Warum Ihre Agenten Unternehmensdokumente nicht lesen können – und wie Sie das beheben
Einführung von Document Intelligence auf Databricks
von Archika Dogra, Sergei Tsarev und Erich Elsen
- Frontier-Agenten erzielen bei realen Unternehmensdokumenten immer noch weniger als 50 % Genauigkeit. Die Ursache ist nicht das Schlussfolgern, sondern das Lesen.
- Die Dokumentenverarbeitung ist die Genauigkeitsgrenze für jeden Agenten-Workflow.
- Wir führen Document Intelligence ein, um diese Lücke zu schließen: Bereitstellung von forschungsbasierter Genauigkeit, Unternehmensskalierung und End-to-End-Einfachheit.
Die wichtigsten Business-Intelligence-Daten sind nicht nur in Warehouses gespeichert – sie stecken in den Millionen von Dokumenten, die täglich die Kern-Unternehmensabläufe antreiben: Verträge, Schadensfälle, Rechnungen und mehr. Ein Jahrzehnt lang wurde Intelligent Document Processing (IDP) als ein eng gefasstes Automatisierungsproblem im Backoffice betrachtet. Im Zeitalter der Agenten ist die Situation grundlegend anders: IDP ist die entscheidende Grundlage, die bestimmt, ob Ihre Agenten Entscheidungen treffen, denen Sie tatsächlich vertrauen.
Betrachten wir die Bearbeitung von Versicherungsansprüchen. Auf dem Papier ist dies ein idealer Agenten-Workflow: Anspruch aufnehmen, Details extrahieren, Anomalien kennzeichnen und weiterleiten. Heutige fortschrittliche Agenten können die Schlussfolgerungen leicht ziehen. Wo sie scheitern, ist das Lesen der Dokumente: gescannte PDFs mit inkonsistenten Layouts, verschachtelten Tabellen, handschriftlichen Notizen und Formatvariationen bei jedem Anbieter. Eine "10.000 $" wird als "3.000 $" halluziniert, der Agent trifft eine fehlerhafte Entscheidung und der falsche Betrag wird stillschweigend ausgezahlt.
Wir sehen dieses Muster branchenweit: Agenten können gut mit klarem Text umgehen, aber sie scheitern, wenn sie mit echten Unternehmensdokumenten konfrontiert werden. Vor einigen Monaten veröffentlichte Databricks AI Research OfficeQA, einen Benchmark, der auf realen Unternehmensdokumenten-Workflows basiert. Wir stellten fest, dass selbst hochleistungsfähige fortschrittliche Agenten bei Dokumenten-Reasoning-Aufgaben eine Genauigkeit von unter 50 % erzielten. Die Engstelle war nicht das Reasoning – es war das Lesen.
Deshalb freuen wir uns, Document Intelligence ankündigen zu können, das auf drei Kernpfeilern basiert: forschungsgestützte Genauigkeit, Unternehmensskalierung und End-to-End-Einfachheit.
Bei Intercontinental Exchange verarbeiten wir jeden Monat Millionen komplexer, hochvariabler Finanzdokumente. Document Intelligence hilft uns, diese Komplexität in strukturierte Marktinformationen umzuwandeln, sodass wir schneller agieren, unseren Kunden einen größeren Mehrwert bieten und Agenten-Workflows erschließen können, die die Analyse und Entscheidungsfindung in großem Maßstab beschleunigen." —Anand Pradhan, CTO und Head of AI, Mortgage Data bei Intercontinental Exchange (NYSE)
Verbesserung der Agentenqualität bei realen Unternehmensdokumenten
Die Dokumentenverarbeitung ist die Genauigkeitsgrenze für jeden Agenten. Um dies richtig zu machen, hat das Databricks AI Research Team spezialisierte Systeme entwickelt, die für die unordentliche Realität konzipiert sind, mit der Unternehmen tatsächlich umgehen: inkonsistente Layouts, verschachtelte Tabellen, Bilder und Handschriften.
