Lakehouse Monitoring: Eine einheitliche Lösung für Datenqualität und KI
von Jacqueline Li, Alkis Polyzotis und Kasey Uhlenhuth
Einführung
Databricks Data Quality Monitoring ermöglicht es Ihnen, alle Ihre Datenpipelines – von Daten über Features bis hin zu ML-Modellen – ohne zusätzliche Tools und Komplexität zu überwachen. Da es in Unity Catalog integriert ist, können Sie die Qualität zusammen mit der Governance nachverfolgen und erhalten tiefe Einblicke in die Performance Ihrer Daten- und KI-Assets. Lakehouse Monitoring ist vollständig serverless, sodass Sie sich nie um die Infrastruktur oder die Feinabstimmung der Rechenkonfiguration kümmern müssen.
Unser einheitlicher Ansatz für das Monitoring macht es einfach, die Qualität zu überwachen, Fehler zu diagnostizieren und Lösungen direkt in der Databricks Data Intelligence Platform zu finden. Lesen Sie weiter, um zu erfahren, wie Sie und Ihr Team das Beste aus Lakehouse Monitoring herausholen können.
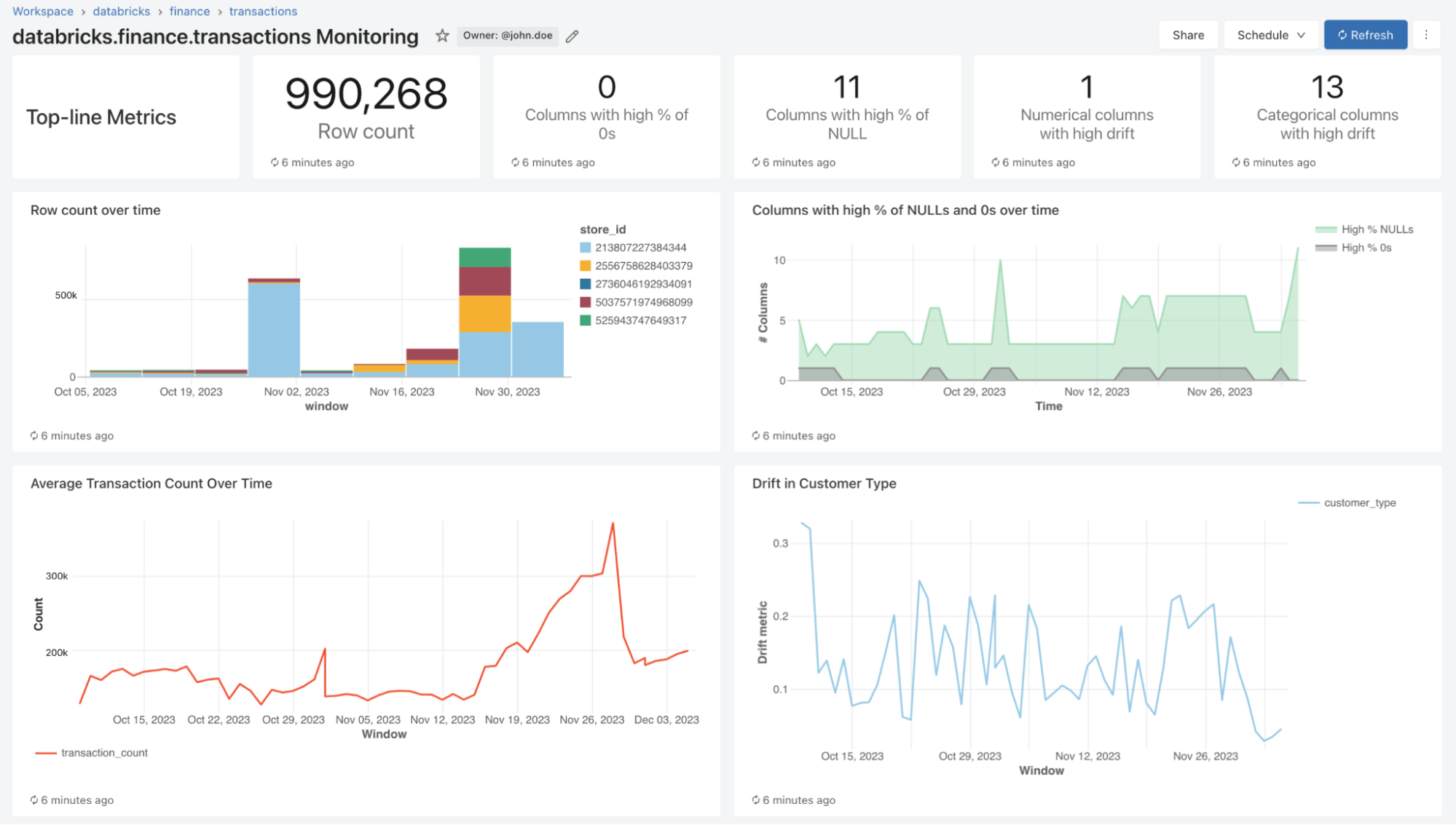
Warum Lakehouse Monitoring?
