Überwachtes vs. unüberwachtes Lernen: Die Unterschiede und Fähigkeiten jedes ML-Ansatzes verstehen
- Beaufsichtigtes Lernen und unüberwachtes Lernen dienen unterschiedlichen Zwecken: Beaufsichtigtes Lernen verwendet gelabelte Daten für präzise Vorhersagen und Klassifizierungen, während unüberwachtes Lernen verborgene Muster in rohen, ungelabelten Daten findet. Jede Methode eignet sich besser für unterschiedliche Geschäftsziele.
- Modernes ML kombiniert beide Ansätze: Techniken wie semi-überwachtes und selbst-überwachtes Lernen vereinen die Stärken beider Paradigmen.
- Die eigentliche Herausforderung liegt im Aufbau von Systemen: Erfolgreiches Enterprise ML hängt von der Orchestrierung beider Ansätze innerhalb zuverlässiger Datenpipelines, starker Governance und kontinuierlicher Evaluierung während des gesamten Modelllebenszyklus ab.
Machine learning systems lernen aus Daten, um Vorhersagen zu treffen, Informationen zu klassifizieren oder Muster zu entdecken, die für Menschen manuell schwer zu erkennen wären.
Was ist überwachtes Lernen?
Beim überwachten Lernen werden Modelle mit gelabelten Daten trainiert, bei denen jede Eingabe mit einer bekannten Ausgabe verknüpft ist. Das Modell lernt, indem es seine Vorhersagen mit diesen korrekten Antworten vergleicht und den Fehler iterativ reduziert.
Im Kern dieses Prozesses stehen Machine-Learning-Modelle, die explizite Beziehungen zwischen Merkmalen und Ergebnissen lernen. Die Anwesenheit von gelabelten Daten liefert klare Anleitungen, wodurch sich überwachtes Lernen gut für Probleme eignet, bei denen Genauigkeit, Nachverfolgbarkeit und Wiederholbarkeit unerlässlich sind.
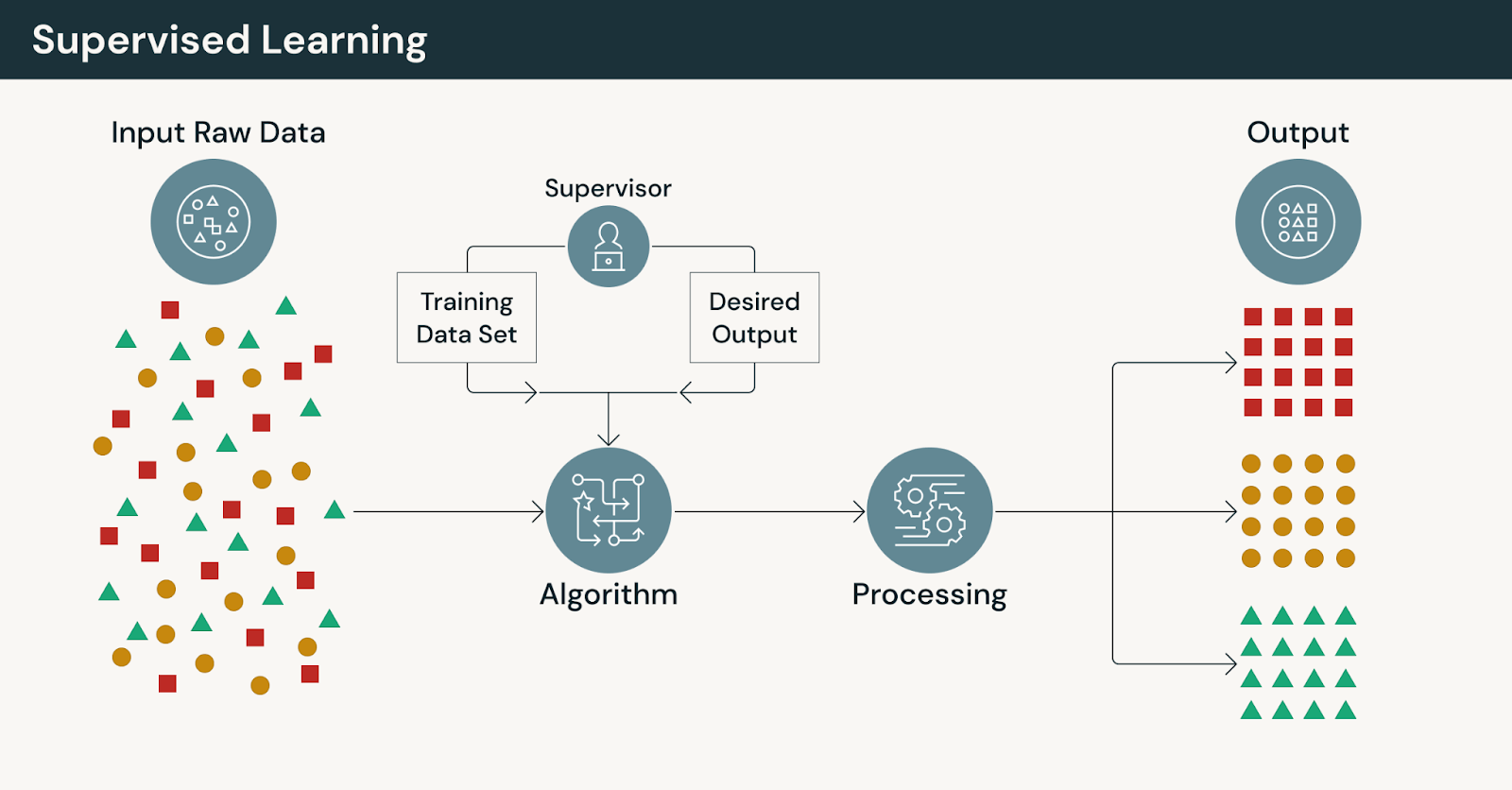
Wie überwachtes Lernen funktioniert
Ein typischer Workflow für überwachtes Lernen umfasst:
- Sammeln historischer Trainingsdaten mit bekannten Ergebnissen
- Vorbereiten und Validieren von gelabelten Trainingsdatensätzen
- Entwickeln von Merkmalen, die relevante Signale erfassen
- Trainieren und Evaluieren von Modellen anhand der Ground Truth
- Bereitstellen von Modellen und Verfolgen der Leistung über die Zeit
Dieser Workflow hängt von der Verfügbarkeit und Qualität der Labels ab – eine Einschränkung, die mit wachsendem Datenvolumen oft deutlicher wird.
Arten des überwachten Lernens
Probleme des überwachten Lernens fallen im Allgemeinen in zwei Kategorien:
- Klassifizierung: Zuweisen von Eingabedaten zu vordefinierten Klassen, wie z. B. Spam- vs. legitime E-Mails oder positive vs. negative Stimmungen.
