Was sind große Sprachmodelle (LLM)?
Neuronale Netze mit Milliarden von Parametern, die anhand massiver Textkorpora mittels selbstüberwachtem Lernen trainiert wurden, sind in der Lage, menschenähnliche Texte für NLP-Aufgaben zu generieren.
- Die Architektur nutzt Transformer-Modelle mit Aufmerksamkeitsmechanismen, die die parallele Verarbeitung von Sequenzen ermöglichen. Diese werden durch die Vorhersage des nächsten Tokens auf Texten im Internetmaßstab mithilfe massiver Rechenressourcen und spezialisierter Hardware (GPUs, TPUs) trainiert.
- Zu den Fähigkeiten gehören Few-Shot- und Zero-Shot-Learning, das sich anhand von Beispielen an neue Aufgaben anpasst, mehrsprachiges Verständnis, Schlussfolgerungen über Kontextfenster mit Tausenden von Tokens sowie neu auftretende Fähigkeiten bei großem Umfang.
- Anwendungsbereiche sind Chatbots, Content-Erstellung, Code-Generierung, Forschungsunterstützung, Sprachübersetzung, Dokumentenzusammenfassung, Stimmungsanalyse und Wissensmanagement in Unternehmen. Dabei ist eine sorgfältige Implementierung erforderlich, die Verzerrungen, Sicherheit und Rechenkosten berücksichtigt.
Was sind Large Language Models (LLMs)?
Sprachmodelle sind eine Art von generativer KI (GenAI), die die Verarbeitung natürlicher Sprache (NLP) nutzen, um menschliche Sprache zu verstehen und zu generieren. Große Sprachmodelle (LLMs) sind die leistungsstärksten von diesen. LLMs werden mithilfe riesiger Datasets und fortschrittlicher Algorithmen für machine learning (ML) trainiert, um die Muster und Strukturen menschlicher Sprache zu erlernen und Textantworten auf schriftliche Aufforderungen zu generieren. Beispiele für LLMs sind BERT, Claude, Gemini, Llama und die GPT-Familie (Generative Pretrained Transformer).
LLMs haben ihre Vorgänger in ihrer Performance bei einer Vielzahl von sprachbezogenen Tasks deutlich übertroffen. Ihre Fähigkeit, komplexe, nuancierte Inhalte zu generieren und Tasks mit menschenähnlichen Ergebnissen zu automatisieren, treibt Fortschritte in verschiedenen Bereichen voran. LLMs werden weithin in die Geschäftswelt integriert, um in einer Vielzahl von Umgebungen und geschäftlichen Anwendungsfällen Wirkung zu erzielen, darunter die Automatisierung des Supports, die Gewinnung von Erkenntnissen und die Erstellung personalisierter Inhalte.
Zu den Kernfunktionen von LLM-KI und Sprache gehören:
- Verstehen natürlicher Sprache: LLMs können die Nuancen der menschlichen Sprache verstehen, einschließlich Kontext, Semantik und Absicht.
- Multimodale Inhaltserstellung: LLMs können menschenähnlichen Text für verschiedene Zwecke erzeugen, vom Programmieren bis zum kreativen Schreiben, sowie Bilder, Sprache und mehr.
- Fragenbeantwortung: LLMs können offene Fragen intelligent beantworten.
- Scale: LLMs können die Funktionen von Grafikprozessoren (GPUs) nutzen, um umfangreiche Tasks effizient zu bewältigen und sich an wachsende Geschäftsanforderungen anzupassen.
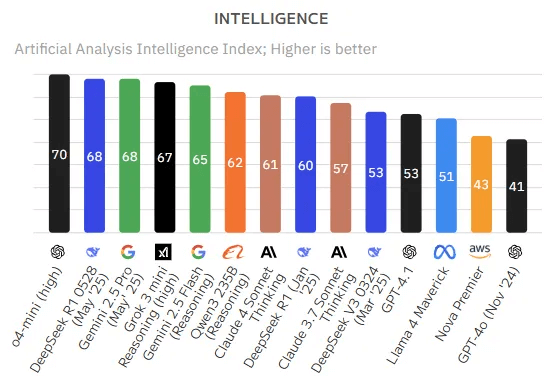
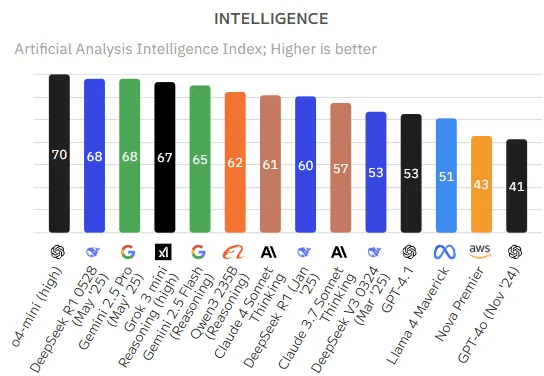
Wie funktionieren LLMs?