Stellen Sie sich folgendes Szenario vor: Ihre Datenpipeline scheint reibungslos zu laufen, nur um dann festzustellen, dass sich die Qualität der Daten im Laufe der Zeit unbemerkt verschlechtert hat. Dies ist ein häufiges Problem unter Data Engineers – alles scheint in Ordnung zu sein, bis sich jemand beschwert, dass die Daten unbrauchbar sind.
Für diejenigen unter Ihnen, die ML-Modelle trainieren, ist das Tracking der Performance von Produktionsmodellen und der Vergleich verschiedener Versionen eine ständige Herausforderung. Infolgedessen sind Teams mit veralteten Modellen in der Produktion konfrontiert und haben die Aufgabe, sie zurückzusetzen.
Die Illusion funktionaler Pipelines, die eine bröckelnde Datenqualität verschleiern, erschwert es Daten- und KI-Teams, die Liefer- und Qualitäts-SLAs einzuhalten. Lakehouse Monitoring kann Ihnen dabei helfen, Qualitätsprobleme proaktiv zu erkennen, bevor nachgelagerte Prozesse beeinträchtigt werden. So können Sie potenziellen Problemen vorbeugen und sicherstellen, dass Pipelines reibungslos laufen und Machine-Learning-Modelle im Laufe der Zeit effektiv bleiben. Kein wochenlanges Debugging und Zurücksetzen von Änderungen mehr!
Wie es funktioniert

Mit Lakehouse Monitoring können Sie die statistischen Eigenschaften und die Qualität all Ihrer Tabellen mit nur einem Klick überwachen. Wir generieren automatisch ein Dashboard, das die Datenqualität für jede Delta-Tabelle im Unity Catalog visualisiert. Unser Produkt berechnet standardmäßig eine Vielzahl von Metriken. Wenn Sie beispielsweise eine Inferenz-Tabelle überwachen, stellen wir Metriken zur Modell-Performance bereit, zum Beispiel R-Quadrat, Genauigkeit usw. Für diejenigen, die Data-Engineering-Tabellen überwachen, stellen wir alternativ Verteilungsmetriken bereit, einschließlich Mittelwert, Min/Max usw. Zusätzlich zu den integrierten Metriken können Sie auch benutzerdefinierte (geschäftsspezifische) Metriken konfigurieren, die wir für Sie berechnen sollen. Lakehouse Monitoring aktualisiert Metriken und hält das Dashboard gemäß dem von Ihnen festgelegten Zeitplan auf dem neuesten Stand. Alle Metriken werden in Delta-Tabellen gespeichert, um Ad-hoc-Analysen, benutzerdefinierte Visualisierungen und Alerts zu ermöglichen.
Monitoring konfigurieren
Sie können das Monitoring für jede Ihrer Tabellen über die Databricks-Benutzeroberfläche (AWS | Azure) oder die API (AWS | Azure) einrichten. Wählen Sie den gewünschten Typ des Monitoringprofils für Ihre Datenpipelines oder Modelle aus:
- Snapshot-Profil: Wenn Sie die gesamte Tabelle im Zeitverlauf überwachen oder aktuelle Daten mit früheren Versionen oder einer bekannten Baseline vergleichen möchten, ist ein Snapshot-Profil am besten geeignet. Wir berechnen dann Metriken für alle Daten in der Tabelle und aktualisieren die Metriken bei jeder Aktualisierung des Monitors.
- Zeitreihenprofil: Wenn Ihre Tabelle Ereigniszeitstempel enthält und Sie Datenverteilungen über Zeitfenster (stündlich, täglich, wöchentlich, ...) vergleichen möchten, ist ein Zeitreihenprofil am besten geeignet. Wir empfehlen, den Change Data Feed (AWS | Azure) zu aktivieren, damit Sie bei jeder Aktualisierung des Monitors eine inkrementelle Verarbeitung erhalten. Hinweis: Sie benötigen eine Zeitstempelspalte, um dieses Profil zu konfigurieren.
