SAP- und Salesforce-Datenintegration für Lieferantenanalysen auf Databricks
Verwenden Sie SAP Business Data Cloud Connect und Lakeflow Connect, um CRM- und ERP-Daten für Lieferanten-Analytics zusammenzuführen.
- Verbinden Sie SAP S/4HANA- und Salesforce-Daten direkt in Databricks
- Nutzen Sie Lakeflow Connect und SAP BDC für einen inkrementellen Zero-Copy-Zugriff
- Erstellen Sie einen regulierten Gold-Layer für Analytics und dialogorientierte Einblicke
So erstellen Sie Lieferanten-Analytics mit Salesforce-SAP-Integration auf Databricks
Lieferantendaten berühren nahezu jeden Bereich einer Organisation – von der Beschaffung und dem Lieferkettenmanagement bis hin zu Finanzen und Analysen. Doch sie sind oft über Systeme verteilt, die nicht miteinander kommunizieren. Beispielsweise enthält Salesforce Anbieterprofile, Kontakte und Accountdetails, und SAP S/4HANA verwaltet Rechnungen, Zahlungen und Hauptbucheinträge. Da diese Systeme unabhängig voneinander arbeiten, fehlt den Teams eine umfassende Sicht auf die Lieferantenbeziehungen. Das Ergebnis sind langsame Abstimmungen, doppelte Datensätze und verpasste Gelegenheiten zur Ausgabenoptimierung.
Databricks löst dieses Problem, indem es beide Systeme auf einer einzigen verwalteten Daten- & KI-Plattform verbindet. Mit Lakeflow Connect for Salesforce für die Datenaufnahme und SAP Business Data Cloud (BDC) Connect können Teams CRM- und ERP-Daten ohne Duplizierung vereinheitlichen. Das Ergebnis ist eine einzige, vertrauenswürdige Ansicht von Anbietern, Zahlungen und Performance Metriken, die sowohl Anwendungsfälle für die Beschaffung und das Finanzwesen als auch für Analytics unterstützt.
In dieser Anleitung erfahren Sie, wie Sie beide Datenquellen verbinden, eine kombinierte Pipeline aufbauen und eine Gold-Schicht erstellen, die Analysen und dialogorientierte Einblicke durch KI/BI-Dashboards und Genie ermöglicht.
Warum die Zero-Copy-Datenintegration von SAP und Salesforce funktioniert
Die meisten Unternehmen versuchen, SAP und Salesforce über herkömmliche ETL- oder Drittanbieter-Tools zu verbinden. Diese Methoden erstellen mehrere Datenkopien, verursachen Latenz und erschweren die Governance. Databricks verfolgt einen anderen Ansatz.
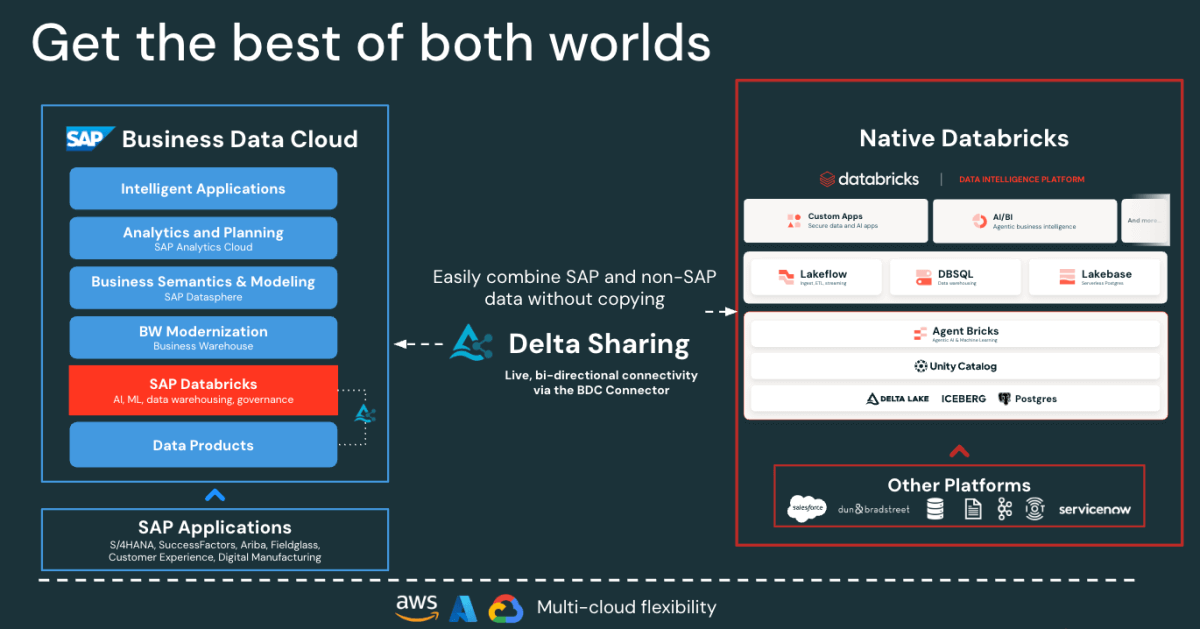
SAP-Zugriff ohne Kopieren: Der SAP BDC Connector for Databricks bietet Ihnen einen kontrollierten Echtzeitzugriff auf SAP S/4HANA-Datenprodukte über Delta Sharing. Keine Exporte oder Duplizierung.
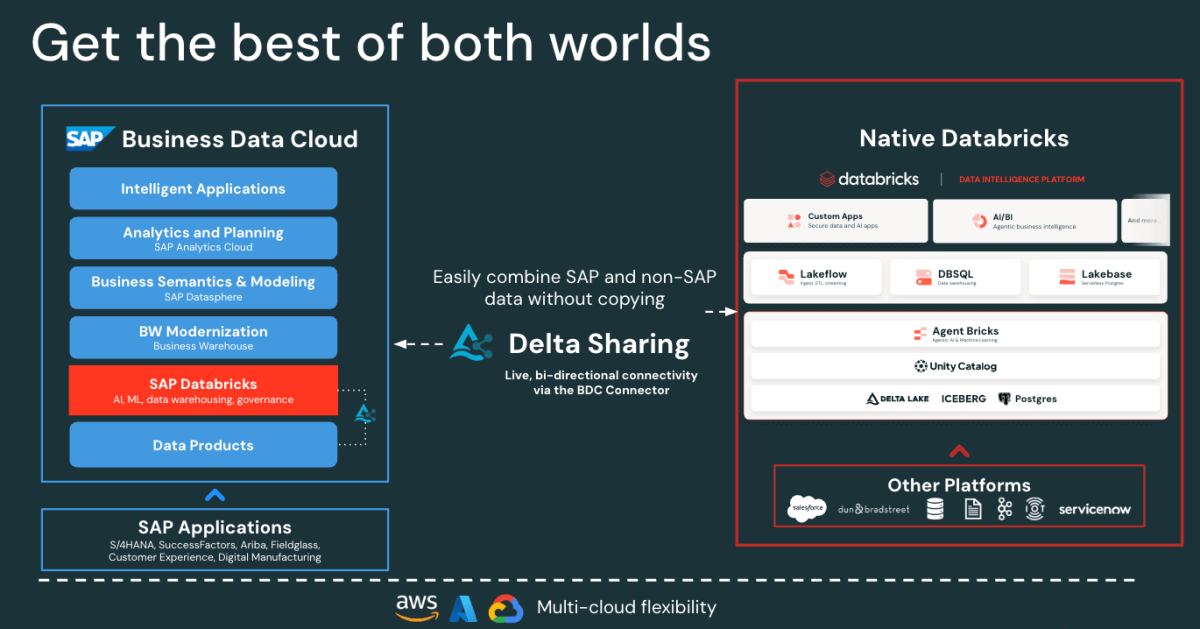
Figure: SAP BDC Connector to Native Databricks(Bi-directional) - Schnelle inkrementelle Salesforce-Ingestion: Lakeflow verbindet sich kontinuierlich mit Salesforce-Daten und erfasst diese, damit Ihre Datensätze stets aktuell und konsistent sind.
- Einheitliche Governance: Unity Catalog setzt Berechtigungen, Datenherkunft und Auditing sowohl für SAP- als auch für Salesforce-Quellen durch.
- Deklarative Pipelines: Lakeflow Spark Declarative Pipelines vereinfachen das ETL-Design und die Orchestrierung mit automatischen Optimierungen für eine bessere Performance.