- Regression: Vorhersage kontinuierlicher Werte, wie z. B. Nachfrageprognosen, Preisgestaltung oder Risikobewertungen. Transportunternehmen nutzen Regressionsmodelle, um Flugzeiten basierend auf historischen Routenleistungen, saisonalen Mustern und operativen Faktoren vorherzusagen, was bei der Optimierung der Planung und der Festlegung genauer Kundenerwartungen hilft.
In beiden Fällen kann die Modellleistung direkt anhand bekannter Ergebnisse gemessen werden, was die Bewertung und Rechenschaftspflicht vereinfacht.
Häufige Anwendungen des überwachten Lernens
Überwachtes Machine Learning wird häufig verwendet für:
- E-Mail-Filterung und Inhaltsmoderation
- Stimmungsanalyse in Kundenfeedback
- Prognose und prädiktive Analysen
- Bild- und Dokumentenklassifizierung
Viele Anwendungen der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) basieren auf überwachtem Fine-Tuning, um allgemeine Modelle an domänenspezifische Aufgaben, Richtlinien oder Vokabulare anzupassen.
Überwachtes Lernen in verschiedenen Branchen
Anwendungen des überwachten Lernens erstrecken sich über praktisch jeden Sektor, wobei einige Anwendungsfälle zu Grundlagen moderner digitaler Infrastrukturen geworden sind.
Cybersicherheit: Spam-Erkennungssysteme analysieren täglich Milliarden von E-Mails und verwenden überwachte Modelle, die auf gelabelten Beispielen legitimer und bösartiger Nachrichten trainiert wurden. Moderne Spam-Erkennung geht über einfache Schlüsselwortabgleiche hinaus und integriert Absenderreputation, Nachrichtenstruktur, Analyse von Anhängen und Verhaltensmuster.
Gesundheitswesen und Biowissenschaften: Überwachtes Lernen beinhaltet das Trainieren prädiktiver Modelle auf gelabelten biomedizinischen und genomischen Daten, um Muster zu identifizieren, die mit krankheitsbezogenen Varianten und therapeutischen Zielen verbunden sind. Durch die Anwendung dieser Modelle innerhalb einer skalierbaren Analyseplattform können Forscher Beziehungen zwischen genetischen Merkmalen und klinischen Ergebnissen quantifizieren, was eine genauere Vorhersage von Medikamentenzielen ermöglicht und die hypothesengesteuerte Entdeckung beschleunigt.
Finanzdienstleistungen: Überwachtes Lernen wurde verwendet, um Risiko- und Betrugserkennungsmodelle auf gelabelten historischen Transaktionsdaten zu trainieren, wodurch das System zwischen legitimen und verdächtigen Aktivitäten unterscheiden kann. Durch das Lernen von bekannten Ergebnissen – wie bestätigten Betrugsfällen oder validierten Kundenverhalten – verbesserten die Modelle die Genauigkeit der Echtzeit-Erkennung und reduzierten gleichzeitig Fehlalarme. Eingebettet in eine skalierbare Datenplattform unterstützten diese überwachten Modelle schnellere Entscheidungsfindung und ein widerstandsfähigeres Management von Finanzrisiken.
