Was ist LLMOps?
Praktiken und Werkzeuge für die Entwicklung, den Einsatz und die Verwaltung von LLMs im Produktivbetrieb, einschließlich Feinabstimmung, schneller Entwicklung, Evaluierung und KI-Governance
- Behandelt LLM-spezifische Workflows, einschließlich der Auswahl von Basismodellen, Feinabstimmungsstrategien (Full Fine-Tuning, PEFT, LoRA), Prompt Engineering, Retrieval-Augmented Generation (RAG)-Pipelines und der Orchestrierung von Multi-Modell-Ensembles.
- Implementiert Evaluierungsframeworks zur Messung der Modellleistung anhand von Metriken (Perplexität, BLEU, ROUGE, menschliches Feedback), A/B-Tests, Red-Teaming zur Sicherheitsprüfung, Bias-Erkennung und Prompt-Optimierung durch systematische Experimente.
- Überwacht Produktionsumgebungen hinsichtlich Inferenzlatenz, Token-Verbrauchskosten, Abweichungen in der Ausgabequalität, Toxizitätswerten und Benutzerzufriedenheit und verwaltet gleichzeitig Modellversionierung, Rollback-Funktionen und die Einhaltung von KI-Governance-Richtlinien.
Was ist LLMOps?
Large Language Model Operations (LLMOps) ist eine Bezeichnung für Praktiken, Verfahren und Tools, die für das betriebliche Management von Large Language Models (LLMs) in Produktionsumgebungen eingesetzt werden.
Die jüngsten Fortschritte bei LLMs, die durch Veröffentlichungen wie GPT von OpenAI, Bard von Google und Dolly von Databricks untermauert werden, führen gegenwärtig zu einem erheblichen Wachstum bei Unternehmen, die LLMs entwickeln und einsetzen. Das hat dazu geführt, dass wir Best Practices für die Operationalisierung solcher Modelle entwickeln müssen. LLMOps gestattet die effiziente Implementierung, Kontrolle und Pflege von Large Language Models. Ähnlich wie traditionelles Machine Learning Ops (MLOps) erfordert LLMOps eine Zusammenarbeit von Data Scientists, DevOps Engineers und IT-Fachkräften. Hier erfahren Sie, wie Sie in Zusammenarbeit mit uns eigene LLMs erstellen können.
Large Language Models (LLMs) stellen eine neue Klasse von Modellen für die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) dar, die bei einer Reihe von Aufgaben – von der Beantwortung offener Fragen über Zusammenfassungen bis hin zum Befolgen nahezu willkürlicher Anweisungen – den bisherigen Stand der Technik deutlich hinter sich gelassen haben. Die operativen Anforderungen von MLOps entsprechen in der Regel auch denen von LLMOps, aber es gibt Herausforderungen bei Training und Implementierung von LLMs, die einen individuellen LLMOps-Ansatz erfordern.
Wie unterscheidet sich LLMOps von MLOps?
Für die Abstimmung von MLOps-Praktiken müssen wir überlegen, wie sich Arbeitsabläufe und Anforderungen des maschinellen Lernens (ML) mit LLMs ändern. Die wichtigsten Aspekte sind dabei folgende:
- Datenverarbeitungsressourcen: Training und Feinabstimmung von LLMs erfordern in der Regel um mehrere Größenordnungen umfangreichere Berechnungen mit großen Datasets. Zur Beschleunigung dieses Vorgangs wird spezielle Hardware wie GPUs für einen deutlich schnelleren datenparallelen Betrieb eingesetzt. Der Zugriff auf diese Datenverarbeitungsressourcen ist für das Training wie auch für die Implementierung von LLMs von entscheidender Bedeutung. Zudem können Inferenzkosten Komprimierungs- und Destillierverfahren für die Modelle wichtig machen.
- Transfer Learning: Anders als zahlreiche herkömmliche ML-Modelle, die von Grund auf neu erstellt oder trainiert werden, steht am Anfang eines LLM häufig ein Grundmodell, das dann mit neuen Daten verfeinert wird, um die Performance in einem ganz konkreten Bereich zu verbessern. Solche Feinabstimmungen ermöglichen für bestimmte Anwendungen eine Leistung nach dem Stand der Technik – mit weniger Daten und weniger Datenverarbeitungsressourcen.
