Verbessern Sie die Antwortqualität Ihrer RAG-Anwendung mit strukturierten Echtzeitdaten
von Mani Parkhe, Aakrati Talati, Sue Ann Hong, Craig Wiley, Chenen Liang und Mingyang Ge
Retrieval Augmented Generation (RAG) ist ein effizienter Mechanismus, um relevante Daten als Kontext in Gen AI-Anwendungen bereitzustellen. Die meisten RAG-Anwendungen verwenden in der Regel Vektorindizes, um in unstrukturierten Daten wie Dokumentation, Wikis und Support-Tickets nach relevantem Kontext zu suchen. Gestern haben wir die Public Preview von Databricks AI Search angekündigt, die genau dabei hilft. Die Antwortqualität von Gen AI kann jedoch verbessert werden, indem diese textbasierten Kontexte mit relevanten und personalisierten strukturierten Daten erweitert werden. Stellen Sie sich ein Gen AI-Tool auf einer Einzelhandels-Website vor, auf der Kunden fragen: "Wo ist meine letzte Bestellung?" Diese KI muss verstehen, dass sich die Abfrage auf einen bestimmten Kauf bezieht, dann aktuelle Versandinformationen für einzelne Posten sammeln, bevor sie LLMs zur Generierung einer Antwort verwendet. Die Entwicklung dieser skalierbaren Anwendungen erfordert erheblichen Aufwand, da Technologien zur Verarbeitung von strukturierten und unstrukturierten Daten mit Gen AI-Funktionen integriert werden müssen.
Wir freuen uns, die Public Preview von Databricks Feature & Function Serving anzukündigen, einem Echtzeit-Dienst mit niedriger Latenz, der für die Bereitstellung strukturierter Daten aus der Databricks Data Intelligence Platform konzipiert wurde. Sie können sofort auf vorberechnete ML-Features zugreifen und Echtzeit-Datentransformationen durchführen, indem Sie eine beliebige Python-Funktion aus dem Unity Catalog bereitstellen. Die abgerufenen Daten können dann in Echtzeit-Regel-Engines, klassischen ML- und Gen AI-Anwendungen verwendet werden.
Die Verwendung von Feature and Function Serving (AWS)(Azure) für strukturierte Daten in Koordination mit Databricks AI Search (AWS)(Azure) für unstrukturierte Daten vereinfacht die Produktivsetzung von Gen-KI-Anwendungen erheblich. Benutzer können diese Anwendungen direkt in Databricks erstellen und bereitstellen und sich auf bestehende Datenpipelines, Governance und andere Unternehmens-Features verlassen. Databricks-Kunden aus verschiedenen Branchen verwenden diese Technologien zusammen mit Open-Source-Frameworks, um leistungsstarke Gen AI-Anwendungen wie die in der folgenden Tabelle beschriebenen zu erstellen.
| Branche | Anwendungsfall |
| Einzelhandel |
|
| Bildung |
|
| Finanzdienstleistungen |
|
| Reisen und Gastgewerbe |
|
| Gesundheitswesen und Biowissenschaften |
|
| Versicherungswesen |
|
| Technologie und Fertigung |
|
| Medien und Unterhaltung |
|
Bereitstellung strukturierter Daten für RAG-Anwendungen
Um zu demonstrieren, wie strukturierte Daten zur Qualitätsverbesserung einer Gen-AI-Anwendung beitragen können, verwenden wir das folgende Beispiel für einen Reiseplanungs-Chatbot. Das Beispiel zeigt, wie Nutzerpräferenzen (z. B. "Meerblick" oder "familienfreundlich") mit unstrukturierten Informationen über Hotels kombiniert werden können, um passende Hotels zu finden. Typischerweise ändern sich die Hotelpreise dynamisch je nach Nachfrage und Saisonalität. Ein in die Gen-AI-Anwendung integrierter Preisrechner stellt sicher, dass die Empfehlungen im Budget des Nutzers liegen. Die Gen-AI-Anwendung, die den Bot betreibt, verwendet Databricks AI Search und Databricks Feature and Function Serving als Bausteine, um die erforderlichen personalisierten Nutzerpräferenzen sowie Budget- und Hotelinformationen mithilfe der Agents-API von LangChain bereitzustellen.