Einzelhandel und Konsumgüter: Mithilfe von gelabelten historischen Verkaufs-, Preis- und Aktionsdaten wurden prädiktive Modelle trainiert, um die Nachfrage vorherzusagen und Lagerbestandsentscheidungen in großem Maßstab zu optimieren. Durch das Lernen von bekannten Ergebnissen – wie früheren Produktbewegungen und regionalen Nachfragemustern – verbesserte das System die Prognosegenauigkeit über Tausende von Standorten hinweg. Dies ermöglichte eine präzisere Nachschubversorgung, reduzierte Fehlbestände und eine engere Abstimmung zwischen Lieferkettenbetrieb und Kundennachfrage.
Kundenerlebnisse: Prädiktive Modelle wurden auf einheitlichen und gelabelten Kundeninteraktions- und Profildaten trainiert, um Muster zu lernen, die bei der Segmentierung von Zielgruppen und der Vorhersage von Kundenverhalten helfen. Diese überwachten Modelle ermöglichten genauere Kundeneinblicke und unterstützten gezielte Marketing- und Personalisierungsstrategien. Dies führte zu einer schnelleren Bereitstellung umsetzbarer Erkenntnisse, die das Kundenengagement und die Kundenerfahrung über verschiedene Kanäle hinweg verbessern.
Medien und Unterhaltung: Gelabelte Gameplay-, Engagement- und Verhaltensdaten wurden verwendet, um prädiktive Modelle zu trainieren, die Muster in der Spieleraktivität und der Inhaltsinteraktion identifizieren. Durch das Lernen von bekannten Ergebnissen – wie Abwanderungssignalen, In-Game-Verhalten und Community-Trends – ermöglichte das System eine genauere Prognose und eine schnellere Inhaltsoptimierung. Dies unterstützte verbesserte Spielerlebnisse, bessere Entscheidungen im Live-Betrieb und datengesteuerte Entwicklung in einem globalen Gaming-Ökosystem.
Jede Anwendung hat eine gemeinsame Anforderung: zuverlässige, gelabelte Trainingsdaten, die den Problembereich genau darstellen, und eine kontinuierliche Überwachung, um festzustellen, wann die Modellleistung nachlässt.
Was ist unüberwachtes Lernen?
Anstatt aus gelabelten Beispielen zu lernen, analysiert unüberwachtes Machine Learning ungelabelte Daten, um Muster, Strukturen oder Beziehungen ohne vordefinierte Ziele zu identifizieren.