- Menschliches Feedback: Eine der größten Verbesserungen beim Training von LLMs ist RLHF (Reinforcement Learning from Human Feedback, verstärkendes Lernen durch menschliches Feedback). Generell gilt: Da LLM-Aufgaben häufig ergebnisoffen sind, ist das menschliche Feedback der Endbenutzer Ihrer Anwendung oft entscheidend für die Bewertung der LLM-Performance. Die Integration einer solchen Feedbackschleife in Ihre LLMOps-Pipelines vereinfacht die Beurteilung und stellt gleichzeitig Daten zur künftigen Feinjustierung Ihrer LLM bereit.
- Hyperparameter-Tuning: Beim klassischen maschinellen Lernen geht es beim Hyperparameter-Tuning oft um die Senkung der Fehlerrate oder die Verbesserung anderer Metriken. Für LLMs ist das Tuning außerdem wichtig, um die Kosten und den Datenverarbeitungsbedarf für Training und Inferenz zu reduzieren. Beispielsweise kann die Optimierung von Batch-Größen und Lernraten einen dramatischen Einfluss auf Trainingsgeschwindigkeit und -kosten haben. Somit profitieren sowohl klassische ML-Modelle als auch LLMs von der Überwachung und Optimierung des Tunings, wenn auch mit unterschiedlichen Schwerpunkten.
- Performancemetriken: Herkömmliche ML-Modelle verfügen über sehr klar definierte Performancemetriken wie Fehlerfreiheit, AUC, F1-Score usw. Diese Metriken sind ziemlich einfach zu berechnen. Wenn es um die Bewertung von LLMs geht, gelten jedoch ganz andere Standardmetriken und -bewertungen, z. B. Bilingual Evaluation Understudy (BLEU) und Recall-Oriented Understudy for Gisting Evaluation (ROUGE), die bei der Implementierung einige zusätzliche Überlegungen erfordern.
- Prompt Engineering: Modelle, die Anweisungen befolgen, können komplexe Prompts (d. h. Anweisungsblöcke) verarbeiten. Das Entwickeln und Pflegen dieser Prompt-Vorlagen – das so genannte Engineering – ist entscheidend, um von LLMs fehlerfreie und belastbare Antworten zu erhalten. Prompt-Engineering kann sowohl das Risiko von Modellhalluzinationen senken als auch dazu beitragen, Prompt-Hacks wie Prompt Injection, das Abfließen sensibler Daten und Jailbreaking zu vermeiden.
- Erstellen von LLM-Chains oder -Pipelines: LLM-Pipelines, die mit Tools wie LangChain oder LlamaIndex erstellt werden, reihen mehrere LLM-Aufrufe und/oder Aufrufe externer Systeme wie Vektordatenbanken oder Websuche aneinander. Diese Pipelines ermöglichen den Einsatz von LLMs für komplexe Aufgaben wie die Informationssuche in Wissensdatenbanken oder das Beantworten von Benutzerfragen auf Grundlage einer Dokumentation. Die LLM-Anwendungsentwicklung befasst sich vorrangig mit dem Aufbau dieser Pipelines und nicht mit der Entwicklung neuer LLMs.
Warum brauchen wir LLMOps?
