Erstellen mit Databricks Document Intelligence und Lakeflow
Verwandeln Sie gesperrtes Unternehmenswissen in abfragbare, vertrauenswürdige Erkenntnisse
von Giselle Goicochea und Joanna Zouhour
- Das meiste Unternehmenswissen ist in unstrukturierten Dokumenten unzugänglich, während die aktuelle intelligente Dokumentenverarbeitung (IDP) oft fehleranfällig und unzuverlässig ist
- Databricks Document Intelligence und Lakeflow ermöglichen es Dateningenieuren, einen End-to-End-IDP-Workflow einfach zu erstellen und zu automatisieren: Erfassung unstrukturierter Daten, deren Verarbeitung mit KI-Intelligenz, die im Unternehmenskontext verankert ist, und anschließende Orchestrierung in großem Maßstab, alles innerhalb einer verwalteten Plattform
- Datenteams können zuvor verborgene Dokumente in vertrauenswürdige, abfragbare Datensätze überführen, die neue Erkenntnisse, agentenbasierte Workflows und Wert für ihr Unternehmen erschließen
Trotz jahrzehntelanger Perfektionierung von strukturierten Datenpipelines bleiben 80 % des Wissens von Unternehmen funktional unsichtbar und sind in PDFs, Bildern und Office-Dokumenten gefangen.
Traditionell war Intelligent Document Processing (IDP) ein fragmentierter Albtraum. Vor der Ära der generativen KI waren Organisationen gezwungen, sich auf getrennte NLP- und Computer-Vision-APIs zu verlassen, die außerhalb ihrer primären Datenplattformen lagen. Diese isolierten OCR-Anbieter (Optical Character Recognition) boten eine begrenzte Genauigkeit und verfügten über keine formellen Governance-Protokolle, was zu erheblichen Reibungsverlusten führte. Um das Versprechen von Enterprise AI zu erfüllen, benötigen wir einen einheitlichen Ansatz, der Datenintelligenz direkt in den Datenlebenszyklus integriert.
Heute zeigen wir, wie Dateningenieure Lakeflow, die einheitliche Dateningineering-Lösung von Databricks, und Databricks Document Intelligence nutzen können, um diese Daten zu erschließen und in geschäftsentscheidende Intelligenz umzuwandeln, indem sie produktionsreife autonome IDP-Lösungen auf ihrer Databricks Platform aufbauen.

Schritt 1: Sichere Aufnahme mit Lakeflow Connect
Unternehmensdokumente leben in isolierten Archiven, die nur über fragile, benutzerdefinierte API-Integrationen zugänglich sind, die beim Umbenennen eines Ordners brechen. Lakeflow Connect, die Lösung von Databricks zur Aufnahme von Daten in das Lakehouse, verändert das Spiel mit integrierten Konnektoren für viele beliebte Unternehmensanwendungen, Datenbanken und Dateiquellen, einschließlich SharePoint und Google Drive.
Diese Lösung bietet eine wartungsfreie Aufnahme, da die Verwaltung komplexer OAuth-Flows oder benutzerdefinierter Python-Skripte entfällt. Dokumente landen direkt in Unity Catalog Volumes und Tabellen, sodass Zugriffskontrolle, Abstammung und Überwachung sofort nach der Speicherung der Datei im Lakehouse gelten und Sie dieselben feingranularen, attributbasierten Richtlinien wiederverwenden können, auf die Sie sich bereits für strukturierte Daten verlassen.
Dank der robusten Funktionen von Lakeflow Connect, einschließlich inkrementeller Lese- und Schreibvorgänge, die vollständige erneute Abfragen großer Bibliotheken für Batch-Backfills und nahezu Echtzeit-Dokumentflüsse in Kombination mit nachgelagertem Streaming vermeiden, erhalten Sie auch eine schnelle und effiziente Aufnahme in großem Maßstab.