Dies macht unüberwachtes Lernen besonders wertvoll zu Beginn von ML-Projekten, wenn Teams möglicherweise noch nicht wissen, welche Fragen sie stellen sollen – oder wenn das Labeln von Daten unpraktisch oder zu teuer ist.
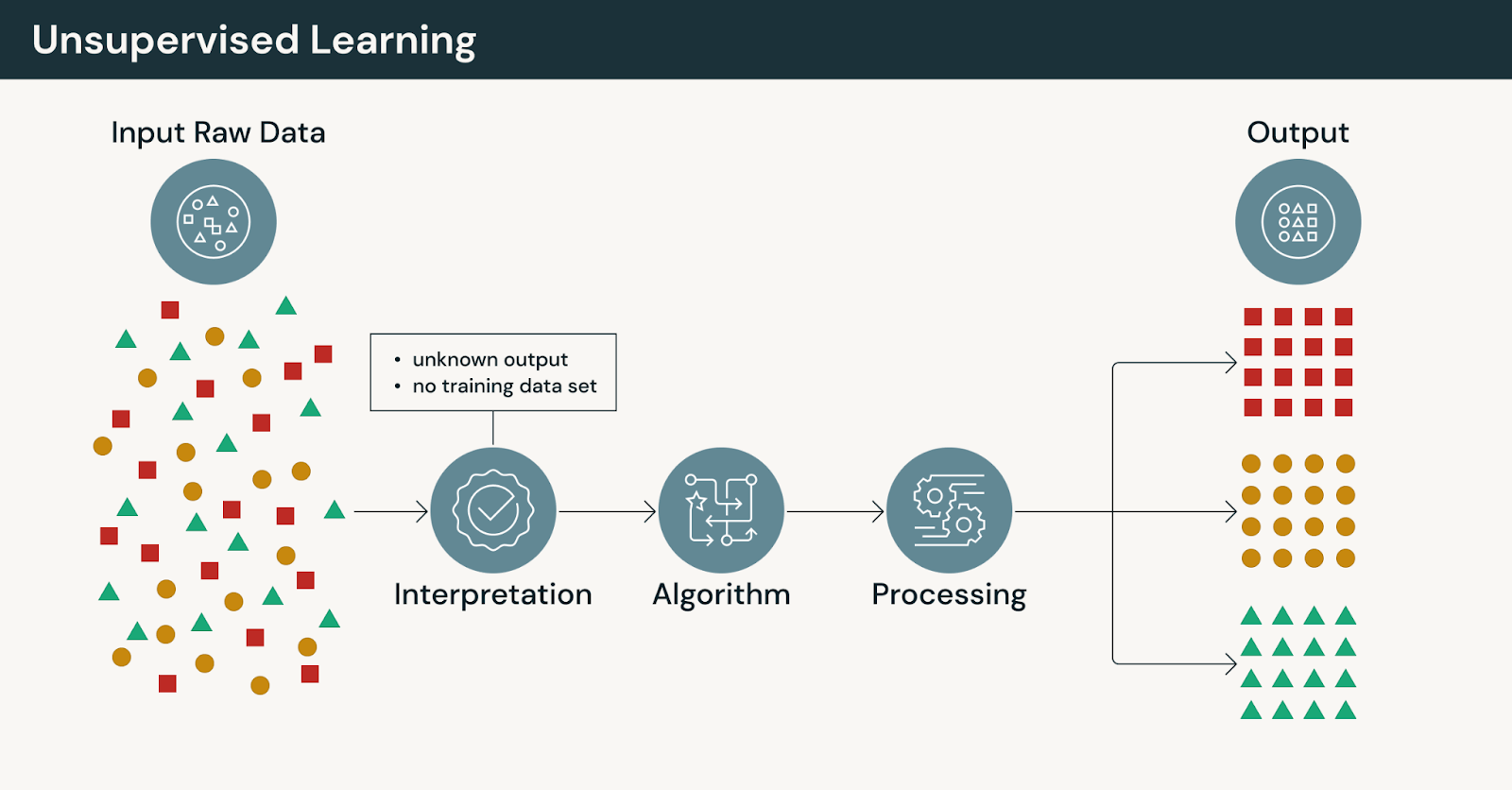
Wie unüberwachtes Lernen funktioniert
Beim unüberwachten Lernen:
- Modelle arbeiten ohne explizit vom Menschen bereitgestellte Labels
- Algorithmen gruppieren, komprimieren oder organisieren Daten basierend auf Ähnlichkeit
- Ausgaben erfordern Interpretation und Validierung durch Fachexperten
Da es keine korrekten Antworten gibt, legt unüberwachtes Lernen den Schwerpunkt auf Erkundung statt auf Vorhersage.
Arten des unüberwachten Lernens
Gängige unüberwachte Techniken umfassen:
- Clustering: Gruppieren ähnlicher Datenpunkte, um Struktur aufzudecken
- Dimensionsreduktion: Vereinfachen komplexer Datensätze zur Analyse
- Assoziationsregel-Lernen: Identifizieren von Beziehungen zwischen Variablen
Viele dieser Methoden basieren auf Clustering-Algorithmen, um Muster aufzudecken, die nicht im Voraus explizit definiert wurden.
Häufige Anwendungen des unüberwachten Lernens
Unüberwachtes Machine Learning wird häufig verwendet für:
- Kundensegmentierungsstrategien im Marketing und in der Personalisierung, wobei Clustering verwendet wird, um ähnliche Datenpunkte nach Verhalten, Vorlieben und Wert zu gruppieren, anstatt nach vordefinierten Kategorien
- Anomalieerkennungssysteme zur Betrugsprävention und Betriebsüberwachung
- Explorative Datenanalyse und Entdeckung von Verhaltensmustern
- Groß angelegte Ähnlichkeitssuche und -gruppierung
- Warenkorbanalysen und Produktempfehlungssysteme, bei denen Algorithmen wie der Apriori-Algorithmus Kaufmuster und Produktassoziationen entdecken, ohne dass ihnen mitgeteilt wird, welche Artikel miteinander in Beziehung stehen sollten
Da Organisationen immer mehr Rohdaten ansammeln, bietet unüberwachtes Lernen eine Möglichkeit, Wert zu extrahieren, ohne auf aufwändige Labeling-Bemühungen warten zu müssen.