Diese Forschung treibt eine Reihe von verkettbaren KI-Funktionen an, die die Dokumentenverarbeitung in komponierbare Schritte unterteilen: ai_parse_document (jetzt allgemein verfügbar) wandelt Rohscans in layout-angereicherte strukturierte Texte um, während nachgelagert ai_classify Dokumente korrekt weiterleitet und ai_extract die wichtigsten strukturierten Erkenntnisse extrahiert. Zusammen bilden sie eine Document Intelligence-Pipeline, die Sie einfach zusammenstellen können: einmal parsen, dann klassifizieren, extrahieren und erneut extrahieren, ohne das Originaldokument erneut zu verarbeiten.
Verbessert eine bessere Dokumentenverarbeitung tatsächlich die Genauigkeit von Agenten? Als wir reale Schatzbriefdokumente über OfficeQA benchmarkten, lieferte die Vorverarbeitung mit ai_parse_document eine durchschnittliche Leistungssteigerung von 16 % über alle getesteten Agenten-Frameworks hinweg. Das Reasoning-Gerüst des Agenten änderte sich überhaupt nicht, aber die darunterliegende Datenebene des Dokuments schon.
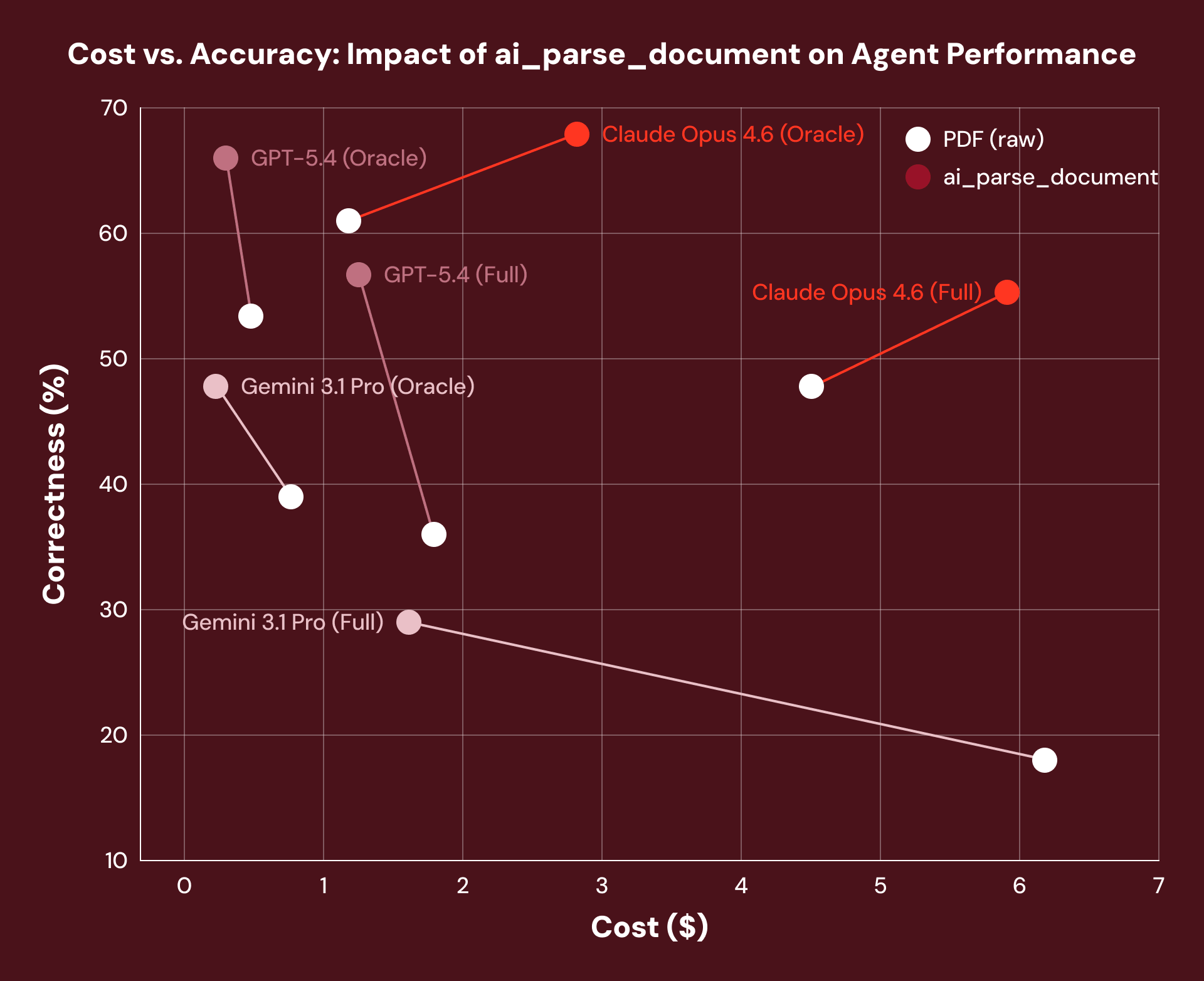
Hinweis: Wir beobachteten eine Erhöhung der Claude Opus 4.6 Kosten aufgrund der Tendenz des Modells, mehr Tokens abzurufen, wenn ihm der strukturierte Layout-Text eines Dokuments zur Verfügung gestellt wurde.
