Selbstoptimierender Football-Chatbot, geleitet von Fachexperten auf Databricks
Ein Leitfaden zur Erstellung, Bereitstellung und Optimierung eines agentenbasierten Assistenten, der Defensive Coordinators hilft, gegnerische Tendenzen vorherzusagen und sich durch Expertenfeedback kontinuierlich verbessert.
von Wesley Pasfield und Nick Ragonese
- Zweck: Erstellen eines auf Trainer ausgerichteten agentenbasierten Assistenten, der Fragen wie „Was wird dieser Angriff tun?“ mithilfe von verwalteten, produktionsreifen Tools über Play-by-Play-, Teilnahme- und Kaderdaten beantwortet.
- Ansatz: Erstellen eines Tool-aufrufenden Agenten mit Unity Catalog-Funktionen (SQL-Analytics über Delta) und Bereitstellung über das Agent Framework mit MLflow Tracing. Implementieren einer selbstoptimierenden Schleife, in der das in MLflow-Label-Sitzungen erfasste Feedback von Fachexperten abgestimmte Bewerter (align()) trainiert, die die automatische Prompt-Verbesserung (optimize_prompts()) vorantreiben, wodurch das Football-Fachwissen direkt in das System kodiert wird.
- Ergebnis: Koordinatoren erhalten situationsbezogene Tendenzen (Down und Distanz, Formation/Personal, Zwei-Minuten-Drill, Screen-Raten) mit schneller Iteration und Qualitätsprüfungen, die für die Installationen in der Spielwoche bereit sind. Entwickler erhalten eine wiederverwendbare Architektur für jeden Bereich: Expertenfeedback erfassen, Bewerter darauf abstimmen, was „gut“ für Ihren Anwendungsfall bedeutet, und das System durch eine von den abgestimmten Bewertern geleitete Prompt-Optimierung kontinuierlich verbessern lassen.
Generische LLM-Juroren und statische Prompts können domänenspezifische Nuancen nicht erfassen. Um zu bestimmen, was eine „gute“ Analyse der Football-Defensive ausmacht, sind umfassende Football-Kenntnisse erforderlich: Coverage-Schemata, Formationstendenzen, situativer Kontext. Allzweck-Evaluatoren übersehen dies. Dasselbe gilt für die juristische Prüfung, die medizinische Triage, die finanzielle Due Diligence oder jede andere Domäne, in der Expertenwissen zählt.
Dieser Beitrag beschreibt eine Architektur für selbstoptimierende Agenten, die auf dem Databricks Agent Framework aufbaut, bei der unternehmensspezifisches menschliches Fachwissen die KI-Qualität mithilfe von MLflow kontinuierlich verbessert und Entwickler die gesamte Erfahrung steuern. In diesem Beitrag verwenden wir einen Assistenten für den Defensive Coordinator (DC) im American Football als durchgehendes Beispiel: ein Tool-aufrufender Agent, der Fragen beantworten kann wie "Wer bekommt den Ball bei 11 Personnel bei 3rd-and-6?" oder "Was macht der Gegner in den letzten 2 Minuten der Halbzeiten?" Das folgende Beispiel zeigt, wie dieser Agent über Databricks Apps mit einem Benutzer interagiert.

Vom Agenten zum selbstoptimierenden System
Die Lösung hat zwei Phasen: Zuerst wird der Agent erstellt und dann kontinuierlich mit Expertenfeedback optimiert.
Erstellen
- Daten erfassen: Laden Sie Domänendaten (Play-by-Play, Teilnahme, Kader) in verwaltete Delta-Tabellen in Unity Catalog.
- Wir haben Daten aus zwei Jahren (2023–2024) zu Football-Teilnahmen und Play-by-Play-Daten von
nflreadpyals Daten für diesen Agenten aufgenommen.
- Wir haben Daten aus zwei Jahren (2023–2024) zu Football-Teilnahmen und Play-by-Play-Daten von
- Tools erstellen: Definieren Sie SQL-Funktionen als Unity Catalog-Tools, die der Agent aufrufen kann, und nutzen Sie dabei die extrahierten Daten.
- Definiere und verteile den Agenten: Verbinde die Tools mit einem
ResponsesAgent, registriere einen Basis-Systemprompt in der Prompt Registry und verteile ihn auf Model Serving. - Erste Bewertung: Führe eine automatische Bewertung mit LLM-Richtern und Log-Traces durch und verwende dabei die Basisversionen der benutzerdefinierten Richter.
Optimieren
- Expertenfeedback erfassen: Fachexperten überprüfen die Agent-Ausgaben und geben in MLflow-Kennzeichnungssitzungen strukturiertes Feedback.