{kind=link}
Zusammen ermöglichen diese Funktionen es Dateningenieuren, SAP- und Salesforce-Daten auf einer Plattform zu kombinieren, wodurch die Komplexität reduziert und gleichzeitig eine Governance auf Unternehmensebene gewährleistet wird.
SAP-Salesforce-Datenintegrationsarchitektur auf Databricks
Bevor Sie die Pipeline erstellen, ist es nützlich zu verstehen, wie diese Komponenten in Databricks zusammenpassen.
Auf hoher Ebene veröffentlicht SAP S/4HANA Geschäftsdaten als kuratierte, sofort einsatzbereite und von SAP verwaltete Datenprodukte in der SAP Business Data Cloud (BDC). SAP BDC Connect for Databricks ermöglicht über Delta Sharing den sicheren, kopierfreien Zugriff auf diese Datenprodukte. Währenddessen übernimmt Lakeflow Connect die Salesforce-Ingestion und erfasst dabei Account-, Kontakt- und Opportunity-Daten über inkrementelle Pipelines.
Alle eingehenden Daten, ob von SAP oder Salesforce, werden für Governance, Datenherkunft und Berechtigungen im Unity Catalog verwaltet. Data Engineers verwenden dann Lakeflow Declarative Pipelines, um diese Datasets zu joinen und in eine Medallion-Architektur (Bronze-, Silber- und Gold-Schichten) zu transformieren. Schließlich dient die Gold-Schicht als Grundlage für Analytics und Exploration in AI/BI-Dashboards und Genie.
Diese Architektur stellt sicher, dass die Daten aus beiden Systemen synchronisiert und gesteuert bleiben und für Analysen und KI bereit sind – ohne den Aufwand von Replikation oder externen ETL-Tools.
Wie Sie einheitliches Supplier Analytics erstellen
Die folgenden Schritte beschreiben, wie Sie SAP- und Salesforce-Daten auf Databricks verbinden, zusammenführen und analysieren.
Schritt 1: Ingestion von Salesforce-Daten mit Lakeflow Connect
Verwenden Sie Lakeflow Connect, um Salesforce-Daten in Databricks zu importieren. Sie können Pipelines über die Benutzeroberfläche oder die API konfigurieren. Diese Pipelines verwalten inkrementelle Updates automatisch und stellen sicher, dass die Daten ohne manuelle Refreshes auf dem neuesten Stand bleiben.
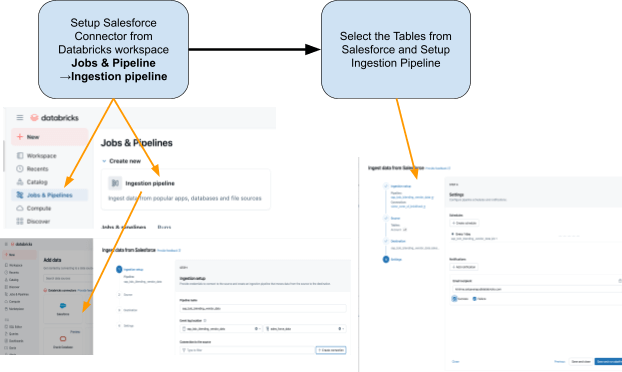
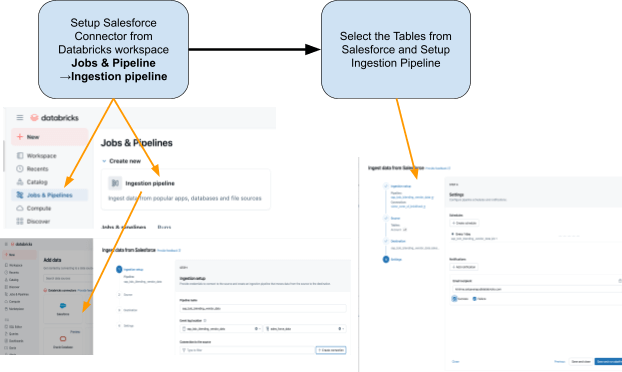{kind=link}
Der Connector ist vollständig in die Unity Catalog-Governance, die Lakeflow Spark Declarative Pipelines für ETL und die Lakeflow Jobs für die Orchestrierung integriert.
Dies sind die Tabellen, die wir aus Salesforce erfassen möchten:
- Account: Kreditoren-/Lieferantendetails (Felder umfassen: AccountId, Name, Industry, Type, BillingAddress)
- Kontakt: Lieferantenkontakte (Felder enthalten: ContactId, AccountId, FirstName, LastName, E-Mail)
Schritt 2: Auf SAP-S/4HANA-Daten mit dem SAP BDC Connector zugreifen
SAP BDC Connect bietet einen live und gesteuerten Zugriff auf Kreditorenzahlungsdaten von SAP S/4HANA direkt in Databricks. Dadurch entfällt der herkömmliche ETL-Prozess, da das SAP BDC-Datenprodukt sap_bdc_working_capital.entryviewjournalentry.operationalacctgdocitemgenutzt wird – die Ansicht Einzelposten des Universal Journals.
Dieses BDC-Datenprodukt ist direkt der SAP-S/4HANA-CDS-View I_JournalEntryItem (Einzelposten des operativen Buchhaltungsbelegs) auf ACDOCA zugeordnet.
Im ECC-Kontext waren die nächstgelegenen physischen Strukturen BSEG (FI-Belegpositionen) mit Kopfdaten in BKPF, CO-Buchungen in COEP, und Indizes für offene/ausgeglichene Posten BSIK/BSAK (Kreditoren) und BSID/BSAD (Kunden). In SAP S/4HANA sind diese BS** -Objekte Teil des vereinfachten Datenmodells, in dem Kreditoren- und Hauptbuchpositionen im Universal Journal (ACDOCA) zentralisiert sind, was den ECC-Ansatz ersetzt, der oft das Verbinden mehrerer separater Finanztabellen erforderte.
Dies sind die Schritte, die im SAP BDC Cockpit ausgeführt werden müssen.
1: Melden Sie sich beim SAP BDC Cockpit an und überprüfen Sie die SAP BDC Formation in der Systemlandschaft. Stellen Sie über den Delta-Sharing -Konnektor von SAP BDC eine Verbindung zu Native Databricks her. Weitere Informationen dazu, wie Sie Native Databricks mit dem SAP BDC verbinden, damit es Teil seiner Formation wird.