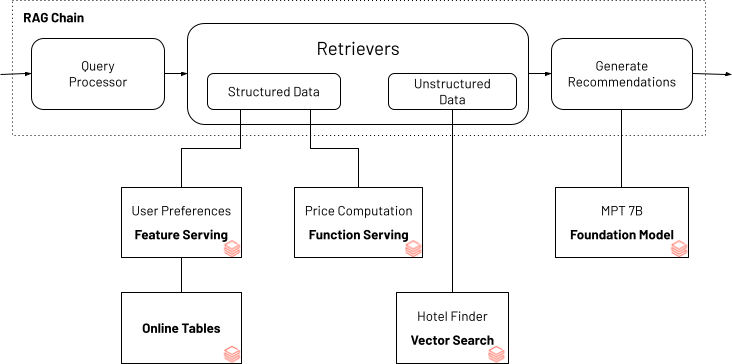
*Reiseplanungs-Bot, der Nutzerpräferenzen und Budget berücksichtigt
Das vollständige Notebook für diese oben dargestellte RAG-Chain-Anwendung finden Sie hier. Diese Anwendung kann lokal im Notebook ausgeführt oder als endpoint angewendet werden, der über eine Chatbot-Benutzeroberfläche zugänglich ist.
Greifen Sie auf Ihre Daten und Funktionen als Echtzeit-Endpunkte zu
Mit Feature Engineering im Unity Catalog können Sie bereits jede Tabelle mit einem Primärschlüssel verwenden, um Features für Training und Serving bereitzustellen. Databricks Model Serving unterstützt die Verwendung von Python-Funktionen