Erstellen hochwertiger RAG-Anwendungen mit Databricks
Eine neue Tool-Suite, um generative KI-Anwendungen in die Produktion zu bringen
von Patrick Wendell und Hanlin Tang
Retrieval-Augmented-Generation (RAG) hat sich schnell als leistungsstarke Methode etabliert, um proprietäre Echtzeitdaten in Large Language Model (LLM) -Anwendungen zu integrieren. Heute freuen wir uns, eine Suite von RAG-Tools vorzustellen,die Databricks-Benutzer dabei unterstützt, hochwertige, produktionsreife LLM-Anwendungen unter Verwendung ihrer Unternehmensdaten zu erstellen.
LLMs haben einen wichtigen Durchbruch bei der schnellen Entwicklung von Prototypen für neue Anwendungen ermöglicht. Doch nach der Zusammenarbeit mit Tausenden von Unternehmen, die RAG-Anwendungen entwickeln, haben wir festgestellt, dass ihre größte Herausforderung darin besteht, diese Anwendungen auf Produktionsqualität zu bringen. Damit die Qualitätsanforderungen für kundenorientierte Anwendungen erfüllt werden, muss die KI-Ausgabe fehlerfrei, aktuell sowie sicher sein und den Unternehmenskontext berücksichtigen.
Um mit RAG-Anwendungen eine hohe Qualität zu erzielen, benötigen Entwickler umfangreiche Tools zum Verständnis der Qualität ihrer Daten und Modellausgaben sowie eine zugrundeliegende Plattform, mit der sie alle Aspekte des RAG-Prozesses kombinieren und optimieren können. RAG umfasst viele Komponenten, wie z. B. Datenaufbereitung, Abrufmodelle, Sprachmodelle (entweder SaaS oder Open Source), Ranking- und Nachverarbeitungspipelines, Prompt-Engineering und das Trainieren von Modellen mit benutzerdefinierten Unternehmensdaten. Databricks hat sich schon immer darauf konzentriert, Ihre Daten mit modernsten ML-Techniken zu kombinieren. Mit der heutigen Veröffentlichung erweitern wir diese Philosophie, damit Kunden ihre Daten bei der Erstellung hochwertiger KI-Anwendungen nutzen können.
Die heutige Veröffentlichung umfasst die Public Preview von:
- Ein Dienst für die Vektorsuche, der die semantische Suche in bestehenden Tabellen in Ihrem Lakehouse ermöglicht.
- Online- Feature- und Funktions-Serving, um strukturierten Kontext für RAG-Apps verfügbar zu machen.
- Vollständig verwaltete Foundation Models, die Basis-LLMs auf Pay-per-Token-Basis bereitstellen.
- Eine flexible Schnittstelle zum Qualitäts-Monitoring , um die Performance von RAG-Apps in der Produktion zu beobachten.
- Eine Reihe von LLM-Entwicklungstools zum Vergleichen und Bewerten verschiedener LLMs.
Diese Features sollen die drei größten Herausforderungen bei der Erstellung von produktionsreifen RAG-Anwendungen bewältigen:
Herausforderung Nr. 1 – Bereitstellung von Echtzeitdaten für Ihre RAG-App
RAG-Anwendungen kombinieren Ihre neuesten strukturierten und unstrukturierten Daten, um die hochwertigsten und personalisiertesten Antworten zu erzeugen. Die Wartung einer Online-Infrastruktur zur Datenbereitstellung kann jedoch sehr schwierig sein, und Unternehmen mussten in der Vergangenheit mehrere Systeme zusammenfügen und komplexe Datenpipelines unterhalten, um Daten aus zentralen Data Lakes in maßgeschneiderte Bereitstellungsebenen zu laden. Die Sicherung wichtiger Datasets ist ebenfalls sehr schwierig, wenn Kopien über verschiedene Infrastruktur-Stacks verteilt sind.
