Große Sprachmodelle
Schnellere Innovationen mithilfe großer Sprachmodelle mit Databricks

Was sind große Sprachmodelle?
Große Sprachmodelle (Large Language Models, LLMs) sind Machine-Learning-Modelle, die bei sprachbezogenen Aufgaben wie Übersetzung, Beantwortung von Fragen, Chat und Inhaltszusammenfassung sowie Inhalts- und Codegenerierung sehr effektiv sind. LLMs ziehen wertvolle Informationen aus riesigen Datensätzen und machen Ergebnisse sofort verfügbar. Mit Databricks können Sie ganz einfach auf diese LLMs zugreifen, um sie in Ihre Workflows zu integrieren. Außerdem bietet die Plattform Funktionen zur Feinabstimmung von LLMs anhand Ihrer eigenen Daten für eine bessere Performance im jeweiligen Fachbereich.

Verarbeitung natürlicher Sprache mit LLMs
S&P Global verwendet große Sprachmodelle auf Databricks, um die wichtigsten Unterschiede und Ähnlichkeiten in den Unterlagen von Unternehmen besser zu verstehen und Vermögensverwaltern dabei zu helfen, ein vielfältigeres Portfolio zusammenzustellen.
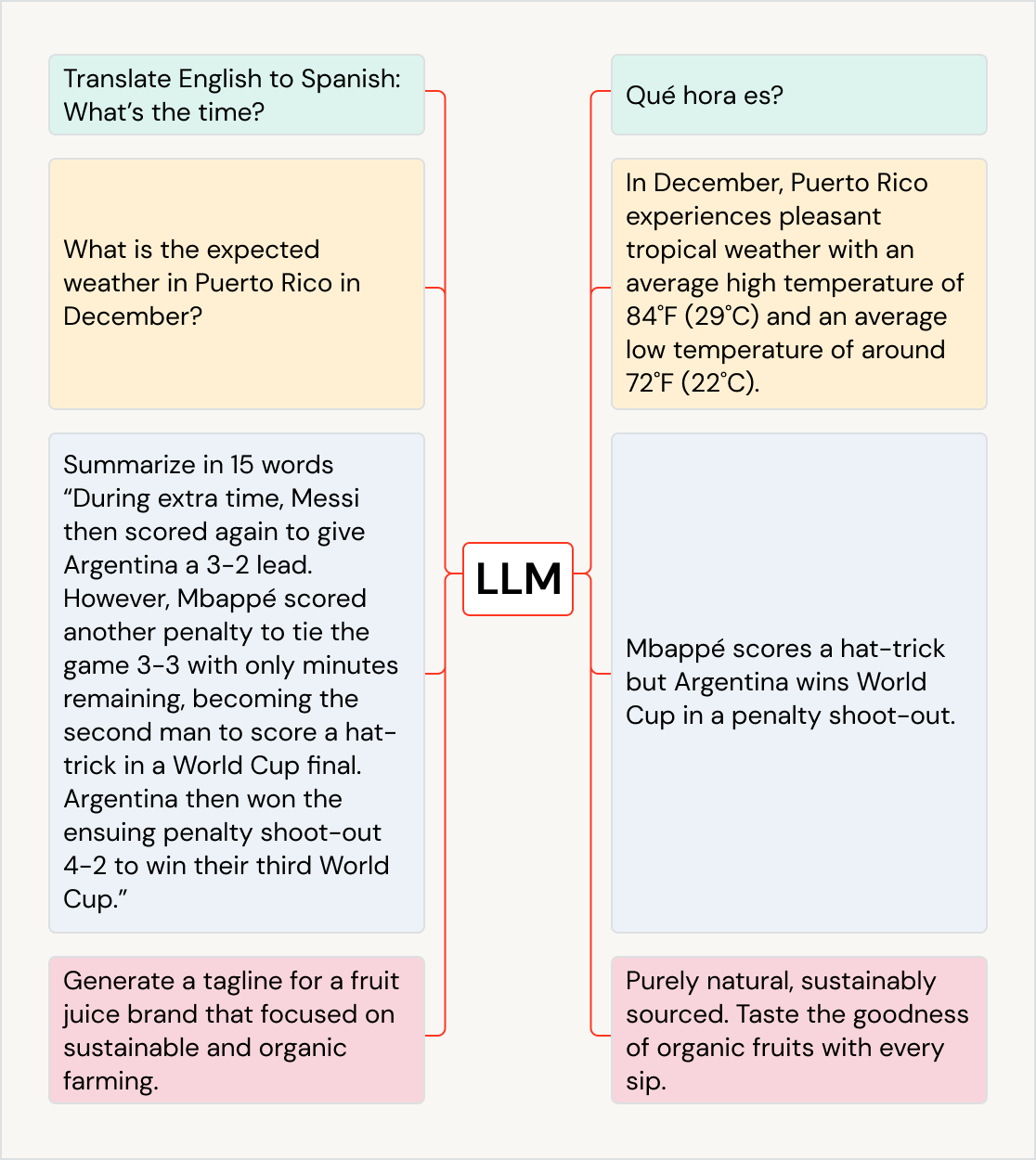
LLMs für eine Vielzahl von Anwendungsfällen verwenden
LLMs können die geschäftlichen Auswirkungen über Anwendungsfälle und Branchen hinweg vorantreiben: Text in andere Sprachen übersetzen, das Kundenerlebnis mit Chatbots und KI-Assistenten verbessern, Kundenfeedback organisieren und für die richtigen Abteilungen klassifizieren, große Dokumente wie Erlösaufrufe und Rechtsdokumente zusammenfassen, neue Marketinginhalte erstellen und Softwarecode aus natürlicher Sprache generieren. Sie können sogar verwendet werden, um Daten in andere Modelle einzuspeisen, beispielsweise solche, die Kunst generieren. Einige beliebte LLMs sind die GPT-Modellfamilie (z. B. ChatGPT), BERT, T5 und BLOOM.
