SQL ETL für moderne Datenplattformen neu überdenken
Reduzieren Sie Kosten und Komplexität, indem Sie fragmentierte SQL-Pipelines auf einer einzigen Plattform vereinheitlichen
von Matt Jones und Shanelle Roman
- Fragmentierte SQL-ETL treiben versteckte Kosten, brüchige Pipelines und langsame Problemlösung voran
- Die Ausführung von ETL über Warehouses, Orchestratoren und Tools hinweg erzeugt operative Belastungen, die mit jeder Pipeline skalieren
- Eine vereinheitlichte Plattform für alle SQL-ETL beseitigt Koordinationsaufwand und ermöglicht es Teams, schneller auf einem einzigen, gesteuerten System zu liefern
SQL ist die Grundlage moderner Datenarbeit. So definieren Analytics Engineers Transformationen, so verwalten Data Warehouse Engineers Pipelines und so erkunden und verfeinern Analysten Daten.
Aber während SQL selbst standardisiert ist, sind die Systeme, die zur Ausführung von SQL ETL verwendet werden, alles andere als das.
In den meisten Organisationen sind SQL-Pipelines über eine Kombination von Tools verteilt: ein Data Warehouse für die Ausführung, ein Transformations-Framework für die Modellierung, ein Orchestrator für die Planung und separate Systeme für Monitoring, Lineage und Datenqualität. Jede Ebene erfüllt einen bestimmten Bedarf, aber zusammen schaffen sie eine fragmentierte Umgebung, die schwierig zu betreiben und zunehmend schwierig zu skalieren ist.
Wenn Datenteams wachsen, zeigt sich diese Fragmentierung im Tagesgeschäft. Pipelines schlagen über mehrere Systeme hinweg fehl, Abhängigkeiten sind schwer nachzuvollziehen und die Lösung von Problemen erfordert oft das Springen zwischen Tools, die nie dafür konzipiert wurden, zusammenzuarbeiten. Gleichzeitig steigen die Erwartungen. Teams werden gebeten, aktuellere Daten zu liefern, mehr Anwendungsfälle zu unterstützen und schneller zu agieren, ohne den operativen Aufwand zu erhöhen.
Hier beginnen viele Strategien für Datenplattformen zu scheitern. Selbst wenn Organisationen in moderne Infrastrukturen investieren, bleibt SQL ETL oft über mehrere Systeme verteilt und trägt die gleiche Komplexität und Einschränkungen mit sich.
Die Herausforderung ist nicht SQL selbst – es geht darum, wie SQL ETL implementiert wird.
Wenn SQL ETL von Grund auf für die Art und Weise konzipiert wäre, wie Teams heute tatsächlich arbeiten, würde es ganz anders aussehen. In der Praxis würde das bedeuten:
- Eine einzige Plattform für ETL
- Unterstützung für jeden SQL-Praktiker
- Offene, zukunftssichere Pipelines
Zusammen definieren diese Prinzipien einen einfacheren und robusteren Ansatz für SQL ETL – einen, der die Fragmentierung heute reduziert und gleichzeitig die Entwicklung von Daten-Workloads im Laufe der Zeit unterstützt.
SQL ETL auf einer einzigen Plattform ausführen und betreiben
Die Herausforderung bei SQL ETL liegt nicht im Schreiben von Transformationen – es geht darum, Pipelines zu betreiben, wenn sie mehrere Systeme umfassen.
In der Praxis bedeutet dies die Koordination der Ausführung im Data Warehouse, die Orchestrierung in einem separaten System und die anschließende Überwachung. Um Pipelines am Laufen zu halten, müssen diese Teile zusammengefügt werden – Abhängigkeiten verfolgen, Fehler diagnostizieren und Wiederholungsversuche über Tools hinweg verwalten, die keinen Kontext teilen.
Wenn die Anzahl und Bedeutung von Pipelines wächst, wird diese Koordination zu einer erheblichen operativen Belastung.
