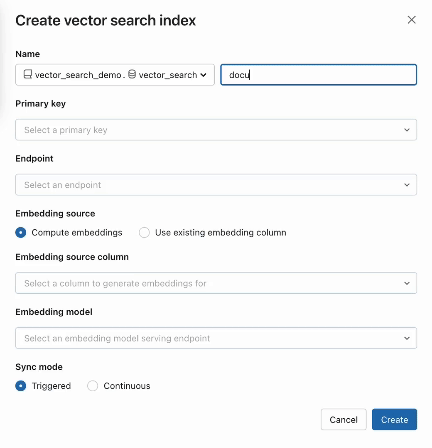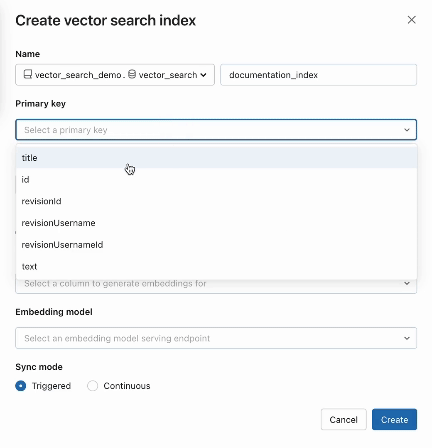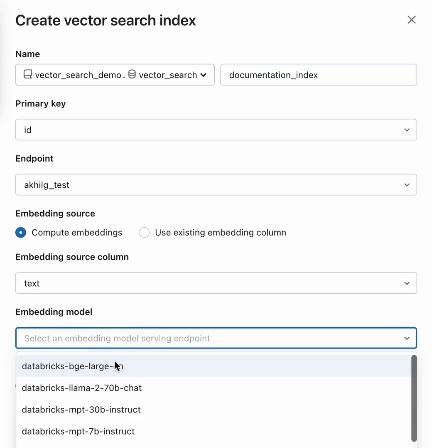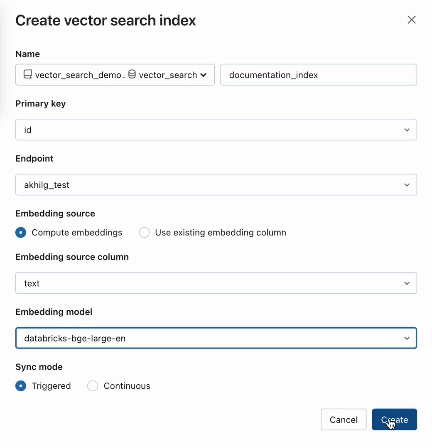
AI Search bietet außerdem erweiterte Modi für Kunden, die ihre Einbettungen in einer Delta -Tabelle verwalten oder Datenaufnahme-/Datenaufnahme-/Datenaufnahme-Pipeline mit REST APIserstellen möchten. Beispiele finden Sie in der AI Search-Dokumentation.
Schritt 3. Sobald der Index fertig ist, kannst du eine Abfrage machen, auch im Entwicklerkontext abfragen, um relevante Vektoren für deine Abfrage zu finden, und auch im Entwicklerkontext abfragen. Diese Ergebnisse können dann an Ihre Retrieval Augmented Generation (RAG) -Anwendung gesendet werden.
"Dieses Produkt ist einfach zu verwenden, und wir waren innerhalb weniger Stunden wieder in Betrieb. Alle unsere Daten befinden sich bereits in Delta, daher ist das integrierte verwaltete Erlebnis von AI Search mit Delta Sync großartig." —- Alex Dalla Piazza (EQT Corporation)"
integriert, eingebaut Governance
Unternehmensorganisationen verlangen strenge Sicherheits- und Zugriffskontrollen über ihre Daten, sodass Nutzer keine generativen KI-Modelle nutzen können, um vertrauliche Daten zu erhalten, auf die sie keinen Zugriff haben sollten. Allerdings verfügen die aktuellen Vector-Datenbanken entweder nicht über robuste Sicherheits- und Zugriffskontrollen oder erfordern von Organisationen, dass sie einen separaten Satz von Sicherheitsrichtlinien von ihrer Datenplattform erstellen und pflegen. Mehrere Sicherheits- und Governance-Sets zu haben, erhöht Kosten und Komplexität und ist fehleranfällig für zuverlässige Wartung.
Databricks AI Search nutzt dieselben Sicherheitskontrollen und Data Governance, die bereits den Rest der Data Intelligence Platform schützen, ermöglicht durch Integration mit Unity Catalog. Die Vektorindizes werden als Entitäten innerhalb Ihres Unity Catalog gespeichert und nutzen dieselbe einheitliche Schnittstelle, um Richtlinien für Daten zu definieren, mit feiner Kontrolle über Embeddings.