Genau deshalb bauen wir Document Intelligence als Grundlage für Ihre Agenten-Workflows: Die Qualitäts- und Kostenvorteile der Dokumentenverarbeitung summieren sich über alles, was darauf aufbaut.
Mit Document Intelligence legen wir den Grundstein für eine intelligente Dokumentenverarbeitungspipeline, die jedes Jahr wichtige strukturierte Erkenntnisse aus Millionen unstrukturierter technischer PDFs gewinnt, die von Tausenden von Organisationen stammen und stark inkonsistente Formate umfassen. —Graham Lammers, Executive Director of Data Intelligence, Accuris
Document Intelligence im Unternehmensmaßstab erschließen
Selbst wenn die Qualität gelöst ist, ist der Friedhof des unternehmensweiten IDP voller Projekte, die den Pilot erfolgreich abgeschlossen haben, aber die Wirtschaftlichkeit der Produktion nicht überlebten. Dies liegt an Kosten, die auf sechsstellige Beträge ansteigen, und Batch-Jobs, die Tage statt Stunden dauern.
Wir haben Document Intelligence von Anfang an für die Produktionsskalierung wirtschaftlich konzipiert, nicht als nachträglichen Gedanken. Da KI-Funktionen wie ai_parse_document forschungsspezialisiert sind, erzielen sie eine branchenführende Genauigkeit ohne den Rechenaufwand allgemeiner Modelle.
In verschiedenen Lösungen haben wir Genauigkeit und Kosten bei der Extraktion strukturierter Dokumente verglichen, indem wir Schlüsselentitäten aus Unternehmensrechnungen, Verträgen, medizinischen Notizen und Finanzberichten identifiziert haben. Document Intelligence erzielte durchweg die höchste Genauigkeit zu 5-7x geringeren Kosten als vergleichbare Pipelines.

Hinweis: Angebote, die mit (parse + extract) gekennzeichnet sind, verwenden eine zweistufige Pipeline-Architektur – einmal parsen in eine wiederverwendbare Silber-Schicht, dann extrahieren und erneut extrahieren, ohne erneut zu parsen. VLM-basierte Angebote verarbeiten das gesamte Dokument bei jedem Extraktionsaufruf neu.
Wichtig ist, dass zur Unterstützung dieser Skalierung jede KI-Funktion auf einer serverlosen Batch-Infrastruktur läuft, die für volumenstarke Workloads entwickelt wurde: derselbe SQL-Aufruf in einer Zeile, der 100 Rechnungen verarbeitet, verarbeitet 100.000, ohne Ihre Pipeline neu zu gestalten.
Mit Document Intelligence haben wir die gleiche hochwertige Entitätsextraktion zu fast 90 % geringeren Kosten innerhalb weniger Wochen erreicht. Dieser Preis-Leistungs-Durchbruch treibt nun unsere Produktionspipelines an und ermöglicht es uns, schneller in neue Krankheitsbereiche vorzudringen, Hunderte Millionen klinischer Notizen effizient zu verarbeiten und unseren Kunden Erkenntnisse in großem Maßstab zu liefern. —Jerry Dennany, CTO Loopback Analytics
Wichtig ist, dass für die Verarbeitung im großen Maßstab jede KI-Funktion auf einer serverlosen Batch-Infrastruktur läuft, die für volumenstarke Workloads entwickelt wurde: derselbe SQL-Aufruf in einer Zeile, der 100 Rechnungen verarbeitet, verarbeitet 100.000, ohne Ihre Pipeline neu zu gestalten.