- Judges abgleichen: Verwenden Sie die MLflow-Funktion
align(), um den Basis-LLM-Judge so zu kalibrieren, dass er den Präferenzen von Fachexperten (SMEs) entspricht, und ihm beizubringen, wie „gut“ für diese Domäne aussieht. - Optimiere Prompts: MLflow's
optimize_prompts()verwendet einen GEPA-Optimierer, der sich an dem ausgerichteten Richter orientiert, um den ursprünglichen Systemprompt iterativ zu verbessern. - Wiederholung: Jede MLflow-Labeling-Sitzung wird verwendet, um den Judge zu verbessern, der wiederum zur Optimierung des System-Prompts verwendet wird. Dieser gesamte Prozess kann automatisiert werden, um neue Prompt-Versionen, die die Performance-Benchmarks übertreffen, automatisch zu übernehmen, oder er kann als Grundlage für manuelle Aktualisierungen des Agenten dienen, z. B. das Hinzufügen weiterer Tools oder Daten, basierend auf beobachteten Fehlermodi.
In der Aufbauphase erstellst du einen ersten Prototyp und in der Optimierungsphase kannst du deinen Agenten mit Hilfe des Feedbacks von Fachleuten kontinuierlich optimieren und in Produktion bringen.
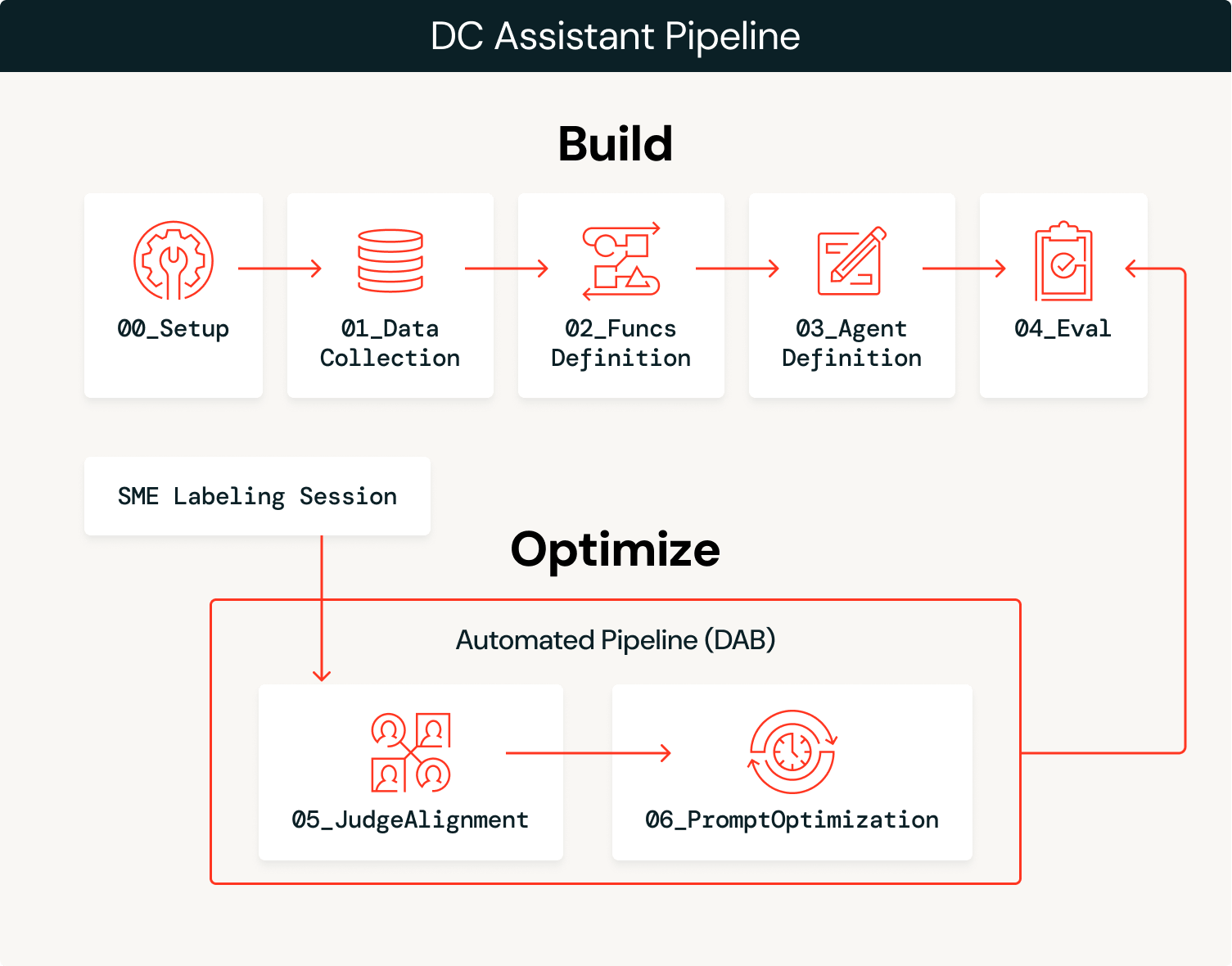
Architekturübersicht
Der Agent gleicht Probabilismus und Determinismus aus: Ein LLM interpretiert die semantische Absicht von Benutzer-Queries und wählt die richtigen Tools aus, während deterministische SQL-Funktionen Daten mit 100%iger Genauigkeit abrufen. Wenn ein Coach beispielsweise fragt: „Wie greift unser Gegner den Blitz an?“, interpretiert das LLM dies als eine Anfrage für eine Pass-Rush-/Coverage-Analyse und wählt success_by_pass_rush_and_coverage() aus. Die SQL-Funktion gibt exakte Statistiken aus den zugrunde liegenden Daten zurück. Durch die Verwendung von Unity Catalog-Funktionen stellen wir sicher, dass die Statistiken zu 100 % genau sind, während das LLM den Konversationskontext verarbeitet.