Die meisten LLMs basieren auf einer Transformer-Architektur. Sie zerlegen Eingabetext in Tokens (Subwort-Einheiten), betten diese Tokens in numerische Vektoren ein und verwenden Aufmerksamkeitsmechanismen, um Beziehungen innerhalb der Eingabe zu verstehen. Sie sagen dann das nächste Token in einer Sequenz voraus, um kohärente Ausgaben zu generieren.
Was bedeutet es, LLMs vorzutrainieren?
Das Training eines LLM-Modells bezeichnet den Prozess, bei dem es anhand eines großen Datenkorpus, z. B. Text oder Code, trainiert wird, ohne dass dabei Vorwissen oder Gewichtungen aus einem bestehenden Modell verwendet werden. Das Ergebnis des vollständigen Pre-Trainings ist ein Basismodell, das entweder direkt verwendet oder für nachfolgende Aufgaben weiter verfeinert werden kann.
Das Vortraining stellt sicher, dass die Wissensgrundlage des Modells auf Ihre spezifische Domain zugeschnitten ist. Das Ergebnis ist ein benutzerdefiniertes Modell, das sich durch die einzigartigen Daten Ihrer Organisation abhebt. Allerdings ist das Vortraining in der Regel die umfangreichste und teuerste Art des Trainings und für die meisten Organisationen nicht üblich.
Was bedeutet es, LLMs feinabzustimmen?
Unter dem Begriff „Fine-Tuning“ versteht man den Prozess der Anpassung eines vortrainierten LLMs unter Verwendung eines vergleichsweise kleineren Datasets, das konkret auf ein einzelnes Fachgebiet oder eine Aufgabe zugeschnitten ist. Beim Fine-Tuning wird das Training für eine kurze Zeit fortgesetzt, wobei ggf. eine im Vergleich zum Gesamtmodell relativ kleine Anzahl von Gewichtungen angepasst wird.
Die beiden häufigsten Formen des Fine-Tunings sind:
Überwachtes Fine-Tuning von Anweisungen: Dieser Ansatz beinhaltet das Weitertraining eines vortrainierten LLM mit einem Dataset mit (in der Regel mehreren Tausend) Eingabe-Ausgabe-Trainingsbeispielen.
Fortgesetztes Pre-Training: Diese Fine-Tuning-Methode basiert nicht auf Eingabe- und Ausgabebeispielen, sondern verwendet stattdessen domänenspezifischen unstrukturierten Text, um denselben Pre-Training-Prozess fortzusetzen (z. B. die Vorhersage des nächsten Tokens und die Masked-Language-Modellierung).
Fine-Tuning ist wichtig, da es einem Unternehmen ermöglicht, ein Basis-LLM zu nehmen und es mit eigenen Daten zu trainieren, um eine höhere Genauigkeit und Anpassung für die Domäne und die Workloads des Unternehmens zu erreichen. Dadurch haben Sie auch die Kontrolle über die für das Training verwendeten Daten, sodass Sie sicherstellen können, dass Sie KI verantwortungsvoll einsetzen.
Neuronale Netze und Transformer-Architektur
LLMs basieren auf Deep Learning, einer Form der KI, bei der große Datenmengen in ein Programm eingespeist werden, um es auf der Grundlage von Wahrscheinlichkeiten zu trainieren. Dank des Zugriffs auf riesige Datasets können sich LLMs selbst trainieren, Sprachmuster und Zusammenhänge ohne explizite Programmierung zu erkennen und ihre Genauigkeit mit selbstlernenden Mechanismen kontinuierlich zu verbessern.