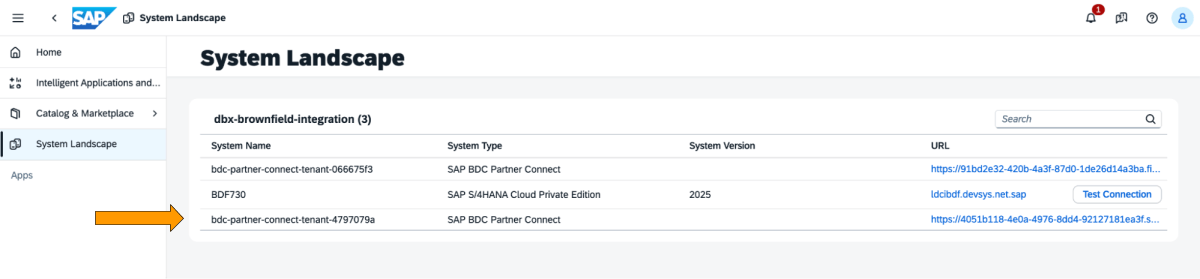
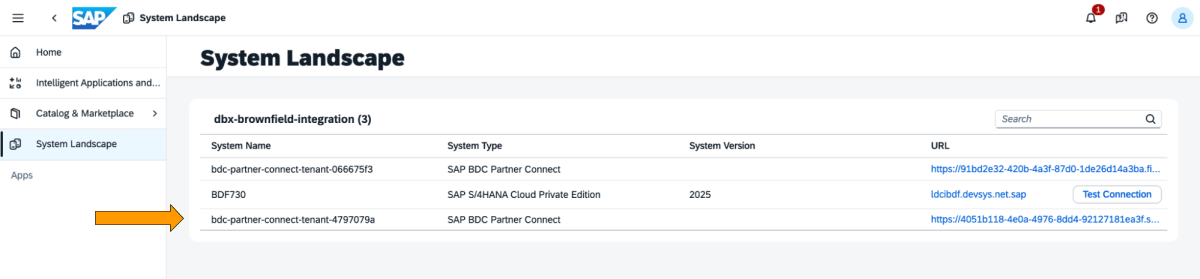{kind=link}
2: Gehen Sie zum Katalog und suchen Sie nach „Data Product Entry View Journal Entry“, wie unten gezeigt
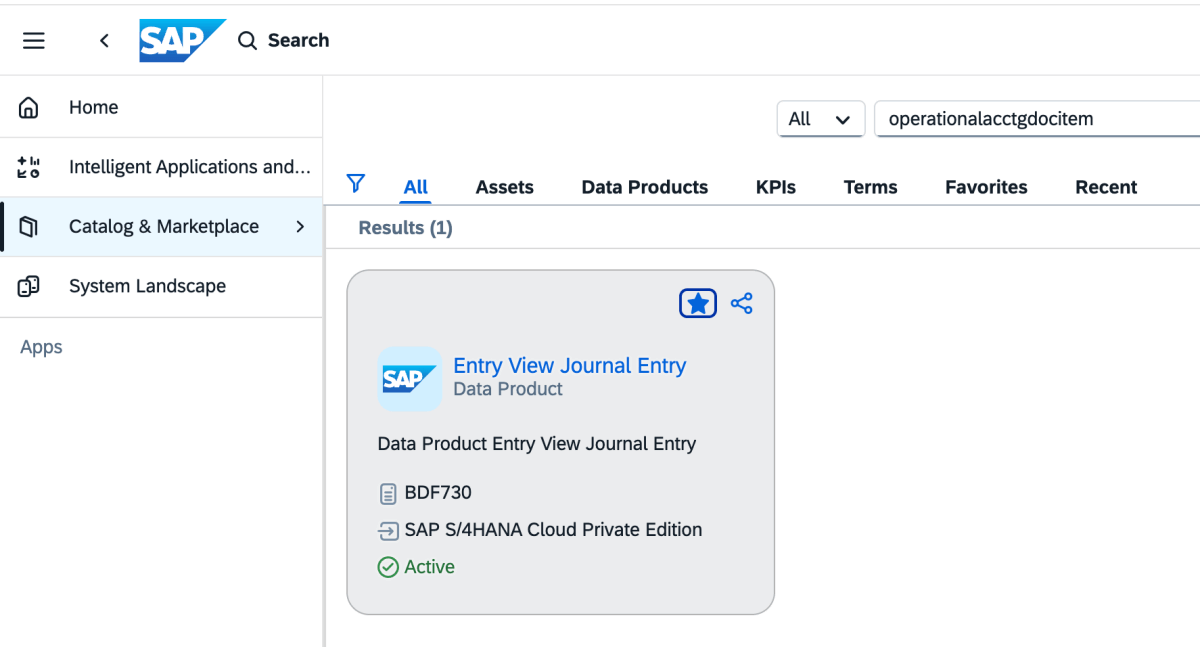
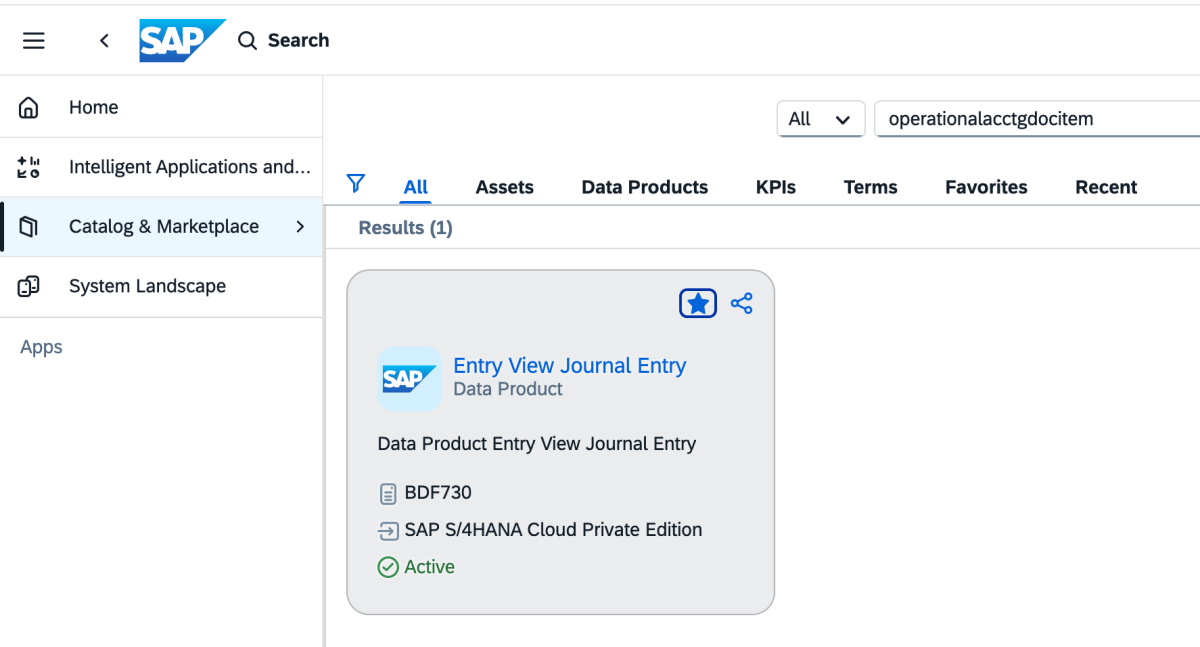{kind=link}
3: Wählen Sie für das Datenprodukt „Teilen“ und dann das Zielsystem aus, wie in der folgenden Abbildung dargestellt.
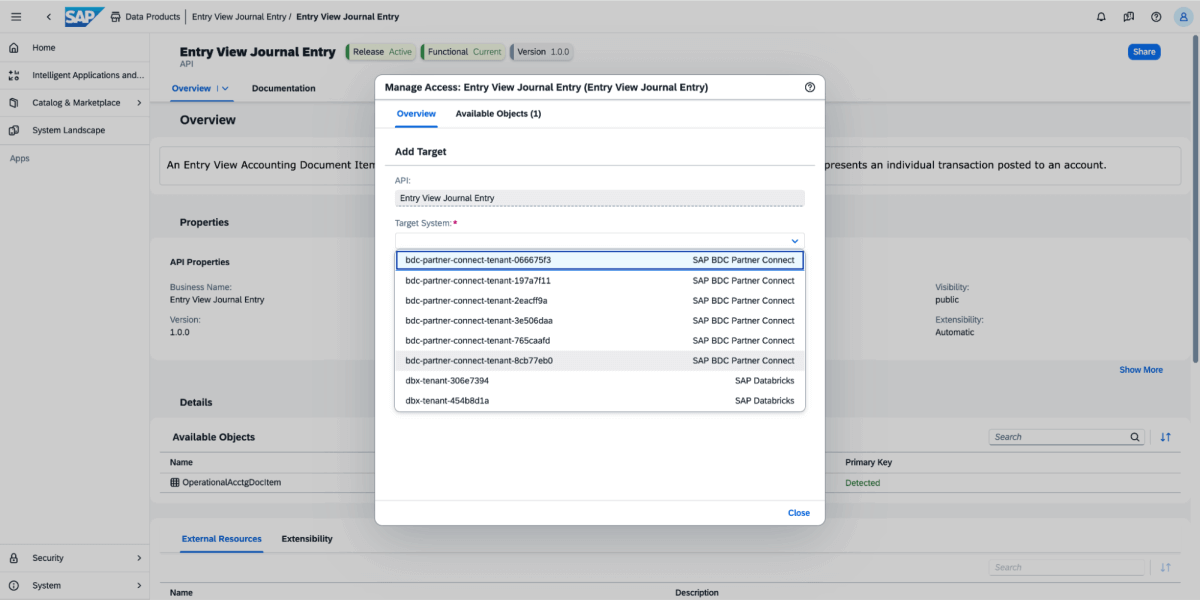
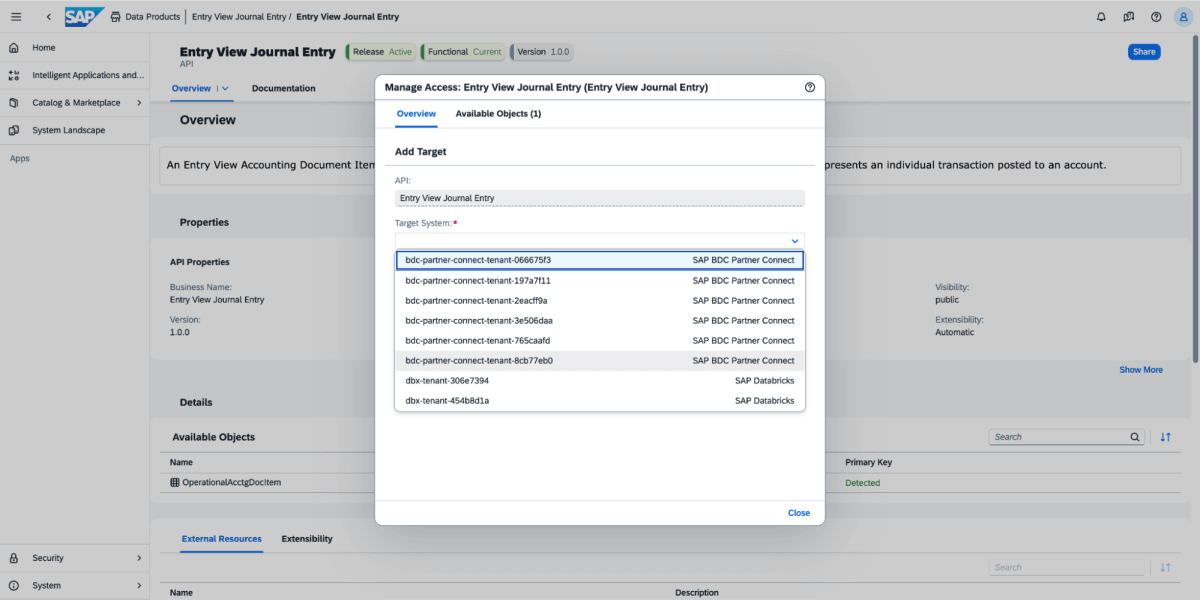{kind=link}
4: Sobald das Datenprodukt freigegeben ist, wird es wie unten gezeigt als Delta Share im Databricks-Workspace angezeigt. Stellen Sie sicher, dass Sie über die Berechtigung „Use Provider“ verfügen, um diese Anbieter sehen zu können.