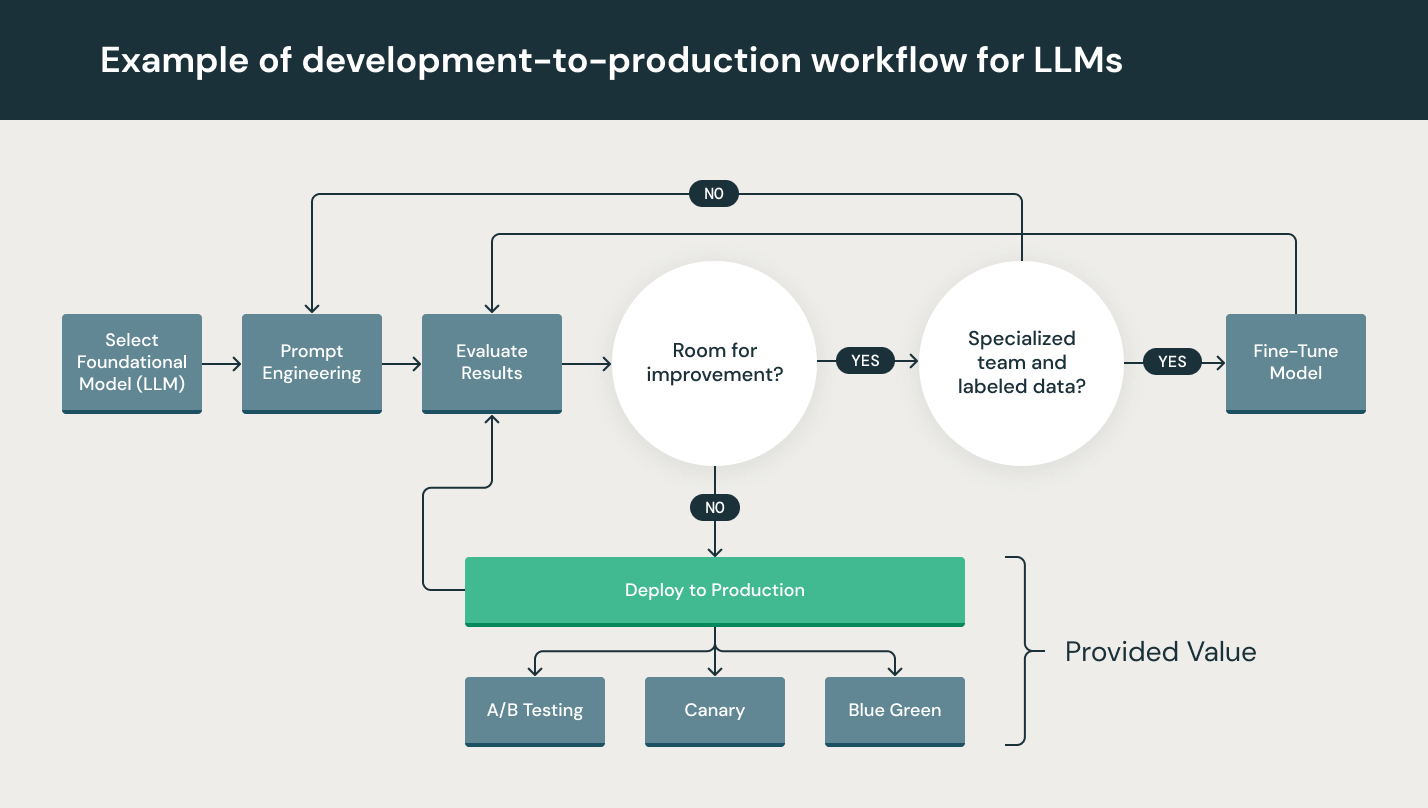
Auch wenn sich LLMs beim Prototyping besonders einfach einsetzen lassen, stellt die Nutzung eines LLM in einem kommerziellen Produkt immer noch eine besondere Herausforderung dar. Der LLM-Entwicklungszyklus umfasst viele komplex Teilschritte wie Datenerfassung, Datenaufbereitung, Prompt Engineering, Modelloptimierung, Modellimplementierung, Modellüberwachung usw. Er erfordert außerdem die teamübergreifende Zusammenarbeit – vom Data Engineering über Data Science bis hin zum ML Engineering. Es erfordert rigorose operative Disziplin, all diese Prozesse aufeinander abzustimmen und zu synchronisieren.LLMOps umfasst das Experimentieren, Iterieren, Implementieren und fortlaufende Verbessern des LLM-Entwicklungslebenszyklus.
Worin bestehen die Vorteile von LLMOps?
Die wesentlichen Vorteile von LLMOps sind Effizienz, Skalierbarkeit und Risikominderung.
- Effizienz: LLMOps ermöglicht Datenteams eine schnellere Modell- und Pipeline-Entwicklung, die Bereitstellung hochwertigerer Modelle sowie eine schnellere Implementierung und Produktion.