- Profil für Inferenz-Log: Wenn Sie die Modell-Performance im Zeitverlauf vergleichen oder nachverfolgen möchten, wie sich Modelleingaben und Vorhersagen im Laufe der Zeit verändern, ist ein Inferenzprofil am besten geeignet. Sie benötigen eine Inferenztabelle (AWS | Azure), die Eingaben und Ausgaben aus einem ML-Klassifizierungs- oder Regressionsmodell enthält. Sie können optional auch Ground-Truth-Labels einfügen, um drift zu berechnen, sowie andere Metadaten wie demografische Informationen, um Fairness- und Bias-Metriken zu erhalten.
Sie können wählen, wie oft unser Monitoring-Dienst ausgeführt werden soll. Viele Kunden wählen einen täglichen oder stündlichen Schedule, um die Aktualität und Relevanz ihrer Daten sicherzustellen. Wenn das Monitoring am Ende der Ausführung der Datenpipeline automatisch ausgeführt werden soll, können Sie auch die API aufrufen, um das Monitoring direkt in Ihrem Workflow zu refreshen.
Um das Monitoring weiter anzupassen, können Sie Slicing-Ausdrücke festlegen, um neben der gesamten Tabelle auch Feature-Teilmengen der Tabelle zu überwachen. Sie können eine beliebige Spalte, z. B. ethnische Zugehörigkeit oder Geschlecht, in Slices unterteilen, um Fairness- und Bias-Metriken zu generieren. Sie können auch benutzerdefinierte Metriken auf der Grundlage von Spalten in Ihrer Primärtabelle oder zusätzlich zu den vordefinierten Metriken definieren. Weitere Informationen zur Verwendung von benutzerdefinierten Metriken finden Sie unter (AWS | Azure).
Qualität visualisieren
Im Rahmen eines Refresh scannen wir Ihre Tabellen und Modelle, um Metriken zu generieren, die die Qualität im Zeitverlauf nachverfolgen. Wir berechnen zwei Arten von Metriken, die wir für Sie in Delta-Tabellen speichern:
- Profilmetriken: Sie liefern zusammenfassende Statistiken zu Ihren Daten. Sie können beispielsweise die Anzahl der Nullwerte und Nullen in Ihrer Tabelle oder die Genauigkeitsmetriken für Ihr Modell nachverfolgen. Weitere Informationen finden Sie im Tabellenschema für Profilmetriken (AWS | Azure).
- Drift-Metriken: Sie bieten statistische Drift-Metriken, die einen Vergleich mit Ihren Baseline-Tabellen ermöglichen. Siehe das Tabellenschema für Drift-Metriken (AWS | Azure) für weitere Informationen.
Zur Visualisierung all dieser Metriken bietet Lakehouse Monitoring ein vordefiniertes Dashboard, das vollständig anpassbar ist. Sie können auch Databricks SQL-Alerts (AWS | Azure) erstellen, um bei threshold-Verletzungen, Änderungen der Datenverteilung und Drift von Ihrer Basistabelle benachrichtigt zu werden.