zur bedarfsgesteuerten Berechnung von Features. Feature- und Funktions-Endpoints basieren auf derselben Technologie, die auch für Databricks Model Serving verwendet wird, und können für den Zugriff auf vorberechnete Features oder deren bedarfsgesteuertes Compute genutzt werden. Mit einer einfachen Syntax können Sie eine Feature-Spec-Funktion im Unity Catalog definieren, die den gerichteten azyklischen Graphen kodieren kann, um Features als REST-Endpunkt zu berechnen und bereitzustellen.
Diese Feature-Spec-Funktion kann in Echtzeit als REST-Endpunkt bereitgestellt werden. Alle Endpunkte sind im linken Navigations-Tab „Serving“ zugänglich, einschließlich Features, Funktionen, benutzerdefiniert trainierten Modellen und Foundation Models. Stellen Sie den endpoint mithilfe dieser API bereit
Der Endpunkt kann auch wie unten gezeigt über einen UI-Workflow erstellt werden
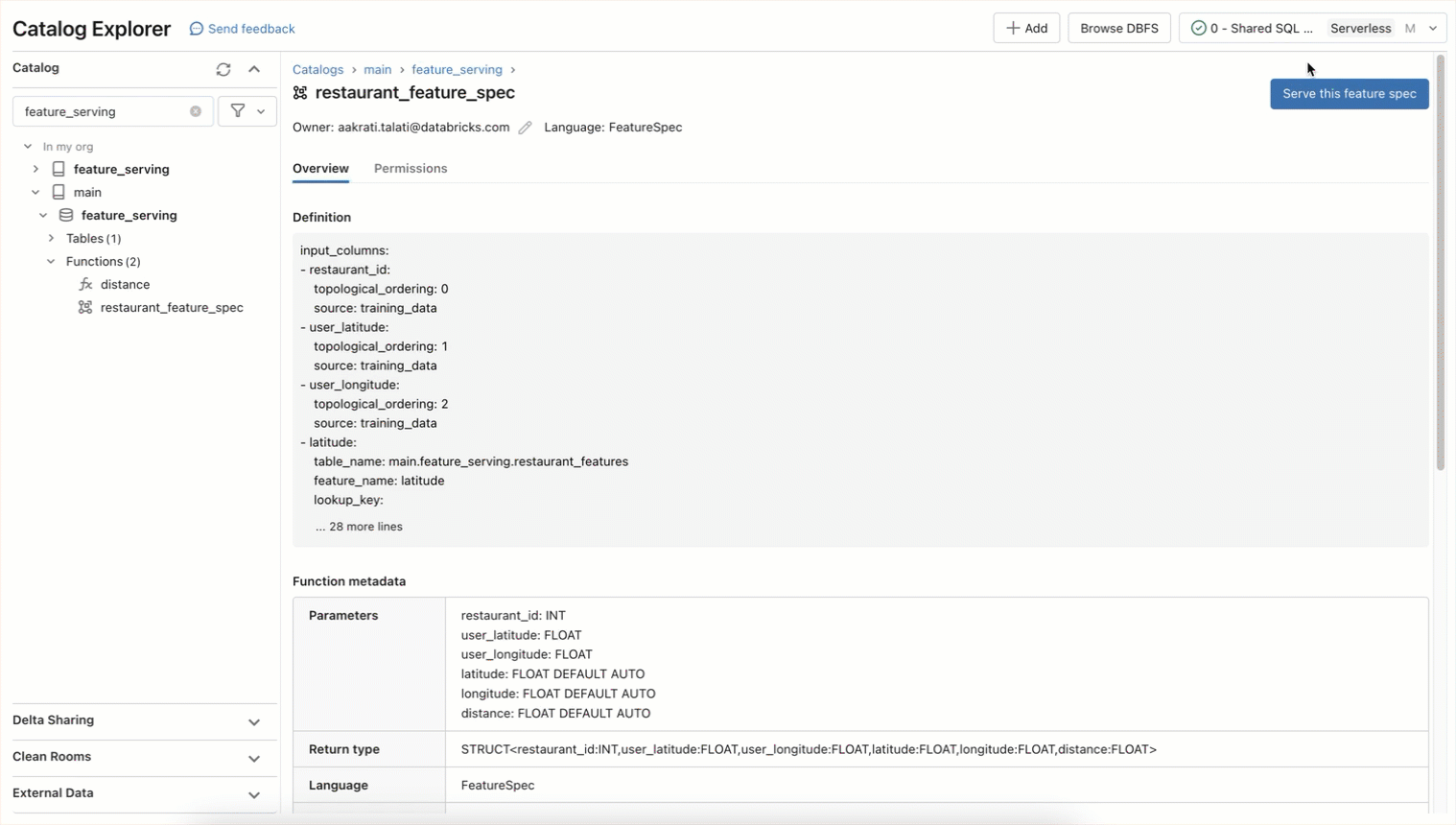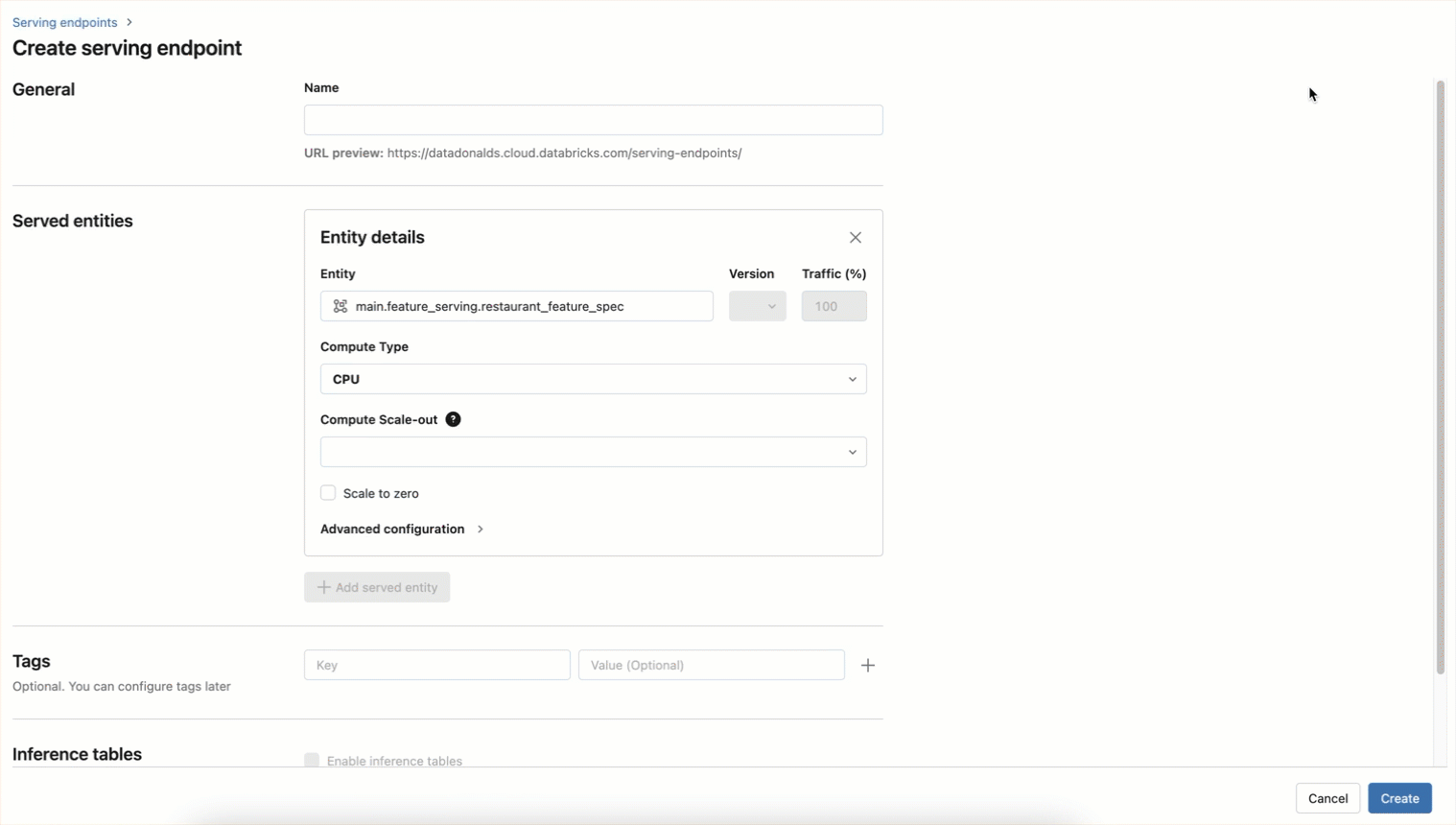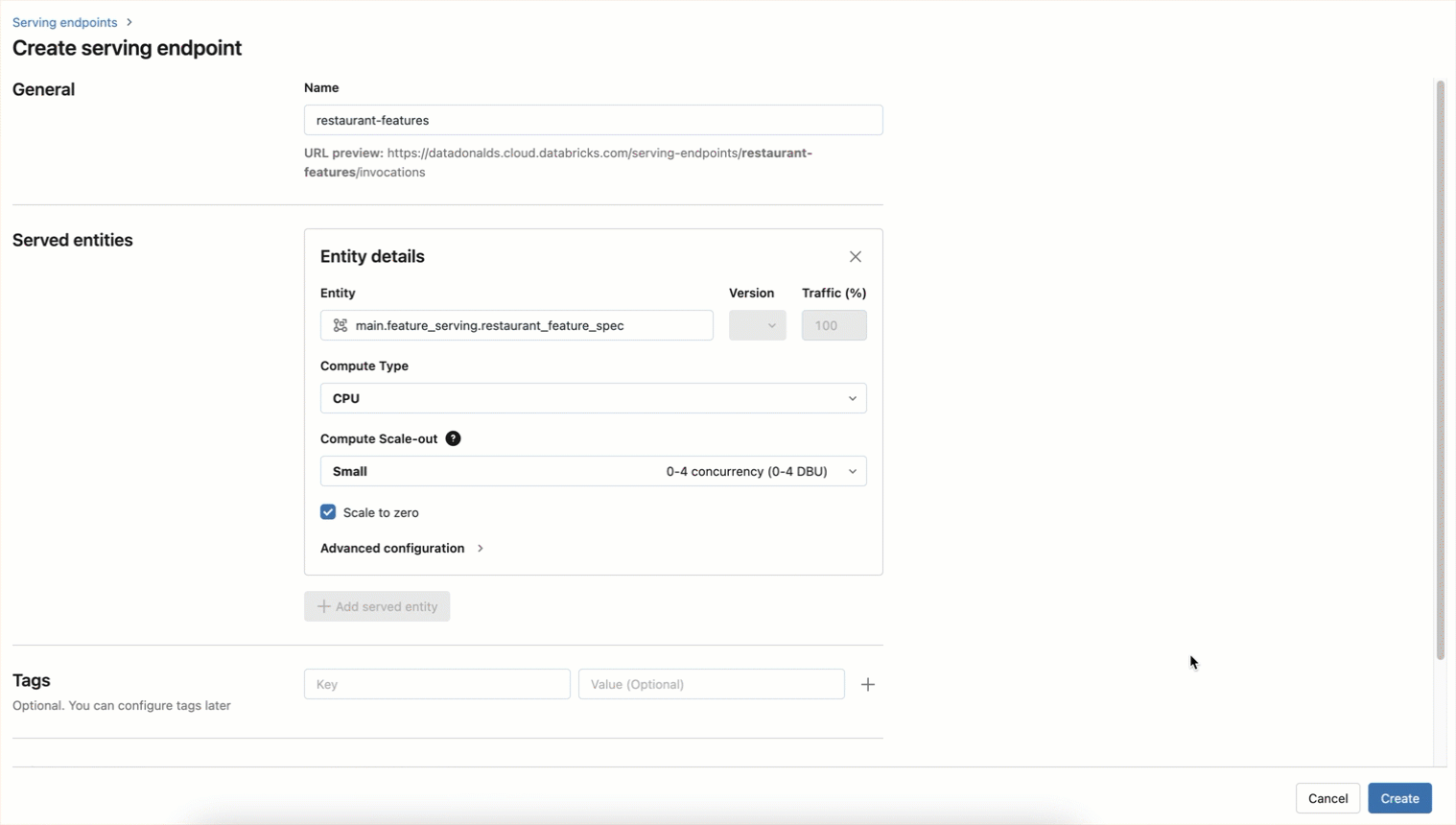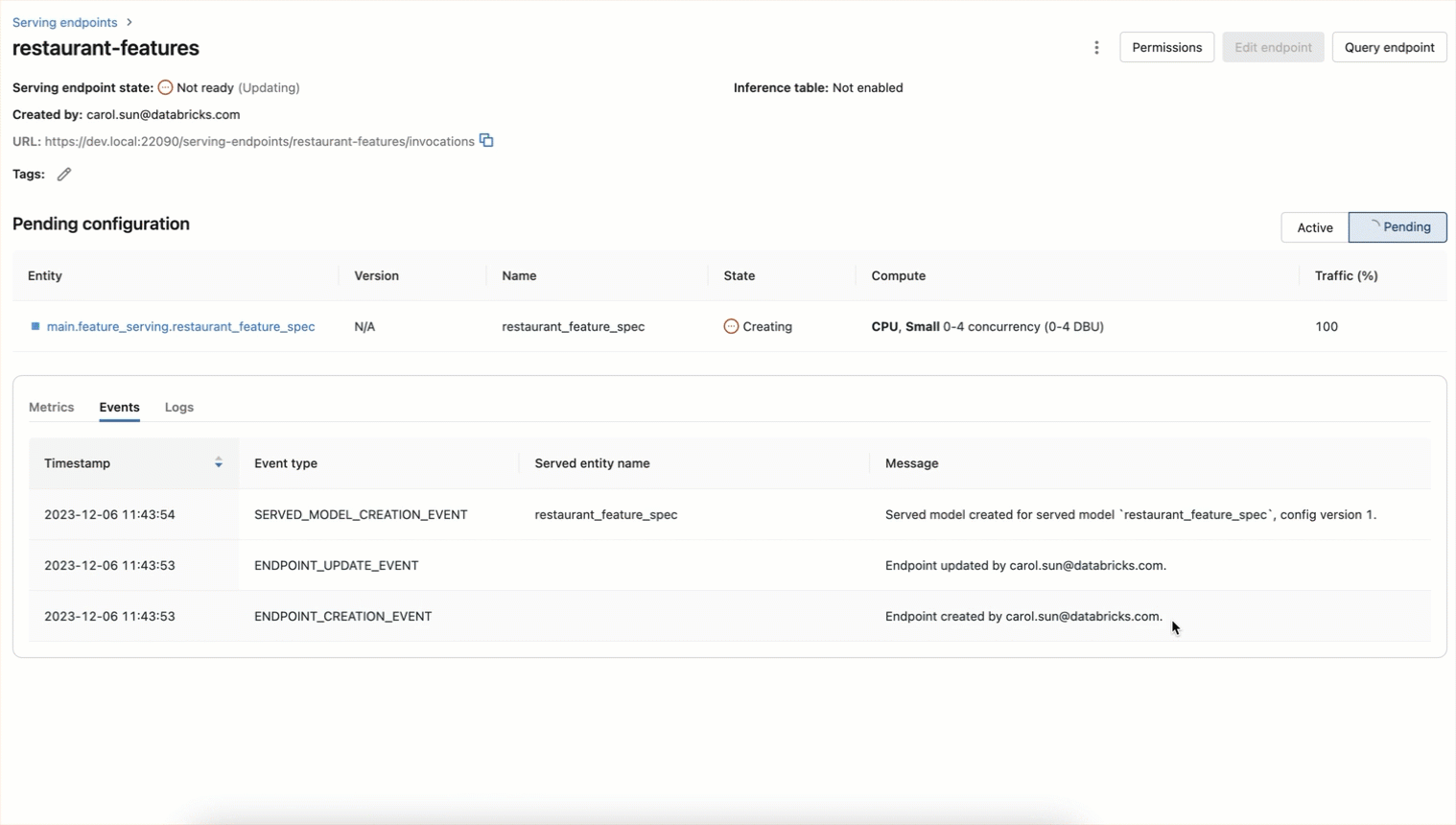
Features können jetzt in Echtzeit durch Abfragen des Endpunkts abgerufen werden:
Um strukturierte Daten an Echtzeit-KI-Anwendungen auszuliefern, müssen vorberechnete Daten in operativen Datenbanken bereitgestellt werden. Benutzer können