- Skalierbarkeit: LLMOps bietet außerdem umfassende Skalierbarkeit und Verwaltung, sodass Tausende von CI/CD-Modellen beaufsichtigt, gesteuert, verwaltet und überwacht werden können. LLMOps sorgt insbesondere für die Reproduzierbarkeit von LLM-Pipelines, was eine engere Zusammenarbeit zwischen Datenteams ermöglicht, Konflikte mit DevOps und der IT reduziert und die Release-Geschwindigkeit beschleunigt.
- Risikominderung: LLMs erfordern häufig eine behördliche Prüfung. LLMOps sorgt bei solchen Anfragen für mehr Transparenz, erlaubt eine schnellere Reaktion und gewährleistet eine bessere Compliance im Hinblick auf Unternehmens- oder Branchenrichtlinien.
Das Playbook für agentenbasierte KI für Unternehmen

Wie setzt sich LLMOps zusammen?
Das LLMOps-Spektrum bei Machine-Learning-Projekten kann so breit oder tief sein, wie es das Projekt erfordert. In bestimmten Fällen kann LLMOps alles umfassen – von der Datenaufbereitung bis zur Pipeline-Erstellung –, während für andere Projekte vielleicht nur die Implementierung des Modellbereitstellungsprozesses erforderlich ist. Die meisten Unternehmen wenden die LLMOps-Prinzipien wie folgt an:
- EDA (Exploratory Data Analysis, explorative Datenanalyse)
- Datenaufbereitung und Prompt Engineering
- Modelloptimierung
- Modellprüfung und Governance
- Modellinferenz und -bereitstellung
- Modellüberwachung mit menschlichem Feedback
Worin bestehen Best Practices für LLMOps?
Best Practices für LLMOps lassen sich anhand der Phase abgrenzen, in der sie jeweils angewendet werden.
- EDA(Explorative Data Analysis, explorative Datenanalyse): Erkunden und teilen Sie Daten und bereiten Sie sie iterativ für den ML-Lebenszyklus auf. Zu diesem Zweck erstellen Sie Datasets, Tabellen und Visualisierungen, die reproduziert, bearbeitet und freigegeben werden können.
- Datenaufbereitung und Prompt Engineering: Transformieren, aggregieren und deduplizieren Sie Daten iterativ und machen Sie sie für alle Datenteams sichtbar und gemeinsam nutzbar. Entwickeln Sie iterativ Prompts für strukturierte und zuverlässige LLM-Abfragen.
- Modelloptimierung: Nutzen Sie beliebte Open-Source-Bibliotheken wie Hugging Face Transformers, DeepSpeed, PyTorch, TensorFlow und JAX, um die Modellperformance zu optimieren und feinzujustieren.
- Modellüberprüfung und Governance: Erfassen Sie Modell- und Pipelineherkunft und -versionen und verwalten Sie diese Artefakte und Übergänge über den gesamten Lebenszyklus hinweg. Nutzen Sie eine Open-Source-Plattform für MLOps wie etwa MLflow, um ML-Modelle zu entdecken, zu teilen und gemeinsam zu bearbeiten.
- Modellinferenz und -bereitstellung: Ermitteln Sie die Refresh-Häufigkeit für das Modell, Inferenzbedarfszeiten und ähnliche Produktionsspezifika mithilfe von Tests und QA. Verwenden Sie CI/CD-Tools wie Repos und Orchestrators (unter Anwendung der DevOps-Prinzipien), um die Vorproduktions-Pipeline zu automatisieren. Aktivieren Sie REST-API-Modellendpunkte mit GPU-Beschleunigung.
- Modellüberwachung mit menschlichem Feedback: Erstellen Sie Modell- und Datenüberwachungspipelines, die sowohl bei Driftverhalten als auch bei Auffälligkeiten warnen, die auf das Handeln böswilliger Nutzer schließen lassen.
Was ist eine LLMOps-Plattform?
Eine LLMOPs-Plattform stellt eine kollaborative Umgebung bereit, die Data Scientists und Software Engineers iterative Datenexploration, Echtzeit-Kooperationsfunktionen für das Tracking von Experimenten, Prompt Engineering und Modell- und Pipelineverwaltung sowie kontrollierte Modelltransition, -bereitstellung und -überwachung für LLMs bietet. LLMOps automatisiert die Betriebs-, Synchronisierungs- und Überwachungsaspekte des Machine-Learning-Lebenszyklus.