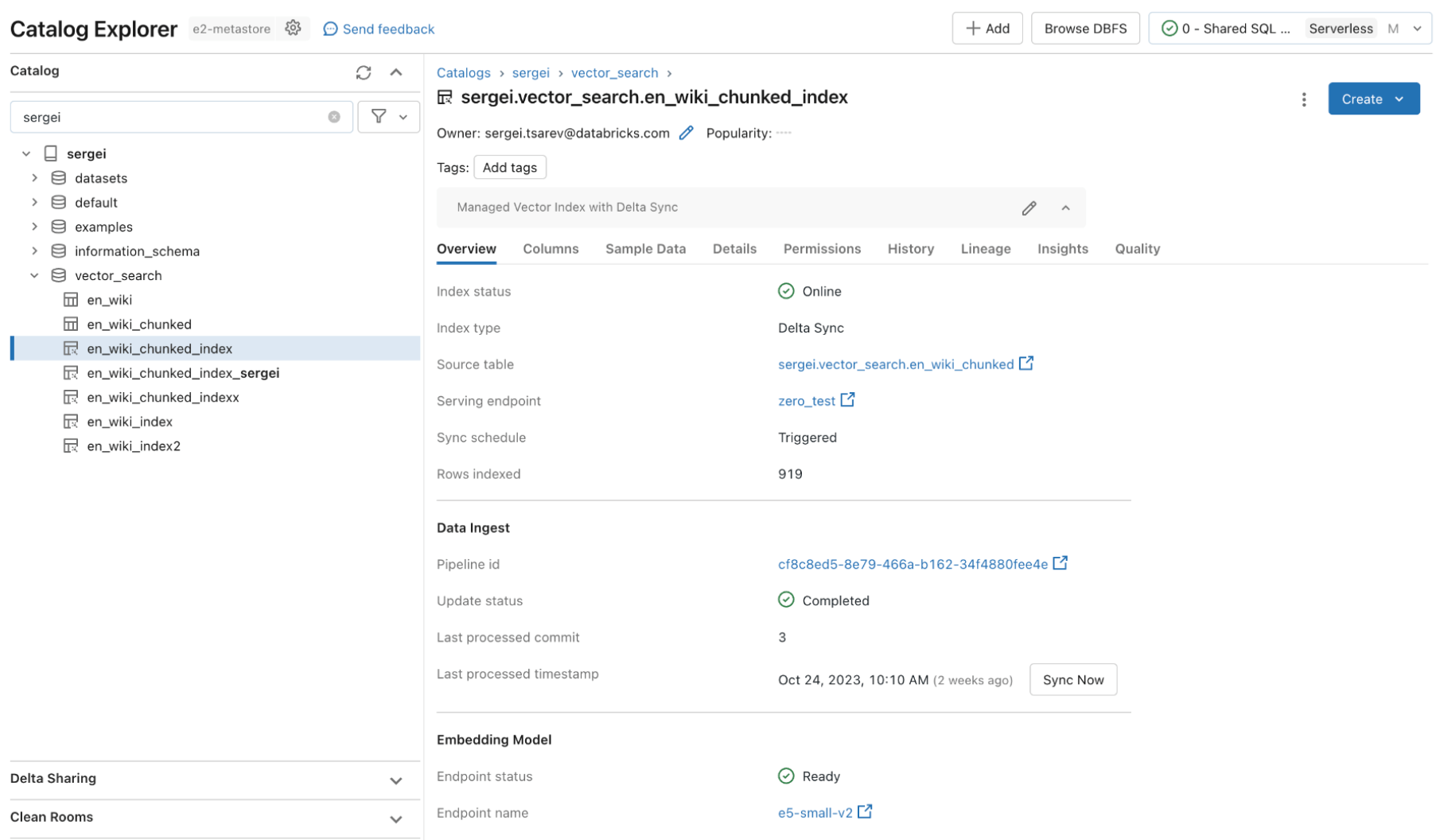
Fast Abfrage, auch Abfrage im Entwicklerkontext Performance
Aufgrund der Marktreife zeigen viele Vektordatenbanken gute Ergebnisse bei Proof of Concept (PoC) (POCs) mit kleinen Datenmengen. Allerdings fehlen sie oft in Leistung oder Skalierbarkeit für Produktionseinsätze. Bei schlechter direkter Leistung müssen Nutzer herausfinden, wie man Suchindizes optimiert und skaliert, was zeitaufwendig und schwer gut zu machen ist. Sie sind gezwungen, ihre Arbeitsbelastung zu verstehen und schwierige Entscheidungen darüber zu treffen, welche compute Instanzen sie wählen und welche Konfiguration sie verwenden.