| Schritt | Technologie |
|---|---|
| Daten aufnehmen | Delta Lake + Unity Catalog |
| Tools erstellen | Unity Catalog-Funktion |
| Agenten anwenden | ResponsesAgent + Model Serving über agents.deploy() |
| Evaluierung mit LLM als Judge | MLflow GenAI evaluate() mit integrierten und benutzerdefinierten Beurteilern |
| Feedback erfassen | MLflow Labeling-Sitzungen für SME-Feedback |
| Richter ausrichten | MLflow align() mit einem eigenen SIMBA-Optimierer |
| Prompts optimieren | MLflow optimize_prompts() mit einem GEPA-Optimierer |
Gehen wir jeden Schritt mit dem Code und den Ausgaben aus der DC Assistant-Implementierung durch.
Erstellen
1. Daten einlesen.
Ein Setup-Notebook (00_setup.ipynb) definiert alle globalen Konfigurationsvariablen, die im gesamten Workflow verwendet werden: workspace-Katalog/Schema, MLflow-Experiment, LLM-Endpunkte, Modellnamen, Evaluierungsdatensätze, Unity Catalog-Toolnamen und Authentifizierungseinstellungen. Diese Konfiguration wird in config/dc_assistant.json gespeichert und von allen nachgelagerten Notebooks geladen, was die Konsistenz in der gesamten Pipeline sicherstellt. Dieser Schritt ist optional, hilft aber bei der Gesamtorganisation.
Mit dieser Konfiguration laden wir Football-Daten über nflreadpy und wenden eine inkrementelle Verarbeitung an, um sie für die Nutzung durch den Agenten vorzubereiten: Wir entfernen nicht verwendete Spalten, standardisieren Schemata und persistieren bereinigte Delta-Tabellen im Unity Catalog. Hier ist ein einfaches Beispiel für das Laden der Daten, das nicht näher auf die Datenverarbeitung eingeht:
Die Ausgaben dieses Prozesses sind verwaltete Delta-Tabellen im Unity Catalog (Play-by-Play, Teilnahme, Kader, Teams, Spieler), die für die Tool-Erstellung und die Nutzung durch Agenten bereit sind.
2. Tools erstellen.
Der Agent benötigt deterministische Tools, um die zugrunde liegenden Daten abzufragen. Wir definieren diese als Unity Catalog-SQL-Funktionen, die offensive Tendenzen über verschiedene situative Dimensionen hinweg berechnen. Jede Funktion übernimmt Parameter wie team und season und gibt aggregierte Statistiken zurück, die der Agent zur Beantwortung von Koordinatorenfragen verwenden kann. Für dieses Beispiel verwenden wir nur SQL-basierte Funktionen, aber es ist möglich, Python-basierte UC-Funktionen, Vektorsuchindizes, Model Context Protocol (MCP)-Tooling und Genie Spaces als zusätzliche Funktionalität zu konfigurieren, die ein Agent nutzen kann, um das den Prozess überwachende LLM zu ergänzen.
Das folgende Beispiel zeigt `success_by_pass_rush_and_coverage()`, eine Funktion, die Pass/Run-Aufteilungen, EPA (Expected Points Added), Erfolgsrate und gewonnene Yards berechnet, gruppiert nach der Anzahl der Pass-Rusher und der Art der Defensivdeckung. Die Funktion enthält einen COMMENT, der ihren Zweck beschreibt und vom LLM verwendet wird, um zu bestimmen, wann die Funktion aufgerufen werden soll.
Da sich diese Funktionen im Unity Catalog befinden, erben sie das Governance-Modell der Plattform: rollenbasierte Zugriffskontrollen, Herkunftsverfolgung und Auffindbarkeit im gesamten workspace. Teams können Tools finden und wiederverwenden, ohne Logik zu duplizieren, und Administratoren behalten den Überblick darüber, auf welche Daten der Agent zugreifen kann.
3. Den Agenten definieren und anwenden.
Die Erstellung des Agenten kann so einfach sein wie die Nutzung des AI Playground. Wählen Sie das LLM aus, das Sie verwenden möchten, fügen Sie Ihre Unity Catalog-Tools hinzu, definieren Sie Ihren System-Prompt und klicken Sie auf „Agenten-Notebook erstellen“, um ein Notebook zu exportieren, das einen Agenten im ResponsesAgent -Format erstellt. Der folgende Screenshot zeigt diesen Workflow in Aktion. Das exportierte Notebook enthält die Agentendefinitionsstruktur und verbindet Ihre UC-Funktionen über das UCFunctionToolkit mit dem Agenten.