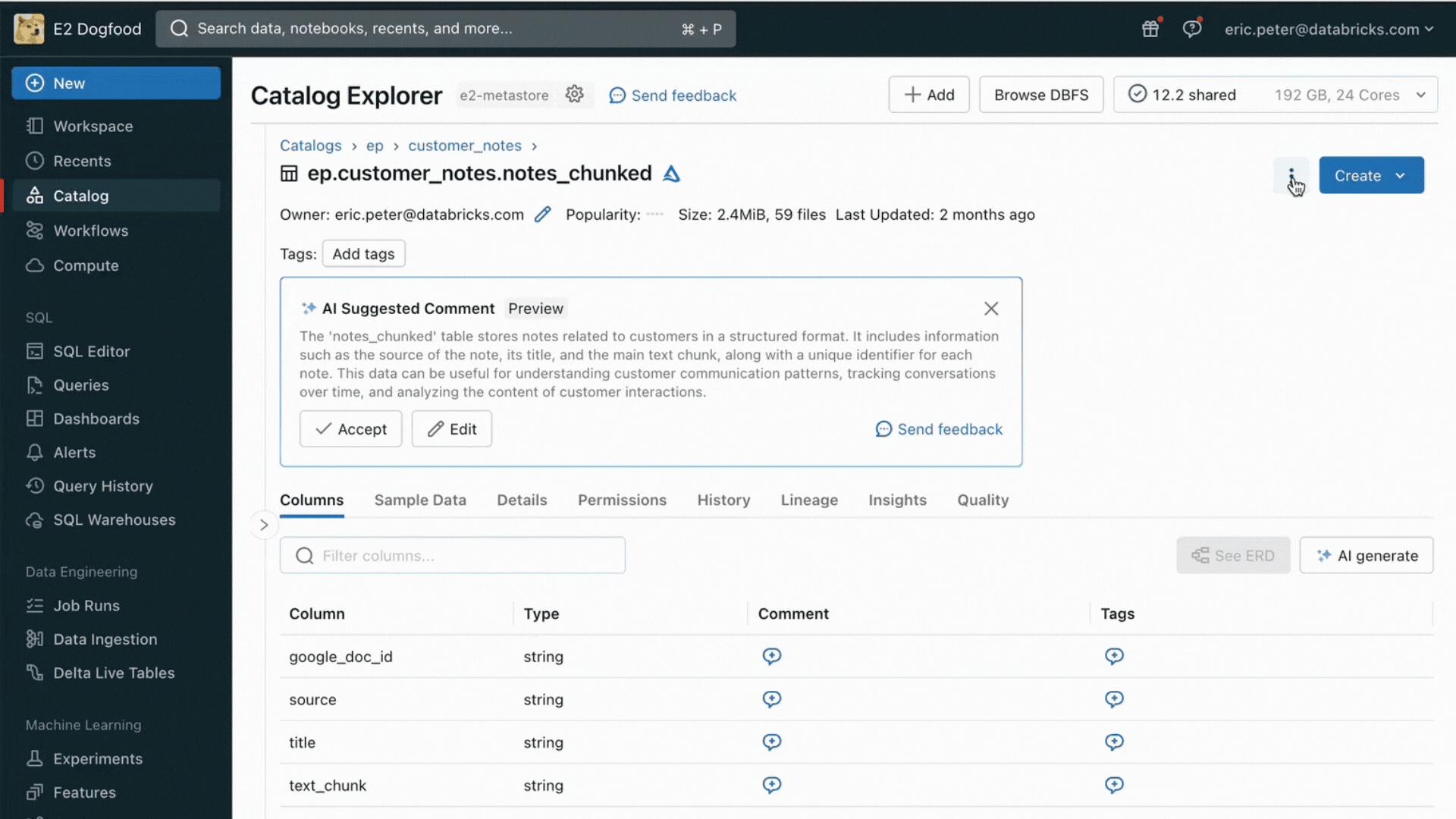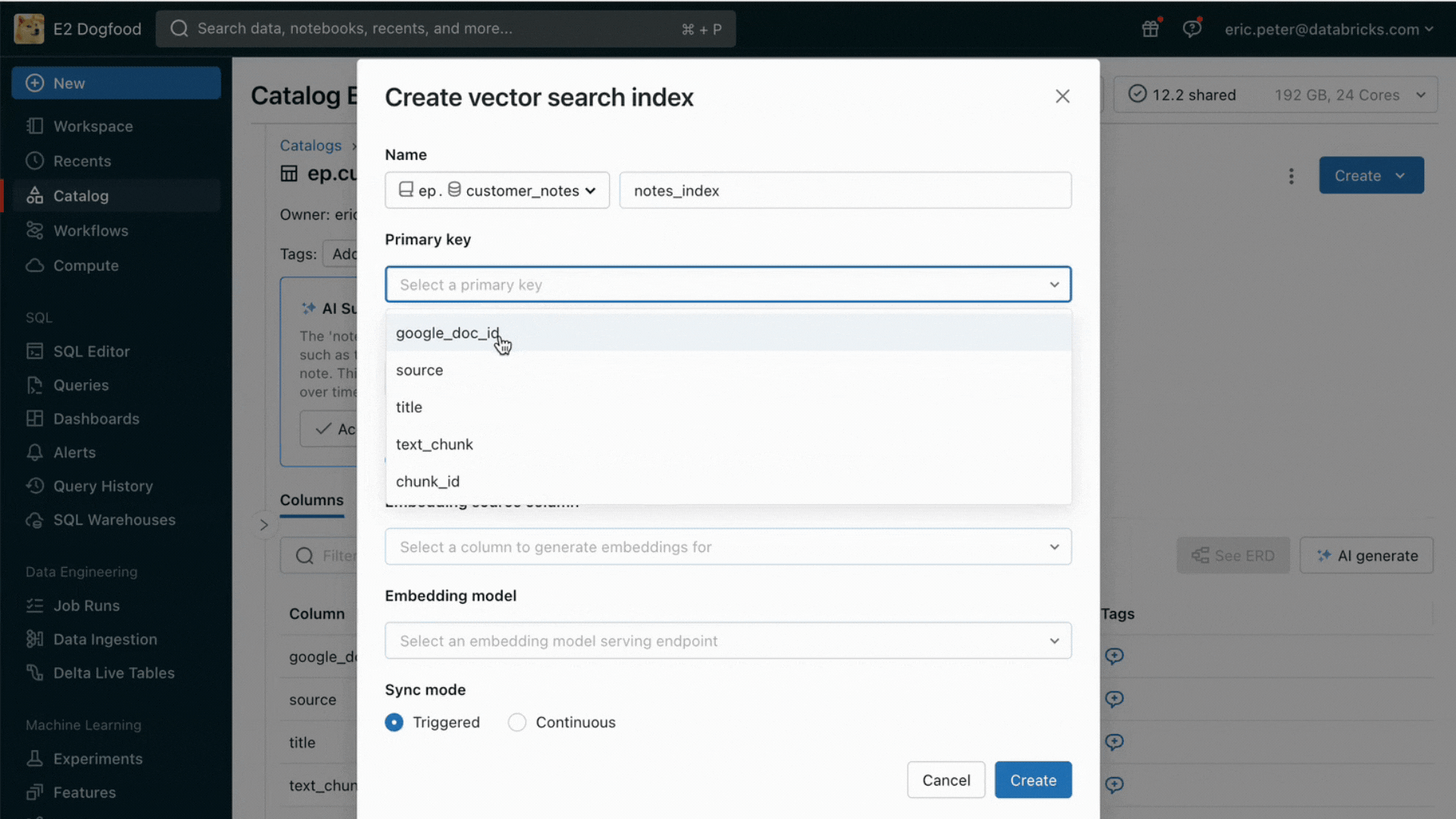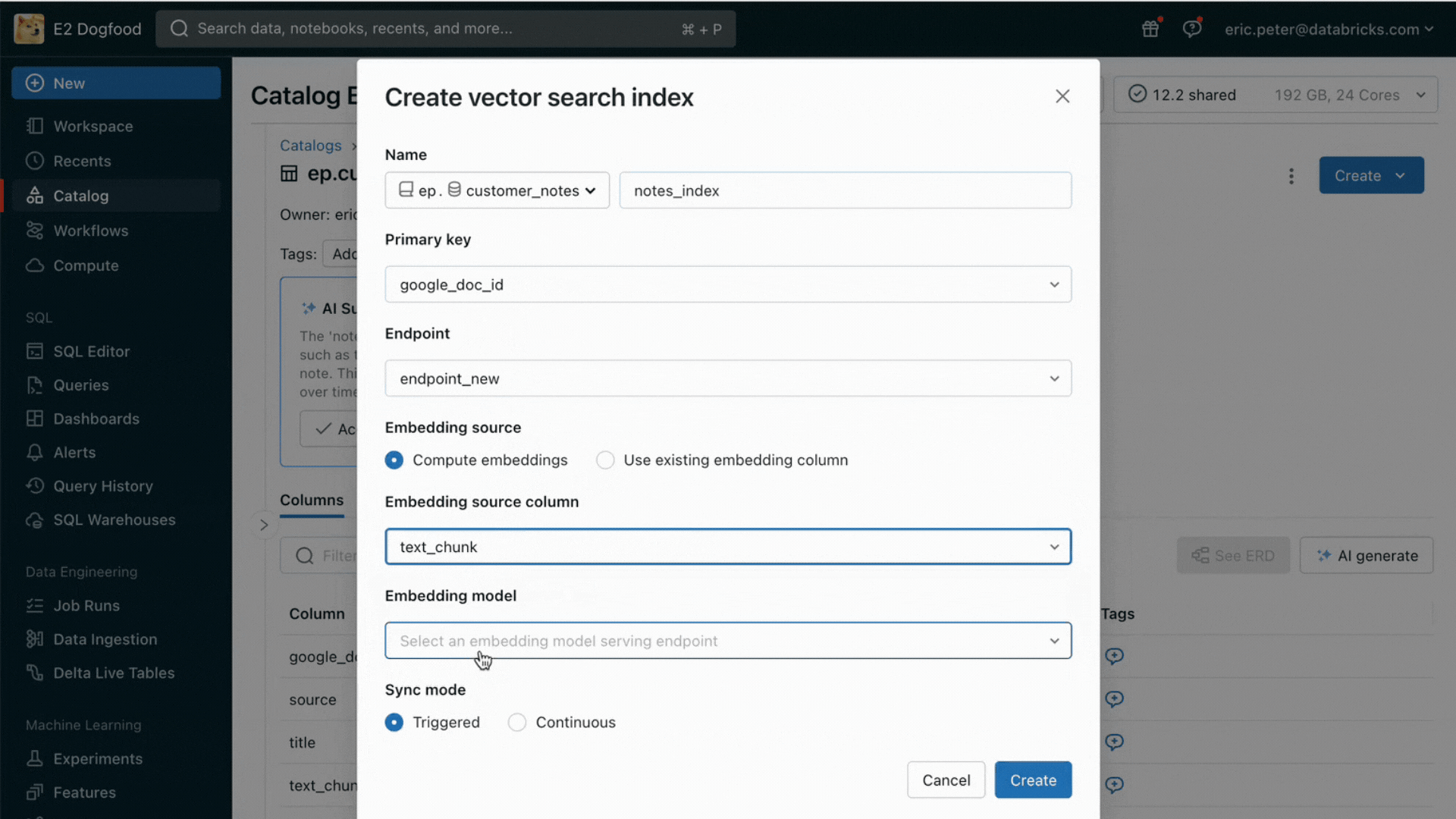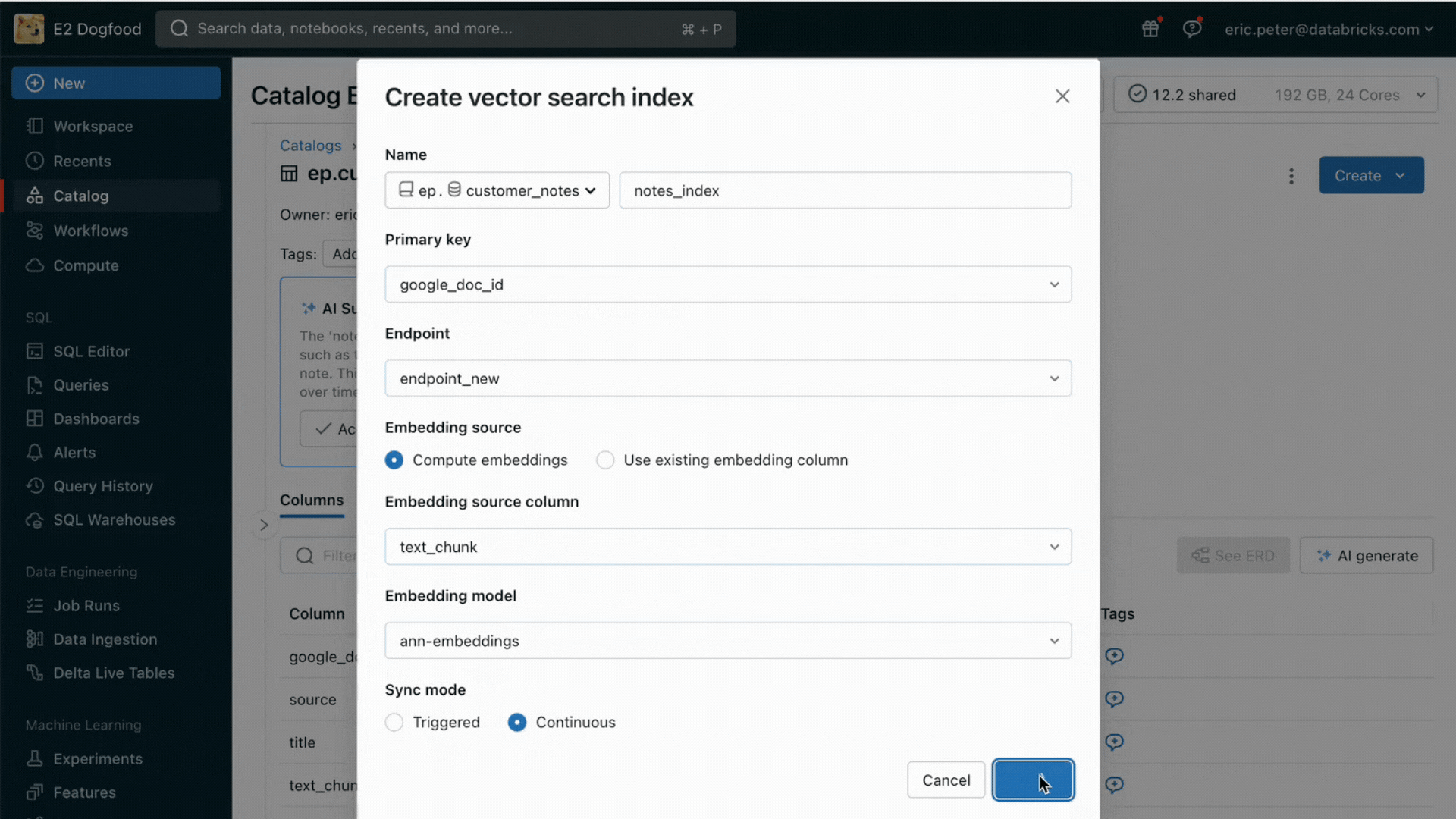
Mit diesem Release unterstützt Databricks nativ das Bereitstellen und Indizieren Ihrer Daten für den Online-Abruf. Für unstrukturierte Daten (Text, Bilder und Videos) indiziert und stellt AI Search automatisch Daten aus Delta-Tabellen bereit und macht sie über eine semantische Ähnlichkeitssuche für RAG-Anwendungen zugänglich. Unter der Haube verwaltet AI Search Ausfälle, behandelt Wiederholungsversuche und