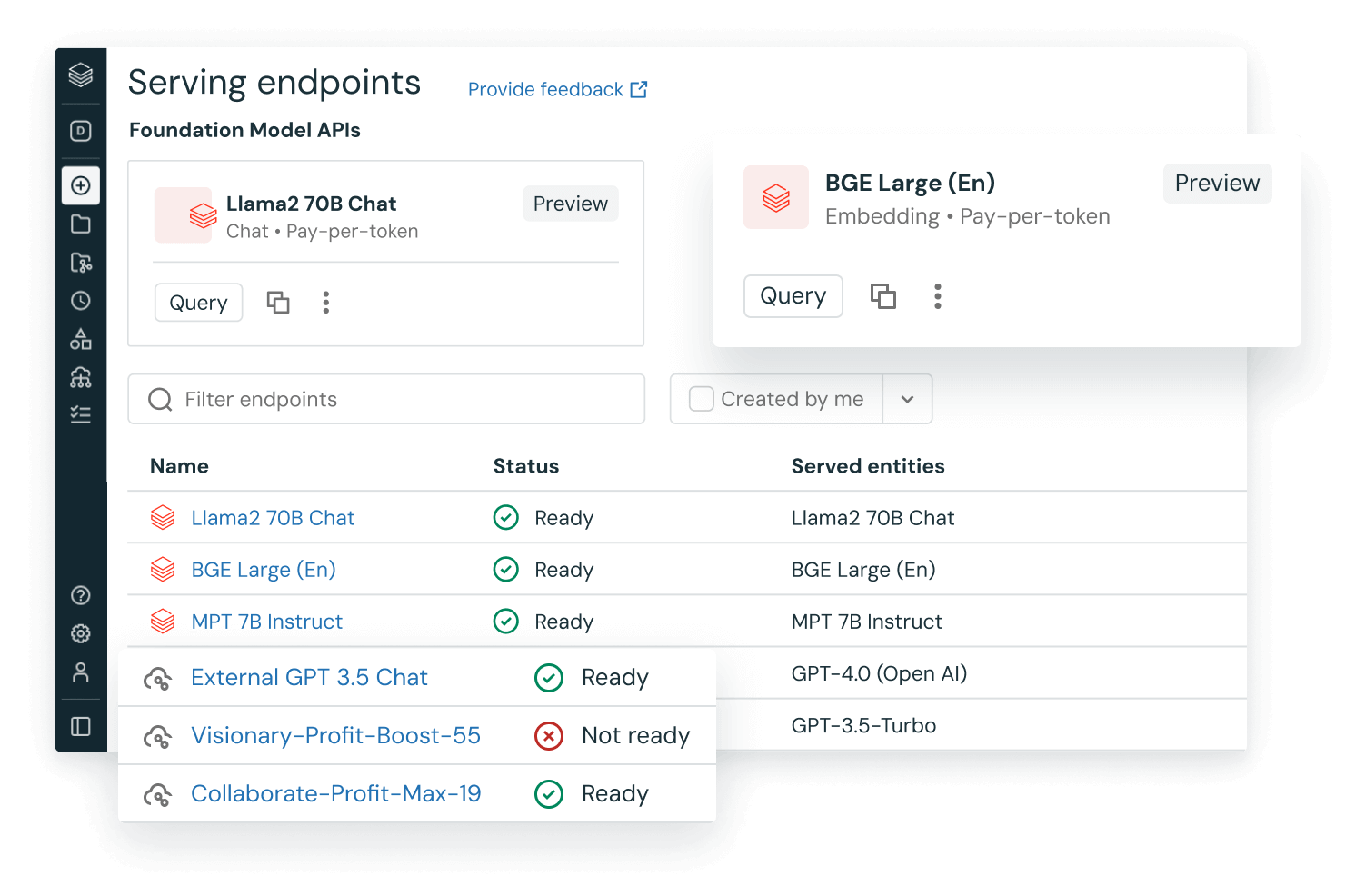
Vortrainierte LLMs in Ihren Apps verwenden
Integrieren Sie vorhandene vortrainierte Modelle – wie die aus der Hugging Face Transformers Library oder anderen Open-Source-Bibliotheken – in Ihren Workflow. Transformer-Pipelines vereinfachen die Verwendung von GPUs und ermöglichen das Batching von Elementen, die an die GPU gesendet werden, um einen besseren Durchsatz zu erzielen.
Mit der MLflow-Variante für Hugging Face Transformers erhalten Sie eine native Integration von Transformer-Pipelines, Modellen und Verarbeitungskomponenten in den MLflow-Tracking-Dienst. Sie können auch OpenAI-Modelle oder Lösungen von Partnern wie John Snow Labs in Ihre Workflows auf Databricks integrieren.
Mithilfe von KI-Funktionen können SQL-Datenanalysten direkt in ihrer Datenpipeline und ihren Workflows problemlos auf LLM-Modelle zugreifen, einschließlich derer von OpenAI.
Feinabstimmung von LLMs anhand Ihrer Daten
Passen Sie ein Modell an Ihre Daten für Ihre spezifische Aufgabe an. Mit der Unterstützung von Open-Source-Tools wie Hugging Face und DeepSpeed können Sie schnell und effizient ein grundlegendes LLM erstellen und mit dem Training mit Ihren eigenen Daten beginnen, um mehr Genauigkeit für Ihren Fachbereich und Workload zu erzielen. Dadurch haben Sie auch die Kontrolle über die für das Training verwendeten Daten, sodass Sie sicherstellen können, dass Sie KI verantwortungsvoll einsetzen.