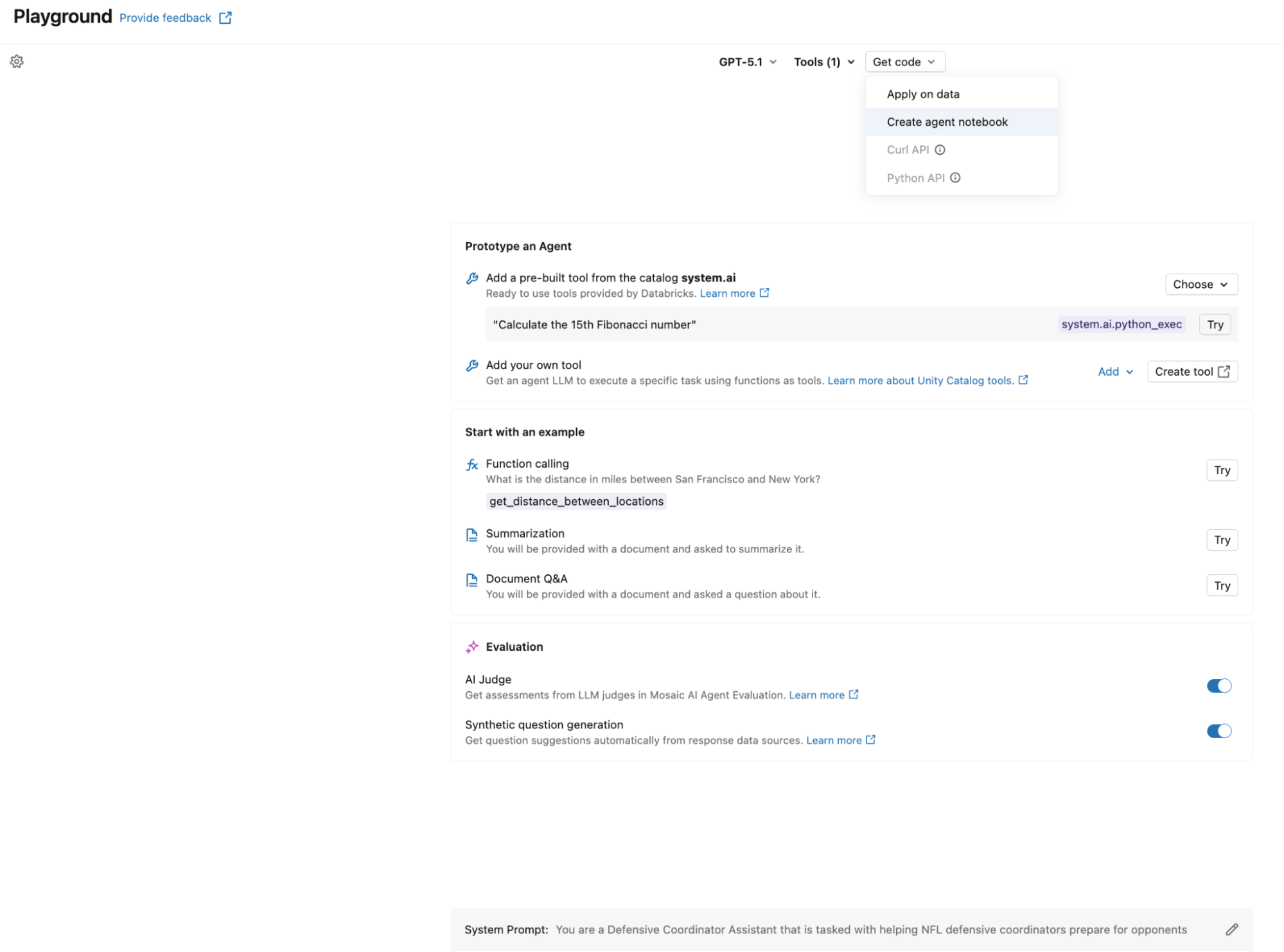
Um die selbstoptimierende Schleife zu ermöglichen, registrieren wir den System-Prompt in der Prompt Registry, anstatt ihn fest zu codieren. Dies ermöglicht es der Optimierungsphase, den Prompt zu aktualisieren, ohne den Agenten erneut bereitzustellen:
Sobald der Agenten-Code getestet und das Modell im Unity Catalog registriert ist, ist die Bereitstellung auf einem persistenten Endpunkt so einfach wie der folgende Code. Dadurch wird ein Model-Serving-Endpunkt mit aktiviertem MLflow Tracing, Inferenztabellen zur Protokollierung von Anfragen/Antworten und automatischer Skalierung erstellt:
Für den Endbenutzerzugriff kann der Agent auch als Databricks-App angewendet werden. Diese bietet eine Chat-Oberfläche, die Koordinatoren und Analysten direkt nutzen können, ohne dass ein Notebook- oder API-Zugriff erforderlich ist. Der Screenshot in der Einleitung zeigt diese App-basierte Bereitstellung in Aktion.
