Von Legacy zu Lakehouse: Wie Mazda GenAI für den technischen Service beschleunigte
Wie ein schlankes Team einen gesteuerten GenAI-Assistenten mit RAG, Unity Catalog und Vektorsuche entwickelte
von Tim Marx (Mazda), Foon Hoe Campbell-Wong (Mazda), Jiayi Wu, Arthur Dooner und Olivia Zhang
- Wie Mazda die Databricks Lakehouse-Plattform nutzte, um Servicehistorie, Diagnosedaten und Dokumente als Grundlage für GenAI zusammenzuführen.
- Wie das Team den GenAI-Assistenten entwickelte, einschließlich der Abfrage der richtigen Dokumente und der Logik für die gemeinsame Nutzung zwischen der Benutzeroberfläche und dem Agenten.
- Wie Mazda von ad-hoc GenAI-Tests zu wiederholbaren Auswertungen und Testfällen mit MLflow überging.
Automobilhersteller stehen unter Druck. Das Anrufvolumen steigt weiter, Elektrofahrzeuge führen zu neuer Komplexität bei der Diagnose, und vernetzte Autos generieren mehr Daten, als die Mitarbeiter im Service-Center realistisch durchsehen können. Jedes Modelljahr bringt Hunderte von Service-Informationen (SI)-Dokumenten mit sich, die jeweils einzigartige Verfahren und Bedingungen aufweisen. Wenn sich etwas ändert, benötigen die Mitarbeiter im Service-Center Zeit, um es zu verarbeiten, bevor sie die Techniker sicher durch unbekannte Probleme führen können. Diese Verzögerung ist entscheidend, wenn ein Kunde wartet.
Mazda hatte bereits die Rohstoffe zur Lösung dieses Problems: einen wachsenden Lakehouse mit Garantie-, Rückruf-, Diagnosecodes-, Service- und Fahrzeughistorie sowie eine sich ständig aktualisierende Bibliothek von Service-Dokumenten. Die Herausforderung bestand darin, diese Assets so zusammenzuführen, dass die Fähigkeit der Mitarbeiter, ihre Arbeit mit Genauigkeit, Konsistenz und Zuversicht zu erledigen, verbessert wird.
Hier kam Databricks ins Spiel. Das Datenteam von Mazda arbeitete schnell und lernte im Prozess, vom Kickoff bis zu einem funktionierenden Konzept in etwa acht Wochen. Es gab keine lange Planungsphase. Das Team baute, testete, machte Fehler und passte sich an, während es ein Pilotprojekt lieferte, das für Mazda echten Einfluss und Wert hatte.
Ausgangspunkt: Ein kleines Team mit großen Ambitionen
Dieses Projekt war eine der ersten End-to-End-GenAI-Initiativen von Mazda, die vollständig auf seiner neuen Cloud-Datenplattform aufgebaut wurde. Das Team war klein – zwei Datenwissenschaftler, die schnell iterierten – und die Werkzeuge waren noch in einem frühen Stadium. Datenpipelines mussten erstellt werden. Dokumente mussten extrahiert und in Vektorsuchindizes umgewandelt werden. Experimente liefen in isolierten Notebooks, und der Erfolg hing mehr vom Gedächtnis als von der Nachverfolgbarkeit ab.
Für ein so kleines Team musste der Infrastrukturaufwand minimal sein. Das war ein wichtiger Faktor bei der Wahl von Databricks. Die Plattform ermöglichte Agilität: keine Verwaltung von Vektordatenbanken, keine Konfiguration von verteilten Compute-Frameworks, keine maßgeschneiderte Orchestrierung, keine Klebedienste, um alles zusammenzufügen. Der Fokus liegt auf der Wertschöpfung – nicht auf der Infrastruktur.