bereits externe Online-Stores als Quelle für vorberechnete Features verwenden – beispielsweise werden DynamoDB und Cosmos DB häufig zur Bereitstellung von Features in Databricks Model Serving genutzt. Databricks Online Tables (AWS)(Azure) fügt neue Funktionen hinzu, die die Synchronisierung von vorberechneten Features in ein Datenformat vereinfachen, das für Datenabrufe mit geringer Latenz optimiert ist. Sie können jede Tabelle mit einem Primärschlüssel als Online-Tabelle synchronisieren, und das System richtet automatisch eine Pipeline ein, um die Datenaktualität zu gewährleisten.
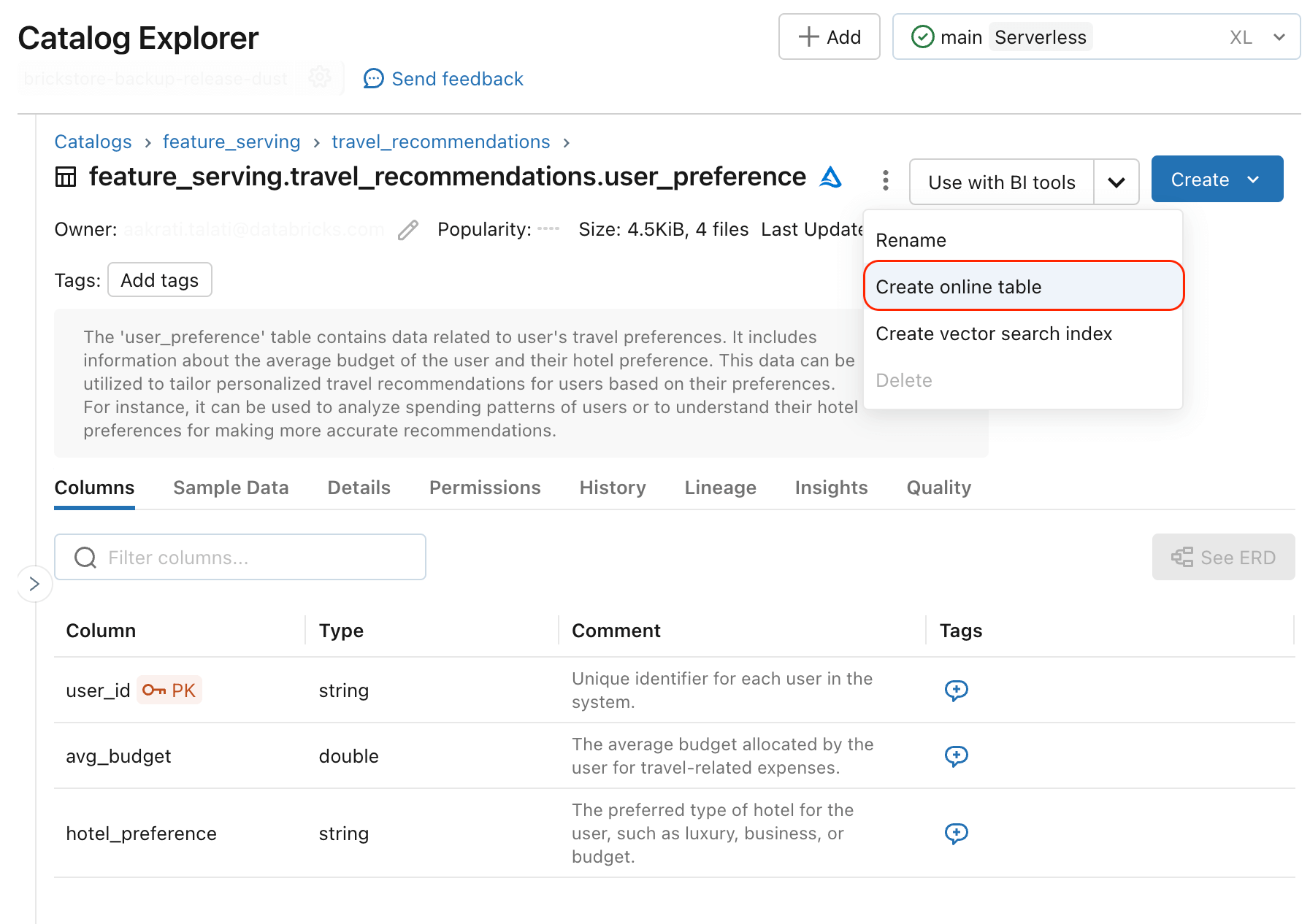