Die Grundlage von LLMs sind künstliche neuronale Netze, die von der Struktur des menschlichen Gehirns inspiriert sind. Diese Netzwerke bestehen aus miteinander verbundenen Knoten, die in Schichten angeordnet sind, einschließlich einer Eingabeschicht, einer Ausgabeschicht und einer oder mehrerer Schichten dazwischen. Jeder Knoten verarbeitet und überträgt Informationen an die nächste Schicht, basierend auf gelernten Mustern.
LLMs verwenden eine Art von neuronales Netz, das als Transformer-Modell bezeichnet wird. Diese bahnbrechenden Modelle können einen ganzen Satz auf einmal betrachten, im Gegensatz zu älteren Modellen, die Wörter sequenziell verarbeiten. Dadurch können sie Sprache schneller und effizienter verstehen. Transformer-Modelle verwenden ein mathematisches Verfahren namens Self-Attention, das verschiedenen Wörtern in einem Satz eine unterschiedliche Wichtigkeit zuweist, wodurch das Modell Bedeutungsnuancen erfassen und den Kontext verstehen kann. Positionskodierung hilft dem Modell, die Wichtigkeit der Wortreihenfolge in einem Satz zu verstehen, was für das Sprachverständnis unerlässlich ist. Das Transformer-Modell ermöglicht es LLMs, riesige Datenmengen zu verarbeiten, kontextrelevante Informationen zu lernen und kohärente Inhalte zu generieren.
Eine vereinfachte Version des LLM-Trainingsvorgangs

Weitere Informationen zu Transformern, die die Grundlage jedes LLM bilden
Welche Anwendungsfälle gibt es für LLMs?
LLMs unterstützen viele Anwendungsfälle und können das geschäftliche Wachstum von Unternehmen aus verschiedensten Branchen befeuern. Exemplarisch seien genannt:
- Chatbots und virtuelle Assistenten: LLMs werden verwendet, um Chatbots zu betreiben. Hiermit können Kunden und Mitarbeiter offene Dialoge führen, um die Kundenbetreuung zu unterstützen, auf der Website bei Leads nachzufassen und als persönlicher Assistent zu fungieren.
- Erstellung von Inhalten: LLMs können verschiedene Arten von Inhalten generieren, wie zum Beispiel Artikel, Blogposts und Social-Media-Updates.
- Codegenerierung und Debugging: LLMs können nützliche Codefragmente generieren, Fehler im Code erkennen und beheben sowie Programme auf der Grundlage eingegebener Anweisungen vervollständigen.
- Sentimentanalyse: LLMs können automatisch die Stimmung eines Textes erfassen, um die Kundenzufriedenheit zu messen.
- Textklassifizierung und Clustering: LLMs können große Datenmengen organisieren, kategorisieren und sortieren, um Gemeinsamkeiten und Trends zu erkennen, die eine fundierte Entscheidungsfindung unterstützen.
- Sprachübersetzung: LLMs können Dokumente und Webseiten in verschiedene Sprachen übersetzen, um verschiedene Märkte zu erreichen.
- Zusammenfassungen und Paraphrasen: LLMs können Abhandlungen, Artikel, Kundengespräche oder Meetings zusammenfassen und die wichtigsten Punkte herausarbeiten.
- Sicherheit: LLMs können in der Cybersicherheit verwendet werden, um Bedrohungsmuster zu erkennen und Reaktionen zu automatisieren.
Das Playbook für agentenbasierte KI für Unternehmen

Welche Beispiele gibt es, bei denen LLMs von Kunden effektiv eingesetzt wurden?
JetBlue
JetBlue hat „BlueBot“ implementiert. BlueBot ist ein Chatbot, der Open-Source-GenAI-Modelle nutzt und diese – gestützt auf Databricks – mit Unternehmensdaten ergänzt. Dieser Chatbot kann von allen Teams bei JetBlue genutzt werden, um auf Rollenbasis Zugriff auf Daten zu erhalten. So kann beispielsweise das Finanzteam Daten aus SAP und behördliche Unterlagen einsehen, während das Betriebsteam nur Wartungsinformationen erhält.