Wesentliche Unterschiede zwischen überwachtem und unüberwachtem Lernen
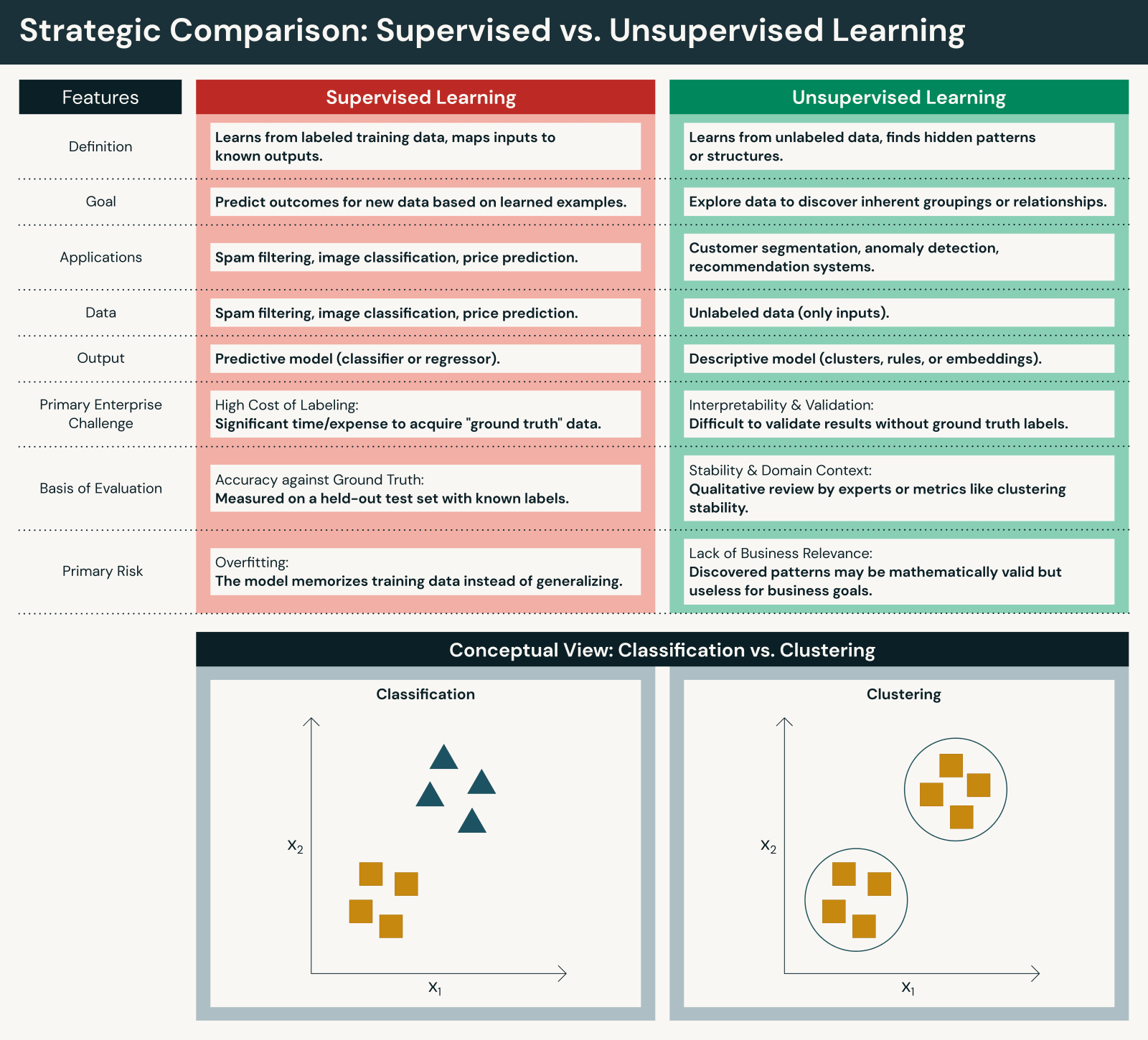
Obwohl beide Ansätze grundlegend sind, unterscheiden sie sich in wichtigen Punkten:
Daten und menschlicher Aufwand
- Überwachtes Lernen erfordert gelabelte Datensätze, die oft durch manuelle Annotation oder Expertenprüfung erstellt werden. Während überwachtes Machine Learning erheblichen menschlichen Eingriff für das Labeling erfordert, stellt dieser menschliche Eingriff sicher, dass die Genauigkeit mit den Geschäftszielen übereinstimmt.
- Unüberwachtes Lernen arbeitet direkt mit Rohdaten, was die Vorbereitung reduziert, aber den Interpretationsaufwand erhöht. Unüberwachtes Machine Learning reduziert den menschlichen Eingriff während des Trainings, erfordert aber menschlichen Eingriff zur Interpretation der Ergebnisse.
Ziele
- Überwachtes Lernen konzentriert sich auf Vorhersage und Klassifizierung anhand bekannter Ergebnisse, um Ergebnisse präzise vorherzusagen.
- Unüberwachtes Lernen konzentriert sich auf Entdeckung und Erkenntnisgewinnung, um Muster in Daten aufzudecken.
Bewertung und Transparenz
- Überwachte Modelle können anhand klarer Leistungsmetriken gegen korrekte Antworten bewertet werden (Genauigkeit, Präzision, Recall, F1, RMSE usw.).