4. Erstbewertung.
Nach Anwendung des Agents führen wir die Ausführung einer automatisierten Evaluierung mit LLM-Bewertern durch, um eine Baseline für die Qualität zu ermitteln. MLflow unterstützt mehrere Judge-Typen, und wir verwenden drei davon in Kombination.
Integrierte Beurteiler behandeln standardmäßig gängige Bewertungskriterien. RelevanceToQuery() prüft, ob die Antwort die Frage des Nutzers beantwortet. Richtlinienbasierte Beurteiler bewerten anhand spezifischer textbasierter Regeln nach dem Prinzip „bestanden“/„nicht bestanden“. Wir definieren eine Richtlinie, die sicherstellt, dass in den Antworten eine passende Fachterminologie aus dem Profifußball verwendet wird:
Benutzerdefinierte Beurteiler verwenden make_judge() für die domänenspezifische Evaluierung mit voller Kontrolle über die Bewertungskriterien. Dies ist der Judge, den wir in der Optimierungsphase an das SME-Feedback anpassen werden:
Mit allen definierten Judges können wir eine Ausführung gegen das Dataset (das) durchführen:
Der benutzerdefinierte Judge football_analysis_base liefert eine Baseline-Bewertung. Diese ist jedoch lediglich ein Best-Effort-Versuch, von Grund auf eine Rubrik zu erstellen, die das LLM für seine Beurteilungen verwenden kann, und stellt kein echtes Domänenwissen dar. Die Benutzeroberfläche von MLflow Experiments zeigt uns die Performance des Agenten für diesen Baseline-Judge sowie eine Begründung für die Bewertung in jedem Beispiel.
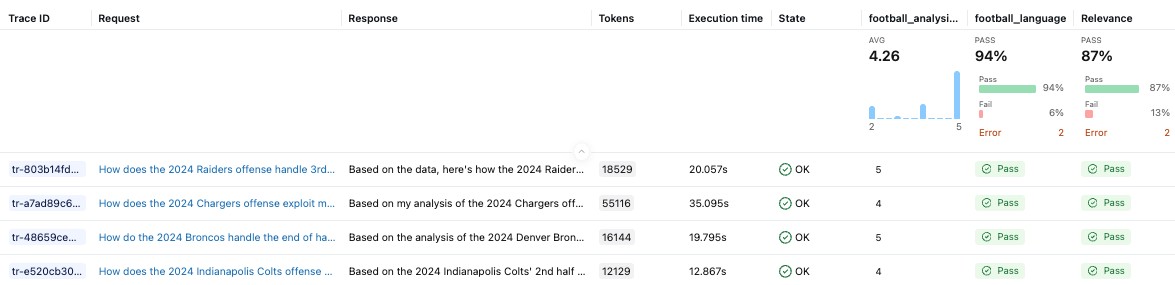

In der Optimierungsphase werden wir den Football-Analyse-Judge an die Präferenzen von Fachexperten anpassen und ihm beibringen, was „gut“ für die Analyse eines Defensive Coordinators tatsächlich bedeutet.
Optimieren
5. Erfasse das Feedback von Experten.
Nachdem der Agent angewendet und die Baseline-Evaluierung abgeschlossen ist, treten wir in die Optimierungsschleife ein. Hier wird die Fachexpertise in das System kodiert, zuerst durch abgestimmte LLM-Judges, dann direkt in den Agenten durch die von unserem abgestimmten Judge geleitete Optimierung des System-Prompts.
Wir starten mit der Erstellung eines Label-Schemas, das dieselben Anweisungen und Bewertungskriterien verwendet wie der Football-Analyse-Judge, den wir mit make_judge() erstellt haben. Anschließend erstellen wir eine Kennzeichnungssitzung, die es unserem Fachexperten ermöglicht, die Antworten für dieselben Traces, die im evaluate() -Job verwendet wurden, zu überprüfen und seine Bewertungen und sein Feedback über die Review App (siehe Abbildung unten) abzugeben.