Chevron Phillips
Chevron Phillips nutzt generative KI-Lösungen, die auf Open-Source-Modellen wie Dolly von Databricks basieren, um die Automatisierung von Dokumentenprozessen zu optimieren. Diese Tools wandeln unstrukturierte Daten aus PDFs und Handbüchern in strukturierte Erkenntnisse um und ermöglichen so eine schnellere und genauere Datenextraktion für den operativen Betrieb und die Market Intelligence. Governance-Richtlinien gewährleisten Produktivität sowie Risikomanagement und erhalten gleichzeitig die Rückverfolgbarkeit.
Thrivent Financial
Thrivent Financial nutzt generative KI und Databricks, um Suchvorgänge zu beschleunigen, klarere und leichter zugängliche Erkenntnisse zu liefern und die Engineering-Produktivität zu steigern. Durch die Zusammenführung von Daten auf einer einzigen Plattform mit rollenbasierter Governance schafft das Unternehmen einen sicheren Bereich, in dem Teams innovativ sein, neue Möglichkeiten erkunden und effizienter arbeiten können.
Warum werden LLMs plötzlich so beliebt?
Es sind vor allem zahlreiche technologische Fortschritte, die LLMs ins Rampenlicht haben rücken lassen:
- Fortschritte bei Technologien für machine learning: LLMs nutzen viele Fortschritte bei ML-Techniken. Am bemerkenswertesten ist die Transformer-Architektur, die den meisten LLMs zugrunde liegt.
- Bessere Zugänglichkeit: Die Veröffentlichung von ChatGPT ermöglichte es jedem mit Internetzugang, über eine einfache Weboberfläche mit einem der fortschrittlichsten LLMs zu interagieren, wodurch die ganze Welt die Leistungsfähigkeit von LLMs verstehen konnte.
- Erhöhte Rechenleistung: Die Verfügbarkeit von leistungsfähigeren Rechenressourcen wie Grafikprozessoren (GPUs) und besseren Datenverarbeitungstechniken ermöglichte es Forschern, wesentlich größere Modelle zu trainieren.
- Quantität und Qualität der Trainingdaten: Die Verfügbarkeit großer Datasets und die Fähigkeit, diese zu verarbeiten, haben die Performance drastisch verbessert. GPT-3 wurde beispielsweise mit Big Data (ca. 500 Mrd. Tokens) trainiert, die auch kleinere hochwertige Datasets wie das WebText2-Dataset (17 Mio. Dokumente) umfassten, das öffentlich gecrawlte Webseiten mit Schwerpunkt auf Qualität enthält.
Wie kann ich ein LLM mit den Daten meines Unternehmens anpassen?
Bei der Anpassung einer LLM-Anwendung an die Daten Ihres Unternehmens sind vier Architekturmuster zu berücksichtigen. Diese Techniken werden im Folgenden beschrieben und schließen sich nicht gegenseitig aus. Vielmehr können (und sollten) sie kombiniert werden, um die Stärken einer jeden zu nutzen.
Unabhängig von der gewählten Technik stellt der Aufbau einer gut strukturierten und modularisierten Lösung sicher, dass Unternehmen nach Bedarf iterieren und Anpassungen vornehmen können. Erfahren Sie mehr über diesen Ansatz und vieles mehr in The Big Book of Generative KI.