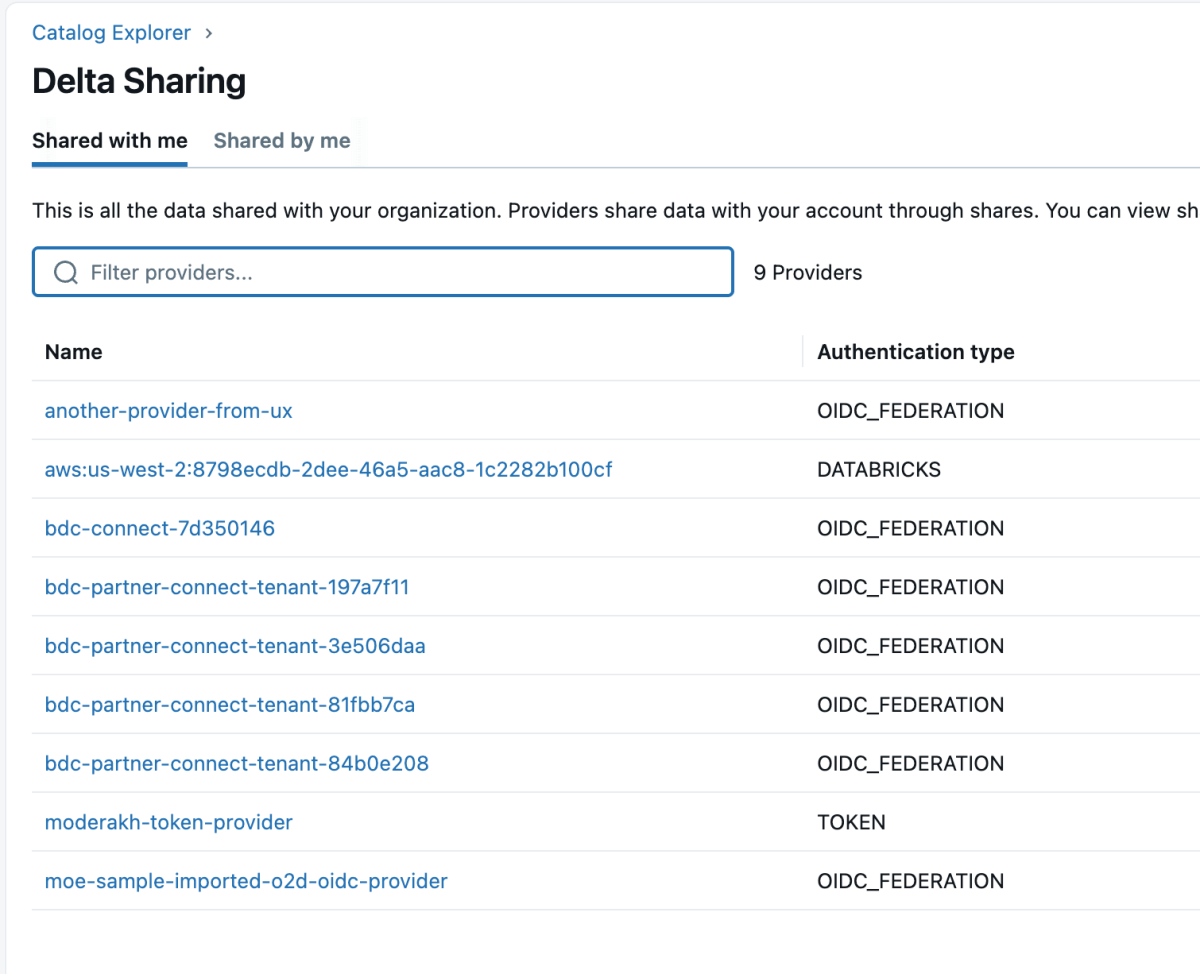
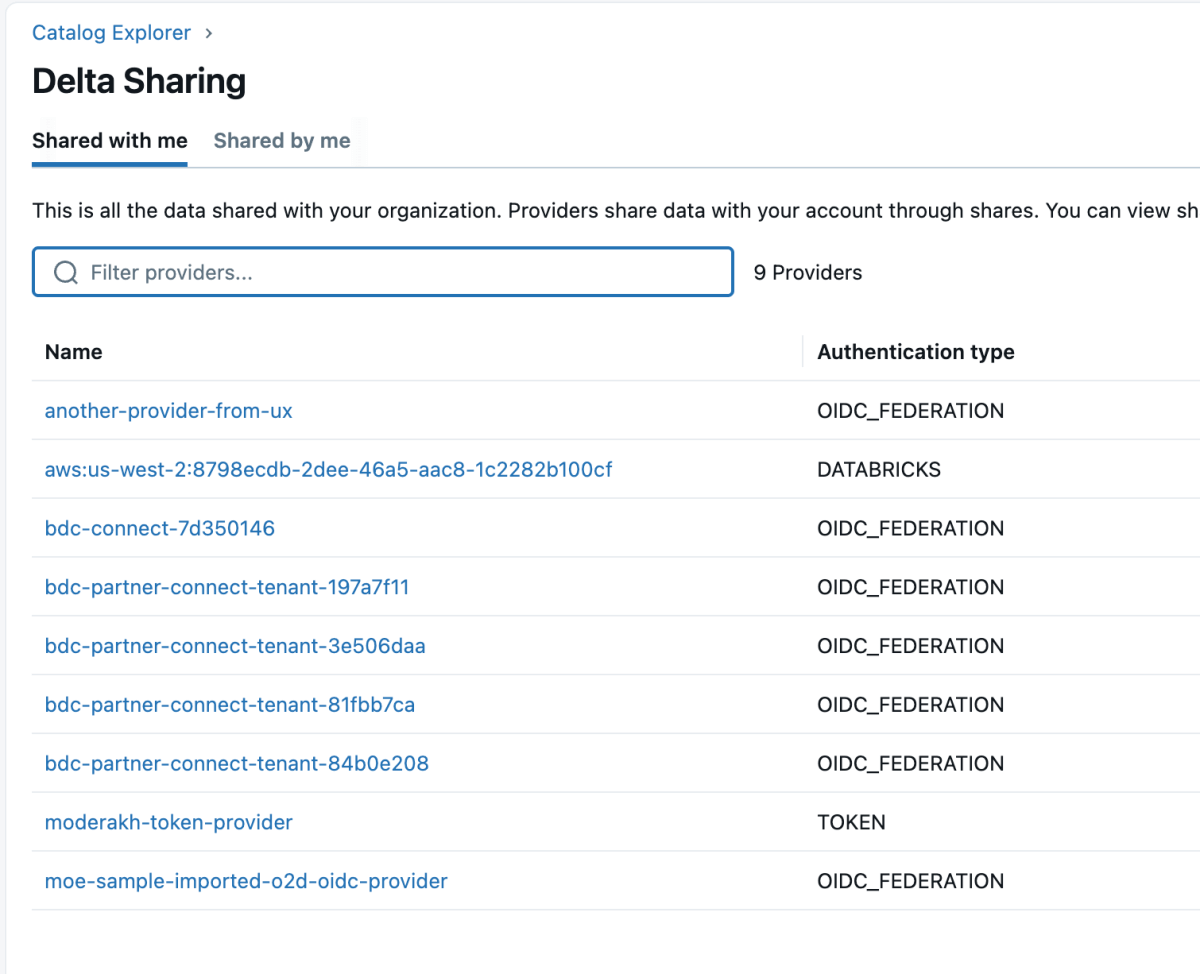{kind=link}
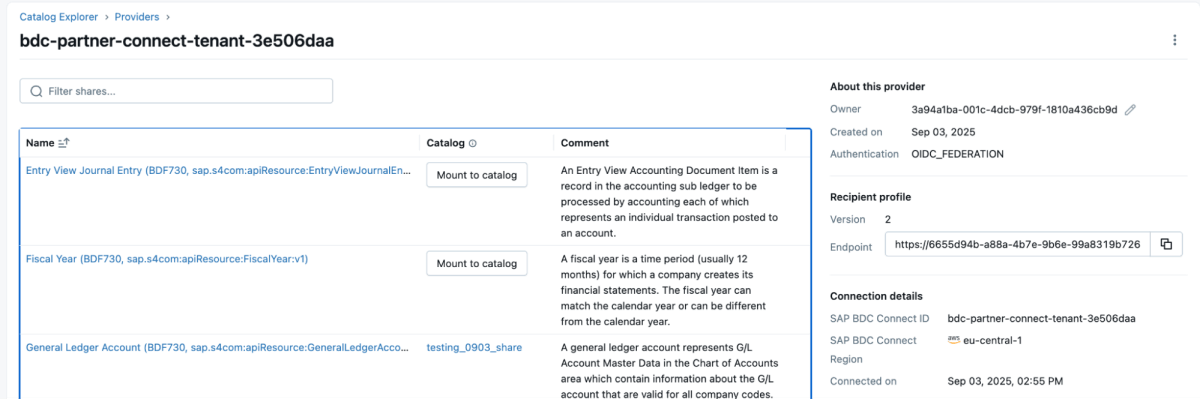
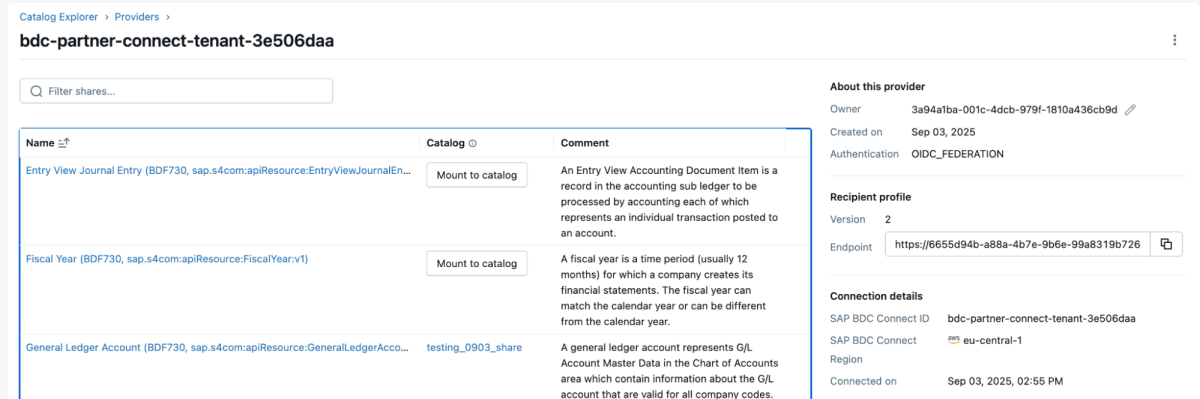{kind=link}
5: Anschließend können Sie diese Freigabe in den Katalog einbinden