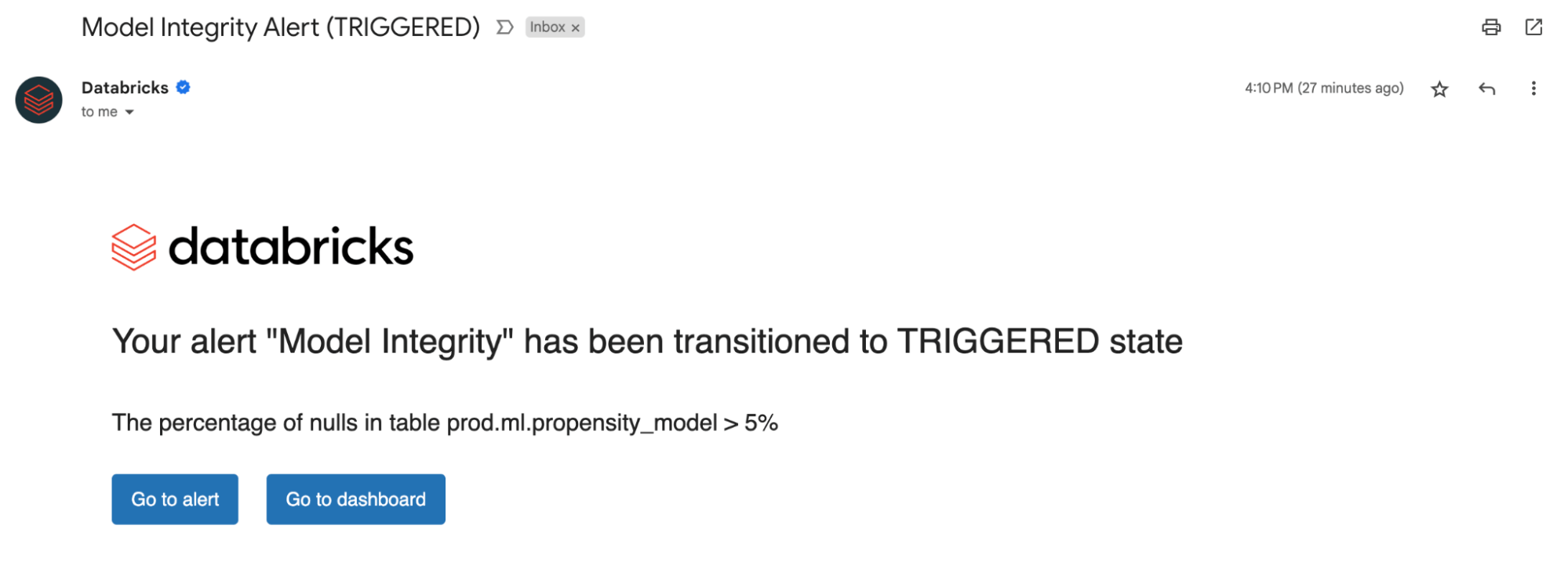
Benachrichtigungen einrichten
Unabhängig davon, ob Sie Monitoring von Datentabellen oder Modellen betreiben, benachrichtigt Sie das Einrichten von Alerts für unsere berechneten Metriken über potenzielle Fehler und hilft, nachgelagerte Risiken zu vermeiden.
Sie können benachrichtigt werden, wenn der prozentuale Anteil von Nullwerten und Nullen einen bestimmten threshold überschreitet oder sich im Laufe der Zeit ändert. Wenn Sie Modelle im Monitoring haben, können Sie benachrichtigt werden, wenn Metriken zur Modell-Performance wie Toxizität oder Drift unter bestimmte Qualitätsschwellenwerte fallen.
Mit den aus unseren Alerts gewonnenen Erkenntnissen können Sie nun feststellen, ob ein Modell neu trainiert werden muss oder ob es potenzielle Probleme mit Ihren Quelldaten gibt. Nachdem Sie die Probleme behoben haben, können Sie die refresh-API manuell aufrufen, um die neuesten Metriken für Ihre aktualisierte Pipeline abzurufen. Lakehouse Monitoring hilft Ihnen dabei, proaktiv Maßnahmen zu ergreifen, um die allgemeine Integrität und Zuverlässigkeit Ihrer Daten und Modelle zu erhalten.
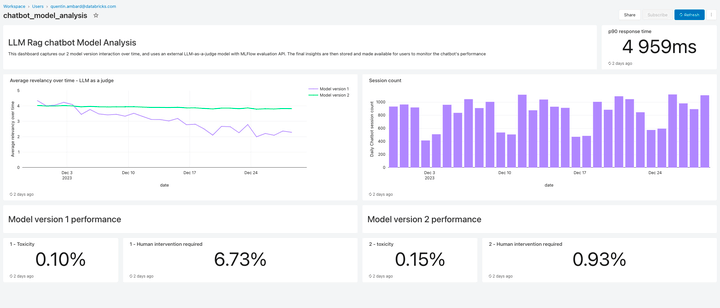
LLM-Qualität überwachen
Lakehouse Monitoring bietet eine vollständig verwaltete Qualitätslösung für Retrieval Augmented Generation (RAG)-Anwendungen. Es scannt die Ausgaben Ihrer Anwendung auf toxische oder anderweitig unsichere Inhalte. Sie können schnell Fehler diagnostizieren, die z. B. mit veralteten Datenpipelines oder unerwartetem Modellverhalten zusammenhängen. Lakehouse Monitoring verwaltet Monitoring-Pipelines vollständig, sodass sich Entwickler auf ihre Anwendungen konzentrieren können.
Was kommt als Nächstes?
Wir freuen uns auf die Zukunft von Lakehouse Monitoring und darauf, Folgendes zu unterstützen:
- Datenklassifizierung/ PII-Erkennung – Registrieren Sie sich für unsere Private Preview hier!
- Expectations zur automatischen Durchsetzung von Datenqualitätsregeln und Orchestrierung Ihrer Pipelines
- Eine ganzheitliche Ansicht Ihrer Monitore, um die Qualität und Integrität Ihrer Tabellen zusammenzufassen
Um mehr über Lakehouse Monitoring zu erfahren und noch heute loszulegen, besuchen Sie unsere Produktdokumentation (AWS | Azure). Lesen Sie außerdem die neuesten Ankündigungen zur Erstellung hochwertiger RAG-Anwendungen und nehmen Sie an unserem GenAI- Webinar teil.
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.