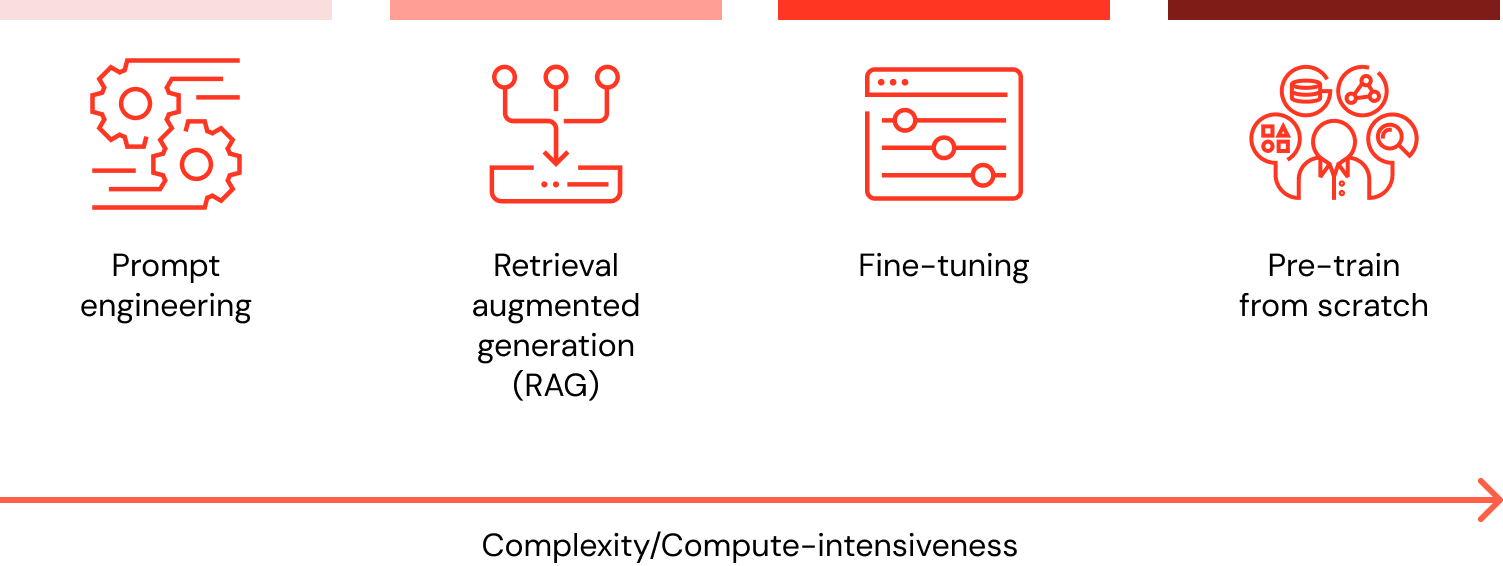
| Methode | Definition | Primärer Anwendungsfall | Datenanforderungen | Vorteile | Überlegungen |
|---|---|---|---|---|---|
| Formulierung spezieller Prompts zur Steuerung des LLM-Verhaltens | Schnelle, spontane Modellführung | N/A | Schnell, kostengünstig, kein Training erforderlich | Weniger Kontrolle als beim Fine-Tuning | |
| Kombiniert ein LLM mit externem Wissensabruf | Dynamische Datasets und externes Wissen | Externe Wissensbasis oder Datenbank (z. B. Vektordatenbank) | Dynamisch aktualisierter Kontext, höhere Fehlerfreiheit | Verlängert den Prompt und die Inferenzberechnung | |
| Passt ein vortrainiertes LLM an spezifische Datasets oder Fachgebiete an | Fach- oder Aufgabenspezialisierung | Tausende fachspezifische Beispiele oder Anleitungen | Granulare Kontrolle, hoher Spezialisierungsgrad | Erfordert gelabelte Daten und hohen Rechenaufwand | |
| Training eines LLM von Grund auf | Individuelle Aufgaben oder fachspezifische Korpora | Große Datasets (Milliarden oder Billionen Tokens) | Maximale Kontrolle, maßgeschneidert für hochspezielle Anforderungen | Äußerst ressourcenintensiv |

{kind=link}
Was bedeutet Prompt-Engineering im Zusammenhang mit LLMs?
Unter Prompt Engineering versteht man die Anpassung der Text-Prompts, die einem LLM gegeben werden, mit dem Ziel, korrektere oder relevantere Antworten zu erhalten. Nicht jedes LLM-Modell liefert die gleiche Qualität, da das Prompt Engineering modellspezifisch ist. Nachfolgend finden Sie einige allgemeine Tipps, die für eine Vielzahl von Modellen funktionieren:
- Verwenden Sie klare und prägnante Prompts, die beispielsweise eine Anweisung, ggf. einen Kontext, eine Benutzerabfrage oder -eingabe und eine Beschreibung des gewünschten Ausgabetyps oder -formats enthalten.
- Geben Sie in Ihrem Prompt ein paar Beispiele an, damit das LLM versteht, was Sie von ihm wollen (dies bezeichnet man als „Few-Shot Learning“).