und entweder einen neuen Katalog erstellen oder sie in einen bestehenden Katalog einbinden.
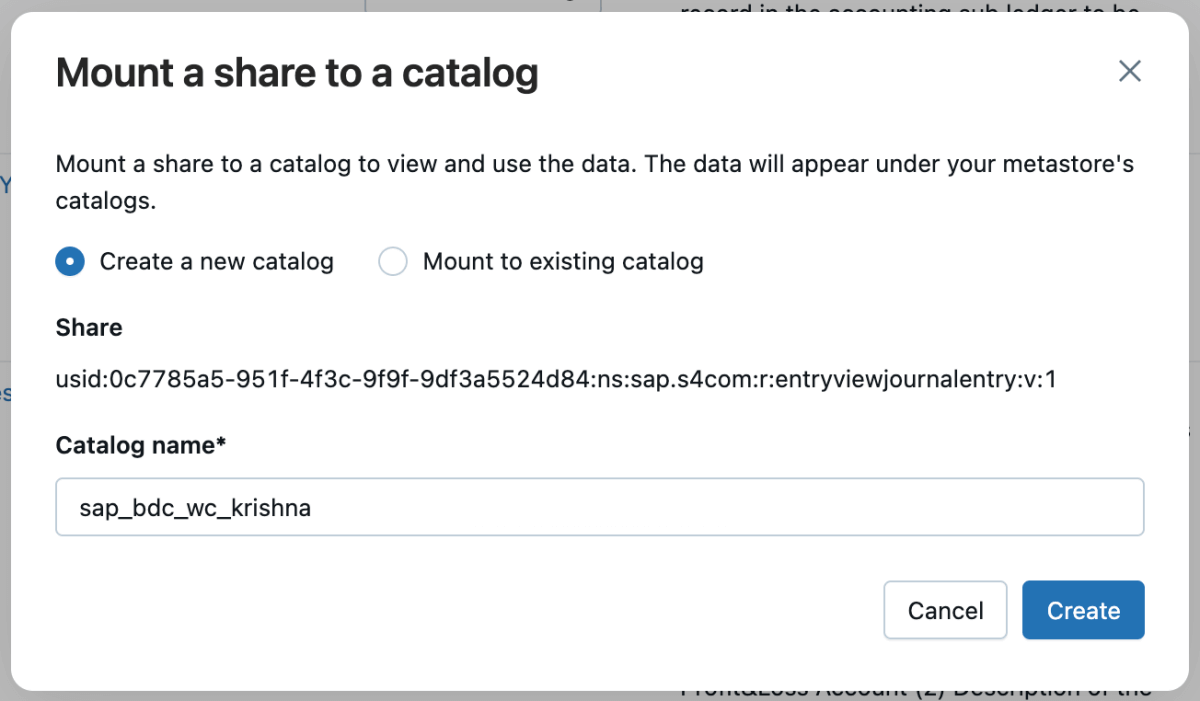
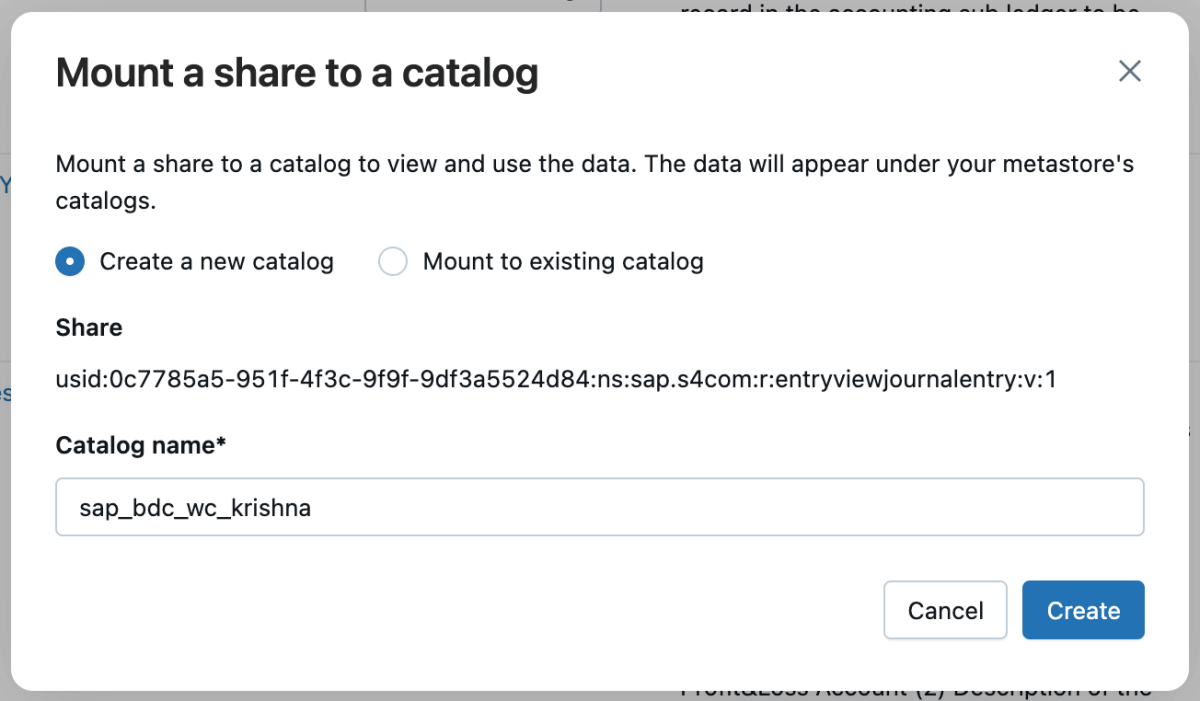{kind=link}
6: Sobald die Freigabe gemountet ist, wird sie im Katalog angezeigt.
