Wir stellen vor: Predictive Optimization: Schnellere Abfragen, günstigerer Speicher, kein Aufwand
von Sirui Sun, Vijayan Prabhakaran, Naga Raju Bhanoori, Rajesh Parangi Sharabhalingappa, Jintian Liang, Kam Cheung Ting, Vivek Narasimhan, Sunitha Beeram, Himanshu Raja, Rahul Potharaju, Reynold Xin, Matei Zaharia und Susan Pierce
Wir freuen uns, die Public Preview von Databricks Predictive Optimization anzukündigen. Diese Funktion optimiert intelligent die Datenlayouts Ihrer Tabellen für eine verbesserte Performance und Kosteneffizienz.
Prädiktive Optimierung nutzt Unity Catalog und Lakehouse AI, um die besten Optimierungen für Ihre Daten zu ermitteln, und führt diese Operationen dann auf einer speziell dafür entwickelten serverlosen Infrastruktur aus. Dies vereinfacht Ihren Weg zum Lakehouse erheblich und gibt Ihnen mehr Zeit, sich darauf zu konzentrieren, aus Ihren Daten einen geschäftlichen Nutzen zu ziehen.
Diese Funktion ist die neueste in einer langen Reihe von Databricks-Funktionen, die KI nutzen, um Aktionen basierend auf Ihren Daten und deren Zugriffsmustern vorausschauend durchzuführen. Zuvor haben wir Predictive I/O for reads und updates veröffentlicht, die diese Techniken bei der Ausführung von Lese- und Aktualisierungsabfragen anwenden.
Herausforderungen
Lakehouse-Tabellen profitieren stark von Hintergrundoptimierungen, die ihre Datenlayouts verbessern. Dazu gehört die Kompaktierung von Dateien, um angemessene Dateigrößen zu gewährleisten, oder das Vacuum, um nicht benötigte Datendateien zu bereinigen. Eine richtige Optimierung verbessert die Performance erheblich und senkt gleichzeitig die Kosten.
Dies stellt für Data-Engineering-Teams jedoch eine ständige Herausforderung dar, denn sie müssen Folgendes herausfinden:
- Welche Optimierungen sollen ausgeführt werden?
- Welche Tabellen sollten optimiert werden?
- Wie oft sollen diese Optimierungen ausgeführt werden?
Da Lakehouse-Plattformen immer größer werden und zunehmend als Self-Service genutzt werden, ist es für Plattformteams praktisch unmöglich, diese Fragen effektiv zu beantworten. Ein wiederkehrendes Feedback unserer Kunden ist, dass sie mit der Optimierung der zahlreichen Tabellen, die aus all den neuen Geschäftsanwendungsfällen erstellt werden, nicht Schritt halten können.
Darüber hinaus müssen Teams, selbst wenn diese heiklen Fragen beantwortet sind, weiterhin den operativen Aufwand für das Scheduling und die Durchführung dieser Optimierungen bewältigen – z. B. das Scheduling von Jobs, die Diagnose von Fehlern und die Verwaltung der zugrunde liegenden Infrastruktur.
So funktioniert die prädiktive Optimierung
Mit Predictive Optimization löst Databricks diese heiklen Probleme für Sie und gibt Ihnen wertvolle Zeit frei, um sich darauf zu konzentrieren, mit Ihren Daten einen geschäftlichen Mehrwert zu schaffen. Die prädiktive Optimierung kann mit einem einzigen Klick aktiviert werden. Danach übernimmt es die ganze schwere Arbeit.

Zuerst ermittelt Predictive Optimization intelligent, welche Optimierungen und wie oft deren Ausführung erfolgen soll. Unser KI-Modell berücksichtigt eine breite Palette von Eingaben, einschließlich der Nutzungsmuster Ihrer Tabellen sowie deren bestehendes Datenlayout und Leistungsmerkmale. Anschließend wird der ideale Optimierungs-Schedule ausgegeben, wobei die erwarteten Vorteile der Optimierung gegen die erwarteten compute-Kosten abgewogen werden.