- Sagen Sie dem Modell, wie es sich verhalten soll, z. B. dass es eingestehen soll, eine Frage nicht beantworten zu können.
- Weisen Sie das Modell an, Schritt für Schritt zu denken oder seine Beweggründe zu erklären.
- Wenn Ihr Prompt Benutzereingaben enthält, sollten Sie Techniken anwenden, die das Hacken von Prompts verhindern. Hierzu können Sie beispielsweise deutlich machen, welche Teile des Prompts Ihre Anweisungen und welche Benutzereingaben sind.
Was bedeutet Retrieval Augmented Generation (RAG) in Bezug auf LLMs?
Retrieval-Augmented Generation, oder RAG, ist ein Architekturansatz, der die Wirksamkeit von LLM-Anwendungen durch die Nutzung benutzerdefinierter Daten verbessern kann. Zu diesem Zweck werden Daten und/oder Dokumente, die für eine Frage oder Aufgabe relevant sind, abgerufen und als Kontext für das LLM bereitgestellt. RAG hat sich bei der Unterstützung von Chatbots und Q&A-Systemen, die aktuelle Informationen bereithalten oder auf fachspezifisches Wissen zugreifen müssen, als erfolgreich erwiesen.
Weitere Informationen zu RAG finden Sie hier.
Welche LLMs sind am verbreitetsten und wie unterscheiden sie sich?
Das Feld der LLMs ist dicht besetzt und bietet viele Optionen zur Auswahl. Grundsätzlich lassen sich LLMs in zwei Kategorien einteilen: proprietäre Dienste und Open-Source-Modelle.
Proprietäre Modelle
Proprietäre LLM-Modelle werden von privaten Unternehmen entwickelt, sind deren Eigentum und erfordern für den Zugriff in der Regel Lizenzen. Das wohl bekannteste proprietäre LLM ist GPT-4o, das ChatGPT antreibt und 2022 mit viel Tamtam veröffentlicht wurde. ChatGPT bietet eine benutzerfreundliche Suchoberfläche, auf der die Benutzer Prompts eingeben können und dann normalerweise schnell eine relevante Antwort erhalten. Entwickler können auf die ChatGPT-API zugreifen, um dieses LLM in eigene Anwendungen, Produkte oder Dienste zu integrieren. Weitere proprietäre Modelle sind zum Beispiel Gemini von Google und Claude von Anthropic.
Open-Source-Modelle
Eine andere Möglichkeit besteht darin, selbst ein LLM zu hosten. Hierzu wird in der Regel ein Modell verwendet, das quelloffen und für eine kommerzielle Nutzung verfügbar ist. Die Open-Source-Community hat leistungstechnisch schnell mit den proprietären Modellen gleichgezogen. Zu den beliebten Open-Source-LLM-Modellen gehören Llama 4 von Meta und Mixtral 8x22B.
Wie Sie die beste Wahl treffen
Die wichtigsten Überlegungen und Unterschiede in der Herangehensweise zwischen der Nutzung der API eines Drittanbieters mit geschlossenem Modell und dem Hosten eines eigenen quelloffenen (oder individuell angepassten) LLM sind Zukunftssicherheit, Kostenkontrolle und die Nutzung Ihrer Daten als Wettbewerbsvorteil. Proprietäre Modelle können veralten oder entfernt werden, wodurch Ihre bestehenden Pipelines und Vektorindizes zunichtegemacht werden. Dagegen bleiben Open-Source-Modelle für immer zugänglich. Ferner bieten quelloffene und feinabgestimmte Modelle mehr Auswahl und ermöglichen eine bessere Anpassung an Ihre Anwendung. So profitieren Sie von einem besseren Preis-Leistungs-Verhältnis. Wenn Sie ein künftiges Fine-Tuning Ihrer eigenen Modelle planen, können Sie die Daten Ihres Unternehmens als Wettbewerbsvorteil nutzen, um Modelle zu erstellen, die besser sind als die öffentlich verfügbaren. Schließlich können bei Nutzung proprietärer Modelle Governance-Bedenken entstehen, da solche „Blackbox-LLMs“ weniger Kontrolle über Trainingsverfahren und Gewichtungen bieten.