Eine einheitliche Plattform vereinfacht dieses Modell, indem sie diese Funktionen zusammenführt. Wenn Ausführung, Orchestrierung, Beobachtbarkeit und Governance Teil desselben Systems sind, werden Pipelines per Design einfacher zu verwalten. Abhängigkeiten werden automatisch verfolgt und Probleme können schneller identifiziert und behoben werden, da der relevante Kontext an einem Ort verfügbar ist.
Auf Databricks werden SQL ETL-Pipelines innerhalb einer einzigen Plattform definiert und ausgeführt. Pipelines laufen mit integrierter Orchestrierung, während Lineage und Beobachtbarkeit über jede Stufe hinweg automatisch erfasst werden. Datenqualitätsprüfungen und Governance-Kontrollen sind direkt in die Pipeline-Ausführung integriert, anstatt über separate Tools verwaltet zu werden.
Dieser Ansatz wird durch serverlose Infrastruktur und KI-gestützte Optimierung weiter gestärkt. Performance-Tuning, Ressourcenmanagement und Skalierung werden automatisch gehandhabt, sodass sich Teams auf die Bereitstellung zuverlässiger Daten konzentrieren können, anstatt Systeme zu betreiben.
Nach der Umstellung unserer Databricks-Pipelines auf serverlose Rechenleistung erzielte HP Cloud-Einsparungen von über 32 % und reduzierte die kombinierte Laufzeit von Jobs um 36 %. Das mühelose Infrastrukturmanagement, das Serverless bietet, machte diese Entscheidung zu einer offensichtlichen und strategischen Wahl. —Luis Alonso, Head of Data Strategy & Engineering bei HP Marketing
Das Ergebnis ist eine optimierte und zuverlässige Grundlage für SQL ETL – eine, die den operativen Aufwand reduziert und gleichzeitig Leistung und Zuverlässigkeit in großem Maßstab verbessert.
Unterstützen Sie die Art und Weise, wie Teams SQL-Pipelines tatsächlich erstellen
SQL ETL ist nicht nur wegen der Tools fragmentiert, sondern weil Teams Pipelines nicht alle auf die gleiche Weise erstellen.
Analytics Engineers – die sich auf die Definition von Geschäftslogik in SQL konzentrieren – wünschen sich oft eine Möglichkeit, Pipelines zu erstellen, ohne die zugrunde liegende Infrastruktur zu verwalten, wobei Tests, Versionskontrolle und Abhängigkeiten automatisch gehandhabt werden. Data Warehouse Engineers verlassen sich tendenziell auf SQL-Skripte und gespeicherte Prozeduren, oft in eng kontrollierten Ausführungsumgebungen. Analysten erstellen möglicherweise Transformationen direkt in No-Code-Tools oder schlanken SQL-Schnittstellen.
Viele Plattformen bevorzugen implizit einen dieser Ansätze. Wenn Organisationen wachsen, führen sie oft zusätzliche Systeme ein, um andere Personas zu unterstützen, was zu parallelen Umgebungen führt, die schwer zu standardisieren und zu warten sind.
Ein effektiverer Ansatz ist die Standardisierung der Plattform anstelle der Schnittstelle.
Databricks unterstützt eine Reihe von SQL ETL-Workflows innerhalb derselben Umgebung. Teams können bestehende dbt-Workflows direkt auf der Plattform ausführen, Warehouse-ähnliches SQL in Skripte und gespeicherte Prozeduren übertragen, BI-Workloads mit Materialized Views in Databricks SQL beschleunigen, deklarative Pipelines definieren, die Produktions-Workflows vereinfachen, oder No-Code-Tools für Business-Analysten nutzen, die auf derselben Plattform aufbauen. Obwohl sich diese Ansätze in der Art und Weise, wie Pipelines erstellt werden, unterscheiden, teilen sie dieselbe Ausführungs-Engine, dasselbe Governance-Modell und denselben Beobachtbarkeits-Framework.