optimiert die Batch-Größen, um Ihnen die beste Performance, den besten Durchsatz und die besten Kosten zu bieten. Für strukturierte Daten bietet Feature and Function Serving Abfragen von kontextbezogenen Daten wie Benutzer- oder Account-Daten im Millisekundenbereich, die Unternehmen häufig in Prompts einfügen, um diese auf Grundlage von Benutzer-Informationen anzupassen.
Unity Catalog verfolgt automatisch die Herkunft zwischen den Offline- und Online-Kopien der bereitgestellten Datasets, was das Debugging von Datenqualitätsproblemen erheblich erleichtert. Er erzwingt außerdem konsistent die Einstellungen der Zugriffskontrolle zwischen Online- und Offline-Datasets, sodass Unternehmen besser prüfen und kontrollieren können, wer sensible, geschützte Information einsieht.
Herausforderung Nr. 2 – Vergleich, Abstimmung und Bereitstellung von Basismodellen
Ein entscheidender Faktor für die Qualität einer RAG-Anwendung ist die Wahl des Basis-LLM-Modells. Der Vergleich von Modellen kann schwierig sein, da sich die Modelle in mehreren Dimensionen unterscheiden, z. B. in Bezug auf die Fähigkeit zum logischen Denken, die Neigung zu Halluzinationen, die Größe des Kontextfensters und die Bereitstellungskosten. Einige Modelle können auch für bestimmte Anwendungen feinabgestimmt werden, was die Performance weiter verbessern und die Kosten potenziell senken kann. Da fast wöchentlich neue Modelle veröffentlicht werden, kann der Vergleich von Basismodell-Permutationen zur Auswahl der besten Option für eine bestimmte Anwendung extrem aufwendig sein. Erschwerend kommt hinzu, dass Modellanbieter oft unterschiedliche APIs haben, was einen schnellen Vergleich oder die Zukunftssicherheit von RAG-Anwendungen sehr erschwert.