Das Hosten eines eigenen Open-Source-LLM ist arbeitsaufwendiger als die Nutzung proprietärer LLMs. Mit MLflow von Databricks wird es für Nutzer mit Python-Erfahrung einfacher, ein beliebiges Transformer-Modell auszuwählen und als Python-Objekt zu verwenden.
Wie wähle ich aus, welches LLM ich verwenden soll?
Die Evaluierung von LLMs ist ein anspruchsvoller Bereich, der vor allem deswegen ständigen Veränderungen unterworfen ist, weil LLMs bei verschiedenen Aufgaben oft uneinheitliche Fähigkeiten aufweisen. Ein LLM mag bei einem Benchmark hervorragend abschneiden, aber bereits geringfügige Abweichungen beim Prompt oder dem zu lösenden Problem können die Leistung drastisch beeinflussen.
Nachfolgend aufgeführt sind einige bekannte Tools und Benchmarks, die zur Bewertung der Leistung von LLMs verwendet werden:
- MLflow
- Bietet eine Reihe von LLMOps-Tools für die Modellbewertung.
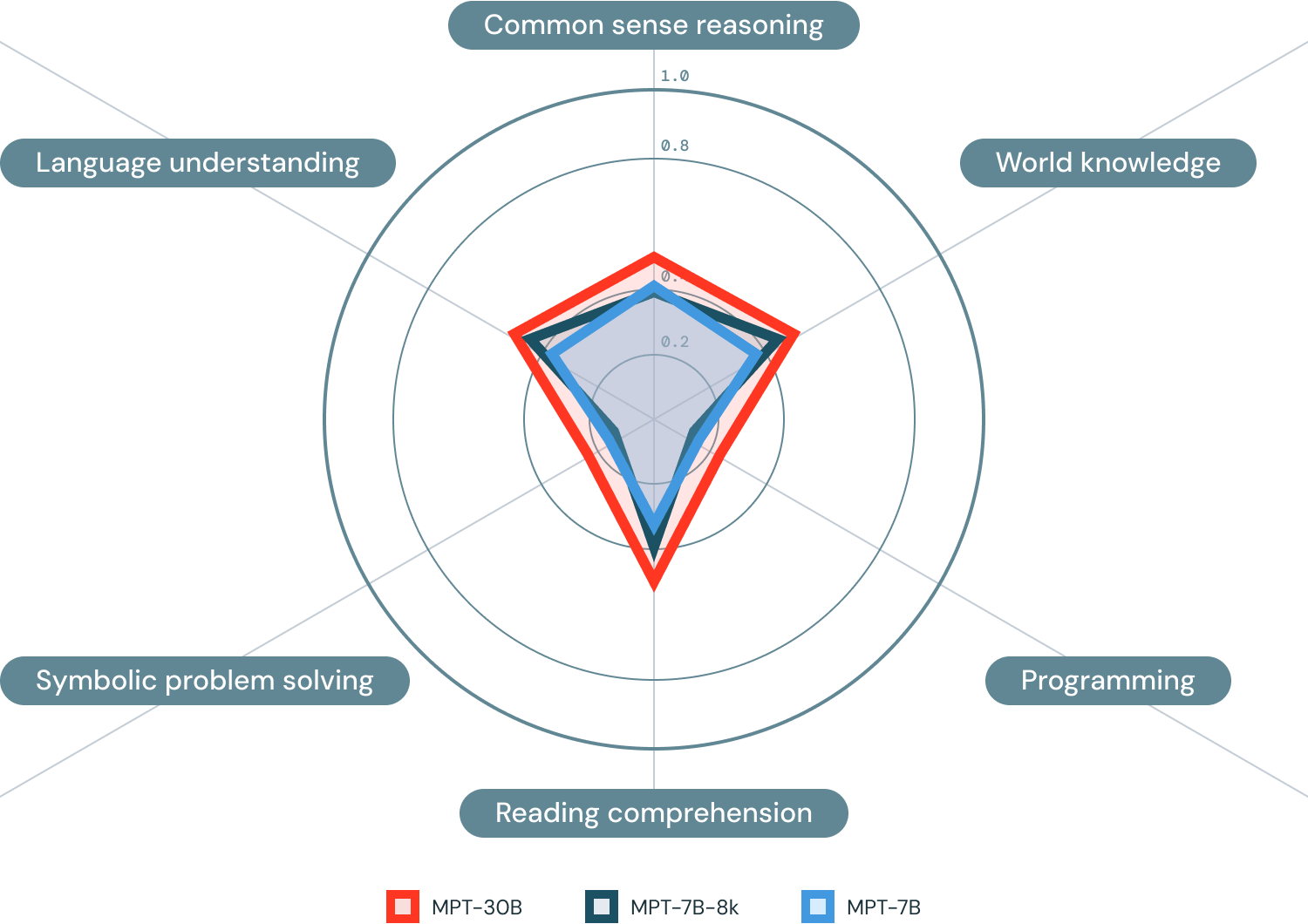
- Mosaic Model Gauntlet
- Ein aggregierter Bewertungsansatz, bei dem, statt auf eine einzige monolithische Metrik zu destillieren, die Modellkompetenz in sechs allgemeine Fachgebiete (siehe unten) unterteilt wird.