Jede Unity Catalog-Tabelle mit Primärschlüsseln kann mithilfe von Databricks Online Tables zur Bereitstellung von Features in Gen-KI-Anwendungen genutzt werden.
Die nächsten Schritte
Verwenden Sie dieses oben dargestellte Notebook-Beispiel, um Ihre RAG-Anwendungen anzupassen.
Melden Sie sich für ein Databricks Generative KI Webinar an, das auf Abruf verfügbar ist.
Feature- und Funktionsbereitstellung (AWS)(Azure) ist in der Public Preview verfügbar. Weitere Informationen finden Sie in der API-Dokumentation und in zusätzlichen Beispielen.
Databricks Online Tables (AWS)(Azure) sind als Gated Public Preview verfügbar. Verwenden Sie dieses Formular, um sich für das Enablement anzumelden.
Lesen Sie die zusammenfassenden Ankündigungen (Erstellung hochwertiger RAG-Anwendungen), die Anfang dieser Woche gemacht wurden.
Generative KI Engineer Learning Pathway: Nehmen Sie an On-Demand-Kursen im Selbststudium und von Kursleitern geführten Kursen zu Generative KI teil
Möchten Sie Anwendungsfälle für Generative KI lösen? Nehmen Sie am Databricks & AWS Generative KI Hackathon teil! Hier können Sie sich registrieren.
Haben Sie einen Anwendungsfall, den Sie mit Databricks teilen möchten? Kontaktieren Sie uns unter feature-serving@databricks.com
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.