Sobald der Schedule generiert ist, führt Predictive Optimization diese Optimierungen automatisch auf der speziell entwickelten serverlessen Infrastruktur aus. Es startet automatisch die korrekte Anzahl von Maschinen in der richtigen Größe und stellt sicher, dass Optimierungs-Tasks für eine optimale Effizienz ordnungsgemäß per Bin-Packing zusammengefasst und geplant werden.
Das gesamte System läuft End-to-End ohne manuelle Anpassung und Abstimmung und lernt im Laufe der Zeit aus der Nutzung Ihrer Organisation, wobei die für Ihre Organisation wichtigen Tabellen optimiert und die unwichtigen herabgestuft werden. Ihnen wird nur die Serverless-compute in Rechnung gestellt, die für die Durchführung der Optimierungen erforderlich ist. Standardmäßig werden alle Betriebe in einer Systemtabelle protokolliert, sodass Sie die Auswirkungen und Kosten der Betriebe einfach prüfen und nachvollziehen können.
Auswirkungen
In den letzten Monaten haben wir eine Reihe von Kunden in das Private-Preview-Programm für die Prädiktive Optimierung aufgenommen. Viele haben beobachtet, dass es den goldenen Mittelweg zwischen zwei gängigen Extremen findet:
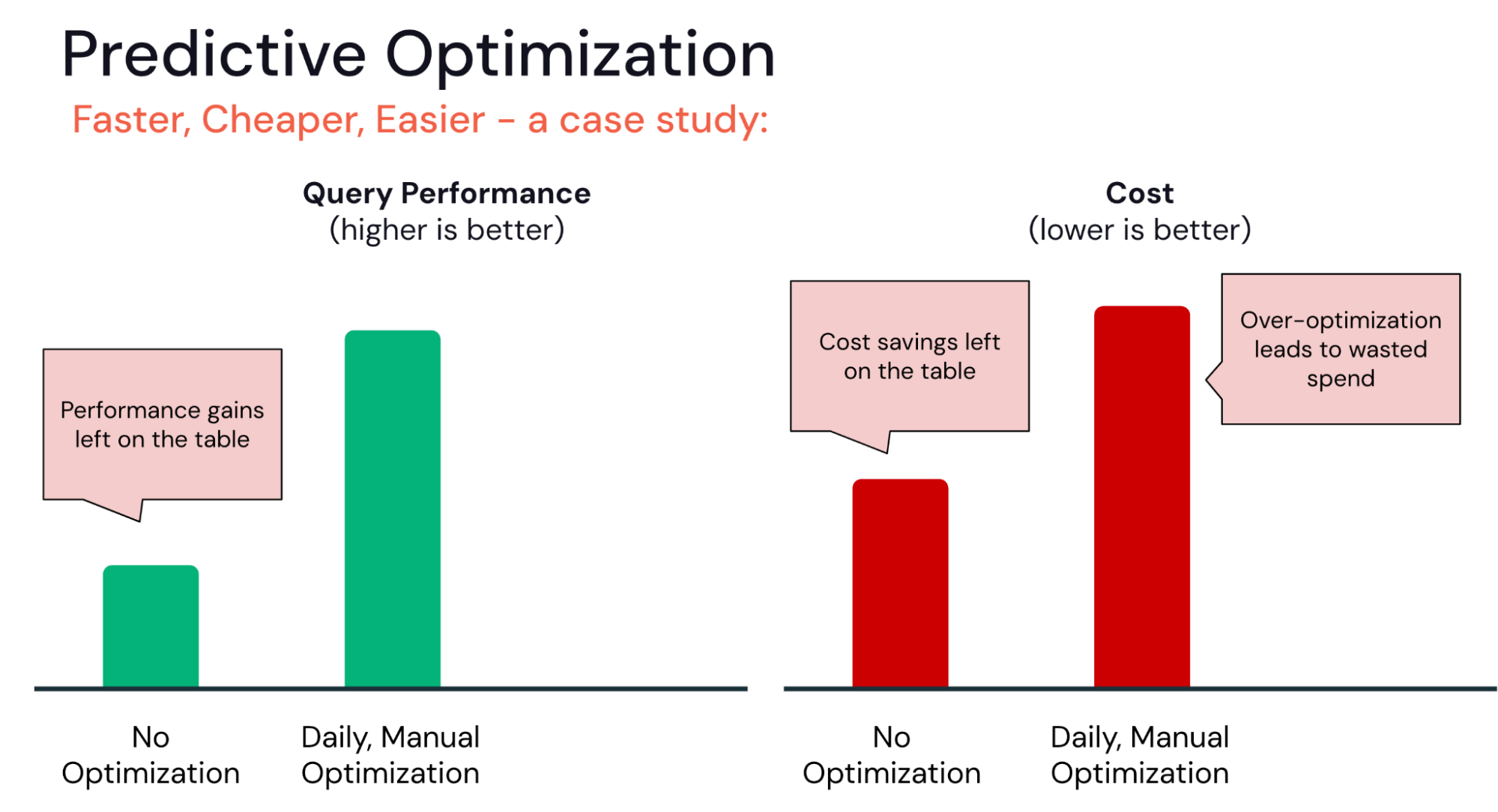
Im einen Extremfall haben einige Organisationen noch keine komplexen Pipelines zur Tabellenoptimierung eingerichtet. Mit Predictive Optimization können sie sofort mit der Optimierung ihrer Tabellen beginnen, ohne den besten Optimierungszeitplan ermitteln oder die Infrastruktur verwalten zu müssen.