Schritt 2: Erste Schritte mit Databricks Document Intelligence
Diese Unternehmensdokumente enthalten einige der wertvollsten Erkenntnisse Ihres Unternehmens, sind aber von Natur aus unordentlich, variabel und inkonsistent. Gescannte Seiten, handschriftliche Notizen und verschachtelte Tabellen speichern Ihre wertvollsten Erkenntnisse. Um dies zu beheben, benötigen Sie nicht nur ein weiteres Dokumentextraktionswerkzeug; wie Forrester feststellt, benötigen Sie eine „reasoning-first architectural evolution“. Mit diesem Ansatz prognostiziert Gartner, dass GenAI den Bedarf an benutzerdefinierten Dokumentmodellen um 70 % reduzieren wird.
Heute können Sie mit Databricks Document Intelligence modernste Dokumentenverständnis direkt in Ihre Daten bringen. Ihre Dateningenieurteams können speziell entwickelte KI-Funktionen nutzen, die komplexe Dokumente zuverlässig analysieren, strukturieren und anreichern können, direkt neben Ihren bestehenden Datenpipelines, alles nahtlos gesteuert durch Unity Catalog.
- ai_parse_document (neu - GA): Diese Funktion konvertiert unstrukturierte Dateien in strukturierte Darstellungen mithilfe des Variant-Datentyps. Sie verarbeitet nativ Eingabekomplexitäten, die herkömmliche Parser typischerweise überfordern, wie z. B. gescannte Bilder, Handschrift und variable Layouts, während die kritische Dokumentstruktur (z. B. verschachtelte Tabellen, Abschnitte und Kopfzeilen) erhalten bleibt, die bei der reinen Textextraktion verloren gehen würde. Dies ermöglicht es Ihnen, Schemata im Laufe der Zeit zu entwickeln, ohne Ihre Pipelines zu unterbrechen. Nachgelagert behandeln Sie die VARIANT-Ausgabe als flexible Bronze/Silver-Darstellung und projizieren sie mithilfe von SQL oder PySpark in Lakeflow Spark Declarative Pipelines in Delta-Spalten in Ihren Silver/Gold-Schichten.
Aufbauend auf der analysierten Struktur können Sie zusätzliche forschungsoptimierte KI-Funktionen verketten:
- ai_extract (PuPr) zum Extrahieren strukturierter Erkenntnisse wie Vertragsbeginn- und -ablaufdaten, Vertragspartner, Rechnungssummen, Steuern, Währung und Bestellnummern.
- ai_classify (PuPr) zum Weiterleiten von Dokumenten nach Typ (Rechnung, Bestellung, SOW, NDA), Dringlichkeit/Risiko oder zuständiger Geschäftseinheit.
- ai_prep_search (neu - Beta) zur intelligenten Aufteilung von Dokumenten in Chunks für qualitativ hochwertige nachgelagerte Einbettungen, die sie für Retrieval- oder Suchanwendungsfälle vorbereiten
Unten sehen Sie ein einfaches Beispiel für die Verkettung von ai_parse_document und ai_extract.
Hinweis: Dieses Beispiel zeigt PySpark, aber Sie können auch SQL verwenden (siehe Dokumentation).
Da es sich um verwaltete KI-Funktionen handelt, die in die Databricks Platform integriert sind, kann Document Intelligence diese mit Ihrem Unternehmenskontext (Katalogmetadaten, Geschäftsdefinitionen, vorhandene Tabellen) kombinieren, um agentenbasierte Workflows zu ermöglichen, die mit hoher Genauigkeit über Ihre Daten schlussfolgern, basierend auf Ihrem unternehmensspezifischen Domänenkontext.
Schritt 3: IDP-Workloads in großem Maßstab produktiv einsetzen
Sobald die Aufnahme und Analyse in Notebooks funktioniert, müssen Sie Ihre IDP produktiv einsetzen: Aufnahme, Analyse, Anreicherung und Bereitstellung orchestrieren. Sie möchten aber auch SLAs, Fehler und Wiederholungsversuche in CI/CD überwachen, um sicherzustellen, dass die Pipelines einwandfrei funktionieren.