Dolly 2.0 ist ein großes Sprachmodell, das von Databricks trainiert wurde, um zu demonstrieren, wie Sie Ihr eigenes LLM kostengünstig und schnell trainieren können. Der hochwertige, von Menschen generierte Datensatz (databricks-dolly-15k), mit dem das Modell trainiert wurde, wurde ebenfalls als Open Source bereitgestellt. Mit Dolly 2.0 können Kunden jetzt ihr eigenes LLM besitzen, betreiben und anpassen. Unternehmen können ein LLM mit ihren eigenen Daten aufbauen und trainieren, ohne Daten an proprietäre LLMs senden zu müssen. Den Dolly 2.0-Code, Modellgewichtungen oder den databricks-dolly-15k-Datensatz erhalten Sie unter Hugging Face.
Integrierte LLMOps (MLOps für LLMs)
Verwenden Sie integrierte und produktionsbereite MLOps mit Managed MLflow für die Tracking, Verwaltung und Bereitstellung von Modellen. Sobald das Modell bereitgestellt ist, können Sie Dinge wie Latenz, Datendrift und mehr überwachen. Außerdem haben Sie die Möglichkeit, Pipelines für erneutes Training auszulösen – alles auf derselben einheitlichen Databricks Lakehouse-Plattform für End-to-End-LLMOps.
Daten und Modelle auf einer einheitlichen Plattform
Die meisten Modelle werden mehr als einmal trainiert, sodass es sowohl für die Leistung als auch für die Kosten entscheidend ist, die Trainingsdaten in derselben ML-Plattform zu haben. Das Training von LLMs im Lakehouse gibt Ihnen Zugang zu erstklassigen Tools und Datenverarbeitungen – innerhalb eines äußerst kostengünstigen Data Lakehouse – und ermöglicht es Ihnen, Modelle weiter zu trainieren, wenn sich Ihre Daten im Laufe der Zeit weiterentwickeln.