Im anderen Extrem investieren einige Organisationen möglicherweise zu viel in die Optimierung. Für ein Team, das seine Optimierungs-Pipelines automatisiert, ist es beispielsweise verlockend, stündliche oder tägliche OPTIMIZE- oder VACUUM-Jobs auszuführen. Allerdings besteht bei diesen das Risiko sinkender Erträge. Könnten die gleichen Performance-Steigerungen mit weniger Optimierungsvorgängen erzielt werden?
Predictive Optimization hilft dabei, die richtige Balance zu finden und stellt sicher, dass Optimierungen nur bei einer hohen Kapitalrendite (Return on Investment) in Ausführung gebracht werden:
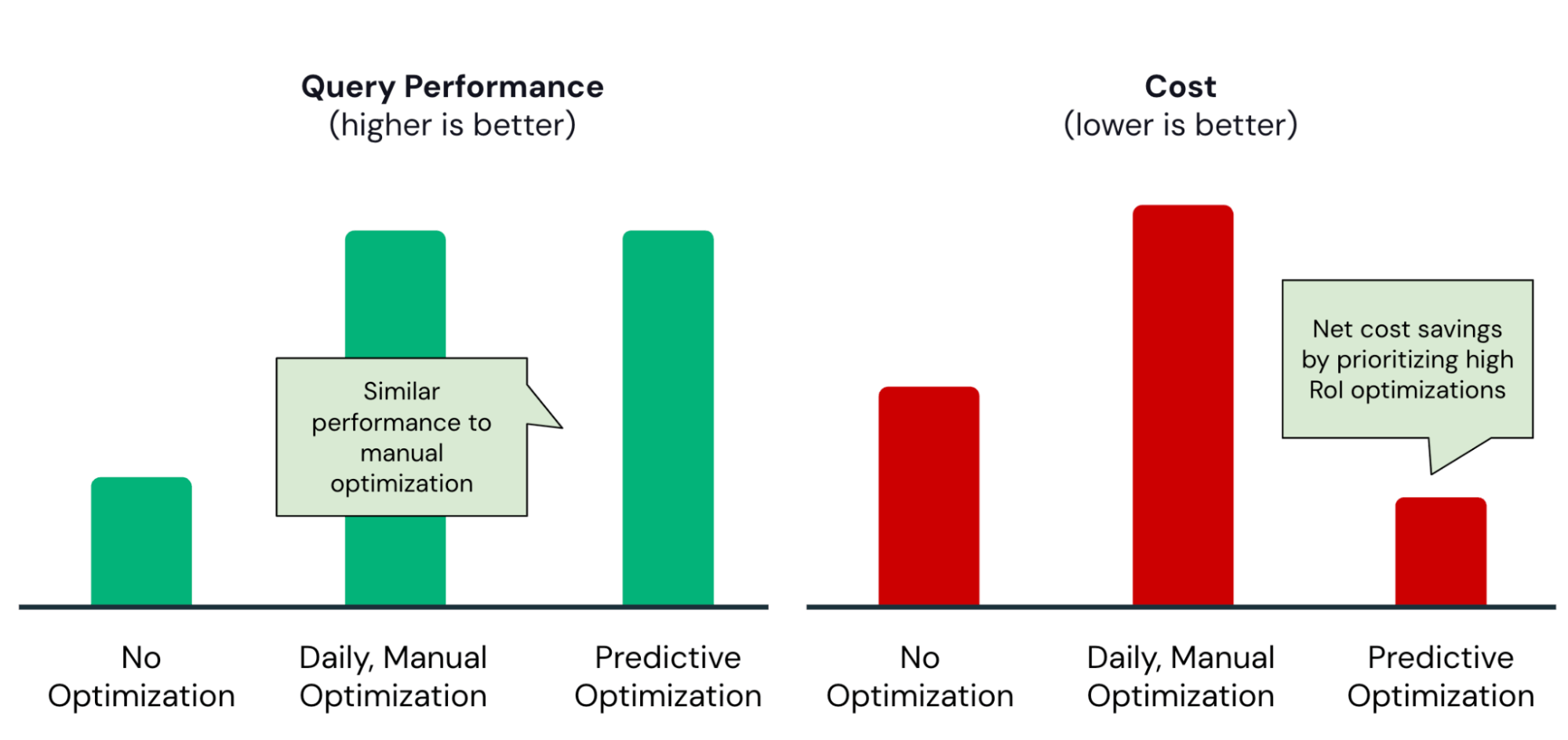
Als konkretes Beispiel hat das Data-Engineering-Team bei Anker Predictive Optimization aktiviert und schnell diese Vorteile realisiert:
50 % Reduzierung der jährlichen Speicherkosten
|
|
 2-fache Abfragebeschleunigung
2-fache Abfragebeschleunigung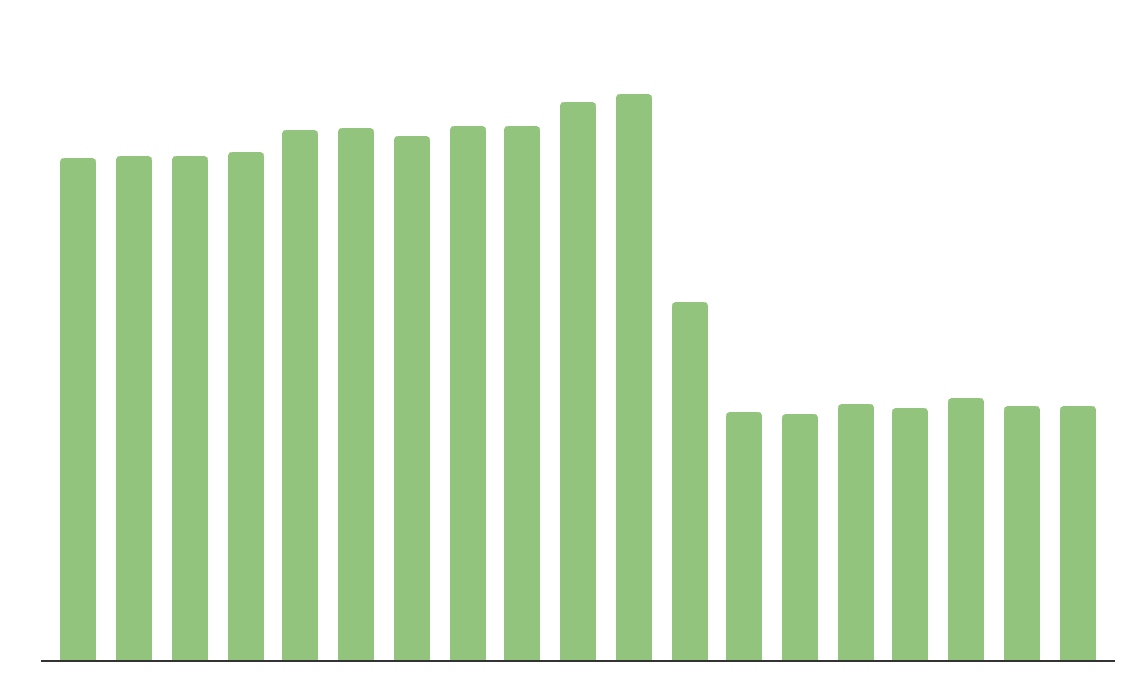