Diese Konsistenz ermöglicht es Organisationen, mehrere Entwicklungsstile zu unterstützen, ohne die Art und Weise, wie Pipelines ausgeführt werden, zu fragmentieren. Teams können auf der Abstraktionsebene arbeiten, die ihren Bedürfnissen entspricht, und dennoch von gemeinsam genutzten Lineage-, Überwachungs- und operativen Kontrollen profitieren.
Es stellt auch sicher, dass bestehende Warehouse-ähnliche SQL-Skripte und neuere Ansätze auf derselben Grundlage koexistieren können. Teams müssen sich nicht zwischen der Wartung dessen, was sie haben, und der Einführung neuer Muster entscheiden – sie können beides innerhalb eines einzigen Systems tun.
Jeder dieser Workflows spiegelt sich in einer dedizierten Authoring-Umgebung wider.
1. Für Data Warehouse Engineers, die SQL-Skripte und gespeicherte Prozeduren ausführen:
SQL-Editor für gespeicherte Prozeduren & Materialized Views
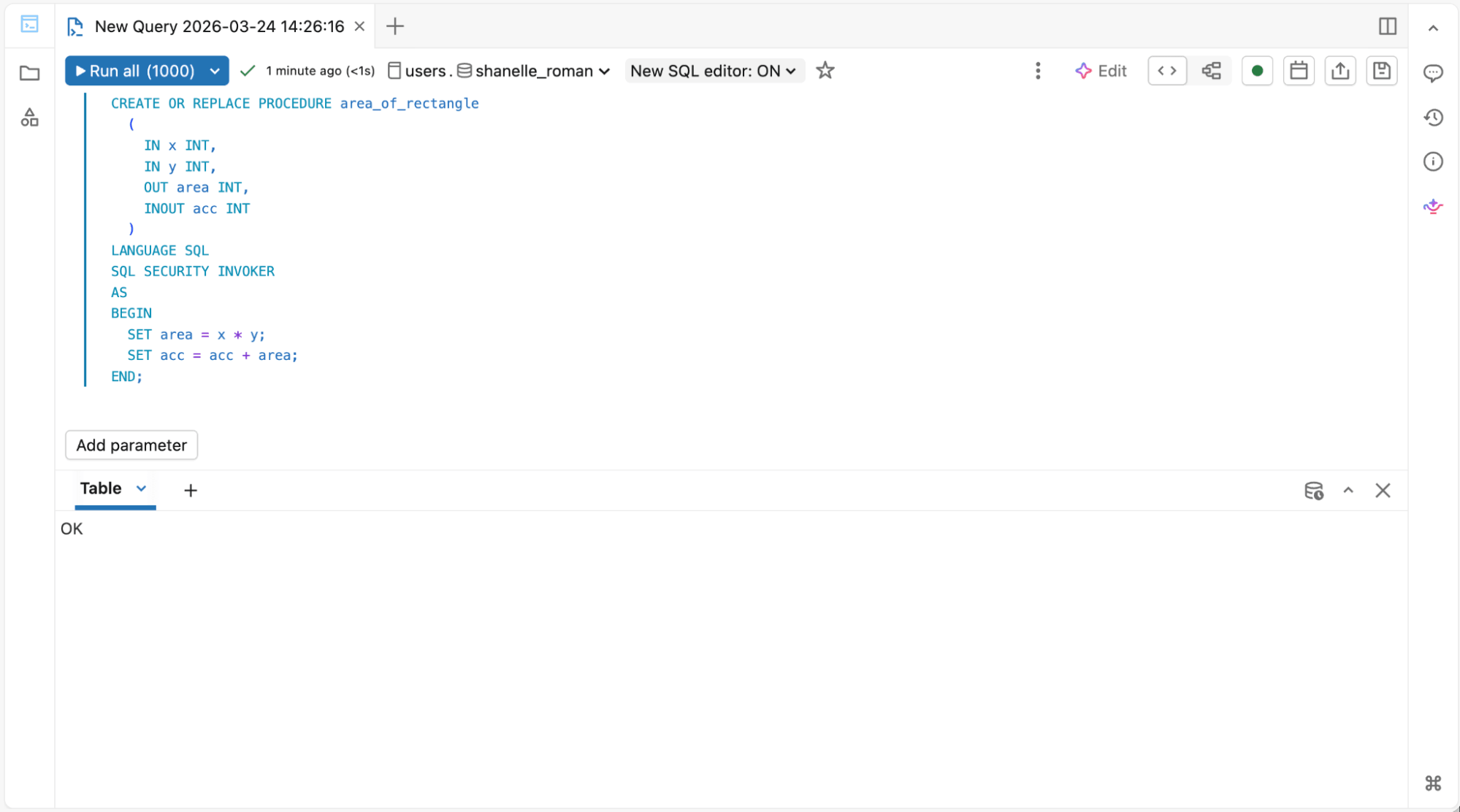
{kind=link}