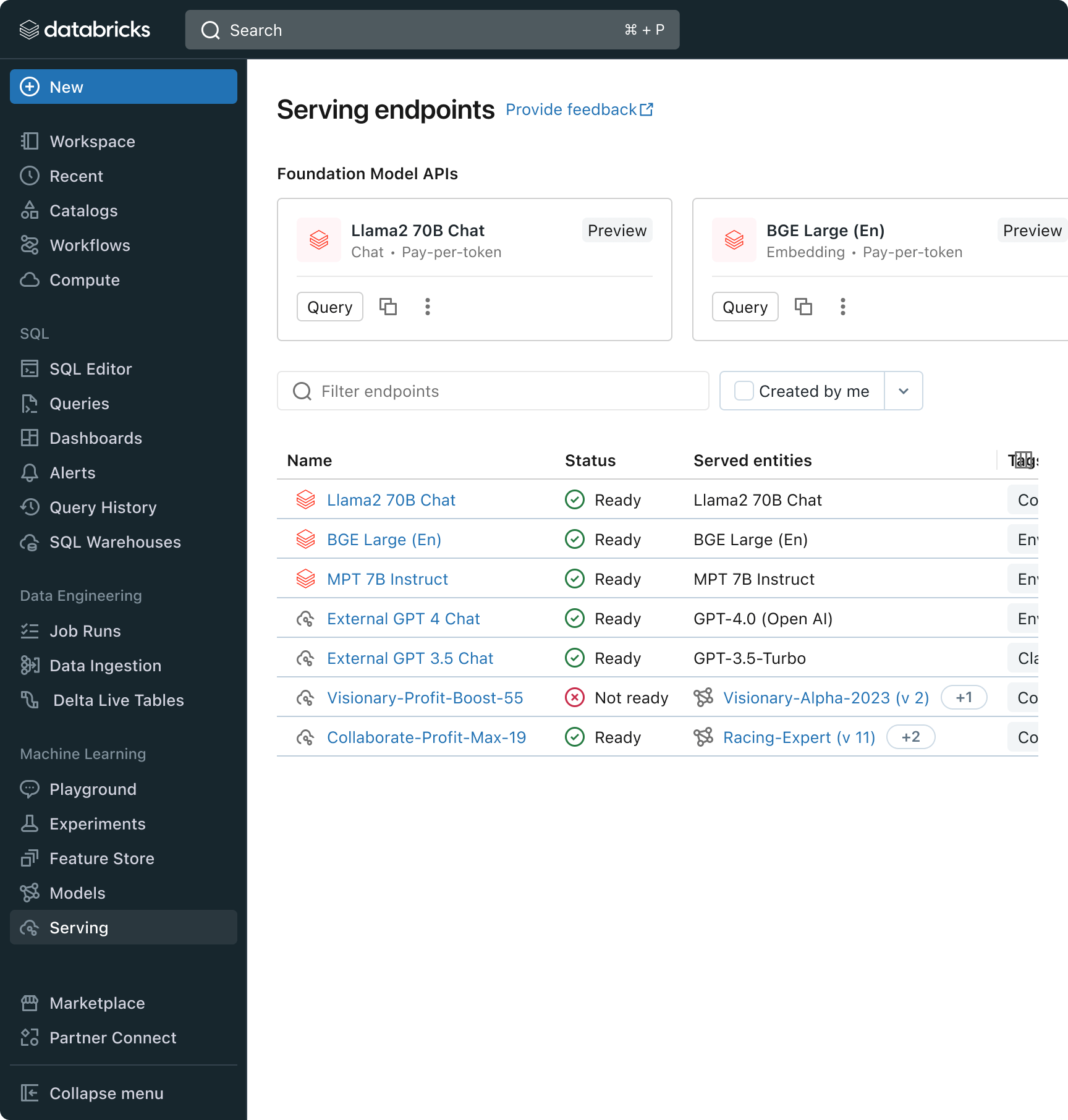
Mit dieser Version bietet Databricks jetzt eine einheitliche Umgebung für die Entwicklung und Evaluierung von LLMsund stellt einen konsistenten Satz von Tools für alle Modellfamilien auf einer cloud-agnostischen Plattform bereit. Databricks-Nutzer können auf führende Modelle von Azure OpenAI Dienst, AWS Bedrock und Anthropic, Open-Source-Modelle wie Llama 2 und MPT oder auf von Kunden feinabgestimmte, vollständig benutzerdefinierte Modelle zugreifen. Der neue interaktive AI Playground ermöglicht einen einfachen Chat mit diesen Modellen, während unsere integrierte Toolchain mit MLflow umfassende Vergleiche durch das Tracking von Key Metriken wie Toxizität, Latenz und Token-Anzahl ermöglicht. Der direkte Modellvergleich im Playground oder in MLflow ermöglicht es Kunden, den besten Modellkandidaten für jeden Anwendungsfall zu identifizieren, und unterstützt sogar die Evaluierung der Retriever-Komponente.