Mit Lakeflow Jobs, dem nativen Orchestrator von Databricks, können Sie IDP-Workloads in robuste, automatisierte Pipelines mit demselben Orchestrierungssystem umwandeln, das Sie für ETL, Analysen und ML verwenden. Es bietet einheitliche Orchestrierung für jede Aufgabe im IDP-DAG, sodass Sie Notebooks, Python-Skripte, SQL-Abfragen, Pipelines, LLMs oder Agentenaufrufe in einem einzigen Job verketten und den gesamten Ablauf von der Dokumentenaufnahme modellieren können.
Lakeflow Jobs verfügt außerdem über integrierte erweiterte Kontrollflüsse (einschließlich Wenn/Dann-Bedingungen, For-Each, Wiederholungsversuche usw.) und Trigger (Tabellenaktualisierung, Dateiankunft, kontinuierlich usw.). Dies erleichtert 1) die erneute Verarbeitung nur fehlgeschlagener Partitionen oder bestimmter Dokumenten-Batches und 2) die Verwaltung von Jobs für bestimmte Zeitpläne, ereignisbasierte Trigger oder den kontinuierlichen Modus für Echtzeit-Dokumentenströme.
Mit dem Serverless Compute von Lakeflow Jobs mit nativer Beobachtbarkeit erhalten Sie außerdem automatische Skalierung bei Spitzen im Dokumentenvolumen und gleichzeitig Echtzeit-Überwachung, Metriken und Benachrichtigungen, sodass Sie Engpässe erkennen und Fehler beheben können, ohne erfolgreiche Aufgaben erneut ausführen zu müssen.
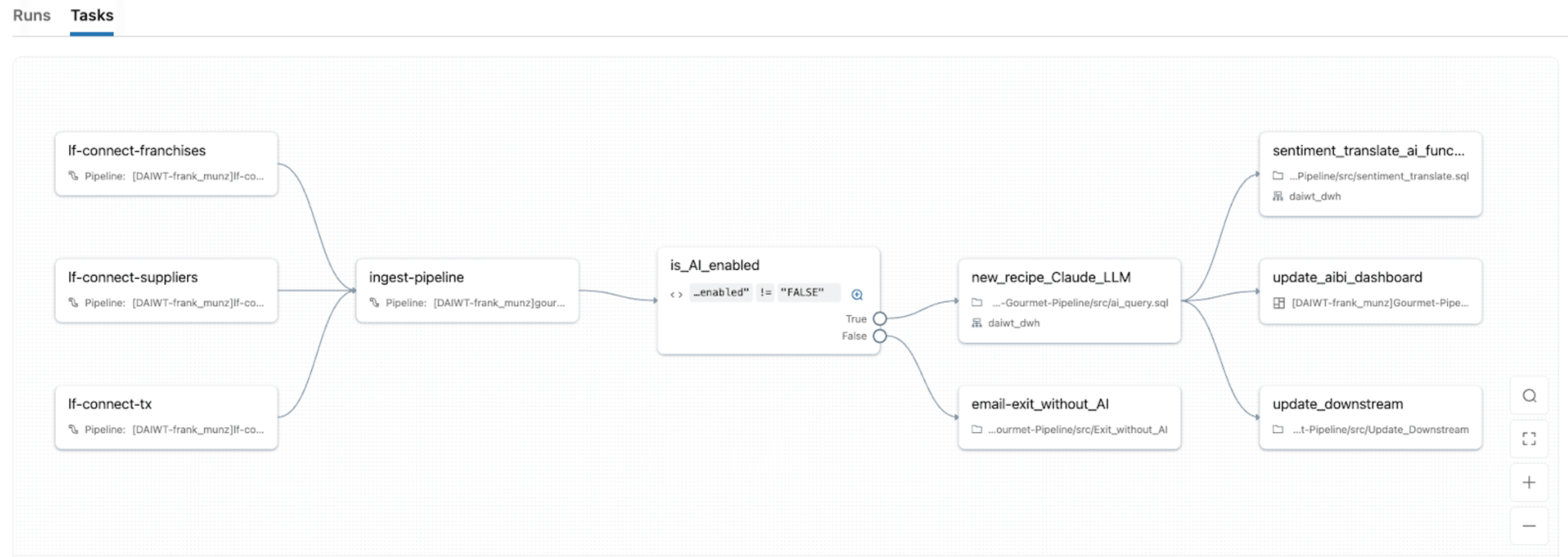
KI im Unternehmenskontext verankern
IDP ist am wertvollsten, wenn es durch Unternehmenskontext gestützt wird: Ihre einzigartigen Schemata, Geschäftsdefinitionen und benutzerdefinierten Semantiken.