2. Für Analytics Engineers, die Produktions-Pipelines mit SQL erstellen:
Spark Declarative Pipelines Editor
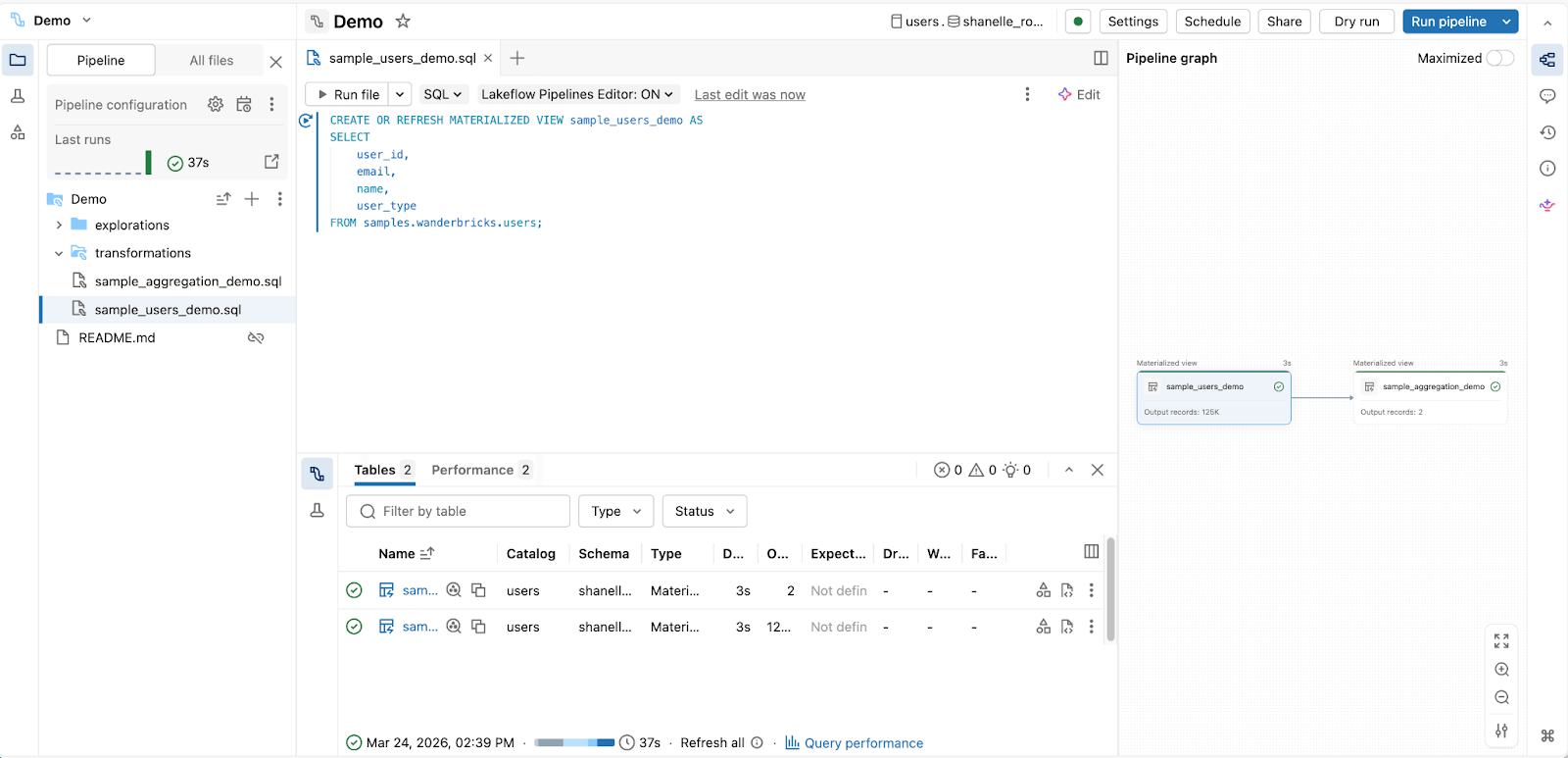
3. Für Analysten und Business-Anwender, die Daten ohne Code vorbereiten:
Lakeflow Designer
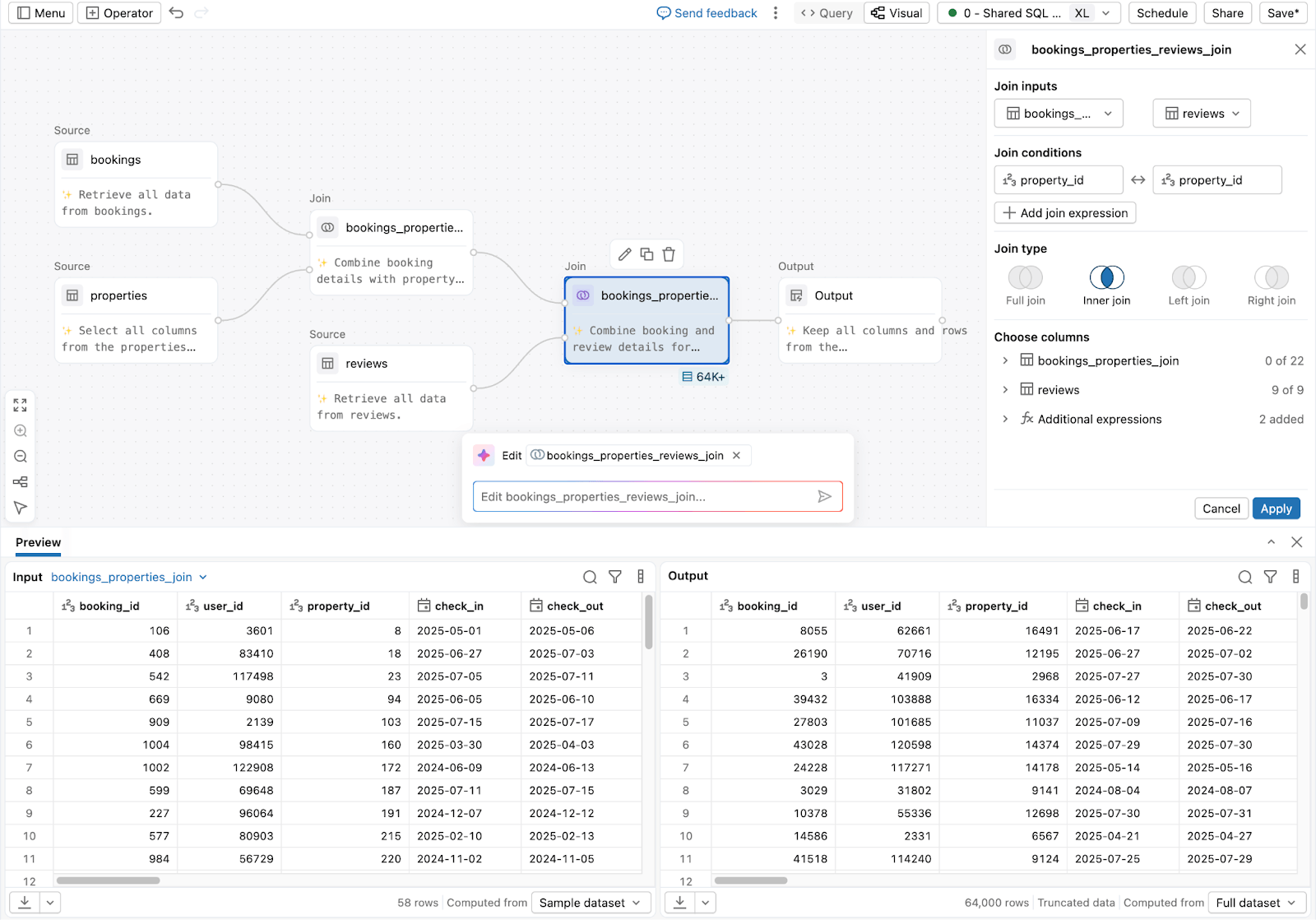
Das Ergebnis ist eine kohärentere Umgebung für SQL ETL, in der die Zusammenarbeit verbessert wird und die operative Komplexität mit zunehmender Skalierung nicht steigt.
Erstellen Sie SQL-Pipelines, die sich mit Ihren Workloads weiterentwickeln
Wenn neue Datenquellen, Echtzeit-Anwendungsfälle und KI-Workloads entstehen, sind Teams oft gezwungen, zusätzliche Systeme einzuführen oder bestehende Pipelines neu zu schreiben – was im Laufe der Zeit Komplexität und Kosten erhöht.
Viele SQL ETL-Lösungen führen diese Einschränkungen durch proprietäre Formate, eng gekoppelte Ausführungsmodelle oder Annahmen darüber ein, wie Daten verarbeitet werden. Diese Einschränkungen sind möglicherweise nicht