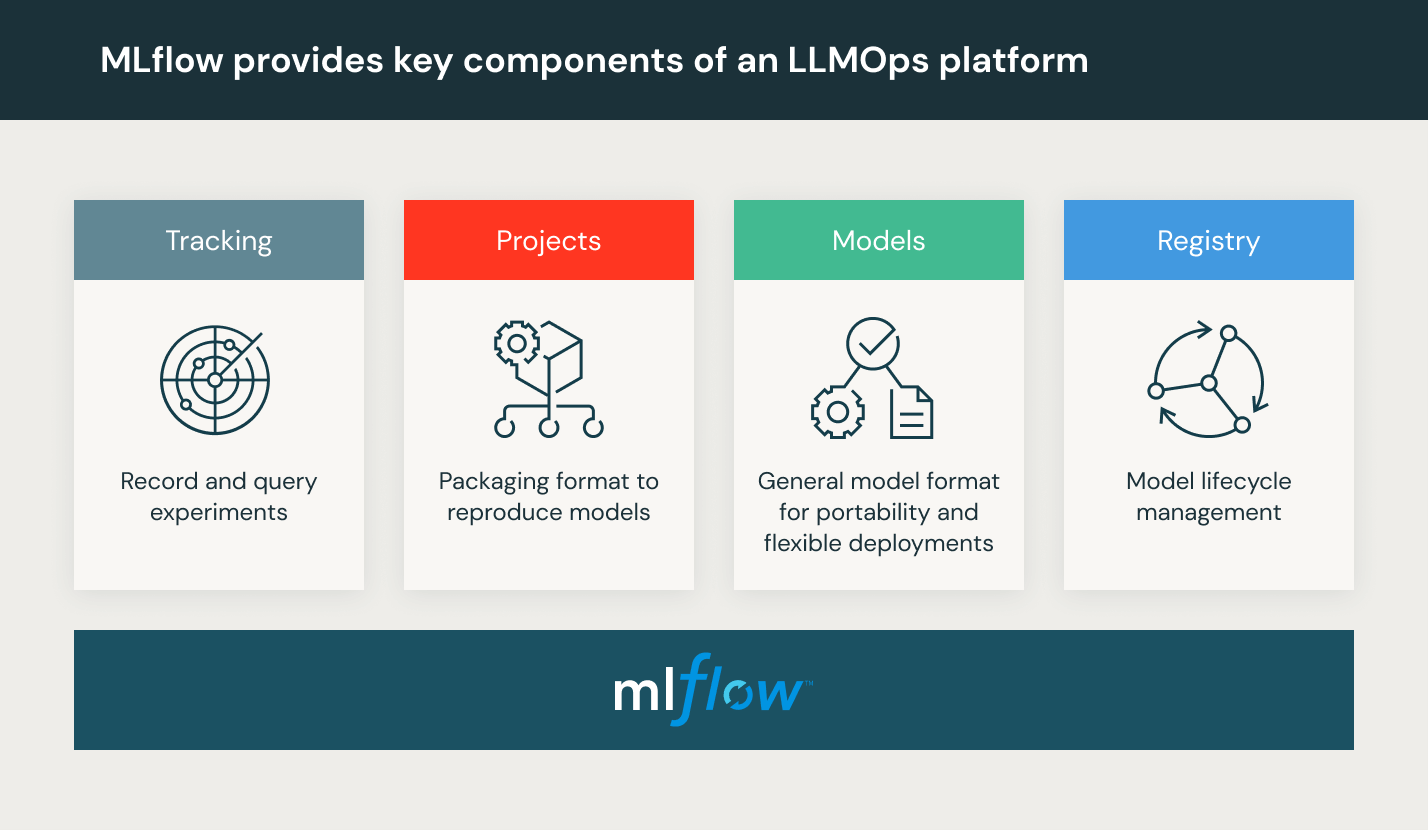
Databricks stellt eine vollständig verwaltete Umgebung bereit, die auch MLflow umfasst, die weltweit führende quelloffene MLOps-Plattform.Databricks Machine Learning testen
Zusätzliche Ressourcen
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.