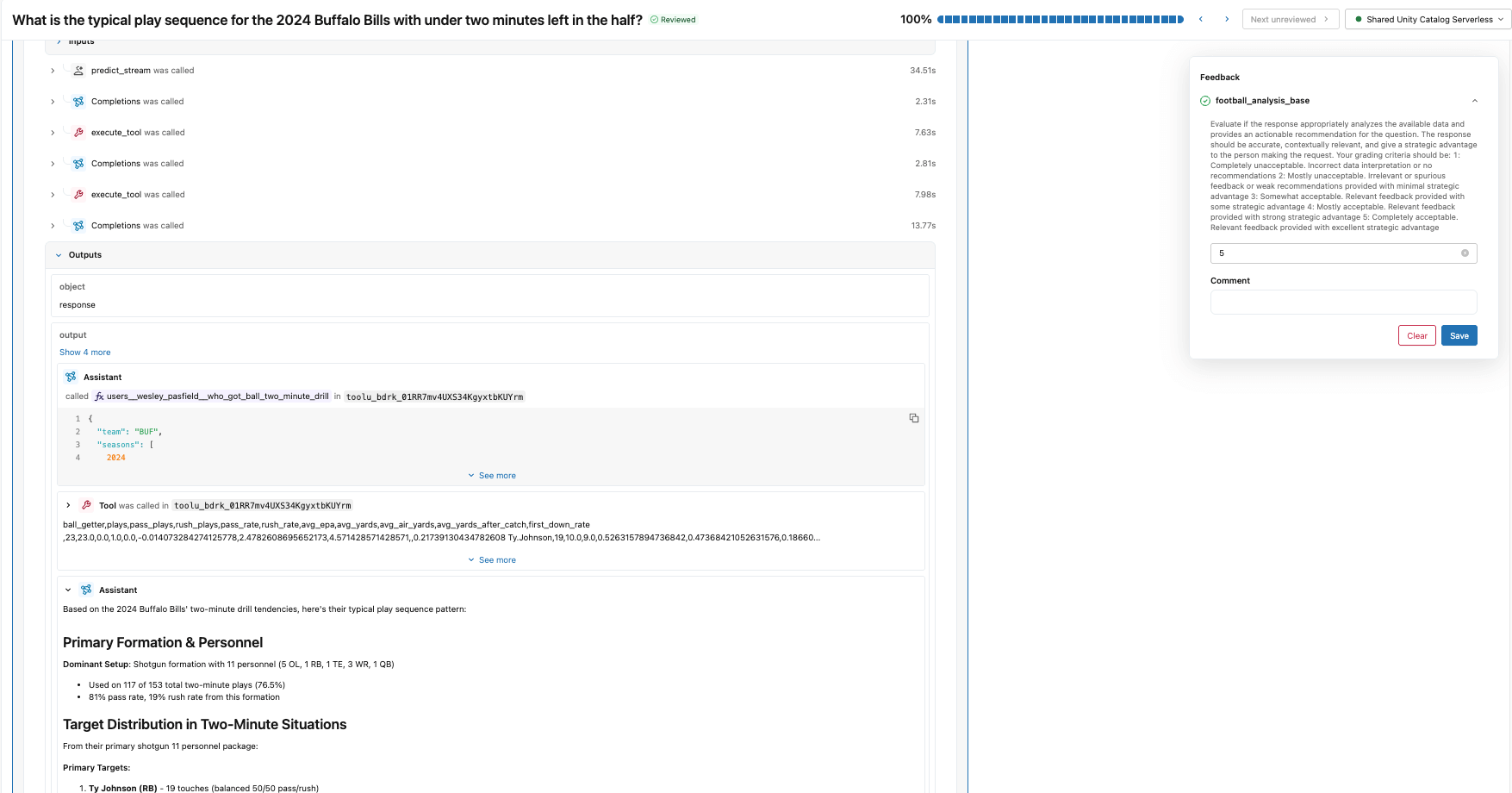
Dieses Feedback wird zur Ground Truth für den Judge-Abgleich. Wo die Bewertungen des Baseline-Bewerters und der SMEs voneinander abweichen, zeigt uns, was der Bewerter in dieser spezifischen Domäne falsch macht.
6. Judges abgleichen.
Da wir nun Traces haben, die sowohl das Feedback von Fachexperten als auch das Feedback des LLM-Judge enthalten, können wir die align() -Funktionalität von MLflow nutzen, um unseren LLM-Judge auf das Feedback unserer Fachexperten abzustimmen. Ein abgestimmter Judge spiegelt die Perspektive Ihrer Fachexperten und die einzigartigen Daten Ihrer Organisation wider. Die Abstimmung bindet Fachexperten auf eine Weise in den Entwicklungsprozess ein, die bisher nicht möglich war: Das Feedback der Fachexperten beeinflusst direkt, wie das System die Qualität misst, wodurch die Performance-Metriken des Agenten sowohl zuverlässig als auch skalierbar werden.
align() ermöglicht es Ihnen, Ihren eigenen Optimizer oder den default binären SIMBA-Optimizer (Simplified Multi-Bootstrap Aggregation) zu verwenden. In diesem Fall nutzen wir einen benutzerdefinierten SIMBA-Optimizer, um einen Judge mit Likert-Skala zu kalibrieren:
Als Nächstes rufen wir Traces ab, die sowohl LLM-Judge-Bewertungen als auch SME-Feedback enthalten, das wir während des gesamten Prozesses getaggt haben. Diese gepaarten Bewertungen sind es, die SIMBA verwendet, um die Lücke zwischen einer generischen Beurteilung und einer Expertenbeurteilung zu erlernen.
Der folgende Screenshot zeigt den laufenden Abgleichprozess. Das Modell identifiziert Lücken zwischen den LLM-Judges und dem SME-Feedback, schlägt neue Regeln und Details vor, die in den Judge integriert werden sollen, um diese Lücken zu schließen, und bewertet dann die neuen Judge-Kandidaten, um festzustellen, ob sie die Performance des Baseline-Judges übertreffen.