sofort ersichtlich, aber sie treten tendenziell auf, wenn Organisationen in neue Workloads expandieren, aktuellere Daten benötigen oder eine breitere Palette von Anwendungsfällen unterstützen.
Ein zukunftssicherer Ansatz für SQL ETL priorisiert von Anfang an Offenheit und Flexibilität.
Databricks baut SQL ETL auf offenen Tabellenformaten und ANSI SQL auf, um sicherzustellen, dass Pipelines portabel und interoperabel zwischen Systemen bleiben. Dies reduziert das Risiko von Lock-ins und ermöglicht es Organisationen, die Kontrolle über ihre Daten und Logik zu behalten, während sich ihre Architektur weiterentwickelt.
Gleichzeitig bietet Databricks ein einheitliches SQL-Modell, das sowohl Batch- als auch Echtzeit-Analyseanwendungsfälle unterstützt. Anstatt separate Systeme für verschiedene Workloads zu benötigen, kann derselbe SQL-basierte Ansatz für eine breite Palette von Anwendungsfällen angewendet werden.
Diese Flexibilität ermöglicht es Pipelines, sich parallel zur Organisation weiterzuentwickeln. Teams können weiterhin bestehende SQL-Workflows ausführen und gleichzeitig fortschrittlichere Muster – wie inkrementelle Verarbeitung oder deklarative Pipelines – übernehmen, wenn sie benötigt werden.
Die Umstellung auf Materialized Views hat zu einer drastischen Verbesserung der Abfrageleistung geführt, wobei sich die Ausführungszeit von 8 Minuten auf nur 3 Sekunden reduziert hat. Dies ermöglicht unserem Team, effizienter zu arbeiten und schnellere Entscheidungen auf der Grundlage der gewonnenen Erkenntnisse zu treffen. Außerdem haben die zusätzlichen Kosteneinsparungen wirklich geholfen. —Karthik Venkatesan, Security Software Engineering Sr. Manager, Adobe
Durch die Vermeidung starrer architektonischer Einschränkungen bietet dieser Ansatz eine stabile Grundlage, die sowohl aktuelle Anforderungen als auch zukünftige Anforderungen unterstützen kann, ohne disruptive Änderungen zu erfordern.