Erste Schritte
Ab heute ist Predictive Optimization in der Public Preview verfügbar. Die Aktivierung sollte weniger als fünf Minuten dauern. Als Kontoadministrator gehen Sie einfach zur Kontokonsole > Einstellungen > Feature-Aktivierung tab, und aktivieren Sie die Einstellung „Predictive Optimization“:
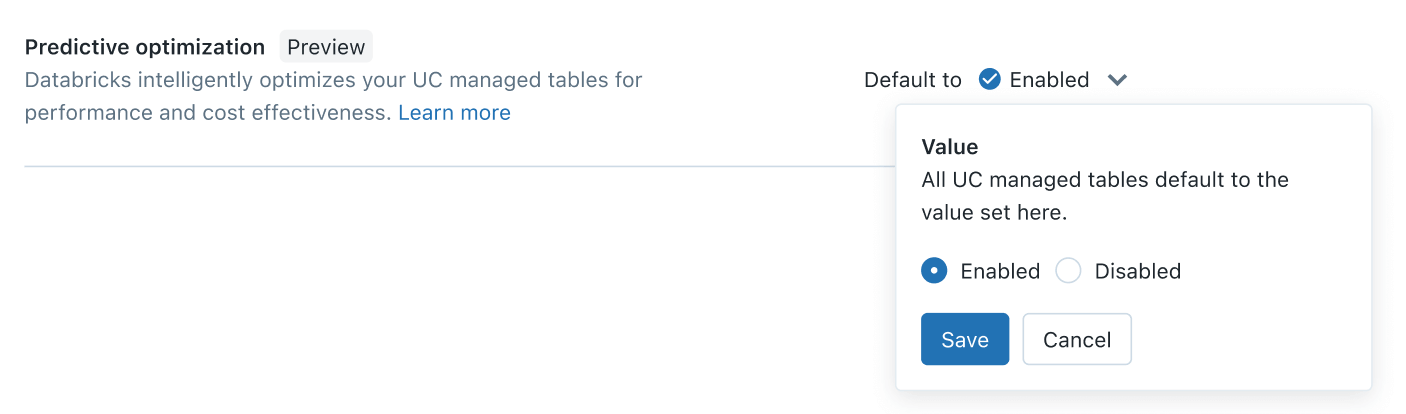
Mit nur einem Klick nutzen Sie die Leistung KI-optimierter Datenlayouts für Ihre von Unity Catalog verwalteten Tabellen, wodurch Ihre Daten schneller und kostengünstiger werden. Weitere Informationen finden Sie in der
Und das ist erst der Start. In den kommenden Monaten werden wir dieser Funktion weitere Optimierungen hinzufügen. Bleiben Sie dran für viel mehr.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.