Aufbau des Pilotprojekts
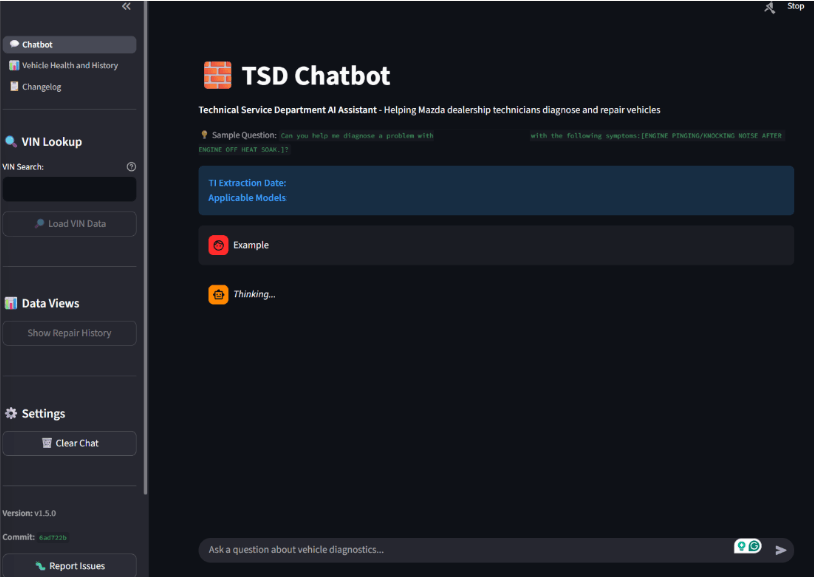
Zu Beginn des Pilotprojekts konzentrierte sich das Team auf ein Retrieval Augmentation Generation (RAG)-Design, wobei der Schwerpunkt auf der Verbindung eines LLM mit unserem benutzerdefinierten Korpus lag. Bald bemerkte Mazda, dass Tester oft ein vollständiges Bild des Fahrzeugs wünschten: seine Servicehistorie, offene Rückrufe, frühere Eskalationen im Callcenter, Garantie-Status.
Diese Beobachtung prägte eine bewusste architektonische Entscheidung: das Frontend und der Agent teilen sich Code und Werkzeuge. Der Zugriff auf Fahrzeugdaten, die Transformation und die Prompting-Logik werden einmal implementiert und von der Streamlit-Oberfläche und dem bereitgestellten Agenten-Endpunkt identisch verwendet.
Wenn ein Service-Mitarbeiter zu Beginn einer Sitzung eine VIN eingibt, lädt das Frontend den vollständigen Fahrzeugkontext (Reparaturhistorie, Eskalationen im Callcenter, Garantiedaten, Rückrufstatus) vor und fügt ihn in den System-Prompt ein, bevor die erste Nachricht gesendet wird. Dies eliminiert Tool-Aufrufe und sorgt für sofortige Interaktivität.
Wenn der KI-Agent hingegen ohne diesen vorab geladenen Kontext aufgerufen wird, verwendet er dieselben Werkzeuge, mit denen die Benutzer interagieren. Die Ausgabe ist in beiden Fällen strukturell identisch, und der System-Prompt behandelt beide Pfade explizit: Kontext verwenden, wenn vorhanden, Tools aufrufen, wenn nicht. Ein Prompt, zwei Ausführungsmodi, keine Verhaltensabweichung zwischen den Oberflächen.
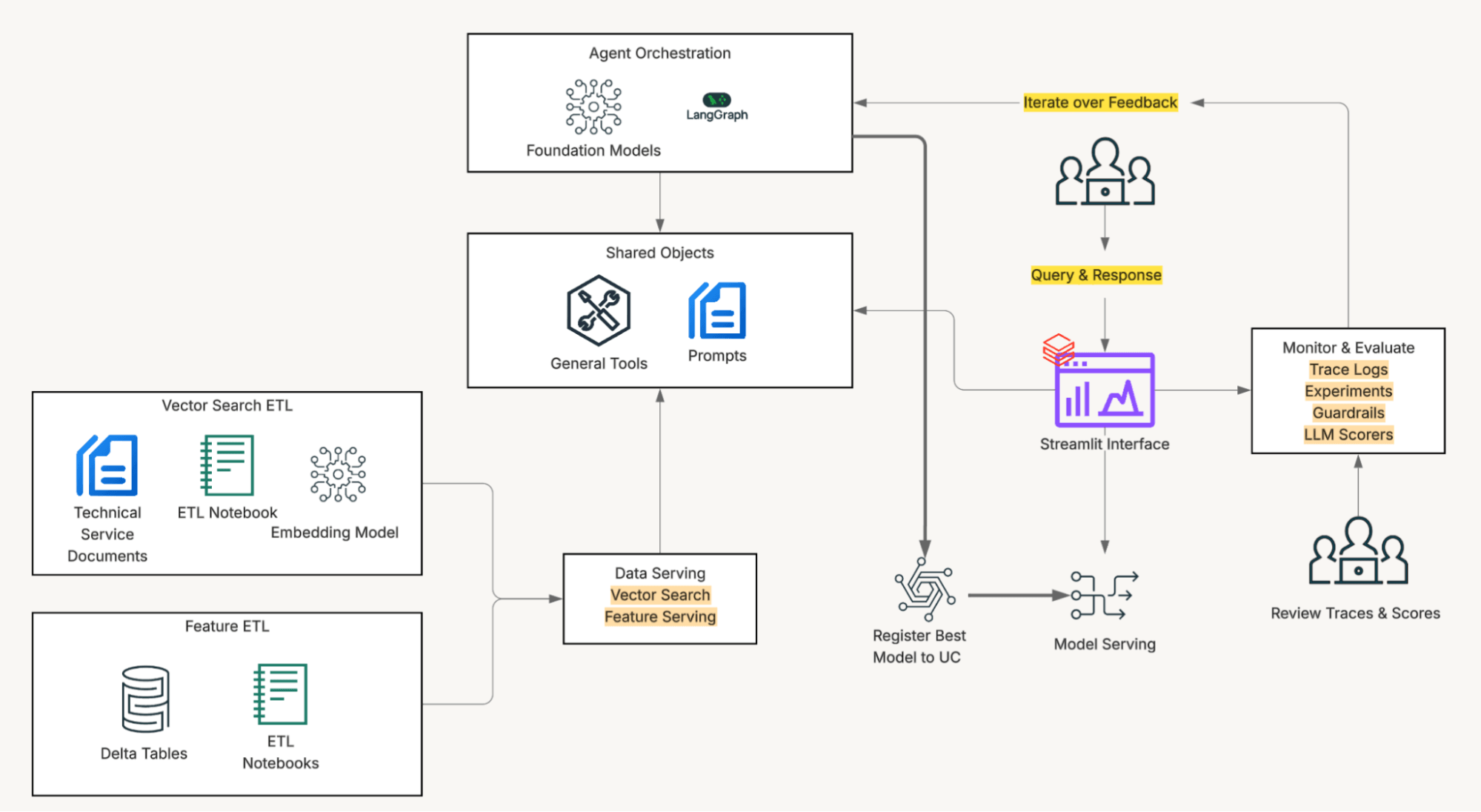
Unity Catalog
Die Lösung wird durch den Databricks Lakehouse angetrieben. Unity Catalog bietet kontrollierten Zugriff auf die Daten, auf die die Service-Mitarbeiter täglich angewiesen sind, und wo Embeddings, Vektorsuche, SQL-Tool-Aufrufe und Modell-Serving in derselben Umgebung laufen, was die Entwicklung vereinfacht und Integrationsprobleme beseitigt. Mazda nutzte LLMs über die Foundation Models API (Pay-per-Token) und das Embedding-Modell über den verwalteten Vektorsuch-Endpunkt.