Das Endergebnis dieses Prozesses ist ein ausgerichteter Judge, der das Feedback von Fachexperten mit detaillierten Anweisungen direkt widerspiegelt.

Tipps für eine effektive Ausrichtung:
- Das Ziel der Abstimmung ist es, Ihnen während der Entwicklung das Gefühl zu geben, dass Fachexperten neben Ihnen sitzen. Dieser Prozess kann zu niedrigeren Performance-Werten für Ihren Baseline-Agenten führen, was bedeutet, dass Ihr Baseline-Judge nicht ausreichend spezifiziert war. Da Sie nun einen Judge haben, der den Agenten auf die gleiche Weise kritisiert, wie es Ihre Fachexperten (SMEs) tun würden, können Sie manuelle oder automatisierte Verbesserungen vornehmen, um die Performance zu steigern.
- Der Abstimmungsprozess ist nur so gut wie das bereitgestellte Feedback. Konzentrieren Sie sich auf Qualität statt auf Quantität. Detailliertes, konsistentes Feedback zu einer kleineren Anzahl von Beispielen (mindestens 10) führt zu besseren Ergebnissen als inkonsistentes Feedback zu vielen Beispielen.
Die Definition von Qualität ist oft das größte Hindernis auf dem Weg zu einer besseren Performance der Agenten. Unabhängig von der Optimierungstechnik wird die Performance des Agenten enttäuschen, wenn es keine klare Definition von Qualität gibt. Databricks bietet einen Workshop an, der Kunden hilft, Qualität durch eine iterative, funktionsübergreifende Übung zu definieren. Um mehr zu erfahren, kontaktiere bitte dein Databricks-Accountteam oder fülle dieses Formular aus.
7. Prompts optimieren.
Mit einem abgestimmten Judge, der die Präferenzen von Fachexperten widerspiegelt, können wir jetzt den System-Prompt des Agenten automatisch verbessern. Die optimize_prompts() -Funktion von MLflow verwendet GEPA, um den Prompt basierend auf der Bewertung des abgestimmten Judges iterativ zu verfeinern. GEPA (Genetic-Pareto), mitentwickelt von Databricks CTO Matei Zaharia, ist ein genetischer evolutionärer Prompt-Algorithmus, der große Sprachmodelle nutzt, um reflektierende Mutationen an Prompts durchzuführen. Dies ermöglicht es, Anweisungen iterativ zu verfeinern und herkömmliche Reinforcement-Learning-Techniken bei der Optimierung der Modellperformance zu übertreffen.
Anstatt dass ein Entwickler rät, welche Adjektive dem System-Prompt hinzugefügt werden sollen, entwickelt der GEPA-Optimierer den Prompt mathematisch weiter, um die vom Experten definierte spezifische Punktzahl zu maximieren. Der Optimierungsprozess erfordert einem Dataset mit erwarteten Antworten, der den Optimierer in Richtung des gewünschten Verhaltens leitet, wie folgt:
Der GEPA-Optimierer verwendet den aktuellen System-Prompt und schlägt iterativ Verbesserungen vor, wobei jeder Kandidat anhand des abgestimmten Beurteilers bewertet wird. Hier rufen wir den ursprünglichen Prompt, das von uns erstellte Optimierungs-Dataset und den abgestimmten Beurteiler ab, um optimize_prompts() von MLflow zu nutzen. Anschließend verwenden wir den GEPA-Optimierer, um einen neuen System-Prompt zu erstellen, der von unserem abgestimmten Beurteiler geleitet wird:
Der folgende Screenshot zeigt die Änderung im System-Prompt – der alte befindet sich links und der neue rechts. Der endgültig ausgewählte Prompt ist derjenige, der die höchste von unserem abgestimmten Judge gemessene Punktzahl aufweist. Der neue Prompt wurde aus Platzgründen gekürzt, aber dieses Beispiel macht deutlich, dass wir in der Lage waren, Antworten von Fachexperten zu integrieren, um einen Prompt zu erstellen, der in fachspezifischer Sprache verankert ist und explizite Anleitungen zur Behandlung bestimmter Anfragen enthält.

Die Möglichkeit, diese Art von Anleitung automatisch aus dem Feedback der KMUs zu generieren, ermöglicht es deinen KMUs, einem Agenten indirekt Anweisungen zu geben, indem sie einfach Feedback zu den Spuren des Agenten geben.
In diesem Fall erzielte der neue Prompt laut unserem abgestimmten Judge eine bessere Performance auf unserem Optimierungs-Dataset, daher haben wir dem neu registrierten Prompt den Produktions-Alias gegeben. Dies ermöglicht es uns, unseren Agenten mit diesem verbesserten Prompt neu bereitzustellen.
Tipps zur Prompt-Optimierung:
- Der Optimierungsdatensatz sollte die Vielfalt der Abfragen abdecken, die Ihr Agent verarbeiten wird. Beziehen Sie Grenzfälle, mehrdeutige Anfragen und Szenarien ein, in denen die Tool-Auswahl eine Rolle spielt.