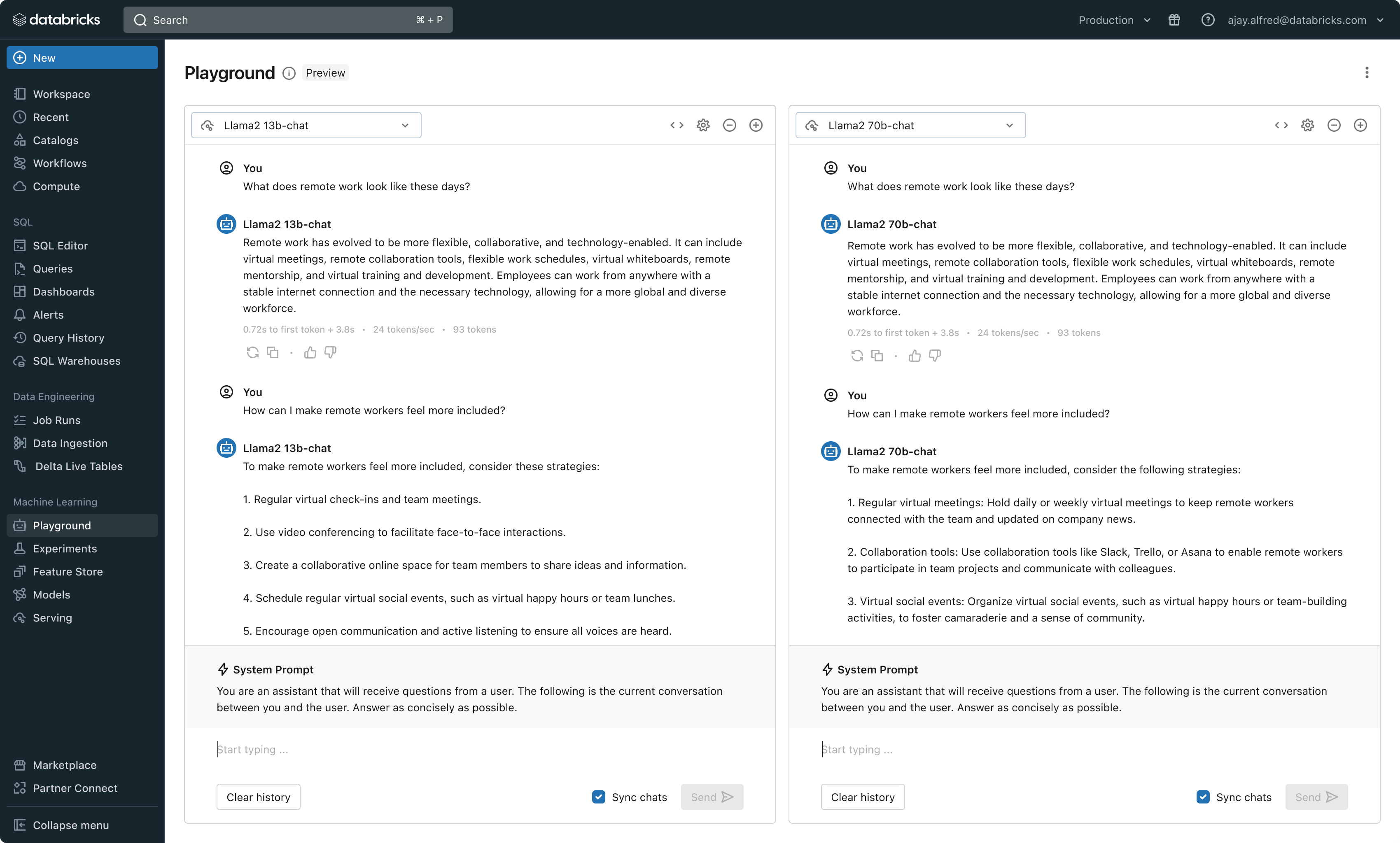
Databricks veröffentlicht außerdem Foundation Model APIs, eine vollständig verwaltete Sammlung von LLM-Modellen, einschließlich der beliebten Llama- und MPT-Modellfamilien. Die Foundation Model APIs können auf Pay-per-Token-Basis genutzt werden, was die Kosten drastisch senkt und die Flexibilität erhöht. Da die Foundation Model APIs aus der Databricks-Infrastruktur heraus bereitgestellt werden, müssen sensible Daten nicht an Drittanbieterdienste übertragen werden.