Alles befindet sich innerhalb des Unity Catalog: SI-Dokumente, Delta-Tabellen mit Fahrzeughistorie und Diagnosecodes, Vektorsuchindizes, Datentransformationen und Modelle. Einheitliche Governance bedeutet die Möglichkeit, den Zugriff auf bestimmte Datenteilmengen zu isolieren, Änderungen im laufenden Betrieb vorzunehmen und die Auswirkungen sofort zu beobachten. Dann verbindet Databricks Apps alles mit einem Streamlit-Frontend, das Service-Teams ohne neue Schulungen oder Werkzeuge nutzen können.
Genaue Korpusfilterung, ermöglicht durch Unity Catalog-Funktionen
Eine naive Vektorsuche im gesamten Korpus liefert Ergebnisse, die semantisch plausibel, aber nicht unbedingt für das Fahrzeug vor dem Techniker relevant sind. Um die Abfrage richtig zu gestalten, musste zuerst ein Skoping-Problem gelöst werden, bevor ein Relevanzproblem gelöst werden konnte.
Das Team implementierte die Filterung über benutzerdefinierte Funktionen (User-Defined Functions, UDFs) des Unity Catalog. Bevor eine Vektorsuche durchgeführt wird, ruft das System eine UC-Funktion auf, die die VIN (oder den Diagnosefehlercode) der Teilmenge der für dieses Fahrzeug zutreffenden Dokumente zuordnet und die semantische Übereinstimmung auf die zutreffenden Dokumente beschränkt.
Das Hosten dieser Logik als Unity Catalog-Funktion anstelle von Anwendungscode bedeutet, dass die Anwendbarkeitsregeln neben den Daten leben, die sie steuern, sowohl für den Agenten als auch für jede andere nachgelagerte Anwendung zugänglich sind und unabhängig vom Bereitstellungszyklus des Agenten aktualisiert werden können.
Von Ad-hoc-Tests zur testgetriebenen Entwicklung
Mazda pilotierte die Anwendung mit 10 Service-Agenten-Testern. Zu Beginn des Pilotprojekts basierte die Iteration auf Feedback: Tester meldeten Probleme, das Team passte Prompts oder die Abfragekonfiguration an und bewertete das Ergebnis informell. Das funktionierte für die anfängliche Entwicklung, skalierte aber nicht, als das System komplexer wurde.