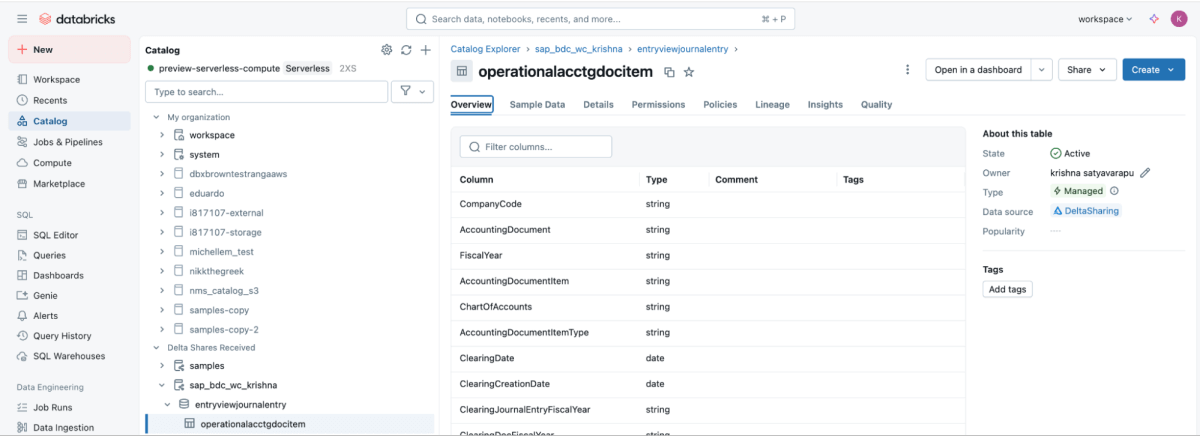
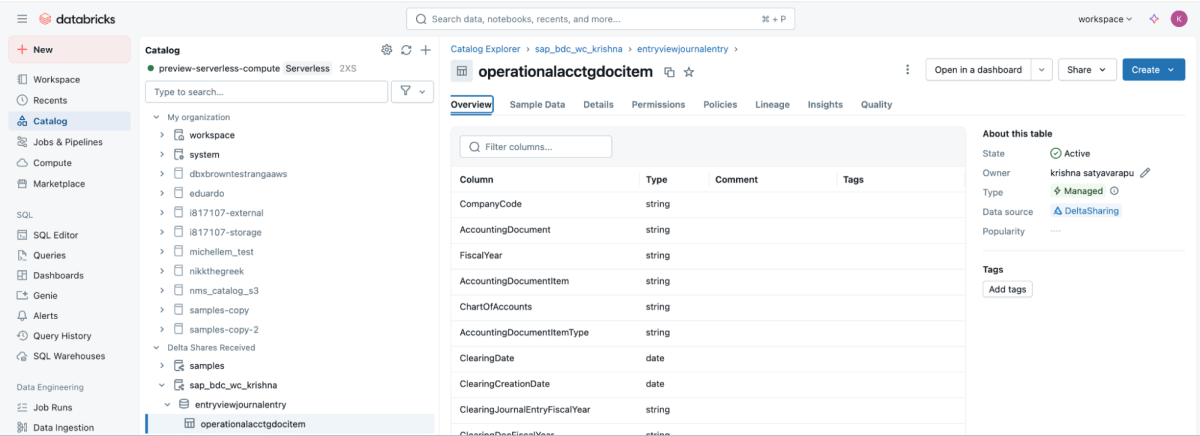{kind=link}
Schritt 3: Zusammenführen der ETL-Pipeline in Databricks mithilfe von deklarativen Lakeflow-Pipelines
Wenn beide Quellen verfügbar sind, verwenden Sie Lakeflow Declarative Pipelines, um eine ETL-Pipeline mit Salesforce- und SAP-Daten zu erstellen.
Die Salesforce- Account -Tabelle enthält normalerweise das Feld SAP_ExternalVendorId__c, das der Lieferanten-ID in SAP entspricht. Dies wird zum primären Join-Schlüssel für Ihre Silver-Schicht.
Mit Lakeflow Spark Declarative Pipelines können Sie Transformationslogik in SQL definieren, während Databricks die Optimierung automatisch übernimmt und die Pipelines orchestriert.
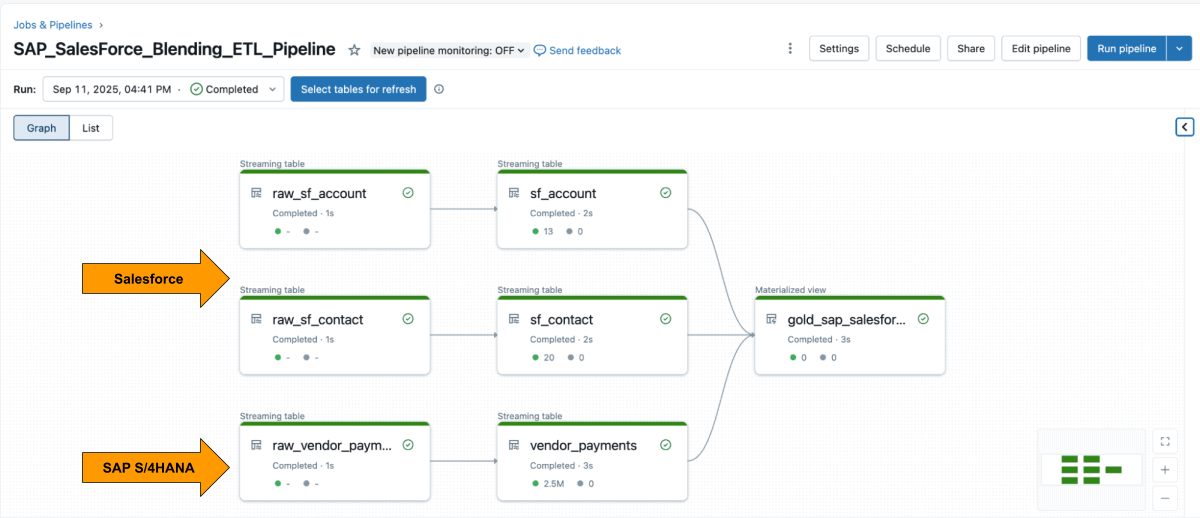
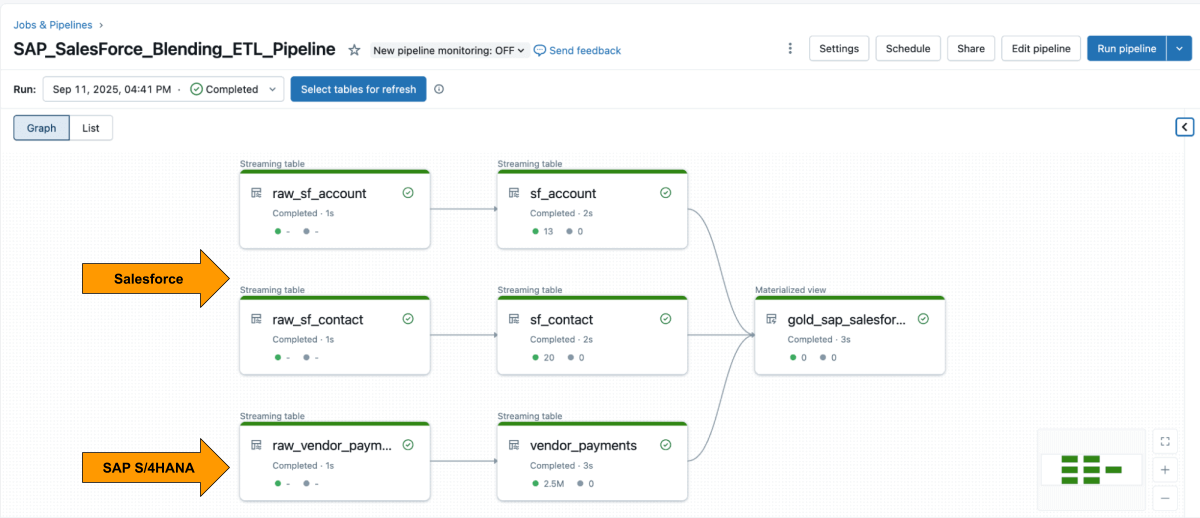{kind=link}
Beispiel: Erstellen Sie kuratierte Tabellen auf Unternehmensebene
Diese Abfrage erstellt eine kuratierte materialisierte Ansicht auf Geschäftsebene, die Zahlungsdatensätze von Anbietern aus SAP mit Anbieterdetails aus Salesforce vereinheitlicht und für Analysen und Berichterstattung bereit ist.