- Unüberwachte Lernmodelle erfordern eine indirekte Bewertung und Domänenkontext, um die Nützlichkeit zu beurteilen (Silhouetten-Scores, Ellenbogenmethode, Validierung durch Domänenexperten usw.).
Skalierbarkeit
- Überwachtes Lernen skaliert aufgrund von Kennzeichnungsbeschränkungen oft langsamer.
- Unüberwachtes Lernen skaliert natürlich mit dem Datenvolumen, kann aber zu verrauschteren Ergebnissen führen.
In Unternehmensumgebungen führen diese Hauptunterschiede dazu, dass Teams hybride Ansätze anstelle von ausschließlichen Entscheidungen verfolgen.
Das Playbook für agentenbasierte KI für Unternehmen

Semi-überwachtes und selbst-überwachtes Lernen
Moderne ML-Systeme kombinieren zunehmend Paradigmen:
Semi-überwachtes Lernen kombiniert einen kleinen, gekennzeichneten Datensatz mit einem viel größeren Pool unbeschrifteter Daten, wodurch die Kennzeichnungskosten reduziert und gleichzeitig die Vorhersagegenauigkeit beibehalten werden.
Selbst-überwachtes Lernen geht weiter, indem es Modellen ermöglicht, ihre eigenen Trainingssignale aus Rohdaten zu generieren. Dieser Ansatz bildet die Grundlage für viele moderne Foundation Models und hat das überwachte Lernen von einer Ausgangsbasis zu einer Verfeinerungsrolle verschoben.
Diese Techniken ermöglichen es Organisationen:
- Bestehende Datenbestände in großem Maßstab zu nutzen
- Schneller an neue Datenverteilungen anzupassen
- Abhängigkeit von manueller Kennzeichnung zu reduzieren
Es ist erwähnenswert, dass überwachtes und unüberwachtes Lernen nicht die gesamte Landschaft des maschinellen Lernens darstellen. Reinforcement Learning ist ein drittes Hauptparadigma, bei dem Agenten optimale Verhaltensweisen durch Versuch-und-Irrtum-Interaktionen mit Umgebungen lernen und für ihre Aktionen Belohnungen oder Strafen erhalten. Obwohl Reinforcement Learning außerhalb des Spektrums von überwacht und unüberwacht liegt, kombinieren moderne Systeme zunehmend alle drei Ansätze, abhängig von den Aufgabenanforderungen.
Wann überwachtes vs. unüberwachtes Lernen verwenden
In der Praxis hängt die richtige Wahl von Daten, Zielen und betrieblichen Einschränkungen ab.
Bewerten Sie Ihre Daten
- Haben Sie heute zuverlässige Kennzeichnungen?
- Können Sie die Kennzeichnungsqualität bei wachsender Datenmenge aufrechterhalten?
- Wie oft ändern sich Ihre Daten?
Definieren Sie Ihr Ziel
- Ergebnisse vorhersagen? Überwachtes Lernen passt.
- Unbekannte Struktur erkunden? Unüberwachtes Lernen ist oft der richtige Einstiegspunkt.
Planen Sie für den gesamten Lebenszyklus
Unabhängig vom Ansatz hängen erfolgreiche Systeme von zuverlässigen Data Engineering-Pipelines ab, die Daten konsistent von der Aufnahme über das Training bis zur Produktion bewegen.
Viele Teams beginnen mit unüberwachter Exploration und führen dann überwachtes Lernen ein, sobald Ziele und Metriken gut definiert sind.
Warum einheitliche Daten- und KI-Governance für eine unternehmensweite ML-Strategie entscheidend ist
Wenn ML-Systeme skaliert werden, müssen Unternehmen Zugriff, Herkunft, Compliance und Rechenschaftspflicht verwalten.
Hier wird einheitliche Datengovernance entscheidend. Die konsistente Steuerung von Daten und Modellen über Workflows hinweg stellt sicher, dass Erkenntnisse vertrauenswürdig sind und Systeme im Laufe ihrer Entwicklung überprüfbar bleiben.
Häufig gestellte Fragen
Ist lineare Regression überwacht oder unüberwacht?
Lineare Regression ist überwachtes Lernen, da sie gekennzeichnete Ausgabewerte erfordert.
Was ist der Hauptunterschied zwischen überwachtem und unüberwachtem Lernen?
Überwachtes Lernen sagt bekannte Ergebnisse anhand gekennzeichneter Daten voraus. Unüberwachtes Lernen entdeckt Muster in unbeschrifteten Daten.
Was Sie für die Zukunft wissen müssen
Mehrere Trends gestalten Enterprise ML neu:
- Selbst-überwachtes Lernen dominiert das Training von Foundation Models.
- Überwachtes Lernen dient zunehmend als Präzisionsebene.