Von fragmentierten Pipelines zu einem einheitlichen Workflow
Für die meisten Unternehmen ist Document Intelligence heute keine Plattformfunktion. Es ist eine Sammlung von Einweg-Pipelines. Für nur einen Anwendungsfall fügt ein Team einen OCR-Dienst zusammen, schaltet eine separate Extraktions-API hinzu und integriert ein Klassifizierungsmodell von einem weiteren Anbieter. Bald darauf verwalten sie drei bis fünf getrennte APIs, die durch fragile benutzerdefinierte Klebe-Codes zusammengehalten werden – eine Pipeline, die spröde, teuer in der Wartung und fast unmöglich zu debuggen ist, wenn sie um 3 Uhr morgens ausfällt. Und wenn ein anderes Team einen anderen Dokumententyp verarbeiten muss, gibt es nichts Wiederverwendbares, worauf man aufbauen kann. Sie fangen von vorne an.
Dies ist der Kreislauf, der Document Intelligence als eine Reihe von Einwegprojekten gefangen hält, anstatt als unternehmensweite Fähigkeit. Document Intelligence durchbricht diesen Kreislauf. Anstatt getrennte Dienste zusammenzufügen, läuft jeder Schritt nativ innerhalb Ihrer bestehenden Databricks-Orchestrierungs- und Governance-Schicht:
- Ingestieren Sie Dokumente (z. B. von SharePoint) mit Lakeflow Connect.
- Orchestrieren Sie die gesamte Pipeline mit Lakeflow Jobs oder Spark Declarative Pipelines, mit integrierter Fehlerbehandlung, Beobachtbarkeit und automatischer Verarbeitung neuer Dokumente.
- Verwalten Sie die End-to-End-Datenherkunft, Sicherheit und Zugriffskontrollen Ihrer Pipelines und Daten – vom Rohdokument bis zur strukturierten Tabellenausgabe – mit Unity Catalog.
- Erstellen Sie Agenten auf der neuen, angereicherten Dokumentendaten-Schicht mit der Agent Bricks-Plattform.