Schritt 4: Analysieren mit AI/BI-Dashboards und Genie
Sobald die materialisierte Ansicht erstellt ist, können Sie sie direkt in AI/BI-Dashboards untersuchen. Mit diesen können Teams Kreditorzahlungen, ausstehende Salden und Ausgaben nach Region visualisieren. Sie unterstützen dynamische Filterung, Suche und Zusammenarbeit, alles gesteuert durch Unity Catalog. Genie ermöglicht die Untersuchung derselben Daten in natürlicher Sprache.
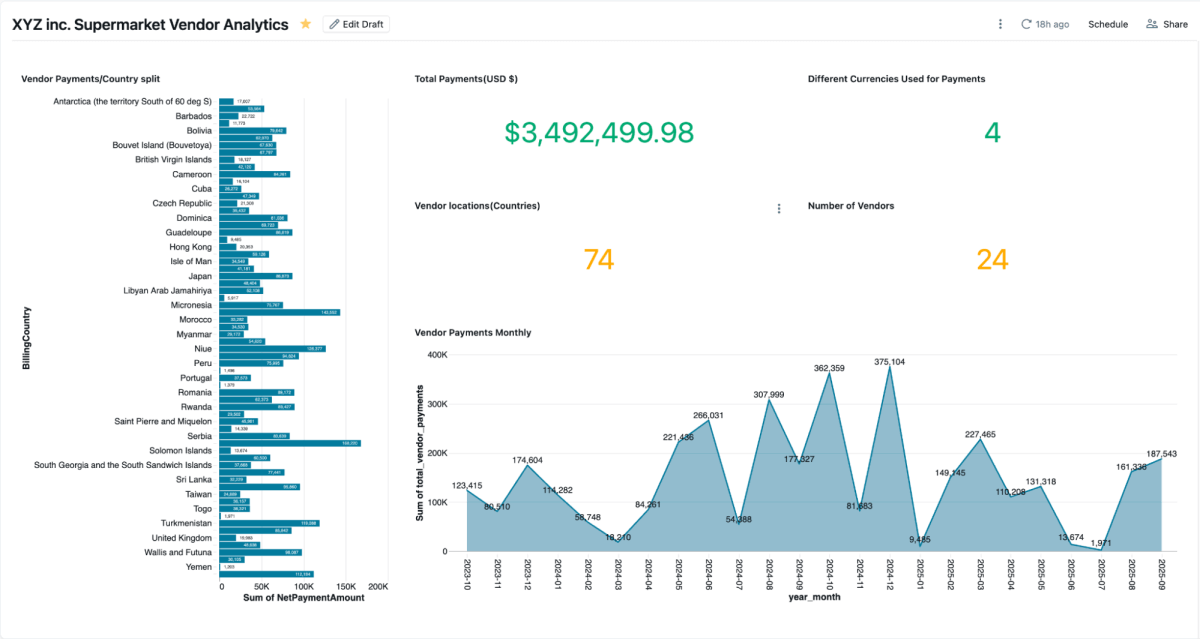
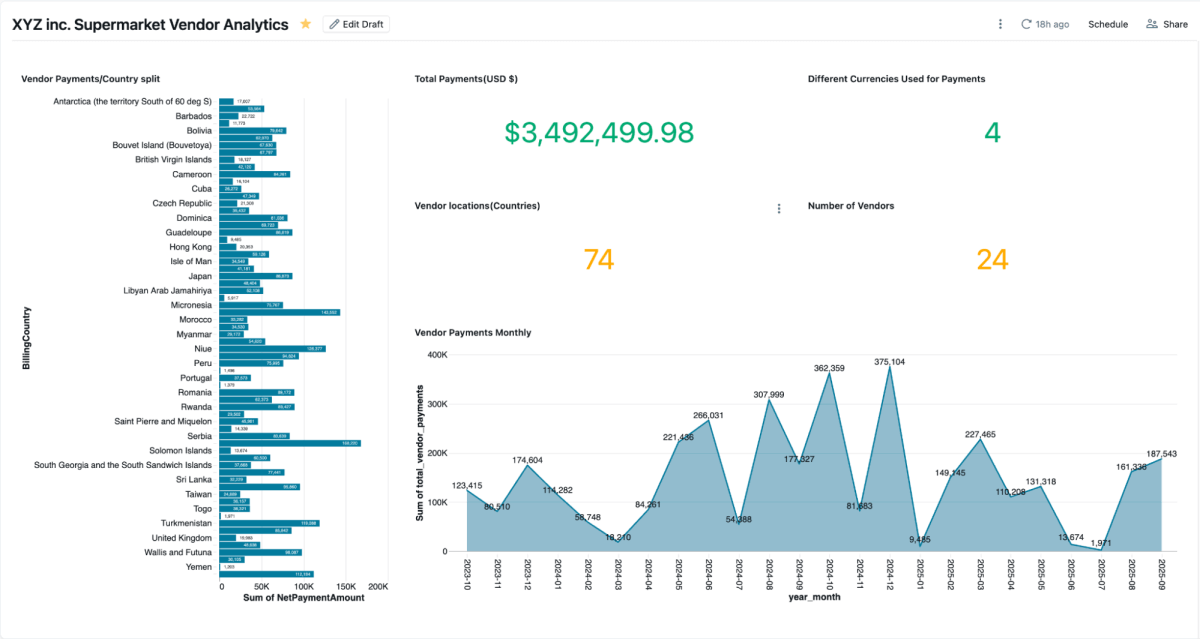{kind=link}
Sie können Genie Spaces auf diesen gemischten Daten erstellen und Fragen stellen, was nicht möglich wäre, wenn die Daten in Salesforce und SAP isoliert wären.