- Clustering und Embeddings werden zu Kernfähigkeiten für Unternehmen.
- Bewertung und Governance gewinnen an Bedeutung, da die Nutzung unbeschrifteter Daten zunimmt.
Diese Verschiebungen bekräftigen die Notwendigkeit, in Systemen und nicht in Silos zu denken.
Herausforderungen und Einschränkungen
Sowohl überwachtes als auch unüberwachtes Lernen spielen eine wesentliche Rolle in Enterprise ML, aber jeder Ansatz birgt Kompromisse, für die Teams frühzeitig planen müssen.
Herausforderungen beim überwachten Lernen
Datenanforderungen sind oft die größte Einschränkung. Das Erstellen von gekennzeichneten Datensätzen kann zeitaufwendig und teuer sein, insbesondere wenn die Kennzeichnung Domänenexpertise erfordert. In vielen Fällen ist die Modellgenauigkeit direkt an die Qualität der Kennzeichnungen gebunden, was inkonsistente oder voreingenommene Annotationen zu einem ernsthaften Risiko macht.
Überwachte Modelle sind auch Risiken des Overfittings ausgesetzt. Wenn Modelle Trainingsdaten zu genau lernen, können sie bei der Bewertung gut abschneiden, aber bei neuen oder ungesehenen Daten nicht verallgemeinern. Häufige Abhilfemaßnahmen sind Kreuzvalidierung, Regularisierungstechniken und die Erweiterung von Trainingsdatensätzen, um die reale Variabilität besser widerzuspiegeln.
Skalierbarkeitsbedenken entstehen mit wachsenden Datenvolumina. Die Kennzeichnung durch Menschen im Loop skaliert nicht linear, und manuelle Prozesse können für große oder schnelllebige Projekte zu Engpässen werden. Ohne sorgfältige Planung können überwachte Workflows Schwierigkeiten haben, mit Geschäftsanforderungen Schritt zu halten.
Herausforderungen beim unüberwachten Lernen
Unüberwachtes Lernen führt zu einer anderen Reihe von Problemen, beginnend mit Interpretationsschwierigkeiten. Cluster oder Muster haben ohne Domänenkontext möglicherweise keine offensichtliche Bedeutung, und die entdeckte Struktur stimmt nicht immer mit Geschäftszielen überein. Die Wertschöpfung erfordert oft eine enge Zusammenarbeit zwischen Data Scientists und Fachexperten.
Die Komplexität der Validierung ist eine weitere Herausforderung. Ohne Ground-Truth-Labels kann es schwierig sein, die Modellqualität objektiv zu bewerten. Teams verlassen sich oft auf Proxy-Metriken, Geschäftsausrichtung oder vergleichende Bewertungen über mehrere Algorithmen hinweg, um Vertrauen in die Ergebnisse aufzubauen.
Schließlich erfordert die Algorithmenauswahl Experimente. Die Ergebnisse können je nach Parameterwahl, Distanzmaßen oder Vorverarbeitungsschritten erheblich variieren, was Iteration unvermeidlich macht.
Best Practices für maschinelles Lernen
Bei beiden Ansätzen verbessern mehrere Praktiken durchweg die Ergebnisse:
- Stellen Sie qualitativ hochwertige Eingabedaten sicher, einschließlich der ordnungsgemäßen Behandlung fehlender Werte und Ausreißer
- Beginnen Sie mit einer klaren Problemdefinition, bevor Sie einen Ansatz wählen
- Implementieren Sie frühzeitig Datenqualitätsprüfungen und Validierungsprozesse
- Verwenden Sie für jedes Paradigma geeignete Bewertungsmetriken
- Beginnen Sie mit explorativer Datenanalyse, bevor Sie sich auf Produktions-Workflows festlegen
Zuverlässige Data Engineering-Lösungen bilden die Grundlage für die konsistente Anwendung dieser Praktiken und helfen Teams, mit größerer Zuversicht von der Experimentierphase zur Produktion zu gelangen.
Was Sie 2026 wissen müssen
Mehrere Verschiebungen gestalten die Praxis von Enterprise ML bereits neu.
1. Selbst-überwachtes Pre-Training bildet nun die Grundlage für die meisten modernen Foundation Models
Die meisten State-of-the-Art-Modelle – einschließlich großer Sprachmodelle, Computer-Vision-Systeme und multimodaler Architekturen – werden jetzt hauptsächlich mithilfe von selbst-überwachtem Lernen trainiert. Anstatt sich auf von Menschen gekennzeichnete Datensätze zu verlassen, generieren diese Modelle ihre eigenen Trainingssignale aus Rohdaten, z. B. durch Vorhersage des nächsten Tokens in einer Sequenz oder Rekonstruktion maskierter Teile einer Eingabe.