Unity Catalog
Unity Catalog bietet einheitliche Governance und Entdeckung für strukturierte Daten, unstrukturierte Dateien, ML-Modelle und Geschäftsmetriken in jeder Cloud. Für IDP bedeutet dies:
- Ein zentraler Ort zur Definition von Zugriffsrichtlinien, Datenherkunft und Überwachung für sowohl Rohdokumente als auch abgeleitete strukturierte Tabellen
- Unterstützung für offene Formate (Delta, Apache Iceberg, Hudi, Parquet), damit Sie nicht an eine proprietäre Dokumentendarstellung gebunden sind
- Semantische Geschäftsdaten und Metadaten auf Katalogebene, die Agenten verwenden können, um Entitäten wie „Anbieter“, „Kunde“ oder „Vertragswert“ konsistent zu benennen und zu interpretieren.
Dokumentenintelligenz
Dokumentenintelligenz nutzt diesen Kontext, um produktive KI-Agenten zu erstellen, die wissen, welche Tabellen, Tools und Modelle für eine bestimmte IDP-Aufgabe verwendet werden sollen, die durchgängig gesteuert werden, sodass sie nie mehr zugreifen, als sie sollten, und die sich kontinuierlich durch LLM-basiertes Qualitäts-Scoring, aufgabenspezifische Benchmarks und Lernschleifen verbessern. Für Entwickler bietet Databricks APIs und SDKs, damit Sie diese Agenten als Code definieren und wie jeden anderen Daten- oder ML-Asset in Ihre bestehenden CI/CD-Pipelines integrieren können.
Best Practices für den modernen IDP-Stack
Um von der Pilotphase zur Plattform zu gelangen, beachten Sie diese Best Practices:
- Datenanreicherung: Extrahieren Sie nicht nur einen „Anbieternamen“. Verknüpfen Sie ihn mit Ihren internen Masterdaten oder Drittanbieterquellen (wie Dun & Bradstreet), um den vollständigen Geschäftskontext bereitzustellen.
- Betriebliche Exzellenz: Verwenden Sie Service Principals für Lakeflow Jobs, um die Stabilität der Pipeline zu gewährleisten.
- Überwachung: Verwenden Sie Lakehouse Monitoring, um Modelldrift und Extraktionsgenauigkeit im Laufe der Zeit zu verfolgen.
Der Weg zur modernen Datenintelligenz
Mit Databricks können Sie den gesamten Lebenszyklus der Intelligenten Dokumentenverarbeitung auf einer modernen Datenplattform verwalten. Durch die Kombination von Lakeflow und KI-Funktionen können Sie unstrukturierte, verborgene Daten in vertrauenswürdige, abfragbare Datensätze umwandeln und beobachtbare Dokumenten-Pipelines nahtlos neben Ihrer Kern-ETL und ML ausführen.
Nachdem wir nun den strategischen Wert der autonomen Dokumentenintelligenz behandelt haben, ist es an der Zeit, sie zu erstellen. Sehen Sie sich unseren Begleitbeitrag From PDF to Insights für eine schrittweise technische Anleitung zur Bereitstellung dieser genauen Architektur mit Databricks an.
Sie können auch die Dokumentation zu Dokumentenintelligenz und Lakeflow erkunden, um noch heute mit dem Erstellen Ihrer ersten IDP-Pipeline zu beginnen!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.