In der Praxis bedeutet das Erzielen hoher Qualität oft, Basismodelle gemäß den spezifischen Anforderungen jeder Anwendung zu mischen und anzupassen. Die Model Serving -Architektur von Databricks bietet jetzt eine einheitliche Schnittstelle, um jede Art von LLM bereitzustellen, zu steuern und abzufragen, sei es ein vollständig benutzerdefiniertes Modell, ein von Databricks verwaltetes Modell oder ein Foundation Model eines Drittanbieters. Diese Flexibilität ermöglicht es den Kunden, das richtige Modell für den jeweiligen Job auszuwählen und angesichts zukünftiger Fortschritte bei den verfügbaren Modellen zukunftssicher zu sein.
Herausforderung Nr. 3 – Gewährleistung von Qualität und Sicherheit in der Produktion
Sobald eine LLM-Anwendung angewendet wird, kann es schwierig sein zu beurteilen, wie gut sie funktioniert. Im Gegensatz zu herkömmlicher Software gibt es bei sprachbasierten Anwendungen keine einzig richtige Antwort oder offensichtliche „Fehlerbedingungen“. Das bedeutet, dass es nicht trivial ist, die Qualität zu verstehen (Wie gut funktioniert das?) oder zu bestimmen, was eine anomale, unsichere oder toxische Ausgabe ausmacht (Ist das sicher?). Wir bei Databricks haben festgestellt, dass viele Kunden zögern, RAG-Anwendungen einzuführen, da sie unsicher sind, ob sich die Qualität, die sie in einem kleinen internen Prototyp beobachten, auf ihren Scale übertragen lässt.
Dieses Release enthält Lakehouse Monitoring , eine vollständig verwaltete Lösung zur Qualitäts-Monitoring für RAG-Anwendungen. Lakehouse Monitoring scannt die Ausgaben der Anwendung automatisch auf schädliche, halluzinierte oder anderweitig unsichere Inhalte. Diese Daten können dann an Dashboards, Warnmeldungen oder andere nachgelagerte Datenpipelines übertragen werden, um daraufhin Maßnahmen zu ergreifen. Da das Monitoring in die Herkunft von Datasets und Modellen integriert ist, können Entwickler Fehler, die z. B. im Zusammenhang stehen mit, schnell diagnostizieren. veraltete Datenpipelines oder Modelle, deren Verhalten sich unerwartet geändert hat.
Beim Monitoring geht es nicht nur um Sicherheit, sondern auch um Qualität. Lakehouse Monitoring kann Konzepte auf Anwendungsebene integrieren, z. B. Benutzerfeedback im Stil von „Daumen hoch/Daumen runter“ oder sogar abgeleitete Metriken wie die „User Accept Rate“ (wie oft ein Endbenutzer KI-generierte Empfehlungen akzeptiert). Unserer Erfahrung nach stärkt die Messung von End-to-End-Benutzermetriken das Vertrauen von Unternehmen erheblich, dass RAG-Anwendungen in der Praxis gut funktionieren. Monitoring Pipeline werden ebenfalls vollständig von Databricks verwaltet, sodass Entwickler Zeit für ihre Anwendungen aufwenden können, anstatt die Infrastruktur für die Beobachtbarkeit zu verwalten.
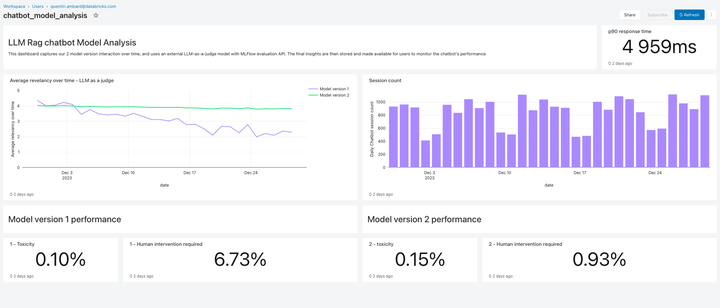
Die Monitoring-Funktionen in diesem Release sind erst der Anfang. Bleiben Sie dran – es folgt noch viel mehr!
Die nächsten Schritte
Wir haben diese und nächste Woche ausführliche Blogartikel, die detailliert auf Best Practices für die Implementierung eingehen. Besuchen Sie also unseren Databricks-Blog, entdecken Sie unsere Produkte mit der neuen RAG-Demo, sehen Sie sich das Databricks Gen KI Webinar on-demand an, nehmen Sie an einem Training zu Gen KI mit unserem Gen KI Engineer Learning Pathway teil und sehen Sie sich eine kurze Videodemo der RAG-Tool-Suite in Aktion an:
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.