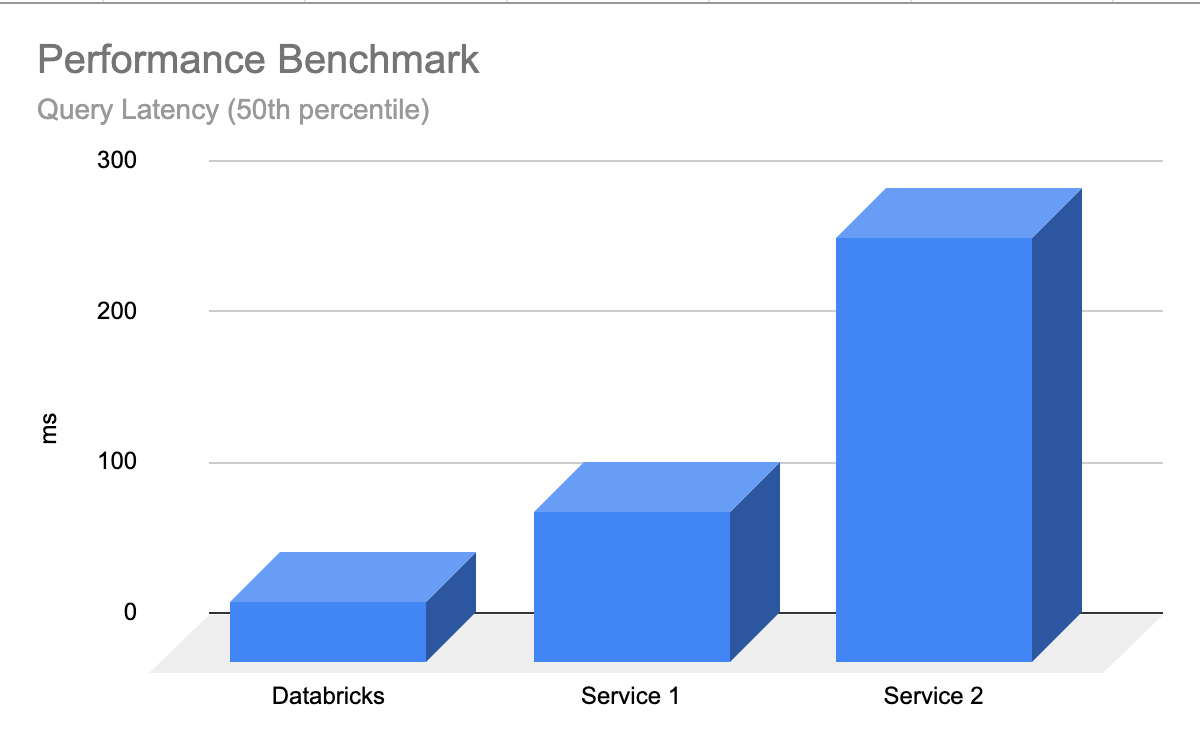
Databricks AI Search ist sofort leistungsfähig, wobei die LLMs relevante Ergebnisse schnell zurückgeben, mit minimaler Latenz und ohne Aufwand, um die Datenbank zu optimieren und zu skalieren. Vektorsuche ist so konzipiert, dass sie für Abfragen und Abfragen im Entwicklerkontext mit oder ohne Filterung extrem schnell ist. Sie zeigt eine bis zu fünfmal bessere Leistung als bei einigen anderen führenden Vektordatenbanken. Es ist einfach zu konfigurieren – Sie nennen uns einfach Ihre erwartete Arbeitslastgröße (z. B. Abfrage, auch Abfrage im Entwicklerkontext pro Sekunde), die benötigte Latenz und die erwartete Anzahl der Embeddings – wir kümmern uns um den Rest. Du musst dir keine Sorgen um Instanztypen, RAM/CPU oder das Verständnis der Funktionsweise von Vektordatenbanken machen.
Wir haben viel Mühe investiert, Databricks AI Search anzupassen, um KI-Workloads zu unterstützen, die bereits Tausende unserer Kunden auf Databricks ausführen. Die Optimierungen umfassten Benchmarking und die Identifizierung der besten Hardware für semantische Suche, die Optimierung des zugrundeliegenden Suchalgorithmus und des Netzwerk-Overheads, um die beste Leistung im Skalenbereich zu erzielen.
Nächste Schritte
Lernen Sie start, indem Sie unsere Dokumentation lesen und speziell einen AI Search-Index erstellen.
Lesen Sie mehr über die Preisevon AI Search
Anfänge mit der Anwendung deiner eigenen RAG Anwendung (Demo)
Melden Sie sich für ein Databricks Generative KI-Webinaran
Möchten Sie Anwendungsfälle für generative KI lösen? Nehmen Sie am Databricks & AWS Generative KI Hackathon teil! Melden Sie sich hieran
Lernweg für generative KI-Ingenieure: Belege selbstgesteuerte, von Lehrkräften geleitete Kurse zu generativer KI im Selbststudium
Lesen Sie die Zusammenfassungsankündigungen, die Anfang dieser Woche gemacht wurden
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.