Diese Verschiebung spiegelt eine praktische Realität wider: Unternehmen verfügen über riesige Mengen unbeschrifteter Daten, aber die Kennzeichnung in großem Maßstab ist kostspielig und langsam. Selbst-überwachtes Lernen ermöglicht es Organisationen, Wert aus bestehenden Datenbeständen zu ziehen und gleichzeitig Repräsentationen aufzubauen, die später an spezifische Aufgaben angepasst werden können.
2. Supervised Fine-Tuning hat eine Verfeinerungsrolle übernommen
Überwachtes Lernen ist nicht verschwunden – aber seine Rolle hat sich geändert. Anstatt als primärer Trainingsmechanismus zu dienen, wird Supervised Fine-Tuning zunehmend verwendet, um Modelle für klar definierte Geschäftsziele zu verfeinern, abzustimmen und zu validieren.
Dieser Ansatz ermöglicht es Teams, Kennzeichnungsbemühungen dort zu konzentrieren, wo Präzision am wichtigsten ist, z. B. bei regulatorischen Anforderungen, Sicherheitsbeschränkungen oder domänenspezifischer Genauigkeit, und unnötige Kennzeichnungen früher in der Pipeline zu vermeiden.
3. Embeddings sind jetzt Kernfähigkeiten für Unternehmen
Embeddings sind zu einer Kerninfrastruktur für Unternehmen geworden. Foundation Models geben zunehmend Vektor-Embeddings aus, die semantische Bedeutung über Text, Bilder, Audio und strukturierte Daten hinweg erfassen. Diese Embeddings treiben Ähnlichkeitssuche, Retrieval, Personalisierung, Anomalieerkennung und Empfehlungssysteme in großem Maßstab an.
Clustering und andere Ähnlichkeitsmethoden sind wichtig – aber sie sind nachgelagerte Anwendungen von Embeddings und keine gleichwertigen Paradigmen. Die strategische Verschiebung geht nicht zum Clustering selbst, sondern zu Embedding-zentrierten Architekturen, die eine einheitliche Suche, Retrieval und Schlussfolgerung über Unternehmensdaten hinweg ermöglichen.
Wenn Organisationen KI operationalisieren, werden Embeddings zum Bindeglied zwischen selbst-überwachtem Pre-Training, Supervised Fine-Tuning und nachgelagerten Anwendungen. Sie bieten eine gemeinsame Repräsentationsebene, die sowohl Erkundungs- als auch Präzisions-Workflows innerhalb moderner, einheitlicher Datenplattformen unterstützt.
Systeme aufbauen, nicht Seiten
Überwachtes und unüberwachtes Lernen lösen unterschiedliche Probleme – und moderne ML-Systeme benötigen beides. Überwachtes maschinelles Lernen eignet sich hervorragend, wenn Sie über gelabelte Daten verfügen und präzise, nachvollziehbare Vorhersagen oder Klassifizierungen benötigen. Unüberwachtes maschinelles Lernen gedeiht, wenn das Ziel die Entdeckung ist und Teams dabei hilft, Muster und Erkenntnisse in Rohdaten ohne vordefinierte Ausgaben aufzudecken. Wenn gelabelte Daten begrenzt sind, schließen Ansätze des semi-überwachten Lernens die Lücke, indem sie beide Paradigmen kombinieren.
Die eigentliche Herausforderung besteht nicht darin, zwischen überwachtem und unüberwachtem Lernen zu wählen, sondern Systeme zu entwickeln, die Ansätze kombinieren, sich im Laufe der Zeit weiterentwickeln und zuverlässig in der Produktion laufen können. Effektive Teams beginnen damit, ihre Datenverfügbarkeit zu bewerten, zu klären, ob ihr Hauptziel Vorhersage oder Exploration ist, und die Ressourcen zu bewerten, die für die Unterstützung jedes Ansatzes erforderlich sind.
Strategien des maschinellen Lernens sind selten statisch. Unüberwachte Exploration informiert oft die spätere Entwicklung von überwachten Modellen, während die überwachte Feinabstimmung Präzision und Validierung für Systeme liefert, die auf breiteren Darstellungen basieren. Im Laufe der Zeit müssen Erkenntnisse in die Business Intelligence und Analytik fließen, wo sie Entscheidungen informieren und Ergebnisse erzielen können.
Um tiefer einzusteigen, erkunden Sie diese Ressourcen:
- Ein kompakter Leitfaden zur Feinabstimmung und Vortrainierung von LLMs – Erlernen Sie Techniken zur Feinabstimmung und Vortrainierung Ihres LLM
Holen Sie sich den Leitfaden - Das große Buch der generativen KI – Best Practices für die Erstellung von GenAI-Anwendungen in Produktionsqualität
Herunterladen - Das große Buch der Anwendungsfälle für maschinelles Lernen – Erhalten Sie alles, was Sie brauchen, um maschinelles Lernen einzusetzen
Jetzt lesen
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.