Das native GenAI-Evaluierungsframework von MLflow 3 veränderte den Workflow des Teams. MLflow 3 bietet eine umfassende Möglichkeit, Evaluationsdatensätze und eine Vielzahl von LLM- und deterministischen Scorern zu erstellen. Für schnelle Tests werden Entwurfs-Evaluationsdatensätze in YAML definiert, bevor sie zu Standard-Evaluationsdatensätzen befördert werden. Wenn Tester eine Lücke aufzeigten, fügte das Team diese dem Evaluationsdatensatz hinzu und betrachtete das Bestehen dieser Fälle als Akzeptanzkriterium für jede Korrektur. Wenn neue Funktionen und Datenquellen hinzugefügt wurden, wurden neue Evaluationsfälle geschrieben, bevor die Integration akzeptiert wurde.
Das Ergebnis war eine Verschiebung von „es scheint besser“ zu „es ist besser, und hier sind die Beweise“. Experiment-Spuren erfassten Prompts, Abfragestrategien, Token-Anzahlen und Metriken zur Antwortqualität, sodass Änderungen objektiv und nicht nach Gedächtnis verglichen werden konnten.
Mehrsprachige Fähigkeiten
Der schnelle anfängliche Erfolg führte zu der Frage, ob die gleiche Architektur auch für andere Regionen dienen könnte. Nach Experimenten mit mehrsprachigen Embedding-Modellen stellte das Team fest, dass LLMs die Benutzer-Prompts und die endgültige Antwort übersetzen können, ohne die Kernarchitektur und die Werkzeuge zu ändern. Dies hat Auswirkungen auf Mazdas umfassendere Pläne, die Anwendung auf weitere Märkte auszudehnen.
Governance
Die Abstimmung von Berechtigungen über Apps, Cluster, Warehouses, Endpunkte und Agenten hinweg hatte eine Lernkurve, aber sobald sie standardisiert war, schuf sie ein wiederverwendbares Governance-Muster, das sicher und für zukünftige GenAI-Anwendungen anwendbar ist. Das funktionierende Muster: Leiten Sie den gesamten Zugriff über das Service Principal des Serving-Endpunkts und definieren Sie Berechtigungen auf Katalog- und Schema-Ebene für rollenbasierte Zugriffskontrollgruppen. Sobald dies etabliert war, wurde es wiederverwendbar – die Aufnahme eines neuen Modells oder einer neuen Datenquelle bedeutete, dem gleichen Service Principal Zugriff auf dasselbe Schema zu gewähren, anstatt die Berechtigungsstruktur neu zu verhandeln. In Kombination mit privater Konnektivität für KI-Traffic bietet dies Mazda einen kontrollierten, sicheren Weg zwischen Anwendungen und verwalteten Daten.
Die Partnerschaft mit dem Databricks Field Engineering Team ermöglichte es Mazda, schneller voranzukommen, geleitet von Best Practices und der Vorwegnahme von Hindernissen.
Auswirkungen und Nächstes
Mazda verfügt nun über eine wiederholbare Grundlage für GenAI-Anwendungen, die strukturierte und unstrukturierte Daten kombinieren, alles innerhalb des Lakehouse: Vektorsuchindizes, Modell-Serving, Evaluierungen, Beobachtbarkeit, Katalog-Level-Governance und Frontend-Bereitstellung über eine Web-App. Diese Fähigkeiten auf einer einzigen Plattform zu haben, machte das Zusammenfügen mehrerer Dienste überflüssig, was die Entwicklung um ein Vielfaches beschleunigte.
Zwei Datenwissenschaftler, die mit isolierten Notebooks begannen, betreiben nun KI-Anwendungen und -Experimente mit vollständiger Nachverfolgbarkeit auf Databricks. Das Team erweitert den Ansatz auf zusätzliche Diagnose-Workflows und untersucht, wie generative Agenten Techniker, Außendienstingenieure und den Kundensupport unterstützen können.
Dieser Wandel ist nicht nur technisch. Er bewegt Mazda von deskriptiver Berichterstattung hin zu intelligenten, generativen Anwendungen, die direkt auf verwalteten Unternehmensdaten aufgebaut sind.
Fazit
Sie brauchen kein großes Team oder eine ausgereifte MLOps-Praxis, um aussagekräftige GenAI-Anwendungen zu erstellen. Mazda hatte zwei Data Scientists, knappe Zeitpläne und viel zu lernen. Databricks als Plattform hat mehr Schwerstarbeit geleistet als erwartet, und Databricks hat uns geholfen, schnell etwas Reales zu liefern.
Im Kern ist das Projekt ein Ausdruck von Omotenashi – Mazdas Leitprinzip der herzlichen Gastfreundschaft. Bessere Werkzeuge für Mazdas Servicetechniker helfen ihnen, sich besser um ihre Kunden zu kümmern. Und jetzt, mit dieser Grundlage, hat das Team gerade erst angefangen.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.