- Erwartete Antworten sollten beschreiben, was der Agent tun soll (welche Tools aufgerufen und welche Informationen einbezogen werden sollen), anstatt den genauen Ausgabetext vorzugeben.
- Starten Sie mit
max_metric_calls, das auf einen Wert zwischen50und100eingestellt ist. Höhere Werte prüfen mehr Kandidaten, erhöhen aber die Kosten und die Laufzeit. - Der GEPA-Optimierer lernt aus Fehlermodi. Wenn der abgestimmte Beurteiler fehlende Benchmarks oder Vorbehalte bei kleinen Stichproben penalisiert, fügt GEPA diese Anforderungen in den optimierten Prompt ein.
8. Den Kreislauf schließen: Automatisierung und kontinuierliche Verbesserung.
Die einzelnen Schritte, die wir durchgegangen sind, können zu einer kontinuierlichen Optimierungs-Pipeline orchestriert werden, wobei das Labeling durch den Fachexperten zum Trigger für die Optimierungsschleife wird, und alles kann in einem Databricks-Job unter Verwendung von Asset Bundles zusammengefasst werden:
- SMEs labeln Agent-Ausgaben über die Benutzeroberfläche der MLflow Labeling Session und vergeben dabei Bewertungen und Kommentare zu echten Produktions-Traces.
- Die Pipeline erkennt neue Labels und ruft Traces mit dem Feedback von Fachexperten und den Scores des Basis-LLM-Judge ab.
- Das Judge-Alignment wird ausgeführt und erzeugt eine neue Judge-Version, die auf die neuesten SME-Präferenzen kalibriert ist.
- Prompt-Optimierungs-Ausführungen, wobei der abgestimmte Judge verwendet wird, um den System-Prompt iterativ zu verbessern.
- Durch die bedingte Beförderung wird der neue Prompt in die Produktion verschoben, wenn er die Performance-Thresholds überschreitet. Das könnte bedeuten, dass ein weiterer Bewertungsjob einen Trigger auslöst, um sicherzustellen, dass die neue Aufforderung auf andere Beispiele übertragbar ist.
- Der Agent verbessert sich automatisch, da die Prompt-Registry die optimierte Version bereitstellt.
Wenn Fachexperten eine Kennzeichnungssitzung abschließen, wird ein evaluate() -Job getriggert, um LLM-Judge-Scores für dieselben Traces zu generieren. Wenn der evaluate() -Job abgeschlossen ist, wird ein align() -Job ausgeführt, um den LLM-Judge mit dem Feedback der Fachexperten abzugleichen. Wenn dieser Job abgeschlossen ist, wird ein optimize_prompts() -Job ausgeführt, um einen neuen und verbesserten System-Prompt zu generieren, der sofort an einem neuen Dataset getestet und gegebenenfalls in die Produktion überführt werden kann.
Dieser gesamte Prozess kann vollständig automatisiert werden, aber eine manuelle Überprüfung kann auch in jedem Schritt eingefügt werden, was den Entwicklern die vollständige Kontrolle über den Grad der involvierten Automatisierung gibt. Der Prozess wiederholt sich, während die Fachexperten (SMEs) mit dem Label versehen fortfahren, was zu schnellen Performance-Tests für neue Versionen des Agenten und zu kumulativen Performance-Steigerungen führt, denen Entwickler wirklich vertrauen können.
Fazit
Diese Architektur verändert mithilfe des Databricks Agent Framework und MLflow, wie sich Agenten im Laufe der Zeit verbessern. Anstatt dass Entwickler raten, was eine gute Antwort ausmacht, gestalten Fachexperten das Verhalten des Agenten durch Expertenfeedback direkt. Die Prozesse für den Judge-Abgleich und die Optimierung setzen Fachexpertise in konkrete Systemänderungen um, während Entwickler die Kontrolle über das gesamte System behalten, einschließlich der Frage, welche Teile automatisiert und wo manuelle Eingriffe zugelassen werden sollen.
In diesem Beitrag haben wir gezeigt, wie man einen Agenten so anpasst, dass er die spezifische Sprache und die Details widerspiegelt, die für Fachexperten im Profifußball wichtig sind. Der DC-Assistent demonstriert das Muster, aber der Ansatz funktioniert in jedem Bereich, in dem es auf das Urteil von Experten ankommt: bei der Prüfung von Rechtsdokumenten, bei der Vorbereitung von Baseball-Schlägern, bei der medizinischen Triage, bei der Analyse von Golfschlägen, bei der Eskalation des Kundensupports oder bei jeder anderen Anwendung, bei der "gut" für die Entwickler ohne die Unterstützung von Fachexperten schwer zu definieren ist.
Probieren Sie es bei Ihrem eigenen domänenspezifischen Problem aus und sehen Sie, wie es basierend auf dem Feedback von Fachexperten eine automatisierte und kontinuierliche Verbesserung vorantreiben kann!
Erfahren Sie mehr über Databricks Sports und Agent Bricks oder fordern Sie eine Demo an, um zu sehen, wie Ihre Organisation wettbewerbsrelevante Erkenntnisse gewinnen kann.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.