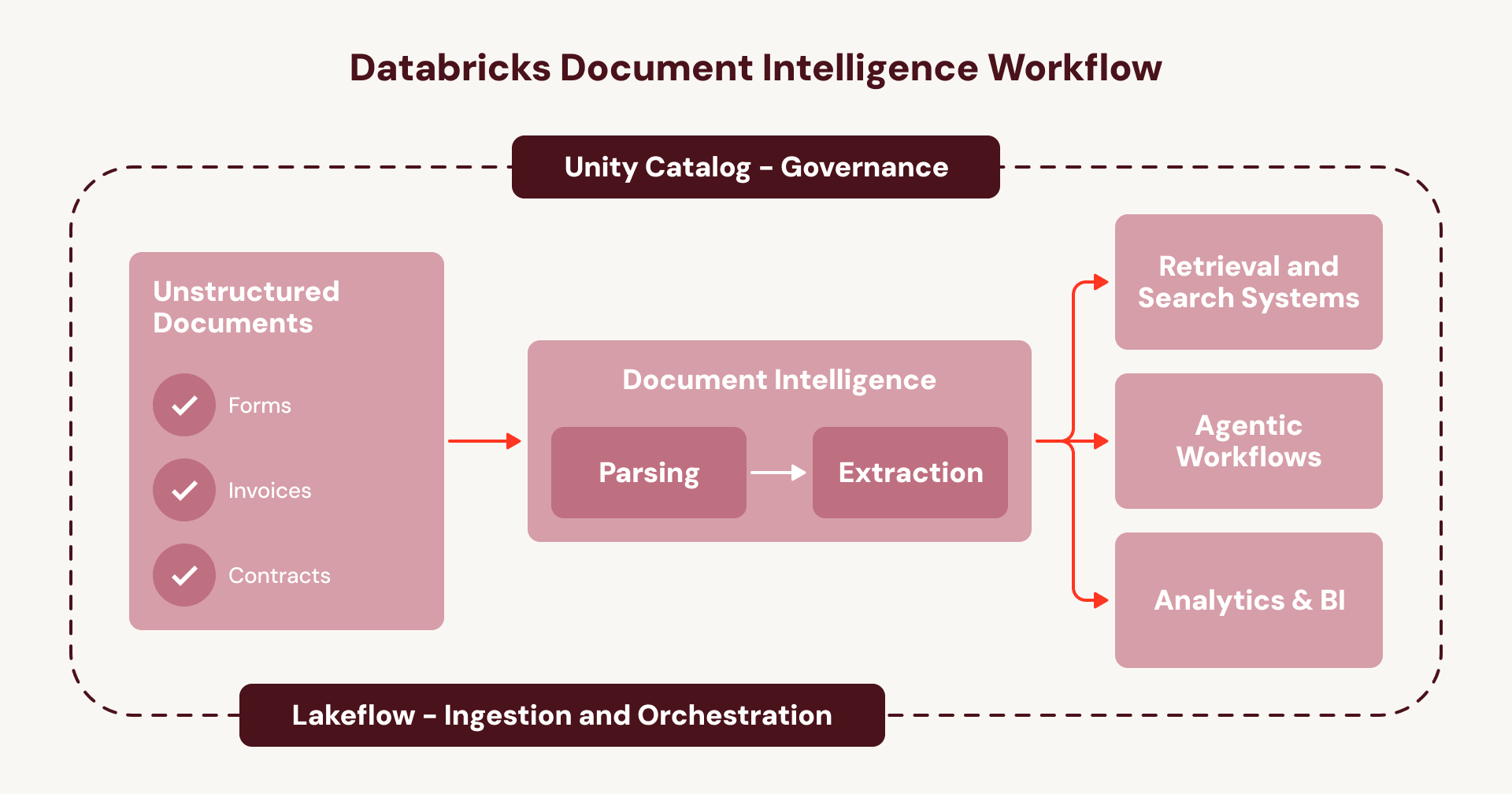
Für Unternehmen bedeutet dies, dass Document Intelligence auf einem einheitlichen und verwalteten Workflow anstelle eines Netzes von undurchsichtigen, fragmentierten Diensten läuft – ein wiederholbares Playbook, um Agenten-Anwendungsfälle über alle Ihre Dokumente hinweg zu skalieren.
Mit Databricks sind wir von manuellen, fragmentierten Prozessen zu automatisierter, skalierbarer Intelligenz übergegangen. Was früher Wochen dauerte, erledigen wir jetzt in Tagen – und gewinnen Erkenntnisse, die unsere Kunden nirgendwo anders bekommen können. —Tony Qui, EY-Parthenon Global Innovation Leader, Strategy and Transactions
Ihre Agenten sind nur so gut wie Ihre Dokumentenverarbeitungsschicht
Das Versprechen von Enterprise Agents hängt von einer Frage ab, die die meisten Organisationen noch nicht beantwortet haben: Können Ihre Agenten die Millionen von Dokumenten in Ihrem Unternehmen tatsächlich verstehen?
Deshalb freuen wir uns, Document Intelligence ankündigen zu können, um diese Lücke zu schließen: genau genug für geschäftskritische Workflows, durchgängig verwaltet, sodass Ihr Compliance-Team nicht Daten über verschiedene Anbieter hinweg verfolgen muss, und skalierbar vom ersten Pilotprojekt bis zur Produktion, ohne eine einzige Codezeile zu ändern.
Ihre Dokumente sind die reichhaltigste Quelle für Intelligenz in Ihrem Unternehmen. Es ist an der Zeit, dass Ihre Agenten sie lesen können.
- Lesen Sie unseren Anleitungs-Blogbeitrag zum Erstellen mit Document Intelligence und Lakeflow.
- Melden Sie sich für die Databricks Testversion an.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.