- „Wer sind meine Top-3-Lieferanten, an die ich am meisten zahle, und wie lauten deren Kontaktinformationen?“
- „Wie lauten die Rechnungsadressen der 3 wichtigsten Lieferanten?“
- „Welche meiner Top-5-Kreditoren stammen nicht aus den USA?“

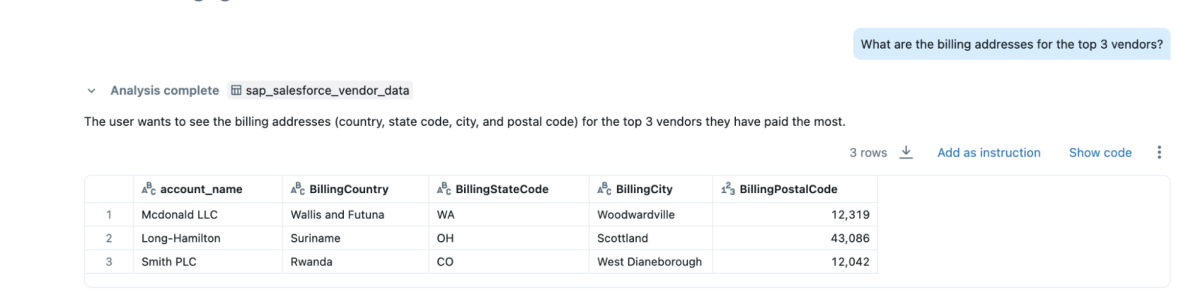
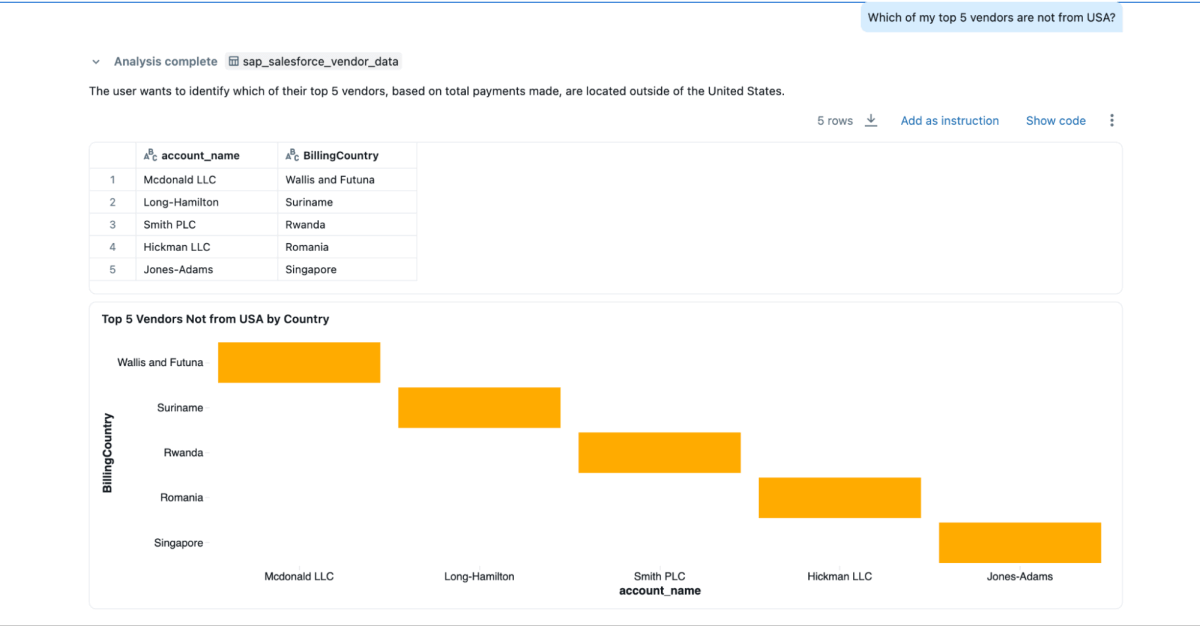
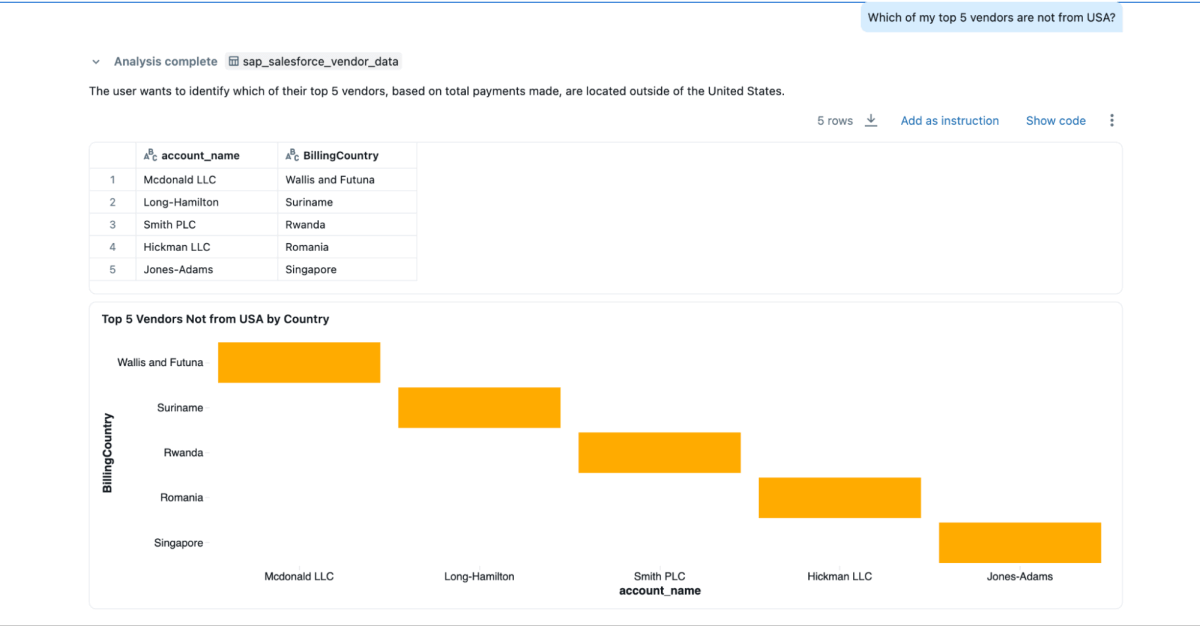{kind=link}
Geschäftsergebnisse
Durch die Kombination von SAP- und Salesforce-Daten auf Databricks erhalten Unternehmen einen vollständigen und vertrauenswürdigen Überblick über die Performance, Zahlungen und Beziehungen von Lieferanten. Dieser einheitliche Ansatz bietet sowohl operative als auch strategische Vorteile:
- Schnellere Klärung von Unstimmigkeiten: Teams können Zahlungsdetails und Lieferanten-Kontaktinformation nebeneinander einsehen, was die Untersuchung von Problemen und deren schnelle Lösung erleichtert.
- Einsparungen durch frühzeitige Zahlung: Da Zahlungsbedingungen, Verrechnungsdaten und Nettobeträge an einem Ort zusammengefasst sind, können Finanzteams leicht Möglichkeiten für Skonti bei frühzeitiger Zahlung erkennen.
- Sauberere Kreditorenstammdaten: Das Verknüpfen über das Feld
SAP_ExternalVendorId__chilft dabei, doppelte oder nicht übereinstimmende Lieferantendatensätze zu identifizieren und aufzulösen, wodurch genaue und konsistente Lieferantendaten systemübergreifend beibehalten werden. - Prüfungssichere Governance: Unity Catalog stellt sicher, dass alle Daten mit konsistenter Datenherkunft, Berechtigungen und Auditierung gesteuert werden, sodass Analysen, KI-Modelle und Berichte auf derselben vertrauenswürdigen Quelle basieren.
Zusammengenommen helfen diese Ergebnisse Unternehmen dabei, das Lieferantenmanagement zu optimieren und die finanzielle Effizienz zu verbessern – und das bei gleichzeitiger Wahrung der für Unternehmenssysteme erforderlichen Governance und Sicherheit.
Fazit
Die Vereinheitlichung von Lieferantendaten über SAP und Salesforce hinweg muss nicht bedeuten, Pipelines neu aufzubauen oder doppelte Systeme zu verwalten.
Mit Databricks können Teams auf einer einzigen, gesteuerten Grundlage arbeiten, die ERP- und CRM- Daten in Echtzeit nahtlos integriert. Die Kombination aus Zero-Copy-Zugriff auf SAP BDC, inkrementeller Salesforce-Ingestion, einheitlicher Governance und deklarativen Pipelines ersetzt den Integrationsaufwand durch Erkenntnisse.
Das Ergebnis geht über ein schnelleres Reporting hinaus. Sie bietet eine vernetzte Sicht auf die Lieferanten-Performance, die Kaufentscheidungen verbessert, Lieferantenbeziehungen stärkt und messbare Einsparungen ermöglicht. Und da es auf der Databricks Data Intelligence Platform aufbaut, können dieselben SAP-Daten, die für Zahlungen und Rechnungen verwendet werden, auch für Dashboards, KI-Modelle und Conversational Analytics genutzt werden – alles aus einer einzigen vertrauenswürdigen Quelle.
SAP-Daten sind oft das Rückgrat des Geschäftsbetriebs. Durch die Integration von SAP Business Data Cloud, Delta Sharing und Unity Catalog können Unternehmen diese Architektur über die Lieferantenanalyse hinaus erweitern – auf die Optimierung des Betriebskapitals, die Bestandsverwaltung und die Bedarfsplanung.
Dieser Ansatz verwandelt SAP-Daten von einem Aufzeichnungssystem in ein Intelligenzsystem, in dem jedes Dataset live, verwaltet und für das gesamte Unternehmen einsatzbereit ist.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.