- Hugging Face führt Hunderttausende von Modellen von Anbietern offener LLMs zusammen
- BIG-bench (Beyond the Imitation Game-Benchmark)
- Ein dynamisches Benchmarking-Framework, das derzeit über 200 Aufgaben enthält. Der Schwerpunkt liegt dabei auf der Anpassung an künftige LLM-Funktionen.
- EleutherAI LM Evaluation Harness
- Ein ganzheitliches Framework, das Modelle anhand von mehr als 200 Aufgaben bewertet und dabei Evaluierungen wie BIG-bench und MMLU zusammenführt, um Reproduzierbarkeit und Vergleichbarkeit zu fördern.
Lesen Sie auch die Best Practices für die LLM-Auswertung von RAG-Anwendungen.
Wie operationalisiert man das Management von LLMs mithilfe von Large Language Model Ops?
Large Language Model Operations (LLMOps) ist eine Bezeichnung für Praktiken, Verfahren und Tools, die für das betriebliche Management von Large Language Models (LLMs) in Produktionsumgebungen eingesetzt werden.
LLMOps ermöglicht die effiziente Bereitstellung, Monitoring und Wartung von LLMs. Ähnlich wie traditionelles Machine Learning Ops (MLOps) erfordert LLMOps eine Zusammenarbeit von Data Scientists, DevOps Engineers und IT-Fachkräften. Ausführliche Informationen zu LLMOps finden Sie hier.
Wo finde ich weitere Informationen über Large Language Models?
Es gibt viele Ressourcen mit ausführlichen Informationen zu LLMs, beispielsweise die folgenden:
Weiterbildung
- LLMs: Foundation Models From the Ground Up (Schulung von EDX und Databricks): Kostenlose Schulung von Databricks, die sich den Details der Grundlagenmodelle in LLMs widmet
- LLMs: Application Through Production (Schulung von EDX und Databricks): Kostenlose Schulung von Databricks, die sich schwerpunktmäßig mit der Erstellung von LLM-Anwendungen unter Verwendung der neuesten und bekanntesten Frameworks befasst
E-Books
- Das Big Book der GenAI
- Kompaktleitfaden zum Erstellen und Optimieren individueller LLMs
- Ein Kompaktleitfaden zu Large Language Models
Technische Blogs
- Wir stellen vor: Llama 4 von Meta auf der Databricks Data Intelligence Platform | Databricks-Blog
- Bereitstellen von Qwen-Modellen auf Databricks | Databricks-Blog
- Best Practices für die LLM-Auswertung von RAG-Anwendungen
- Mit MLflow AI Gateway und Llama 2 Apps für generative KI entwickeln
- Erstellen Sie hochwertige RAG-Apps mit dem Agent Bricks Custom Agents, Agent Evaluation, Model Serving und AI Search.
- LLMOps: Alles was Sie zum Verwalten von LLMs wissen müssen
Die nächsten Schritte
- Setzen Sie sich mit Databricks in Verbindung, um einen Termin für eine Demo zu vereinbaren und mit einem Mitarbeiter über Ihre LLM-Projekte zu sprechen.
- Erfahren Sie mehr über die Databricks-Angebote für LLMs.
- Informieren Sie sich über den RAG-Anwendungsfall (Retrieval Augmented Generation) – die häufigste LLM-Architektur.
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.