Warum SQL ETL Ihre Data-Platform-Strategie prägen sollte
Diskussionen über Datenplattformen konzentrieren sich oft darauf, wo Daten gespeichert und wie Abfragen ausgeführt werden. In der Praxis hängt die Effektivität einer Plattform jedoch genauso davon ab, wie Datenpipelines erstellt und gepflegt werden und ob sie auf offene, interoperable Weise definiert sind, die langfristige Abhängigkeiten vermeidet.
Wenn SQL ETL über mehrere Systeme fragmentiert bleibt, werden Organisationen wahrscheinlich die gleichen betrieblichen Komplexitäten und Ineffizienzen mitnehmen, selbst nach der Einführung einer neuen Plattform. Im Laufe der Zeit schränkt dies den Wert der Plattform ein und erschwert die Skalierung von Datenoperationen.
Ein effektiverer Ansatz besteht darin, zu bewerten, wie gut eine Plattform SQL ETL über ihren gesamten Lebenszyklus unterstützt – von der Entwicklung und Ausführung bis hin zur Überwachung und Governance. Dazu gehört die Fähigkeit, unterschiedliche Arbeitsstile zu unterstützen, den Betriebsaufwand zu reduzieren und sich an sich entwickelnde Anforderungen anzupassen, ohne zusätzliche Systeme einzuführen.
Databricks erfüllt diese Anforderungen, indem es SQL-Ausführung, Pipeline-Management, Governance und Optimierung auf einer einzigen Plattform kombiniert. Dieser einheitliche Ansatz ermöglicht es Teams, SQL-Pipelines effizienter zu erstellen und zu betreiben und gleichzeitig die Flexibilität zu wahren, eine breite Palette von Workloads zu unterstützen.
Schlussfolgerung
SQL wird weiterhin eine zentrale Rolle dabei spielen, wie Organisationen mit Daten arbeiten.
Daher hat die Implementierung von SQL ETL direkte Auswirkungen auf die Effektivität der gesamten Datenplattform. Fragmentierte Ansätze führen zu Komplexität und verlangsamen Teams, während einheitliche Ansätze den Betrieb vereinfachen und die Skalierbarkeit verbessern.
Für Organisationen, die die Weiterentwicklung ihrer Datenplattformen bewerten, ist SQL ETL ein Kernaspekt. Databricks bietet ein Modell für ein einheitliches, zukunftssicheres SQL ETL, das Ausführung, Pipeline-Management und Governance auf einer einzigen Plattform vereint und gleichzeitig offen und anpassungsfähig bleibt, wenn sich Anforderungen weiterentwickeln.
In der Praxis beginnen die meisten Organisationen nicht bei Null. Die Modernisierung von SQL ETL kommt oft zum Stillstand, da die Kosten und Risiken einer Neufassung von Produktionspipelines zu hoch sind. Anstatt einen disruptiven Umbau zu erzwingen, ist ein effektiverer Ansatz die schrittweise Weiterentwicklung – zuerst bestehende Pipelines ausführen, Systeme im Laufe der Zeit konsolidieren und schrittweise modernisieren.
So können Teams die Fragmentierung heute reduzieren und gleichzeitig auf eine einheitlichere, zukunftssichere Datenplattform hinarbeiten. Diesen Ansatz werden wir in einem zukünftigen Beitrag detaillierter behandeln. In der Zwischenzeit können Sie in diesem E-Book, A Guide to Building ETL Pipelines with SQL, mehr über die Erstellung, Ausführung und Skalierung von SQL-Pipelines auf einer einheitlichen Lakehouse-Plattform erfahren.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.